
Oracle посчитать количество уникальных значений
Как узнать количество моделей ПК, выпускаемых тем или иным поставщиком? Как определить среднее значение цены на компьютеры, имеющие одинаковые технические характеристики? На эти и многие другие вопросы, связанные с некоторой статистической информацией, можно получить ответы при помощи итоговых (агрегатных) функций. Стандартом предусмотрены следующие агрегатные функции:
Все эти функции возвращают единственное значение. При этом функции COUNT , MIN и MAX применимы к данным любого типа, в то время как SUM и AVG используются только для данных числового типа. Разница между функцией COUNT (*) и COUNT (имя столбца | выражение) состоит в том, что вторая (как и остальные агрегатные функции) при подсчете не учитывает NULL -значения.
Найти минимальную и максимальную цену на персональные компьютеры:
Консоль
Результатом будет единственная строка, содержащая агрегатные значения:
Найти имеющееся в наличии количество компьютеров, выпущенных производителем А
Консоль
В результате получим
Если же нас интересует количество различных моделей, выпускаемых производителем А, то запрос можно сформулировать следующим образом (пользуясь тем фактом, что в таблице Product номер модели - столбец model - является первичным ключом и, следовательно, не допускает повторений):
Консоль
Найти количество имеющихся различных моделей ПК, выпускаемых производителем А.
Запрос похож на предыдущий, в котором требовалось определить общее число моделей, выпускаемых производителем А. Здесь же требуется найти число различных моделей в таблице РС (то есть имеющихся в продаже).
Для того чтобы при получении статистических показателей использовались только уникальные значения, при аргументе агрегатных функций можно применить параметр DISTINCT . Другой параметр - ALL - задействуется по умолчанию и предполагает подсчет всех возвращаемых (не NULL ) значений в столбце. Оператор
Консоль
даст следующий результат
Если же нам требуется получить количество моделей ПК, производимых каждым производителем, то потребуется использовать предложение GROUP BY , синтаксически следующего после предложения WHERE .


Содержание:

(5.5.1.) Предложение GROUP BY
(5.5.2.) Предложение HAVING
Получение итоговых данных с помощью оператора ROLLUP
Комбинация детализированных и агрегированных данных
Сортировка и NULL-значения
Агрегатная функция от агрегатной функции
Произведение значений столбца
В этом учебном материале вы узнаете, как использовать SQL функцию COUNT с синтаксисом и примерами.
hstore
Но в варианте с массивом нам пришлось каждый из них unnest 'ить и уникализировать самостоятельно? Но ведь есть способ отдать уникализацию самому серверу - использовать сложение hstore с одноименными ключами:
Не забываем, что сначала необходимо установить это расширение в свою базу:
И только после этого пакуем, не забывая, что все ключи должны быть текстовыми:
Теперь нам необходимо "сложить" hstore -объекты в нужных строках, но соответствующей агрегатной функции hstore_agg не существует. Не беда - создадим ее сами:
Воспользуемся функцией akeys , которая вернет нам массив ключей собранного объекта:

Группировка hstore
ARRAY
Но мы можем попробовать заранее "упаковать" имеющиеся у нас данные, чтобы в момент запроса читать самый минимум - использовать массив уникальных идентификаторов за каждый день (ведь нам заранее неизвестен интервал, который захочет запросить пользователь):
Тогда нам останется лишь прочитать записи за нужный интервал дней, "развернуть" все идентификаторы и посчитать количество уникальных:

Группировка массивов
Описание
SQL функция COUNT используется для подсчета количества строк, возвращаемых в операторе SELECT.
Пример - поиск уникальных значений в столбце
Давайте посмотрим, как использовать оператор DISTINCT для поиска уникальных значений в одном столбце таблицы.
В этом примере у нас есть таблица suppliers со следующими данными:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 100 | Yandex | Moscow | Russia |
| 200 | Lansing | Michigan | |
| 300 | Oracle | Redwood City | California |
| 400 | Bing | Redmond | Washington |
| 500 | Yahoo | Sunnyvale | Washington |
| 600 | DuckDuckGo | Paoli | Pennsylvania |
| 700 | Qwant | Paris | Ile de France |
| 800 | Menlo Park | California | |
| 900 | Electronic Arts | San Francisco | California |
Давайте найдем все уникальные значения в таблице suppliers . Введите следующий SQL оператор:
Для систем управления бизнесом часто приходится решать очень похожий класс задач по вычислению количества уникальных объектов на произвольном временном интервале. В контексте CRM это могут быть "пользователи, обращавшиеся на горячую линию на прошлой неделе", "контрагенты, оплатившие за последние 30 дней" или "потенциальные клиенты, с кем был контакт в этом квартале".
Искать в большом количестве фактов «уники» — всегда сложно и долго, если их достаточно много. Если интервалы фиксированы (календарные месяц/квартал/год), можно материализовывать такие агрегаты заранее. А если интервал — произвольный, как тогда эффективно найти ответ?

Сначала смоделируем ситуацию, как она выглядит для нас, в масштабах «Тензора» — 5000 наших сотрудников до 100 000 раз за сутки общаются с потенциальными клиентами или с кем-то из уже работающих с нами 5 миллионов пользователей:
А теперь попробуем ответить на простой вопрос — сколько было уникальных клиентов в декабре?
Понятно, что если вся "первичка" уже лежит в PostgreSQL, то для реализации одной лишь этой функции выгружать данные во внешнюю СУБД с колоночным хранением данных вроде ClickHouse, которая подошла бы именно для этой задачи лучше, не особо оправданно с точки зрения эксплуатации разнородной архитектуры.

"Наивный" подсчет по первичным данным
Но самое печальное - это объем данных, который нам приходится прочитать - почти 23K страниц, то есть примерно 180MB. И если любая из них окажется не в кэше, и ее придется вычитывать с диска - тормоза нам обеспечены.
Синтаксис
Синтаксис для функции COUNT в SQL.
SELECT COUNT(aggregate_expression)
FROM tables
[WHERE conditions]
[ORDER BY expression [ ASC | DESC ]];
Или синтаксис для функции COUNT при группировке результатов по одному или нескольким столбцам.
SELECT expression1, expression2, . expression_n,
COUNT(aggregate_expression)
FROM tables
[WHERE conditions]
GROUP BY expression1, expression2, . expression_n
[ORDER BY expression [ ASC | DESC ]];
jsonb
Но ведь есть "нативный" тип, который самостоятельно делает уникализацию ключей - json[b]:
Давайте обойдемся без всех этих дополнительно устанавливаемых расширений:
Правда, агрегатную функцию снова придется делать самим:
И даже не будем пробовать извлекать ключи - достаточно уже агрегации.

Группировка jsonb
Итак, в сегодняшнем забеге упаковка в массив позволяет получить наиболее сбалансированный по объему и скорости результат.
А еще быстрее - можно? Да, но это уже материал для хаба "ненормальное программирование".
Основные затраты времени у нас шли на объединение массивов/объектов. То есть чем меньше записей с "пакетами" нам необходимо обработать - тем лучше.
Для этого все даты можно покрыть отрезками длиной 2^N :

Сегментация дат
Тогда любой из заданных пользователем интервалов можно разбить на такие непересекающиеся отрезки:

Разбиение интервала на сегменты
Ну, а каскадное добавление ID клиента во все такие отрезки можно с помощью несложной функции:
Этот способ всем хорош, пока у нас достаточно памяти под хранение хэш массива.
При росте размера данных время и потребляемые ресурсы начинают катастрофически расти.
Пример со страницы antognini с разным числом уникальных значений на 10 млн. строк:
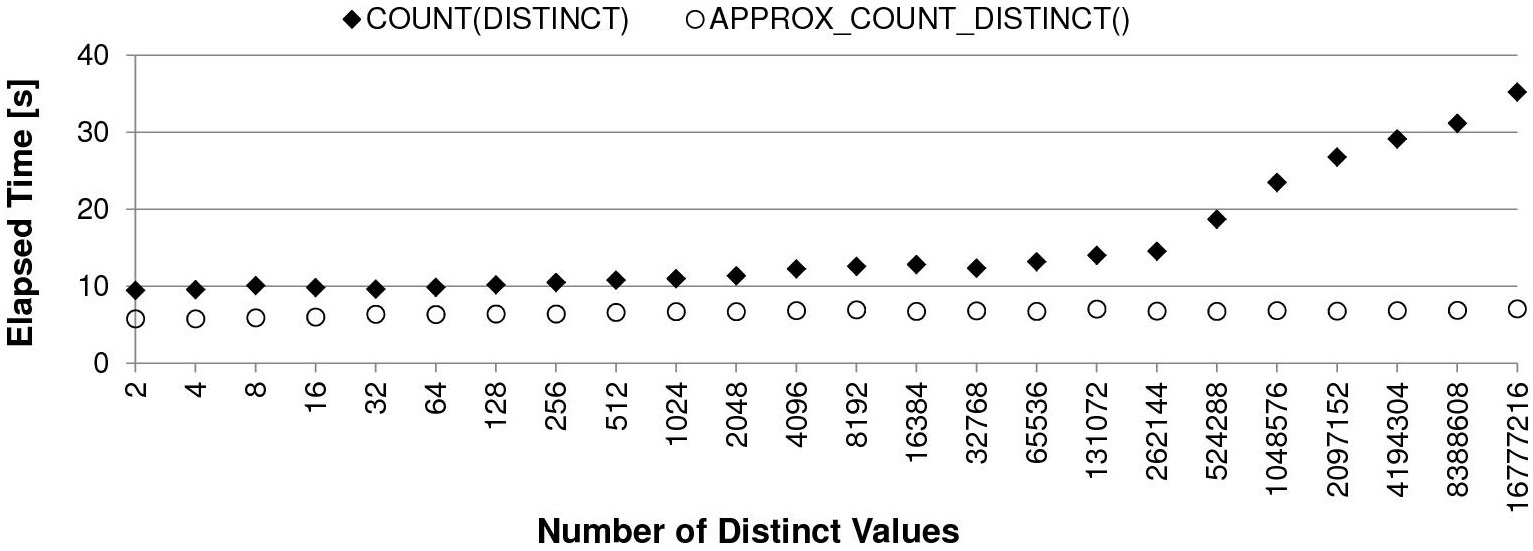
Скорость вычислений классическим способом падает вместе с ростом числа уникальных значений:
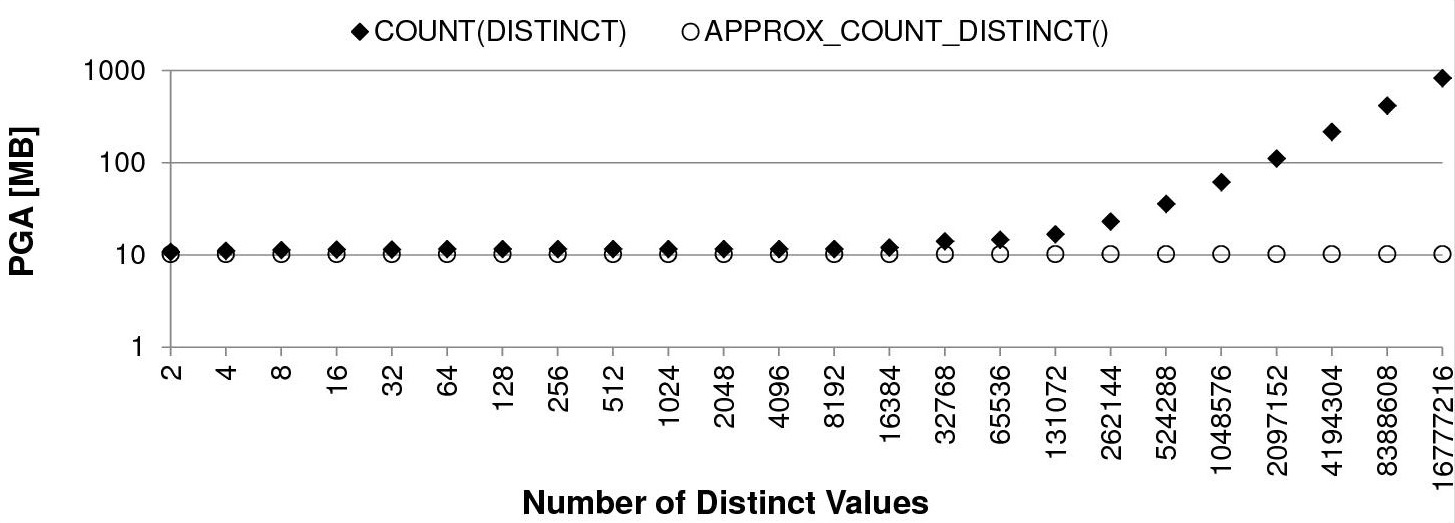
Пропорционально времени работы растет и потребление PGA памяти под хранение хэш массива:
Чтобы решить проблему производительности/памяти и при этом получить приемлемый результат, можно применить приблизительный расчет числа уникальных значений.
Как и bloom filter он основан на вероятностных хэш значениях от данных.
Общий смысл приблизительного расчета (habr):
1. От каждого значения берется произвольная хэш функция
2. У каждого хэш значения определяется ранк первого ненулевого бита справа.
Вероятность того, что мы встретим хеш с рангом 1 равна 0.5, с рангом 2 — 0.25, с рангом r — 1 / 2 ранг
Если запоминать наибольший обнаруженный ранг R, то 2 R сгодится в качестве грубой оценки количества уникальных элементов среди уже просмотренных.
Такой подход даст нам приблизительное число уникальных значений, но с сильной ошибкой.
Для данного алгоритма есть усовершенствованный вариант HyperLogLog:
а. От битового представления хэш берется 8 первых левых бит. Они становятся ключом массива (2^8 = 256 значений)

б. Над массивов вычисляется формула:
где am - корректирующий коэффициент, m - размер массива = 256, M[] - массив ранков (hashes)
Для погрешности в 6.5% числитель этой формулы будет равен константе = 47072.7126712022335488.
Остается в цикле возвести 2 в -степень максимального ранка из каждого элемента массива:
Данный алгоритм уже дает приемлемый результат на больших данных, но серьезно ошибается на небольшом наборе.
Для небольших значение применяется дополнительная математическая корректировка:
Проведенных тест на 1-2 томах войны и мира показал результаты:
* реальное количество уникальных слов = 3737
* приблизительное число уникальных слов основываясь только на максимальном ранке первого ненулевого бита справа = 16384
* приблизительное число уникальных слов по формуле из п. б на массиве из 256 элементов = 3676
* приблизительное число уникальных слов по формуле и корректировке = 3676
При ошибке числа уникальных значений в 6,1% мы затратили константное число памяти под массив из 256 элементов, что в разы меньше, чем при обычном хэш массиве.
Пример - функция COUNT включает только значения NOT NUL
Не все это понимают, но функция COUNT будет подсчитывать только те записи, в которых expressions НЕ равно NULL в COUNT( expressions ). Когда expressions является значением NULL, оно не включается в вычисления COUNT. Давайте рассмотрим это дальше.
SQL оператор DISTINCT используется для удаления дубликатов из результирующего набора оператора SELECT.
Синтаксис
Синтаксис для оператора DISTINCT в SQL:
Параметры или аргумент
expression1 , expression2 , . expression_n Выражения, которые не инкапсулированы в функции COUNT и должны быть включены в предложение GROUP BY в конце SQL запроса aggregate_expression Это столбец или выражение, чьи ненулевые значения будут учитываться tables Таблицы, из которых вы хотите получить записи. В предложении FROM должна быть указана хотя бы одна таблица WHERE conditions Необязательный. Это условия, которые должны быть выполнены для выбора записей ORDER BY expression Необязательный. Выражение, используемое для сортировки записей в наборе результатов. Если указано более одного выражения, значения должны быть разделены запятыми ASC Необязательный. ASC сортирует результирующий набор в порядке возрастания по expressions . Это поведение по умолчанию, если модификатор не указан DESC Необязательный. DESC сортирует результирующий набор в порядке убывания по expressions
Примечание
- Если в операторе DISTINCT указано только одно выражение, запрос возвратит уникальные значения для этого выражения.
- Если в операторе DISTINCT указано несколько выражений, запрос извлекает уникальные комбинации для перечисленных выражений.
- В SQL оператор DISTINCT не игнорирует значения NULL. Поэтому при использовании DISTINCT в вашем операторе SQL ваш результирующий набор будет содержать значение NULL в качестве отдельного значения.
Параметры или аргументы
expressions Столбцы или расчеты, которые вы хотите получить. tables Таблицы, из которых вы хотите получить записи. В предложении FROM должна быть указана хотя бы одна таблица. WHERE conditions Необязательный. Условия, которые должны быть выполнены для записей, которые будут выбраны.
Читайте также: