
Oracle etl что это
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
- Как случайные ошибки, возникшие на уровне ввода, переноса данных, или из-за багов;
- Как различия в справочниках и детализации данных между смежными ИТ-системами.
- Привести все данные к единой системе значений и детализации, попутно обеспечив их качество и надежность;
- Обеспечить аудиторский след при преобразовании (Transform) данных, чтобы после преобразования можно было понять, из каких именно исходных данных и сумм собралась каждая строчка преобразованных данных.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
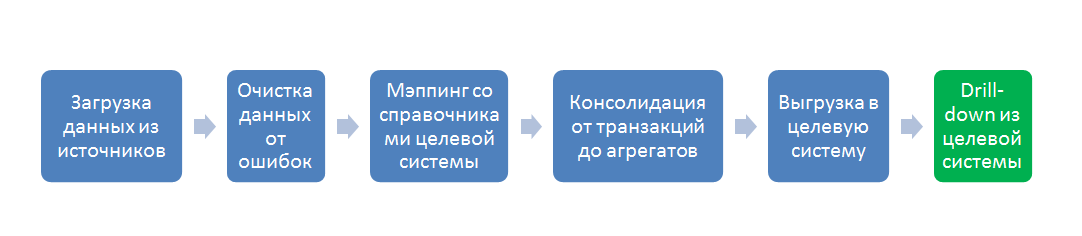
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
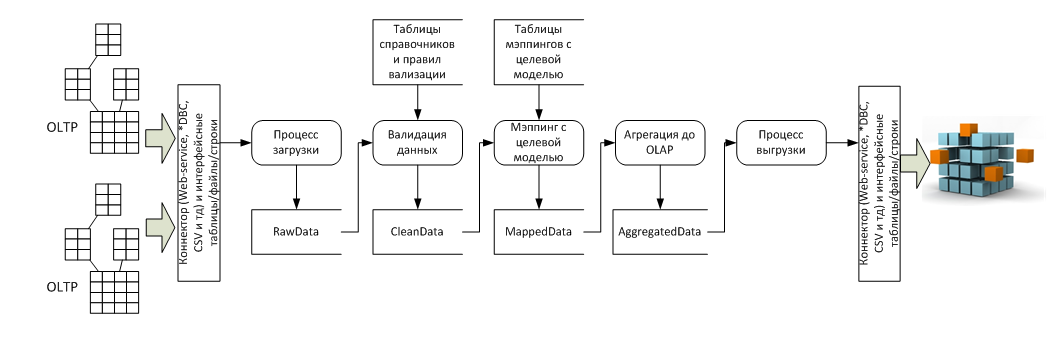
- Процесс загрузки – Его задача затянуть в ETL данные произвольного качества для дальнейшей обработки, на этом этапе важно сверить суммы пришедших строк, если в исходной системе больше строк, чем в RawData то значит — загрузка прошла с ошибкой;
- Процесс валидации данных – на этом этапе данные последовательно проверяются на корректность и полноту, составляется отчет об ошибках для исправления;
- Процесс мэппинга данных с целевой моделью – на этом этапе к валидированной таблице пристраивается еще n-столбцов по количеству справочников целевой модели данных, а потом по таблицам мэппингов в каждой пристроенной ячейке, в каждой строке проставляются значения целевых справочников. Значения могут проставляться как 1:1, так и *:1, так и 1:* и *:*, для настройки последних двух вариантов используют формулы и скрипты мэппинга, реализованные в ETL-инструменте;
- Процесс агрегации данных – этот процесс нужен из-за разности детализации данных в OLTP и OLAP системах. OLAP-системы — это, по сути, полностью денормализованная таблица фактов и окружающие ее таблицы справочников (звездочка/снежинка), максимальная детализация сумм OLAP – это количество перестановок всех элементов всех справочников. А OLTP система может содержать несколько сумм для одного и того же набора элементов справочников. Можно было-бы убивать OLTP-детализацию еще на входе в ETL, но тогда мы потеряли бы «аудиторский след». Этот след нужен для построения Drill-down отчета, который показывает — из каких строк OLTP, сформировалась сумма в ячейке OLAP-системы. Поэтому сначала делается мэппинг на детализации OLTP, а потом в отдельной таблице данные «схлопывают» для загрузки в OLAP;
- Выгрузка в целевую систему — это технический процесс использования коннектора и передачи данных в целевую систему.
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
- Надо учитывать требования бизнеса по длительности всего процесса. Например: Если данные должны быть загружены в течение недели с момента готовности в исходных системах, и происходит 40 итераций загрузки до получения нормального качества, то длительность загрузки пакета не может быть больше 1-го часа. (При этом если в среднем происходит не более 40 загрузок, то процесс загрузки не может быть больше 30 минут, потому что в половине случаев будет больше 40 итераций, ну или точнее надо считать вероятности:) ) Главное если вы не укладываетесь в свой расчет, то не надейтесь на чудо — сносите и все, делать заново т.к. вы не впишитесь;
- Данные могут загружаться набегающей волной – с последовательным обновлением данных одного и того-же периода в будущем в течение нескольких последовательных периодов. (например: обновление прогноза окончания года каждый месяц). Поэтому кроме справочника «Период», должен быть предусмотрен технический справочник «Период загрузки», который позволит изолировать процессы загрузки данных в разных периодах и не потерять историю изменения цифр;
- Данные имеют обыкновение быть перегружаемыми много раз, и хорошо если будет технический справочник «Версия» как минимум с двумя элементами «Рабочая» и «Финальная», для отделения вычищенных данных. Кроме-того создание персональных версий, одной суммарной и одной финальной позволяет хорошо контролировать загрузку в несколько потоков;
- Данные всегда содержат ошибки: Перезагружать весь пакет в [50GB -> +8] это очень не экономно по ресурсам и вы, скорее всего, не впишитесь в регламент, следовательно, надо грамотно делить загружаемый пакет файлов и так проектировать систему, чтобы она позволяла обновлять пакет по маленьким частям. По моему опыту лучший способ – техническая аналитика «файл-источник», и интерфейс, который позволяет снести все данные только из одного файла, и вставить вместо него обновленные. А сам пакет разумно делить на файлы по количеству исполнителей, ответственных за их заполнение (либо админы систем готовящие выгрузки, либо пользователи заполняющие вручную);
- При проектировании разделения пакета на части надо еще учитывать возможность так-называемого «обогащения» данных (например: Когда 12 января считают налоги прошлого года по правилам управленческого учета, а в марте-апреле перегружают суммы на посчитанные по бухгалтерскому), это решается с одной стороны правильным проектированием деления пакета данных на части так, чтобы для обогащения надо было перегрузить целое количество файлов (не 2,345 файла), а с другой стороны введением еще одного технического справочника с периодами обогащения, чтобы не потерять историю изменений по этим причинам).
Процесс валидации
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
- Не из списка разрешенных значений
- Отсутствие обязательных значений
- Не соответствие формату (Все договора должны нумероваться «ДГВxxxx..»)
- Не из списка разрешенных значений для связанного элемента
- Отсутствие обязательных элементов для связанного элемента
- Не соответствие формату для связанного элемента(например: для продукта «АИС» все договора должны нумероваться «АИСxxxx..»)
- Символы допустимые в одном формате, недопустимы в другом
- Кодировка
- Обратная совместимость (Элемент справочника был изменен в целевой системе без добавления мэппинга)
- Новые значения (нет мэппинга)
- Устаревшие значения (не из списка разрешенных в целевой системе)
- Не число
- Не в границах разрешенного интервала значений
- Пропущено порядковое значение (например: данные не дошли)
- Не выполняется отношение y=ax+b (например: НДС и Выручка, или Встречные суммы равны)
- Элементу «А» присвоен неправильный порядковый номер
- Разницы за счет разных правил округления значений (например: в 1С и SAP никогда не сходится рассчитанный НДС)
- Переполнение
- Потеря точности и знаков
- Несовместимость форматов при конвертации в не число
- День недели не соответствует дате
- Сумма единиц времени не соответствует из-за разницы рабочие/не рабочие/праздничные/сокращенные дни
- Несовместимость формата даты при передаче текстом (например: ISO 8601 в UnixTime, или разные форматы в ISO 8601)
- Ошибка точки отсчета и точности при передаче числом (например: TimeStamp в DateTime)
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
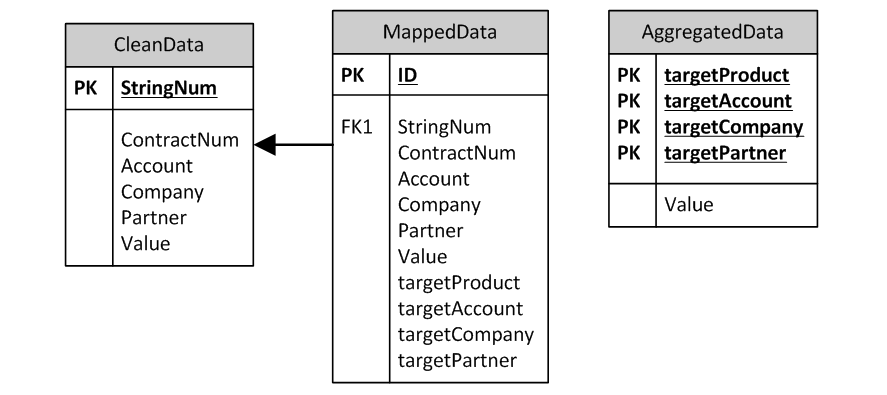
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
-
Таблица замэпленных данных должна включать одновременно два набора полей – старых и новых аналитик, чтобы можно был сделать select по исходным аналитикам и посмотреть, какие целевые аналитики им присвоены, и наоборот:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
Extract, transform, and load (ETL) is the process data-driven organizations use to gather data from multiple sources and then bring it together to support discovery, reporting, analysis, and decision-making.
The data sources can be very diverse in type, format, volume, and reliability, so the data needs to be processed to be useful when brought together. The target data stores may be databases, data warehouses, or data lakes, depending on the goals and technical implementation.
ETL use cases
The ETL process is fundamental for many industries because of its ability to ingest data quickly and reliably into data lakes for data science and analytics, while creating high-quality models. ETL solutions also can load and transform transactional data at scale to create an organized view from large data volumes. This enables businesses to visualize and forecast industry trends. Several industries rely on ETL to enable actionable insights, quick decision-making, and greater efficiency.
Financial services
Financial services institutions gather large amounts of structured and unstructured data to glean insights into consumer behavior. These insights can analyze risk, optimize banks’ financial services, improve online platforms, and even supply ATMs with cash.
Oil and gas
Oil and gas industries use ETL solutions to generate predictions about usage, storage, and trends in specific geographical areas. ETL works to gather as much information as possible from all the sensors of an extraction site and process that information to make it easy to read.
Automotive
ETL solutions can enable dealerships and manufacturers to understand sales patterns, calibrate their marketing campaigns, replenish inventory, and follow up on customer leads.
Telecommunications
With the unprecedented volume and variety of data being produced today, telecommunications providers rely on ETL solutions to better manage and understand that data. Once this data is processed and analyzed, businesses can use it to improve advertising, social media, SEO, customer satisfaction, profitability, and more.
Healthcare
With the need to reduce costs while also improving care, the healthcare industry employs ETL solutions to manage patient records, gather insurance information, and meet evolving regulatory requirements.
Life sciences
Clinical labs rely on ETL solutions and artificial intelligence (AI) to process various types of data being produced by research institutions. For example, collaborating on vaccine development requires huge amounts of data to be collected, processed, and analyzed.
Public sector
With Internet of Things (IoT) capabilities emerging so quickly, smart cities are using ETL and the power of AI to optimize traffic, monitor water quality, improve parking, and more.
ETL Products and Solutions
Service Oriented Architecture (SOA) Suite
How can you decrease the complexity of application integration? With simplified cloud, mobile, on-premises, and IoT integration capabilities—all within a single platform—this solution can deliver faster time to integration and increased productivity, along with a lower total cost of ownership (TCO). Many enterprise applications, including, Oracle E-Business Suite, heavily use this product to orchestrate dataflows.
GoldenGate
Digital transformation often demands moving data from where it’s captured to where it’s needed, and GoldenGate is designed to simplify this process. Oracle GoldenGate is a high-speed data replication solution for real-time integration between heterogeneous databases located on-premises, in the cloud, or in an autonomous database. GoldenGate improves data availability without affecting system performance, providing real-time data access and operational reporting.
Cloud Streaming
Our Cloud Streaming solution provides a fully managed, scalable, and durable solution for ingesting and consuming high-volume data streams in real time. Use this service for messaging, application logs, operational telemetry, web clickstream data, or any other instance in which data is produced and processed continually and sequentially in a publish-subscribe messaging model. It is fully compatible with Spark and Kafka.
Extract, transform, and load (ETL) is the process data-driven organizations use to gather data from multiple sources and then bring it together to support discovery, reporting, analysis, and decision-making.
The data sources can be very diverse in type, format, volume, and reliability, so the data needs to be processed to be useful when brought together. The target data stores may be databases, data warehouses, or data lakes, depending on the goals and technical implementation.
Таблицы фактов и таблицы измерений
Чтобы лучше понять, как строить денормализованные таблицы из таблиц фактов и таблиц измерений, обсудим роли каждой из них:
Таблицы фактов чаще всего содержат транзакционные данные в определенные моменты времени. Каждая строка в таблице может быть чрезвычайно простой и чаще всего является одной транзакцией. У нас в Airbnb есть множество таблиц фактов, которые хранят данные по типу транзакций: бронирования, оформления заказов, отмены и т.д.
Таблицы измерений содержат медленно меняющиеся атрибуты определенных ключей из таблицы фактов, и их можно соединить с ней по этим ключам. Сами атрибуты могут быть организованы в рамках иерархической структуры. В Airbnb, к примеру, есть таблицы измерений с пользователями, заказами и рынками, которые помогают нам детально анализировать данные.
Ниже представлен простой пример того, как таблицы фактов и таблицы измерений (нормализованные) могут быть соединены, чтобы ответить на простой вопрос: сколько бронирований было сделано за последнюю неделю по каждому из рынков?
Обратное заполнение (backfilling) исторических данных
Еще одно важное преимущество использования временной метки в качестве ключа партиционирования — легкость обратного заполнения данных. Если ETL-пайплайн уже построен, то он рассчитывает метрики и измерения наперед, а не ретроспективно. Часто нам бы хотелось посмотреть на сложившиеся тренды путем расчета измерений в прошлом — этот процесс и называется backfilling.
Backfilling настолько распространен, что в Hive есть встроенная возможность динамического партиционирования, чтобы выполнять одни и те же SQL запросы по нескольким партициям сразу. Проиллюстрируем эту идею на примере: пусть требуется заполнить количество бронирований по каждому рынку для дашборда, начиная с earliest_ds и заканчивая latest_ds. Одно из возможных решений выглядит примерно так:
Такой запрос возможен, однако он слишком громоздкий, поскольку мы выполняем одну и ту же операцию, только над разными партициями. Используя динамическое партиционирование мы можем все упростить до одного запроса:
Отметим, что мы добавили ds в SELECT и GROUP BY выражения, расширили диапазон в операции WHERE и изменили синтаксис с PARTITION (ds= '>') на PARTITION (ds). Вся прелесть динамического партиционирования в том, что мы обернули GROUP BY ds вокруг необходимых операций, чтобы вставить результаты запроса во все партиции в один заход. Такой подход очень эффективен и используется во многих пайплайнах в Airbnb.
Теперь, рассмотрим все изученные концепции на примере ETL джобы в Airflow.
ETL use cases
The ETL process is fundamental for many industries because of its ability to ingest data quickly and reliably into data lakes for data science and analytics, while creating high-quality models. ETL solutions also can load and transform transactional data at scale to create an organized view from large data volumes. This enables businesses to visualize and forecast industry trends. Several industries rely on ETL to enable actionable insights, quick decision-making, and greater efficiency.
Financial services
Financial services institutions gather large amounts of structured and unstructured data to glean insights into consumer behavior. These insights can analyze risk, optimize banks’ financial services, improve online platforms, and even supply ATMs with cash.
Oil and gas
Oil and gas industries use ETL solutions to generate predictions about usage, storage, and trends in specific geographical areas. ETL works to gather as much information as possible from all the sensors of an extraction site and process that information to make it easy to read.
Automotive
ETL solutions can enable dealerships and manufacturers to understand sales patterns, calibrate their marketing campaigns, replenish inventory, and follow up on customer leads.
Telecommunications
With the unprecedented volume and variety of data being produced today, telecommunications providers rely on ETL solutions to better manage and understand that data. Once this data is processed and analyzed, businesses can use it to improve advertising, social media, SEO, customer satisfaction, profitability, and more.
Healthcare
With the need to reduce costs while also improving care, the healthcare industry employs ETL solutions to manage patient records, gather insurance information, and meet evolving regulatory requirements.
Life sciences
Clinical labs rely on ETL solutions and artificial intelligence (AI) to process various types of data being produced by research institutions. For example, collaborating on vaccine development requires huge amounts of data to be collected, processed, and analyzed.
Public sector
With Internet of Things (IoT) capabilities emerging so quickly, smart cities are using ETL and the power of AI to optimize traffic, monitor water quality, improve parking, and more.
ETL and data marts
Data marts are smaller and more focused target datastores than enterprise data warehouses. They can, for instance, focus on information about a single department or a single product line. Because of that, the users of ETL tools for data marts are often line-of-business (LOB) specialists, data analysts, and/or data scientists.
ETL tools for data marts must be usable by business personnel and data managers, rather than by programmers and IT staff. Therefore, these tools should have a visual workflow to make it easy to set up ETL pipelines.

Data Engineering
Maxime Beauchemin, один из разработчиков Airflow, так охарактеризовал data engineering: «Это область, которую можно рассматривать как смесь бизнес-аналитики и баз данных, которая привносит больше элементов программирования. Эта сфера включает в себя специализацию по работе с распределенными системами больших данных, расширенной экосистемой Hadoop и масштабируемыми вычислениями».
Среди множества навыков инженера данных можно выделить один, который является наиболее важным — способность разрабатывать, строить и поддерживать хранилища данных. Отсутствие качественной инфраструктуры хранения данных приводит к тому, что любая активность, связанная с анализом данных, либо слишком дорога, либо немасштабируема.
ELT or ETL: What’s the difference?
The transformation step is by far the most complex in the ETL process. ETL and ELT, therefore, differ on two main points:
- When the transformation takes place
- The place of transformation
In a traditional data warehouse, data is first extracted from "source systems" (ERP systems, CRM systems, etc.). OLAP tools and SQL queries depend on standardizing the dimensions of datasets to obtain aggregated results. This means that the data must undergo a series of transformations.
Traditionally, these transformations have been done before the data was loaded into the target system, typically a relational data warehouse.
However, as the underlying data storage and processing technologies that underpin data warehousing evolve, it has become possible to effect transformations within the target system. Both ETL and ELT processes involve staging areas. In ETL, these areas are found in the tool, whether it is proprietary or custom. They sit between the source system (for example, a CRM system) and the target system (the data warehouse).
In contrast, with ELTs, the staging area is in the data warehouse, and the database engine that powers the DBMS does the transformations, as opposed to an ETL tool. Therefore, one of the immediate consequences of ELTs is that you lose the data preparation and cleansing functions that ETL tools provide to aid in the data transformation process.
Какой ETL-фреймворк выбрать?
В мире batch-обработки данных есть несколько платформ с открытым исходным кодом, с которыми можно попробовать поиграть. Некоторые из них: Azkaban — open-source воркфлоу менеджер от Linkedin, особенностью которого является облегченное управление зависимостями в Hadoop, Luigi — фреймворк от Spotify, базирующийся на Python и Airflow, который также основан на Python, от Airbnb.
У каждой платформы есть свои плюсы и минусы, многие эксперты пытаются их сравнивать (смотрите тут и тут). Выбирая тот или иной фреймворк, важно учитывать следующие характеристики:

Конфигурация. ETL-ы по своей природе довольно сложны, поэтому важно, как именно пользователь фреймворка будет их конструировать. Основан ли он на пользовательском интерфейсе или же запросы создаются на каком-либо языке программирования? Сегодня все большую популярность набирает именно второй способ, поскольку программирование пайплайнов делает их более гибкими, позволяя изменять любую деталь.
Мониторинг ошибок и оповещения. Объемные и долгие batch запросы рано или поздно падают с ошибкой, даже если в самой джобе багов нет. Как следствие, мониторинг и оповещения об ошибках выходят на первый план. Насколько хорошо фреймворк визуализирует прогресс запроса? Приходят ли оповещения вовремя?
Обратное заполнение данных (backfilling). Часто после построения готового пайплайна нам требуется вернуться назад и заново обработать исторические данных. В идеале нам бы не хотелось строить две независимые джобы: одну для обратного а исторических данных, а вторую для текущей деятельности. Насколько легко осуществлять backfilling c помощью данного фреймворка? Масштабируемо и эффективно ли полученное решение?
ELT or ETL: What’s the difference?
The transformation step is by far the most complex in the ETL process. ETL and ELT, therefore, differ on two main points:
- When the transformation takes place
- The place of transformation
In a traditional data warehouse, data is first extracted from "source systems" (ERP systems, CRM systems, etc.). OLAP tools and SQL queries depend on standardizing the dimensions of datasets to obtain aggregated results. This means that the data must undergo a series of transformations.
Traditionally, these transformations have been done before the data was loaded into the target system, typically a relational data warehouse.
However, as the underlying data storage and processing technologies that underpin data warehousing evolve, it has become possible to effect transformations within the target system. Both ETL and ELT processes involve staging areas. In ETL, these areas are found in the tool, whether it is proprietary or custom. They sit between the source system (for example, a CRM system) and the target system (the data warehouse).
In contrast, with ELTs, the staging area is in the data warehouse, and the database engine that powers the DBMS does the transformations, as opposed to an ETL tool. Therefore, one of the immediate consequences of ELTs is that you lose the data preparation and cleansing functions that ETL tools provide to aid in the data transformation process.
ETL and enterprise data warehouses
Traditionally, tools for ETL primarily were used to deliver data to enterprise data warehouses supporting business intelligence (BI) applications. Such data warehouses are designed to represent a reliable source of truth about all that is happening in an enterprise across all activities. The data in these warehouses is carefully structured with strict schemas, metadata, and rules that govern the data validation.
The ETL tools for enterprise data warehouses must meet data integration requirements, such as high-volume, high-performance batch loads; event-driven, trickle-feed integration processes; programmable transformations; and orchestrations so they can deal with the most demanding transformations and workflows and have connectors for the most diverse data sources.
After loading the data, you have multiple strategies for keeping it synchronized between the source and target datastores. You can reload the full dataset periodically, schedule periodic updates of the latest data, or commit to maintain full synchronicity between the source and the target data warehouse. Such real-time integration is referred to as change data capture (CDC). For this advanced process, the ETL tools need to understand the transaction semantics of the source databases and correctly transmit these transactions to the target data warehouse.
ETL or ELT and data lakes
Data lakes follow a different pattern than data warehouses and data marts. Data lakes generally store their data in object storage or Hadoop Distributed File Systems (HDFS), and therefore they can store less-structured data without schema; and they support multiple tools for querying that unstructured data.
One additional pattern this allows is extract, load, and transform (ELT), in which data is stored “as-is” first, and will be transformed, analyzed, and processed after the data is captured in the data lake. This pattern offers several benefits.
- All data gets recorded; no signal is lost due to aggregation or filtering.
- Data can be ingested very fast, which is useful for Internet of Things (IoT) streaming, log analytics, website metrics, and so forth.
- It enables discovery of trends that were not expected at the time of capture.
- It allows deployment of new artificial intelligence (AI) techniques that excel at pattern detection in large, unstructured datasets.
ETL tools for data lakes include visual data integration tools, because they are effective for data scientists and data engineers. Additional tools that are often used in data lake architecture include the following:
-
Services that can ingest large streams of real-time data into data lakes for messaging, application logs, operational telemetry, web clickstream data tracking, event processing, and security analytics. Compatibility with Kafka ensures that these services can retrieve data from near-infinite data sources. that can quickly perform data processing and transformation tasks on very large datasets. Spark services can load the datasets from object storage or HDFS, process and transform them in memory across scalable clusters of compute instances, and write the output back to the data lake or to data marts and/or data warehouses.
ETL: Extract, Transform, Load
Extract, Transform и Load — это 3 концептуально важных шага, определяющих, каким образом устроены большинство современных пайплайнов данных. На сегодняшний день это базовая модель того, как сырые данные сделать готовыми для анализа.

Extract. Это шаг, на котором датчики принимают на вход данные из различных источников (логов пользователей, копии реляционной БД, внешнего набора данных и т.д.), а затем передают их дальше для последующих преобразований.
Transform. Это «сердце» любого ETL, этап, когда мы применяем бизнес-логику и делаем фильтрацию, группировку и агрегирование, чтобы преобразовать сырые данные в готовый к анализу датасет. Эта процедура требует понимания бизнес задач и наличия базовых знаний в области.
Load. Наконец, мы загружаем обработанные данные и отправляем их в место конечного использования. Полученный набор данных может быть использован конечными пользователями, а может являться входным потоком к еще одному ETL.
ETL and data marts
Data marts are smaller and more focused target datastores than enterprise data warehouses. They can, for instance, focus on information about a single department or a single product line. Because of that, the users of ETL tools for data marts are often line-of-business (LOB) specialists, data analysts, and/or data scientists.
ETL tools for data marts must be usable by business personnel and data managers, rather than by programmers and IT staff. Therefore, these tools should have a visual workflow to make it easy to set up ETL pipelines.
ETL and enterprise data warehouses
Traditionally, tools for ETL primarily were used to deliver data to enterprise data warehouses supporting business intelligence (BI) applications. Such data warehouses are designed to represent a reliable source of truth about all that is happening in an enterprise across all activities. The data in these warehouses is carefully structured with strict schemas, metadata, and rules that govern the data validation.
The ETL tools for enterprise data warehouses must meet data integration requirements, such as high-volume, high-performance batch loads; event-driven, trickle-feed integration processes; programmable transformations; and orchestrations so they can deal with the most demanding transformations and workflows and have connectors for the most diverse data sources.
After loading the data, you have multiple strategies for keeping it synchronized between the source and target datastores. You can reload the full dataset periodically, schedule periodic updates of the latest data, or commit to maintain full synchronicity between the source and the target data warehouse. Such real-time integration is referred to as change data capture (CDC). For this advanced process, the ETL tools need to understand the transaction semantics of the source databases and correctly transmit these transactions to the target data warehouse.
ETL or ELT and data lakes
Data lakes follow a different pattern than data warehouses and data marts. Data lakes generally store their data in object storage or Hadoop Distributed File Systems (HDFS), and therefore they can store less-structured data without schema; and they support multiple tools for querying that unstructured data.
One additional pattern this allows is extract, load, and transform (ELT), in which data is stored “as-is” first, and will be transformed, analyzed, and processed after the data is captured in the data lake. This pattern offers several benefits.
- All data gets recorded; no signal is lost due to aggregation or filtering.
- Data can be ingested very fast, which is useful for Internet of Things (IoT) streaming, log analytics, website metrics, and so forth.
- It enables discovery of trends that were not expected at the time of capture.
- It allows deployment of new artificial intelligence (AI) techniques that excel at pattern detection in large, unstructured datasets.
ETL tools for data lakes include visual data integration tools, because they are effective for data scientists and data engineers. Additional tools that are often used in data lake architecture include the following:
-
Services that can ingest large streams of real-time data into data lakes for messaging, application logs, operational telemetry, web clickstream data tracking, event processing, and security analytics. Compatibility with Kafka ensures that these services can retrieve data from near-infinite data sources. that can quickly perform data processing and transformation tasks on very large datasets. Spark services can load the datasets from object storage or HDFS, process and transform them in memory across scalable clusters of compute instances, and write the output back to the data lake or to data marts and/or data warehouses.
2 парадигмы: SQL против JVM
Как мы выяснили, у компаний есть огромный выбор того, какие инструменты использовать для ETL, и для начинающего data scientist-а не всегда понятно, какому именно фреймворку посвятить время. Это как раз про меня: в Washington Post Labs очередность джобов осуществлялась примитивно, с помощью Cron, в Twitter ETL джобы строились в Pig, а сейчас в Airbnb мы пишем пайплайны в Hive через Airflow. Поэтому перед тем, как пойти в ту или иную компанию, постарайтесь узнать, как именно организованы ETL в них. Упрощенно, можно выделить две основные парадигмы: SQL и JVM-ориентированные ETL.
JVM-ориентированные ETL обычно написаны на JVM-ориентированном языке (Java или Scala). Построение пайплайнов данных на таких языках означает задавать преобразования данных через пары «ключ-значение», однако писать пользовательские функции и тестировать джобы становится легче, поскольку не требуется использовать для этого другой язык программирования. Эта парадигма весьма популярна среди инженеров.
SQL-ориентированные ETL чаще всего пишутся на SQL, Presto или Hive. В них почти все крутится вокруг SQL и таблиц, что весьма удобно. В то же время написание пользовательских функций может быть проблематично, поскольку требует использования другого языка (к примеру, Java или Python). Такой подход популярен среди data scientist-ов.
Поработав с обеими парадигмами, я все-таки предпочитаю SQL-ориентированные ETL, поскольку, будучи начинающим data scientist-ом, намного легче выучить SQL, чем Java или Scala (если, конечно, вы еще с ними не знакомы) и сконцентрироваться на изучении новых практик, чем накладывать это поверх изучения нового языка.
ETL Products and Solutions
Service Oriented Architecture (SOA) Suite
How can you decrease the complexity of application integration? With simplified cloud, mobile, on-premises, and IoT integration capabilities—all within a single platform—this solution can deliver faster time to integration and increased productivity, along with a lower total cost of ownership (TCO). Many enterprise applications, including, Oracle E-Business Suite, heavily use this product to orchestrate dataflows.
GoldenGate
Digital transformation often demands moving data from where it’s captured to where it’s needed, and GoldenGate is designed to simplify this process. Oracle GoldenGate is a high-speed data replication solution for real-time integration between heterogeneous databases located on-premises, in the cloud, or in an autonomous database. GoldenGate improves data availability without affecting system performance, providing real-time data access and operational reporting.
Cloud Streaming
Our Cloud Streaming solution provides a fully managed, scalable, and durable solution for ingesting and consuming high-volume data streams in real time. Use this service for messaging, application logs, operational telemetry, web clickstream data, or any other instance in which data is produced and processed continually and sequentially in a publish-subscribe messaging model. It is fully compatible with Spark and Kafka.
Способность data scientist-а извлекать ценность из данных тесно связана с тем, насколько развита инфраструктура хранения и обработки данных в компании. Это значит, что аналитик должен не только уметь строить модели, но и обладать достаточными навыками в области data engineering, чтобы соответствовать потребностям компании и браться за все более амбициозные проекты.
При этом, несмотря на всю важность, образование в сфере data engineering продолжает оставаться весьма ограниченным. Мне повезло, поскольку я успел поработать со многими инженерами, которые терпеливо объясняли мне каждый аспект работы с данными, но не все обладают такой возможностью. Именно поэтому я решил написать эту статью — введение в data engineering, в которой я расскажу о том, что такое ETL, разнице между SQL- и JVM-ориентированными ETL, нормализации и партиционировании данных и, наконец, рассмотрим пример запроса в Airflow.

Моделирование данных, нормализация и схема «звезды»
В процессе построения качественной аналитической платформы, главная цель дизайнера системы — сделать так, чтобы аналитические запросы было легко писать, а различные статистики считались эффективно. Для этого в первую очередь нужно определить модель данных.
В качестве одного из первых этапов моделирования данных необходимо понять, в какой степени таблицы должны быть нормализованы. В общем случае нормализованные таблицы отличаются более простыми схемами, более стандартизированными данными, а также исключают некоторые типы избыточности. В то же время использование таких таблиц приводит к тому, что для установления взаимоотношений между таблицами требуется больше аккуратности и усердия, запросы становятся сложнее (больше JOIN-ов), а также требуется поддерживать больше ETL джобов.
С другой стороны, гораздо легче писать запросы к денормализованным таблицам, поскольку все измерения и метрики уже соединены. Однако, учитывая больший размер таблиц, обработка данных становится медленнее (“Тут можно поспорить, ведь все зависит от того, как хранятся данные и какие запросы бывают. Можно, к примеру, хранить большие таблицы в Hbase и обращаться к отдельным колонкам, тогда запросы будут быстрыми” — прим. пер.).
Среди всех моделей данных, которые пытаются найти идеальный баланс между двумя подходами, одной из наиболее популярных (мы используем ее в Airbnb) является схема «звезды». Данная схема основана на построении нормализованных таблиц (таблиц фактов и таблиц измерений), из которых, в случае чего, могут быть получены денормализованные таблицы. В результате такой дизайн пытается найти баланс между легкостью аналитики и сложностью поддержки ETL.

The three distinct steps of ETL
Extract
During extraction, ETL identifies the data and copies it from its sources, so it can transport the data to the target datastore. The data can come from structured and unstructured sources, including documents, emails, business applications, databases, equipment, sensors, third parties, and more.
Transform
Because the extracted data is raw in its original form, it needs to be mapped and transformed to prepare it for the eventual datastore. In the transformation process, ETL validates, authenticates, deduplicates, and/or aggregates the data in ways that make the resulting data reliable and queryable.
Load
ETL moves the transformed data into the target datastore. This step can entail the initial loading of all the source data, or it can be the loading of incremental changes in the source data. You can load the data in real time or in scheduled batches.
Направленный ациклический граф (DAG)
Казалось бы, с точки зрения идеи ETL джобы очень просты, однако на деле они часто очень запутаны и состоят из множества комбинаций Extract, Transform и Load операций. В этом случае очень полезно бывает визуализировать весь поток данных, используя граф, в котором узел отображает операцию, а стрелка — взаимосвязь между операциями. Учитывая, что каждая операция выполняется единожды, а данные идут дальше по графу, то он является направленным и ациклическим, отсюда и название.

Одна из особенностей интерфейса Airflow — это наличие механизма, который позволяет визуализировать пайплайн данных через DAG. Автор пайплайна должен задать взаимосвязи между операциями, чтобы Airflow записал спецификацию ETL джоба в отдельный файл.
При этом помимо DAG-ов, которые определяют порядок запуска операций, в Airflow есть операторы, которые задают, что необходимо выполнить в рамках пайплайна. Обычно есть 3 вида операторов, каждый из которых имитирует один из этапов ETL-процесса:
- Сенсоры: открывают поток данных по истечении определенного времени, либо когда данные из входного источника становятся доступны (по аналогии с Extract).
- Операторы: запускают определенные команды (выполни Python-файл, запрос в Hive и т.д.). По аналогии с Transform, операторы занимаются преобразованием данных.
- Трансферы: переносят данные из одного места в другое (как и на стадии Load).
ELT or ETL: What’s the difference?
The transformation step is by far the most complex in the ETL process. ETL and ELT, therefore, differ on two main points:
- When the transformation takes place
- The place of transformation
In a traditional data warehouse, data is first extracted from "source systems" (ERP systems, CRM systems, etc.). OLAP tools and SQL queries depend on standardizing the dimensions of datasets to obtain aggregated results. This means that the data must undergo a series of transformations.
Traditionally, these transformations have been done before the data was loaded into the target system, typically a relational data warehouse.
However, as the underlying data storage and processing technologies that underpin data warehousing evolve, it has become possible to effect transformations within the target system. Both ETL and ELT processes involve staging areas. In ETL, these areas are found in the tool, whether it is proprietary or custom. They sit between the source system (for example, a CRM system) and the target system (the data warehouse).
In contrast, with ELTs, the staging area is in the data warehouse, and the database engine that powers the DBMS does the transformations, as opposed to an ETL tool. Therefore, one of the immediate consequences of ELTs is that you lose the data preparation and cleansing functions that ETL tools provide to aid in the data transformation process.
Партиционирование данных по временной метке
Сейчас, когда стоимость хранения данных очень мала, компании могут себе позволить хранить исторические данные в своих хранилищах, вместо того, чтобы выбрасывать. Обратная сторона такого тренда в том, что с накоплением количества данных аналитические запросы становятся неэффективными и медленными. Наряду с такими принципами SQL как «фильтровать данные чаще и раньше» и «использовать только те поля, которые нужны», можно выделить еще один, позволяющий увеличить эффективность запросов: партиционирование данных.
Основная идея партиционирования весьма проста — вместо того, чтобы хранить данные одним куском, разделим их на несколько независимых частей. Все части сохраняют первичный ключ из исходного куска, поэтому получить доступ к любым данным можно достаточно быстро.
В частности, использование временной метки в качестве ключа, по которому проходит партиционирование, имеет ряд преимуществ. Во-первых, в хранилищах типа S3 сырые данные часто сортированы по временной метке и хранятся в директориях, также отмеченных метками. Во-вторых, обычно batch-ETL джоб проходит примерно за один день, то есть новые партиции данных создаются каждый день для каждого джоба. Наконец, многие аналитические запросы включают в себя подсчет количества событий, произошедших за определенный временной промежуток, поэтому партиционирование по времени здесь очень кстати.
ETL and data marts
Data marts are smaller and more focused target datastores than enterprise data warehouses. They can, for instance, focus on information about a single department or a single product line. Because of that, the users of ETL tools for data marts are often line-of-business (LOB) specialists, data analysts, and/or data scientists.
ETL tools for data marts must be usable by business personnel and data managers, rather than by programmers and IT staff. Therefore, these tools should have a visual workflow to make it easy to set up ETL pipelines.
ETL use cases
The ETL process is fundamental for many industries because of its ability to ingest data quickly and reliably into data lakes for data science and analytics, while creating high-quality models. ETL solutions also can load and transform transactional data at scale to create an organized view from large data volumes. This enables businesses to visualize and forecast industry trends. Several industries rely on ETL to enable actionable insights, quick decision-making, and greater efficiency.
Financial services
Financial services institutions gather large amounts of structured and unstructured data to glean insights into consumer behavior. These insights can analyze risk, optimize banks’ financial services, improve online platforms, and even supply ATMs with cash.
Oil and gas
Oil and gas industries use ETL solutions to generate predictions about usage, storage, and trends in specific geographical areas. ETL works to gather as much information as possible from all the sensors of an extraction site and process that information to make it easy to read.
Automotive
ETL solutions can enable dealerships and manufacturers to understand sales patterns, calibrate their marketing campaigns, replenish inventory, and follow up on customer leads.
Telecommunications
With the unprecedented volume and variety of data being produced today, telecommunications providers rely on ETL solutions to better manage and understand that data. Once this data is processed and analyzed, businesses can use it to improve advertising, social media, SEO, customer satisfaction, profitability, and more.
Healthcare
With the need to reduce costs while also improving care, the healthcare industry employs ETL solutions to manage patient records, gather insurance information, and meet evolving regulatory requirements.
Life sciences
Clinical labs rely on ETL solutions and artificial intelligence (AI) to process various types of data being produced by research institutions. For example, collaborating on vaccine development requires huge amounts of data to be collected, processed, and analyzed.
Public sector
With Internet of Things (IoT) capabilities emerging so quickly, smart cities are using ETL and the power of AI to optimize traffic, monitor water quality, improve parking, and more.
Простой пример
Ниже представлен простой пример того, как объявить DAG-файл и определить структуру графа, используя операторы в Airflow, которые мы обсудили выше:
Когда граф будет построен, можно увидеть следующую картинку:

Итак, надеюсь, что в данной статье мне удалось максимально быстро и эффективно погрузить вас в интересную и многообразную сферу — Data Engineering. Мы изучили, что такое ETL, преимущества и недостатки различных ETL-платформ. Затем обсудили моделирование данных и схему «звезды», в частности, а также рассмотрели отличия таблиц фактов от таблиц измерений. Наконец, рассмотрев такие концепции как партиционирование данных и backfilling, мы перешли к примеру небольшого ETL джоба в Airflow. Теперь вы можете самостоятельно изучать работу с данными, наращивая багаж своих знаний. Еще увидимся!
Роберт отмечает недостаточное количество программ по data engineering в мире, однако мы таковую проводим, и уже не в первый раз. В октябре у нас стартует Data Engineer 3.0, регистрируйтесь и расширяйте свои профессиональные возможности!
ETL and enterprise data warehouses
Traditionally, tools for ETL primarily were used to deliver data to enterprise data warehouses supporting business intelligence (BI) applications. Such data warehouses are designed to represent a reliable source of truth about all that is happening in an enterprise across all activities. The data in these warehouses is carefully structured with strict schemas, metadata, and rules that govern the data validation.
The ETL tools for enterprise data warehouses must meet data integration requirements, such as high-volume, high-performance batch loads; event-driven, trickle-feed integration processes; programmable transformations; and orchestrations so they can deal with the most demanding transformations and workflows and have connectors for the most diverse data sources.
After loading the data, you have multiple strategies for keeping it synchronized between the source and target datastores. You can reload the full dataset periodically, schedule periodic updates of the latest data, or commit to maintain full synchronicity between the source and the target data warehouse. Such real-time integration is referred to as change data capture (CDC). For this advanced process, the ETL tools need to understand the transaction semantics of the source databases and correctly transmit these transactions to the target data warehouse.
ETL Products and Solutions
Service Oriented Architecture (SOA) Suite
How can you decrease the complexity of application integration? With simplified cloud, mobile, on-premises, and IoT integration capabilities—all within a single platform—this solution can deliver faster time to integration and increased productivity, along with a lower total cost of ownership (TCO). Many enterprise applications, including, Oracle E-Business Suite, heavily use this product to orchestrate dataflows.
GoldenGate
Digital transformation often demands moving data from where it’s captured to where it’s needed, and GoldenGate is designed to simplify this process. Oracle GoldenGate is a high-speed data replication solution for real-time integration between heterogeneous databases located on-premises, in the cloud, or in an autonomous database. GoldenGate improves data availability without affecting system performance, providing real-time data access and operational reporting.
Cloud Streaming
Our Cloud Streaming solution provides a fully managed, scalable, and durable solution for ingesting and consuming high-volume data streams in real time. Use this service for messaging, application logs, operational telemetry, web clickstream data, or any other instance in which data is produced and processed continually and sequentially in a publish-subscribe messaging model. It is fully compatible with Spark and Kafka.
Extract, transform, and load (ETL) is the process data-driven organizations use to gather data from multiple sources and then bring it together to support discovery, reporting, analysis, and decision-making.
The data sources can be very diverse in type, format, volume, and reliability, so the data needs to be processed to be useful when brought together. The target data stores may be databases, data warehouses, or data lakes, depending on the goals and technical implementation.
The three distinct steps of ETL
Extract
During extraction, ETL identifies the data and copies it from its sources, so it can transport the data to the target datastore. The data can come from structured and unstructured sources, including documents, emails, business applications, databases, equipment, sensors, third parties, and more.
Transform
Because the extracted data is raw in its original form, it needs to be mapped and transformed to prepare it for the eventual datastore. In the transformation process, ETL validates, authenticates, deduplicates, and/or aggregates the data in ways that make the resulting data reliable and queryable.
Load
ETL moves the transformed data into the target datastore. This step can entail the initial loading of all the source data, or it can be the loading of incremental changes in the source data. You can load the data in real time or in scheduled batches.
ETL or ELT and data lakes
Data lakes follow a different pattern than data warehouses and data marts. Data lakes generally store their data in object storage or Hadoop Distributed File Systems (HDFS), and therefore they can store less-structured data without schema; and they support multiple tools for querying that unstructured data.
One additional pattern this allows is extract, load, and transform (ELT), in which data is stored “as-is” first, and will be transformed, analyzed, and processed after the data is captured in the data lake. This pattern offers several benefits.
- All data gets recorded; no signal is lost due to aggregation or filtering.
- Data can be ingested very fast, which is useful for Internet of Things (IoT) streaming, log analytics, website metrics, and so forth.
- It enables discovery of trends that were not expected at the time of capture.
- It allows deployment of new artificial intelligence (AI) techniques that excel at pattern detection in large, unstructured datasets.
ETL tools for data lakes include visual data integration tools, because they are effective for data scientists and data engineers. Additional tools that are often used in data lake architecture include the following:
-
Services that can ingest large streams of real-time data into data lakes for messaging, application logs, operational telemetry, web clickstream data tracking, event processing, and security analytics. Compatibility with Kafka ensures that these services can retrieve data from near-infinite data sources. that can quickly perform data processing and transformation tasks on very large datasets. Spark services can load the datasets from object storage or HDFS, process and transform them in memory across scalable clusters of compute instances, and write the output back to the data lake or to data marts and/or data warehouses.
The three distinct steps of ETL
Extract
During extraction, ETL identifies the data and copies it from its sources, so it can transport the data to the target datastore. The data can come from structured and unstructured sources, including documents, emails, business applications, databases, equipment, sensors, third parties, and more.
Transform
Because the extracted data is raw in its original form, it needs to be mapped and transformed to prepare it for the eventual datastore. In the transformation process, ETL validates, authenticates, deduplicates, and/or aggregates the data in ways that make the resulting data reliable and queryable.
Load
ETL moves the transformed data into the target datastore. This step can entail the initial loading of all the source data, or it can be the loading of incremental changes in the source data. You can load the data in real time or in scheduled batches.
Читайте также: