
Oracle лог подключений к базе
It is important that you monitor the operation of your database on a regular basis. Doing so not only informs you of errors that have not yet come to your attention but also gives you a better understanding of the normal operation of your database. Being familiar with normal behavior in turn helps you recognize when something is wrong.
You can monitor database errors and alerts to prevent, detect, and solve problems.
Monitoring performance includes monitoring locks and wait events and querying a set of data dictionary views.
Object quarantine enables an Oracle database to function even when there are corrupted, unrecoverable objects. The V$QUARANTINE view contains information about quarantined objects.
Предисловие
Данным постом хотел бы начать цикл статей посвященных «Логированию ошибок» в Oracle PL/SQL. В первую очередь донести мысль до многих разработчиков, о том как можно построить функционал фиксации, хранения логов в БД. На своем опыте продемонстрировать поэтапный процесс создания полноценного логирования в БД. Рассказать как нам удалось создать логирование ошибок, разработать единую нумерацию событий для их дальнейшей идентификации, как поверх логирования «натянуть» мониторинг событий, создать функционал позволяющий увидеть все текущие ошибки в БД в виде таблиц (с указанием частоты возникновения ошибок и кол-ва и т.д.), графиков (отразить динамику роста кол-ва ошибок) и правильно распределить ресурсы для устранения тех или иных ошибок.
Оговорюсь сразу, что на рынке возможно уже есть успешные существующие коммерческие продукты осуществляющие логирование гораздо лучше и качественнее хотя бы, потому что у них есть многолетний опыт внедрения и сопровождения своего продукта в различных компаниях. Я же хочу показать один из множества примеров реализации функционала логирования, которые вполне можно осуществить силами своих разработчиков.
Average Runnable Process

Этот график дает общее понимание использования CPU.
| № | Показатель | Описание |
|---|---|---|
| 1 | Instance Foreground CPU | Отображает утилизацию CPU процессами текущего инстанса, напрямую запущенными клиентом, например выполнение запросов. Список событий ожидания текущего инстанса можно посмотреть в AWR-отчете |
| 2 | Instance Background CPU | Отображает утилизацию CPU фоновыми процессами текущего инстанса, например LGWR. Список событий фонового процесса текущего инстанса можно посмотреть в AWR-отчете или в официальной документации Oracle |
| 3 | Non-database Host CPU | Отображает утилизацию CPU процессами, не относящимися к текущему инстансу |
| 4 | Load Average | Отображает среднюю длину очереди процессов, ожидающих выполнения |
| 5 | CPU Treads/CPU Cores | Отображает лимит максимально возможного использования CPU |
5.2 Listing and Viewing Log Files With Enterprise Manager
You can use the Oracle Enterprise Manager 10 g Application Server Control Console to list log files. On the Application Server Control Console, click the Logs link to display the View Logs page.
This section contains the following:
5.1.1 Understanding Log File Data and Naming
Several Oracle Application Server components use Oracle Diagnostic Logging (ODL). ODL ensures that the log file naming and log file content formats conform to an Oracle standard. ODL writes the diagnostic messages in XML. Components that do not use ODL write their diagnostic messages using a component-specific text format.
You can view log files of any format by using the Application Server Control Console. Application Server Control Console. You can also download log files to your local client and view them using a text editor or another file viewing utility.
5.1.1.1 Log File Messages by Component
Table 5-1 lists the supported message formats for each Oracle Application Server component.
Table 5-1 Diagnostic Message Format By Component
ORACLE_HOME /ifs/cmsdk/log/ cmsdk_domain_name / node_name .log
The Discoverer Viewer is an OC4J application. The log file is named application.log and is found under: ORACLE_HOME /j2ee/OC4J_BI_FORMS
ORACLE_HOME /j2ee/ instance_name /application-deployments/ application_name /application.log
Logging for user and administrator usage, other than command line, is stored in the database and accessed through the Oracle Application Server Certificate Authority (OCA) Administrator web interface.
ORACLE_HOME /opmn/logs / component_type ~.
Введение
Модель логирования позволяет реализовать:
Единый подход в обработке и хранении событий
Собственную нумерацию и идентификацию событий происходящих в БД (статья)
Единый мониторинг событий (статья в разработке)
Анализ событий происходящих в БД (статья в разработке)
Описанные выше характеристики указаны в порядке нумерации и каждый следующий пункт (шаг) есть улучшение и усложнение существующей модели. Описание этой модели будет сложно выполнить в рамках одной статьи, поэтому опишем их последовательно. Начнём с первого пункта.
Единый подход в обработке и хранении событий
Основной идеей "Единого подхода в обработке и хранении событий" заключается в создании одного одновременно простого и в тоже время очень сложного правила: "Все объекты базы данных (функции, процедуры) в обязательном порядке должны завершаться блоком обработки исключений с последующим логированием события". Простота заключается в том, что легко, в команде разработчиков, на словах договориться об исполнении данного правила. Сложность же заключается в том, что данное правило должно быть установлено на ранних этапах создания вашей БД и выполняться обязательно на протяжении всего жизненного цикла. Внедрить функционал логирования в уже существующие и действующие БД очень сложно (практически не возможно).
Все объекты базы данных (функции, процедуры) в обязательном порядке должны завершаться блоком обработки исключений с последующим логированием события. Для этого можно использовать шаблон процедуры (функции) описанный во второй статье.
Наверное сейчас кто-то из читателей может возразить: "Зачем в обязательном порядке?". А всё очень просто, если вы разработчик PL/SQL и вы не согласны с этим правилом, то вот вам пример. Посмотрите на свой текущий проект более внимательно. Скорее всего вы найдете какое-нибудь логирование событий реализованное кем-то, когда-то. Вспомните сколько раз вы обращались к этому логированию при решении багов. Именно в таких ситуациях, когда есть срочность по времени в исправлении бага, вы или ваши коллеги начинают использовать dbms_output.put_line в качестве экспресс-дебага (быстрый способ получения значений переменных используемых в коде). Согласитесь, что для исправления бага мало знать в какой процедуре, в каком запросе и на какой строке возникла ошибка, необходимо знать параметры запроса на которых возникает ошибка. И вот тут нам на помощь приходит "Логирование событий", потому что помимо места возникновения ошибки мы узнаем параметры вызова процедуры, в которой возникает ошибка и это очень упрощает исправление бага.
Первая статья посвящена базовому функционалу «Логирования событий». В простейшей реализации это одна общая таблица и пакет процедур для работы с ней. Для создания и демонстрации логирования, нам необходимо реализовать следующие объекты БД (весь список объектов с их исходными кодами представлен в Git):
Таблица messagelog - единая таблица логов. Именно в данной таблице будет храниться информация о дате и времени события, об объекте где происходит событие, типе события с указанием кода, текста и параметров. В нашем примере, столбец backtrace вынесен в отдельную таблицу messagelog_backtrace для удобства.
Примечание. Представленное ниже описание таблицы является демонстрационным с минимальным набором столбцов для создания простейшего функционала логирования. Наличие дополнительных столбцов и их тип данных может меняться в зависимости от целей и задач логирования.
Также, учитывайте пожалуйста, что создание партиции требует как минимум Oracle EE. Создание партиции вне указанной версии Oracle приведет к нарушению лицензионного соглашения.
Убедительная просьба, рассматривать данный текст только как продолжение к статье о "Событийной модели логирования". Эта статья будет полезна тем, у кого уже реализовано логирование событий в БД и кто хотел бы осуществлять сбор статистики и начать проводить аналитику этих событий. Только представьте, что ваша БД сможет информировать вас о критичных сбоях системы, накапливать информацию о событиях в БД (кол-во повторений, период повторений и т.д.). И всё это без использования стороннего ПО силами одного PL/SQL.
SQL statistics

Раздел содержит несколько таблиц со статистикой по SQL-запросам, отсортированным по определенному критерию.
Подробнее про оптимизацию запросов и примеры типичных проблем в запросах можно почитать в статье Проактивная оптимизация производительности БД Oracle.
| № | Параметр | Описание |
|---|---|---|
| 1 | SQL ordered by Elapsed Time | Топ SQL-запросов по затраченному времени на их выполнение |
| 2 | SQL ordered by CPU Time | Топ SQL-запросов по процессорному времени |
| 3 | SQL ordered by User I/O Wait Time | Топ SQL-запросов по времени ожидания ввода/вывода для пользователя |
| 4 | SQL ordered by Gets | Запросы к БД, упорядоченные по убыванию логических операций ввода/вывода. При анализе стоит учитывать, что для PL/SQL-процедур их количество прочитанных Buffer Gets будет состоять из суммы всех запросов в рамках этой процедуры |
| 5 | SQL ordered by Reads | Этот раздел схож с предыдущим: в нем указываются все операции ввода/вывода, наиболее активно физически считывающие данные с жесткого диска. Именно на эти запросы и процессы надо обратить внимание, если система не справляется с объемом ввода/вывода |
| 6 | SQL ordered by Physical Reads (UnOptimized) | В этом разделе выводятся неоптимизированные запросы. В Oracle неоптимизированными считаются все запросы, которые не обслуживаются DSFC или Exadata Cell Smart Flash Cache (ECSFC) |
| 7 | SQL ordered by Executions | Наиболее часто выполняемые запросы |
| 8 | SQL ordered by Parse Calls | Отображает количество попыток разбора SQL-запросов до его выполнения |
| 9 | SQL ordered by Sharable Memory | Запросы, занимающие больший объем памяти общего пула SGA |
| 10 | SQL ordered by Version Count | Здесь показано количество SQL-операторов экземпляров одного и того же оператора в разделяемом пуле |
| 11 | Complete List of SQL Text | Показывает полный SQL-запрос, не только его хэш. В этой таблице можно найти неоптимальные запросы (например, запросы по всем столбцам таблицы «select * from. », запросы с большим количеством «like» и т. п.) |
5.2.4 Using Log Files Advanced Search
On the View Logs page, click the Advanced Search button to display the View Logs Advanced Search page. The Advanced Search page allows you to list log files for Oracle Application Server components and filter the search for log files by certain log file attributes.
On the View Logs Advanced Search page, you can list the log files using a search filter by performing the following steps:
Select the Move or Move All button to move the selected or all available components to the Selected Components box.
Select a field from the Log File Attribute list.
Select the Add Row button to add a row for the selected log file attribute.
Enter the desired search value in the Value field.
If you want to select additional fields with values, then select the Add Another Row button and enter additional values.
Select the Search button to perform the search. When the search returns, the Results section displays the log files with matching fields.
To obtain more information about filtering using the log file attributes, click the information icon next to the Log File Attribute list.
ASH Report

ASH Report (Active Session History) дает более подробную информацию по потреблению ресурсов. Чтобы перейти к графику, в меню Performance нужно выбрать пункт Performance Hub/ASH Report. Также перейти к ASH Report можно при выборе класса события ожидания на графике Average Active Session.
- События ожидания и группы событий ожидания.
- Группы пользователей, пользователи, сервисы, инстансы.
- SQL-запросы.
AWR (Automatic Workload Repository) дает подробную информацию о процессах, происходящих с БД в определенный период. Для построения AWR-отчета нужно выбрать пункт меню Performance/AWR/AWR Report. Также есть возможность сравнивать два временных промежутка. Для этого нужно выбрать пункт меню Performance/AWR/Compare Period Report.
Ниже будут описаны наиболее показательные разделы AWR-отчета, описание остальных разделов можно поискать в официальной документации.
5.2.5 Viewing Log File Details and Log File Contents
After you click Search from either the View Logs Simple Search or Advanced Search page, the View Logs page shows the search output at the bottom of the page in the Results section. You can sort the output by selecting column headings. For example, to sort results by size, select the Size (bytes) column heading (multiple selections on a column heading toggle ascending and descending sort).
To view log file contents, select the link shown in the Log File column.
After selecting a log file link, the Log File page shows the contents of the selected log file, and supports the following:
The Refresh list determines whether the file view is updated manually or automatically. Select Automatically when you want to refresh the page at regular intervals. The Log File page scrolls to the bottom when a page refreshes.
Selecting the refresh icon next to the Page Refreshed date, on either the top or the bottom of the page, initiates manual refresh. Each refresh displays the log entries added since the last refresh.
Selecting the Log File link lets you use browser features to display, print, or download the log file.
Заключение
В заключении наверное скажу банальную вещь, о том что ваша БД является сложным механизмом ежесекундно выполняющая рутинные операции. Прямо сейчас в БД могут происходить различные ошибки. Критичные, которые вы исправляете практически сразу или некритичные, о которых вы можете вообще не знать. И если у вас нет информации о подобных ошибках, то возникает вопрос: "Нужно ли их вообще исправлять? Или можно подождать до тех пор, пока проблема не всплывёт?". Вопрос наверное "риторический".
Я же данной статьёй хотел показать один из способов ведения логирования с кодированием отдельных событий. Данный метод требует некоторых "обязательств" от разработчика и в нынешнее время этого тяжело добиться. В следующей статье постараюсь показать один из способов мониторинга ошибок основанный напрямую по кодам ошибок созданных в текущей статье.
5.3.5 Understanding Log Loader Diagnostic Messages
The Log Loader logs its diagnostic messages, including errors to its log file. Diagnostic messages might include errors encountered due to an incorrect configuration, or errors that occur while the Log Loader is reading data from a log file or is writing data to the log repository.
The common Log Loader problems include:
Errors in the Log Loader configuration file ( $ORACLE_HOME/diagnostics/config/logloader.xml ). Errors in the configuration file usually prevent the Log Loader from running. Such errors need to be corrected before the Log Loader can work properly.
Configuration errors that occur when a component's registration file contains errors ( $ORACLE_HOME/diagnostics/config/registration/*.xml ). Errors in the registration files do not prevent the Log Loader from running but may prevent the contents of certain log files from being loaded in the repository. Typically, there are two common types of registration file errors:
XML syntax errors that prevent the file from being parsed. If such errors are encountered, then the Log Loader completely ignores the contents of the file.
A wrong path specified for a configuration file. If the Log Loader cannot find a log file at the specified path, then it issues a Warning level diagnostic message. This does not always indicate an error, for example, it is possible that the component that generates that log was not active when the Log Loader started and the log file had not been created yet. The Log Loader continues to look for the log file and starts reading messages when the log file is created.
Errors may occur while the Log Loader is reading messages from a log file. If the log file includes contents that cannot be read or parsed, then the Log Loader issues a log message indicating that it cannot read part of the contents of the file. In this case, the Log Loader attempts to recover from the error and continue to read the Log File.
Errors may occur when writing messages to the repository (for example, a disk error). This type of error may indicate a problem that may require attention from the system administrator to correct the problem.
The Log Loader produces an error message when it skips reading log files because a log file exceeds the currently specified maximum load size. The maximum load size can be specified on the Log Loader properties page.
In this case the Log Loader logs an error message in the following format:
This message indicates the size of data to be read exceeds the specified maximum load size x , and that the Log Loader is skipping to the end of the log file. The error message provides information about the name of the log file / logfile , and the number of bytes skipped y_skipped .
Active Session History (ASH) Report
В данной таблице находятся самые тяжелые SQL запросы, на которые приходится наибольший процент активности и наибольшее время ожидания.
В таблице содержится статистика по запросам, на которые приходится наибольший процент выборочной активности и подробная информация о их плане выполнения. Вы можете использовать эту информацию, чтобы определить, какая часть выполнения SQL операторов значительно повлияла на затраченное время SQL оператора.

рис. Старый "дедовский" debug кода
Добрый день! Работая разработчиком Oracle PL/SQL, часто ли вам приходилось видеть в коде dbms_output.put_line в качестве средства debug-а? Стоит признать, что к сожалению, большинство (по моему личному мнению и опыту) разработчиков Oracle PL/SQL не уделяет должного внимания логированию как к «спасательному кругу» в случае возникновения ошибок. Более того, большая часть разработчиков не совсем понимает зачем нужно логировать информацию об ошибках и самое главное, не совсем понимают что делать и как использовать эту информацию в будущем.
8.1 Monitoring Errors and Alerts
You can monitor database errors and alerts to prevent, detect, and solve problems.
The easiest and best way to monitor the database for errors and alerts is with the Database Home page in Oracle Enterprise Manager Cloud Control (Cloud Control). See the Cloud Control online help for more information. This section provides alternate methods for monitoring, using data dictionary views, PL/SQL packages, and other command-line facilities.
A trace file is a file that contains diagnostic data used to investigate problems. An alert log is a file that provides a chronological log of database messages and errors.
A server-generated alert is a notification from the Oracle Database server of an impending problem.
8.1.1 Monitoring Errors with Trace Files and the Alert Log
A trace file is a file that contains diagnostic data used to investigate problems. An alert log is a file that provides a chronological log of database messages and errors.
The trace file and alert log contain information about errors.
To control the size of an alert log, you must manually delete the file when you no longer need it. Otherwise the database continues to append to the file.
You can control the maximum size of all trace files (excluding the alert log) using the initialization parameter MAX_DUMP_FILE_SIZE .
Background processes always write to a trace file when appropriate.
If shared server is enabled, each session using a dispatcher is routed to a shared server process, and trace information is written to the server trace file only if the session has enabled tracing (or if an error is encountered). Therefore, to track tracing for a specific session that connects using a dispatcher, you might have to explore several shared server trace files.
8.1.1.1 About Monitoring Errors with Trace Files and the Alert Log
The trace file and alert log contain information about errors.
Each server and background process can write to an associated trace file . When an internal error is detected by a process, it dumps information about the error to its trace file. Some of the information written to a trace file is intended for the database administrator, and other information is for Oracle Support Services. Trace file information is also used to tune applications and instances.
Critical errors also create incidents and incident dumps in the Automatic Diagnostic Repository. See Diagnosing and Resolving Problems for more information.
The alert log is a chronological log of messages and errors, and includes the following items:
All internal errors ( ORA-00600 ), block corruption errors ( ORA-01578 ), and deadlock errors ( ORA-00060 ) that occur
Administrative operations, such as some CREATE , ALTER , and DROP statements and STARTUP , SHUTDOWN , and ARCHIVELOG statements
Messages and errors relating to the functions of shared server and dispatcher processes
Errors occurring during the automatic refresh of a materialized view
The values of all initialization parameters that had nondefault values at the time the database and instance start
Oracle Database uses the alert log to record these operations as an alternative to displaying the information on an operator's console (although some systems also display information on the console). If an operation is successful, a "completed" message is written in the alert log, along with a timestamp.
The alert log is maintained as both an XML-formatted file and a text-formatted file. You can view either format of the alert log with any text editor or you can use the ADRCI utility to view the XML-formatted version of the file with the XML tags stripped.
Check the alert log and trace files of an instance periodically to learn whether the background processes have encountered errors. For example, when the log writer process (LGWR) cannot write to a member of a log group, an error message indicating the nature of the problem is written to the LGWR trace file and the alert log. Such an error message means that a media or I/O problem has occurred and should be corrected immediately.
Oracle Database also writes values of initialization parameters to the alert log, in addition to other important statistics.
The alert log and all trace files for background and server processes are written to the Automatic Diagnostic Repository, the location of which is specified by the DIAGNOSTIC_DEST initialization parameter. The names of trace files are operating system specific, but each file usually includes the name of the process writing the file (such as LGWR and RECO).
"Diagnosing and Resolving Problems" for information about the Automatic Diagnostic Repository (ADR).
"Alert Log" for additional information about the alert log.
Oracle Database Utilities for information on the ADRCI utility.
Your operating system specific Oracle documentation for information about the names of trace files
8.1.1.2 Controlling the Size of an Alert Log
To control the size of an alert log, you must manually delete the file when you no longer need it. Otherwise the database continues to append to the file.
You can safely delete the alert log while the instance is running, although you should consider making an archived copy of it first. This archived copy could prove valuable if you should have a future problem that requires investigating the history of an instance.
To control the size of an alert log:
Delete the alert log file.
8.1.1.3 Controlling the Size of Trace Files
You can control the maximum size of all trace files (excluding the alert log) using the initialization parameter MAX_DUMP_FILE_SIZE .
You can set this parameter in the following ways:
A numerical value specifies the maximum size in operating system blocks. The specified value is multiplied by the block size to obtain the limit.
A number followed by a K, M, or G suffix specifies the file size in kilobytes, megabytes, or gigabytes.
UNLIMITED , which is the default, specifies no limit.
Oracle Database can automatically segment trace files based on the limit you specify with the MAX_DUMP_FILE_SIZE initialization parameter. When a limit is reached, the database renames the current trace file using a sequential number, and creates an empty file with the original name.
Oracle Database Reference for more information about the MAX_DUMP_FILE_SIZE initialization parameter
8.1.1.3.1 Trace File Segmentation and MAX_DUMP_FILE_SIZE
Oracle Database can automatically segment trace files based on the limit you specify with the MAX_DUMP_FILE_SIZE initialization parameter. When a limit is reached, the database renames the current trace file using a sequential number, and creates an empty file with the original name.
The following table describes how trace files are segmented based on the MAX_DUMP_FILE_SIZE setting.
Trace files are not segmented.
Larger than 15M
Trace files are segmented on a boundary that is 1/5 of the MAX_DUMP_FILE_SIZE setting. Trace files with sizes that are less than this boundary in size are not segmented. For example, if the MAX_DUMP_FILE_SIZE setting is 100M , then the boundary is 20 MB (1/5 of 100 MB).
Trace files are not segmented.
There can be up to five segments, but the total combined size of the segments cannot exceed the MAX_DUMP_FILE_SIZE limit. When the combined size of all segments of the trace file exceeds the specified limit, the oldest segment after the first segment is deleted, and a new, empty segment is created. Therefore, the trace file always contains the most recent trace information. The first segment is not deleted because it might contain relevant information about the initial state of the process.
Segmentation improves space management for trace files. Specifically, segmentation enables you to manage trace files in the following ways:
You can purge old trace files when they are no longer needed.
You can diagnose problems with smaller trace files and isolate trace files that must be packaged for the incident packaging service (IPS).
Any segment that covers a time range that includes an incident is not deleted. It is kept in addition to the five default segments.
8.1.1.4 Controlling When Oracle Database Writes to Trace Files
Background processes always write to a trace file when appropriate.
In the case of the ARC n background process, it is possible, through the LOG_ARCHIVE_TRACE initialization parameter, to control the amount and type of trace information that is produced. To do so:
Other background processes do not have this flexibility.
Trace files are written on behalf of server processes whenever critical errors occur. Additionally, setting the initialization parameter SQL_TRACE = TRUE causes the SQL trace facility to generate performance statistics for the processing of all SQL statements for an instance and write them to the Automatic Diagnostic Repository.
Optionally, you can request that trace files be generated for server processes. Regardless of the current value of the SQL_TRACE initialization parameter, each session can enable or disable trace logging on behalf of the associated server process by using the SQL statement ALTER SESSION SET SQL_TRACE . This example enables the SQL trace facility for a specific session:
Use the DBMS_SESSION or the DBMS_MONITOR packages to control SQL tracing for a session.
The SQL trace facility for server processes can cause significant system overhead resulting in severe performance impact, so you should enable this feature only when collecting statistics.
"Diagnosing and Resolving Problems" for more information about how the database handles critical errors, otherwise known as incidents .

Привет! Меня зовут Александра, я работаю в команде тестирования производительности. В этой статье расскажу базовые сведения об OEM от Oracle. Статья будет полезна для тех, кто только знакомится с платформой, но и не только для них. Основная цель статьи — помочь провести быстрый анализ производительности БД и поиск отправных точек для более глубокого анализа.
OEM (Oracle Enterprise Manager) — платформа для управления БД. OEM предоставляет графический интерфейс для выполнения большого количества операций с базами данных: резервное копирование, просмотр аварийных журналов, графиков производительности.
5.2.2 Listing Log Files for Selected Components
Using the Application Server Control Console, selecting the Logs link shows the View Logs page. To list selected components log files, starting on the View Logs page perform the following steps:
Select the components whose log files you want to view from the Available Components box and use Move to move the selected component to the Selected Components box (some browsers support double clicking to move components between the boxes).
Click Search to list the log files for the selected components.
After a search returns, the Results section shows log file information such as the name of the component associated with a log file and a link to the file.
Figure 5-1 shows the View Logs page Results after a search.
Архитектурное логирование событий
Давайте рассмотрим пример, имеется процедура поиска активного номера телефона принадлежащего конкретному клиенту (для примера его Предположим, что при постановке задачи для разработчика не было описания каких-либо особых условий т.е. по условиям задачи предполагалось, что для конкретного пользователя (id = 43, идентификатор передается в качестве параметра) в таблице client_telnumbers всегда будет хотя бы одна запись с номером телефона клиента и признаком «активный» (значение поля enddate равно дате 31.12.5999 23:59:59, что означает что номер используется клиентом. В случае, любой другой даты в указанном поле означает, что номер перестал быть активным и более не используется), поэтому наша процедура будет выглядеть примерно так:
Исходный код демонстрационной процедуры
Важно! Представленный код является примерным (примитивным) и служит только для демонстрации логирования в рамках данной статьи. В своих статьях я не выкладываю текст кода из реально действующих БД. Надеюсь, вы понимаете, что в реальности указанная процедура написана гораздо сложнее.
*Исходный код других используемых объектов смотрите в Git
Если мы будем использовать логирование ошибок как показано в предыдущей статье, то с течением времени обнаружим, что идентифицировать ошибки из данной процедуры будет сложно. Поэтому для всех ошибок попадающих в обработку исключения «WHEN OTHERS» реализована процедура pkg_msglog.p_log_archerr, которая при первом возникновении ошибки автоматически присваивает ей уникальный код и сохраняет ошибку в таблице лога. В дальнейшем, при повторении данной ошибки процедура найдет ранее созданный код и использует его при логировании в таблице лога.
В итоге, после добавления блока «архитектурного» логирования (строки с 18 по 24), наша процедура будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
На этапе написания текста процедуры разработчик не всегда может предугадать возникновение той или иной ошибки (если честно, не всегда есть на это время), поэтому на начальном этапе ему достаточно «отлавливать» абсолютно все ошибки возникающие в данной процедуре с помощью оператора «WHEN OTHERS». Таким образом мы можем ввести новый термин (в рамках данного цикла статей), «Архитектурные логирование» - это логирование всех ошибок, возникновение которых не предполагается при штатной работе алгоритма. Для функционала «Архитектурных ошибок» были созданы объекты: отдельный справочник ошибок messagecodes_arch и процедура pkg_msglog.p_log_archerr создания записи в таблице лога для указанного типа ошибок.
Исходный код таблицы
Ограничение в таблице на комбинацию (Имя объекта, код ошибки SQLCODE). При первом появлении ошибки создается запись в таблице и генерируется код ошибки "SYS0000" + счетчик ошибок. При повторном появлении указанной ошибки будет взят уже сгенерированный ранее код ошибки.

рис. Пример содержимого таблицы messagecodes_arch
*Исходный код других используемых объектов смотрите в Git
Обратите внимание, что при использовании описанной модели «архитектурного» логирования у вас появляется функционал позволяющий максимально быстро реагировать на первое появление ошибки (в конкретной функции/процедуре). Для этого необходимо реализовать отдельный мониторинг архитектурных ошибок, который постараюсь продемонстрировать в следующей (третьей) статье. Использование процедуры pkg_msglog.p_log_archerr не требует каких-либо действий кроме описания входных параметров.
Таким образом мы можем создать базовый шаблон процедуры (функции), использование которого позволит вам гарантированно отлавливать все архитектурные ошибки в вашем коде.
Шаблон процедуры/функции с архитектурным логированием
Рекомендую использовать данный шаблон для построения "Событийной модели логирования".
*Исходный код других используемых объектов смотрите в Git
В рамках событийной модели логирования, предполагается, что все архитектурные ошибки будут исправляться отдельной задачей т.е. основная цель это устранить повторное появление ошибок с кодом "SYS****" в таблице лога. В указанной задаче вам необходимо либо устранить причины возникновения данной ошибки, либо добавить отдельную обработку ошибки отличную от «when others», которую в дальнейшем будем назвать «пользовательское» логирование (в рамках данного цикла статей).
8.1 Monitoring Errors and Alerts
You can monitor database errors and alerts to prevent, detect, and solve problems.
The easiest and best way to monitor the database for errors and alerts is with the Database Home page in Oracle Enterprise Manager Cloud Control (Cloud Control). See the Cloud Control online help for more information. This section provides alternate methods for monitoring, using data dictionary views, PL/SQL packages, and other command-line facilities.
A trace file is a file that contains diagnostic data used to investigate problems. An alert log is a file that provides a chronological log of database messages and errors.
A server-generated alert is a notification from the Oracle Database server of an impending problem.
8.1.1 Monitoring Errors with Trace Files and the Alert Log
A trace file is a file that contains diagnostic data used to investigate problems. An alert log is a file that provides a chronological log of database messages and errors.
The trace file and alert log contain information about errors.
To control the size of an alert log, you must manually delete the file when you no longer need it. Otherwise the database continues to append to the file.
You can control the maximum size of all trace files (excluding the alert log) using the initialization parameter MAX_DUMP_FILE_SIZE .
Background processes always write to a trace file when appropriate.
If shared server is enabled, each session using a dispatcher is routed to a shared server process, and trace information is written to the server trace file only if the session has enabled tracing (or if an error is encountered). Therefore, to track tracing for a specific session that connects using a dispatcher, you might have to explore several shared server trace files.
8.1.1.1 About Monitoring Errors with Trace Files and the Alert Log
The trace file and alert log contain information about errors.
Each server and background process can write to an associated trace file . When an internal error is detected by a process, it dumps information about the error to its trace file. Some of the information written to a trace file is intended for the database administrator, and other information is for Oracle Support Services. Trace file information is also used to tune applications and instances.
Critical errors also create incidents and incident dumps in the Automatic Diagnostic Repository. See Diagnosing and Resolving Problems for more information.
The alert log is a chronological log of messages and errors, and includes the following items:
All internal errors ( ORA-00600 ), block corruption errors ( ORA-01578 ), and deadlock errors ( ORA-00060 ) that occur
Administrative operations, such as some CREATE , ALTER , and DROP statements and STARTUP , SHUTDOWN , and ARCHIVELOG statements
Messages and errors relating to the functions of shared server and dispatcher processes
Errors occurring during the automatic refresh of a materialized view
The values of all initialization parameters that had nondefault values at the time the database and instance start
Oracle Database uses the alert log to record these operations as an alternative to displaying the information on an operator's console (although some systems also display information on the console). If an operation is successful, a "completed" message is written in the alert log, along with a timestamp.
The alert log is maintained as both an XML-formatted file and a text-formatted file. You can view either format of the alert log with any text editor or you can use the ADRCI utility to view the XML-formatted version of the file with the XML tags stripped.
Check the alert log and trace files of an instance periodically to learn whether the background processes have encountered errors. For example, when the log writer process (LGWR) cannot write to a member of a log group, an error message indicating the nature of the problem is written to the LGWR trace file and the alert log. Such an error message means that a media or I/O problem has occurred and should be corrected immediately.
Oracle Database also writes values of initialization parameters to the alert log, in addition to other important statistics.
The alert log and all trace files for background and server processes are written to the Automatic Diagnostic Repository, the location of which is specified by the DIAGNOSTIC_DEST initialization parameter. The names of trace files are operating system specific, but each file usually includes the name of the process writing the file (such as LGWR and RECO).
"Diagnosing and Resolving Problems" for information about the Automatic Diagnostic Repository (ADR).
"Alert Log" for additional information about the alert log.
Oracle Database Utilities for information on the ADRCI utility.
Your operating system specific Oracle documentation for information about the names of trace files
8.1.1.2 Controlling the Size of an Alert Log
To control the size of an alert log, you must manually delete the file when you no longer need it. Otherwise the database continues to append to the file.
You can safely delete the alert log while the instance is running, although you should consider making an archived copy of it first. This archived copy could prove valuable if you should have a future problem that requires investigating the history of an instance.
To control the size of an alert log:
Delete the alert log file.
8.1.1.3 Controlling the Size of Trace Files
You can control the maximum size of all trace files (excluding the alert log) using the initialization parameter MAX_DUMP_FILE_SIZE .
You can set this parameter in the following ways:
A numerical value specifies the maximum size in operating system blocks. The specified value is multiplied by the block size to obtain the limit.
A number followed by a K, M, or G suffix specifies the file size in kilobytes, megabytes, or gigabytes.
UNLIMITED , which is the default, specifies no limit.
Oracle Database can automatically segment trace files based on the limit you specify with the MAX_DUMP_FILE_SIZE initialization parameter. When a limit is reached, the database renames the current trace file using a sequential number, and creates an empty file with the original name.
Oracle Database Reference for more information about the MAX_DUMP_FILE_SIZE initialization parameter
8.1.1.3.1 Trace File Segmentation and MAX_DUMP_FILE_SIZE
Oracle Database can automatically segment trace files based on the limit you specify with the MAX_DUMP_FILE_SIZE initialization parameter. When a limit is reached, the database renames the current trace file using a sequential number, and creates an empty file with the original name.
The following table describes how trace files are segmented based on the MAX_DUMP_FILE_SIZE setting.
Trace files are not segmented.
Larger than 15M
Trace files are segmented on a boundary that is 1/5 of the MAX_DUMP_FILE_SIZE setting. Trace files with sizes that are less than this boundary in size are not segmented. For example, if the MAX_DUMP_FILE_SIZE setting is 100M , then the boundary is 20 MB (1/5 of 100 MB).
Trace files are not segmented.
There can be up to five segments, but the total combined size of the segments cannot exceed the MAX_DUMP_FILE_SIZE limit. When the combined size of all segments of the trace file exceeds the specified limit, the oldest segment after the first segment is deleted, and a new, empty segment is created. Therefore, the trace file always contains the most recent trace information. The first segment is not deleted because it might contain relevant information about the initial state of the process.
Segmentation improves space management for trace files. Specifically, segmentation enables you to manage trace files in the following ways:
You can purge old trace files when they are no longer needed.
You can diagnose problems with smaller trace files and isolate trace files that must be packaged for the incident packaging service (IPS).
Any segment that covers a time range that includes an incident is not deleted. It is kept in addition to the five default segments.
8.1.1.4 Controlling When Oracle Database Writes to Trace Files
Background processes always write to a trace file when appropriate.
In the case of the ARC n background process, it is possible, through the LOG_ARCHIVE_TRACE initialization parameter, to control the amount and type of trace information that is produced. To do so:
Other background processes do not have this flexibility.
Trace files are written on behalf of server processes whenever critical errors occur. Additionally, setting the initialization parameter SQL_TRACE = TRUE causes the SQL trace facility to generate performance statistics for the processing of all SQL statements for an instance and write them to the Automatic Diagnostic Repository.
Optionally, you can request that trace files be generated for server processes. Regardless of the current value of the SQL_TRACE initialization parameter, each session can enable or disable trace logging on behalf of the associated server process by using the SQL statement ALTER SESSION SET SQL_TRACE . This example enables the SQL trace facility for a specific session:
Use the DBMS_SESSION or the DBMS_MONITOR packages to control SQL tracing for a session.
The SQL trace facility for server processes can cause significant system overhead resulting in severe performance impact, so you should enable this feature only when collecting statistics.
"Diagnosing and Resolving Problems" for more information about how the database handles critical errors, otherwise known as incidents .
Привет! Меня зовут Александра, я работаю в команде тестирования производительности. В этой статье расскажу базовые сведения об OEM от Oracle. Статья будет полезна для тех, кто только знакомится с платформой, но и не только для них. Основная цель статьи — помочь провести быстрый анализ производительности БД и поиск отправных точек для более глубокого анализа.
OEM (Oracle Enterprise Manager) — платформа для управления БД. OEM предоставляет графический интерфейс для выполнения большого количества операций с базами данных: резервное копирование, просмотр аварийных журналов, графиков производительности.
5.1 Introduction to Oracle Application Server Logging
The Oracle Enterprise Manager 10 g Application Server Control Console (Application Server Control Console) allows you to list and search log files across Oracle Application Server components. You can view log files from the Application Server Control Console pages or download a log file to your local client and view the log files using another tool.
This section contains the following topics:
Foreground Wait Class, Foreground Wait events и Background Wait Events
Показывают классы и события, которые провели в ожидании большего всего. Foreground Wait events дополняет информацию раздела Top 10 Foreground Events By Total Wait Time. Background Wait Events показывает детализацию по событиям ожидания фоновых процессов.
5.3.2 Enabling and Disabling Log Loader
On the Log Loader page, click the Enable button to enable the Log Loader. When you first install Oracle Application Server, the Log Loader is enabled. When you disable the Log Loader, its log files are not displayed in the component lists on the View Logs page.
Load Profile

Здесь отображается общая информация по тому, как была загружена БД за выбранный период.
| № | Параметр | Описание |
|---|---|---|
| 1 | DB Time(s) | Сумма времени утилизации процессора и время ожидания (без простоя) |
| 2 | DB CPU(s) | Нагрузка на процессор |
| 3 | Background CPU(s) | Загрузка процессора фоновыми задачами |
| 4 | Redo size | Объем чтения |
| 5 | Logical reads | Среднее количество логических чтений блоков |
| 6 | Block changes | Среднее значение измененных блоков |
| 7 | Physical reads | Физическое чтение в блоках |
| 8 | Physical writes | Количество записей в блоках |
| 9 | Read I/O requests | Количество чтений |
| 10 | Write I/O requests | Количество записей |
| 11 | Read I/O (MB) | Объем чтения |
| 12 | Write I/O (MB) | Объем записей |
| 13 | IM scan rows | Количество строк в In-Memory Compression Units (IMCU), которые были доступны |
| 14 | Session Logical Read IM | Чтения в In-Memory |
| 15 | User calls | Пользовательские вызовы |
| 16 | Parses | Разборы |
| 17 | Logons | Количество входов |
| 18 | Excecutes | Количество вызовов |
| 19 | Rollback | Количество откатов данных |
| 20 | Transacions | Количество транзакций |
Для чего это нужно?
Для начала давайте рассмотрим пример. Вы реализовали логирование ошибок в вашей БД. С течением времени в ваш лог «прилетают» самые разнообразные ошибки. Предположим, имеются две ошибки вида «no_data_found» возникшие в двух разных процедурах при двух разных запросах (select). Первая ошибка возникла при попытке найти «email» клиента, что в принципе не является критичной ошибкой. Вторая ошибка возникла при попытке найти номер лицевого счета клиента, что вполне может являться критичной ошибкой. При этом если мы посмотрим в таблицу лога (из статьи), то увидим, что указанные ошибки будут храниться с одинаковым кодом 1403 (ORA-01403) в столбце msgcode. Более того, текст указанных ошибок будет практически аналогичным (текст полученный с помощью функции SQLERRM) за исключением имен объектов, на которых произошла ошибка. Для того чтобы понять является ли критичной конкретная ошибка, разработчику необходимо вникать в текст ошибки, смотреть в каком объекте возникла ошибка и на основе этой информации сделать вывод о срочности исправления. При этом, если мы сможем задать более четкое описание ошибки отличное от текста Oracle (SQLERRM), то это позволит упростить понимание причин возникновения и способов решения ошибки.
Как должно быть (в идеале)
Не найдена запись в таблице содержащей адреса электронной почты клиентов
ORA-01403: данные не найдены
USR0001: Не найден адрес электронной почты клиента (идентификатор клиента)
Не найдена запись в таблице содержащей лицевые счета клиентов
ORA-01403: данные не найдены
USR0002: Не найден лицевой счет клиента (идентификатор клиента)
Из этого примера видно, что одна и та же ошибка «no_data_found» (ORA-01403: данные не найдены) может иметь совершенно разное значение с точки зрения бизнес логики, а значит нам необходимо разработать механизм, который позволит идентифицировать каждое событие происходящее в БД как отдельное событие с нашим внутренним уникальным кодом и текстом события (отличную от Oracle). Таким образом мы решаем две проблемы:
1) В месте возникновения ошибки мы устанавливаем уникальный код ошибки. В будущем это позволяет достаточно быстро найти место возникновения ошибки. Также, наличие уникальных кодов позволяет нам произвести точечный подсчет повторений и на основании этой информации принять решение об устранении данной ошибки.
2) Дополнительный "читаемый" текст позволяет сильно упростить понимание ошибки. В таблице выше показано, как одна и та же ошибка может запутать или разъяснить пользователю сведения об ошибке.
Надеюсь мне удалось объяснить зачем необходимо кодировать события в таблице логов. Далее по тексту, будут введены термины «Архитектурный лог» и «Пользовательский лог». На примере процедуры поиска активного номера телефона клиента будет показано как и зачем создано разделение на архитектурный и пользовательский лог.
Throughput

Раздел Throughput отображает пропускную способность. Пропускная способность базы данных измеряет объем работы, которую база данных выполняет за единицу времени.
Пики на графике Throughput должны соответствовать пикам на графике Average Active Sessions. Если заметен рост времени ожидания, необходимо убедиться, что увеличивается пропускная способность. Если пропускная способность низкая, а время ожидания растет — необходимо изменить настройки БД.

Latency показывает задержку чтения блоков. Это разница между временем выполнения чтения и временем обработки чтения БД. Показатель должен стремиться к нулю.
Оптимальным считается значение до 10 мс. Этот график — основной показатель производительности в этом блоке. Если зафиксирован рост времени задержки, нужно посмотреть, не растет ли количество I/O операций и их вес, также на рост Latency может влиять утилизация CPU.
Статистику по I/O можно смотреть в разрезе функций, в разрезе типов и в разрезе групп потребителей ресурсов (группы пользователей). Для этого на графике необходимо выбрать соответствующий Breakdown. Графики показывают количество I/O-операций в секунду и их вес в разрезе выбранного значения Breakdown. Для большей детализации можно провалиться глубже в статистику, выбрав соответствующее значение на графике или в легенде, и посмотреть статистику именно по выбранному значению.
I/O Function

График дает представление об уровне утилизации диска приложениями или джобами. То есть на графике можно увидеть, какие процессы больше всего читали и писали за определенный период.
Можно выделить следующие категории:
| № | Категория | Описание |
|---|---|---|
| 1 | Фоновые процессы | Включают в себя ARCH, LGWR, DBWR (полный список фоновых процессов есть в документации) |
| 2 | Активность | XML DB, Streams AQ, Data Pump, Recovery, RMAN |
| 3 | Тип I/O | Включает прямую запись и чтение (в том числе чтение из кэша) |
| 4 | Другое | Включает операции ввода/вывода управляющих файлов |
I/O Type

Выводит статистику по тяжести операций ввода-вывода. Маленькими считаются операции, которые обрабатывают до 128 КБ. К большим операциям ввода-вывода относятся: сканирование таблиц и индексов, прямая загрузка данных, резервное копирование, восстановление и архивирование.
Consumer group
Дает представление об утилизации диска в разрезе групп пользователей: показывает, какая группа пользователей выполняет операции чтения и записи в определенный период. Включает в себя фоновые процессы.
5.2.1 Listing Log Files
To list the log files, perform the following steps:
Select the Move or Move All button to move the selected or all available components to the Selected Components box.
Select the Search button to list the log files for the selected components.
After the search returns, the Results section shows log file information such as the name of the component associated with a log file and a link to the log file.
Figure 5-1 shows the Application Server Control Console View Logs page after a search.
Figure 5-1 Enterprise Manager View Logs Search Results
When you click the Logs link, the Application Server Control Console displays the View Logs page and runs a search for the component's log files. You can then view the log files by selecting the Log File links shown in the Results section.
Average Active Sessions
- Если зафиксирован рост активных сессий, то должна расти пропускная способность (график Throughput).
- Если Active Sessions превышает CPU Cores/CPU Threads, это свидетельствует о проблемах производительности.
- Если зафиксирован рост времени отклика операций, но при этом активные сессии не превышают CPU, это значит, что узкое место не в CPU и нужно более детально смотреть, по каким классам события ожидания фиксируется рост, после чего можно на графике нажать на соответствующий класс и провалиться глубже в детализацию (откроется отчет ASH — Active Session History).
5.1.2 Using a Log Repository
The Application Server Control Console supports viewing diagnostic messages from a Log Repository. A Log Repository:
Stores error logs, but does not store access logs.
Contains diagnostic messages collected from multiple log files across components.
Consolidates Oracle Application Server log file data, which allows you to use the Application Server Control Console to easily search and view log file data generated by multiple components.
Speeds up the diagnostic process and reduces the resources required to support Oracle Application Server.
A Log Repository is updated by the Oracle Application Server Log Loader component.
Пользовательское логирование событий
Предположим, что однажды в нашей процедуре get_telnumber произошла «архитектурная ошибка». В частности, для конкретного пользователя в таблице client_telnumbers хранится два номера телефона с признаком «активный». В таком случае, процедура «упадёт» с ошибкой «ORA-01422: too_many_rows». При этом, наш функционал архитектурного логирования сгенерировал новый код ошибки «SYS0061» и создал запись в таблице лога.
![]()
рис. Код архитектурной ошибки SYS0061
Самое важно в такой ситуации это не откладывать «на потом» исправление архитектурных ошибок. В идеале, необходимо создать отдельную задачу (баг) и в рамках неё устранить ошибку.
Предположим ,что была создана отдельная задача для устранения ошибки и назначена разработчику. В рамках этой задачи, разработчик совместно с технологом, аналитиком и др. коллегами пришел к выводу, что указанная ошибка носит систематический характер, является некорректной работой системы и требует исправления. В качестве мер исправления было решено добавить обработку события «too_many_rows» с последующим логированием события в таблице лога и выводом текста ошибки для пользователя.
Для этого в процедуре get_telnumber добавлено исключение (exception) «too_many_rows» пользовательского логирования. Также, был создан справочник пользовательских ошибок отличный от архитектурного справочника, тем что в него все записи добавляются разработчиком "вручную". Наверное это самое слабое место во всей архитектуре логирования. Предполагается, что разработчик должен описать исключение (exception) и создать для него уникальный код ошибки. Также, желательно к указанной ошибке сформулировать читаемый текст ошибки (для своих коллег, пользователя, техподдержки и т.д.), что бывает иногда очень сложным (из личного опыта).
Таблица пользовательских ошибок и процедура их "регистрации" будет выглядеть следующим образом:
Исходный код таблицы пользовательских ошибок и процедуры регистрации
Обратите внимание, что текст ошибок имеет параметризацию т.е. для ошибки в тексте имеются специальные символы $1, $2, $3 и т.д. Например, рассмотрим ошибку "USR0003" с текстом "Для клиента найдено два и более активных номеров телефона!" при вызове функции f_get_errcode на вход подаётся код ошибки и параметры ошибки. Далее, функция по коду ошибки найдет строку, в тексте ошибки заменит подстроку "$1" на значение параметра to_char(p_userid) т.е. подставит значение to_char(p_userid).
В случае если в тексте ошибки будут два и более спецсимвола $1, $2, $3 и т.д., то параметры передаются с использованием символа-разделителя ";".
Итого, содержимое справочника пользовательских ошибок будет выглядеть следующим образом:

рис. Пример содержимого справочника пользовательских ошибок
*Исходный код других используемых объектов смотрите в Git
После того, как мы "зарегистрировали" пользовательскую ошибку "USR0003" и добавив отдельную обработку пользовательского логирования (строки с 19 по 28), наша процедура get_telnumber будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
При повторном возникновении ошибки «too_many_rows» обработка события пройдет по нашему сценарию «пользовательского» логирования. Таким образом мы можем ввести второй термин (в рамках данного цикла статей), «Пользовательские логирование» - это логирование всех ошибок, возникновение которых предполагается и ожидается при нештатной работе алгоритма. В итоге, пользователь получит читаемый текст ошибки с кодом «USR0003», также, мы же всегда сможем подсчитать количество ошибок с указанным кодом. В случае большого количества ошибок у нас на руках будет «живая» статистика частоты возникновения ошибки и их количества, что позволит нам выйти на руководство с предложением по доработке/оптимизации процесса.
Давайте рассмотрим еще один пример (кейс из реального случая), в момент когда процедура get_telnumber по id клиента находит один "активный" номер телефона иногда возникает ситуация, что номер телефона не принадлежит мобильному оператору. Ситуации бывают разные иногда указанный номер мог быть номером городской телефонной сети, иногда номером международного оператора, а иногда вообще набор из нескольких цифр и т.д. Основным требованием от бизнес-заказчика было использование номера телефона российских операторов мобильной связи. Поэтому было решено добавить проверку соответствия найденного номера некому "корректному" шаблону (строки с 18 по 29). В случае обнаружения некорректного номера, логировать данное событие отдельным кодом "USR0004" и типом "WRN". Добавим функцию проверки корректности номера телефона, если номер соответствует шаблону (требованиям), то вернем номер телефона, иначе пустое значение.
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
После сбора статистических данных по конкретной ошибке с кодом "USR0004", руководству стало понятно, что ошибка актуальна и количество ошибок с течением времени не только не уменьшается, а наоборот растет с линейной прогрессией. В дальнейшем, были выявлены источники "кривых" данных и были установлены внутренние требования по первичной обработке номера телефона клиентов. В итоге, со временем количество ошибок уменьшилось до нуля. И этого нельзя было добиться до тех пор, пока у всех участвующих лиц не возникло понимание о масштабе проблемы.
Исходный код запроса
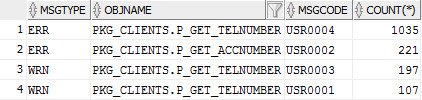
рис. Пример результата запроса с группировкой
*Исходный код других используемых объектов смотрите в Git
Instance Efficiency Percentages

| № | Показатель | Критерии |
|---|---|---|
| 1 | Buffer nowait | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size |
| 2 | Buffer Hit | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size |
| 3 | Library cache hit | Если показатель меньше 95% — нужно расширять shared pool (либо причина в bind-переменных) |
| 4 | Redo NOWAIT | Если показатель меньше 95%, это говорит о проблеме в redo log buffer или redo log |
| 5 | Parse CPU to Parse Elapsd | Показатель должен быть больше или равен 90%, тогда большинство процессов не ожидает ресурсов, что говорит о правильной работе базы данных |
| 6 | Non-Parse CPU | Показатель должен приближаться к 100%, это значит, что большинство ресурсов CP используется в различных операциях, кроме parsing, что говорит о правильной работе базы данных. Если Non-Parse CPU низкий, значит, база много времени тратит на разбор запроса вместо реальной работы |
| 7 | In-memory sort | Значение меньше 100 говорит о том, что сортировка идет через диск, а также есть потенциальные проблемы с PGA_AGGREGATE_TARGET,SORT_AREA_SIZE,HASH_AREA_SIZE и bitmap setting |
| 8 | Soft Parse | Чем он выше, тем меньше у нас Hard Parse |
| 9 | Latch Hit | Чем он выше, тем меньше мы ждем Latches (если он низкий — у нас проблемы с CPU-Bound и Latches) |
Services

Службы на этом графике представляют собой группы приложений. Отображаются только сессии активных служб, находящиеся в ожидании в определенный момент времени. Например, служба SYS$USERS — это установка пользовательского сеанса.
Performance Home
На вкладке Performance Home можно увидеть основные графики утилизации БД.
5.3.1 Starting and Stopping Log Loader
You can use the controls on the Application Server Control Console Log Loader page to start and stop the Log Loader.
Click the Logs link on the Application Server Control Console page.
On the View Logs page, click the Search Log Repository link.
Click the Log Loader button on the view logs page.
On the Log Loader page, click Start . The confirmation page is displayed.
If the log loader is already running, then click the Stop button to stop it.
Click Start or Start and Load Existing Logs .
Use the Start and Load Existing Logs button to start and initialize the log repository with the existing log messages.
Top 10 Foreground Events by Total Wait Time
В разделе находится топ-10 событий, которые ожидали ресурсов дольше остальных.
При анализе необходимо обратить внимание на класс события ожидания. Если wait class System I/O, User I/O или Other, это нормально для БД. Если класс события ожидания Concurrency, это может свидетельствовать о проблемах.
Классы события ожидания можно посмотреть в разделе Wait Classes by Total Wait Time. В разделе находится статистика по классам события ожидания с сортировкой по времени ожидания.
Описание некоторых событий ожидания:
| № | Событие ожидания | Описание |
|---|---|---|
| 1 | DB CPU | Отображает процессорное время, затраченное на пользовательские операции над БД. Это событие должно находиться на первом месте списка |
| 2 | db file sequential read | Метрика сигнализирует, что пользовательский процесс не находит нужный блок в buffer cache, загружает его с диска в SGA и ждет физического ввода/вывода |
| 3 | db file scattered read | Указывает на проблему с фулл-сканами, возможно, нужны индексы |
| 4 | read by other session | Может говорить о том, что размер блока слишком большой или задержка (latency) слишком большая |
| 5 | enq TX – row lock contention | Событие возникает при ожидании блокировки строки для дальнейшей ее модификации DML-запросом. Если показатель больше 10%, необходимо разбираться в причинах. Более детальную информацию можно посмотреть в разделе Segments by Row Lock Waits, в котором есть сведения о том, какие таблицы были заблокированы и какими запросами |
| 6 | DB FILE SEQUENTIAL READ | Если среднее значение параметра больше 100 мс, это может свидетельствовать о том, что диск работает медленно |
| 7 | LOG FILE SYNC | Значение AVG WAIT более 20 мс может свидетельствовать о проблемах |
| 8 | DB FILE SCATTERED READ | Если это событие выполняется — возможно, имеет смысл создать дополнительные индексы. Для более подробной информации нужно перейти к разделу Segments By Physical Read, в котором находится информация по таблицам и индексам, в которых происходит физическое чтение |
| 9 | direct path read temp ИЛИ direct path write temp | Эти события дают информацию по использованию временных файлов |
| 10 | Buffer Busy Wait | Событие указывает на то, что несколько процессов пытаются обратиться к одному блоку памяти, то есть пока первый процесс работает с конкретным блоком памяти, остальные процессы находятся в статусе ожидания |
5.3 Using Oracle Application Server Log Loader
The Oracle Application Server Log Loader component initializes and updates messages in the Log Repository. A Log Repository stores diagnostic messages from multiple log files across Oracle Application Server components. After the Log Loader starts, at regular intervals, it reads the contents of log files incrementally and stores the contents to the Log Repository.
This section contains the following topics:
5.3.4 Setting Log Loader Properties
You can set Log Loader properties from the Log Loader page. To navigate to the Log Loader page:
Select the Logs link on any Application Server Control Console page.
From the View Logs page, select the Search Log Repository link.
Click Log Loader on the View Logs page.
Select the Log Loader Properties link in the Administration section. The Log Loader Properties page includes fields showing the current values for the Log Loader properties.
To change the Log Loader properties, perform the following steps:
Enter updated values in the appropriate fields on the Log Loader Properties page.
Click Apply to apply the new values.
Figure 5-2 shows the Application Server Control Console Log Loader Properties page.
The Application Server Control Console online help includes detailed information about the Log Loader Properties fields.
Figure 5-2 Log Loader Properties Page
Parallel Executions
Раздел дает представление о показателях, связанных с параллельным выполнением запросов. Параллельный запрос делится на несколько процессов для ускорения выполнения запроса. Параллельное выполнение полезно при выполнении тяжелых запросов. Подробнее можно прочесть в официальной документации Oracle.
5.2.3 Listing Log Files from Oracle Application Server Components Pages
After you select a system component link on the Application Server Control Console main page, you can view the component log files by selecting the Logs link. When you select this link, the Application Server Control Console shows the View Logs page and runs a search for the component's log files. Thus, clicking on the Logs link for pages associated with a component runs a log file search for that component. You can then view the log files by selecting the Log File links shown in the Results section.
When you select the Logs link from a component page, the log file pages include a Return to link at the bottom of each page. The Return to link returns you to the component page from which you selected the Logs link.
Введение
Модель логирования позволяет реализовать:
Единый подход в обработке и хранении событий (статья)
Собственную нумерацию и идентификацию событий происходящих в БД
Единый мониторинг событий (статья в разработке)
Анализ событий происходящих в БД (статья в разработке)
Описанные выше характеристики указаны в порядке нумерации и каждый следующий пункт (шаг) есть улучшение и усложнение существующей модели. Описание этой модели будет сложно выполнить в рамках одной статьи, поэтому опишем их последовательно. В этой (второй) статье создадим собственную нумерацию кодов для событий, а также создадим функционал идентификации событий происходящих в БД.
5.3.3 Updating the Log Configuration
When the Log Loader starts, it loads configuration information about the component log files to use as source for the diagnostic messages. These messages are stored in the Log Repository, which includes information about the location and format of the log files. The instance is reconfigured after the Log Loader is started. For example, when a new component is added, click the Update Log Configuration button to update the Log Loader configuration. Updating the log configuration allows the Log Loader to reread configuration files to locate and load all the component log files into the Log Repository.
Host CPU и Instance CPU
Здесь стоит обратить внимание на %Idle и %Total CPU. Если показатель %Idle низкий, а %Total CPU высокий, это может свидетельствовать о том, что процессор является узким местом.
5.1.3 Configuring Component Logging Options
You can configure logging options to manage and limit the logging information that Oracle Application Server components generate and save.
Specifying Log File Names and Pathnames
Limiting Log File Size
Using Log File Archiving
Setting Component Logging Levels
The logging configuration options are component dependent. All components do not support the logging configuration options.
Читайте также: