
Oracle кто изменил пакет
← →
AV © ( 2012-05-22 10:10 ) [0]
Что бы его перекомпилить (внес правку)
Как это сделать?
Только вышибу одного - второй залез..
← →AV © ( 2012-05-22 10:19 ) [1]
права убить сессиию есть,
но такой скрипт не работает, нет прав, видимо, т.к. не вижу вьюху
можно было бы получить скрипт, всех прибить и моментально запустить перекомпиляцию, пока никто не залез
← →AV © ( 2012-05-22 10:32 ) [2]
вообще не понимаю..
есть учетка, коннектится "as SYSDBA" и dba_ddl_locks не видит..
AV © ( 2012-05-22 11:28 ) [3]
А, может, кто подскажет, как пакет совсем "свалить"?
Пусть побудет инвалидным пока, пусть ошибки полезут у юзеров,
главное не дать им юзать его, пока не подсуну поправленный.
Inovet © ( 2012-05-22 11:39 ) [4]
Клиент пусть сам проверяет свою версию и отключается.
зы
пакет тоже не мой, не я писал, но пароль владельца знаю
Он из пакета дергает функцию, совсем простою
буквально -- если параметр в (список вариантов), то вернуть ДА --
Наблюдая, понял, что не все варианты в списке перечислены. Вот и хочу дописать
in (. еще_один_вариант)
AV © ( 2012-05-22 12:49 ) [6]
перекомпилил таки,
но буду признателен, если подскажете как это можно было сделать
а не так как сделал, а именно: открыв справочник должностей юзеров, постоянно прибивал подозрительных и пытался компилить. В очередной раз получилось.
← →Pit ( 2012-05-23 20:20 ) [7]
Бред какой-то. Ты что пытался с пакетом делать то?
Есть такое понятие как исходный код пакета, а есть его откомпиленная версия.
По-умолчанию, после сохранения кода пакета - он помечается неоткомпиленным. Первый же вызов этого пакета приведет к его компиляции (и блокировке всех других до окончания компиляции).
В чём у тебя проблема то была?
← →Petr V. Abramov © ( 2012-05-23 23:01 ) [8]
а в чем проблема перекомпилить-то.
ну получили бы юзеры existing state of packages has been discarded или как-то так, и вышли бы из программы в ужасе, перезашли бы, и все путем.
Pit ( 2012-05-23 23:49 ) [9]
угу. Ну или хотя бы давайте уточним версию oracle и что за клиент используется. И что в этом клиенте нажимается, что автор обозвал перекомпиляцией.
1) для выполнения процедуры ALTER (изменение исходника пакета) требуется эксклюзивная сессия.
При выполнении пакета работает shared-сессия.
Соответственно, если речь про изменение исходников пакета - то при работающих сессиях произойдет блокировка, пока эксклюзивная сессия не захватит "управление", после чего уже все shared-сессии пытающиеся исполнить пакет будут залочены. После сохранения исходников первая же "вошедшая" в пакет сессия приведет к автоматической перекомпиляции, на время компиляции все сессии также будут залочены.
← →Petr V. Abramov © ( 2012-05-24 00:02 ) [11]
> Pit (23.05.12 23:53) [10]
ну тут наверное не alter, а сreate or replace, что, правда, сути не меняет.
повисит-повисит, да скомпилится, а остальные получат
ORA-04068: existing state of packages has been discarded
AV © ( 2012-05-24 11:53 ) [12]
Знаю ,что теоретически,
> после сохранения кода пакета - он помечается неоткомпиленным.
> Первый же вызов этого пакета приведет к его компиляции
но получалось так:
поправил, нажал компилировать, все повисло
> повисит-повисит, да скомпилится
сколько повисит?
Висело до 20-30 минут. Потом процесс прибивал.
Pit ( 2012-05-24 17:09 ) [13]
А это значит транзакция, затронувшая этот пакет продолжалась без комита более твоего времени ))
Не стоит так писать транзакции )
Petr V. Abramov © ( 2012-05-24 21:20 ) [14]
> Pit (24.05.12 17:09) [13]
>
> А это значит транзакция, затронувшая этот пакет продолжалась
> без комита более твоего времени ))
> Не стоит так писать транзакции )
>
ну как бы это самое очевидное, что приходит в голову, хорошо, если так.
или что-то сурьезнее, но тоже ниче хорошего.
завтра поболтаю.
AV © (24.05.12 11:53) [12]
> сколько повисит?
> Висело до 20-30 минут. Потом процесс прибивал.
выясни, не самое ли очевидное.
Кщд ( 2012-05-25 08:54 ) [15]
> Pit (23.05.12 20:20) [7]
> По-умолчанию, после сохранения кода пакета - он помечается
> неоткомпиленным.
> Есть такое понятие как исходный код пакета, а есть его откомпиленная
> версия.
что такое компиляция - понятно, а что за зверь "сохранение кода пакета"?
> Petr V. Abramov © (23.05.12 23:01) [8]
> а в чем проблема перекомпилить-то.
проблема в том, что перекомпиляция модуля(например, пакета) в высоконагруженной среде - это, действительно, задача непростая.
>AV © (22.05.12 10:19) [1]
для появления dba_ddl_locks: catblock.sql
НО это неприятный и неэффективный способ по двум причинам:
1. при большой пользовательской активности на каждую убитую таким образом сессию - будет создано несколько новых)
2. это дико, когда пользователь час редактирует большую форму и внезапно получает "your session has been killed". многие при этом пытаются перелогиниться. только затем, чтобы через некоторое время снова попасть под комбайн смерти "alter system kill session" - неприятненько.)
Гарантированный результат достигается:
1. alter user NutsUser account lock;
2. dba_ddl_locks + alter system kill session.
Всё это делается в контексте регламентированного технологического окна.
Кщд ( 2012-05-25 09:00 ) [16]
> Pit (24.05.12 17:09) [13]
> А это значит транзакция, затронувшая этот пакет продолжалась
> без комита более твоего времени ))
> Не стоит так писать транзакции )
какие транзакции?
SQL> create table uuu (id number);
SQL> create or replace package body ptmp is
2
3 procedure do_smth
4 is
5 begin
6 insert into uuu values(1);
7 end;
8
9 end ptmp;
10 /
Package body created
SQL> create or replace package ptmp is
2
3 procedure do_smth;
4
5 end ptmp;
6 /
SQL> exec ptmp.do_smth;
PL/SQL procedure successfully completed
SQL> alter package ptmp compile;
> Гарантированный результат достигается:
> 1. alter user NutsUser account lock;
прибить сессию - еще куда ни шло. Но запретить вообще все -
действительно
> Всё это делается в контексте регламентированного технологического
> окна.
Кщд ( 2012-05-25 09:54 ) [18]
>AV © (25.05.12 09:48) [17]
> прибить сессию - еще куда ни шло. Но запретить вообще все
> -
> действительно
ещё раз: при большой активности пользователей на продуктиве иначе - никак
AV © ( 2012-05-25 10:46 ) [19]
Кщд, (не знаю как Вас по батюшке :),)
а может Вы подскажете осуществима ли такая идея:
1. Считываем всех, у кого есть грант на пакет, запоминаем
2. Отнимаем его у всех. Никого не надо выгонять совсем, просто никто больше не может пакетом воспользоваться.
3. Делаем что надо
4. Восстанавливаем гранты из запомненного.
AV © ( 2012-05-25 10:51 ) [20]
т.е. там же есть таблички sys где гранты прописаны,
считывая их, генерируем два запроса-строки. на выдачу прав и на отбор
запускаем на отбор
работаем
запускаем на выдачу
Pit ( 2012-05-25 11:09 ) [21]
> что такое компиляция - понятно, а что за зверь "сохранение
> кода пакета"?
ну выполнение операции alt / create or replace - которое изменяет код пакета.
Кщд ( 2012-05-25 11:21 ) [22]
>AV © (25.05.12 10:46) [19]
cчитаю, плохая идея с grant: в случае исключительной ситуации, некоторые пользователи останутся без grant
+ ко всему, придется раскручивать всё дерево зависимости этого пакета и делать revoke для всех зависящих от данного пакетов.
чем не устраивает вариант с account lock + kill session?
← →Кщд ( 2012-05-25 11:23 ) [23]
>Pit (25.05.12 11:09) [21]
>ну выполнение операции alt / create or replace - которое изменяет код пакета.
это перекомпиляция
AV © ( 2012-05-25 13:03 ) [24]
> чем не устраивает вариант с account lock + kill session?
да не, все нормально, так и сделаю в след. раз. Это же не долго.
alter package ptmp compile; - что же она тогда делает?
Создание / изменение ИСХОДНОГО кода пакета / процедуры / функции не приводит по-умолчанию к компиляции. Скомпилированное тело помечается как INVALID до первого вхождения, когда оно компилируется.
Можно откомпилить вручную.
← →Кщд ( 2012-05-25 17:09 ) [27]
>Pit (25.05.12 16:38) [26]
> Создание / изменение ИСХОДНОГО кода пакета / процедуры /
> функции не приводит по-умолчанию к компиляции. Скомпилированное
> тело помечается как INVALID до первого вхождения, когда
> оно компилируется.
это, простите, феерический бред
покажите лог из sqlplus созданного без ошибок компиляции пакета, у которого статус после компиляции "INVALID"
PS то, о чем говорите Вы, касается состояния зависимых от компилируемого объектов
← →Pit ( 2012-05-25 18:28 ) [28]
да очень просто.
- Создайте пакет с помощью create or replace. Скомпильте его или используйте хотя бы один раз
- далее измените код пакета с помощью create or replace. Вот и всё.
Во втором случае АВТОМАТИЧЕСКОЙ компиляции не будет. Исходный код пакета будет ОТЛИЧАТЬСЯ от скомпилированной версии, которая будет помечена ошибочной (ну или там требующей перекомпила, смотря как интерпретировать).
Впрочем, вы утверждаете, что понятия компиляции вообще не существует. Уже отсюда у нас с вами разные дороги. Видимо, разный оракл используем, нет смысла спорить.
Впрочем, в моем мире оракла про компиляцию все же сказано. И создание кода пакета вовсе не означает его компиляцию, во что вы не верите.
Скомпилить пакет можно или вручную:
alter package ptmp compile;
или просто дождаться, что кто-то заюзает этот пакет и он будет скомпилирован автоматически тогда. Этим самым оракл демонстрирует свой принцип типа "отложенных вычислений", то есть не делать того, что можно сделать позже.
Точно также и с фетчингом записей. Оракл утверждает, что в нормальной ситуации реальное вычисление следующих записей происходит по мере фетчинга записей, а не сразу при исполнении запроса.
Влад ( 2012-05-25 19:51 ) [29]
> Pit (25.05.12 18:28) [28]
> или просто дождаться, что кто-то заюзает этот пакет и он
> будет скомпилирован автоматически тогда.
ну, допустим, дождался. Это я же и есть. Поправил и нажал compile.
Для этого я желательно ищу SQL-запрос, но могут быть полезны и другие варианты.
Будучи разработчиком веб-приложений, легко впасть в заблуждение, считая, что приложение без JavaScript не имеет права на жизнь. Нам становится удобно.
Если вы ищете пакет для быстрой интеграции календаря с выбором даты в ваше приложения, то библиотека Flatpickr отлично справится с этой задачей.
Клиент для URL-адресов, cURL, позволяет взаимодействовать с множеством различных серверов по множеству различных протоколов с синтаксисом URL.
У каждого из нас бывали случаи, когда нам нужно отцентрировать блочный элемент, но мы не знаем, как это сделать. Даже если мы реализуем какой-то.
Пользовательское логирование событий
Предположим, что однажды в нашей процедуре get_telnumber произошла «архитектурная ошибка». В частности, для конкретного пользователя в таблице client_telnumbers хранится два номера телефона с признаком «активный». В таком случае, процедура «упадёт» с ошибкой «ORA-01422: too_many_rows». При этом, наш функционал архитектурного логирования сгенерировал новый код ошибки «SYS0061» и создал запись в таблице лога.
![]()
рис. Код архитектурной ошибки SYS0061
Самое важно в такой ситуации это не откладывать «на потом» исправление архитектурных ошибок. В идеале, необходимо создать отдельную задачу (баг) и в рамках неё устранить ошибку.
Предположим ,что была создана отдельная задача для устранения ошибки и назначена разработчику. В рамках этой задачи, разработчик совместно с технологом, аналитиком и др. коллегами пришел к выводу, что указанная ошибка носит систематический характер, является некорректной работой системы и требует исправления. В качестве мер исправления было решено добавить обработку события «too_many_rows» с последующим логированием события в таблице лога и выводом текста ошибки для пользователя.
Для этого в процедуре get_telnumber добавлено исключение (exception) «too_many_rows» пользовательского логирования. Также, был создан справочник пользовательских ошибок отличный от архитектурного справочника, тем что в него все записи добавляются разработчиком "вручную". Наверное это самое слабое место во всей архитектуре логирования. Предполагается, что разработчик должен описать исключение (exception) и создать для него уникальный код ошибки. Также, желательно к указанной ошибке сформулировать читаемый текст ошибки (для своих коллег, пользователя, техподдержки и т.д.), что бывает иногда очень сложным (из личного опыта).
Таблица пользовательских ошибок и процедура их "регистрации" будет выглядеть следующим образом:
Исходный код таблицы пользовательских ошибок и процедуры регистрации
Обратите внимание, что текст ошибок имеет параметризацию т.е. для ошибки в тексте имеются специальные символы $1, $2, $3 и т.д. Например, рассмотрим ошибку "USR0003" с текстом "Для клиента найдено два и более активных номеров телефона!" при вызове функции f_get_errcode на вход подаётся код ошибки и параметры ошибки. Далее, функция по коду ошибки найдет строку, в тексте ошибки заменит подстроку "$1" на значение параметра to_char(p_userid) т.е. подставит значение to_char(p_userid).
В случае если в тексте ошибки будут два и более спецсимвола $1, $2, $3 и т.д., то параметры передаются с использованием символа-разделителя ";".
Итого, содержимое справочника пользовательских ошибок будет выглядеть следующим образом:

рис. Пример содержимого справочника пользовательских ошибок
*Исходный код других используемых объектов смотрите в Git
После того, как мы "зарегистрировали" пользовательскую ошибку "USR0003" и добавив отдельную обработку пользовательского логирования (строки с 19 по 28), наша процедура get_telnumber будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
При повторном возникновении ошибки «too_many_rows» обработка события пройдет по нашему сценарию «пользовательского» логирования. Таким образом мы можем ввести второй термин (в рамках данного цикла статей), «Пользовательские логирование» - это логирование всех ошибок, возникновение которых предполагается и ожидается при нештатной работе алгоритма. В итоге, пользователь получит читаемый текст ошибки с кодом «USR0003», также, мы же всегда сможем подсчитать количество ошибок с указанным кодом. В случае большого количества ошибок у нас на руках будет «живая» статистика частоты возникновения ошибки и их количества, что позволит нам выйти на руководство с предложением по доработке/оптимизации процесса.
Давайте рассмотрим еще один пример (кейс из реального случая), в момент когда процедура get_telnumber по id клиента находит один "активный" номер телефона иногда возникает ситуация, что номер телефона не принадлежит мобильному оператору. Ситуации бывают разные иногда указанный номер мог быть номером городской телефонной сети, иногда номером международного оператора, а иногда вообще набор из нескольких цифр и т.д. Основным требованием от бизнес-заказчика было использование номера телефона российских операторов мобильной связи. Поэтому было решено добавить проверку соответствия найденного номера некому "корректному" шаблону (строки с 18 по 29). В случае обнаружения некорректного номера, логировать данное событие отдельным кодом "USR0004" и типом "WRN". Добавим функцию проверки корректности номера телефона, если номер соответствует шаблону (требованиям), то вернем номер телефона, иначе пустое значение.
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
После сбора статистических данных по конкретной ошибке с кодом "USR0004", руководству стало понятно, что ошибка актуальна и количество ошибок с течением времени не только не уменьшается, а наоборот растет с линейной прогрессией. В дальнейшем, были выявлены источники "кривых" данных и были установлены внутренние требования по первичной обработке номера телефона клиентов. В итоге, со временем количество ошибок уменьшилось до нуля. И этого нельзя было добиться до тех пор, пока у всех участвующих лиц не возникло понимание о масштабе проблемы.
Исходный код запроса
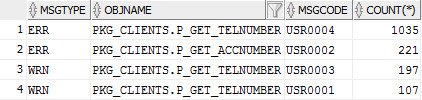
рис. Пример результата запроса с группировкой
*Исходный код других используемых объектов смотрите в Git
Предисловие
Данным постом хотел бы начать цикл статей посвященных «Логированию ошибок» в Oracle PL/SQL. В первую очередь донести мысль до многих разработчиков, о том как можно построить функционал фиксации, хранения логов в БД. На своем опыте продемонстрировать поэтапный процесс создания полноценного логирования в БД. Рассказать как нам удалось создать логирование ошибок, разработать единую нумерацию событий для их дальнейшей идентификации, как поверх логирования «натянуть» мониторинг событий, создать функционал позволяющий увидеть все текущие ошибки в БД в виде таблиц (с указанием частоты возникновения ошибок и кол-ва и т.д.), графиков (отразить динамику роста кол-ва ошибок) и правильно распределить ресурсы для устранения тех или иных ошибок.
Оговорюсь сразу, что на рынке возможно уже есть успешные существующие коммерческие продукты осуществляющие логирование гораздо лучше и качественнее хотя бы, потому что у них есть многолетний опыт внедрения и сопровождения своего продукта в различных компаниях. Я же хочу показать один из множества примеров реализации функционала логирования, которые вполне можно осуществить силами своих разработчиков.
Ответы 4
LAST_DDL_TIME - это последний раз, когда он был скомпилирован. TIMESTAMP - это последний раз, когда он был изменен.
Может потребоваться перекомпиляция процедур, даже если они не изменились при изменении зависимости.
я не могу найти user_objects. Ошибка при выполнении этого запроса
@Harie - это потому, что этот вопрос касается Oracle, а не SQL Server.
Соответствует ли описание LAST_DDL_TIME и TIMESTAMP ? Я только что перекомпилировал тело пакета (оно было недействительным): alter package foo compile body reuse settings; и оба столбца были обновлены. Другое отличие состоит в том, что я запрашиваю DBA_OBJECTS (но это не имеет значения?).
@ user272735 На какой у вас версии Oracle? Я думаю, что они улучшили некоторые вещи, связанные с зависимостями, в 11, которые могли бы это изменить.
@ user272735 В таком случае, похоже, я ошибаюсь. Возможно, вам стоит опубликовать ответ с выводом сценария, показывающим это.
можно ли также узнать, с какой машины он был скомпилирован?
Следующий запрос будет выполняться в Oracle
@Thilakan - Если вы собираетесь запросить ALL_OBJECTS , вы должны включить предикат в OWNER , иначе вы можете получить несколько строк в дополнение к предикату OBJECT_TYPE из ответа WW пару лет назад. Вы, вероятно, также должны отметить, что ALL_OBJECTS содержит все объекты, которые текущий пользователь имеет привилегии, не для всех объектов в базе данных, которые будут в DBA_OBJECTS .

рис. Старый "дедовский" debug кода
Добрый день! Работая разработчиком Oracle PL/SQL, часто ли вам приходилось видеть в коде dbms_output.put_line в качестве средства debug-а? Стоит признать, что к сожалению, большинство (по моему личному мнению и опыту) разработчиков Oracle PL/SQL не уделяет должного внимания логированию как к «спасательному кругу» в случае возникновения ошибок. Более того, большая часть разработчиков не совсем понимает зачем нужно логировать информацию об ошибках и самое главное, не совсем понимают что делать и как использовать эту информацию в будущем.
Архитектурное логирование событий
Давайте рассмотрим пример, имеется процедура поиска активного номера телефона принадлежащего конкретному клиенту (для примера его Предположим, что при постановке задачи для разработчика не было описания каких-либо особых условий т.е. по условиям задачи предполагалось, что для конкретного пользователя (id = 43, идентификатор передается в качестве параметра) в таблице client_telnumbers всегда будет хотя бы одна запись с номером телефона клиента и признаком «активный» (значение поля enddate равно дате 31.12.5999 23:59:59, что означает что номер используется клиентом. В случае, любой другой даты в указанном поле означает, что номер перестал быть активным и более не используется), поэтому наша процедура будет выглядеть примерно так:
Исходный код демонстрационной процедуры
Важно! Представленный код является примерным (примитивным) и служит только для демонстрации логирования в рамках данной статьи. В своих статьях я не выкладываю текст кода из реально действующих БД. Надеюсь, вы понимаете, что в реальности указанная процедура написана гораздо сложнее.
*Исходный код других используемых объектов смотрите в Git
Если мы будем использовать логирование ошибок как показано в предыдущей статье, то с течением времени обнаружим, что идентифицировать ошибки из данной процедуры будет сложно. Поэтому для всех ошибок попадающих в обработку исключения «WHEN OTHERS» реализована процедура pkg_msglog.p_log_archerr, которая при первом возникновении ошибки автоматически присваивает ей уникальный код и сохраняет ошибку в таблице лога. В дальнейшем, при повторении данной ошибки процедура найдет ранее созданный код и использует его при логировании в таблице лога.
В итоге, после добавления блока «архитектурного» логирования (строки с 18 по 24), наша процедура будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
На этапе написания текста процедуры разработчик не всегда может предугадать возникновение той или иной ошибки (если честно, не всегда есть на это время), поэтому на начальном этапе ему достаточно «отлавливать» абсолютно все ошибки возникающие в данной процедуре с помощью оператора «WHEN OTHERS». Таким образом мы можем ввести новый термин (в рамках данного цикла статей), «Архитектурные логирование» - это логирование всех ошибок, возникновение которых не предполагается при штатной работе алгоритма. Для функционала «Архитектурных ошибок» были созданы объекты: отдельный справочник ошибок messagecodes_arch и процедура pkg_msglog.p_log_archerr создания записи в таблице лога для указанного типа ошибок.
Исходный код таблицы
Ограничение в таблице на комбинацию (Имя объекта, код ошибки SQLCODE). При первом появлении ошибки создается запись в таблице и генерируется код ошибки "SYS0000" + счетчик ошибок. При повторном появлении указанной ошибки будет взят уже сгенерированный ранее код ошибки.

рис. Пример содержимого таблицы messagecodes_arch
*Исходный код других используемых объектов смотрите в Git
Обратите внимание, что при использовании описанной модели «архитектурного» логирования у вас появляется функционал позволяющий максимально быстро реагировать на первое появление ошибки (в конкретной функции/процедуре). Для этого необходимо реализовать отдельный мониторинг архитектурных ошибок, который постараюсь продемонстрировать в следующей (третьей) статье. Использование процедуры pkg_msglog.p_log_archerr не требует каких-либо действий кроме описания входных параметров.
Таким образом мы можем создать базовый шаблон процедуры (функции), использование которого позволит вам гарантированно отлавливать все архитектурные ошибки в вашем коде.
Шаблон процедуры/функции с архитектурным логированием
Рекомендую использовать данный шаблон для построения "Событийной модели логирования".
*Исходный код других используемых объектов смотрите в Git
В рамках событийной модели логирования, предполагается, что все архитектурные ошибки будут исправляться отдельной задачей т.е. основная цель это устранить повторное появление ошибок с кодом "SYS****" в таблице лога. В указанной задаче вам необходимо либо устранить причины возникновения данной ошибки, либо добавить отдельную обработку ошибки отличную от «when others», которую в дальнейшем будем назвать «пользовательское» логирование (в рамках данного цикла статей).
Введение
Модель логирования позволяет реализовать:
Единый подход в обработке и хранении событий (статья)
Собственную нумерацию и идентификацию событий происходящих в БД
Единый мониторинг событий (статья в разработке)
Анализ событий происходящих в БД (статья в разработке)
Описанные выше характеристики указаны в порядке нумерации и каждый следующий пункт (шаг) есть улучшение и усложнение существующей модели. Описание этой модели будет сложно выполнить в рамках одной статьи, поэтому опишем их последовательно. В этой (второй) статье создадим собственную нумерацию кодов для событий, а также создадим функционал идентификации событий происходящих в БД.
Для чего это нужно?
Для начала давайте рассмотрим пример. Вы реализовали логирование ошибок в вашей БД. С течением времени в ваш лог «прилетают» самые разнообразные ошибки. Предположим, имеются две ошибки вида «no_data_found» возникшие в двух разных процедурах при двух разных запросах (select). Первая ошибка возникла при попытке найти «email» клиента, что в принципе не является критичной ошибкой. Вторая ошибка возникла при попытке найти номер лицевого счета клиента, что вполне может являться критичной ошибкой. При этом если мы посмотрим в таблицу лога (из статьи), то увидим, что указанные ошибки будут храниться с одинаковым кодом 1403 (ORA-01403) в столбце msgcode. Более того, текст указанных ошибок будет практически аналогичным (текст полученный с помощью функции SQLERRM) за исключением имен объектов, на которых произошла ошибка. Для того чтобы понять является ли критичной конкретная ошибка, разработчику необходимо вникать в текст ошибки, смотреть в каком объекте возникла ошибка и на основе этой информации сделать вывод о срочности исправления. При этом, если мы сможем задать более четкое описание ошибки отличное от текста Oracle (SQLERRM), то это позволит упростить понимание причин возникновения и способов решения ошибки.
Как должно быть (в идеале)
Не найдена запись в таблице содержащей адреса электронной почты клиентов
ORA-01403: данные не найдены
USR0001: Не найден адрес электронной почты клиента (идентификатор клиента)
Не найдена запись в таблице содержащей лицевые счета клиентов
ORA-01403: данные не найдены
USR0002: Не найден лицевой счет клиента (идентификатор клиента)
Из этого примера видно, что одна и та же ошибка «no_data_found» (ORA-01403: данные не найдены) может иметь совершенно разное значение с точки зрения бизнес логики, а значит нам необходимо разработать механизм, который позволит идентифицировать каждое событие происходящее в БД как отдельное событие с нашим внутренним уникальным кодом и текстом события (отличную от Oracle). Таким образом мы решаем две проблемы:
1) В месте возникновения ошибки мы устанавливаем уникальный код ошибки. В будущем это позволяет достаточно быстро найти место возникновения ошибки. Также, наличие уникальных кодов позволяет нам произвести точечный подсчет повторений и на основании этой информации принять решение об устранении данной ошибки.
2) Дополнительный "читаемый" текст позволяет сильно упростить понимание ошибки. В таблице выше показано, как одна и та же ошибка может запутать или разъяснить пользователю сведения об ошибке.
Надеюсь мне удалось объяснить зачем необходимо кодировать события в таблице логов. Далее по тексту, будут введены термины «Архитектурный лог» и «Пользовательский лог». На примере процедуры поиска активного номера телефона клиента будет показано как и зачем создано разделение на архитектурный и пользовательский лог.
Глобальные данные в сеансе Oracle
В среде PL/SQL структуры данных пакета функционируют как глобальные. Однако следует помнить, что они доступны только в пределах одного сеанса или подключения к базе данных Oracle и не могут совместно использоваться несколькими сеансами. Если доступ к данным нужно обеспечить для нескольких сеансов Oracle, используйте пакет DBMS_PIPE (его описание имеется в документации Oracle Built-In Packages).
Будьте осторожны с предположением о том, что разные части приложения всегда работают с Oracle через одно подключение. В некоторых случаях среда, из которой выполняется компонент приложения, устанавливает для него новое подключение. При этом данные пакета, записанные первым подключением, будут недоступны для второго.
Допустим, приложение Oracle Forms сохранило значение в пакетной структуре данных. Когда форма вызывает хранимую процедуру, эта процедура может обращаться к тем же пакетным переменным и значениям, что и форма, потому что они используют одно подключение к базе данных. Но допустим, форма генерирует отчет с использованием Oracle Reports. По умолчанию Oracle Reports создает для отчета отдельное подключение к базе данных с тем же именем пользователя и паролем. Даже если отчет обратится к тому же пакету и структурам данных, что и форма, значения, хранимые в структурах данных, доступных форме и отчету, будут разными, поскольку сеанс отчета имеет свой экземпляр пакета и всех его структур.
По аналогии с двумя типами структур данных в пакетах (общедоступные и приватные) также существуют два типа глобальных данных пакетов: глобальные общедоступные данные и глобальные приватные данные. В следующих трех разделах статьи рассматриваются различные способы использования данных пакетов.
Пакетные курсоры
Одним из самых интересных типов пакетных данных является явный курсор PL/SQL. Его можно объявить в теле либо в спецификации пакета. Состояние курсора (открыт или закрыт), а также указатель на его набор данных сохраняются в течение всего сеанса. Это означает, что открыть пакетный курсор можно в одной программе, выбрать из него данные — в другой, а закрыть — в третьей. Такая гибкость курсоров предоставляет большие возможности, но в то же время она может стать источником проблем. Сначала мы рассмотрим некоторые тонкости объявления пакетных курсоров, а затем перейдем к открытию, выборке данных и закрытию таких курсоров.
Объявление пакетных курсоров
Явный курсор в спецификации пакета можно объявлять двумя способами:
- Полностью (заголовок курсора и запрос). Именно так объявляются курсоры в локальных блоках PL/SQL .
- Частично (только заголовок курсора). В этом случае запрос определяется в теле пакета, поэтому реализация курсора скрыта от использующего пакет разработчика. При использовании второго способа в объявление нужно добавить секцию RETURN , указывающую, какие данные будут возвращены при выборке из курсора. На самом деле эти данные определяются инструкцией SELECT , которая присутствует только в теле, но не в спецификации
В секции RETURN можно задать одну из следующих структур данных:
- О запись, объявленная на основе таблицы базы данных с использованием атрибута %rowtype ;
- О запись, определенная программистом.
Объявление курсора в теле пакета осуществляется так же, как в локальном блоке PL/ SQL . Следующий пример спецификации пакета демонстрирует оба подхода:
Логика программы описана в следующей таблице.
| Строки | Описание |
| 3-9 | Типичное определение явного курсора, полностью заданное в спецификации пакета |
| 11-13 | Определение курсора без запроса. Спецификация указывает, что открыв курсор и выбрав из него данные, пользователь получит одну строку из таблицы books под действием заданного фильтра |
| 15-18 | Определение нового типа записи для хранения информации об авторе |
| 20-22 | Объявление курсора, возвращающего сводную информацию о заданном авторе (всего три значения) |
Рассмотрим тело пакета и выясним, какой код необходимо написать для работы с каждым из этих курсоров:
Работа с пакетными курсорами
Теперь давайте посмотрим, как пользоваться пакетными курсорами. Прежде всего для открытия, выборки данных и закрытия вам не придется изучать новый синтаксис — нужно только задать имя пакета перед именем курсора. Например, чтобы запросить информацию о книгах по PL/SQL, можно выполнить такой блок кода:
Как видите, на основе пакетного курсора точно так же можно объявить переменную с использованием %ROWTYPE и проверить атрибуты. Ничего нового!
Однако и в этом простом фрагменте кода есть скрытый нюанс. Поскольку курсор объявлен в спецификации пакета, его область видимости не ограничивается конкретным блоком PL/SQL . Предположим, мы выполняем следующий код:
Дело в том, что блок, выполненный первым, не закрыл курсор, и по завершении его работы курсор остался открытым.
При работе с пакетными курсорами необходимо всегда соблюдать следующие правила:
- Никогда не рассчитывайте на то, что курсор закрыт (и готов к открытию).
- Никогда не рассчитывайте на то, что курсор открыт (и готов к закрытию).
- Всегда явно закрывайте курсор после завершения работы с ним. Эту логику также необходимо включить в обработчики исключений; убедитесь в том, что курсор закрывается на всех путях выхода из программы.
Если пренебречь этими правилами, то ваши приложения будут работать нестабильно, а в процессе их функционирования могут появиться неожиданные необработанные исключения. Поэтому лучше написать процедуры, которые открывают и закрывают курсоры и учитывают все возможные их состояния. Этот подход реализован в следующем пакете:
Как видите, вместе с курсором объявлены две сопутствующие процедуры для его открытия и закрытия. Если нам, скажем, потребуется перебрать в цикле строки курсора, это можно сделать так:
В этом фрагменте не используются явные вызовы OPEN и CLOSE . Вместо них вызываются соответствующие процедуры, скрывающие особенности работы с пакетными курсорами.
Можно взглянуть на ситуацию под другим углом:
. Вместо того чтобы работать с пакетными курсорами, можно добиться точно такого же эффекта посредством инкапсуляции логики и данных в представлениях и опубликовать их для разработчиков. В этом случае разработчики будут нести ответственность за сопровождение своих курсоров; дело в том, что обеспечить нормальное сопровождение с инструментарием, существующим для общедоступных пакетных курсоров, невозможно. А именно, насколько мне известно, невозможно гарантировать использование процедур открытия/закрытия, но курсор всегда будет оставаться видимым для разработчика, который открывает/закрывает его напрямую; следовательно, такая конструкция остается уязвимой. Проблема усугубляется тем, что использование общедоступных пакетных курсоров и процедур открытия/ закрытия может породить в группе ложное чувство безопасности и защищенности».
Пакетное создание курсоров и предоставление доступа к ним всем разработчикам, участвующим в проекте, приносит большую пользу. Проектирование оптимальных структур данных приложения — непростая и кропотливая работа. Эти структуры — и хранящиеся в них данные — используются в программах PL/SQL, а работа с ними почти всегда осуществляется через курсоры. Если вы не определите свои курсоры в пакетах и не предоставите их «в готовом виде» всем разработчикам, то каждый будет писать собственную реализацию курсора, а это создаст массу проблем с производительностью и сопровождением кода. Пакетные курсоры являются лишь одним из примеров инкапсуляции доступа к структурам данных.
Заключение
В заключении наверное скажу банальную вещь, о том что ваша БД является сложным механизмом ежесекундно выполняющая рутинные операции. Прямо сейчас в БД могут происходить различные ошибки. Критичные, которые вы исправляете практически сразу или некритичные, о которых вы можете вообще не знать. И если у вас нет информации о подобных ошибках, то возникает вопрос: "Нужно ли их вообще исправлять? Или можно подождать до тех пор, пока проблема не всплывёт?". Вопрос наверное "риторический".
Я же данной статьёй хотел показать один из способов ведения логирования с кодированием отдельных событий. Данный метод требует некоторых "обязательств" от разработчика и в нынешнее время этого тяжело добиться. В следующей статье постараюсь показать один из способов мониторинга ошибок основанный напрямую по кодам ошибок созданных в текущей статье.
Глобальные общедоступные данные
Любая структура данных, объявленная в спецификации пакета, является глобальной общедоступной структурой данных; это означает, что к ней может обратиться любая
программа за пределами пакета. Например, вы можете определить коллекцию PL/ SQL в спецификации пакета и использовать ее для ведения списка работников, заслуживших повышение. Вы также можете создать пакет с константами, которые должны использоваться во всех программах. Другие разработчики будут ссылаться на пакетные константы вместо использования фиксированных значений в программах. Глобальные общедоступные структуры данных также могут изменяться, если только они не были объявлены с ключевым словом CONSTANT .
Глобальные данные обычно считаются источником повышенной опасности в программировании. Их очень удобно объявлять, они прекрасно подходят для того, чтобы вся информация была доступна в любой момент времени — однако зависимость от глобальных структур данных приводит к созданию неструктурированного кода с множеством побочных эффектов.
Вспомните, что спецификация модуля должна сообщать полную информацию, необходимую для вызова и использования этого модуля. Однако по спецификации пакета невозможно определить, выполняет ли пакет чтение и/или запись в глобальные структуры данных. По этой причине вы не можете быть уверены в том, что происходит в приложении и какая программа изменяет те или иные данные.
Передачу данных модулям и из них всегда рекомендуется осуществлять через параметры. В этом случае зависимость от структур данных документируется в спецификации и может учитываться разработчиками. С другой стороны, именованные глобальные структуры данных должны создаваться для информации, действительно глобальной по отношению к приложению — например, констант и параметров конфигурации.
Такие данные следует разместить в централизованном пакете. Однако учтите, что при такой архитектуре в приложении возникает «единая точка перекомпиляции»: каждый раз, когда вы вносите изменение в пакет и перекомпилируете спецификацию, многие программы приложения теряют работоспособность.
Введение
Модель логирования позволяет реализовать:
Единый подход в обработке и хранении событий
Собственную нумерацию и идентификацию событий происходящих в БД (статья)
Единый мониторинг событий (статья в разработке)
Анализ событий происходящих в БД (статья в разработке)
Описанные выше характеристики указаны в порядке нумерации и каждый следующий пункт (шаг) есть улучшение и усложнение существующей модели. Описание этой модели будет сложно выполнить в рамках одной статьи, поэтому опишем их последовательно. Начнём с первого пункта.
Единый подход в обработке и хранении событий
Основной идеей "Единого подхода в обработке и хранении событий" заключается в создании одного одновременно простого и в тоже время очень сложного правила: "Все объекты базы данных (функции, процедуры) в обязательном порядке должны завершаться блоком обработки исключений с последующим логированием события". Простота заключается в том, что легко, в команде разработчиков, на словах договориться об исполнении данного правила. Сложность же заключается в том, что данное правило должно быть установлено на ранних этапах создания вашей БД и выполняться обязательно на протяжении всего жизненного цикла. Внедрить функционал логирования в уже существующие и действующие БД очень сложно (практически не возможно).
Все объекты базы данных (функции, процедуры) в обязательном порядке должны завершаться блоком обработки исключений с последующим логированием события. Для этого можно использовать шаблон процедуры (функции) описанный во второй статье.
Наверное сейчас кто-то из читателей может возразить: "Зачем в обязательном порядке?". А всё очень просто, если вы разработчик PL/SQL и вы не согласны с этим правилом, то вот вам пример. Посмотрите на свой текущий проект более внимательно. Скорее всего вы найдете какое-нибудь логирование событий реализованное кем-то, когда-то. Вспомните сколько раз вы обращались к этому логированию при решении багов. Именно в таких ситуациях, когда есть срочность по времени в исправлении бага, вы или ваши коллеги начинают использовать dbms_output.put_line в качестве экспресс-дебага (быстрый способ получения значений переменных используемых в коде). Согласитесь, что для исправления бага мало знать в какой процедуре, в каком запросе и на какой строке возникла ошибка, необходимо знать параметры запроса на которых возникает ошибка. И вот тут нам на помощь приходит "Логирование событий", потому что помимо места возникновения ошибки мы узнаем параметры вызова процедуры, в которой возникает ошибка и это очень упрощает исправление бага.
Первая статья посвящена базовому функционалу «Логирования событий». В простейшей реализации это одна общая таблица и пакет процедур для работы с ней. Для создания и демонстрации логирования, нам необходимо реализовать следующие объекты БД (весь список объектов с их исходными кодами представлен в Git):
Таблица messagelog - единая таблица логов. Именно в данной таблице будет храниться информация о дате и времени события, об объекте где происходит событие, типе события с указанием кода, текста и параметров. В нашем примере, столбец backtrace вынесен в отдельную таблицу messagelog_backtrace для удобства.
Примечание. Представленное ниже описание таблицы является демонстрационным с минимальным набором столбцов для создания простейшего функционала логирования. Наличие дополнительных столбцов и их тип данных может меняться в зависимости от целей и задач логирования.
Также, учитывайте пожалуйста, что создание партиции требует как минимум Oracle EE. Создание партиции вне указанной версии Oracle приведет к нарушению лицензионного соглашения.

Данные пакета PL/SQL состоят из переменных и констант, определенных на уровне пакета, а не в конкретной его функции или процедуре. Их областью видимости является не отдельная программа, а весь пакет. Структуры данных пакета существуют (и сохраняют свои значения) на протяжении всего сеанса, а не только во время выполнения программы. Если данные пакета объявлены в его теле, они сохраняются в течение сеанса, но доступны только элементам пакета (то есть являются приватными).
Если данные пакета объявлены в его спецификации, они также сохраняются в течение всего сеанса, но их чтение и изменение разрешено любой пользовательской программе, обладающей привилегией EXECUTE для пакета. Общие данные пакета похожи на глобальные переменные Oracle Forms (а их использование сопряжено с таким же риском).
Если пакетная процедура открывает курсор, он остается открытым и доступным в ходе всего сеанса. Нет необходимости объявлять курсор в каждой программе. Один модуль может его открыть, а другой — выполнить выборку данных. Переменные пакета могут использоваться для передачи данных между транзакциями, поскольку они привязаны не к транзакции, а к сеансу.
Повторно инициализируемые пакеты
По умолчанию пакетные данные сохраняются в течение всего сеанса (или до перекомпиляции пакета). Это исключительно удобное свойство пакетов, но и у него имеются определенные недостатки:
- Постоянство глобально доступных (общих и приватных) структур данных сопровождается нежелательными побочными эффектами. В частности, можно случайно оставить пакетный курсор открытым, а в другой программе попытаться открыть его без предварительной проверки, что приведет к ошибке.
- Если данные хранятся в структурах уровня пакетов, то программа может занять слишком большой объем памяти, не освобождая ее.
Для оптимизации использования памяти при работе с пакетами можно использовать директиву SERIALLY_REUSABLE . Она указывает Oracle, что пакет является повторно инициализируемым, то есть его состояние (состояние переменных, открытых пакетных курсоров и т. п.) нужно сохранять не на протяжении сеанса, а на время одного вызова пакетной программы.
Рассмотрим действие этой директивы на примере пакета book_info . В нем имеются две отдельные программы: для заполнения списка книг и для вывода этого списка.
Как видно из приведенного ниже тела пакета, список объявляется как приватный глобальный ассоциативный массив:
Чтобы увидеть, как работает эта директива, заполним список и выведем его на экран. В первом варианте оба шага выполняются в одном блоке:
Заполнение и вывод в одном блоке:
Во второй версии заполнение и вывод списка производятся в разных блоках. В результате коллекция окажется пустой:
Заполнение в первом блоке
Вывод во втором блоке:
Работая с повторно инициализируемыми пакетами, необходимо учитывать некоторые особенности:
Убедительная просьба, рассматривать данный текст только как продолжение к статье о "Событийной модели логирования". Эта статья будет полезна тем, у кого уже реализовано логирование событий в БД и кто хотел бы осуществлять сбор статистики и начать проводить аналитику этих событий. Только представьте, что ваша БД сможет информировать вас о критичных сбоях системы, накапливать информацию о событиях в БД (кол-во повторений, период повторений и т.д.). И всё это без использования стороннего ПО силами одного PL/SQL.
Читайте также: