
Oracle соединение типа звезда
Многомерная схема специально разработана для моделирования систем хранилищ данных. Схемы предназначены для удовлетворения уникальных потребностей очень больших баз данных, разработанных для аналитических целей (OLAP).
Типы схем хранилища данных:
Ниже приведены 3 основных типа многомерных схем, каждая из которых имеет свои уникальные преимущества.
- Схема звезды
- Снежинка Схема
- Галактика Схема
В этом уроке вы узнаете больше о
Правое внешнее соединение
Вернуть все записи в правой таблице и записи в левой таблице, которые соответствуют условиям.
Схема «звезда против снежинки»: основные отличия
| Схема звезды | Схема снежных хлопьев |
|---|---|
| Иерархии для измерений хранятся в таблице измерений. | Иерархии разделены на отдельные таблицы. |
| Он содержит таблицу фактов, окруженную таблицами измерений. | Одна таблица фактов, окруженная таблицей измерений, которая в свою очередь окружена таблицей измерений |
| В схеме типа «звезда» только одно соединение создает связь между таблицей фактов и любыми таблицами измерений. | Схема снежинки требует много соединений для извлечения данных. |
| Простой дизайн БД. | Очень сложный дизайн БД. |
| Денормализованная структура данных и запрос также выполняются быстрее. | Нормализованная структура данных. |
| Высокий уровень избыточности данных | Очень низкоуровневая избыточность данных |
| Таблица одного измерения содержит агрегированные данные. | Данные разбиты на разные таблицы измерений. |
| Обработка куба происходит быстрее. | Обработка куба может быть медленной из-за сложного соединения. |
| Предлагает более эффективные запросы, используя Star Join Query Optimization. Таблицы могут быть связаны с несколькими измерениями. | Схема снежных хлопьев представлена централизованной таблицей фактов, которая вряд ли связана с несколькими измерениями. |
Что такое схема снежинка?
SCHEMA SNOWFLAKE – это логическое расположение таблиц в многомерной базе данных, так что диаграмма ER напоминает форму снежинки. Схема «Снежинка» является расширением схемы «Звезда» и добавляет дополнительные измерения. Таблицы измерений нормализуются, что разбивает данные на дополнительные таблицы.
В следующем примере Страна далее нормализуется в отдельную таблицу.

Характеристики схемы «Снежинка»:
- Основное преимущество схемы «снежинка» – использование меньшего дискового пространства.
- Проще реализовать измерение добавляется в схему
- Из-за нескольких таблиц производительность запросов снижается
- Основная проблема, с которой вы столкнетесь при использовании схемы «снежинка», заключается в том, что вам нужно выполнять больше усилий по обслуживанию из-за большего количества таблиц поиска.
О моделировании нормализованных источников
Нормализованные или транзакционные источники распределяют данные по нескольким таблицам, чтобы свести к минимуму избыточность хранения данных и оптимизировать обновление данных. В нормализованном источнике есть несколько файлов данных, соответствующих каждой из транзакционных таблиц. Вероятно, данные из приложений Oracle Cloud секционированы в нормализованном источнике.
Подобно источникам с ветвлением с самопересечением моделирование нормализованных источников включает создание представлений баз данных для объединения столбцов из нескольких исходных таблиц в отдельные таблицы фактов и измерений. Для некоторых очень сложных нормализованных источников требуется несколько представлений базы данных, чтобы организовать данные в звездообразную модель.
Например, у вас есть исходные файлы для таблиц "Продукты", "Заказчики", "Заказы" и "Позиции заказа". В таблицах "Заказы" и "Позиции заказа" содержатся факты.
В этом сценарии сначала необходимо загрузить файлы в виде отдельных таблиц базы данных. Затем создается представление базы данных, объединяющее несколько столбцов фактов в одну таблицу. В этом примере создается представление, объединяющее столбцы из таблиц "Заказы" и "Позиции заказа".
Затем с помощью построителя моделей данных создается таблица фактов (представление "Заказы" плюс "Позиции заказа") и таблица измерений ("Продукты" и "Заказчики"). На последнем этапе необходимо создать соединения между таблицами измерений и таблицей фактов.
Полный список задач моделирования данных см. в разделе План действий по моделированию данных.
Выбор способа хранения данных зависит от объема и структуры детальных данных, требований к скорости выполнения запросов и частоты обновления OLAP -кубов. В настоящее время применяются три способа хранения данных :
MOLAP (Multidimensional OLAP)
Детальные и агрегированные данные хранятся в многомерной базе данных. Хранение данных в многомерных структурах позволяет манипулировать данными как многомерным массивом, благодаря чему скорость вычисления агрегатных значений одинакова для любого из измерений. Однако в этом случае многомерная база данных оказывается избыточной , так как многомерные данные полностью содержат детальные реляционные данные.
- Высокая производительность . Поиск и выборка данных осуществляется значительно быстрее, чем при многомерном концептуальном взгляде на реляционную базу данных .
- Структура и интерфейсы наилучшим образом соответствуют структуре аналитических запросов.
- Многомерные СУБД легко справляются с задачами включения в информационную модель разнообразных встроенных функций .
- MOLAP могут работать только со своими собственными многомерными БД и основываются на патентованных технологиях для многомерных СУБД , поэтому являются наиболее дорогими. Эти системы обеспечивают полный цикл OLAP -обработки и либо включают в себя, помимо серверного компонента, собственный интегрированный клиентский интерфейс, либо используют для связи с пользователем внешние программы работы с электронными таблицами.
- По сравнению с реляционными, очень неэффективно используют внешнюю память , обладают худшими по сравнению с реляционными БД механизмами транзакций .
- Отсутствуют единые стандарты на интерфейс, языки описания и манипулирования данными.
- Не поддерживают репликацию данных, часто используемую в качестве механизма загрузки.
ROLAP (Relational OLAP)
ROLAP -системы позволяют представлять данные, хранимые в классической реляционной базе, в многомерной форме или в плоских локальных таблицах на файл-сервере , обеспечивая преобразование информации в многомерную модель через промежуточный слой метаданных . Агрегаты хранятся в той же БД в специально созданных служебных таблицах. В этом случае гиперкуб эмулируется СУБД на логическом уровне.
- Реляционные СУБД имеют реальный опыт работы с очень большими БД и развитые средства администрирования . При использовании ROLAP размер хранилища не является таким критичным параметром, как в случае MOLAP .
- При оперативной аналитической обработке содержимого хранилища данных инструменты ROLAP позволяют производить анализ непосредственно над хранилищем (потому что в подавляющем большинстве случаев корпоративные хранилища данных реализуются средствами реляционных СУБД ).
- В случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP системы с динамическим представлением размерности являются оптимальным решением, так как в них такие модификации не требуют физической реорганизации БД , как в случае MOLAP .
- Системы ROLAP могут функционировать на гораздо менее мощных клиентских станциях, чем системы MOLAP , поскольку основная вычислительная нагрузка в них ложится на сервер, где выполняются сложные аналитические SQL-запросы , формируемые системой.
- Реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа.
- Ограниченные возможности с точки зрения расчета значений функционального типа.
- Меньшая производительность , чем у MOLAP . Для обеспечения сравнимой с MOLAP производительности реляционные системы требуют тщательной проработки схемы БД и специальной настройки индексов. Но в результате этих операций производительность хорошо настроенных реляционных систем при использовании схемы " звезда " сравнима с производительностью систем на основе многомерных БД .
HOLAP (Hybrid OLAP)
Детальные данные остаются в той же реляционной базе данных, где они изначально находились, а агрегатные данные хранятся в многомерной базе данных.
Компоненты моделей данных
Таблицы фактов, таблицы измерений, соединения и иерархии – ключевые компоненты, с которыми приходится иметь дело при построении модели данных.
В таблицах фактов содержатся показатели (столбцы), в определения которых встроены агрегирования.
В таблице фактов необходимо определить показатели, агрегированные из фактов. Обычно показатели представляют собой вычисленные данные, такие как цена в долларах или проданное количество. Их можно указывать в терминах иерархий. Например, требуется определить сумму долларов для заданного продукта на заданном рынке за заданный период времени.
У каждого показателя есть собственное правило агрегирования, такое как SUM, AVG, MIN или MAX. Бизнесу может потребоваться сравнение значений показателя и вычисление, чтобы выразить такое сравнение.
В бизнесе факты используются для измерения эффективности по хорошо заданным измерениям, например по времени, продуктам и рынкам. У каждого измерения есть набор описательных атрибутов. В таблицах измерений содержатся атрибуты, описывающие хозяйственные единицы (например, "Имя заказчика", "Регион", "Адрес" или "Страна").
Атрибуты таблицы измерений предоставляют контекст для числовых данных, такой как возможность категоризации запросов на обслуживание. Сохраненные в измерении атрибуты могут включать владельца запроса на обслуживание, область, учетную запись или приоритет.
Таблицы измерений в таблице данных согласованы. Другими словами, даже если есть три разных исходных экземпляра конкретной таблицы "Заказчик", в модели данных существует только одна таблица. Для этого все три исходных экземпляра таблицы "Заказчик" объединяются в одну с помощью представлений базы данных.
Соединения указывают на отношения между таблицами фактов и таблицами измерений в модели данных. При создании соединений указываются таблица фактов, таблица измерений, столбец фактов и столбец измерений, которые требуется соединить.
Соединения позволяют с помощью запросов возвращать строки хотя бы с одним соответствием в обеих таблицах.
Совет: при создании отчетов аналитики могут использовать параметр Включать неопределенные значения чтобы вернуть строки из одной таблицы, для которых нет соответствующих строк в другой таблице.
См. раздел Подавление неопределенных значений в представлениях в документе Работа с Oracle Business Intelligence Cloud Service .
Иерархии — это наборы нисходящих отношений между атрибутами таблицы измерений.
В иерархиях уровни сворачиваются от самых нижних уровней к самым высоким. Например, месяцы можно свернуть в год. Такие свертки возникают с элементами иерархии и охватывают естественные деловые отношения.
Внутреннее соединение
Вернуть совпадающие данные в двух таблицах. (Возвращать только те данные, которые соответствуют условиям) Эквивалентные соединения, неэквивалентные соединения и естественные соединения - все это внутренние соединения.
union
Оператор объединения используется для получения объединения двух наборов результатов, автоматически удаляет повторяющиеся строки в наборе результатов и сортирует результаты в порядке возрастания в первом столбце.
О моделировании денормализованных источников
Денормализованные источники объединяют факты и измерения в виде столбцов одной таблицы (или плоского файла). При использовании плоского денормализованного источника в одну таблицу загружается один файл данных. Этот файл данных состоит из атрибутов измерений и столбцов показателей.
В некоторых случаях модель данных может представлять собой гибридную структуру – комбинацию денормализованных источников, источников типа "звезда" и источников типа "снежинка". Например, денормализованный источник может содержать информацию о показателях дохода, продуктах, клиентах и заказах, но все эти данные будут представлены в виде одного файла, а не в виде нескольких отдельных исходных файлов.
Первый шаг этого сценария — загрузка денормализованного файла в виде одиночной таблицы базы данных. Затем необходимо разбить столбцы на несколько таблиц фактов и измерений с помощью мастера "Добавить в модель". В приведенном примере показан процесс создания таблицы фактов путем перемещения столбцов показателей дохода и процесс создания трех отдельных таблиц измерений путем перемещения столбцов с данными продуктов, клиентов и заказов. На последнем этапе необходимо создать соединения между таблицами измерений и таблицей фактов.
Полный список задач моделирования данных см. в разделе План действий по моделированию данных.
О моделировании объектов источника по схеме "звезда"
Источники типа "Звезда" содержат одну или несколько таблиц фактов, ссылающихся на любое количество таблиц измерений. Поскольку построитель моделей данных представляет данные в виде звездообразной структуры, при моделировании проще всего работать с источниками типа "звезда". В источниках типа "звезда" измерения нормализуются с каждым измерением, представленным в одной таблице.
Пример: предположим, что имеются отдельные источники для показателей дохода, продуктов, клиентов и заказов. В этом сценарии необходимо загрузить данные из каждого источника в отдельные таблицы базы данных. Затем с помощью построителя моделей данных создается таблица фактов ("Показатели дохода") и несколько таблиц измерений ("Продукты", "Клиенты" и "Заказы"). На последнем этапе необходимо создать соединения между таблицами измерений и таблицей фактов.
При создании таблиц фактов и измерений можно перемещать объекты источника в модель данных или создавать отдельные таблицы фактов и измерений с помощью функций, доступных в меню.
Полный список задач моделирования данных см. в разделе План действий по моделированию данных.
Cross join cross join (понять)
В практических приложениях декартово множество, сгенерированное перекрестным соединением, само по себе не очень полезно, и только когда две таблицы связаны, могут быть добавлены следующие ограничения, имеющие практическое значение. Кроме того, он может обеспечить быстрый и простой способ создания большого количества наборов данных, которые можно использовать для тестирования и так далее.
intersect
Оператор пересечения используется для получения пересечения двух наборов результатов. Будут отображаться только данные, которые существуют в обоих наборах результатов, а результаты в первом столбце будут отсортированы в порядке возрастания.
minus
Оператор минус используется для получения разности двух наборов результатов. Будут отображаться только данные, которые существуют в первом наборе результатов, но не существуют во втором наборе результатов, а набор результатов в первом столбце будет отсортирован в порядке возрастания.
Что такое схема звездного кластера?
Схема снежинки содержит полностью расширенные иерархии. Однако это может усложнить схему и потребует дополнительных объединений. С другой стороны, схема «звезда» содержит полностью свернутые иерархии, что может привести к избыточности. Таким образом, лучшим решением может быть баланс между этими двумя схемами, который представляет собой проект STAR CLUSTER SCHEMA .

Перекрывающиеся измерения могут быть найдены в виде вилок в иерархиях. Разветвление происходит, когда сущность выступает в качестве родителя в двух разных иерархиях измерений. Объекты-вилки затем идентифицируются как классификация с отношениями один-ко-многим.
Срикант Белламконда, Рафи Ахмед, Анжела Амор, Мохамед Зэйд
Оригинал: Enhanced Subquery Optimizations in Oracle / Srikanth Bellamkonda, Rafi Ahmed, Andrew Witkowski, Angela Amor, Mohamed Zait, Chun-Chieh Lin // Proceedings of the 35th international conference on Very large data base, 2009, pp. 1366 — 1377
Содержание
Аннотация
В статье описывается расширенная оптимизация подзапросов в реляционной СУБД Oracle. Рассматривается несколько методов – сращивание подзапросов (subquery coalescing), удаление подзапросов с использованием оконных функций (subquery removal using window functions) и устранение представлений для запросов с группировкой (group by view elimination). Эти методы распознают и устраняют избыточность в структурах запроса и преобразуют запросы к потенциально более оптимальным формам. В статье также обсуждаются новые методы параллельного выполнения, которые обладают универсальной применимостью и используются для улучшения масштабируемости запросов, подвергнутых некоторым из этих преобразований. Описывается новый вариант антисоединения для оптимизации подзапросов с квантором всеобщности, столбцы которых могут содержать неопределенное значение. Далее представляются результаты проверки производительности этих оптимизаций, которые показывают существенное уменьшение времени выполнения.
1. Введение
Современные реляционные СУБД выполняют сложные SQL-запросы, включающие вложенные подзапросы с функциями агрегации, представления с union/union all , distinct , group by и т.д. Такие запросы становятся все более и более важными в системах поддержки принятия решений (Decision-Support System, DSS) и оперативной аналитической обработки (On-Line Analytical Processing, OLAP). В качестве метода оптимизации таких запросов принято использовать преобразование запросов.
Подзапросы – это мощный компонент языка SQL, повышающий его уровень декларативности и выразительных возможностей. Стандарт SQL позволяет использовать подзапросы в разделах SELECT , FROM , WHERE и HAVING . Подзапросы широко используются в эталонных тестовых наборах поддержки принятия решений TPC-H [4] и TPC-DS [15]. Почти половина из 22 запросов в тестовом наборе TPC-H содержит подзапросы. Почти все подзапросы являются коррелированными, и многие из них содержат вызовы агрегатных функций. Поэтому эффективное выполнение сложных подзапросов является существенно важным для систем баз данных.
1.1. Преобразование запросов в Oracle
В Oracle выполняется множество преобразований запросов – устранение вложенности подзапросов (subquery unnesting), слияние представлений с группировкой и удалением дубликатов (group-by and distinct view merging), исключение общих подвыражений (common sub-expression elimination), проталкивание предикатов соединений (join predicate pushdown), факторизация соединений (join factorization), преобразование теоретико-множественных операций пересечения и вычитания в (анти)соединение (conversion of set operators intersect and minus into (anti)join), раскрытие OR (OR expansion), преобразование типа "звезда" (star transformation), размещение операций группировки и удаления дубликатов (group-by and distinct placement) и т.д. Преобразования запросов могут быть основаны на эвристиках или оценке стоимости. При применении преобразований, основанных на оценке стоимости, для генерации оптимального плана комбинируются логические преобразования и физическая оптимизация.
В Oracle 10g появились общая инфраструктура (framework) [8] преобразований запросов на основе оценки стоимости и несколько стратегий поиска в пространстве состояний. При выполнении преобразований, основанных на оценке стоимости, запрос копируется, преобразуется, и с использованием существующего стоимостного физического оптимизатора вычисляется его стоимость. Этот процесс повторяется несколько раз с применением новых наборов преобразований; и в конце концов выбирается одно или несколько преобразований, которые применяются к исходному запросу, если это приводит к оптимальной стоимости. Инфраструктура преобразований на основе оценки стоимости обеспечивает механизм для исследования пространства состояний, образуемого при применении одного или нескольких преобразований, что позволяет Oracle эффективным образом выбирать оптимальное преобразование. Инфрастуктура преобразований на основе оценки стоимости позволяет справляться со сложностями, возникающими при наличии в запросе пользователя нескольких блоков запроса и взаимной зависимости преобразований. Наличие общей инфрастуктуры преобразований на основе оценки стоимости позволяет расширять обширный репертуар методов преобразования запросов Oracle новыми преобразованиями. В этой статье представлены новые методы преобразования – сращивание подзапросов (subquery coalescing), удаление подзапросов (subquery removal) и устранение фильтрующего соединения (filtering join elimination).
1.2. Устранение вложенности подзапросов
Устранение вложенности подзапросов [1], [2], [8], [9] – это важное преобразование запросов, поддерживаемое во многих системах баз данных. Если вложенность коррелированного подзапроса не устраняется, он вычисляется несколько раз с использованием семантики покортежной итерации (tuple iteration semantics). Это похоже на соединение методом вложенных циклов, и, следовательно, при этом не могут быть учитываться эффективные пути доступа, методы соединений и порядки соединений.
В Oracle устраняется вложенность подзапросов почти всех типов. Имеются две широкие категории методов устранения вложенности – методы первой категории порождают производные таблицы (inline views, встроенные представления), а методы второй категории сливают подзапрос с телом содержащего его запроса. В Oracle методы первой категории применяется на основе оценок стоимости, а методы второй категории – эвристическим способом.
Устранение вложенности нескалярных подзапросов часто приводит к полу- или антисоединениям. В Oracle для выполнения полу- или антисоединения могут использоваться индексный поиск, хеширование и сортировка со слиянием. Исполнительный механизм Oracle кэширует результаты полу- и антисоединений для кортежей левой таблицы, так что можно избежать нескольких вычислений результатов подзапроса, если в столбцах соединения левой таблицы имеется большое число дубликатов. В Oracle устраняется вложенность подзапросов, входящих в квантифицированное (с квантором существования или всеобщности) сравнение с операцией сравнения, отличной от равенства (например, > ANY , < ALL и т.д.) c использованием соединения методом сортировки со слиянием по предикату сравнения при отсутствии соответствующих индексов.
Вложенность подзапросов, являющихся операндами операций сравнения с квантором всеобщности (например, <> ALL ), со столбцами, в которых допускаются неопределенные значения, не может быть устранена с использованием обычного антисоединения. Для устранения вложенности таких подзапросов в Oracle используется вариант антисоединения, называемый антисоединением с учетом наличия неопределенных значений (null-aware antijoin).
1.3. Оконные функции
В стандарте SQL 2003 [11] SQL расширяется оконными функциями 1 , которые не только обеспечивают простые и изящные выразительные средства для формулировки аналитических запросов, но также могут способствовать эффективной оптимизации и выполнению запросов, позволяя избежать многочисленных самосоединений (self-join) и наличия нескольких блоков запроса. Оконные функции широко используются в ряде аналитических приложений. В Oracle оконные функции поддерживаются начиная с версии Oracle 8i. Синтаксис оконных функций выглядит следующим образом:
Оконные функции вычисляются внутри разделов (partition), определяемых ключами pk1, pk2 и т.д. раздела PARTITION BY (PBY) , над данными, упорядоченными внутри каждого раздела по значениями ключей ok1, ok2 и т.д. раздела ORDER BY (OBY) . В разделе WINDOW определяется окно (window) (начальная и конечная точки) для каждой строки. В качестве оконных функций могут использоваться агрегатные функции SQL ( SUM , MIN , COUNT и т.д.), функции ранжирования ( RANK , ROW_NUMBER и т.д.) или ссылочные функции ( LAG , LEAD , FIRST_VALUE и т.д.). Детали синтаксиса и семантики оконных функций описаны в стандарте ANSI SQL [10] [11].
Оконные функции в блоке запроса вычисляются после разделов WHERE , GROUP BY и HAVING . Oracle вычисляет оконную функцию, сортируя данные по ключам разделов PBY и OBY и выполняя, если это требуется, проходы по отсортированным данным. Мы называем такой способ выполнения методом сортировки окна (window sort). Очевидно, что, если оконная функция не содержит ключей PBY и OBY , сортировка не требуется. В этом случае Oracle буферизирует данные, требуемые для вычисления оконной функции, и такой способ выполнения называется методом буферизации окна (window buffer).
Оценочный оптимизатор Oracle устраняет сортировку при оконных вычислениях, если выбирается план, производящий данные в порядке ключей PBY и OBY . В этом случае выполнение производится на основе буферизации окна, когда Oracle просто буферизирует данные и производит несколько проходов по ним для вычисления оконной функции. Однако если данные поступают упорядоченными, то для вычисления оконных функций типа RANK , ROW_NUMBER , кумулятивных (cumulative)(нарастающих) оконных агрегатов можно избежать и буферизации. Сохраняя некоторую информацию о контексте (значения оконной функции и ключей PBY ), можно вычислить эти функции при обработке входных данных.
1.3.1. Оконные функции для генерации отчетов
Оптимизация подзапросов, представленная в этой статье, используется для класса оконных функций, называемых оконными функциями для генерации отчетов (Reporting Window Functions). Это такие оконные функции, которые, в силу своей спецификации, возвращают для каждой строки агрегированное значение всех строк соответствующего раздела (как он определяется ключами PBY ). Если оконная функция не содержит разделов OBY и WINDOW , или если окно для каждой строки включает в себя все строки раздела, к которому она относится, то эта функция является оконной функцией для генерации отчетов. В этой статье мы иногда называем эти функции агрегатами для генерации отчетов (reporting aggregate).
Оконные функции для генерации отчетов полезны в сравнительном анализе, где они обеспечивают возможность сравнить значение строки на некотором уровне детализации со значением на более общем уровне детализации. Например, чтобы вычислить для некоторого тикера (кода акции) отношение каждодневного объема биржевых торгов к общему объему, для каждой строки (на уровне одного дня) требуется получить агрегированную сумму за все дни. Оконная функция, которая выдает агрегированную сумму для всех строк, и ее результирующие данные выглядели бы примерно таким образом :
Таблица 1. Пример оконной функции для генерации отчетов SUM
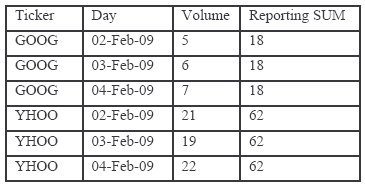
Если в агрегате для генерации отчетов отсутствуют ключи PBY , то выдаваемое им значение является общим итогом по всем строкам, так как имеется только один неявный раздел. Мы называем такие агрегаты для генерации отчетов функциями общего итога (grand-total, GT). Наши преобразования запросов в некоторых случаях вставляют в запрос GT-функции.
Приступая к моделированию данных, необходимо продумать бизнес-требования и изучить понятия моделирования данных.
Моделирование многомерных кубов на реляционной модели данных
Схема звезда. Преимущества и недостатки
Схема типа звезды ( Star Schema ) - схема реляционной базы данных , служащая для поддержки многомерного представления содержащихся в ней данных.
*Особенности ROLAP -схемы типа " звезда "*
- Одна таблица фактов ( fact table ), которая сильно денормализована. Является центральной в схеме, может состоять из миллионов строк и содержит суммируемые или фактические данные, с помощью которых можно ответить на различные вопросы.
- Несколько денормализованных таблиц измерений ( dimensional table ). Имеют меньшее количество строк, чем таблицы фактов, и содержат описательную информацию. Эти таблицы позволяют пользователю быстро переходить от таблицы фактов к дополнительной информации.
- Таблица фактов и таблицы размерности связаны идентифицирующими связями, при этом первичные ключи таблицы размерности мигрируют в таблицу фактов в качестве внешних ключей . Первичный ключ таблицы факта целиком состоит из первичных ключей всех таблиц размерности .
- Агрегированные данные хранятся совместно с исходными.
Преимущества
Благодаря денормализации таблиц измерений упрощается восприятие структуры данных пользователем и формулировка запросов, уменьшается количество операций соединения таблиц при обработке запросов. Некоторые промышленные СУБД и инструменты класса OLAP / Reporting умеют использовать преимущества схемы " звезда " для сокращения времени выполнения запросов.
Денормализация таблиц измерений вносит избыточность данных, возрастает требуемый для их хранения объем памяти. Если агрегаты хранятся совместно с исходными данными, то в измерениях необходимо использовать дополнительный параметр - уровень иерархии .

Схема снежинка. Преимущества и недостатки
Схема типа снежинки ( Snowflake Schema ) - схема реляционной базы данных , служащая для поддержки многомерного представления содержащихся в ней данных, является разновидностью схемы типа " звезда " ( Star Schema ).
*Особенности ROLAP -схемы типа "снежинка"*
- Одна таблица фактов ( fact table ), которая сильно денормализована. Является центральной в схеме, может состоять из миллионов строк и содержать суммируемые или фактические данные, с помощью которых можно ответить на различные вопросы.
- Несколько таблиц измерений ( dimensional table ), которые нормализованы в отличие от схемы " звезда ". Имеют меньшее количество строк, чем таблицы фактов, и содержат описательную информацию. Эти таблицы позволяют пользователю быстро переходить от таблицы фактов к дополнительной информации. Первичные ключи в них состоят из единственного атрибута (соответствуют единственному элементу измерения).
- Таблица фактов и таблицы размерности связаны идентифицирующими связями, при этом первичные ключи таблицы размерности мигрируют в таблицу фактов в качестве внешних ключей . Первичный ключ таблицы факта целиком состоит из первичных ключей всех таблиц размерности .
- В схеме "снежинка" агрегированные данные могут храниться отдельно от исходных.
Преимущества
Нормализация таблиц измерений в отличие от схемы " звезда " позволяет минимизировать избыточность данных и более эффективно выполнять запросы, связанные со структурой значений измерений.
За нормализацию таблиц измерений иногда приходится платить временем выполнения запросов.
Oracle и SQL Server во многом имеют одинаковый синтаксис, но внешнее соединение немного отличается, поэтому здесь оно специально упоминается.
Внешнее соединение завершается оператором «(+)», см. Следующий рисунок:

Правое внешнее соединение: вернуть все записи таблицы справа от знака равенства (то есть table2), которая также содержит записи, не соответствующие условиям соединения; вернуть записи, которые соответствуют условиям таблицы слева от знака равенства (то есть table1).
Левое внешнее соединение: вернуть все записи таблицы слева от знака равенства (то есть table1), которая также содержит записи, не удовлетворяющие условиям соединения; вернуть записи, которые соответствуют условиям таблицы справа от знака равенства (то есть table1).
Несколько типов запросов на соединение, упомянутых в стандарте SQL1999: перекрестное соединение, естественное соединение, внутреннее соединение, внешнее соединение (разделенное на левое внешнее соединение, правое внешнее соединение и полное (полное) внешнее соединение).
Что такое схема Galaxy?
GALAXY SCHEMA содержит два факта таблицы , что таблицы измерений доли между ними. Это также называется Схема Созвездия Фактов. Схема рассматривается как набор звезд, отсюда и название Galaxy Schema.

Как вы можете видеть в приведенном выше примере, есть две таблицы фактов
В общих схемах Galaxy размеры измерений называются Conformed Dimensions.
Характеристики галактической схемы:
- Измерения в этой схеме разделены на отдельные измерения на основе различных уровней иерархии.
- Например, если география имеет четыре уровня иерархии, таких как регион, страна, штат и город, то схема Galaxy должна иметь четыре измерения.
- Более того, можно построить схему такого типа, разбив схему с одной звездой на несколько схем типа Star.
- Размеры в этой схеме велики, что необходимо для построения на основе уровней иерархии.
- Эта схема полезна для объединения таблиц фактов для лучшего понимания.
Моделирование объектов источника по схеме "снежинка"
Источники типа "снежинка" схожи с источниками типа "звезда". Однако в структуре "снежинка" измерения нормализованы и представлены в виде нескольких родственных таблиц, а не в виде отдельных таблиц измерений.
Пример: предположим, что имеются отдельные источники для показателей дохода, продуктов, клиентов и заказов. Помимо этого имеются отдельные источники для брендов (соединенные с продуктами) и группы клиентов (соединенные с клиентами). Таблицы "Бренды" и "Группа клиентов" относятся к типу "снежинка", так как они являются "ответвлениями" основных таблиц измерений "Клиенты" и "Продукты".
В этом сценарии необходимо загрузить данные из каждого источника в отдельные таблицы базы данных. Затем необходимо создать представления базы данных, объединяющие несколько таблиц измерений в одну таблицу. В приведенном примере создано одно представление, объединяющее таблицы "Продукты" и "Бренды", и еще одно представление, объединяющее таблицы "Клиенты" и "Группа клиентов".
Затем с помощью построителя моделей данных необходимо создать таблицу фактов ("Показатели дохода") и таблицы измерений (представление "Продукты + Бренд", представление "Клиенты + Группа клиентов" и "Заказы"). На последнем этапе необходимо создать соединения между таблицами измерений и таблицей фактов.
Полный список задач моделирования данных см. в разделе План действий по моделированию данных.
Левое внешнее соединение
Вернуть все записи в левой таблице и записи в правой таблице, которые соответствуют условиям.
Общие сведения о требованиях моделей данных
Прежде чем начинать моделировать данные, необходимо сначала понять требования моделей данных.
На какие вопросы, связанные с коммерческой деятельностью, вы пытаетесь ответить?
Какие показатели требуются для понимания эффективности предприятия?
В каких направлениях действует предприятие? Или, другими словами, какие измерения используются для анализа измерений и предоставления заголовков для отчетов?
Есть ли в каждом измерении иерархические элементы и какой тип отношений определяет каждую иерархию?
Ответив на эти вопросы, вы можете идентифицировать и определить элементы своей бизнес-модели.
Полное внешнее соединение
Вернуть все записи в левой и правой таблицах
Оператор набора: Оператор набора специально используется для объединения результатов нескольких операторов выбора, включая четыре:
- союз / союз все: союз
- перекресток: перекресток
- минус: разница
Примечание по использованию оператора set: имена столбцов и выражения в списке выбора должны соответствовать по количеству и типу данных.
union all
Оператор union all используется для получения объединения двух наборов результатов, он не удаляет автоматически повторяющиеся строки в наборе результатов и не сортирует данные набора результатов.
Естественное соединение
Особый вид эквивалентного соединения, которое автоматически сопоставляет записи столбцов с тем же именем в таблице. Естественное подключение не требует указания каких-либо эквивалентных условий подключения.
Что такое схема звезды?
В схеме STAR центр звезды может иметь одну таблицу фактов и несколько связанных таблиц измерений. Это известно как схема звезды, поскольку ее структура напоминает звезду. Схема «звезда» – это самый простой тип схемы хранилища данных. Он также известен как схема соединения звездой и оптимизирован для запросов больших наборов данных.
В следующем примере таблица фактов находится в центре, которая содержит ключи для каждой таблицы измерений, такие как Dealer_ID, ID модели, Date_ID, Product_ID, Branch_ID и другие атрибуты, такие как проданные единицы и доход.

Характеристики схемы звезды:
- Каждое измерение в звездообразной схеме представлено единственной одномерной таблицей.
- Таблица измерений должна содержать набор атрибутов.
- Таблица измерений присоединяется к таблице фактов с помощью внешнего ключа
- Таблица измерений не соединена друг с другом
- Таблица фактов будет содержать ключ и меру
- Схема Star проста для понимания и обеспечивает оптимальное использование диска.
- Таблицы измерений не нормализованы . Например, на приведенном выше рисунке Country_ID не имеет таблицы поиска Country, как было бы в проекте OLTP.
- Схема широко поддерживается BI Tools
Читайте также: