
Oracle что нужно знать для собеседования
SQL — один из самых востребованных навыков в современной IT индустрии (на 3 месте по популярности согласно StackOverflow Developer Survey 2020, даже Python идет на 4 месте).
Само собой, конкуренция в этой сфере огромна и собеседования порой превращаются в сущую пытку — кандидатам дают огромные задачи, задают десятки каверзных вопросов, устраивают дизайн-интервью и все это на позицию Junior аналитика…
Сегодня Елизавета, аналитик и эксперт IT Resume, делится 5 задачами и вопросами, которые входят в программу подготовки к собеседованию SQL Interview. Это задачи с реальных собеседований в крупные IT-компании, и они разбиты по уровням — Junior, Middle и Senior. Попробуйте и вы свои силы — сможете их решить без подсказки 😉
Вводные данные
Есть таблица анализов Analysis:
- an_id — ID анализа;
- an_name — название анализа;
- an_cost — себестоимость анализа;
- an_price — розничная цена анализа;
- an_group — группа анализов.
Есть таблица групп анализов Groups:
- gr_id — ID группы;
- gr_name — название группы;
- gr_temp — температурный режим хранения.
Есть таблица заказов Orders:
- ord_id — ID заказа;
- ord_datetime — дата и время заказа;
- ord_an — ID анализа.
Далее мы будем работать с этими таблицами.
№ 2. Маркировка древовидной структуры
Контекст: предположим, у вас есть таблица tree с двумя столбцами: в первом указаны узлы, а во втором — родительские узлы.
Задача: написать SQL таким образом, чтобы мы обозначили каждый узел как внутренний (inner), корневой (root) или конечный узел/лист (leaf), так что для вышеперечисленных значений получится следующее:
(Примечание: более подробно о терминологии древовидной структуры данных можно почитать здесь. Однако для решения этой проблемы она не нужна!)
Решение:
Благодарность: это более обобщённое решение предложил Фабиан Хофман 2 мая 2020 года. Спасибо, Фабиан!
Альтернативное решение, без явных соединений:
Благодарность: Уильям Чарджин 2 мая 2020 года обратил внимание на необходимость условия WHERE parent IS NOT NULL , чтобы это решение возвращало Leaf вместо NULL . Спасибо, Уильям!
При выборке из таблицы прибавьте к дате 1 день
Функция DATE_ADD() прибавляет к дате заданный промежуток времени. Синтаксис выглядит следующим образом:
Какими бывают подстановочные знаки?
- % — заменить ноль или более символов;
- _ — заменить один символ.
Данный запрос позволяет найти данные всех пользователей, имена которых содержат в себе «test».
А в этом случае имена искомых пользователей начинаются на «t», после содержат какой-либо символ и «est» в конце.
Какие типы СУБД в соответствии с моделями данных вы знаете?
Этот вопрос по SQL предполагает не просто назвать, но и дать краткое описание каждому типу.
- Реляционные, которые поддерживают установку связей между таблицами с помощью первичных и внешних ключей. Пример — MySQL.
- Flat File — базы данных с двумерными файлами, в которых содержатся записи одного типа и отсутствует связь с другими файлами, как в реляционных. Пример — Excel.
- Иерархические подразумевают наличие записей, связанных друг с другом по принципу отношений один-к-одному или один-ко-многим. А вот для отношений многие-ко-многим следует использовать реляционную модель. Пример — Adabas.
- Сетевые похожи на иерархические, но в этом случае «ребёнок» может иметь несколько «родителей» и наоборот. Примеры — IDS и IDMS.
- Объектно-ориентированные СУБД работают с базами данных, которые состоят из объектов, используемых в ООП. Объекты группируются в классы и называются экземплярами, а классы в свою очередь взаимодействуют через методы. Пример — Versant.
- Объектно-реляционные обладают преимуществами реляционной и объектно-ориентированной моделей. Пример — IBM Db2.
- Многомерная модель является разновидностью реляционной и использует многомерные структуры. Часто представляется в виде кубов данных. Пример — Oracle Essbase.
- Гибридные состоят из двух и более типов баз данных. Используются в том случае, если одного типа недостаточно для обработки всех запросов. Пример — Altibase HDВ.
Часть 3
Примечание: вероятно, это более сложная задача, чем вам предложат на реальном собеседовании. Воспринимайте её скорее как головоломку — или можете пропустить и перейти к следующей задаче.
Контекст: итак, мы хорошо справились с двумя предыдущими проблемами. По условиям новой задачи теперь у нас появилась таблица потерянных пользователей user_churns . Если пользователь была активен в прошлом месяце, но затем не активен в этом, то он вносится в таблицу за этот месяц. Вот как выглядит user_churns :
Задача: теперь вы хотите провести когортный анализ, то есть анализ совокупности активных пользователей, которые были реактивированы в прошлом. Создайте таблицу с такими пользователями. Для создания когорты можете использовать таблицы user_churns и logins . В Postgres текущая временная метка доступна через current_timestamp .
№ 1. Процентное изменение месяц к месяцу
Контекст: часто полезно знать, как изменяется ключевая метрика, например, месячная аудитория активных пользователей, от месяца к месяцу. Допустим у нас есть таблица logins в таком виде:
Задача: найти ежемесячное процентное изменение месячной аудитории активных пользователей (MAU).
Решение:
(Это решение, как и другие блоки кода в этом документе, содержит комментарии об элементах синтаксисе SQL, которые могут отличаться между разными вариантами SQL, и прочие заметки)
Вопрос 2. Уровень Middle
Этот вопрос не такой хитрый, как предыдущий, а вполне себе конкретный. Однако, он требует знания оконных функций и их тонкостей, а это исконное Middle требование.
Вопрос: В чем отличие функции RANK() от DENSE_RANK() ?
Примечание Кстати говоря, по мотивам этого вопроса очень любят давать задачи на собеседованиях в разных вариациях: пронумеровать строки с одинаковыми значениями без разрывов, с разрывами и так далее. Так что потренируйтесь на досуге 🙂
По аналогии с функцией ROW_NUMBER , оконные функции RANK и DENSE_RANK служат для нумерации строк. Однако, делают они это немного иначе: строки с одинаковым значениям получают одинаковый ранг. Для ряда задач это логично: если у двух сотрудников одинаковая зарплата, мы не можем сказать, что кто-то из них первый, а кто-то второй. Они одинаковы. Но при таком подходе возникает проблема: а какой ранг должен получить следующий сотрудник? Например, если первые два были одинаковые и у них ранги 1, то сотрудник со второй зарплатой в компании должен иметь ранг 2 или 3?
Что делают псевдонимы Aliases?
SQL-псевдонимы нужны для того, чтобы дать временное имя таблице или столбцу. Это нужно, когда в запросе есть таблицы или столбцы с неоднозначными именами. В этом случае для удобства в составлении запроса используются псевдонимы. SQL-псевдоним существует только на время запроса.
№ 3. Удержание пользователей в месяц (несколько частей)
Для чего используется ключевое слово ORDER BY?
Для сортировки данных в порядке возрастания ( ASC ) или убывания ( DESC ).
Выбираются пользователи, которые будут отсортированы по имени в порядке убывания. Дополните ответ на этот вопрос по SQL тем, что без указания DESC данные были бы отсортированы по умолчанию — в порядке возрастания:
№ 2. Перекрёстное соединение (несколько частей)
Как найти дубли в поле email?
Функция COUNT() возвращает количество строк из поля email . Оператор HAVING работает почти так же, как и WHERE , вот только применяется не для всех столбцов, а для набора, созданного оператором GROUP BY .
Чем VARCHAR отличается от NVARCHAR?
Главное отличие в том, что VARCHAR хранит значения в формате ASCII, где символ занимает один байт, а NVARCHAR хранит значения в формате Unicode, где символ «весит» 2 байта. Тип VARCHAR следует использовать, если вы уверены, что в значениях не будет Unicode-символов. Например, VARCHAR можно применить к адресам электронной почты, состоящих из ASCII-символов.
Часть 1
Контекст: допустим, у нас есть таблица state_streams , где в каждой строке указано название штата и общее количество часов потоковой передачи с видеохостинга:
(На самом деле в агрегированных таблицах такого типа обычно есть ещё столбец даты, но для этой задачи мы его исключим)
Задача: написать запрос, чтобы получить пары штатов с общим количеством потоков в пределах тысячи друг от друга. Для приведённого выше фрагмента мы хотели бы увидеть что-то вроде:
Для информации, перекрёстные соединения также можно писать без явного указания соединения:
Для чего нужен оператор UNION?
Он используется для объединения полученных данных из двух или более запросов, которые должны иметь одинаковое количество столбцов с одинаковыми типами данных и расположенных в том же порядке.
№ 6. Несколько условий соединения
Благодарность: эта задача адаптирована из статьи в блоге SiSense «Анализ вашей электронной почты с помощью SQL».
Теория
А что такое внешний ключ?
Внешний ключ или FOREIGN KEY также является атрибутом ограничения и обеспечивает связь двух таблиц. По сути, это поле или несколько полей, которые ссылаются на PRIMARY KEY в родительской таблице.
В данном случае внешний ключ, привязанный к полю user_id в таблице order , ссылается на первичный ключ id в таблице users , и именно по этим полям происходит связывание двух таблиц.
Задача 3: Уровень Senior
В этой задаче мы будем работать с другой таблицей (да, она будет всего одна). Сам запрос в этой задаче не сложный, но для его написания необходимо как бы уметь «мыслить на SQL».
Рассмотрим таблицу балансов клиентов:
ClientBalance(client_id, client_name, client_balance_date, client_balance_value)
- client_id — идентификатор клиента;
- client_name — ФИО клиента;
- client_balance_date — дата баланса клиента;
- client_balance_value — значение баланса клиента.
Формулировка: в данной таблице в какой-то момент времени появились полные дубли. Предложите способ для избавления от них без создания новой таблицы.

Вопрос 1. Уровень: Junior
Есть категория «хитрых» вопросов, которые особенно любят задавать Junior-специалистам. Хотя чего уж там, любым специалистам.
Один из таких видов — вопросы по темам, на которые в повседневной жизни не обращаешь внимания и о которых не задумываешься. Просто делаешь на автомате, а на собеседовании это стреляет. Ну или на проекте, когда код начинает работать неправильно. Но это другая история…
Вопрос: Как оператор GROUP BY обрабатывает поля с NULL?
Если Вы не знаете ответ на этот вопрос, то после прочтения ответа обязательно проверьте свои проекты — может у вас где-то закралась ошибка? 😉
Учитывая, что NULL в SQL — просто отсутствие значения, то все значения NULL при группировке попадают в одну группу. Например, пусть есть таблица:
Тогда запрос select sum(score) from table group by name даст:
Часть 2
Задача: напишите запрос, который добавляет столбец с позицией каждого сотрудника в табели на основе его зарплаты в своём отделе, где сотрудник с самой высокой зарплатой получает позицию 1. Мы бы ожидали таблицу в таком виде:
Часть 1
Контекст: допустим, у нас есть таблица salaries в таком формате:
Задача: написать запрос, который возвращает ту же таблицу, но с новым столбцом, в котором указана средняя зарплата по департаменту. Мы бы ожидали таблицу в таком виде:
Задача 2. Уровень: Middle
Формулировка: нарастающим итогом рассчитать, как увеличивалось количество проданных тестов каждый месяц каждого года с разбивкой по группе.
Эта задача уже более высокого уровня: ее можно давать как Middle, так и Junior специалистам. Здесь проверяется базовое понимание оконных функций, джоинов и группировок.
Примечание После того, как вы написали первую версию своего запроса, попробуйте его оптимизировать. Например, в данном примере мы используем CTE — обобщенные табличные выражения.

Найдите в таблице среднюю зарплату работников
Функция AVG() применяется только к числовым типам данных и возвращает среднее значение по столбцу.
Задача 1. Уровень: Junior
Формулировка: вывести название и цену для всех анализов, которые продавались 5 февраля 2020 и всю следующую неделю.

Это задача для начинающих специалистов. В ней проверяется базовое знание SELECT-запросов и умение работать с датой-временем.
Примечание На собеседованиях редко придираются к специфике диалекта — если Вы привыкли работать в PostgreSQL, то используйте привычные функции. Главное — правильно решить задачу.

№ 4. Нарастающий итог
Благодарность: эта задача адаптирована из статьи в блоге SiSense «Моделирование денежных потоков в SQL».
Контекст: допустим, у нас есть таблица transactions в таком виде:
Где cash_flow — это выручка минус затраты за каждый день.
Задача: написать запрос, чтобы получить нарастающий итог для денежного потока каждый день таким образом, чтобы в конечном итоге получилась таблица в такой форме:
Альтернативное решение с использованием оконной функции (более эффективное!):
Часть 1
Контекст: допустим, у нас есть статистика по авторизации пользователей на сайте в таблице logins :
Задача: написать запрос, который получает количество удержанных пользователей в месяц. В нашем случае данный параметр определяется как количество пользователей, которые авторизовались в системе и в этом, и в предыдущем месяце.
Благодарность:
Том Моэртел указал на то, что предварительная дедубликация user_id перед самообъединением делает решение более эффективным, и предложил код ниже. Спасибо, Том!
Практика
Что такое нормализация и денормализация?
Нормализация отношений в SQL призвана организовать информацию в базе данных таким образом, чтобы она не занимала много места и с ней было удобно работать. Это удаление избыточных данных, устранение дублей, идентификация наборов связанных данных через PRIMARY KEY , etc.
Соответственно, денормализация является обратным процессом, который вносит в нормализованную таблицу избыточные данные.
Подробнее о пяти нормальных формах и форме Бойса-Кодда можно узнать из данного видеокурса:
Для чего нужен оператор INSERT INTO SELECT?
Данный оператор копирует данные из одной таблицы и вставляет их в другую, при этом типы данных в обеих таблицах должны соответствовать.
Когда используется PRIMARY KEY?
PRIMARY KEY — это первичный ключ, который используется в качестве основного ключа и может быть использован для связи с дочерней таблицей, содержащей внешний ключ.
Какие ещё ограничения вы знаете, как они работают и указываются?
SQL-ограничения (constraints) указываются при создании или изменении таблицы. Это правила для ограничения типа данных, которые могут храниться в таблице. Действие с данными не будет выполнено, если нарушаются установленные ограничения.
- UNIQUE — гарантирует уникальность значений в столбце;
- NOT NULL — значение не может быть NULL ;
- INDEX — создаёт индексы в таблице для быстрого поиска/запросов;
- CHECK — значения столбца должны соответствовать заданным условиям;
- DEFAULT — предоставляет столбцу значения по умолчанию.
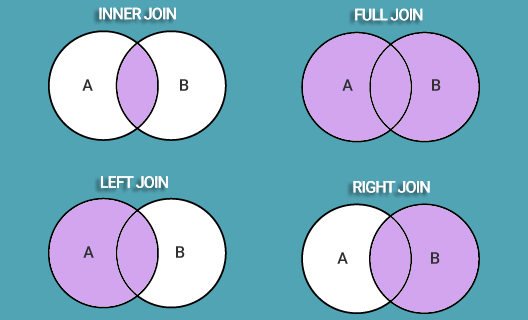
Назовите четыре основных типа соединения в SQL
Чтобы объединить две таблицы в одну, следует использовать оператор JOIN . Соединение таблиц может быть внутренним ( INNER ) или внешним ( OUTER ), причём внешнее соединение может быть левым ( LEFT ), правым ( RIGHT ) или полным ( FULL ).
- INNER JOIN — получение записей с одинаковыми значениями в обеих таблицах, т.е. получение пересечения таблиц.
- FULL OUTER JOIN — объединяет записи из обеих таблиц (если условие объединения равно true) и дополняет их всеми записями из обеих таблиц, которые не имеют совпадений. Для записей, которые не имеют совпадений из другой таблицы, недостающее поле будет иметь значение NULL .
- LEFT JOIN — возвращает все записи, удовлетворяющие условию объединения, плюс все оставшиеся записи из внешней (левой) таблицы, которые не удовлетворяют условию объединения.
- RIGHT JOIN — работает точно так же, как и левое объединение, только в качестве внешней таблицы будет использоваться правая.
Рассмотрим пример соединения SQL таблиц с использованием INNER JOIN . Следующий запрос выбирает все заказы с информацией о клиенте:
Объясните разницу между командами DELETE и TRUNCATE
Команда DELETE — это DML-операция, которая удаляет записи из таблицы, соответствующие заданному условию:
При этом создаются логи удаления, то есть операцию можно отменить.
А вот команда TRUNCATE — это DDL-операция, которая полностью пересоздаёт таблицу, и отменить такое удаление невозможно:
Как работают подстановочные знаки?
Это специальные символы, которые нужны для замены каких-либо знаков в запросе. Они используются вместе с оператором LIKE , с помощью которого можно отфильтровать запрашиваемые данные.
Эпилог
Мы разобрали с вами всего 5 возможных заданий, которые судьба и рекрутеры могут подкинуть вам на собеседовании. Однако, вариантов, на самом деле, масса. И чтобы реально подготовиться к собеседованию, нужно нарешать как можно больше задач, понять и прочувствовать теоретические аспекты и буквально научиться «мыслить на SQL». Именно на это и нацелена программа SQL Interview — так что будем рады помочь вам получить работу мечты!
И, помимо этого, не забывайте: SQL — чисто прикладной инструмент. Чтобы его освоить, нужно практиковаться, практиковаться и практиковаться. Выучить его можно буквально за несколько недель интенсивных занятий, а вот освоить на уровне Senior… порой на это уходят годы.

Реляционные базы данных являются одними из наиболее часто используемых баз данных по сей день, и поэтому навыки работы с SQL для большинства должностей являются обязательными. В этой статье с вопросами по SQL с собеседований я познакомлю вас с наиболее часто задаваемыми вопросами по SQL (Structured Query Language — язык структурированных запросов). Эта статья является идеальным руководством для изучения всех концепций, связанных с SQL, Oracle, MS SQL Server и базой данных MySQL.
Вопрос 1. В чем разница между операторами DELETE и TRUNCATE?
| DELETE | TRUNCATE |
|---|---|
| Используется для удаления строки в таблице | Используется для удаления всех строк из таблицы |
| Вы можете восстановить данные после удаления | Вы не можете восстановить данные (прим. перевод.: операции логируются по разному, но в SQL Server есть возможность сделать откат) транзакции) |
| DML-команда | DDL-команда |
| Медленнее, чем оператор TRUNCATE | Быстрее |
№ Вопрос 2. Из каких подмножеств состоит SQL?
- DDL (Data Definition Language, язык описания данных) — позволяет выполнять различные операции с базой данных, такие как CREATE (создание), ALTER (изменение) и DROP (удаление объектов).
- DML (Data Manipulation Language, язык управления данными) — позволяет получать доступ к данным и манипулировать ими, например, вставлять, обновлять, удалять и извлекать данные из базы данных.
- DCL (Data Control Language, язык контролирования данных) — позволяет контролировать доступ к базе данных. Пример — GRANT (предоставить права), REVOKE (отозвать права).
Вопрос 3. Что подразумевается под СУБД? Какие существуют типы СУБД?
База данных — структурированная коллекция данных. Система управления базами данных (СУБД) — программное обеспечение, которое взаимодействует с пользователем, приложениями и самой базой данных для сбора и анализа данных. СУБД позволяет пользователю взаимодействовать с базой данных. Данные, хранящиеся в базе данных, могут быть изменены, извлечены и удалены. Они могут быть любых типов, таких как строки, числа, изображения и т. д.
Существует два типа СУБД:
- Реляционная система управления базами данных: данные хранятся в отношениях (таблицах). Пример — MySQL.
- Нереляционная система управления базами данных: не существует понятия отношений, кортежей и атрибутов. Пример — Mongo.
Вопрос 4. Что подразумевается под таблицей и полем в SQL?
Таблица — организованный набор данных в виде строк и столбцов. Поле — это столбцы в таблице. Например:
Таблица: Student_Information
Поле: Stu_Id, Stu_Name, Stu_Marks
Вопрос 5. Что такое соединения в SQL?
Для соединения строк из двух или более таблиц на основе связанного между ними столбца используется оператор JOIN. Он используется для объединения двух таблиц или получения данных оттуда. В SQL есть 4 типа соединения, а именно:
- Inner Join (Внутреннее соединение)
- Right Join (Правое соединение)
- Left Join (Левое соединение)
- Full Join (Полное соединение)
Вопрос 6. В чем разница между типом данных CHAR и VARCHAR в SQL?
И Char, и Varchar служат символьными типами данных, но varchar используется для строк символов переменной длины, тогда как Char используется для строк фиксированной длины. Например, char(10) может хранить только 10 символов и не сможет хранить строку любой другой длины, тогда как varchar(10) может хранить строку любой длины до 10, т.е. например 6, 8 или 2.
Вопрос 7. Что такое первичный ключ (Primary key)?

- Первичный ключ — столбец или набор столбцов, которые однозначно идентифицируют каждую строку в таблице.
- Однозначно идентифицирует одну строку в таблице
- Нулевые (Null) значения не допускаются
_Пример: в таблице Student StuID является первичным ключом.
Вопрос 8. Что такое ограничения (Constraints)?
Ограничения (constraints) используются для указания ограничения на тип данных таблицы. Они могут быть указаны при создании или изменении таблицы. Пример ограничений:
Вопрос 9. В чем разница между SQL и MySQL?
SQL — стандартный язык структурированных запросов (Structured Query Language) на основе английского языка, тогда как MySQL — система управления базами данных. SQL — язык реляционной базы данных, который используется для доступа и управления данными, MySQL — реляционная СУБД (система управления базами данных), также как и SQL Server, Informix и т. д.
Вопрос 10. Что такое уникальный ключ (Unique key)?
- Однозначно идентифицирует одну строку в таблице.
- Допустимо множество уникальных ключей в одной таблице.
- Допустимы NULL-значения (прим. перевод.: зависит от СУБД, в SQL Server значение NULL может быть добавлено только один раз в поле с UNIQUE KEY).
Вопрос 11. Что такое внешний ключ (Foreign key)?
- Внешний ключ поддерживает ссылочную целостность, обеспечивая связь между данными в двух таблицах.
- Внешний ключ в дочерней таблице ссылается на первичный ключ в родительской таблице.
- Ограничение внешнего ключа предотвращает действия, которые разрушают связи между дочерней и родительской таблицами.
Вопрос 12. Что подразумевается под целостностью данных?
Целостность данных определяет точность, а также согласованность данных, хранящихся в базе данных. Она также определяет ограничения целостности для обеспечения соблюдения бизнес-правил для данных, когда они вводятся в приложение или базу данных.
Вопрос 13. В чем разница между кластеризованным и некластеризованным индексами в SQL?
- Различия между кластеризованным и некластеризованным индексами в SQL:
Кластерный индекс используется для простого и быстрого извлечения данных из базы данных, тогда как чтение из некластеризованного индекса происходит относительно медленнее. - Кластеризованный индекс изменяет способ хранения записей в базе данных — он сортирует строки по столбцу, который установлен как кластеризованный индекс, тогда как в некластеризованном индексе он не меняет способ хранения, но создает отдельный объект внутри таблицы, который указывает на исходные строки таблицы при поиске.
- Одна таблица может иметь только один кластеризованный индекс, тогда как некластеризованных у нее может быть много.
Вопрос 14. Напишите SQL-запрос для отображения текущей даты.
В SQL есть встроенная функция GetDate (), которая помогает возвращать текущий timestamp/дату.
Вопрос 15. Перечислите типы соединений
Существуют различные типы соединений, которые используются для извлечения данных между таблицами. Принципиально они делятся на четыре типа, а именно:

Inner join (Внутреннее соединение): в MySQL является наиболее распространенным типом. Оно используется для возврата всех строк из нескольких таблиц, для которых выполняется условие соединения.
Left Join (Левое соединение): в MySQL используется для возврата всех строк из левой (первой) таблицы и только совпадающих строк из правой (второй) таблицы, для которых выполняется условие соединения.
Right Join (Правое соединение): в MySQL используется для возврата всех строк из правой (второй) таблицы и только совпадающих строк из левой (первой) таблицы, для которых выполняется условие соединения.
Full Join (Полное соединение): возвращает все записи, для которых есть совпадение в любой из таблиц. Следовательно, он возвращает все строки из левой таблицы и все строки из правой таблицы.
Вопрос 16. Что вы подразумеваете под денормализацией?
Денормализация — техника, которая используется для преобразования из высших к низшим нормальным формам. Она помогает разработчикам баз данных повысить производительность всей инфраструктуры, поскольку вносит избыточность в таблицу. Она добавляет избыточные данные в таблицу, учитывая частые запросы к базе данных, которые объединяют данные из разных таблиц в одну таблицу.
Вопрос 17. Что такое сущности и отношения?
Сущности: человек, место или объект в реальном мире, данные о которых могут храниться в базе данных. В таблицах хранятся данные, которые представляют один тип сущности. Например — база данных банка имеет таблицу клиентов для хранения информации о клиентах. Таблица клиентов хранит эту информацию в виде набора атрибутов (столбцы в таблице) для каждого клиента.
Отношения: отношения или связи между сущностями, которые имеют какое-то отношение друг к другу. Например — имя клиента связано с номером учетной записи клиента и контактной информацией, которая может быть в той же таблице. Также могут быть отношения между отдельными таблицами (например, клиент к счетам).
Вопрос 18. Что такое индекс?
Индексы относятся к методу настройки производительности, позволяющему быстрее извлекать записи из таблицы. Индекс создает отдельную структуру для индексируемого поля и, следовательно, позволяет быстрее получать данные.
Вопрос 19. Опишите различные типы индексов.
Есть три типа индексов, а именно:
- Уникальный индекс (Unique Index): этот индекс не позволяет полю иметь повторяющиеся значения, если столбец индексируется уникально. Если первичный ключ определен, уникальный индекс может быть применен автоматически.
- Кластеризованный индекс (Clustered Index): этот индекс меняет физический порядок таблицы и выполняет поиск на основе значений ключа. Каждая таблица может иметь только один кластеризованный индекс.
- Некластеризованный индекс (Non-Clustered Index): не изменяет физический порядок таблицы и поддерживает логический порядок данных. Каждая таблица может иметь много некластеризованных индексов.
Вопрос 20. Что такое нормализация и каковы ее преимущества?
Нормализация — процесс организации данных, цель которого избежать дублирования и избыточности. Некоторые из преимуществ:
- Лучшая организация базы данных
- Больше таблиц с небольшими строками
- Эффективный доступ к данным
- Большая гибкость для запросов
- Быстрый поиск информации
- Проще реализовать безопасность данных
- Позволяет легко модифицировать
- Сокращение избыточных и дублирующихся данных
- Более компактная база данных
- Обеспечивает согласованность данных после внесения изменений
Вопрос 21. В чем разница между командами DROP и TRUNCATE?
Команда DROP удаляет саму таблицу, и нельзя сделать Rollback команды, тогда как команда TRUNCATE удаляет все строки из таблицы (прим. перевод.: в SQL Server Rollback нормально отработает и откатит DROP).
Вопрос 22. Объясните различные типы нормализации.
Существует много последовательных уровней нормализации. Это так называемые нормальные формы. Каждая последующая нормальная форма включает предыдущую. Первых трех нормальных форм обычно достаточно.
- Первая нормальная форма (1NF) — нет повторяющихся групп в строках
- Вторая нормальная форма (2NF) — каждое неключевое (поддерживающее) значение столбца зависит от всего первичного ключа
- Третья нормальная форма (3NF) — каждое неключевое значение зависит только от первичного ключа и не имеет зависимости от другого неключевого значения столбца
Вопрос 23. Что такое свойство ACID в базе данных?
ACID означает атомарность (Atomicity), согласованность (Consistency), изолированность (Isolation), долговечность (Durability). Он используется для обеспечения надежной обработки транзакций данных в системе базы данных.
Атомарность. Гарантирует, что транзакция будет полностью выполнена или потерпит неудачу, где транзакция представляет одну логическую операцию данных. Это означает, что при сбое одной части любой транзакции происходит сбой всей транзакции и состояние базы данных остается неизменным.
Согласованность. Гарантирует, что данные должны соответствовать всем правилам валидации. Проще говоря, вы можете сказать, что ваша транзакция никогда не оставит вашу базу данных в недопустимом состоянии.
Изолированность. Основной целью изолированности является контроль механизма параллельного изменения данных.
Долговечность. Долговечность подразумевает, что если транзакция была подтверждена (COMMIT), произошедшие в рамках транзакции изменения сохранятся независимо от того, что может встать у них на пути (например, потеря питания, сбой или ошибки любого рода).
Вопрос 24. Что вы подразумеваете под «триггером» в SQL?
Триггер в SQL — особый тип хранимых процедур, которые предназначены для автоматического выполнения в момент или после изменения данных. Это позволяет вам выполнить пакет кода, когда вставка, обновление или любой другой запрос выполняется к определенной таблице.
Вопрос 25. Какие операторы доступны в SQL?
В SQL доступно три типа оператора, а именно:
- Арифметические Операторы
- Логические Операторы
- Операторы сравнения
Вопрос 26. Совпадают ли значения NULL со значениями нуля или пробела?
Значение NULL вовсе не равно нулю или пробелу. Значение NULL представляет значение, которое недоступно, неизвестно, присвоено или неприменимо, тогда как ноль — это число, а пробел — символ.
Вопрос 27. В чем разница между перекрестным (cross join) и естественным (natural join) соединением?
Перекрестное соединение создает перекрестное или декартово произведение двух таблиц, тогда как естественное соединение основано на всех столбцах, имеющих одинаковое имя и типы данных в обеих таблицах.
Вопрос 28. Что такое подзапрос в SQL?
Подзапрос — это запрос внутри другого запроса, в котором определен запрос для извлечения данных или информации из базы данных. В подзапросе внешний запрос называется основным запросом, тогда как внутренний запрос называется подзапросом. Подзапросы всегда выполняются первыми, а результат подзапроса передается в основной запрос. Он может быть вложен в SELECT, UPDATE или любой другой запрос. Подзапрос также может использовать любые операторы сравнения, такие как >, < или =.
Вопрос 29. Какие бывают типы подзапросов?
Существует два типа подзапросов, а именно: коррелированные и некоррелированные.
- Коррелированный подзапрос: это запрос, который выбирает данные из таблицы со ссылкой на внешний запрос. Он не считается независимым запросом, поскольку ссылается на другую таблицу или столбец в таблице.
- Некоррелированный подзапрос: этот запрос является независимым запросом, в котором выходные данные подзапроса подставляются в основной запрос.
Вопрос 30. Перечислите способы получить количество записей в таблице?
Для подсчета количества записей в таблице вы можете использовать следующие команды:
SELECT * FROM table1
SELECT COUNT(*) FROM table1
SELECT rows FROM sysindexes WHERE AND indid < 2
Ещё 35 вопросов с ответами опубликуем в следующей части… Следите за новостями!
С 2015 по 2019 годы я прошёл четыре цикла собеседований на должность аналитика данных и специалиста по анализу данных в более чем десятке компаний. После очередного неудачного интервью в 2017 году — когда я запутался в сложных вопросах по SQL — я начал составлять задачник с вопросами по SQL средней и высокой сложности, чтобы лучше готовиться к собеседованиям. Этот справочник очень пригодился в последнем цикле собеседований 2019 года. За последний год я поделился этим руководством с парой друзей, а благодаря дополнительному свободному времени из-за пандемии отшлифовал его — и составил этот документ.
Есть множество отличных руководств по SQL для начинающих. Мои любимые — это интерактивные курсы Codecademy по SQL и Select Star SQL от Цзы Чон Као. Но в реальности первые 70% из курса SQL довольно просты, а настоящие сложности начинаются в остальных 30%, которые не освещаются в руководствах для начинающих. Так вот, на собеседованиях для аналитиков данных и специалистов по анализу данных в технологических компаниях часто задают вопросы именно по этим 30%.
Удивительно, но я не нашёл исчерпывающего источника по таким вопросам среднего уровня сложности, поэтому составил данное руководство.
Оно полезно для собеседований, но заодно повысит вашу эффективность на текущем и будущих местах работы. Лично я считаю, что некоторые упомянутые шаблоны SQL полезны и для ETL-систем, на которых работают инструменты отчётности и функции анализа данных для выявления тенденций.
Нужно понимать, что на собеседованиях дата-аналитиков и специалистов по анализу данных задают вопросы не только по SQL. Другие общие темы включают обсуждение прошлых проектов, A/B-тестирование, разработку метрик и открытые аналитические проблемы. Примерно три года назад на Quora публиковались советы по собеседованию на должность аналитика продукта (product analyst) в Facebook. Там эта тема обсуждается более подробно. Тем не менее, если улучшение знаний по SQL поможет вам на собеседовании, то это руководство вполне стоит потраченного времени.
В будущем я могу перенести код из этого руководства на сайт вроде Select Star SQL, чтобы было проще писать инструкции SQL — и видеть результат выполнения кода в реальном времени. Как вариант — добавить вопросы как проблемы на платформу для подготовки к собеседованиям LeetCode. Пока же я просто хотел опубликовать этот документ, чтобы люди могли прямо сейчас ознакомиться с этой информацией.
Предположения о знании языка SQL: Предполагается, что у вас есть рабочие знания SQL. Вероятно, вы часто используете его на работе, но хотите отточить навыки в таких темах, как самообъединения и оконные функции.
Как использовать данное руководство: Поскольку на собеседовании часто используется доска или виртуальный блокнот (без компиляции кода), то рекомендую взять карандаш и бумагу — и записать решения для каждой проблемы, а после завершения сравнить свои записи с ответами. Или отработайте свои ответы вместе с другом, который выступит в качестве интервьюера!
- Небольшие синтаксические ошибки не имеют большого значения во время собеседования с доской или блокнотом. Но они могут отвлекать интервьюера, поэтому в идеале старайтесь уменьшить их количество, чтобы сконцентрировать всё внимание на логике.
- Приведённые ответы не обязательно единственный способ решить каждую задачу. Не стесняйтесь писать комментарии с дополнительными решениями, которые можно добавить в это руководство!
Сначала стандартные советы для всех собеседований по программированию…
Некоторые из перечисленных здесь проблем адаптированы из старых записей в блоге Periscope (в основном написанных Шоном Куком около 2014 года, хотя его авторство, видимо, убрали из материалов после слияния SiSense с Periscope), а также из обсуждений на StackOverflow. В случае необходимости, источники отмечены в начале каждого вопроса.
На Select Star SQL тоже хорошая подборка задачек, дополняющих проблемы из этого документа.
Пожалуйста, обратите внимание, что эти вопросы не являются буквальными копиями вопросов с моих собственных собеседований, и они не использовались в компаниях, в которых я работал или работаю.
№ 3. Продвинутые расчёты
Благодарность: эта задача адаптирована из обсуждения по вопросу, который я задал на StackOverflow (мой ник zthomas.nc).
Примечание: вероятно, это более сложная задача, чем вам предложат на реальном собеседовании. Воспринимайте её скорее как головоломку — или можете пропустить её!
Контекст: допустим, у нас есть таблица table такого вида, где одному и тому же пользователю user могут соответствовать разные значения класса class :
Задача: предположим, что существует только два возможных значения для класса. Напишите запрос для подсчёта количества пользователей в каждом классе. При этом пользователи с обеими метками a и b должны относиться к классу b .
Для нашего образца получится такой результат:
Альтернативное решение использует инструкции SELECT в операторах SELECT и UNION :
У нас, как и во многих других организациях, проводится тестирование соискателей при поступлении их на работу. Основу тестирования составляет устное собеседование, но в некоторых случаях, даются также практические задания. Несколько дней назад, Руководство попросило меня подготовить набор задач на знание SQL.
Разумеется, я постарался сделать задания не слишком сложными. Уровень соискателей различен и задачи, на мой взгляд, должны быть составлены таким образом, чтобы по результатам их решения можно было судить о том, насколько хорошо испытуемый знает предмет.
Также, не имело смысла давать задания на знание каких-либо особенностей тех или иных СУБД. Мы в работе используем Oracle, но это не должно создавать трудностей для соискателей знающих, например, только MS SQL или PostgreSQL. Таким-образом, использование платформо-зависимых решений не возбраняется, но и не является ожидаемым при решении задач.
Для проведения тестирования, в Oracle 11g была развернута схема, содержащая следующие таблицы:

Требовалось составить SQL-запросы, для решения следующих пяти заданий:
Вывести список сотрудников, получающих заработную плату большую чем у непосредственного руководителя
Вывести список сотрудников, получающих максимальную заработную плату в своем отделе
Вывести список ID отделов, количество сотрудников в которых не превышает 3 человек
Вывести список сотрудников, не имеющих назначенного руководителя, работающего в том-же отделе
Найти список ID отделов с максимальной суммарной зарплатой сотрудников
Не требовалось искать в каком-либо смысле оптимальное решение. Единственное требование: запрос должен возвращать правильный ответ на любых входных данных. Задания разрешалось решать в любом порядке, без ограничения времени. При правильном решении всех заданий, предлагалось следующее задание повышенной сложности:
Составить SQL-запрос, вычисляющий произведение вещественных значений, содержащихся в некотором столбце таблицы
Разумеется, опубликованные здесь ответы не являются единственно верными. В случае, если запрос соискателя не содержит явных ошибок, результаты его выполнения (для различных наборов исходных данных) сравниваются с результатами выполнения соответствующего эталонного запроса.
Вопросы по SQL на собеседованиях — обычное дело, и чтобы не завалиться, нужно хорошо понимать, как работать с базами данных. В этом списке представлены основные вопросы и задачи по SQL, которые часто встречаются на собеседованиях, а также ответы на них.
№ 2. Среднее значение и ранжирование с оконной функцией (несколько частей)
Выберите только уникальные имена
SELECT DISTINCT возвращает разные значения, даже если в выбранном столбце есть дубли.
Что такое СУБД?
Допустим, есть большая база данных, которой пользуются многие сотрудники: кто-то ищет информацию, а кто-то изменяет или даже удаляет её. Чтобы правильно обрабатывать все эти запросы, нужно специальное программное обеспечение, и именно такое ПО получило название системы управления базами данных (СУБД).
Часть 2
Задача: теперь возьмём предыдущую задачу по вычислению количества удержанных пользователей в месяц — и перевернём её с ног на голову. Напишем запрос для подсчёта пользователей, которые не вернулись на сайт в этом месяце. То есть «потерянных» пользователей.
Обратите внимание, что эту проблему можно решить также с помощью соединений LEFT или RIGHT .
Как выбрать записи с нечётными Id?
Один из самых распространённых вопросов на собеседовании. SQL запрос для выбора записей с нечётными id должен выглядеть следующим образом:
Если остаток от деления id на 2 равен нулю, перед нами чётное значение, и наоборот.
№ 1. Найти идентификатор с максимальным значением
Контекст: Допустим, у нас есть таблица salaries с данными об отделах и зарплате сотрудников в следующем формате:
Задача: написать запрос, чтобы получить empno с самой высокой зарплатой. Убедитесь, что ваше решение обрабатывает случаи одинаковых зарплатами!
Альтернативное решение с использованием RANK() :
А что такое Self JOIN?
Такой вопрос тоже может прозвучать на собеседовании по SQL. Это выражение используется для того, чтобы таблица объединилась сама с собой, словно это две разные таблицы. Чтобы такое реализовать, одна из таких «таблиц» временно переименовывается.
Например, следующий SQL-запрос объединяет клиентов из одного города:
Что такое первичный ключ?
Первичный ключ или PRIMARY KEY предназначен для однозначной идентификации каждой записи в таблице и является строго уникальным ( UNIQUE ): две записи таблицы не могут иметь одинаковые значения первичного ключа. Нулевые значения ( NULL ) в PRIMARY KEY не допускаются. Если в качестве PRIMARY KEY используется несколько полей, их называют составным ключом.
Здесь в качестве первичного ключа используется поле id.
№ 1. Гистограммы
Контекст: Допустим, у нас есть таблица sessions , где каждая строка представляет собой сеанс потоковой передачи видео с длиной в секундах:
Задача: написать запрос, чтобы подсчитать количество сеансов, которые попадают промежутки по пять секунд, т. е. для приведённого выше фрагмента результат будет примерно такой:
Максимальная оценка засчитывается за надлежащие метки строк ("5-10" и т. д.)
Часть 2
Примечание: этот скорее бонусный вопрос, чем реально важный шаблон SQL. Можете его пропустить!
Задача: как можно изменить SQL из предыдущего решения, чтобы удалить дубликаты? Например, на примере той же таблицы, чтобы пара NC и SC появилась только один раз, а не два.
№ 5. Скользящее среднее
Благодарность: эта задача адаптирована из статьи в блоге SiSense «Скользящие средние в MySQL и SQL Server».
Примечание: скользящее среднее можно вычислить разными способами. Здесь мы используем предыдущее среднее значение. Таким образом, метрика для седьмого дня месяца будет средним значением предыдущих шести дней и его самого.
Контекст: допустим, у нас есть таблица signups в таком виде:
Задача: написать запрос, чтобы получить 7-дневное скользящее среднее ежедневных регистраций.
Читайте также: