
Не нужно писать весь исходный файл целиком пишите только метод класс который необходим в задаче
Скажем, у меня есть класс, предназначенный для выполнения одной функции. После выполнения функции ее можно уничтожить. Есть ли причина предпочитать один из этих подходов?
Я был намеренно неопределенным в деталях, чтобы попытаться получить рекомендации для различных ситуаций. Но я не имел в виду простые библиотечные функции, такие как Math.random (). Я думаю больше о классах, которые выполняют какую-то конкретную, сложную задачу, но для этого требуется только один (публичный) метод.
Я любил вспомогательные классы, заполненные статическими методами. Они сделали большую консолидацию вспомогательных методов, которые в противном случае могли бы привести к избыточности и адскому обслуживанию. Они очень просты в использовании, без инстанцирования, без утилизации, просто fire'n'forget. Я думаю, это была моя первая невольная попытка создать сервис-ориентированную архитектуру - множество сервисов без сохранения состояния, которые просто сделали свою работу и ничего больше. Однако по мере роста системы появляются драконы.
Полиморфизм
Допустим, у нас есть метод UtilityClass.SomeMethod, который радостно гудит. Внезапно нам нужно немного изменить функциональность. Большая часть функциональности одинакова, но, тем не менее, мы должны изменить несколько частей. Если бы это не был статический метод, мы могли бы создать производный класс и изменить содержимое метода по мере необходимости. Поскольку это статический метод, мы не можем. Конечно, если нам просто нужно добавить функциональность либо до, либо после старого метода, мы можем создать новый класс и вызвать внутри него старый класс - но это просто грубо.
Тестирование
Это в основном идет рука об руку с интерфейсом, упомянутым выше. Поскольку наша способность обмениваться реализациями очень ограничена, у нас также будут проблемы с заменой производственного кода тестовым кодом. Опять же, мы можем обернуть их, но это потребует, чтобы мы изменили большие части нашего кода, чтобы иметь возможность принимать обертки вместо реальных объектов.
Fosters blob
Поскольку статические методы обычно используются в качестве служебных методов, а служебные методы обычно имеют разные цели, мы быстро получим большой класс, заполненный непоследовательной функциональностью - в идеале каждый класс должен иметь одну цель в системе , Я бы предпочел проводить занятия в пять раз, если их цели четко определены.
Параметр ползучести
Начнем с того, что этот маленький симпатичный и невинный статический метод может принимать один параметр. По мере роста функциональности добавляется пара новых параметров. Вскоре добавляются дополнительные параметры, которые являются необязательными, поэтому мы создаем перегрузки метода (или просто добавляем значения по умолчанию на языках, которые их поддерживают). Вскоре у нас есть метод, который принимает 10 параметров. Только первые три действительно необходимы, параметры 4-7 являются необязательными. Но если указан параметр 6, 7-9 также должны быть заполнены . Если бы мы создали класс с единственной целью сделать то, что сделал этот статический метод, мы могли бы решить это, приняв необходимые параметры в конструктор и позволяющий пользователю устанавливать необязательные значения через свойства или методы для одновременного задания нескольких взаимозависимых значений. Кроме того, если метод вырос до такой степени сложности,
Требовательные потребители для создания экземпляра классов без причины
Один из наиболее распространенных аргументов: зачем потребовать, чтобы потребители нашего класса создавали экземпляр для вызова этого единственного метода, но впоследствии не использовали этот экземпляр? Создание экземпляра класса является очень дешевой операцией в большинстве языков, поэтому скорость не является проблемой. Добавление дополнительной строки кода для потребителя - это низкая стоимость, чтобы заложить основу гораздо более удобного решения в будущем. И, наконец, если вы хотите избежать создания экземпляров, просто создайте одноэлементную оболочку вашего класса, которая позволяет легко использовать повторно - хотя это делает требование, чтобы ваш класс не имел состояния. Если это не состояние, вы все равно можете создавать статические методы-обертки, которые обрабатывают все, но при этом дают вам все преимущества в долгосрочной перспективе. В заключение,
Только ситхи имеют дело с абсолютами.
Конечно, есть исключения из моей неприязни к статическим методам. Истинные служебные классы, которые не представляют опасности для вздутия, являются отличными примерами для статических методов - System.Convert в качестве примера. Если ваш проект одноразовый без каких-либо требований для будущего обслуживания, общая архитектура на самом деле не очень важна - статическая или нестатическая, на самом деле не имеет значения - однако скорость разработки имеет значение.
Стандарты, стандарты, стандарты!
Использование методов экземпляра не мешает вам также использовать статические методы, и наоборот. Пока есть основания для дифференциации и она стандартизирована. Нет ничего хуже, чем просматривать бизнес-уровень с различными методами реализации.
Как говорит Марк, полиморфизм, возможность передавать методы в качестве параметров «стратегии» и возможность конфигурировать / задавать параметры - все это причины для использования экземпляра . Например: ListDelimiter или DelimiterParser можно настроить относительно того, какие разделители использовать / принимать, обрезать ли пробельные символы из проанализированных токенов, заключать ли в скобки список, как обрабатывать пустой / нулевой список и т. Д.
@ user3667089 Общие аргументы, необходимые для логического существования класса, которые я передал бы в конструктор. Они обычно используются в большинстве / всех методов. Определенные аргументы метода я передам в этом конкретном методе
На самом деле то, что вы делаете со статическим классом, возвращается к необработанному, не объектно-ориентированному C (хотя и управляемому из памяти) - все функции находятся в глобальном пространстве, нет this , вы должны управлять глобальным состоянием и т.д. если вам нравится процедурное программирование, сделайте это. Но учтите, что тогда вы потеряете многие структурные преимущества ОО.
Я предпочитаю статичный способ. Поскольку класс не представляет объект, не имеет смысла создавать его экземпляр.
Классы, которые существуют только для их методов, должны оставаться статическими.
Как правило задачи про классы не носят вычислительный характер. Обычно нужно написать классы, которые отвечают определенным интерфейсам. Насколько удобны эти интерфейсы и как сильно связаны классы между собой, определит легкость их использования в будущих программах.
Предположим есть данные о разных автомобилях и спецтехнике. Данные представлены в виде таблицы с характеристиками. Вся техника разделена на три вида: спецтехника, легковые и грузовые автомобили. Обратите внимание на то, что некоторые характеристики присущи только определенному виду техники. Например, у легковых автомобилей есть характеристика «кол-во пассажирских мест», а у грузовых автомобилей — габариты кузова: «длина», «ширина» и «высота».
| Тип (car_type) | Марка (brand) | Кол-во пассажирских мест (passenger_seats_count) | Фото (photo_file_name) | Кузов ДxШxВ, м (body_whl) | Грузоподъемность, Тонн (carrying) | Дополнительно (extra) |
| car | Nissan xTtrail | 4 | f1.jpg | 2.5 | ||
| truck | Man | f2.jpg | 8x3x2.5 | 20 | ||
| car | Mazda 6 | 4 | f3.jpg | 2.5 | ||
| spec_machine | Hitachi | f4.jpg | 1.2 | Легкая техника для уборки снега |
Вам необходимо создать свою иерархию классов для данных, которые описаны в таблице. Классы должны называться CarBase (базовый класс для всех типов машин), Car (легковые автомобили), Truck (грузовые автомобили) и SpecMachine (спецтехника). Все объекты имеют обязательные атрибуты:
— car_type, значение типа объекта и может принимать одно из значений: «car», «truck», «spec_machine».
— photo_file_name, имя файла с изображением машины, допустимы названия файлов изображений с расширением из списка: «.jpg», «.jpg», «.jpg», «.jpg»
— brand, марка производителя машины
— carrying, грузоподъемность
В базовом классе CarBase нужно реализовать метод get_photo_file_ext для получения расширения файла изображения. Расширение файла можно получить при помощи os.path.splitext.
Для грузового автомобиля необходимо в конструкторе класса определить атрибуты: body_length, body_width, body_height, отвечающие соответственно за габариты кузова — длину, ширину и высоту. Габариты передаются в параметре body_whl (строка, в которой размеры разделены латинской буквой «x»). Обратите внимание на то, что характеристики кузова должны быть вещественными числами и характеристики кузова могут быть не валидными (например, пустая строка). В таком случае всем атрибутам, отвечающим за габариты кузова, присваивается значение равное нулю.
Также для класса грузового автомобиля необходимо реализовать метод get_body_volume, возвращающий объем кузова.
В классе Car должен быть определен атрибут passenger_seats_count (количество пассажирских мест), а в классе SpecMachine — extra (дополнительное описание машины).
Полная информация о атрибутах классов приведена в таблице ниже, где 1 — означает, что атрибут обязателен для объекта, 0 — атрибут должен отсутствовать.
| Car | Truck | SpecMachine | |
| car_type | 1 | 1 | 1 |
| photo_file_name | 1 | 1 | 1 |
| brand | 1 | 1 | 1 |
| carrying | 1 | 1 | 1 |
| passenger_seats_count | 1 | 0 | 0 |
| body_width | 0 | 1 | 0 |
| body_height | 0 | 1 | 0 |
| body_length | 0 | 1 | 0 |
| extra | 0 | 0 | 1 |
Обратите внимание, что у каждого объекта из иерархии должен быть свой набор атрибутов и методов. Например, у класса легковой автомобиль не должно быть метода get_body_volume в отличие от класса грузового автомобиля. Имена атрибутов и методов должны совпадать с теми, что описаны выше.
Далее вам необходимо реализовать функцию get_car_list, на вход которой подается имя файла в формате csv. Файл содержит данные, аналогичные строкам из таблицы. Вам необходимо прочитать этот файл построчно при помощи модуля стандартной библиотеки csv. Затем проанализировать строки на валидность и создать список объектов с автомобилями и специальной техникой. Функция должна возвращать список объектов.
Вы можете использовать для отладки работы функции get_car_list следующий csv-файл:
Первая строка в исходном файле — это заголовок csv, который содержит имена колонок. Нужно пропустить первую строку из исходного файла. Обратите внимание на то, что в некоторых строках исходного файла , данные могут быть заполнены некорректно, например, отсутствовать обязательные поля или иметь не валидное значение. В таком случае нужно проигнорировать подобные строки и не создавать объекты. Строки с пустым или не валидным значением для body_whl игнорироваться не должны. Вы можете использовать стандартный механизм обработки исключений в процессе чтения, валидации и создания объектов из строк csv-файла. Проверьте работу вашего кода с входным файлом, прежде чем загружать задание для оценки.

Признак того, что объект не должен быть классом — если в нём всего 2 метода, и один из них — инициализация, __init__. Каждый раз видя это, подумайте: «наверное, мне нужна просто одна функция».
Каждый раз когда из написанного класса вы создаёте всего один экземпляр, используете только раз и тут же выбрасываете, следует думать: «ой, надо бы это отрефакторить! Можно сделать проще, намного проще!»
Перевод доклада Джэка Дидриха, одного из ключевых разработчиков языка Питон. Доклад прозвучал 9 марта 2012 на конференции PyCon US.
Все из вас читали Дзэн Питона, наверное много раз. Вот несколько пунктов из него:
- Простое лучше сложного
- Плоское лучше вложенного
- Важна читаемость
- Если программу трудно объяснить, она плохая
- Если программу легко объяснить, возможно, она хорошá
Написал этот текст Тим Питерс. Он умнее и вас, и меня. Сколько вы знаете людей, в честь которых назвали алгоритм сортировки? Вот такой человек написал Дзэн Питона. И все пункты гласят: «Не делай сложно. Делай просто.» Именно об этом и пойдёт речь.
Итак, в первую очередь, не делайте сложно, там, где можно сделать проще. Классы очень сложны или могут быть очень сложны. Но мы всё равно делаем сложно, даже стараясь делать проще. Поэтому в этом докладе мы прочитаем немного кода и узнаем, как заметить, что идём неверным путём, и как выбраться обратно.
На своей работе я говорю коллегам: «Я ненавижу код, и хочу чтобы его было как можно меньше в нашем продукте.» Мы продаём функционал, не код. Покупатели у нас не из-за кода, а из-за широкого функционала. Каждый раз, когда код удаляется, это хорошо. Нас четверо, и в последний год мы перестали считать количество строк в продукте, но продолжаем вводить новый функционал.
Классы
Из этого доклада вам в первую очередь нужно запомнить вот этот код. Это крупнейшее злоупотребление классами, встречающееся в природе.
Это не класс, хотя он похож на класс. Имя — существительное, «приветствие». Он принимает аргументы и сохраняет их в __init__. Да, выглядит как класс. У него есть метод, читающий состояние объекта и делающий что-то ещё, как в классах. Внизу написано, как этим классом пользуются: создаём экземпляр Приветствия и затем используем это Приветствие чтобы сделать что-то ещё.
Но это не класс, или он не должен быть классом. Признак этого — в нём всего 2 метода, и один из них — инициализация, __init__. Каждый раз видя это, подумайте: «наверное, мне нужна просто одна функция».
Каждый раз когда из написанного класса вы создаёте всего один экземпляр, используете только раз и тут же выбрасываете, следует думать: «ой, надо бы это отрефакторить! Можно сделать проще, намного проще!»
Эта функция состоит из 4 строк кода. А вот как можно сделать то же самое всего за 2 строки:
Если вы всё время вызываете функцию с тем же первым аргументом, стандартной библиотеке есть инструмент! functools.partial. Вот посмотрите в код выше: добавляете аргумент, и результат можно вызывать многократно.
Не знаю, у скольких из вас диплом в ИТ, у меня он есть. Я учил такие понятия как
— разделение полномочий
— уменьшение связанности кода
— инкапсуляция
— изоляция реализации
С тех пор как я закончил вуз, 15 лет я этих терминов не употреблял. Слыша эти слова, знайте, вас дурят. Эти термины сами по себе не требуются. Если их используют, люди имеют в виду совершенно разное, что только мешает разговору.
Пример: брюки превращаются.
Многие из вас пользуются в повседневной работе сторонними библиотеками. Каждый раз когда надо пользоваться чужим кодом, первое, что нужно сделать — прочитать его. Ведь неизвестно, что там, какого качества, есть ли у них тесты и так далее. Нужно проверить код прежде чем включать его. Иногда читать код бывает тяжко.
Сторонняя библиотека API, назовём её ShaurMail, включала 1 пакет, 22 модуля, 20 классов и 660 строк кода. Мне пришлось всё это прочитать прежде чем включить в продукт. Но это был их официальный API, поэтому мы пользовались им. Каждый раз когда приходили обновления API, приходилось просматривать диффы, потому что было неизвестно, что они поменяли. Вы посылали патчи — а в обновлении они появились?
660 строк кода, 20 классов — это многовато, если программе нужно только дать список адресов электронной почты, текст письма и узнать, какие письма не доставлены, и кто отписался.
Что такое злоупотребление классами? Часто люди думают, что им понадобится что-то в будущем.… Не понадобится. Напишите всё, когда потребуется. В библиотеке ШаурМаил есть модуль ШаурХэш, в котором 2 строки кода:
Кто-то решил, что позже понадобится надстройка над словарём. Она не понадобилась, но везде в коде остались строки, как первая:
Вторая и третья строки кода — никому не нужно объяснять их. Но там везде повторялась эта мантра «ШаурМаил-ШаурХэш-ШаурХэш». Троекратное повторение слова «Шаур» — ещё один признак излишества. От повторений всем только вред. Вы раздражаете пользователя, заставляя его писать «Шаур» три раза. (Это не настоящее имя компании, а вымышленное.)
Потом они уволили этого парня и наняли того, кто знал, что делает. Вот вторая версия API:
В той было 660 строк, в этой — 15. Всё, что делает этот код — пользуется методами стандартной библиотеки. Он читается целиком, легко, за секунды, и можно сразу понять, что он делает. Кстати, в нём был ещё набор тестов из 20 строк. Вот как надо писать. Когда они обновляли API, я мог прочесть изменения буквально за пару секунд.
Но и здесь можно заметить проблему. В классе два метода, и один из них — __init__. Авторы этого не скрывали. Второй метод — call, «вызвать». Вот как этим API пользоваться:
Строка длинная, поэтому мы делаем алиас и вызываем его многократно:
Заметьте, мы пользуемся этим классом как функцией. Ею он и должен быть. Если видите подобное, знайте, класс тут не нужен. Поэтому я послал им третью версию API:
Он вообще не создаёт файлов в нашем проекте, потому что я вставил его в тот модуль, где он используется. Он делает всё, что делал 15-строковый API, и всё, что делал 660-строковый API.
Вот с чего мы начали и к чему пришли:
- 1 пакет + 20 модулей => 1 модуль
- 20 классов => 1 класс => 0 классов
- 130 методов => 2 метода => 1 функция
- 660 строк кода => 15 строк => 5 строк
Легче пользоваться, легче писать, никому не надо выяснять, что происходит.
Стандартная библиотека
Кто пришёл из языка Java, возможно, считает, что пространства имён нужны для таксономии. Это неверно. Они нужны чтобы предотвратить совпадения имён. Если у вас глубокие иерархии пространств, это никому ничего не даёт. ShaurMail.ShaurHash.ShaurHash — всего лишь лишние слова, которые людям надо помнить и писать.
В стандартной библиотеке Питона пространство имён очень неглубокое, потому что вы либо помните, как называется модуль, либо надо смотреть в документации. Ничего хорошего если надо выяснять цепочку, в каком пакете искать, в каком пакете в нём, в каком пакете дальше, и как называется модуль в нём. Нужно просто знать имя модуля.
К нашему стыду, вот пример из нашего же кода, и те же грехи видно и здесь:
Пакет, в котором модуль из 2 строк, класс исключения и «pass». Чтобы использовать это исключение, надо дважды написать «crawler», дважды слово «exception». Имя ArticleNotFoundException само себя повторяет. Так не надо. Если вы называете исключения, пусть это будет EmptyBeer, BeerError, BeerNotFound, но BeerNotFoundError — это уже много.
Можно просто пользоваться исключениями из стандартной библиотеки. Они понятны всем. Если только вам не нужно выловить какое-то специфическое состояние, LookupError вполне подойдёт. Если вы получили отлуп по почте, всё равно придётся его читать, поэтому неважно, как называется исключение.
Кроме того, исключения в коде обычно идут после raise и except, и всем сразу понятно, что это исключения. Поэтому не нужно добавлять «Exception» в название.
В стандартной библиотеке Питона есть и ржавые детали, но она — очень хороший пример организации кода:
- 200 000 строк кода
- 200 модулей верхнего уровня
- в среднем по 10 файлов в пакете
- 165 исключений
10 файлов в пакете — это много, но только из-за некоторых сторонних проектов, добавленных в библиотеку, где были пакеты из всего 2 файлов. Если вам вздумается создать новое исключение, подумайте лучше, ведь в стандартной библиотеке обошлись 1 исключением на 1200 строк кода.
Я не против классов в принципе. Классы бывают нужны — когда много меняющихся данных и связанных с ними функций. Однако в каждодневной работе такое бывает нечасто. Регулярно приходится работать со стандартной библиотекой, а там уже есть подходящие классы. За вас их уже написали.
Единственное исключение в библиотеке Питона — модуль heapq. Heap queue, «очередь в куче» — это массив, который всегда отсортирован. В модуле heapq десяток методов, и они все работают с той же «кучей». Первый аргумент всегда остаётся тем же, что значит, здесь действительно напрашивается класс.
Каждый раз, когда нужно пользоваться heapq, я беру реализацию этого класса из своего инструментария.
Классы разрастаются как сорняки
Состояние OAuth в Питоне — неважное. Опять же, есть сторонние библиотеки, и прежде чем использовать в своём проекте, их нужно прочесть.
Я пытался использовать сокращатель урлов от Гугла: мне нужно было взять урлы и просто сократить их. У Гугла есть проект, в котором 10 000 строк кода. 115 модулей и 207 классов. Я написал отповедь об этом в Гугле+, но мало кто её видел, а Гвидо (Ван Россум — прим. пер.) прокомментировал: «Я снимаю с себя ответственность за гугловский код API.» 10 000 строк кода — там же обязательно найдётся какая-нибудь дрянь вроде ШаурМэйла. Вот, например, класс Flow («поток»), от которого наследуют другие.
Он пустой. Но у него есть свой модуль, и каждый раз читая наследующий его класс, надо сходить, проверить тот файл и снова убедиться, что тот класс пуст. Кто-то глядел в будущее и решил: «Напишу-ка я 3 строчки кода сейчас, чтобы в будущем эти 3 строчки не менять.» И отнял время у всех, кто читает его библиотеку. Есть ещё класс Хранилище, (Storage) который почти ничего не делает. В нём правильно обрабатываются ошибки, используя стандартные исключения, но им делают алиасы, и опять же нужно ходить читать их код, чтобы выяснить, как это работает.
Чтобы внедрить OAuth2 мне понадобилась неделя. Пару дней заняло чтение десяти тысяч строк кода, после чего я стал искать другие библиотеки. Нашёл python-oauth2. Это вторая версия python-oauth, но она на самом деле не умеет работать с OAuth2, что не сразу удалось выяснить. Впрочем, эта библиотека немного лучше гугловской: только 540 строк и 15 классов.
Я переписал её ещё проще и назвал python-foauth2. 135 строк кода и 3 класса, и то всё равно много, я не достаточно её отрефакторил. Вот один из этих трёх классов:
Жизнь
Последний пример. Все вы видели игру «Жизнь» Конвэя, даже если не знаете её имени. Есть клетчатое поле, каждый ход вы считаете для каждой клетки соседние, и в зависимости от них она будет либо живой, либо мёртвой. И получаются такие красивые устойчивые узоры, как планер: клетки впереди оживают, а сзади умирают, и планер как будто летит по полю.
Игра «жизнь» очень проста: поле и пара правил. Мы задаём эту задачу на собеседовании, потому что если вы не умеете такого — нам не о чем разговаривать. Многие сразу же говорят «Клетка — существительное. Класс надо.» Какие свойства в этом классе? Место, живая или нет, состояние в следующий ход, всё? Ещё есть соседи. Потом начинают описывать поле. Поле — это множество клеток, поэтому это сетка, у неё метод «подсчитать», который обсчитывает клетки внутри.
На этом месте надо сказать «стоп»: у нас есть класс Поле, в котором 2 метода: __init__ и «сделать ход». В нём одно свойство — словарь, значит со словарём и надо работать. Заметьте, что не надо хранить соседей точки, они уже и так есть в словаре. Живая точка или нет — это просто булево значение, поэтому будем хранить координаты только живых клеток. А раз в словаре хранятся только True, нужен не словарь а просто множество (set) координат. Наконец, новое состояние не нужно, можно просто заново создать список живых клеток.
Получается очень простая, сжатая реализация игры. Двух классов тут не надо. Внизу — координаты планера, их вставляют в поле, и планер летит. Всё. Это полная реализация игры «жизнь».
Резюме
1. Если вы видите класс с двумя методами, включая __init__, это не класс.
2. Не создавайте новых исключений, если они не нужны (а они не нужны).
3. Упрощайте жёстче.
От переводчика: в комментариях я вижу, что многие восприняли доклад как полное отрицание ООП. Это ошибка. Пункт 1 из итогов чётко говорит, что такое не класс. Классы нужны, но суть доклада — в том, что не нужно ими злоупотреблять.

Здравствуй, Хабр!
Пишет тебе девятиклассник, призер регионального этапа всероссийской олимпиады по информатике. В последнее время я стал замечать, что у хабражителей повысился интерес к олимпиадам по программированию. Как их активный участник я постараюсь ответить на все вопросы, рассказать о своем пути, привести примеры реальных, запомнившихся мне задач.
Об обучении
Отбор проходит в два этапа. Первый — экзамен по физике и математике. После него некоторые счастливчики попадают на собеседование, где от них требуется решить несколько олимпиадных задач по математике. И только после этого самые умные и удачливые становятся учениками.
Учиться очень тяжело и сложно. Учителя требуют идеального знания чуть ли не всех предметов. На родительском собрании сказали: «В начале обучения абсолютно все ученики скатываются до двоек, даже отличники. Те, кто начинают реально учиться — получают хорошие оценки. Остальные отсеиваются». У меня больше всего было проблем с русским языком и литературой, как бы это ни было странно.
Меня всегда привлекало программирование (что это такое я понял аж в 4 классе). Я был очень рад, когда в седьмом классе начали преподавать Pascal и различные вычислительные алгоритмы. Именно тогда я написал первый «Hello World!», алгоритм Евклида; изучил условные операторы, циклы, массивы.
С восьмого класса учителя приглашали на факультативы по информатике, где мы изучали графы, алгоритмы сортировки массивов и многое другое.
Задачи
Требования
Риски
Wrong answer
Неверный ответ. Результат работы программы не совпадает с ответом жюри
Неверный формат вывода или алгоритмическая ошибка в программе
Time limit exceeded
Превышен указанный в задаче лимит времени. Программа выполняется дольше установленного времени
Неэффективное решение или алгоритмическая ошибка в программе
Presentation Error
Отсутствие выходного файла OUTPUT.TXT
Файл не создан, неверное имя файла или сбой программы до открытия выходного файла
Compilation error
Ошибка компиляции. В результате компиляции не создан исполняемый файл
Синтаксическая ошибка в программе или неверно указано расширение файла. Возможно, что при реализации на языке Java был использован класс, отличный от Main
Memory limit exceeded
Превышен указанный в задаче лимит памяти. Программа использует больше установленного размера памяти.
Неэффективный алгоритм, либо нерациональное использование памяти
Runtime error
Ошибка исполнения. Программа завершила работу с ненулевым кодом возврата. В этом случае результат работы не проверяется
Возможно, в программе произошло обращение к несуществующему элементу массива, деление на ноль и т.д. Возможно, программа на C++ не завершается оператором «return 0» или по иной причине вернула ненулевой код возврата
Олимпиады
Этап среди старшеклассников
Муниципальный этап
Решить задачу, если объект один достаточно просто. Но когда объектов больше — приходится применять достаточно сложный раздел программирования, «Динамическое программирование». Учитель, который вел у нас факультатив признался в том, что он плохо представляет как решить эту задачу (совместными усилиями мы вывели значение, которое нужно минимализировать, просто построив несколько графиков, даже не спрашивайте что это за значение — я его благополучно забыл).
В результате задачу на полный балл решил лишь один участник олимпиады.
Достаточно простая задача: необходимо отсортировать значения по дате появления Альбатроса, вычислить длину каждой дуги между двумя точками, а потом их все сложить. В решении принимается допущение, которое позволяет использовать теорему Пифагора.
Но почему же решение было пересмотрено? Взглянем на диапазон минут и секунд.
0
Вы, наверное, наивно предположили, что в одном градусе 60 минут? Или что в одной минуте 60 секунд? Ха-ха! Тут же явно написано «90».
Тесты были составлены именно с учетом перевода: в одном градусе 60 минут, в одной минуте 60 секунд. Это безобразие было успешно оспорено нашими учителями.
Самое обидное, что даже пример получился неправильный
В результате задачу не решил, по-моему, вообще никто.
Полный текст муниципального этапа можно найти тут.
Дистанционный тур
5
5 Vasya Pupkin Sergey Syroezhkin
10 Harry Potter
5 Garry Potter Vasya Pupkin
5 Sergey Syroezhkin
12341234463456234123466543342 Arnold Schwarzenegger
Выходные данные
John Lennon
Arnold Schwarzenegger
Пояснение к примерам входных и выходных данных: текст во втором примере не содержит символов перевода строки и возврата каретки.
Достаточно простой алгоритм сжатия (не помню как называется). Мне было интересно реализовать. Я решил эту задачу созданием массива из слов, добавлял туда первое слово. Затем считывал каждое следующее слово, проверял, нет ли его в массиве. Если оно было — записывал в выходной поток номер слова, иначе — добавлял в массив, записывал номер.
В принципе, мое решение не получило полный балл.
Полный текст заданий можно найти здесь.
На дистанционном туре я занял 1 место среди девятиклассников.
Региональный этап
На этапе региональном было не так весело, тура было два. Я боялся подвести школу и не пройти на следующий этап, плохо показать нашу школу. Поэтому и задания воспринимались не так весело и приятно. В общем: ничего не запомнил оттуда, но получил заветный диплом. Да и условия мне не удалось найти.
На второй день к нам приехали представители местной компании «Прогноз», поиграли с нами в «Что? Где? Когда?», провели викторину. Победителям раздали призы.
Подготовка
Как же я готовился?
Ответ достаточно прост: у меня хорошие учителя. Мне это было интересно и я получал от всего происходящего удовольствие. Я усердно готовился и добился того, чего хотел.
Что же дальше?
Говоря это, я подразумеваю вопрос о том, насколько олимпиадники приспособлены к работе в реальных условиях.
Хоть я и не работал еще в IT индустрии, но я считаю: олимпиадники никак не приспособлены к реальной работе. На таких олимпиадах требуется уметь быстро изобрести «велосипед», знать хорошо алгоритмы. Я с другом занимаюсь написанием небольших игр и понимаю, что гораздо важнее уметь выбрать правильную технологию для твоих целей, уметь найти готовое решение чтобы ускорить разработку, «Велосипеды не нужны». Поправьте меня, если это не так.
Если кого интересует то, чего я в жизни хочу: на самом деле я не очень-то люблю IT и информатику, мечта моя — выучиться на физика-теоретика и заниматься исследованиями. А так как в РФ с этим проблемы я планирую уехать в Канаду или США.
Приму любые пожелания в ЛС или в комментариях. Надеюсь, данная статья не получилась длинной. Надеюсь она была для Вас интересна. Надеюсь Вас не раздражала моя неграмотность, уж очень я плохо знаю пунктуацию.
Практически всем, кто обучался программированию, известна книга Стива Макконнелла «Совершенный код». Она всегда производит впечатление, прежде всего, внушительной толщиной (около 900 страниц). К сожалению, реальность такова, что иногда впечатления этим и ограничиваются. А зря. В дальнейшей профессиональной деятельности программисты сталкиваются практически со всеми ситуациями, описанными в книге, и приходят опытным путём к тем же самым выводам. В то время как более тесное знакомство могло бы сэкономить время и силы. Мы в GeekBrains придерживаемся комплексного подхода в обучении, поэтому провели для слушателей вебинар по правилам создания хорошего кода.

В комментариях к нашему первому посту на Хабре пользователи активно обсуждали каналы восприятия информации. Мы подумали и решили, что тему «совершенного кода» стоит развить и изложить ещё и письменно — ведь базовые принципы хорошего кода едины для программистов, пишущих на любом языке.
8 правил хорошего кода по версии GeekBrains
Соблюдайте единый Code style. Если программист приходит работать в организацию, особенно крупную, то чаще всего его знакомят с правилами оформления кода в конкретном проекте (соглашение по code style). Это не случайный каприз работодателя, а свидетельство серьёзного подхода.
Вот несколько общих правил, с которыми вы можете столкнуться:
соблюдайте переносы фигурных скобок и отступы — это значительно улучшает восприятие отдельных блоков кода
соблюдайте правило вертикали — части одного запроса или условия должны находиться на одном отступе
соблюдайте разрядку — ставьте пробелы там, где они улучшают читабельность кода; особенно это важно в составных условиях, например, условиях цикла.
В некоторых средах разработки можно изначально задать правила форматирования кода, загрузив настройки отдельным файлом (доступно в Visual Studio). Таким образом, у всех программистов проекта автоматически получается однотипный код, что значительно улучшает восприятие. Известно, что достаточно трудно переучиваться после долгих лет практики и привыкать к новым правилам. Однако в любой компании code style — это закон, которому нужно следовать неукоснительно.
Не используйте «магические числа». Магические числа не случайно относят к анти-паттернам программирования, проще говоря, правилам того, как не надо писать программный код. Чаще всего магическое число как анти-паттерн представляет собой используемую в коде константу, смысл которой неясен без комментария. Такие числа не только усложняют понимание кода и ухудшают его читабельность, но и приносят проблемы во время рефакторинга.
Например, в коде есть строка:
Очевидно, она не вызовет ошибок в работе кода, но и её смысл не всем понятен. Гораздо лучше не полениться и сразу написать таким образом:
Иногда магические числа возникают при использовании общепринятых констант, например, при записи числа π. Допустим, в проекте было внесено:
Что тут плохого? А плохое есть. Например, если в ходе работы понадобится сделать расчёт с высокой точностью, придётся искать все вхождения константы в коде, а это трата трудового ресурса. Поэтому лучше записать так:
Кстати, иногда коллеги-программисты могут не помнить на память значение использованной вами константы — тогда они просто не узнают её в коде. Поэтому лучше избегать написания чисел без объявления в переменных и даже постоянные величины лучше объявлять. Кстати, эти константы практически всегда есть во встроенных библиотеках, поэтому проблема решается сама собой.

Используйте осмысленные имена для переменных, функций, классов. Всем программистам известен термин “обфускация кода” — сознательное запутывание программного года с помощью приложения-обфускатора. Она делается с целью скрыть реализацию и превращает код в невнятный набор символов, переименовывает переменные, меняет имена методов, функций и проч… К сожалению, случается так, что код и без обфускации выглядит запутанно — именно за счёт бессмысленных имён переменных и функций: var_3698, myBestClass, NewMethodFinal и т.д… Это не только мешает разработчикам, которые участвуют в проекте, но и приводит к бесконечному количеству комментариев. Между тем, переименовав функцию, можно избавиться от комментариев — её имя будет само говорить о том, что она делает.

Получится так называемый самодокументируемый код — ситуация, при которой переменные и функции именуются таким образом, что при взгляде на код понятно, как он работает. У идеи самодокументируемого кода есть много сторонников и противников, к аргументам которых стоит прислушаться. Мы рекомендуем в целом соблюдать баланс и разумно использовать и комментарии, и «говорящие» имена переменных, и возможности самодокументируемого кода там, где это оправданно.
Например, возьмём код такого вида:
Из комментария должно быть понятно, что именно делает код. Но совершенно неясно, что обозначают x.a и x.n. Попробуем внести изменения таким образом:
В этом пункте следует отдельно сказать про комментарии, так как слушатели всегда задают очень много вопросов о целесообразности и необходимости их использования. Когда комментариев много, они приводят к низкой читабельности кода. Почти всегда есть возможность внести в код такие изменения, чтобы исчезла потребность в комментарии. В крупных проектах комментарии оправданы в случае использования API, обозначения подключения кода сторонних модулей, обозначения спорных моментов или моментов, требующих дальнейшей переработки.
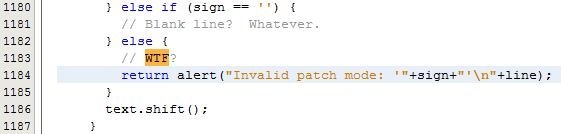
Объединим в одно разъяснение ещё два важных правила. Создавайте методы как новый уровень абстракции с осмысленными именами и делайте методы компактными. Вообще, сегодня модульность кода доступна каждому программисту, а это значит, что нужно стремиться создавать абстракции там, где это возможно. Абстракция — это один из способов сокрытия деталей реализации функциональности. Создавая отдельные небольшие методы, программист получает хороший код, разделённый на блоки, в которых содержится реализация каждой из функций. При таком подходе нередко увеличивается количество строк кода. Есть даже определённые рекомендации, которые указывают длину метода не более 10 строк. Конечно, размер каждого метода остаётся целиком на усмотрении разработчика и зависит от многих факторов. Наш совет: всё просто, делайте метод компактным так, чтобы один метод выполнял одну задачу. Отдельные вынесенные сущности проще улучшить, например, вставить проверку входных данных прямо в начале метода.
Для иллюстрации этих правил возьмём пример из предыдущего пункта и создадим метод, код которого не требует комментариев:
И, наконец, скроем реализацию метода:
В начале методов проверяйте входные данные. На уровне кода нужно обязательно делать проверки входных данных во всех или практически во всех методах. Это связано с пользовательским поведением: будущие пользователи могут вводить любые данные, которые могут вызвать сбои в работе программы. В любом методе, даже в том, который использовался всего один раз, обязательно нужно организовывать проверку данных и создавать обработку ошибок. Это стоит сделать, поскольку метод не только выступает как уровень абстракции, но и необходим для переиспользования. В принципе, возможно разделить методы на те, в которых нужно делать проверку, и те, в которых её делать необязательно, но для полной уверенности и защиты от «хитрого пользователя» лучше проверять все входные данные.
В примере ниже вставляем проверку на то, чтобы на входе не получить null.
Реализуйте при помощи наследования только отношение «является». В остальных случаях – композиция. Композиция является одним из ключевых паттернов, нацеленных на облегчение восприятия кода и, в отличие от наследования, не нарушает принцип инкапсуляции. Допустим, у вас есть класс Руль и класс Колесо. Класс Автомобиль можно реализовать как наследник класса-предка Руль, но ведь Автомобилю нужны и свойства класса Колесо.
Соответственно, программист начинает плодить наследование. А ведь даже с точки зрения обывательской логики класс Автомобиль — это композиция элементов. Допустим, есть такой код, когда новый класс создаётся с использованием наследования (класс ScreenElement наследует поля и методы класса Coordinate и расширяет этот класс):
Композиция — неплохая замена наследованию, этот паттерн более простой для дальнейшего понимания написанного кода. Можно придерживаться такого правила: выбирать наследование, только если нужный класс схож с классом-предком и не будет использовать методы других классов. К тому же, композиция избавляет программиста ещё от одной проблемы — исключает конфликт имён, который случается при наследовании. Есть у композиции и недостаток: размножение количества объектов может оказывать влияние на производительность. Но опять же, это зависит от масштаба проекта и должно оцениваться разработчиком в каждом случае отдельно.
Отделяйте интерфейс от реализации. Любой используемый в программе класс состоит из интерфейса (того, что доступно при использовании класса извне) и реализации (методы). В коде интерфейс должен быть отделён от реализации как для соблюдения одного из принципов ООП, инкапсуляции, так и для улучшения читабельности кода.
Второй случай предпочтительнее, так как он скрывает реализацию с помощью модификатора доступа private. Кроме улучшения читабельности кода, отделение интерфейса от реализации в сочетании с соблюдением правила создания небольшого интерфейса даёт ещё одно важное преимущество: в случае нарушений в работе программы для поиска причины сбоя потребуется проверить лишь несколько функций. Чем больше открытых функций и данных — тем сложнее отследить источник ошибки. Однако интерфейс должен быть полным и должен позволять делать всё, что необходимо, иначе он бесполезен.
В ходе вебинара был задан вопрос: «А можно писать сразу хорошо и не рефакторить?» Вероятно, через несколько лет или даже десятков лет программирования это будет возможно, особенно если есть изначальное видение архитектуры программы. Но никогда нельзя предвидеть конечное состояние проекта через несколько релизов и итераций доработки. Именно поэтому важно всегда помнить о перечисленных правилах, которые гарантируют устойчивость и способность вашей программы к развитию.
Для тех, кто воспринимает информацию через видео и хочет услышать детали вебинара — видеоверсия:
Зачем нужен хороший код, когда всё и так работает?
Несмотря на то, что программа исполняется машиной, программный код пишется людьми и для людей — неслучайно высокоуровневые языки программирования имеют человекопонятные синтаксис и команды. Современные программные проекты разрабатываются группами программистов, порой разделённых не только офисным пространством, но и материками и океанами. Благо, уровень развития технологий позволяет использовать навыки лучших разработчиков, вне зависимости от места нахождения их работодателей. Такой подход к разработке предъявляет серьёзные требования к качеству кода, в частности, к его читабельности и понятности.
Существует множество известных подходов к критериям качества кода, о которых рано или поздно узнаёт практически любой разработчик. Например, есть программисты, которые придерживаются принципа проектирования KISS (Keep It Simple, Stupid! — Делай это проще, тупица!). Этот метод разработки вполне справедлив и заслуживает уважения, к тому же отражает универсальное правило хорошего кода — простоту и ясность. Однако простота должна иметь границы — порядок в программе и читабельность кода не должны быть результатом упрощения. Кроме простоты, существует ещё несколько несложных правил. И они решают ряд задач.
-
Обеспечивать лёгкое покрытие кода тестами и отладку. Unit тестирование — это процесс тестирования модулей, то есть функций и классов, являющихся частью программы. Создавая программу, разработчик должен учитывать возможности тестирования с самого начала работы над написанием кода.
Читайте также: