
Нужен ли мощный компьютер для нейронных сетей
Собственно, как понятно из заголовка, я хочу попытаться собрать домашний компьютер для работы с нейронками (Tenserflow + CUDA под Ubuntu) и не разориться – хочу это сделать по двум причинам: у меня нет ноута с Nvidia карточкой и я устал платить за сервера EC2 на Amazon (дорого), а тренировка модели на CPU может занять буквально месяцы.
Само собой, второй ОС я туда поставлю Windows и буду играть в какие-нибудь игры вроде лучших игр на свете, но это не основная причина сбора компьютера.
Немного поискав в интернете, я наткнулся на эту инструкцию:
Ниже я приведу конфигурацию которую предлагает автор и хотел попросить кого-то кто разбирается в теме оценить конфигурацию и посоветовать что-то лучше чем у автора и где лучше заказывать комплектующие (я нахожусь в Европе).
Видеокарта – 829$
Автор предлагает выбрать из GTX 1070, GTX 1070 Ti, GTX 1080, GTX 1080 Ti и Titan X. Видео-карта нужна Nvidia, так как CUDA уже стандарт для работы с TF. Тут нечего менять мне кажется, самая дорогая часть конфигурации – бы выбрал GTX 1080 Ti (с перспективой докупить еще одну позже, когда вторую почку купят).
Процессор – 200$
Автор предлагает Intel i5 7500, но отмечает, что если взять два титана GPU, то процессор будет работать в 16 PCIe lanes , а для двух титанов нужно 32 PCIe lanes – я не знаю что это все значит, просто вставил сюда, надеюсь поможет кому-то в чем-то.
Тут все просто, две планки по 16 – 32 GB RAM DDR4 DRAM 2666MHz
Жесткий диск – 189$ + 54$
Материнская плата – 185$
Для поддержки потенциально двух GPU и выбранного процессора автор предлагает Asus TUF Z270
Блок питания – 89$
Как пишет автор «Блок питания должен обеспечивать достаточное количество манны для CPU, двух GPU и 100 ватт сверху», поэтому он предлагает – EVGA 750 GQ
Мне пофигу как бы он выглядел, главное чтобы все влезло – автор предлагает такой корпус:
Итого ~ $1966
В общем, помогите выбрать конфигурацию, пожалуйста.
Да ясно чем он там собрался заниматься
Вживую лучше же:
Всякие Таркины, Леи и даже Танос курят в сторонке.
Как говорится, если гора не идет к Магомеду.
присмотрись лучше к AMD Ryzen что то типа 1600x/2600x, +/-(лень гуглить цену) за те же деньги, ты получишь камень который будет актуален еще много лет, а у 7500 нет будущего, если уж на интел смотреть, то покупку i5-8500 еще как то можно оправдать
Спасибо, а материнская плата остается та же? AMD Ryzen с такими же сокетами как и i5? Я давно последний раз компы трогал, еще разные сокеты были в ходу
нет, для AMD сокет AM4, если нужен будет SLI нужно смотреть на чипсеты x370/x470, если SLI не нужен, то B350/B450
Если вычисления умеют работать с SLI то двух 1080 обычных хватит за глаза. Проц лучше взять i7, core i5 не раскроет эти мощные карточки.
Если вычисления умеют работать с SLI то двух 1080 обычных хватит за глаза. Проц лучше взять i7, core i5 не раскроет эти мощные карточки.
РАСКРЫТИЕ
2D18
РАСКРЫТИЕ
Ну давай поиграй на селероне с 1080ti в какой нибудь батлфилд.
C таким же успехом могу привести в пример какой нибудь сталкер или крайзис первый где со старым Core 2 Quad и 1080 гпу будет загружен почти на 100%. Посмотри видос и не неси бред про какое то "расскрытие".
Не. СПС. Не доверяю видосам всяких личностей в маске с ютаба.
Какой то он черезчур агрессивный.
Прям как свидетели АМД.
ну тогда пиши на своем лбе "я - мракобес"
Жалко тут подписей нет, я б поставил. Мне не жалко.
Твой кор 2 куард задохнется даже в уже не совсем новом бф1, это проц для серфинга интернета и для "мамкиных кибер спортсменов", которые играют только в доту, кс и танки.
Интересно, с чем "несогласны" те, кто ставит минусы? Их кор куард "уникальный" и все тащит? Ну давайте хоть одно подтверждение этого, которого, естественно, нет. У меня 2 таких проца, в том числе и максимальный для сокета 775, я его тестил в максимальном разгоне которого удалось добиться (4Ггц) и он НЕ ТАЩИТ, все. Я даже думаю что у этих людей и проца ни одного нет с 775, но надо же выпендриться своими нулевыми знаниями, чтобы почувствовать собственную важность.
А что такое раскрытие? Я просто совсем не в теме
мракобесие для несведущих. Не стоит обращать внимания.
под "раскрытием" имеется в виду сценарий, когда процессор нагружается первым на 100% и далее видеокарту приложение нагрузить не может, эдакое бутылочное горлышко (bottleneck)
А материнская плата остается та же?
Комментарий удален модератором
Согласен. Я дебил. 1080ti лучше из за 11 гигов против 8 vram.
Так ты еще видеокарты по объему видеопамяти выбираешь, мол чем больше тем лучше? Ясно, понятно.
4 гига 4 ядра! Ага.
Но вообще то у чувака тут дип лернинг. Разве для этого не требуется овердохера видеопамяти?
Нужно же где то хранить все эти тыщи картинок.
На счет объема видеопамяти не, могу сказать не вникал, но знаю что для DL нужны тензорные или CUDA ядра, которых у 1080ti на 1к больше чем у обычной 1080, да и ПСП у ti выше на 30%
Ну тогда и правду нужна ti. Я что то проступил, да.
Комментарий удален модератором
Вполне сойдет и такая. Хорошая плата от Асуса с неплохой системой питания.
А если покупать комплектующие, я слышал кто-то советовал это делать в Германии, это так?
На мой взгляд лучше здесь. Случись что с гарантией проще обращаться.
Комментарий удален модератором
Computeruniverse и ждать скидки
Комментарий удален модератором
Не, ну вдруг у человека не только cuda вычисления. Тогда i7 будет намного лучше i5.
Комментарий удален модератором
Но надо учесть, что SLI бесполезно в играх, оно там просто не работает и его поддержку производители вроде как сворачивают окончательно.
В оригинальной статье хотя бы есть пример того, с какими данными он работает (MNIST). А вы какие задачи решать собираетесь?
Собирать армию НейроИлюхеров, видимо.
Она и на регулярках работает нормально ;)
Это как в West World?))
Илюхер слишком прост и умешается в пару регулярок?))
Как оказалось, да :)
Я так себе погромист, зато я умею следовать инструкциям, так что это скорее просто хобби – находить какие-то исходники на гитхабе и смотреть.
Или deepface, или wavenet. Вообще у меня долгий список нейронок, я их выкладываю в свой канал на эту тему, но ссылку не дам, чтобы не было рекламой :)
MNIST – это просто с чего все начинают в этой теме.
Возьмите лучше Intel Xeon E5-1650 6 ядер 12 потоков или E5-2680v2 10 ядер 20 потоков и китайскую мать, второй проц в те же 200$ выйдет, первый и того дешевле, а производительность как небо и земля, особенно в мультипотоке, для задач которые хорошо параллелятся. Не знаю правда ваши к ним относятся, какая нагрузка на проц идет при них, но i5 7500 это несерьезно уже даже для того, чтобы в игрушки поиграть.
Там как раз все расчеты в основном на GPU, поэтому акцент на на них – но я изучу, спасибо.
Всеравно 6 ядер проца под игрушки лучше и с запасом на будущее, а 8700К будет стоить раза в 3-4 дороже. Про оперативку я вообще молчу, сейчас на неё цены бешенные, а серверная оператива для зеона стоит по 60$ за 16 гб. Можно ещё е5 1620, там 4 ядра 8 потоков, стандарт на сегодняшний день за смешную цену меньше 100 $. Я вообще уже давно начал статью писать, но все никак не напишу, там как раз про подобные экзотические сборки с Китая. Решил написать, так сам на такой сижу с недавних пор, на e5 1650.
Бери GTX 1080 Ti, хотя бы просто из-за VRAM. При обучении на картинках она понадобится. В целом конфигурация из статьи - вполне хорошая машина для разработки.
Если расчеты в приоритете, то может найти по-дешевке пару 980ti?
Явно быстрее одиночной 1080ti
нужно 32 PCIe lanes – я не знаю что это все значит
количество линий PCI-express, у i5 7500 16 линий, у рязяни 24. Для расчетов не важно, для игр - ну на 8x PCEe народ не особо жалуется, особенно с большим количеством видеопамяти (8Gb+). .
Смысл кому-то продавать 980ti, она же ещё актуальна и неплохо тащит. Если кто-то и продаёт такую карту, то с ней явно что-то не так, зачем так рисковать.
Выбираем видеокарту под разные задачи машинного обучения и обходим «подводные камни». Узнаем, какие карты не стоит покупать, из чего составить кластер и что делать при скромном бюджете.


Рис. 1. Архитектура центрального процессора (слева) и графического процессора
Центральный процессор (ЦП) не оптимизирован для одновременного выполнения большого количества простых операций. Для параллельных вычислений лучше подходит графический процессор (ГП):
- ГП состоит из множества арифметико-логических устройств ( АЛУ );
- б о́ льшая часть транзисторов обрабатывает данные, а не занимается кэшированием и управлением потоками;
- процесс создания, управления и удаления потоков происходит эффективнее, чем у ЦП.
2.2. Иерархия памяти
Локальная память (local memory):
Разделяемая память (shared memory):
Глобальная память (global memory):
Константная память (constant memory):
Текстурная память (texture memory):
Последовательность шагов при выборе ГП.
- Определить область применения: соревнования в Kaggle, глубокое обучение, исследования в области компьютерного зрения, обработка естественного языка и т. д.
- Выбрать необходимый объем памяти.
- Узнать: сколько видеокарт поместится в системном блоке; правильно ли организована циркуляция воздуха в системном блоке; хватит ли мощности блока питания.
Источники
Больше полезной информации вы найдете на наших телеграм-каналах «Библиотека программиста» и «Книги для программистов».

Свой собственный сервер для обучения — как машина в 20 веке: если вы всерьез занимаетесь Data Science, рано или поздно вы придете к тому, что нужна единая настроенная среда, уверенность в ресурсах, независимых от правил работодателя и админов. Кто-то скажет, что всё можно делать в облаках, однако постоянный доступ, долгие эксперименты 24/7, да еще и с хранением данных выйдут в копеечку.
Итак, если вы решились — нужно строить свой город-сад.
Давайте посмотрим, что нам нужно:
- Датасеты где-то должны лежать. Нужна возможность хранить и иметь быстрый доступ к большим объемам данных.
- Видеокарта. Resnet-ы и Unet-ы ждут.
- Многоядерный процессор. Многие забывают, но многие операции в numpy, pandas, да и алгоритмы градиентного бустинга отлично распараллелены для multithreading, но все еще не работают на видеокартах.
- Оперативная память. Должна вмещать все.
- И остальное, что должно обслуживать параметры: достаточный источник питания, корпус и материнская плата, где все это счастье поместится, операционная система.
Итак, первое и самое дорогое — это видеокарта. Давайте признаем очевидное: Nvidia является сейчас абсолютным лидером по производительности и совместимости фреймворков, и если вы пишете нейросети, то вам нужно cudnn и cuda. Но хорошие видеокарты стоят круглые суммы: если мы хотим хотя бы 11 Gb памяти и соответствующую производительность, надо выложить 1000 $+ за топовую модель. Видеокарты разлетаются, а цены растут. Как быть? Надо вспомнить, что прямо сейчас мы живем в уникальное время: пузырь криптовалют лопается по швам, и на рынок выходит большое количество видеокарт от майнеров. Я являюсь счастливым обладателем подержанной 1080 Ti за 30 тыс. рублей, и почти за год она ни разу меня не подвела, работая 24/7. Возьмите компьютер с Windows (почему-то большинство программ тестирования видеокарт именно под эту систему), запаситесь программами, проверьте вашу рабочую лошадку вдоль и поперек и смело берите графический ускоритель в 1.5-2 раза дешевле.
Продолжая идею вычислителей, перейдем к процессору. Тут хотелось бы сказать, по аналогии с предыдущим, что абсолютный лидер — Intel (тем более, я там когда-то работал). Это верно… только если мы говорим про однопоточные приложения или неограниченный бюджет. Однако, у нас ни тот, ни другой случай, а хочется параллелить и денежку оставить, тут к нам приходит AMD Ryzen в целом и их линейка Threadripper в частности. За 700-1000$ можно купить 24-32 ядерный кристалл, на котором Catboost будет летать, аналогичные параметры Intel стоят в два раза дороже. Конечно, есть большое “НО”: своей производительности Threadripper обязан специфической конструкции, и с этим придется считаться (об этом ниже)…

Немного лирики от сборщика: «Думаю, после недавнего фиаско Intel с 10980XE вопрос о том, какой процессор выбрать для многопоточных вычислений, имеет довольно понятный ответ. Но… всё может поменяться».
И тут мы переходим к памяти. Делать сервер меньше чем с 32 гигабайтами оперативной памяти странно (тогда уже проще считать на фитнес-браслетах) и лучше брать память с высокой частотой (3200+, процессоры архитектур ZEN и ZEN 2 ее любят). Конечно, оперативная память — не самый сложный компонент схемы, а значит и производителей много, но лучше брать проверенных (я взял Corsair). Тут надо определиться с тем, сколько брать, и с количеством каналов. Самый простой ответ: побольше, чтобы на каждой плашке да по 16 гигабайт сидело. Кажется, что можно и 256 гигов оперативы заполучить в свой ПК. Но не всё так просто. Если вы берете двухканальную память, то к одному объему информации в памяти будет лезть вдвое больше активных ядер, а это значит, что снижается скорость доступа – тут надо вспомнить про необходимость быстрого доступа к памяти, как критичное требование. Значит берем четырехканальную. На каждой плашке у нас будет по 8 гигов памяти.
Еще один инсайт от сборщика, а точнее, обещанные подробности о Threadripper: «В целом, если в вас сидит мантра «все каналы памяти должны быть заполнены» (а у Threadripper их 4) можете скроллить вниз. Остальным напоминаю, что у этого процессора старой архитектуры интересная структура из 4 NUMA nodes, узлов с неоднородным доступом к памяти. Работать они могут и с одним каналом, но тогда у вас будут копиться задержки, вызванные этой архитектурой. В более новых Threadripper, построенных уже на ZEN 2, эта особенность ликвидирована, но пожелание компьютеру многих каналов памяти остается».
Итак, мы вывели ограничение материнской платы на количество слотов под память, хотя бы 4 (чтобы получить 32 гигабайта), а желательно — 8. Еще стоит сразу подумать, собираетесь ли вы брать вторую видеокарту, и, конечно, посмотреть на производителя. Тут мы выясняем, что предложений на рынке для PC (не серверных), подходящих под наши ограничения, не так много (по крайней мере, было немного, когда эта машина собиралась). Конечно, на ум приходит ASUS, и при неограниченном бюджете взял бы его, но пытаясь влезть в рамки, берем ASRock, младшего брата большой компании, доступного даже после падения рубля.
Конечно, имея такой быстрый вычислитель, странно упираться в скорость жесткого диска, значит нам нужен SSD. Они, конечно, дороже, однако выясняется, что мало какие задачи требуют терабайтов данных в постоянном доступе. Значит, можно взять 512 Гб, а датасеты, которые пока не хочется удалять, держать вместе с коллекцией домашних фильмов — на отдельном классическом терабайтном диске. Или больше. Сколько нужно и что позволит бюджет.
Собрав основные компоненты, прикидываем, что может дать хозяйству мощность. Тут подумайте о развитии и, например, о второй видеокарте (лучше взять с запасом). И, конечно, надо решить, кто охладит эту мощь. Threadripper-ы греются, как цветочные цены на 8 марта, так что нужна мощная система охлаждения. Формально подойдет сильная воздушная и водяная, но я советую брать водяную: по цене сравнима с сильной воздушной, но не будет постоянного ощущения, что живете на взлетно-посадочной полосе. Плюс, за последнее время количество производителей, предлагающих вменяемые охладители специально для Threadripper, выросло — есть из чего выбрать.

В целом все собрано, осталось упаковать во вместительный корпус — тут советов не будет, это шанс для самовыражения, — можно выбрать тот, который понравится лично вам.
Существуют следующие возможности покупки всего счастья:
- Заказать собрать кому-то внешнему
- плюсы: могут еще раз проверить комплектацию, нет проблем с совместимостью
- минус: ~10-15% стоимости в зависимости от сложности работы и стоимости комплектующих
- Выписать всё на листочек, прийти на Савеловский/Горбушку (если живете в Москве) и собрать там.
- плюсы: точно ничто не побьется при доставке, все сделают при вас, меньше денег за сборку
- минусы: могут быть не самые дешевые компоненты (даже в рамках одного рынка цена прыгает до 50%, плюс за эту цену могу попробовать поставить Б/У)
- Заказать все на Яндекс-маркете
- плюсы: можно дешевый вариант
- минусы: сложно проверить доставку
- Заказать всё за границей (алиэкспресс/ebay)
- плюсы: самый дешевый вариант, сюрприз по приезду
- минус: сюрприз по приезду (серьезно, не надо так – в Спортлото чаще выигрывают)
Когда все приехало и собрано, осталось накатить систему.
Это история для отдельного поста, здесь расскажу вкратце: поскольку я хотел его еще использовать как десктоп и имел предыдущий опыт работы в Linux, то по причине популярности выбрал Ubuntu Linux.
Когда все работает, попросите у своего провайдера статический IP — это бесплатно или недорого и обеспечит доступ к вашим юпитер-ноутбукам почти отовсюду.
Напоследок скажу, что высказал свое мнение, которое сложилось в результате изучения рынка и общения со специалистами. В бюджет я уложился, и почти год чудо современных технологий бесперебойно работает. Через некоторое время поставил jupyterhub и стал пускать друзей, так и живем нашей небольшой коммуной на сервере, да сетки обучаем, чего и вам желаю.

Финальный подсчет (цены начала 2019 года):
Автор: Николай Князев, руководитель группы машинного обучения компании «Инфосистемы Джет»
В сфере Data Science мощное железо с серверным уровнем производительности – необходимый инструмент. Да и в перспективе собственные мощности обходятся куда дешевле, особенно учитывая необходимость постоянного хранения датасетов.
TITAN RTX
Плавно подходим к оптимальным решениям для машинного обучения не инженерной направленности. По производительности эта карта сравнима с Quadro RTX 6000, но стоит в несколько раз дешевле. Причем использование двух и более TITAN RTX даст вам больше производительности, чем одна Quadro RTX 6000. Недостаток – отсутствие полноценной поддержки профессиональных драйверов и ПО от NVIDIA для инженерии и работы в трехмерной среде.
РЕШЕНИЯ ОТ HYPERPC
Quadro RTX 6000, 5000, 4000
Три инженерных видеокарты с относительно высоким уровнем производительности. Цена все так же высокая. По сравнению с игровыми решениями, конечно.
2.1. CUDA
Графический процессор состоит из набора независимых мультипроцессоров, которые включают в себя :
На одном ядре CUDA (архитектура параллельных вычислений от NVIDIA) выполняется одна нить, иначе – поток. Каждому потоку соответствует один элемент вычисляемых данных. Потоки образуют блоки, которые общаются между собой через:
При частоте 1 ГГц процессор делает 10 9 циклов в секунду. Операции занимают больше времени, чем один цикл, поэтому создается конвейер , где для начала новой операции необходимо дождаться окончания предыдущей .
Мультипроцессор на каждом такте выполняет одну и ту же инструкцию над варпом (warp) – группой из 32 потоков. Потоки одного варпа принадлежат одному блоку и могут взаимодействовать только между собой. Каждому потоку и блоку присваивается идентификатор – трехмерный целочисленный вектор:
Блоки группируются в сетки блоков . Размеры блока и сетки блоков задаются переменными blockDim и gridDim при вызове ядра. Потокам из одного блока доступна разделяемая память (shared memory). Их выполнение может быть синхронизировано.
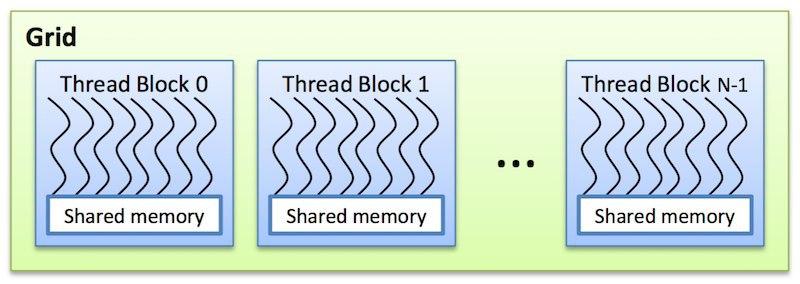
Рис. 5. Сетка блоков в CUDA
Алгоритм работы технологии CUDA выглядит следующим образом.
- Выделение памяти на ГП.
- Копирование расчетных данных в выделенную память ГП.
- Вычисления на ядрах ГП.
- Перенос результатов вычислений в оперативную память для обработки ЦП.
- Освобождение памяти ГП.
Оперативная память
Лучше всего использовать высокочастотную память DDR4, она не такая дорогая и даст вам хороший прирост мощности. 4 канала на процессоре – значит, 8 слотов на материнской плате. Минимум, который стоит ставить на компьютер для машинного обучения, – это 32 Gb, но чем больше – тем лучше. Лучше занять все слоты, чтобы обеспечить каждому ядру процессора максимально быстрый доступ к памяти. Максимально возможный объем памяти для i9 – 256 Gb.
Быстрый доступ к датасетам нужно обеспечить, чтобы работа накопителя не замедляла остальные элементы компьютера. Новые SSD m.2 дают возможность доступа к данным на скорости до 3,5 Gb в секунду. Не обязательно хранить на них всю информацию, можно поставить один SSD и расширить объем памяти дополнительным HDD. Причем необязательно ставить HDD в систему, можно подключить его к локальной сети, снабдив статичным IP адресом, и вы сможете получить к нему доступ с любого устройства, подключенного к интернету.
В сфере Data Science мощное железо с серверным уровнем производительности – необходимый инструмент. Да и в перспективе собственные мощности обходятся куда дешевле, особенно учитывая необходимость постоянного хранения датасетов.
3.3. Тензорные ядра
Тензорные ядра быстрее CUDA-ядер , потому что им требуется меньше циклов для операций с матрицами. В чипах Ampere (линейка RTX 30) стало меньше тензорных ядер, но возросла их производительность .

Рис. 11. Архитектура тензорных ядер в GeForce RTX 2080 Super и GeForce RTX 3080
Quadro GV100
Это самый мощный графический ускоритель на данный момент, она разработана именно для обслуживания и обучения нейронных сетей. Главным преимуществом является память, ее объем и скорость доступа. Из недостатков можно выделить цену и отсутствие RT ядер.
3.4. Пропускная способность памяти
Тензорные ядра быстрые и обычно простаивают до 70% времени, ожидая данные из глобальной памяти. Поэтому выбирайте ГП с максимальной пропускной способностью памяти. Еще нужна большая разделяемая память и кэш L1, чтобы сократить число обращений к внешней памяти и держать данные ближе к АЛУ.
Сколько нужно памяти:
- при использовании предобученных моделей в Transformer ≥ 11 ГБ;
- обучение больших моделей в Transformer или в сверточных нейронных сетях ≥ 24 ГБ;
- прототипирование нейронных сетей ≥ 10 ГБ;
- для Kaggle ≥ 8 ГБ;
- компьютерное зрение ≥ 10 ГБ.
Видеокарта
Производительность карты при машинном обучении напрямую зависит от скорости и объема памяти, а также от количества ядер CUDA. Такие платформы, как PyTorch, MXNet, TensorFlow, а также основанные на их принципах гибриды используют библиотеки для GPU ускорения, например, cuDNN, DALI и NCCL. Это помогает ускорить обучение с использованием одного или нескольких GPU.
В таблице – характеристики всех топовых решений от NVIDIA.
HYPERPC PRO T
HYPERPC PRO T – это серия рабочих станций, основанная на картах NVIDIA TITIAN RTX.
HYPERPC PRO T5 STUDIO – базовая модель линейки. Она работает на базе процессора Intel Core i9-10900X, это 10 ядер и 20 потоков на частоте 3700 МГц в штатном режиме и до 4700 МГц с функцией Turbo Boost. Материнская плата ASUS WS X299 PRO SE имеет 8 слотов памяти, которая работает в четырехканальном режиме. Стандартная сборка оборудована 64 Gb памяти (4х16Gb HyperX Predator RGB DDR4-3200), что позволяет оставить свободным 4 слота под будущий апгрейд. Тут установлено два накопителя – 1TB Samsung 970 EVO Plus и 4TB Seagate BarraCuda, а это быстрый доступ к данным и неограниченное пространство для хранения результатов вашей работы.
Процессор
Для машинного обучения необходимо много оперативной памяти. Чтобы ускорить доступ к ней, необходим процессор, который поддерживает четыре канала, а не 2, как в обычных пользовательских решениях. На данный момент среди не серверных решений на рынке есть прекрасный вариант – Intel Core i9. Много ядер, многопоточность, поддержка 4 каналов памяти, хорошая частота и возможность разгона.
Выбор конкретной модели – вопрос бюджета, чем больше ядер и частоты – тем лучше. Также стоит отметить, что желательно иметь возможность разгона для кратковременного увеличения мощности.
3.11. Можно ли использовать разные карты вместе?
Да, можно! Но будет сложно эффективно распараллелить графические процессоры разных типов, т. к. быстрый ГП будет ждать, пока медленный ГП дойдет до точки синхронизации.
Quadro RTX 8000
Топовое решение для инженеров, огромное количество памяти и прекрасная производительность. Недостаток – цена, не совсем оправданная для Data Science, так как вы переплатите за целый мешок технологий, созданных специально для работы с трехмерной графикой и инженерными программами.
Выбор комплектующих
Большая часть фреймворков адаптируется под карты NVIDIA с их замечательными ядрами CUDA, которые пока никто заменить не смог. Что касается процессора, то выбор тут очевиден – Intel с максимальным количеством ядер и возможностью разгона. Так можно получить хорошую производительность в однопоточных и многопоточных вычислениях. К материнской плате также есть особые требования – это, желательно, 4 канала памяти (чтобы раскрыть потенциал процессора) и хорошее охлаждение на главных узлах питания.
Излишняя мощность не будет вам обузой. Вы всегда сможете предоставлять услуги для облачных вычислений другим специалистам, которые работают с машинным обучением. Все свободное время и даже в ваш отпуск компьютер будет приносить деньги. Хорошая система водяного охлаждения сделает работу бесшумной и позволит не прерывать процесс обучения 24/7.
3.12. Что такое NVLink и полезно ли это?
NVLink – высокоскоростное соединение между ГП. В небольших кластерах (< 128 ГП) он не даст преимущества по сравнению с передачей по PCIe.

Рис. 20. Производительность NVLink M40, P100, V100 и A100
3.8. Не покупайте эти карты
Не покупайте более одной видеокарты RTX Founders Editions или RTX Titans, если нет PCIe-удлинителей для решения проблем с охлаждением.

Рис. 17. Видеокарта NVIDIA RTX Titan
Tesla V100 или A100 рентабельны только в кластерах. Карты серии GTX 16 имеют низкую производительность, так как из них убрали тензорные ядра. Аналоги GTX 16: б/у RTX 2070, RTX 2060 или RTX 2060 Super.

Рис. 18. Видеокарта NVIDIA Tesla V100
При наличии RTX 2080 Ti и выше, обновление до RTX 3090 невыгодно . Прирост производительности мал, а риск получить проблемы с питанием и охлаждением в картах RTX 30 высокий. Апгрейд оправдан, если для задач требуется больше памяти.
Видеокарта
Производительность карты при машинном обучении напрямую зависит от скорости и объема памяти, а также от количества ядер CUDA. Такие платформы, как PyTorch, MXNet, TensorFlow, а также основанные на их принципах гибриды используют библиотеки для GPU ускорения, например, cuDNN, DALI и NCCL. Это помогает ускорить обучение с использованием одного или нескольких GPU.
В таблице – характеристики всех топовых решений от NVIDIA.
| Ядра CUDA | Ядра NVIDIA Tensor | Ядра NVIDIA RT | Количество памяти | Ширина шины памяти | Пропускная способность памяти | Производительность FP32 | |
|---|---|---|---|---|---|---|---|
| Quadro GV100 | 5120 | 640 | нет | 32GB HBM2 | 4096 бит | 870,4 ГБ/с | 14.8 TFLOPS |
| Quadro RTX 8000 | 4608 | 576 | 72 | 48GB GDDR6 с ECC | 384 бит | 624 ГБ/с | 16.3 TFLOPS |
| Quadro RTX 6000 | 4608 | 576 | 72 | 24GB GDDR6 | 384 бит | 624 ГБ/с | 16.3 TFLOPS |
| Quadro RTX 5000 | 3072 | 384 | 48 | 16GB GDDR6 | 256 бит | 448 ГБ/с | 11.2 TFLOPS |
| Quadro RTX 4000 | 2304 | 288 | 36 | 8GB GDDR6 | 256 бит | 416 ГБ/с | 7.1 TFLOPS |
| NVIDIA TITAN RTX | 4608 | 576 | 72 | 24GB GDDR6 | 384 бит | 672 ГБ/с | 16.3 TFLOPS |
| RTX 2080 Ti | 4352 | 544 | 68 | 11GB GDDR6 | 352 бит | 616 ГБ/с | 13.5 TFLOPS |
| RTX 2080 SUPER | 3072 | 384 | 48 | 8GB GDDR6 | 256 бит | 496 ГБ/с | 11.2 TFLOPS |

Quadro GV100
Это самый мощный графический ускоритель на данный момент, она разработана именно для обслуживания и обучения нейронных сетей. Главным преимуществом является память, ее объем и скорость доступа. Из недостатков можно выделить цену и отсутствие RT ядер.

Quadro RTX 8000
Топовое решение для инженеров, огромное количество памяти и прекрасная производительность. Недостаток – цена, не совсем оправданная для Data Science, так как вы переплатите за целый мешок технологий, созданных специально для работы с трехмерной графикой и инженерными программами.

Quadro RTX 6000, 5000, 4000
Три инженерных видеокарты с относительно высоким уровнем производительности. Цена все так же высокая. По сравнению с игровыми решениями, конечно.

TITAN RTX
Плавно подходим к оптимальным решениям для машинного обучения не инженерной направленности. По производительности эта карта сравнима с Quadro RTX 6000, но стоит в несколько раз дешевле. Причем использование двух и более TITAN RTX даст вам больше производительности, чем одна Quadro RTX 6000. Недостаток – отсутствие полноценной поддержки профессиональных драйверов и ПО от NVIDIA для инженерии и работы в трехмерной среде.

RTX 2080 Ti и 2080 SUPER
Топовые игровые видеокарты, которые оборудованы теми же аппаратными решениями, что и их профессиональные «коллеги», но драйвера больше заточены под игры. Хотя их совместимость с фреймворками не ставится под сомнение. Вывод: две RTX 2080 Ti мощнее, чем одна TITAN RTX, хотя стоимость такого решения также будет выше примерно на 1000$.
RTX 2080 Ti и 2080 SUPER
Топовые игровые видеокарты, которые оборудованы теми же аппаратными решениями, что и их профессиональные «коллеги», но драйвера больше заточены под игры. Хотя их совместимость с фреймворками не ставится под сомнение. Вывод: две RTX 2080 Ti мощнее, чем одна TITAN RTX, хотя стоимость такого решения также будет выше примерно на 1000$.
3.10. Необходимы только 8x/16x PCIe-слоты?
Использовать исключительно 8x и 16x PCIe-слоты необязательно. Допускается работа двух ГП на слотах 4х. При установке четырех ГП предпочтение отдавайте слотам 8x на каждый ГП, так как производительность слота 4x ниже на 5-10%.

Рис. 19. Слоты PCIe x1, x4, x16
Оперативная память
Лучше всего использовать высокочастотную память DDR4, она не такая дорогая и даст вам хороший прирост мощности. 4 канала на процессоре – значит, 8 слотов на материнской плате. Минимум, который стоит ставить на компьютер для машинного обучения, – это 32 Gb, но чем больше – тем лучше. Лучше занять все слоты, чтобы обеспечить каждому ядру процессора максимально быстрый доступ к памяти. Максимально возможный объем памяти для i9 – 256 Gb.
Выбор комплектующих
Большая часть фреймворков адаптируется под карты NVIDIA с их замечательными ядрами CUDA, которые пока никто заменить не смог. Что касается процессора, то выбор тут очевиден – Intel с максимальным количеством ядер и возможностью разгона. Так можно получить хорошую производительность в однопоточных и многопоточных вычислениях. К материнской плате также есть особые требования – это, желательно, 4 канала памяти (чтобы раскрыть потенциал процессора) и хорошее охлаждение на главных узлах питания.
Излишняя мощность не будет вам обузой. Вы всегда сможете предоставлять услуги для облачных вычислений другим специалистам, которые работают с машинным обучением. Все свободное время и даже в ваш отпуск компьютер будет приносить деньги. Хорошая система водяного охлаждения сделает работу бесшумной и позволит не прерывать процесс обучения 24/7.
SSD
Быстрый доступ к датасетам нужно обеспечить, чтобы работа накопителя не замедляла остальные элементы компьютера. Новые SSD m.2 дают возможность доступа к данным на скорости до 3,5 Gb в секунду. Не обязательно хранить на них всю информацию, можно поставить один SSD и расширить объем памяти дополнительным HDD. Причем необязательно ставить HDD в систему, можно подключить его к локальной сети, снабдив статичным IP адресом, и вы сможете получить к нему доступ с любого устройства, подключенного к интернету.
Процессор
Для машинного обучения необходимо много оперативной памяти. Чтобы ускорить доступ к ней, необходим процессор, который поддерживает четыре канала, а не 2, как в обычных пользовательских решениях. На данный момент среди не серверных решений на рынке есть прекрасный вариант – Intel Core i9. Много ядер, многопоточность, поддержка 4 каналов памяти, хорошая частота и возможность разгона.
Выбор конкретной модели – вопрос бюджета, чем больше ядер и частоты – тем лучше. Также стоит отметить, что желательно иметь возможность разгона для кратковременного увеличения мощности.
3.6. Электропитание
Картам может не хватить мощности блока питания. Четыре карты RTX 3090 потребляют на пике 1400 Вт. Продаются блоки питания на 1600 Вт, но остальным комплектующим 200 Вт может быть недостаточно.

Рис. 13. Блок питания Super Flower Leadex Titanium SF-1600F14HT на 1600 Вт
3.5. Система охлаждения
В конструкции системы охлаждения Reference RTX 30 (NVIDIA) первый вентилятор расположен на верхней стороне видеокарты. Он выдувает воздух в пространство, где расположена оперативная память и процессор. Второй вентилятор выдувает воздух сразу из корпуса (Рис. 12).
Рис. 12. Cистема охлаждения Reference RTX 30
Еще нет тестов, подтверждающих эффективность решения и необходимость замены штатной системы охлаждения. Установка нескольких ГП в одном корпусе может негативно сказаться на циркуляции потоков воздуха внутри корпуса и охлаждении видеокарт.
3.7. Рекомендации для кластеров
Для кластеров важно надежное электропитание , доступное в дата-центрах, но по лицензионному соглашению карты RTX в них размещать запрещено . Для небольшой системы подойдет Supermicro 8 GPU.

Рис. 14. Сервер SuperMicro Superserver 4028gr-tvrt, до 8 Tesla v100 sxm2
Для кластера из 256+ ГП – NVIDIA DGX SuperPOD.

Рис. 15. Суперкомпьютер NVIDIA DGX SuperPOD
При 1024+ ГП – Google TPU Pod и NVIDIA DGX SuperPod.

Рис. 16. Суперкомпьютер Google TPU Pod на тензорных процессорах
3.2. Когда нужно больше 11 ГБ памяти
Не менее 11 ГБ памяти нужно при работе с архитектурой Transformer , распознаванием медицинских изображений, компьютерным зрением и работой с большими изображениями.
3.1. Когда достаточно менее 11 ГБ памяти
Базовые навыки в глубоком обучении можно освоить, тренируясь на небольших задачах с малыми входными параметрами , поэтому достаточно RTX 3070 (8 ГБ, GDDR6) и RTX 3080 (10 ГБ, GDDR6X). Для прототипирования лучший выбор – RTX 3080.

Рис. 10. Видеокарта NVIDIA RTX 3080
3.14. Итог
- топовые карты: RTX 3080, RTX 3090;
- вторая лига: RTX 3070, RTX 2060 Super;
- бюджетный вариант: RTX 2070, RTX 2060, GTX 1070, GTX 1070 Ti, GTX 1650 Super, GTX 980 Ti;
- новичкам: RTX 3070;
- просто попробовать: RTX 2060 Super, GTX 1050 Ti, облачные сервисы;
- соревнования Kaggle: RTX 3070;
- компьютерное зрение, машинный перевод: четыре RTX 3090;
- NLP с простыми вычислениями: RTX 3080;
- кластеры менее 128 ГП: 66% 8x RTX 3080 и 33% 8x RTX 3090;
- кластеры от 128 до 512 ГП: 8x Tesla A100;
- кластеры более 512 ГП: DGX A100 SuperPOD;
Напоследок несколько сравнительных гистограмм характеристик различных GPU.
Рис. 21. Производительность видеокарт относительно RTX 2080 Ti. Рис. 22. Производительность на доллар (US) ГП относительно RTX 3080. Рис. 23. Производительность на доллар (US) четырех ГП относительно четырех RTX 3080. Рис. 24. Производительность на доллар (US) восьми ГП относительно восьми RTX 3080.
В этом руководстве мы рассмотрели устройство графического процессора и определили параметры, которые влияют на производительность в задачах глубокого обучения. Если запускаете расчет нейросеток время от времени, то апгрейд можно проводить через одно поколение графических процессоров.
3.13. Что делать, если не хватает денег на топовые ГП?
Купить подержанные ГП, либо воспользоваться облачными сервисами. Бюджетные варианты (в порядке убывания цены и производительности):
- RTX 2070 или RTX 2060;
- GTX 1070 или GTX 1070 Ti;
- GTX 980 Ti (6 GB) или GTX 1650 Super.
3.9. Нужен ли PCI 4.0?
Для бюджетной домашней сборки PCI 4.0 не нужен . PCI 4.0 позволит лучше распараллелить и ускорить передачу данных на 1-7% в сравнении с PCIe 3.0 при использовании более четырех ГП. При работе с большими файлами «узким местом» может оказаться SSD-диск, но не передача данных с ГП на ЦП.
Читайте также: