
Oracle кто изменил объект
При разработке баз данных зачастую требуется обеспечить поддержку версионности и хранения истории объектов. Например, у работника может изменяться должность, у должности в свою очередь может меняться оклад — в многомерном моделировании это называется Slowly changing dimensions(далее SCD) — редко изменяющиеся измерения, то есть измерения, не ключевые атрибуты которых имеют тенденцию со временем изменяться. Всего существует 6 основных типов(методов) SCD , которые определяют как история изменений может быть отражена в модели.
Тип 0
Заключается в том, что данные после первого попадания в таблицу далее никогда не изменяются. Этот метод практически никем не используется, т.к. он не поддерживает версионности. Он нужен лишь как нулевая точка отсчета для методологии SCD.
Для чего это нужно?
Для начала давайте рассмотрим пример. Вы реализовали логирование ошибок в вашей БД. С течением времени в ваш лог «прилетают» самые разнообразные ошибки. Предположим, имеются две ошибки вида «no_data_found» возникшие в двух разных процедурах при двух разных запросах (select). Первая ошибка возникла при попытке найти «email» клиента, что в принципе не является критичной ошибкой. Вторая ошибка возникла при попытке найти номер лицевого счета клиента, что вполне может являться критичной ошибкой. При этом если мы посмотрим в таблицу лога (из статьи), то увидим, что указанные ошибки будут храниться с одинаковым кодом 1403 (ORA-01403) в столбце msgcode. Более того, текст указанных ошибок будет практически аналогичным (текст полученный с помощью функции SQLERRM) за исключением имен объектов, на которых произошла ошибка. Для того чтобы понять является ли критичной конкретная ошибка, разработчику необходимо вникать в текст ошибки, смотреть в каком объекте возникла ошибка и на основе этой информации сделать вывод о срочности исправления. При этом, если мы сможем задать более четкое описание ошибки отличное от текста Oracle (SQLERRM), то это позволит упростить понимание причин возникновения и способов решения ошибки.
Как должно быть (в идеале)
Не найдена запись в таблице содержащей адреса электронной почты клиентов
ORA-01403: данные не найдены
USR0001: Не найден адрес электронной почты клиента (идентификатор клиента)
Не найдена запись в таблице содержащей лицевые счета клиентов
ORA-01403: данные не найдены
USR0002: Не найден лицевой счет клиента (идентификатор клиента)
Из этого примера видно, что одна и та же ошибка «no_data_found» (ORA-01403: данные не найдены) может иметь совершенно разное значение с точки зрения бизнес логики, а значит нам необходимо разработать механизм, который позволит идентифицировать каждое событие происходящее в БД как отдельное событие с нашим внутренним уникальным кодом и текстом события (отличную от Oracle). Таким образом мы решаем две проблемы:
1) В месте возникновения ошибки мы устанавливаем уникальный код ошибки. В будущем это позволяет достаточно быстро найти место возникновения ошибки. Также, наличие уникальных кодов позволяет нам произвести точечный подсчет повторений и на основании этой информации принять решение об устранении данной ошибки.
2) Дополнительный "читаемый" текст позволяет сильно упростить понимание ошибки. В таблице выше показано, как одна и та же ошибка может запутать или разъяснить пользователю сведения об ошибке.
Надеюсь мне удалось объяснить зачем необходимо кодировать события в таблице логов. Далее по тексту, будут введены термины «Архитектурный лог» и «Пользовательский лог». На примере процедуры поиска активного номера телефона клиента будет показано как и зачем создано разделение на архитектурный и пользовательский лог.
Ответы 4
LAST_DDL_TIME - это последний раз, когда он был скомпилирован. TIMESTAMP - это последний раз, когда он был изменен.
Может потребоваться перекомпиляция процедур, даже если они не изменились при изменении зависимости.
я не могу найти user_objects. Ошибка при выполнении этого запроса
@Harie - это потому, что этот вопрос касается Oracle, а не SQL Server.
Соответствует ли описание LAST_DDL_TIME и TIMESTAMP ? Я только что перекомпилировал тело пакета (оно было недействительным): alter package foo compile body reuse settings; и оба столбца были обновлены. Другое отличие состоит в том, что я запрашиваю DBA_OBJECTS (но это не имеет значения?).
@ user272735 На какой у вас версии Oracle? Я думаю, что они улучшили некоторые вещи, связанные с зависимостями, в 11, которые могли бы это изменить.
@ user272735 В таком случае, похоже, я ошибаюсь. Возможно, вам стоит опубликовать ответ с выводом сценария, показывающим это.
можно ли также узнать, с какой машины он был скомпилирован?
Следующий запрос будет выполняться в Oracle
@Thilakan - Если вы собираетесь запросить ALL_OBJECTS , вы должны включить предикат в OWNER , иначе вы можете получить несколько строк в дополнение к предикату OBJECT_TYPE из ответа WW пару лет назад. Вы, вероятно, также должны отметить, что ALL_OBJECTS содержит все объекты, которые текущий пользователь имеет привилегии, не для всех объектов в базе данных, которые будут в DBA_OBJECTS .
Убедительная просьба, рассматривать данный текст только как продолжение к статье о "Событийной модели логирования". Эта статья будет полезна тем, у кого уже реализовано логирование событий в БД и кто хотел бы осуществлять сбор статистики и начать проводить аналитику этих событий. Только представьте, что ваша БД сможет информировать вас о критичных сбоях системы, накапливать информацию о событиях в БД (кол-во повторений, период повторений и т.д.). И всё это без использования стороннего ПО силами одного PL/SQL.
Тип 4
История изменений содержится в отдельной таблице: основная таблица всегда перезаписывается текущими данными с перенесением старых данных в другую таблицу. Обычно этот тип используют для аудита изменений или создания архивных таблиц(как я уже говорил, в Oracle этот же 4-й тип можно получить из 1-го используя flashback archive). Подтипом или гибридом этого варианта(со вторым типом), как мне кажется, следует считать секционирование по признаку текущей версии с разрешенным перемещением строк, но это уже за гранью моделирования и скорее относится к администрированию.
| ID | NAME | POSITION_ID | DEPT |
|---|---|---|---|
| 1 | Коля | 21 | 2 |
| 2 | Денис | 23 | 3 |
| 3 | Борис | 26 | 2 |
| 4 | Шелдон | 22 | 3 |
| 5 | Пенни | 25 | 2 |
| ID | NAME | POSITION_ID | DEPT | DATE |
|---|---|---|---|---|
| 1 | Коля | 21 | 1 | 11.08.2010 14:12:13 |
| 2 | Денис | 23 | 2 | 11.08.2010 14:12:13 |
| 3 | Борис | 26 | 1 | 11.08.2010 14:12:13 |
| 4 | Шелдон | 22 | 2 | 11.08.2010 14:12:13 |
Достоинства:
Недостатки:
- Разделение единой сущности на разные таблицы
Введение
Модель логирования позволяет реализовать:
Единый подход в обработке и хранении событий (статья)
Собственную нумерацию и идентификацию событий происходящих в БД
Единый мониторинг событий (статья в разработке)
Анализ событий происходящих в БД (статья в разработке)
Описанные выше характеристики указаны в порядке нумерации и каждый следующий пункт (шаг) есть улучшение и усложнение существующей модели. Описание этой модели будет сложно выполнить в рамках одной статьи, поэтому опишем их последовательно. В этой (второй) статье создадим собственную нумерацию кодов для событий, а также создадим функционал идентификации событий происходящих в БД.
Архитектурное логирование событий
Давайте рассмотрим пример, имеется процедура поиска активного номера телефона принадлежащего конкретному клиенту (для примера его Предположим, что при постановке задачи для разработчика не было описания каких-либо особых условий т.е. по условиям задачи предполагалось, что для конкретного пользователя (id = 43, идентификатор передается в качестве параметра) в таблице client_telnumbers всегда будет хотя бы одна запись с номером телефона клиента и признаком «активный» (значение поля enddate равно дате 31.12.5999 23:59:59, что означает что номер используется клиентом. В случае, любой другой даты в указанном поле означает, что номер перестал быть активным и более не используется), поэтому наша процедура будет выглядеть примерно так:
Исходный код демонстрационной процедуры
Важно! Представленный код является примерным (примитивным) и служит только для демонстрации логирования в рамках данной статьи. В своих статьях я не выкладываю текст кода из реально действующих БД. Надеюсь, вы понимаете, что в реальности указанная процедура написана гораздо сложнее.
*Исходный код других используемых объектов смотрите в Git
Если мы будем использовать логирование ошибок как показано в предыдущей статье, то с течением времени обнаружим, что идентифицировать ошибки из данной процедуры будет сложно. Поэтому для всех ошибок попадающих в обработку исключения «WHEN OTHERS» реализована процедура pkg_msglog.p_log_archerr, которая при первом возникновении ошибки автоматически присваивает ей уникальный код и сохраняет ошибку в таблице лога. В дальнейшем, при повторении данной ошибки процедура найдет ранее созданный код и использует его при логировании в таблице лога.
В итоге, после добавления блока «архитектурного» логирования (строки с 18 по 24), наша процедура будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
На этапе написания текста процедуры разработчик не всегда может предугадать возникновение той или иной ошибки (если честно, не всегда есть на это время), поэтому на начальном этапе ему достаточно «отлавливать» абсолютно все ошибки возникающие в данной процедуре с помощью оператора «WHEN OTHERS». Таким образом мы можем ввести новый термин (в рамках данного цикла статей), «Архитектурные логирование» - это логирование всех ошибок, возникновение которых не предполагается при штатной работе алгоритма. Для функционала «Архитектурных ошибок» были созданы объекты: отдельный справочник ошибок messagecodes_arch и процедура pkg_msglog.p_log_archerr создания записи в таблице лога для указанного типа ошибок.
Исходный код таблицы
Ограничение в таблице на комбинацию (Имя объекта, код ошибки SQLCODE). При первом появлении ошибки создается запись в таблице и генерируется код ошибки "SYS0000" + счетчик ошибок. При повторном появлении указанной ошибки будет взят уже сгенерированный ранее код ошибки.

рис. Пример содержимого таблицы messagecodes_arch
*Исходный код других используемых объектов смотрите в Git
Обратите внимание, что при использовании описанной модели «архитектурного» логирования у вас появляется функционал позволяющий максимально быстро реагировать на первое появление ошибки (в конкретной функции/процедуре). Для этого необходимо реализовать отдельный мониторинг архитектурных ошибок, который постараюсь продемонстрировать в следующей (третьей) статье. Использование процедуры pkg_msglog.p_log_archerr не требует каких-либо действий кроме описания входных параметров.
Таким образом мы можем создать базовый шаблон процедуры (функции), использование которого позволит вам гарантированно отлавливать все архитектурные ошибки в вашем коде.
Шаблон процедуры/функции с архитектурным логированием
Рекомендую использовать данный шаблон для построения "Событийной модели логирования".
*Исходный код других используемых объектов смотрите в Git
В рамках событийной модели логирования, предполагается, что все архитектурные ошибки будут исправляться отдельной задачей т.е. основная цель это устранить повторное появление ошибок с кодом "SYS****" в таблице лога. В указанной задаче вам необходимо либо устранить причины возникновения данной ошибки, либо добавить отдельную обработку ошибки отличную от «when others», которую в дальнейшем будем назвать «пользовательское» логирование (в рамках данного цикла статей).
Тип 0
Заключается в том, что данные после первого попадания в таблицу далее никогда не изменяются. Этот метод практически никем не используется, т.к. он не поддерживает версионности. Он нужен лишь как нулевая точка отсчета для методологии SCD.
Пользовательское логирование событий
Предположим, что однажды в нашей процедуре get_telnumber произошла «архитектурная ошибка». В частности, для конкретного пользователя в таблице client_telnumbers хранится два номера телефона с признаком «активный». В таком случае, процедура «упадёт» с ошибкой «ORA-01422: too_many_rows». При этом, наш функционал архитектурного логирования сгенерировал новый код ошибки «SYS0061» и создал запись в таблице лога.
![]()
рис. Код архитектурной ошибки SYS0061
Самое важно в такой ситуации это не откладывать «на потом» исправление архитектурных ошибок. В идеале, необходимо создать отдельную задачу (баг) и в рамках неё устранить ошибку.
Предположим ,что была создана отдельная задача для устранения ошибки и назначена разработчику. В рамках этой задачи, разработчик совместно с технологом, аналитиком и др. коллегами пришел к выводу, что указанная ошибка носит систематический характер, является некорректной работой системы и требует исправления. В качестве мер исправления было решено добавить обработку события «too_many_rows» с последующим логированием события в таблице лога и выводом текста ошибки для пользователя.
Для этого в процедуре get_telnumber добавлено исключение (exception) «too_many_rows» пользовательского логирования. Также, был создан справочник пользовательских ошибок отличный от архитектурного справочника, тем что в него все записи добавляются разработчиком "вручную". Наверное это самое слабое место во всей архитектуре логирования. Предполагается, что разработчик должен описать исключение (exception) и создать для него уникальный код ошибки. Также, желательно к указанной ошибке сформулировать читаемый текст ошибки (для своих коллег, пользователя, техподдержки и т.д.), что бывает иногда очень сложным (из личного опыта).
Таблица пользовательских ошибок и процедура их "регистрации" будет выглядеть следующим образом:
Исходный код таблицы пользовательских ошибок и процедуры регистрации
Обратите внимание, что текст ошибок имеет параметризацию т.е. для ошибки в тексте имеются специальные символы $1, $2, $3 и т.д. Например, рассмотрим ошибку "USR0003" с текстом "Для клиента найдено два и более активных номеров телефона!" при вызове функции f_get_errcode на вход подаётся код ошибки и параметры ошибки. Далее, функция по коду ошибки найдет строку, в тексте ошибки заменит подстроку "$1" на значение параметра to_char(p_userid) т.е. подставит значение to_char(p_userid).
В случае если в тексте ошибки будут два и более спецсимвола $1, $2, $3 и т.д., то параметры передаются с использованием символа-разделителя ";".
Итого, содержимое справочника пользовательских ошибок будет выглядеть следующим образом:

рис. Пример содержимого справочника пользовательских ошибок
*Исходный код других используемых объектов смотрите в Git
После того, как мы "зарегистрировали" пользовательскую ошибку "USR0003" и добавив отдельную обработку пользовательского логирования (строки с 19 по 28), наша процедура get_telnumber будет выглядеть следующим образом:
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
При повторном возникновении ошибки «too_many_rows» обработка события пройдет по нашему сценарию «пользовательского» логирования. Таким образом мы можем ввести второй термин (в рамках данного цикла статей), «Пользовательские логирование» - это логирование всех ошибок, возникновение которых предполагается и ожидается при нештатной работе алгоритма. В итоге, пользователь получит читаемый текст ошибки с кодом «USR0003», также, мы же всегда сможем подсчитать количество ошибок с указанным кодом. В случае большого количества ошибок у нас на руках будет «живая» статистика частоты возникновения ошибки и их количества, что позволит нам выйти на руководство с предложением по доработке/оптимизации процесса.
Давайте рассмотрим еще один пример (кейс из реального случая), в момент когда процедура get_telnumber по id клиента находит один "активный" номер телефона иногда возникает ситуация, что номер телефона не принадлежит мобильному оператору. Ситуации бывают разные иногда указанный номер мог быть номером городской телефонной сети, иногда номером международного оператора, а иногда вообще набор из нескольких цифр и т.д. Основным требованием от бизнес-заказчика было использование номера телефона российских операторов мобильной связи. Поэтому было решено добавить проверку соответствия найденного номера некому "корректному" шаблону (строки с 18 по 29). В случае обнаружения некорректного номера, логировать данное событие отдельным кодом "USR0004" и типом "WRN". Добавим функцию проверки корректности номера телефона, если номер соответствует шаблону (требованиям), то вернем номер телефона, иначе пустое значение.
Исходный код демонстрационной процедуры
*Исходный код других используемых объектов смотрите в Git
После сбора статистических данных по конкретной ошибке с кодом "USR0004", руководству стало понятно, что ошибка актуальна и количество ошибок с течением времени не только не уменьшается, а наоборот растет с линейной прогрессией. В дальнейшем, были выявлены источники "кривых" данных и были установлены внутренние требования по первичной обработке номера телефона клиентов. В итоге, со временем количество ошибок уменьшилось до нуля. И этого нельзя было добиться до тех пор, пока у всех участвующих лиц не возникло понимание о масштабе проблемы.
Исходный код запроса
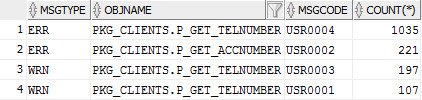
рис. Пример результата запроса с группировкой
*Исходный код других используемых объектов смотрите в Git
Тип 3
В самой записи содержатся дополнительные поля для предыдущих значений атрибута. При получении новых данных, старые данные перезаписываются текущими значениями.
| ID | UPDATE_TIME | LAST_STATE | CURRENT_STATE | |
|---|---|---|---|---|
| 1 | 1 | 11.08.2010 12:58:48 | 0 | 1 |
| 2 | 2 | 11.08.2010 12:29:16 | 1 | 1 |
Достоинства:
- Небольшой объем данных
- Простой и быстрый доступ к истории
Недостатки:
Тип 2
Данный метод заключается в создании для каждой версии отдельной записи в таблице с добавлением поля-ключевого атрибута данной версии, например: номер версии, дата изменения или дата начала и конца периода существования версии.
Пример:
| ID | NAME | POSITION_ID | DEPT | DATE_START | DATE_END |
|---|---|---|---|---|---|
| 1 | Коля | 21 | 2 | 11.08.2010 10:42:25 | 01.01.9999 |
| 2 | Денис | 23 | 3 | 11.08.2010 10:42:25 | 01.01.9999 |
| 3 | Борис | 26 | 2 | 11.08.2010 10:42:25 | 01.01.9999 |
| 4 | Шелдон | 22 | 3 | 11.08.2010 10:42:25 | 01.01.9999 |
| 5 | Пенни | 25 | 2 | 11.08.2010 10:42:25 | 01.01.9999 |
В этом примере в качестве даты конца версии по умолчанию стоит '01.01.9999', вместо которой можно было бы указать, скажем, null, но тогда возникла бы проблема с созданием первичного ключа из ID,DATE_START и DATE_END, и, кроме того, так упрощается условие выборки для определенной даты(" where snapshot_date between DATE_START and DATE_END " вместо " where snapshot_date>DATE_START and (snapshot_date < DATE_END or DATE_END is null) ".
При такой реализации при увольнении сотрудника можно будет просто изменить дату конца текущей версии на дату увольнения вместо удаления записей о работнике.
Достоинства:
- Хранит полную и неограниченную историю версий
- Удобный и простой доступ к данным необходимого периода
Недостатки:
- Провоцирует на избыточность или заведение дополнительных таблиц для хранения изменяемых атрибутов измерения
- Усложняет структуру или добавляет избыточность в случаях, если для аналитики потребуется согласование данных в таблице фактов с конкретными версиями измерения и при этом факт может быть не согласован с текущей для данного факта версией измерения.(Например, у клиента изменились ревизиты или адрес, а нужно провести операцию/доставку по старым значениям)
Гибридный тип/Тип 6(1+2+3)
Тип 6 был придуман Ральфом Кимболлом(Ralph Kimball) как комбинация вышеназванных методов и предназначен для ситуаций, которые они не учитывают или для большего удобства работы с данными. Он заключается во внесении дополнительной избыточности: берется за основу тип 2, добавляется суррогатный атрибут для альтернативного обзора версий(тип 3), и перезаписываются одна или все предыдущие версии(тип 1).
Пример:
| VERSION | ID | NAME | POSITION_ID | DEPT | DATE_START | DATE_END | CURRENT |
|---|---|---|---|---|---|---|---|
| 1 | 1 | Коля | 21 | 2 | 11.08.2010 10:42:25 | 01.01.9999 | 1 |
| 1 | 2 | Денис | 23 | 3 | 11.08.2010 10:42:25 | 01.01.9999 | 1 |
| 1 | 3 | Борис | 26 | 2 | 11.08.2010 10:42:25 | 11.08.2010 11:42:25 | 0 |
| 2 | 3 | Борис | 26 | 2 | 11.08.2010 11:42:26 | 01.01.9999 | 1 |
В данном примере, например, добавление суррогатного ключа добавляет возможность ссылаться из таблиц фактов на конкретную версию измерения, которая может не принадлежать времени существования самого факта, а индикатор текущей версии может помочь секционировать по текущим версиям(хотя правильнее было бы назвать секционированием по последней версии, т.к. версия может устареть без изменения самой записи). Впрочем индикатор текущей версии можно создать и как виртуальное вычислимое поле, не ухудшая нормализации, если это необходимо именно в таблице(если СУБД поддерживает такие поля, в Oracle они появились в 11-й версии), и как поле в представлении из этой таблицы.
В целом же любая комбинация основных типов SCD относится к гибридному типу, поэтому как их недостатки так и достоинства зависят от конкретной Вашей реализации, но безусловно одно — выбор гибридного типа может быть обусловлен только сложностью Вашей модели и практически всегда(во всяком случае я не знаю случаев, когда может быть иначе) можно обойтись основными 4-мя типами.
- Старайтесь реализовывать механизм изменения записей в хранимых процедурах — категорически нежелательно, чтобы код изменений был разбросан по разным местам, даже если код изменений у вас хранится в четко определенных местах Вашего внешнего приложения;
- Если Вы хотите произвести плавный переход от 1-й модели ко второй, Вы можете поступить так:
1) изменить таблицу по типу 2 SCD с переименованием, допустим, в table_name_scd2
2) создать обновляемое представление с названием старой таблицы, которая будет выдавать данные в той же структуре что и старая таблица;
3) если Вы не все изменения проводите в хранимых процедурах(надеюсь, это временно :) ), которые уже изменили, то создать триггеры, которые будут заполнять новые поля в случаях, если они не устанавливаются запросом(when :new.start_date is null. ) и логгировать это, чтобы затем удостовериться, что Вы все изменили - В случаях использования полей начала и конца версии, помимо использования первичного ключа, включающего в себя идентификатор объекта и даты начала и конца версии, Вам нужно будет для контроля целостности — создать ограничение на непересечение дат версий. Очень хорошо, если Ваша СУБД поддерживает check constraints основанные на недетерминированных функциях, позволяющие сделать это(хотелось бы, кстати, узнать какие СУБД это поддерживают), но если это не так, то Вы можете проверять условие в триггере перед созданием или изменением и вызывать исключение, в случае нарушения. Пример для Oracle:
PS. Хабралюди, поделитесь, какие интересные гибридные реализации Вы встречали?
Научитесь использовать средства детального аудита в сервере Oracle Database для того, чтобы отслеживать доступ к конкретным строкам таблиц в режиме "только для чтения" и в других целях.
Традиционные опции аудита в сервере Oracle Database позволяют вам отслеживать на макроуровне действия, выполняемые пользователями над объектами – например, если вы выполняете аудит операторов SELECT, выбирающих данные из таблицы, вы можете следить, кто выбирает данные из таблицы. Однако вы не сможете узнать, что они выбирают. Для операторов манипулирования данными, таких, как INSERT, UPDATE или DELETE, вы можете собирать данные о любых изменениях, используя триггеры или утилиту Oracle LogMiner – анализатор архивных журнальных файлов. Поскольку операторы SELECT не манипулируют данными, они не инициируют запуск триггеров и данные об их выполнении не поступают в архивные журнальные файлы, которые вы могли бы анализировать, так что эти два способа не оправдывают ожиданий, когда дело касается операторов SELECT.
В сервере Oracle9i Database введена новая возможность, названная детальным аудитом (FGA, fine-grained auditing), которая изменила все изложенное выше. Эта возможность позволяет вам выполнять аудит отдельных операторов SELECT. В дополнение к простому отслеживанию выполнения операторов FGA обеспечивает способ моделирования триггеров для операторов SELECT, выполняя некоторый код всякий раз, когда пользователь выбирает определенный набор данных. В этой серии статей (в трех частях) я объясню, как вы можете использовать FGA для того, чтобы решать реальные проблемы. В первой части мы сосредоточимся на том, как построить основную систему FGA.
Настройка примера
Наш пример основан на банковской системе, в которой записи аудита (audit trails) пользовательского доступа к определенным данным традиционно обеспечиваются аудитом на уровне приложения. Однако система терпит неудачу всякий раз, когда пользователи обращаются к данным за пределами приложения, используя инструментальные средства типа SQL*Plus. В этой статье я объясню, как вы, администратор базы данных, с помощью FGA можете выполнить задачу сбора данных о SELECT-доступе пользователей к определенным строкам, независимо от используемого инструмента или механизма доступа.
В нашем примере в базе данных есть таблица, названная ACCOUNTS (счета) и принадлежащая схеме BANK. Таблица имеет следующую структуру:
Для построения системы, которая может выполнять аудит любой выборки из этой таблицы, вам требуется определить для этой таблицы правило аудита, правило FGA (FGA policy), следующим образом:
Этот код должен быть выполнен пользователем, который имеет привилегию выполнения пакета dbms_fga. Однако по соображениям безопасности желательно не предоставлять эту привилегию пользователю BANK, владельцу таблицы, которая подвергается аудиту; предпочтительнее предоставить ее доверенному пользователю с именем, скажем, SECMAN, который должен выполнить эту процедуру, чтобы добавить правило аудита (add_policy).
После того как вы определили правило аудита, когда пользователь обычным образом выполнит запрос к таблице:
select * from bank.accounts;
В журнале аудита (audit trail) это действие зарегистрируется. Вы можете проверить журнал аудита, введя:
Обратите внимание на новое представление с именем DBA_FGA_AUDIT_TRAIL, в которое записывается информация детального аудита. Между прочим, в представлении содержатся: отметка времени возникновения события аудита (TIMESTAMP), имя пользователя базы данных, который выполнил запрос (DB_USER), его же имя как пользователя операционной системы (OS_USER), имя владельца и название таблицы, используемой в запросе (OBJECT_SCHEMA и OBJECT_NAME) и, наконец, сам запрос. Информацию такого вида было невозможно получить до выхода сервера Oracle9i Database, но с появлением FGA эта процедура стала обычной.
FGA в сервере Oracle9i Database позволяет собирать данные только об операторах SELECT. FGA в сервере Oracle Database 10g может также обрабатывать DML-запросы – INSERT, UPDATE и DELETE, обеспечивая возможность полного аудита. В части 3 этой серии статей я подробно объясню эти функции.
Столбцы аудита и условия аудита
Рассмотрим предыдущий пример более подробно. Мы потребовали, чтобы аудит выполнялся для любого оператора SELECT, используемого для запроса к таблице. В действительности в этом, вероятно, нет необходимости, и это может "завалить" данными таблицу аудита, в которой хранится информация аудита. Банк, возможно, должен выполнять аудит тогда, когда пользователь выбирает данные из столбца BALANCE (остаток на счете), которая содержит конфиденциальную информацию, но не должен выполнять аудит тогда, когда пользователь выбирает номер счета для конкретного клиента. Столбец BALANCE, выборка из которого инициирует событие аудита, называют столбцом аудита (audit column), и в этом случае параметр процедуры dbms_fga.add_policy задает это следующим образом:
Если в журнале аудита регистрируется каждая пользовательская выборка из таблицы, размер журнала будет расти, приводя к проблемам с пространством и администрированием, так что вы можете выполнять аудит только в случае удовлетворения определенным условиям, а не каждый раз. Возможно, банк нуждается в аудите только тогда, когда пользователи обращаются к счетам чрезвычайно богатых клиентов, например тогда, когда пользователь выбирает данные из счета с балансом, равным $11,000 и больше. Такой тип условия называют условием аудита (audit condition), и оно передается как параметр процедуры dbms_fga.add_policy следующим образом:
audit_condition => 'BALANCE >= 11000'
Посмотрим, как работают эти два параметра. Определение правила аудита теперь выглядит так:
В этом случае аудит будет выполняться только тогда, когда пользователь выбирает данные из столбца BALANCE и извлеченные строки содержат баланс больший или равный $11,000. Если любое из этих условий не выполняется, действие не регистрируется в журнале аудита. Примеры в таблице 1 иллюстрируют различные сценарии: когда действия будут регистрироваться в журнале аудита и когда не будут.
Таблица 1. Различные сценарии, иллюстрирующие, выполняется или не выполняется аудит действий.
Да разве б не цвела земля афинская,
Когда бы так же рассуждали граждане
И постоянно не искали нового?
Аристофан, Женщины в народном собрании
Реферат
В версии Oracle 11.2 для некоторых видов объектов хранения была введена возможность заводить одновременно несколько «редакций» (editions). Она была придумана для совершенствования процесса внесения изменений в схему данных, позволяя в некоторых случаях отлаживать новый вариант приложения впараллель с работой текущего. Техника использования редакций объектов рассматривается в статье на примерах.
Содержание
Введение
- VIEW
- SYNONYM
- PROCEDURE
- FUNCTION
- TRIGGER
- PACKAGE/PACKAGE BODY
- TYPE/TYPE BODY
- LIBRARY.
Основное применение техники редакций объектов можно видеть в области и поддержки и развития приложения. Она позволяет выполнять часть работ по внесению изменений в существующее прикладное ПО без останова использования рабочей системы и отлаживать нововведения впараллель основной работе.
Хотя техника редакций объектов хранения не распространяется на данные в исходных таблицах БД, версии представлений иногда помогают подготовить приложение в том числе к переходу на новые структуры таблиц.
В версии Oracle 11.2 техника редакций объектов воплощена в своем начальном варианте, вероятно не окончательном.
Далее рассматривается несколько примеров создания и использования версий объектов в Oracle.
Подготовка схемы для редакций объектов
Ниже приводятся команды заведения в SQL*Plus схемы для объектов разных редакций и выполнения необходимых сопутствующих действий.
В схеме YARD появилась таблица EMP с той же структурой, что и одноименная в схеме SCOTT и с теми же данными (но без ограничений целостности).
Создание редакций для объектов и управление ими
Управление редакциями регулируется привилегиями CREATE/ALTER/DROP ANY EDITION. Слово ANY в названиях напоминает о внесхемном характере редакций, распространяющемся на уровень всей БД целиком (формально они все приписаны пользователю SYS).
Если правом создавать редакции объектов и управлять ими требуется доверить пользователю YARD, администратору БД следует продолжить:
Узнать действующую в данный момент редакцию можно из контекста сеанса USERENV (встроенного в СУБД):
ORA$BASE – это встроенная в БД умолчательно действующая редакция, на основе которой администратор может создавать последовательность редакций (а в будущих версиях Oracle возможно дерево) на свое усмотрение. Имя умолчательной для БД редакции можно выяснить запросом:
Примеры создания редакций:
В первом случае редакция APP_RELEASE_1 была создана на основе умолчательно действующей редакции ORA$BASE, во втором – как следует из текста команды.
Откомментировать редакцию в словаре-справочнике БД можно командой COMMENT:
Снять комментарий можно, указав пустую строку ''. Наблюдаются комментарии через таблицу ALL_EDITION_COMMENTS.
Узнать существующие редакции в их взаимосвязи можно запросом к особой таблице:
Удалить можно только лист из дерева (пока – ветки), свободный от подчиненных редакций:
Для того, чтобы пользователь Oracle мог не просто обращаться с редакциями объектов, но и формировать их, ему следует сообщить особое качество:
Качество ENABLE EDITIONS не изначальное и неотъемлемое; буде оно раз выдано, отменить его нельзя. В результате все пользователи Oracle оказываются разделены на две категории: тех, кому разрешено формировать редакции, и тех, кому не разрешено. При том возможен перевод пользователя из второй категории в первую, но никак не обратно. Удостовериться в наличие свойства ENABLE EDITIONS у пользователя можно по значению поля EDITIONS_ENABLED (нового в версии 11.2) в таблице DBA_USERS (владелец ее SYS, и обычным пользователям сама по себе она не видна).
После выдачи последней команды каждый объект пользователя YARD, для которого разрешено редактирование, так или иначе будет привязан к какой-нибудь редакции.
Настройка на работу с нужной редакцией
- он должен иметь привилегию на работу с редакцией, выданную лично ему или, вместо этого, псевдопользователю PUBLIC (то есть всем вообще);
- сеанс должен быть переключен на работу с этой редакцией.
Выдать пользователю личное общее разрешение на работу с объектами требуемой редакции можно примерно так:
USE – это привилегия на объекты вида EDITION, передаваемая к тому же через PUBLIC и через роли. Если редакцию, объявить в БД умолчательной, она автоматически полагается выданной для PUBLIC, то есть общедоступной, и не требует личных (или же ролевых) разрешений. По этой причине изначально частных разрешений на работу с ORA$BASE не требуется – оно есть у всех. То же самое произойдет с редакцией APP_RELEASE_1, если в какой-то момент выдать:
На последнюю команду способен обладатель привилегии ALTER DATABASE (а ею обладают SYS и SYSTEM, но пока что не YARD). Как только такая команда будет выдана, команды GRANT USE, как выше, для придания нужных полномочий пользователю SCOTT, не потребуется. Выдачей подобной команды может венчаться отладка новых редакций объектов («перевод приложения на новую редакцию»).
Когда пользователь Oracle получил разрешение (то есть привилегию) на работу с объектами конкретной редакции, он получает право в рамках отдельных сеансов настраиваться на нее:
Код выше подтверждает то, что по умолчанию при открытии сеанса действует редакция, объявленая ранее умолчательной в БД.
Пример создания и использования разных редакций представления данных (view)
К настоящему моменту в БД имеется две редакции. Будем формировать их содержание редакциями объектов в схеме YARD. Создадим в ней две несложные редакции одного и того же представления данных – с выдачей сведений об отделе сотрудника, и без:
Настройку на редакцию ORA$BASE можно было выше не выполнять, потому что эта редакция умолчательная (это проверялось ранее), и автоматически действует в начале каждого сеанса.
В результате появились две редакции представления данных EMP_VIEW:
Редактируемые представления данных (editioning views) отличаются от обычных не только формальным словом EDITIONING при создании, но и некоторыми техническими свойствами. Они могут строиться на основе единственной таблицы, без фильтрации строк фразой WHERE и с отсутствием преобразований столбцов (в то же время воспроизведение всех столбцов не обязательно). Есть и другие отличия, не востребованными в этом тексте.
Чтобы пользователь SCOTT имел доступ к данным, для каждой редакции требуется выдать отдельное разрешение:
Вот как этими разрешениями может воспользоваться SCOTT:
Теперь без отмены прежнего представления данных (которым может пользоваться текущее приложение) открылась возможность отлаживать приложение применительно к новому.
Упражнение. Отобрать у пользователя SCOTT привилегию на выборку данных из YARD.EMP_VIEW в редакции APP_RELEASE_1 и наблюдать результат попытки обращения.
Пример редакций процедур
Заведение разных редакций одной и той же процедуры в схеме со свойством EDITIONS_ENABLED = TRUE выглядит достаточно прозрачно. Так, для добавления данных о сотрудниках можно завести две редакции процедуры INSERT_EMPLOYEE следующим образом:
Откат транзакций сделан (а) чтобы сохранить прежние данные, и (б) в первом случае – чтобы закрыть транзакцию перед переключением на новую редакцию.
Пример редакций триггерных процедур
Теперь для добавления в БД данных о сотрудниках создадим две редакцмм триггерных процедур. Это делается аналогично обычным процедурам. Прикладной смысл триггерных процедур в данном случае состоит в нормализации имен сотрудников перед помещением в базу.
Обратите внимание, что для редактируемых представлений (EDITIONING VIEW) в триггерных процедурах не действует привязка к событию INSTEAD OF, как для обычных представлений, а вместо этого BEFORE и AFTER, как для основных таблиц. Это одно из проявлений особости редактируемых представлений от обычных.
Проверку можно выполнить следующей последовательностию команд в SQL*Plus:
Перекрестные триггерные процедуры для разных редакций
Когда отлаживается работа приложения с новой редакцией объектов БД, какое-то время обе редакции объектов (старая и новая) сосуществуют. Сложность в том, что работа с новой редакцией не должна портить данные, с которыми продолжает иметь дело старый вариант приложения. Если планируемые изменения в схеме однозначно взаимообратимы с исходным состоянием, помочь в этом способны перекрестные триггерные процедуры для разных редакций (межредакционные триггерные процедуры; crossedition triggers, CET).
Рассмотрим пример подготовки к изменению структуры таблицы EMP в схеме YARD. Предположим, требуется хранить в БД самостоятельно сведения о должностях, как например максимальную зарплату и тому подобное. Ради этого придется завести отдельную новую таблицу с данными о должностях, а в таблице EMP изъять столбец с названием должности сотрудника, и добавить заместо ссылку на сведения о должностях. Пока новая редакция приложения не будет объявлена основной, старый столбец придется какое-то время сохранять.
Подобное разбиение одной таблицы сотрудников на две – сотрудников и должностей – очевидно обратимо, так что на время отладки будет удобно воспользоваться межредакционными триггерными процедурами. Они будут отвечать при работе со старой редакцией за дублированное внесение изменений в новые структуры, а при работе с новой редакцией – в старые, обеспечивая в данных БД возможность предоставления «взгляда» на них как по-старому, так и по-новому.
Подготовка таблиц
Создадим таблицу должностей, добавим в таблицу сотрудников ссылку, при том что столбец с названием должности оставим до будущего перехода на новую редакцию приложения. Выполним в SQL*Plus:
Переименуем таблицу сотрудников, и отдадим ее старое имя двум редакциям представлений:
Создание перекрестных межредакционных триггерных процедур
Одна из создаваемых ниже триггерных процедур отвечает за правку данных, необходимую для работы старой редакции приложений, во время работы нового, а вторая наоборот. Существенно, что транслироваться обе перекрестные процедуры должны быть приписаны новой редакции:
Проверку способен организовать следующий код:
Как и раньше, если транзакция успела изменить какие-нибудь данные в БД, для настройки на новую редакцию ее потребуется сначала закрыть. В результате получим:
При работе со старой редакцией воспроизводится поведение старой таблицы EMP, а при работе с новой – с тою же таблицей, но в новом варианте.
Дополнительные замечания по технологии
Приведенные примеры перекрестных триггерных процедур были намерено упрощены. В жизни в них следовало бы предусмотреть реакцию на указание в качестве нового значения отсутствующей должности. Предположим, что в старом приложении подобная обработка не программировалась, то есть в БД добавлялась ровно то название должности, которае было указано в INSERT/UPDATE. Тогда для сохранения поведения старой реакции приложения следовало бы на возникающую в SELECT . INTO . FROM job ошибку NO_DATA_FOUND среагировать добавлением новой записи в таблицу JOB. Придется решить технический вопрос о поставке значений в JOBID; это может потребовать употребления генератора последовательности (sequence) и других усложнений.
При решении перейти на новую редакцию приложения перекрестные триггерные процедуры и редакционные представления данных следует удалить, а освободившееся имя EMP вернуть основной таблице:
Для этого я желательно ищу SQL-запрос, но могут быть полезны и другие варианты.
Будучи разработчиком веб-приложений, легко впасть в заблуждение, считая, что приложение без JavaScript не имеет права на жизнь. Нам становится удобно.
Если вы ищете пакет для быстрой интеграции календаря с выбором даты в ваше приложения, то библиотека Flatpickr отлично справится с этой задачей.
Клиент для URL-адресов, cURL, позволяет взаимодействовать с множеством различных серверов по множеству различных протоколов с синтаксисом URL.
У каждого из нас бывали случаи, когда нам нужно отцентрировать блочный элемент, но мы не знаем, как это сделать. Даже если мы реализуем какой-то.
Заключение
В заключении наверное скажу банальную вещь, о том что ваша БД является сложным механизмом ежесекундно выполняющая рутинные операции. Прямо сейчас в БД могут происходить различные ошибки. Критичные, которые вы исправляете практически сразу или некритичные, о которых вы можете вообще не знать. И если у вас нет информации о подобных ошибках, то возникает вопрос: "Нужно ли их вообще исправлять? Или можно подождать до тех пор, пока проблема не всплывёт?". Вопрос наверное "риторический".
Я же данной статьёй хотел показать один из способов ведения логирования с кодированием отдельных событий. Данный метод требует некоторых "обязательств" от разработчика и в нынешнее время этого тяжело добиться. В следующей статье постараюсь показать один из способов мониторинга ошибок основанный напрямую по кодам ошибок созданных в текущей статье.
Тип 1
1 тип — это обычная перезапись старых данных новыми. В чистом виде этот метод тоже не содержит версионности и используется лишь там, где история фактически не нужна. Тем не менее, в некоторых СУБД для этого типа возможно добавить ограниченную поддержку версионности средствами самой СУБД(например, Flashback query в Oracle) или отслеживанием изменений через триггеры.
Достоинства:
- Не добавляется избыточность
- Очень простая структура
Недостатки:
Читайте также: