
Oracle что такое dbms
В настоящее время в любой организации действует разграничение доступа к информации на основе определенных знаний о пользователе. Такими знаниями могут служить роль пользователя в организации, его должность либо структурное подразделение, в котором работает пользователь. Многим известно, что проблема ограничения доступа может быть решена с помощью простейших механизмов на основе имени пользователя, таблиц, представлений и триггеров.
Рассмотрим пример:
Предоставить менеджеру информацию о клиентах организации. При этом, менеджер может видеть только клиентов своего структурного подразделения, но не всей компании:
Решением «в лоб» является создание отдельного представления для каждого отдела компании. Например:
Решение, бесспорно, более интересное, но что же делать, когда одному пользователю необходимо «видеть» клиентов нескольких подразделений? Также часто возникает ситуация, когда одному пользователю разрешается только запрашивать данные из одной таблицы, в другой он может еще редактировать, но не удалять, а в третьей просматривать и удалять. Городить несметное количество представлений, триггеров и настоечных таблиц становится уж очень неудобно…
Технология RLS
Технология RLS (row-level security или безопасность на уровне строк) предоставляет возможность создания политик безопасности, которые ограничивают доступ пользователям к информации в БД. Как уже упоминалось выше, политики безопасности позволяют либо «закрыть» информацию полностью или частично, либо разрешить лишь определенные операции над ней. Технология была впервые представлена в Oracle 8i, но в последующих версиях ее возможности были значительно расширены.
При связи объекта БД с политикой безопасности контроль доступа осуществляется через логику, занесенную в специальную PL/SQL-функцию. Согласитесь, что гораздо проще поддерживать несколько программных функций, нежели десятки представлений, разнесенных по N-ому количеству схем.
При непосредственном или косвенном доступе пользователя к объекту БД (таблице, представлению) сервер динамически модифицирует оператор SQL, добавляя к нему предикат WHERE, который возвращается функцией безопасности.
Функция безопасности
Итак, теперь пришло время рассмотреть пример простейшей функции безопасности. Как уже отмечалось, задача функции – формирование предиката, который будет автоматически добавлен к запросу пользователя.
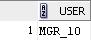
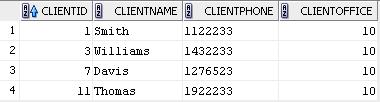
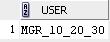
Приведенная выше функция будет добавлять предикат WHERE clientoffice = office_no к SQL запросу пользователя, где office_no – номер подразделения, в котором работает пользователь. Для пользователя с логином MGR_10_20_30 будет добавляться предикат WHERE clientoffice in (10, 20, 30). Таким образом, этот пользователь будет иметь доступ к информации о клиентах трех подразделений.
Процедуры пакета DBMS_RLS
Add_policy
Ну что ж, к данному моменту мы проделали всю необходимую подготовительную работу, и нам осталось лишь добавить политику безопасности в нашу БД. Политика безопасности регистрируется процедурой пакета DBMS_RLS add_policy:
Добавим политику безопасности для таблицы clients:
Теперь вкратце об использованных нами параметрах процедуры:
object_schema и object_name – таблица, представление или синоним, для которого добавляется политика, и схема БД, в которой находится объект.
policy_name – имя добавляемой политики безопасности. Имя должно быть уникально для каждой таблицы или представления в отдельности.
function_schema и policy_function – имя функции безопасности, которая генерирует предикат, и схема БД, в которой находится функция.
statement_types – операторы, к которым применяется политика безопасности.
update_check – опция предотвращает операции INSERT или UPDATE, если INSERT или UPDATE нарушает условия поиска определенные в предикате.
Теперь мы можем посмотреть политику безопасности в действии:

Для пользователя MGR_10:
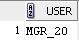
Для пользователя MGR_20:

Для пользователя MGR_10_20_30:

Информация о представлениях в БД хранится в представлениях user_policies, all_policies, dba_policies. Выполним запрос из-под пользователя с правами DBA:

Drop_policy
Соответственно, раз есть процедура создания политики безопасности, то есть и процедура удаления ее:
Попробуем удалить нашу политику безопасности:
Проверим теперь наличие политик в БД юзером с правами DBA:

Enable_policy
Кроме операций добавления/удаления политик безопасности существует возможность временно приостановить действие существующих политик. Для этого служит процедура enable_policy, которая переводит политику в неактивное состояние (enable => false) или возобновляет действие политики (enable => true):



Самые внимательные, я думаю, заметили параметр enable процедуры add_policy пакета dbms_rls. Этот параметр указывает на то, будет ли политика активной или неактивной сразу после создания. По умолчанию значение true.
Refresh_policy
Процедура позволяет обновить предикат политики RLS. Если политика безопасности определена с типом, отличным от DYNAMIC, предикат политики может некоторое время не обновляться, т.к. он кэширован в памяти. Поэтому если есть необходимость обновить политику немедленно, то нужно выполнить процедуру REFRESH_POLICY, которая заново выполнит функцию политики и обновит в кэше предикат.
Заключение
В настоящей статье рассмотрен простейший пример, как говорится, «на пальцах». В следующей статье мы рассмотрим безопасность с использованием контекстов и групп политик.

Большинство программ PL/SQL работает только с базой данных Oracle через SQL . Однако время от времени возникает необходимость в передаче информации из PL/ SQL во внешнюю среду или чтении информации из внешнего источника (экран, файл и т. д.) в PL/SQL .
Пакет DBMS_OUTPUT предоставляет средства вывода информации из программ в буфер. Далее содержимое буфера читается и обрабатывается другой программой PL/SQL или управляющей средой. Пакет DBMS_OUTPUT чаще всего используется для простого вывода информации на экран.
Запись информации в буфер выполняется при помощи программ DBMS_OUTPUT.PUT и DBMS_0UTPUT.PUT_LINE , а чтение на программном уровне — при помощи программ DBMS OUTPUT.GET LINE или DBMS OUTPUT.GET LINES .
Классификация СУБД
Управление данными
В первую очередь, в функции СУБД входит обработка информации во внешней памяти, и данная функция представляет собой обеспечение основных структур ВП, которые нужны не только для хранения информации, непосредственно включенной в базу данных, но и для исполнения различных служебных задач, таких как получение ускоренного доступа к каким-либо файлам в различных случаях. В определенных модификациях активно применяются возможности различных файловых систем, в то время как другие предусматривают проведение работ даже на уровне устройств внешней памяти.
По способу доступа к БД
В файл-серверных СУБД файлы данных располагаются централизованно на файл-серверные. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Примеры: Microsoft Access, Paradox, dBase, Visual FoxPro.
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы. Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
Версии Oracle
Самая новая версия СУБД — 21c. Она включает больше 200 инноваций, в том числе поддержку неизменяемых блокчейн-таблиц, поддержку JavaScript, встроенную в СУБД, поддержку типа данных JSON в бинарном формате и другие.
Для актуальных версий временами появляются обновления и пакеты патчей, которые называются PSU. Они расширяют возможности СУБД. Кроме того, Oracle предлагает использовать систему вместе с другими платными продуктами корпорации. Это Oracle Server, Oracle RPAS и другие решения в области информационных технологий. Для обучения можно пользоваться специальной бесплатной версией Express Edition (XE) или специальным облачным набором Always Free. Их можно скачать на сайте Oracle.
Data Science с нуля
Научитесь выявлять закономерности в данных и создавать модели для решения реальных бизнес-задач.
История
История развития СУБД насчитывает более 30 лет. В 1968 году была введена в эксплуатацию первая промышленная СУБД – система IMS фирмы IBM. (Information Management System). Несмотря на то, что IMS является самой первой из всех коммерческих СУБД, она до сих пор остается основной иерархической СУБД, используемой на большинстве крупных мейнфреймов. 1-й этап развития СУБД связан с организацией БД на больших машинах типа IBM360/370. БД хранились во внешней памяти центральной ЭВМ. Программы доступа к БД писались на различных языках. Интерактивный доступ обеспечивался с помощью консольных терминалов, которые не обладали собственными вычислительными ресурсами, и служили только устройствами ввода- вывода для центральной ЭВМ. На втором этапе - с появлением ПК начали развиваться настольные СУБД с монопольным доступом. Большинство СУБД имели удобный пользовательский интерфейс. В них был предусмотрен интерактивный режим работы с БД, как для описания БД, так и для проектирования запросов. Многие СУБД имели развитый и удобный инструментарий для разработки готовых приложений без программирования. Наличие монопольного режима работы, фактически, привело к вырождению функций администрирования БД, и в связи с этим в них отсутствовали инструментальные средства администрирования БД. Третий этап развития СУБД связан с широким развитием локальных сетей. Работа на изолированном компьютере с небольшой БД в настоящее время становится нехарактерной для большинства приложений. Компьютеры объединяются в сети и необходимость распределения приложений, работающих с единой БД совершенно очевидна. БД при этом становится доступна одновременно многим пользователям. Поэтому важной является проблема согласованности данных, хранящихся и обрабатывающихся в разных местах, но логически друг с другом связанных. Возникают задачи, связанные с параллельной обработкой транзакций – последовательности операций над БД, переводящих ее из одного непротиворечивого состояния в другое непротиворечивое состояние. Успешное решение этих задач приводит к появлению распределенных БД и баз данных с распределенной обработкой, позволяющих организовать параллельную обработку информации и поддержку целостности БД.
Как работает Oracle Database
Информация в системе хранится в отдельных базах — инстансах (instance) или экземплярах БД. Это не физические, а логические понятия, которые состоят из процессов и оперативной памяти. Все содержимое одного экземпляра имеет единую системную глобальную область (SGA) — часть оперативной памяти, с которой работает.
Внутри экземпляров расположены логические пространства, которые называются табличными — tablespaces. Табличные пространства содержат компоненты данных — как файлы в папках. Файлы имеют расширение .dbf.
СУБД состоит из одного или нескольких инстансов и программного обеспечения, которое ими управляет. Система поддерживает работу с независимыми базами (PDB) в рамках одного инстанса. Она может работать и с мультиарендной архитектурой (CDB), где множественными клиентами управляет один экземпляр приложения. В Oracle поддерживаются кластеризация и секционирование — физическое разделение элементов баз данных без потери доступа.
Чтение содержимого буфера
Типичный случай использования DBMS_OUTPUT весьма тривиален: разработчик вызывает DBMS_0UTPUT.PUT_LINE и просматривает результаты на экране. Клиентская среда (например, SQI*Plus ) «за кулисами» вызывает соответствующие программы пакета DBMS_OUTPUT для чтения и вывода содержимого буфера.
Для получения содержимого буфера DBMS_OUTPUT используются процедуры GET_LINE и/или GET_LINES .
Процедура GET_LINE читает одну строку из буфера по принципу «первым пришел, первым вышел» и в случае успешного завершения возвращает код 0. Пример использования программы для чтения следующей строки из буфера в локальную переменную PL/SQL :
Процедура GET_LINES читает несколько строк из буфера за один вызов. Данные загружаются в коллекцию строк PL/SQL (максимальная длина от 255 до 32 767 в зависимости от версии Oracle ). Вы указываете количество читаемых строк, а процедура возвращает их. Следующая программа записывает содержимое буфера DBMS_OUTPUT в журнальную таблицу базы данных:
DBMS (Database Management System) - система управления базами данных "СУБД" представляет собой организованную совокупность программных и лингвистических данных, которые включают в себя схемы , таблицы , запросы , отчеты, просмотры и другое. В сущности DBMS - это программа, которая позволяет взаимодействовать с базами данных как абстрактным объектом (без необходимости писать запросы).
Реляционные
Система управления реляционными базами данных — СУБД, управляющая реляционными базами данных.

В настоящем объектно-ориентированном языке — таком, как Java , — имеется корневой класс, производными от которого являются все остальные классы. (В Java он называется Object .) PL/SQL официально считается объектно-реляционным языком, но по своей сути он является реляционным процедурным языком, а в самой его основе лежит «корневой» пакет с именем STANDARD .
Пакеты PL/SQL, которые вы создаете, не являются производными от STANDARD , но почти каждая написанная вами программа будет зависеть от этого пакета и использовать его. Собственно, это один из двух используемых по умолчанию пакетов PL/SQL (второй — dbms_standard ).
Чтобы лучше понять роль этих пакетов в среде программирования, стоит вернуться к концу 1980-х годов, когда еще не было ни Oracle7 , ни SQL*Forms 3 , не было даже Oracle PL/SQL . Тогда выяснилось, что SQL — замечательный язык, но его возможности ограничены. Клиенты Oracle писали программы C, выполнявшие команды SQL , но эти программы приходилось изменять для каждой новой операционной системы.
Было решено создать язык программирования, который мог бы выполнять команды SQL и при этом работать во всех операционных системах, в которых установлена база данных Oracle . Также компания Oracle решила, что вместо изобретения собственного языка она проанализирует существующие языки и определит, не могут ли они стать прототипом для того, чем в будущем стал PL/SQL .
В итоге за прототип был взят язык Ada , изначально разработанный для Министерства обороны США. Конструкция пакетов была позаимствована из Ada . В этом языке можно задать «пакет по умолчанию» для любой программной единицы. Имена элементов пакета по умолчанию не нужно уточнять именем пакета (как в конструкциях вида мой_пакет. процедура).
При проектировании PL/SQL идея пакета по умолчанию была сохранена, но способ ее применения несколько изменился. Пользователи PL/SQL не могут задать пакет по умолчанию для программной единицы. В PL/SQL существует два пакета по умолчанию, STANDARD и DBMS_STANDARD . Они используются по умолчанию во всем языке, а не в конкретной программной единице.
Имена элементов этих пакетов почти всегда используются без уточнения имен. Пакет STANDARD объявляет набор типов, исключений и подпрограмм, автоматически доступных в любой программе PL/SQL ; многие программисты PL/SQL (ошибочно) считают их «зарезервированными словами» языка. При компиляции кода компилятор Oracle должен разрешить все идентификаторы без уточнения имен; сначала Oracle проверяет, объявлен ли элемент с таким именем в текущей области видимости. Если нет, Oracle проверяет, определен ли элемент с таким именем в пакете STANDARD или DBMS_STANDARD . Если все идентификаторы будут найдены успешно (и в коде не обнаружены синтаксические ошибки), то код компилируется.
Чтобы понять роль пакета STANDARD , рассмотрим следующий, очень странный блок кода PL/SQL . Как вы думаете, что произойдет при выполнении этого блока?
В действительности блок откомпилируется, но при его выполнении произойдет необработанное исключение NO_DATA_FOUND :
Странно, не правда ли? NO_DATA_FOUND , единственное исключение, которое обрабатывается в программе, — как оно осталось необработанным? Вопрос в том, какое исключение NO_DATA_FOUND обрабатывается в программе? В этом блоке мы объявляем собственное исключение с именем NO_DATA_FOUND . Это имя не является зарезервированным словом языка PL/SQL (в отличие, скажем, от BEGIN — объявить переменную с именем BEGIN невозможно). В спецификации пакета STANDARD одноименное исключение определяется следующим образом:
Так как в нашем блоке имеется локально объявленное исключение с именем NO_DATA_ FOUND , любые неуточненные ссылки на этот идентификатор в блоке считаются относящимися именно к нему, а не к исключению пакета STANDARD . Если команда SELECT INTO не находит ни одной строки, инициируется исключение STANDARD.NO_DATA_FOUND — а это совсем не то исключение, которое обрабатывается в разделе исключений.
С другой стороны, если привести строку 12 в разделе исключений к следующему виду:
то исключение будет успешно обработано, а программа выведет слово « Trapped !».
Кроме неоднозначной ситуации с NO_DATA_FOUND , следующие строки тоже выглядят довольно странно.
| Строки | Описание |
| 2 | Определение нового типа данных « DATE », который на самом деле относится к типу NUMBER |
| 3 | Объявление переменной « VARCHAR2 » типа DATA и присваивание ей значения 11111 |
| 4 | Объявление переменной « TO_CHAR » типа PLS_INTEGER |
Мы можем «использовать заново» эти имена «встроенных» элементов языка PL/ SQL , потому что все они определяются в пакете STANDARD . Эти имена не являются зарезервированными словами PL/SQL ; их просто и удобно использовать без указания имени пакета.
Пакет STANDARD содержит определения типов данных, поддерживаемых в PL/SQL , заранее определенных исключений и встроенных функций ( TO_CHAR , SYSDATE , USER и т. д.). Пакет DBMS_STANDARD содержит элементы, относящиеся к работе с транзакциями (такие, как commit и rollback ), а также функции триггерных событий inserting , deleting и updating . Несколько замечаний по поводу STANDARD :
- Никогда не изменяйте содержимое этого пакета. А если вы это сделаете, не обращайтесь в службу поддержки Oracle за помощью — ведь вы нарушили соглашение о сопровождении продукта! Чтобы вы могли изучить содержимое этого пакета и других пакетов (таких, как dbms_output — см. dbmsotpt.sql ) и dbms_utility (см. dbmsutil.sql ), администратор базы данных должен предоставить вам доступ только для чтения для каталога RDBMS/Admin .
- Oracle даже позволяет прочитать тело пакета STANDARD ; тела большинства пакетов (например, DBMS_SQL ) скрываются или защищаются псевдошифрованием. Загляните в сценарий stdbody.sql ; вы увидите, например, что функция USER всегда выполняет SELECT из SYS.dual , а SYSDATE выполняет запрос только в том случае, если при выполнении программы C для получения системной временной метки происходит ошибка.
- Присутствие некоторой конструкции в STANDARD еще не означает, что вы можете использовать точно такой же код в своих блоках PL/SQL . Например, вам не удастся объявить подтип с диапазоном значений, как это делается для BINARY_INTEGER .
- Если некоторый элемент определяется в STANDARD , это еще не означает, что его можно использовать в PL/SQL . Например, функция DECODE объявлена в STANDARD , но вызывать ее можно только из команд SQL .
Пакет STANDARD определяется в файлах stdspec.sql и stdbody.sql из каталога $ORACLE_HOME/ RDBMS/Admin (в ранних версиях базы данных этот пакет находился в файле standard.sql ). Пакет DBMS_STANDARD определяется в файле dbmsstdx.sql .
Если вам интересно, какие из многочисленных предопределенных идентификаторов являются зарезервированными словами в языке PL/SQL , воспользуйтесь сценарием reserved_words.sql .
Кроме рассмотренной темы, программист PL/SQL должен очень хорошо представлять модели предоставления доступа в СУБД Oracle.
Oracle Database — это объектно-реляционная система управления базами данных (СУБД) от компании Oracle. Она используется для создания структуры новой базы, ее наполнения, редактирования содержимого и отображения информации.
Продукт Oracle Database часто называют просто Oracle, по названию компании. Еще одно популярное сокращение — Oracle DB, от английского слова database — «база данных». Oracle RDBMS (Relational Database Management System) — третье название системы.
Что делает СУБД
Для работы с базой используется СУБД. Она позволяет:
- формулировать запросы в виде кода, чтобы находить и получать информацию;
- создавать новые записи, редактировать и удалять существующие;
- разделять и объединять данные, которые хранятся в разных местах;
- управлять доступом к информации;
- выполнять параллельно разные действия;
- создавать резервные копии информации и восстанавливать базу после сбоев;
- управлять транзакциями — последовательными наборами запросов;
- настраивать и обеспечивать безопасность, конфиденциальность информации.
Системы управления поддерживают SQL, иногда другие языки для работы с базами данных. Правда, альтернативные языки используются очень редко.
Data Science с нуля
Станьте востребованным специалистом, изучив набор инструментов, необходимый для уровня junior. Наш карьерный центр поможет вам оформить резюме и начать проходить собеседования.
По степени распределённости
- Локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
- Распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах).
Объектно-ориентированные
Управляют базами данных, в которых данные моделируются в виде объектов, их атрибутов, методов и классов. Этот вид СУБД позволяет работать с объектами баз данных так же, как с объектами в программировании в объектно-ориентированных языках программирования.
По характеру записи
СУБД делятся на два типа:
СУБД, в которых все измененные блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия используется только при высокой эффективности внешней памяти.
СУБД, в которых изменения аккумулируются в буферах внешней памяти до наступления конкреного события.
Состав СУБД
СУБД представляет собой оболочку, с помощью которой при организации структуры таблиц и заполнения их данными получается та или иная база данных. В связи с этим полезно поговорить о системе программно-технических, организационных и "человеческих" составляющих ( рис. 2.5). Программные средства включают систему управления, обеспечивающую ввод-вывод, обработку и хранение информации, создание, модификацию и тестирование БД. . [Источник 2]

Базовыми внутренними языками программирования являются языки четвертого поколения. В качестве базовых языков могут использоваться C, C++, Object Pascal . Язык C++ позволяет строить программы на языке Visual Basic с широким спектром возможностей, более близком и понятном даже пользователю-непрофессионалу, и на непроцедурном (декларативном) языке структурированных запросов SQL. Следует отметить, что исторически для системы управления базой данных сложились три языка: 1. язык описания данных (ЯОД), называемый также языком описания схем, - для построения структуры ("шапки") таблиц БД; 2. язык манипулирования данными (ЯМД) - для заполнения БД данными и операций обновления (запись, удаление, модификация); 3. язык запросов - язык поиска наборов величин в файле в соответствии с заданной совокупностью критериев поиска и выдачи затребованных данных без изменения содержимого файлов и БД (язык преобразования критериев в систему команд). В настоящее время функции всех трех языков выполняет язык SQL, относящийся к классу языков, базирующихся на исчислении кортежей (кортеж чаще всего является единицей информации), языки СУБД FoxPro, Visual Basic for Application (СУБД Access) и т.д.
По модели данных — объектно-реляционная
Это значит, что система объединяет в себе две модели хранения информации: объектно-ориентированную и реляционную.
Реляционная модель представляется как набор отношений между записями. Одни данные связаны с другими — так формируется база. Визуально ее можно представить как двумерную таблицу; математически — как модель, построенную на отношениях.
Объектно-ориентированная модель воспринимает данные как объект. У объекта есть атрибуты, которые описывают его свойства, и методы — они нужны для взаимодействия с другими объектами. Каждый объект принадлежит к классу — это понятие можно представить как «схему» объекта. Объектно-ориентированный подход используется во многих языках программирования и упоминается во многих наших статьях. А в базах данных он нужен для работы с данными, у которых сложная структура.
Oracle Database работает и с объектно-ориентированной, и с реляционной моделью.
Сетевые
Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Запись в буфер
Запись информации в буфер осуществляется двумя встроенными процедурами: PUT_ LINE присоединяет маркер новой строки после текста, а PUT помещает текст в буфер без маркера новой строки. Информация, выведенная PUT , останется в буфере даже при завершении вызова. В этом случае следует вывести ее с очисткой буфера вызовом
Если Oracle знает, как неявно преобразовать ваши данные в строку VARCHAR2 , то эти данные можно передать при вызове программ PUT и PUT_LINE . Примеры:
К сожалению, DBMS_OUTPUT не умеет выполнять такое преобразование для многих распространенных типов PL/SQL , прежде всего для BOOLEAN . В таких случаях стоит написать небольшую утилиту, упрощающую вывод логических значений:
Максимальная длина строки, которая может передаваться за один вызов DBMS_OUTPUT. PUT_LINE , в последних версиях Oracle составляет 32 767 байт. В Oracle10g Release 1 и ранее действовало ограничение в 255 байт. В любой версии при передаче строки с длиной более допустимого максимума происходит исключение ( VALUE_ERROR или ORU-10028 ). Чтобы избавиться от этой проблемы, используйте инкапсуляцию DBMS_OUTPUT. PUT_LINE , которая автоматически разрывает длинные строки. В следующих файлах, доступных на сайте книги, представлены вариации на эту тему:
- pl.sp — автономная процедура позволяет указать длину разрыва строки.
- p.pks/pkb — пакет p представляет собой масштабную инкапсуляцию DBMS_OUTPUT. PUT_LINE с множеством разных перегрузок (например, вызовом процедуры p.l можно вывести документ XML или файл операционной системы), а также с возможностью разрыва длинного текста.
Содержание
Управление транзакциями
Транзакция является последовательностью операций с используемой базой данных, которые система управления рассматривает в качестве единого целого. Если транзакция полностью успешно исполняется, системой фиксируются изменения, которые были ею произведены, во внешней памяти или никакие из указанных изменений не будут отражаться на состоянии БД. Данная операция требуется для того, чтобы обеспечить поддержку логической целостности используемой БД. Стоит отметить, что поддержание правильного хода механизма транзакций является обязательным условием даже при применении однопользовательских СУБД, назначение и функции которых значительно отличаются от других типов систем.
Включение DBMS_OUTPUT
По умолчанию пакет DBMS_OUTPUT отключен, поэтому вызовы программ PUT_LINE и PUT игнорируются, а буфер остается пустым. Обычно включение DBMS_OUTPUT осуществляется специальной командой в управляющей среде. Например, в программе SQL*Plus выполняется следующая команда:
Кроме включения вывода на консоль, эта команда передает серверу базы данных следующую команду:
(Параметр buffer_size со значением NULL означает неограниченный буфер; также может передаваться конкретное значение размера в байтах.) SQL*Plus поддерживает ряд дополнительных параметров команды SERVEROUTPUT ; за дополнительной информацией обращайтесь к документации своей версии.
Среды разработки (например, Oracle SQL Developer или Quest Toad ) обычно выводят результаты DBMS_OUTPUT в специально назначенной части экрана — конечно, для этого вывод должен быть предварительно включен.
Основные функции СУБД
- управление данными во внешней памяти (на дисках); - управление данными в оперативной памяти с использованием дискового кэша; - журнализация изменений, резервное копирование и восстановление базы данных после сбоев; - поддержка языков БД (язык определения данных, язык манипулирования данными). Обычно современная СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию, - процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода, - подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД - а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы. [Источник 3]
Управление буферами ОЗУ
В преимущественном большинстве случаев функции СУБД принято использовать в достаточно объемных базах данных, и этот размер как минимум зачастую гораздо больше доступного объема ОЗУ. Конечно, если в случае обращения к каждому элементу данных будет осуществляться обмен с внешней памятью, скорость последней будет соответствовать скорости самой системы, поэтому практически единственным вариантом реального ее увеличения является буферизация информации в ОЗУ. При этом даже если ОС осуществляет общесистемную буферизацию, например с UNIX, этого не будет достаточно для того, чтобы обеспечивать у СУБД назначение и основные функции, так как она располагает гораздо большим объемом данных о полезных свойствах буферизации каждой конкретной части используемой базы данных. За счет этого развитые системы поддерживают собственный комплект буферов, а также уникальную дисциплину их замены.
По характеру использования
- Персональные (совокупность языковых и программных средств, нужных для создания и управления базами данных - VISUAL FOXPRO, ACCESS).
- Многопользовательские (использует разные операционные системы и включают в себя сервер базы данных и клиентскую часть) - ORACLE, INFORMIX.
Система управления базами данных
Система управления базами данных ( СУБД ) представляет собой компьютерное программное обеспечение, которое взаимодействует с пользователем, другими приложениями, а также отвечает за обработку запросов к базе данных , собирает и анализирует их. СУБД предназначена для определения, создания, выборки, обновления и администрирования баз данных Хорошо известная СУБД включает MySQL , PostgreSQL , MongoDB , MariaDB , Microsoft SQL Server , Oracle , Sybase , SAP HANA , MemSQL и IBM DB2 . База данных, как правило, не переносимы между разными СУБД, но разных СУБД могут взаимодействовать с помощью стандартов, таких как SQL и ODBC или JDBC для одного приложения для работы с более чем одной СУБД Системы управления базами данных часто классифицируются в зависимости от модели базы данных, которые они поддерживают, самые популярные систем баз данных с 1980-х годов представлены на языке SQL. Но может быть написана как на традиционных языках программирования (С/C++, Cobol и др.), так и на специализированных языках баз данных. . [Источник 1]
Объектно-реляционные
Этот тип СУБД позволяет через расширенные структуры баз данных и язык запросов использовать возможности объектно-ориентированного подхода: объекты, классы и наследование.
По способу доступа — клиент-серверная
Система работает по принципу «клиент — сервер». Это означает, что ее основная часть размещается на сервере, там же, где и база данных. Человек работает с интерфейсом приложения-клиента. Клиентская часть управляет только пересылкой и получением информации от сервиса.
Связь между клиентом и сервером обеспечивает специальный компонент, который в Oracle называется SQL *Net.
Достоинства такого подхода — в высоком уровне безопасности и легком доступе для клиентов. Клиент-серверная организация разгружает сеть и снимает вычислительную нагрузку с клиентских компьютеров. А вот сервер для такой СУБД должен быть мощным.
Полная документация по СУБД называется Oracle Concepts. Для прежних версий системы она есть на русском языке, для новых — на английском.
Что такое базы данных
База данных — это организованная структура для хранения, изменения информации и взаимодействия с ней.
Они бывают двух видов:
- нереляционные. Такие БД имеют специфическую структуру: например, данные хранятся в формате ключ-значение или в виде дерева;
- реляционные. В таких БД данные хранятся в виде связанных таблиц.
Каждая таблица обычно содержит данные, относящиеся к похожим объектам. У каждой таблицы есть название: оно соотносится с тем, какая информация хранится в таблице.
Таблицы состоят из строк и столбцов. Каждый столбец имеет уникальное название, которое также отмечает вид хранимой информации. В каждой строке находится информация об одном объекте. Таблица содержит конкретное число столбцов, но может иметь любое количество строк.
В таблице ниже представлена информация о клиентах: имя, адрес, выручка и др., — разбитая на столбцы и строки.
Для связи данных в разных таблицах часто используют ID — уникальный идентификатор строки. Имя или какой-либо признак с этой целью не используются, поскольку они могут быть неуникальными.
Обращаться с таким хранилищем намного сложнее, чем с обычной таблицей. Число записей может исчисляться миллионами. Чтение информации вручную практически невозможно, поэтому для работы с БД используется особый язык программирования. Он называется SQL, и ему посвящена отдельная статья. Там же подробно рассказано про особенности хранения информации в базах.
Что представляет собой Oracle Database
Иерархические
Используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней. Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка к потомку , при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами .
Читайте также: