
Обмен данными между базами oracle
Начнем с того, что утверждение, составляющее заголовок, в общем, ложно. Однако существующие диспропорции между эксплуатационными характеристиками локальных сетей и линий связи с ними, отягченные требованиями приложения, вынуждают часто создавать отдельные локальные сервера БД и, более того, дублировать на них часть данных "из центра". (Это лишь одна причина, по которой тиражирование данных становится единственным техническим решением; есть и другие; но, во-первых, эта причина - важнейшая, а во-вторых, систематичное рассмотрение проблемы не составляет цель этой заметки).
Как часто бывает в Oracle (а может и не только в Oracle ?) идея, звучащая в общем просто, при реализации обрастает таким количеством технических деталей и ухищрений, что увидев все эти "навороты", разработчик твердо решает связываться с ними только в случае полной безвыходности. Но и тогда приходится с чего-то начинать. А начинать лучше с простого. К счастью, построить работающий пример тиражирования в Oracle, прозрачный для понимания новичка, вполне возможно. Цель нижеследующего текста - доказать это.
Начальные условия
Пусть имеются две работающие базы данных. Например, их можно запустить на одном компьютере. У себя на занятиях я пользуюсь именами TEACHER и TEACHER1, и эти названия баз данных буду употребляться далее. Для базы TEACHER заведена внешняя связь под названием MYTEACHER. Проще всего завести ее в Net8 Assistant.
Мы намереваемся завести в схеме SCOTT БД TEACHER1 таблицу, являющуюся копией таблицы SCOTT.DEPT базы TEACHER.
Дальнейший текст "проигран" на версии сервера 8.1.6, управляющего обеими базами. Поскольку некоторые детали организации тиражирования в версии 7 отличны от версии 8, в тексте будут сделаны необходимые оговорки.
Одностороннее тиражирование шаг за шагом
Для удобства можно открыть два консольных окошка с SQL*Plus: первое для работы с БД TEACHER, а второе - с TEACHER1.
- В первом окошке создадим так называемый "журнал изменений таблицы DEPT", то есть служебную таблицу, в которой автоматически будут отражаться все изменения в таблице SCOTT.DEPT (вставки, модификации, удаления). Для этого сначала выдадим от имени SYS:
- Во втором окошке выдадим от имени SYS
Теперь нужно посмотреть значение init-параметра job_queue_processes на вашем сервере. Быстрее всего это сделать командой SQL*Plus show parameter job. Если оно 0, то нужно редактором текста проставить в файле INIT.ORA для TEACHER job_queue_processes = 1, сохранить файл и перезапустить систему. (Если все происходит на одной машине, пожалуйста, не ошибитесь с базами!)
- Войдем во втором окошке как SCOTT. Проверим для верности, есть ли связь с тезкой из базы TEACHER в соседнем окошке:
- Перейдем в первое окошко и от имени SCOTT наберем:
- Вернемся во второе окошко. Передохнем с минуту, и выдадим от имени SCOTT:
Общее пояснение
В однонаправленном тиражировании в Oracle (а именно его мы построили) данные передаются от старшего узла данных (master site) к младшему (snapshot site). (В принципе, никто не мешает и тот, и другой организовать в рамках одной базы).
Для старшей базы выдается команда CREATE SNAPSHOT LOG. По этой команде:
- Автоматически заводится таблица MLOG$_< имя_тиражируемой_таблицы >. Вы можете увидеть ее через USER_OBJECTS, а содержимое - непосредственным обращением к ней. Назначение этой таблицы - регистрировать все изменения, происходящие, в нашем случае, с DEPT.
- Автоматически заводится триггер TLOG$_< имя_тиражируемой_таблицы >. Этот "after action"-триггер и заполняет MLOG$_… . В версии 7 сервера Oracle он был доступен для наблюдения через системный словарь-справочник, а в восьмой версии он упрятан "внутрь", став невидимкой.
Для младшей базы выдается команда CREATE SNAPSHOT, по которой автоматически создаются:
- Таблица SNAP$_< имя_тиражируемой_таблицы >. Это и будет фактическая реплика тиражируемой таблицы.
- Представление MLOG$_ < имя_тиражируемой_таблицы >(только для Oracle7).
- Индекс PK_ < имя_тиражируемой_таблицы >(только для версии Oracle8).
- Представление (view) с именем реплики.
- Задание (job) на выполнение обновления реплики с заданной периодичностью посредством обращения ко встроенному пакету DBMS_REFRESH. Для того, чтобы это задание могло выполняться, мы и вносили изменение в INIT.ORA.
Таким образом, общая техника выполнения тиражирования становится ясной: в старшей базе создается триггер, заносящий все изменения в тиражируемой таблице в специальную журнальную таблицу, а в младшей базе периодически запускается встроенная процедура, обращающаяся по связи (link) за данными в старшую базу, и вносящая необходимые изменения в реплику.
Маленькое терминологическое отступление
Реплика, то есть таблица, воспроизводящая изменения данных в других таблицах (и, возможно, в базах), в версии 7 Oracle называется snapshot. (Встречаются другие переводы на русский язык, например, буквальный: "фотографический снимок"). В версии 8 это название для совместимости сохранено, однако появилось и более общее: materialized view, "материализованное представление". Механизм materialized view может много чего другого по сравнению со snapshot, например, делать автоматическую подмену SQL-запроса на другой, более эффективно обрабатываемый, если это возможно. (Только не ожидайте, пожалуйста, прозрачной для понимания технической реализации materialized view!). Всякий (-ая) snapshot является materialized view, но не всякое materialized view является snapshot.
Комментарий к организации тиражирования
Теперь стоит дать краткий комментарий конкретно относительно проделанных только что действий.
Однонаправленное тиражирование "старший - младший узел" самое простое по организации и сопровождению и не требует наличия в вашей системе Advanced Replication Option. Требуется наличие пакетов DBMS_SNAPSHOT и DBMS_REFRESH, но они обычно устанавливаются при создании базы данных в результате прогона catproc.sql, вызывающего, в свою очередь, dbmssnap.sql и prvtsnap.sql.
Комментарий к начальным условиям
Имена пользователей на старшем и младшем узле вовсе не обязаны совпадать. SCOTT выбран только потому, что этот пользователь всем известен и почти всегда в базе есть (а если нет - создается одной командой в SQL*Plus).
Комментарий к шагу 1
Таблица DEPT выбрана по двум причинам: у нее есть первичный ключ (что в нашем варианте создания реплики обязательно, а вообще-то, необязательно), и она непуста и мала, что удобно для иллюстраций.
Фраза WITH PRIMARY KEY указывает на то, что ссылки из журнала на строки базовой таблицы DEPT будут делаться по ключу. Можно было бы делать и по ROWID, указав WITH ROWID (а в версии 7 это была единственная возможность), но более правильно и надежно (с точки зрения внесения изменений в приложение) организовать в журнале ссылки именно по ключу.
Комментарий к шагу 2
Системные привилегии CREATE SNAPSHOT и CREATE DATABASE LINK входят в состав роли ADM, причем вторая из них - еще и в CONNECT, IMP_FULL_DATABASE и RECOVERY_CATALOG_OWNER. Поэтому не исключено, что они у "вашего" SCOTT уже есть.
Имя создаваемой связи должно совпадать с именем базы данных, с которой налаживается взаимодействие.
Комментарий к шагу 3
В предложении CREATE SNAPSHOT фраза BUILD IMMEDIATE означает, что "первая" реплика будет построена сразу же по выдаче этого предложения.
Фраза REFRESH FAST указывает на то, что реплика будет изменяться путем применения к ней модификаций исходных данных. В противовес этому можно было бы изменять реплику путем полного ее пересоздания с нужной периодичностью. Ясно, то выбранный нами метод изменения более экономен, особенно на больших таблицах.
Фраза START WITH SYSDATE NEXT SYSDATE + 1/1440 говорит о том, что фоновый процесс SNP, заведенный на шаге 2 изменением INIT-параметра, будет привлекаться заданием (job), созданным предложением CREATE SNAPSHOT, для извлечения изменений в базовой таблице и внесения их в реплику, начиная с текущего момента и далее ежеминутно.
Фраза WITH PRIMARY KEY: раз мы ее указали при создании журнальной таблицы, то должны указать и здесь. В прочем см. аналогичный комментарий для шага 2.
По поводу запроса SELECT. Здесь он по виду самый простой, но, во-первых, можно было указать в нем отбор строк по условию WHERE и/или столбцов путем явного перечисления полей. То есть, мы вовсе не обязаны воспроизводить на младшем узле всю исходную таблицу целиком, что составляет большой плюс для разработки приложения. Более того, и во-вторых, мы не обязаны ограничиваться в этом запросе только одной базовой таблицей, и можем извлекать данные из двух и более таблиц. При планировании такого решения, правда, нелишне принять во внимание и проблемы эффективности, и, возможно, подумать над иным вариантом его реализации.
На этом шаге не мешает обратиться к USER_OBJECTS и посмотреть, что нового появилось в вашей схеме (из того, что Oracle8 считает нужным вам показать). Заметим, что DEPTCOPY - это представление, и модифицировать его самим не получится. Это - выводимая таблица только для чтения.
Комментарий к шагу 4
Не забудьте выполнить COMMIT, а то за "минуту" из следующего шага вы успеете не только кофе попить, но и пообедать.
Комментарий к шагу 5
Без комментариев. Впрочем, нет. Если по каким-то причинам процесс обновления реплики не работает (например, не работает связь), то после определенного числа безуспешных попыток задание на обновление реплики будет помечено как "неработающее" (broken) и перестанет активизироваться раз в минуту. Впрочем, это уже выходит за рамки простейшего примера, в котором все должно быть нормально, и здесь начинаются, как говорится, "детали".
О чем я не рассказал
О массе этих самых "деталей" - следуя назначению этой заметки. Например, о том,
- какие имеются ограничения на формулирование запроса на заполнение реплики данными (а они, естественно, имеются);
- какие есть возможности по более тщательному конфигурированию однонаправленного тиражирования;
- какие есть возможности по более тщательной настройке однонаправленного тиражирования;
- какие средства помогают администрировать выполнение однонаправленного тиражирования.
Но если пример, проделанный собственными руками, вас воодушевил, то более плотное изучение вопросов построения однонаправленного тиражирования окажется для вас, чисто психологически, проще.

При использовании распределенных баз данных часто требуется перемещать данные из одной базы данных Oracle в другую. А иногда необходимо организовать несколько копий одной и той же базы в разных местах, чтобы уменьшить объем сетевого трафика или повысить доступность данных. Вы можете экспортировать сами данные и словари данных (метаданные) из одной базы и импортировать их в другую. В Oracle Database 10g для экспорта/импорта была реализована высокоскоростная помпа данных (data pump).
Oracle предлагает много других дополнительных средств этой категории: переносимые табличные пространства, компоненты Advanced Queuing и Oracle Streams, а также решения для извлечения, трансформации и загрузки (ETL) данных. Рассмотрим их подробнее.
Настройка Oracle Streams
Ниже перечислены шаги, которые необходимо выполнить для настройки механизма Oracle Streams и администрирования осуществляемых с его помощью операций по передаче изменений между несколькими базами данных. Следует иметь в виду, что тут предлагается лишь очень краткий обзор процесса настройки Oracle Stream, чтобы у вас могло сложиться общее впечатление о том, что он собой представляет. Для настоящей настройки Oracle Streams следует обязательно использовать соответствующие инструкции, предлагаемые в руководствах по Oracle.
1. Сначала нужно внести необходимые изменения в файл init.ora или SPFILE.
- Проверить, чтобы в параметре COMPATIBLE была указана версия 10.2.0 или выше в обеих базах данных (на самом деле в нем можно даже указывать версию 9.2 или выше).
- Проверить, чтобы для параметра JOB_QUEUE_PROCESSES в исходной базе данных было установлено, как минимум, значение 2.
- Проверить, чтобы для параметра GLOBAL_NAMES как в исходной, так и в целевой базе данных было установлено значение true.
- Установить параметр LOG_ARCHIVE_DEST_n. Нужно, чтобы на сайте, отвечающего за основной процесс захвата, присутствовало хотя бы одно место для размещения архива журналов.
- Проверить, чтобы под компонент памяти STREAMS_POOL_SIZE в SGA было выделено хотя бы 200 Мбайт.
- Удостовериться в том, что табличное пространство является достаточно большим для того, чтобы удовлетворять требования параметра UNDO_RETENTION.
- Удостовериться в том, что исходная база данных функционирует в режиме архивирования журналов (ARCHIVELOG).
2. Затем необходимо создать нового пользователя для управления Oracle Streams. Перед его созданием может потребоваться создать для него новое табличное пространство:
Теперь можно создать в базе данных самого пользователя, ответственного за администрирование Oracle Streams, как показано ниже:
3. Далее нужно выдать пользователю–администратору Oracle Streams (strmadmin) привилегии CONNECT, RESOURCE и DBA:
4. Для предоставления необходимых привилегий администратору Oracle Streams следует использовать процедуру GRANT_ADMIN_PRIVILEGE из пакета DBMS_STREAMS_AUTH:
5. Затем необходимо создавать канал связи между исходной и целевой базой данных, как показано ниже:
6. Oracle Streams осуществляет перемещение данных между исходной и целевой базой данных с помощью очередей. Поэтому далее необходимо создать очередь как в исходной, так и в целевой базе данных. Для этого потребуется выполнить в той и другой следующую процедуру, которая подразумевает создание обеих очередей с принятыми по умолчанию именами.
7. Далее нужно включить дополнительную журнализацию для всех тех таблиц в исходной базе данных, для которых планируется перехватывать изменения. Делается это следующим образом:
8. И, наконец, напоследок необходимо сконфигурировать процесс захвата в исходной базе данных с использованием процедуры ADD_TABLE_RULES из пакета DBMS_STREAMS_ADM:
После настройки Oracle Streams в соответствие с перечисленными выше шагами можно тестировать настроенную конфигурацию, запустив процесс захвата и применив процесс применения для репликации данных таблицы (в данном примере — emp) из исходной базы данных в аналогичную таблицу в целевой базе данных. Для захвата изменений используется следующая процедура:
Для переноса захваченных изменений в целевую базу данных служит такая процедура:
Технология Oracle Streams была рассмотрена в этой статье моего блога очень кратко. Тем не менее, она представляет собой очень мощное и полезное средство для выполнения в базах данных операций по репликации, переносу и обновлению данных. Главным интерфейсом к Oracle Streams служит соответствующая коллекция поставляемых Oracle пакетов PL/SQL. Здесь было показано, как применять некоторые из этих пакетов для настройки и управления механизмом Oracle Streams, чтобы вы могли посмотреть, что конкретно происходит на этапе захвата и передачи изменений. Для оказания помощи пользователям в настройке, администрировании и мониторинге сред Oracle Streams компания Oracle поставляет специальный инструмент Streams в составе интерфейса OEM Console. Для удобства работы с Oracle Streams рекомендуется использовать именно его.
Знает названье потока лишь тот, кто вблизи обитает.
От Махачкалы до Баку
Луны плавают на боку,
И, качаясь, плывут валы
От Баку до Махачкалы.
Введение
Потоки данных появились в Oracle версии 9, а в версии 10 получили свое развитие в возможностях (например, Down Stream) и в организации (например, собственный источник памяти streams pool).
В отличие от "обычной" репликации Oracle Streams не требует заведения особых структур в БД (журналов таблиц, materialized views). Подбно механизму репликации, давно использовавшемуся в Sybase, репликация в Oracle Streams основана на обработке информации из журнала БД.
Основные понятия
Конфигурация СУБД и БД для возможности организации потоков
Параметры СУБД
Для организации потоков данных нужно иметь должные значения целого ряда параметров СУБД, однако чаще всего достаточно удостовериться в следующем:
COMPATIBLE >= 9.2
Далее предполагается >= 10.1.0.
GLOBAL_NAMES = TRUE
для каждой БД, участвующей в переносе данных.
STREAMS_POOL_SIZE >= 200m
Параметр существует с версии 10.1 и задает область памяти для временного размещения захваченных событий. Если STREAMS_POOL_SIZE = 0, будет использована память из shared pool, вплоть до 10% от этой области.
- + 10m для каждого нового уровня параллелизма процесса захвата
- + 1m для каждой степени параллелизма процесса применения
- + 10m для каждой новой очереди захваченных событий.
В версии 9.2 нагрузка на выделение памяти под нужды потоков ложится на shared pool.
SHARED_POOL_SIZE
Каждый процесс захвата требует 10M в памяти shared pool для буфера очереди; в то же время все нужды Oracle Streams в shared pool не могут занимать более 10% этой области.
SGA_MAX_SIZE
(Если речь идет о версии 10). Значение должно учитывать нужды частей SGA (см. выше), особенно для выполнения захвата изменений с помощью LogMiner. Пример, приводимый ниже, в силу его простоты работает даже при значении SGA_MAX_SIZE = 400m.
Конфигурация БД
БД, поддерживающая процесс захвата изменений, должна обеспечить на уровне отдельных таблиц или всей БД режим расширенной журнализации (supplemental logging). В этом режиме журнальные записи об изменениях в таблицах заносятся в расширенном формате, включая данные старых и новых значений полей (независимо от того, какие поля фактически изменялись) для того, чтобы процесс применения изменения в принимающей СУБД смог однозначно воспроизвести изменение.
- индексирован (хотя бы вследствие имеющегося ограничения целостности)
- участвует в правиле преобразования данных или обрабатывается программой обработки (handler)
Как БД-источник, так и БД-получатель используют рабочие таблицы для хранения данных очередей и прочих нужд. Для их размещения целесообразно выделить отдельные табличные пространства. В БД-источнике желательно назначить процессу LogMiner табличное пространство, иное, чем SYSTEM.
Системные пакеты
Технологически организация потоков осуществляется через употребление ряда встроенных пакетов из схемы SYS:
DBMS_APPLY_ADM
DBMS_CAPTURE_ADM
DBMS_PROPAGATION_ADM
DBMS_STREAMS_ADM
DBMS_STREAMS
DBMS_STREAMS_MESSAGING
DBMS_RULE_ADM
DBMS_RULE
DBMS_STREAMS_AUTH 2
DBMS_STREAMS_TABLESPACE_ADM 2
Пример построения потока изменений
В этом примере БД-источник потока носит имя MAINDB.CLASS, БД-приемник потока носит имя SUBDB1.CLASS. Сетевые имена баз в Oracle Net соответственно SOURCE и DESTINATION. Предполагается, что в обеих БД имеется схема SCOTT.
Пример приводится для версии 10.2. Предполагается, что команды выдаются в SQL*Plus.
Подготовка
CONNECT /@source AS SYSDBA
STARTUP MOUNT FORCE
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE OPEN;
Создадим рабочие табличные пространства в обоих БД, например:
CREATE TABLESPACE streams_ts
DATAFILE 'C:\oracle\oradata\maindb\streams_ts.dbf' SIZE 25m;
CONNECT /@destination AS SYSDBA
CREATE TABLESPACE streams_ts
DATAFILE 'C:\oracle\oradata\subdb1\streams_ts.dbf' SIZE 25m;
В версия 9.2 в БД-источнике желательно назначить процессу LogMiner табличное пространство, иное, чем SYSTEM (в версия 10 оно уже SYSAUX), например:
CONNECT /@source AS SYSDBA
EXECUTE DBMS_LOGMNR_D.SET_TABLESPACE ( 'TOOLS' )
В обеих базах создадим администратора потоков:
CONNECT /@source AS SYSDBA
CREATE USER streamadmin IDENTIFIED BY streamadmin
DEFAULT TABLESPACE streams_ts
TEMPORARY TABLESPACE temp
QUOTA UNLIMITED ON streams_ts
;
GRANT dba TO streamadmin;
EXECUTE DBMS_STREAMS_AUTH.GRANT_ADMIN_PRIVILEGE ( 'streamadmin' )
Повторить те же действия для SUBDB1.CLASS.
В БД-источнике заведем связь с БД-получателем. Так как БД-получатель именована глобально, имя связи обязано совпадать с этим глобальным именем:
CONNECT streamadmin/streamadmin@source
CREATE DATABASE LINK subdb1.class
CONNECT TO streamadmin
IDENTIFIED BY streamadmin
USING 'destination'
;
Формирование потоков
Создадим очередь для передачи событий в БД-источнике и очередь для применения событий в БД-получателе, например:
CONNECT streamadmin/streamadmin@destination
Коли указано специально, очереди в обеих БД (и таблицы для данных этих очередей) получили умолчательные названия. Их можно наблюдать так:
Для возможности передавать потоком изменения в исходной таблице SCOTT.EMP требуется заявить расширенную журнализацию хотя бы для этой таблицы:
CONNECT scott/tiger@source
ALTER TABLE emp ADD SUPPLEMENTAL LOG DATA ( PRIMARY KEY ) COLUMNS;
Теперь правка любого поля в таблице EMP будет сопровождаться (безусловно) занесением в журнал не только старого и нового значений этого поля, но также и значения ключевого поля (то есть EMPNO).
В БД-источнике создадим процесс захвата изменений, одновременно указав правила отбора изменений в очередь: Проверка:
Среди прочих умолчаний при создании процесса захвата изменений выше использовано подразумеваемое молчаливо имя очереди STREAMS_QUEUE. В нашем случае это можно было бы обозначить явно, указав параметр QUEUE_NAME => 'streamadmin.streams_queue'. Этим же параметром можно воспользоваться, когда процесс захвата потребуется связать с очередью под иным именем.
Правила отбора изменений в очередь STREAMS_QUEUE также были построены автоматически, но могли бы быть дополнены, или даже выписаны явно с помощью других параметров процедуры ADD_TABLE_RULES.
Создадим процесс переноса изменений: Проверка: Убедиться в учете процессом применения для таблиц точки отсчета можно запросом: Принимающая БД готова к активации процесса применения изменений: Проверка: Для удобства отключим реакцию на ошибки, иначе процесс применения изменений может самопроизвольно прекращаться: Осталось запустить процессы захвата и примения изменений: Проверка: Заметьте, что поток переносит изменения только в одну сторону. Таблица-приемник при этом не закрыта от обычной правки. Однако же такую правку следует выполнять осмотрительно, поскольку она может привести к ошибкам при автоматическом изменении данных потоком (эта проблема решается специально седствами разрешении конфликтов). Вдобавок учтите, что множественные операции INSERT, UPDATE, DELETE применяются в принимающей БД в рамках одной (автономной) транзакции (невзирая на то, что в журнале БД множественные изменения фиксируются набором однострочных изменений). Следовательно ошибка хотя бы в изменении одной-единственной строки приведет к отказу изменений всей множественной операции.
Упражнение. Внести изменения в таблицу SCOTT.EMP на принимающей БД. Убедиться в сохраняющихся расхождениях в таблицах БД-источника и БД-получателя.
Упражнение. Проверить передачу изменений DDL. Добавить столбец в таблицу SCOTT.EMP@MAINDB.CLASS. Наблюдать результат в SCOTT.EMP@SUBDB1.CLASS. Изменить тип столбца, наблюдать результат в базе-получателе.
В настоящее время при построении многих автоматизированных систем возникает проблема синхронизации данных по нескольким источникам информации. Один из способов решения этой проблемы — репликации.
В данном топике я расскажу об одной из таких проблем и о том, как можно решить эту проблему с помощью технологии Oracle Streams.
Абстрактно
Проблема синхронизации данных по нескольким источникам информации представляет собой довольно нетривиальную задачу с весьма неоднозначным решением.
Подобные проблемы возникают довольно часто, но универсального решения такой задачи на текущий момент практически нет. Почти все готовые системы репликации данных работают с существенными ограничениями по структуре и способам накопления и изменения данных.
Введение в проблему
В настоящее время при синхронной репликации задержки отсутствуют, но это, в свою очередь, сказывается на пропускной способности транзакций и возможностях системы в целом.
Таким образом, нет ничего удивительного в том, что большинство пользователей выбирают асинхронную репликацию.
Задача состоит в том, чтобы сконструировать систему асинхронной репликации, которая сможет гарантировать малую фиксированную величину задержки и будет поддерживать полную пропускную способность транзакций базы данных.
Технология Oracle Streams
LCR, CR
В контексте Oracle Streams, информационное представление любого изменения, сделанного в базе данных, называется LCR (logical change record). LCR – это обобщенное представление всех возможных изменений, представленных в базе данных.
CR(change record) — запись изменения, используется для того, чтобы обозначить конкретное изменение в базе.
Rules and transformations
Также пользователь имеет возможность определять соответствия между LCR и набором правил. Эти правила оценивают все изменения, произведенные в базе данных, и проводят фильтрацию несоответствующих LCR.
Например, следующее правило определяет только DML изменения таблицы SCOTT.EMP
Точно также правила определяются и для DDL изменений.
Кроме того, к правилам могут быть привязаны трансформации. Трансформации используют пользовательские или системные хранимые процедуры и автоматически изменяют любой LCR , который удовлетворяет условиям используемого правила.
Queues
Очереди осуществляют хранение LCR, когда они двигаются в системе, т.е. находятся «между» процессами Oracle Streams.
Одна из первоочередных задач при настройке Oracle Streams — создать очереди и привязать их к процессам Oracle Streams. Для каждого процесса Oracle Streams может быть определен набор правил и связанных с этими правилами трансформаций для того, чтобы иметь возможность фильтровать информацию на «входе» и «выходе» процесса.
Очереди поддерживают три типа операций, enqueue — построение LCR в очередь, browse — просмотр LCR и dequeue – удаление.
Capture, Propagation and Apply
- capture,
- propagation,
- apply.
- считывание изменений, содержащихся в журналах транзакций,
- преобразование CR в LCR,
- постановка LCR в очередь.
- просмотр LCR,
- передача LCR из одной очереди в другую, причем очереди могут находится как на одной базе данных, так и на разных,
- удаление LCR.
- извлекает принятые LCR из очереди,
- производит изменения с базой данных в соответствии с LCR,
- удаляет LCR из очереди.
Overview

На рисунке изображена общая схема репликации на основе Oracle Streams:
В примере представлен вариант односторонней репликации, но возможны и другие варианты. К примеру, мы можем добавить другой набор процессов захвата, распространения и применения в противоположном направлении, чтобы получить двухстороннюю репликацию. Точно также, соединяя соответствующие процессы, можно формировать любую репликационную топологию.
Supplemental Logging
Как уже было сказано выше, в основе каждой LCR лежит CR, которая несет минимальное количество информации. Обычно, это возможные к извлечению измененные атрибуты и rowid.
Когда происходит изменение данных, т.е. DML изменение, LCR должен содержать первичные ключи изменяемых строк. Но возможен случай, когда принятые данные применяются в параллельных процессах, и тогда могут понадобиться и другие, не ключевые, колонки. Таким образом, CR может включать дополнительные, не ключевые, колонки. Это нужно для того, чтобы эти колонки оставались неизменными, а также, чтобы усилить проверку соответствия строк источника и приёмника. Добавление этих колонок в журналы транзакций называется supplemental logging.
Apply handler
При решении некоторых задач с помощью Oracle Streams удобно будет изменять принимаемую LCR «на лету» при помощи хранимой процедуры, написанной пользователем и называющейся apply handler.
Например, это необходимо когда репликации происходят между схемами с разными именами и, таким образом, LCR источника не может корректно примениться на приемнике. Отсюда следует, что задачей apply handler является преобразование изменений источника, представленного в виде LCR, так, чтобы они могли корректно применяться на приемнике.
Conflicts
У асинхронной репликации, так же как и у синхронной, есть свои недостатки. Основным недостатком асинхронной репликации является возможность несоответствия данных, также называемых конфликтами данных. Они возникают, когда пользователи делают изменения на приемнике, причем эти изменения конфликтуют с данными источника. Другими словами, после сделанных пользователем изменений данные источника и приёмника не соответствуют друг другу. Эти возможные несоответствия требуют анализа и решения. Такие конфликты чаще всего происходят при обновлении данных на источнике.
При анализе из LCR берутся «старые» данные источника, т.е. данные, которые были до изменения, сделанного конкретным LCR. Затем, во время применения, они сравниваются с текущими значениями в обновляемой строке на приёмнике.
Помимо пользовательских проверок соответствия база данных также отслеживает нарушения ссылочной целостности, уникальности и другие ограничения.
Кроме того, для анализа в Oracle Streams содержится встроенный конфликтный обработчик. Двумя основными «режимами» этого обработчика являются «максимальное значение» и «перезапись». В первом режиме при возникновении конфликта сравнивается старое и новое значения и записывается наибольшее, для строк большее значение выбирается с помощью ASCII кодов, во втором – всегда происходит запись нового значения. Также пользователи могут обрабатывать конфликты и сами, написав хранимую процедуру, которая будет решать возникающие конфликты.
Но практика показывает, что в большинстве случаев «режимы» встроенного обработчика подходят для требований большинства пользователей.
Заключение
В настоящей статье я попытался описать основные процессы и объекты Oracle Streams, которые на мой взгляд могут кому-нибудь интересны. В детали я не вдавался, а описал все поверхностно. Более подробно всегда можно прочитать в официальной документации. Главное знать что читать.
Advanced Queuing и Oracle Streams
Во второй версии Oracle9i компонент AQ стал частью подсистемы Oracle Streams. Последняя состоит из трех основных компонентов: репликация по журналу для сбора данных, очереди для промежуточного хранения данных и определяемые пользователем правила потребления данных. Начиная с Oracle Database 10g Streams включает поддержку технологии Change Data Capture (отслеживание изменений в источниках данных) и передачи файлов. Подсистема Streams управляется из программы Oracle Enterprise Manager.
Извлечение, трансформация и загрузка данных
Инструмент Oracle Warehouse Builder (OWB) служит для проектирования целевых баз данных, особенно используемых в качестве хранилищ (data warehouses), и предоставляет репозиторий метаданных. Однако он более широко известен как графический инструмент построения отображения исходной базы на конечную и генерации сценариев извлечения, трансформации и загрузки данных (ETL). OWB пользуется средствами ETL, которые впервые были встроены в СУБД в версии Ora- cle9i. OWB поставляется в составе СУБД Oracle начиная с версии Oracle Database 10g Release 2. Мы опишем его более подробно в главе 10.
Дополнительно Oracle предлагает инструмент интеграции данных Oracle Data Integrator (ODI), который не так тесно связан с СУБД Oracle, как OWB (хотя база данных Oracle может быть как исходной, так и конечной). Oracle Data Integrator основан на продукте компании Sunopsis, приобретенной Oracle. Помимо средств ETL ODI может генерировать код веб-служб для развертывания в архитектуре SOA и является ключевым компонентом стратегии интеграции с SOA, реализованной в Oracle.
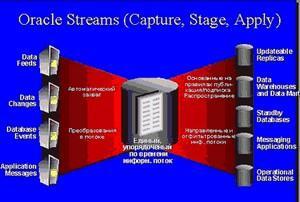
С разрастанием компаний появляется потребность в наличии возможности совместного использования информации между несколькими базами данных и приложениями. Применение разнородных технологий для совместного использования информации лишь усложняет эффективную репликацию. Технология Oracle Streams (Потоки Oracle) представляет собой единое универсальное решение для осуществления обмена информацией по всему предприятию.
В контексте Oracle Streams каждая единица информации называется событием (event), и обмен всеми такими событиями осуществляется в потоке. Поток передает указываемую информацию в указываемые пункты назначения. Oracle Streams захватывает происходящие в базе данных изменения за счет использования как активных, так и архивных журналов повторного выполнения. Он перехватывает их и сохраняет в очередях после выполнения надлежащего форматирования, а затем передает в другие базы данных и, если нужно, применяет их там. С его помощью информацию можно захватывать (собирать), передавать и применять и в пределах одной и той же базы данных Oracle, и между двумя базами данных Oracle, и между несколькими базами данных Oracle и даже между базой данных Oracle и базой данных другого типа (не Oracle).
На заметку! Oracle Streams может применяться на нескольких уровнях: на уровне базы данных, на уровне схемы и даже на уровне отдельных таблиц, и использовать для осуществления перехвата изменений на этих уровнях различные правила.
Переносимые табличные пространства
Переносимые табличные пространства впервые появились в версии Oracle8i. Вместо того чтобы запускать процесс экспорта/импорта, который сбрасывает данные и описывающие их структуры в промежуточный файл для последующей загрузки, можно перевести табличное пространство в режим чтения, перенести или скопировать его из одной базы в другую, а затем смонтировать. При этом в исходной и конечной базах словари, описывающие табличное пространство, должны быть одинаковыми. Такой метод позволяет сэкономить немало времени в случае перемещения больших объемов данных. Начиная с версии Oracle Database 10g можно переносить табличные пространства между различными платформами или операционными системами.
Архитектура Oracle Streams
Тремя базовыми элементами технологии Oracle Streams являются этап захвата, этап подготовки и этап потребления событий внутри базы данных Oracle.
- Сервер считывания, который считывает журналы повторного выполнения и разбивает их на разделы.
- Один или несколько серверов подготовки, которые сканируют разделы журналов параллельным образом и выполняют предварительную фильтрацию изменений.
- Сервер построения, объединяющий записи из журналов повторного выполнения, которые он получает от серверов подготовки и передает их процессу захвата.
Далее процесс захвата преобразует объединенные записи данных повторного выполнения в логические записи изменений (Logical Change Records — LCR) и передает их на этап подготовки для дальнейшей обработки. Каждая LCR-запись описывает изменения, внесенные в одну строку оператором DML. Один оператор DML может приводить к генерации нескольких LCR-записей. LCR-запись, которая представляет собой набор захваченных изменений, также называется событием (event). LCR-записи, содержащие информацию о данных таблицы, называются логическими записями изменений строк (row LCR), а те, что содержат информацию о DDL-изменениях — логическими записями изменений DDL (DDL LCR). Правила, используемые в процессе захвата, зависят от того, какие изменения захватываются. Обратите внимание, что Oracle Streams можно настраивать так, чтобы база данных могла извлекать изменения из потока данных повторного выполнения в исходном месте и затем передавать в целевое место либо отдельно только LCR-записи, либо весь поток данных повторного выполнения с последующим извлечением необходимых LCR-записей непосредственно в самом целевом месте.
На этапе подготовки (staging) процесс Oracle Streams сохраняет события в очереди. В число этих событий могут входить изменения, захваченные как явным, так и не явным образом.
На последнем этапе, этапе потребления (consumption), находящиеся в очереди события начинают использоваться в целевой базе данных. Перед использованием событие должно удаляться из очереди. Пользователи и приложения могут удалять события из очереди явным образом. Однако по большей части их удаление из очереди происходит все-таки в рамках неявного процесса применения (apply process). Удаление из очереди и обработка захваченных данных осуществляется в соответствии с правилами. В ходе процесса применения захваченные данные могут как применяться напрямую, так предварительно преобразовываться с использованием кода PL/SQL.
Читайте также: