
Назначение система автоматического перевода в компьютере
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Худинский Марк Викторович
Проблемы трудоустройства выпускников кафедры лингвистического образования: опыт анализа на основе анкетирования
Системы распознавания текста
Вводить информацию в компьютер можно не только с клавиатуры, но и с помощью специального устройства – сканера. В процессе сканирования текст из журнала или книги из бумажного формата переводится в электронный. Первоначально отсканированный текст имеет вид графического изображения, то есть воспринимается компьютером как картинка. Для того чтобы из картинки получить текстовый формат и далее работать с ней как с текстом, используются специальные программы, выполняющие распознавание текста.
Процесс распознавания происходит так. Программа анализирует полученное изображение, выделяя в нем текстовые, табличные и графические области. Затем строки в текстовых блоках разбиваются на отдельные слова, слова – разбиваются на символы. И затем каждый символ сравнивается с имеющимся в базе изображением букв, цифр или специальных символов. Найдя оптимальный вариант, программа выдает его пользователю в виде распознанного текста.
Самым популярным программным продуктом, выполняющим распознавание текста, является Fine Reader от компании ABBYY.
Компания ABBYY на современном рынке программных продуктов является лидером мирового масштаба в разработке программных решений, использующих технологию распознавания документов. Более 1000 компаний в 150 странах сотрудничают с ABBYY, включая таких мировых лидеров, как Fujitsu, Panasonic, Microsoft, Sharp, Samsung, Xerox.
Рис. 1. Логотип ABBYY Fine Reader.
Приложение Fine Reader конвертирует изображения в электронные редактируемые форматы. В качестве графических объектов могут быть фотографии, PDF-файлы, а также полученные в результате сканирования копии бумажных документов. После преобразования результаты можно сохранить в форматах приложений Microsoft Word, Excel, Powerpoint, а также в текстовом формате RTF и в формате разметки гипертекста HTML. Самые новые версии этого программного продукта позволяют сохранять результаты распознавания в формате DJVU.
Достоинством данного программного продукта является распознавание более чем на 190, а также встроенная проверка орфографии.
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Худинский Марк Викторович
в статье рассматривается роль компьютерных программ в переводческой деятельности. Целью исследования является анализ использования современных автоматизированных и машинных программ перевода в профессиональной деятельности переводчика. Дана оценка эффективности применения подобных программ и направление их дальнейшего развития.
Что мы узнали?
Для работы с текстом разработчики программных решений предлагают ряд специальных программных продуктов, предназначенных для машинного перевода и распознавания текста. Приложения для распознавания текста конвертируют фотографии, pdf-документы и друге изображения в электронные редактируемые форматы doc, xlsx, pptx, rtf, html. Программы-переводчики предназначены для перевода текстовых документов с одного языка на другой.
Машинный перевод противопоставляется переводу, сделанному человеком без использования информационных технологий – «ручному» переводу.
Первые алгоритмы машинного перевода использовали перекодирование текста исходного языка ( ИЯ ) на текст языка перевода ( ПЯ ). В специальной литературе преобразование исходного текста в конечный стало называться трансфер [1].
В 1947 г. в США, после появления первых ЭВМ, была высказана идея использовать их для перевода. В 1954 г. прошла первая демонстрация возможностей машинного перевода. Несмотря на несовершенство использовавшейся системы (около 250 слов в словаре, 6 правил грамматики), эксперимент получил широкий резонанс: начались исследования в Англии, Болгарии, ГДР, Италии, Китае, Франции, ФРГ, Японии и в СССР [2].
Формы организации взаимодействия человека и ЭВМ при машинном переводе
1. С постредактированием : исходный текст перерабатывается машиной, а человек-редактор исправляет результат. Автоматический перевод с постредактированием: включает работу с «грубым» переводом предварительно нередактированного текста, сделанным машиной, с целью привести его в соответствие с нормами языка перевода;
2. С предредактированием : человек приспосабливает текст к обработке машиной (устраняет возможные неоднозначные прочтения, упрощает и размечает текст), после чего начинается программная обработка.
Преобразование текста перед его вводом в систему перевода осуществляется таким образом, чтобы отредактированный текст на лексико-семантическом и грамматическом уровнях приближался к языку перевода или к конструкциям языка-источника, правила преобразования которых формализованы и известны используемой системе;
3. С интерредактированием : человек вмешивается в работу системы перевода, разрешая трудные случаи. Подразумевает взаимодействие человека и машины в процессе самого перевода; человек при этом разрешает трудные случаи «онлайн» (например, при переводе лексически неоднозначных единиц определяет, какую именно единицу следует употребить в каждом случае).
Смешанные системы (например, одновременно с пред- и постредактированием) [2, 3].
Автоматизированный перевод
Вместо « машинный » иногда употребляется слово « автоматический », что не влияет на смысл. Однако термин « автоматизированный перевод » имеет совсем другое значение — при нём программа просто помогает человеку переводить тексты.
Автоматизированный перевод предполагает такие формы взаимодействия:
1. Частично автоматизированный перевод : например, использование переводчиком-человеком компьютерных словарей.
2. Системы с разделением труда : компьютер обучен переводить только фразы жёстко заданной структуры (но делает это так, чтобы исправлять за ним не требовалось), а всё, не уложившееся в схему, отдаёт человеку.
В англоязычной терминологии также различаются термины machine translation , MT (полностью автоматический перевод) и machine-aided или machine-assisted translation ( MAT ) (автоматизированный); если же надо обозначить и то, и другое, пишут M(A)T .
Существуют два принципиально разных подхода к построению алгоритмов машинного перевода: основанный на правилах ( rule-based ) и статистический , или основанный на статистике ( statistical (phrase-based) ). Первый подход является традиционным и используется большинством разработчиков систем машинного перевода (ПРОМТ в России, SYSTRAN во Франции, Linguatec в Германии и др.). Ко второму типу относится популярные переводные сервисы от Яндекс и Google [2].
Качество перевода
Современные компьютерные программы перевода достаточно совершенны, но они до сих пор не могут разрешить самую сложную задачу процесса перевода: выбор контекстуально-необходимого варианта, который в каждом тексте обусловлен многими причинами. В результате начальную эйфорию сменили более уравновешенные взгляды на возможности машинного перевода. В настоящее время результат этого вида перевода может быть использован как черновой вариант будущего текста, который будет редактировать переводчик , а также как средство, чтобы в крайней ситуации отсутствия переводчика получить общее представление о теме и содержании текста [1].
Качество перевода зависит от тематики и стиля исходного текста, а также грамматической, синтаксической и лексической родственности языков, между которыми производится перевод.
Машинный перевод художественных текстов практически всегда оказывается неудовлетворительного качества. Тем не менее, для технических документов при наличии специализированных машинных словарей и некоторой настройке системы на особенности того или иного типа текстов возможно получение перевода приемлемого качества, который нуждается лишь в небольшой редакторской корректировке.
Чем более формализован стиль исходного документа, тем большего качества перевода можно ожидать. Самых лучших результатов при использовании машинного перевода можно достичь для текстов, написанных в техническом (различные описания и руководства) и официально-деловом стиле.
Применение машинного перевода без настройки на тематику (или с намеренно неверной настройкой) служит предметом многочисленных шуток [2].
Ошибки обусловлены тем, что компьютер не может думать образами и не имеет возможности оперировать реалиями разных культур и эпох так, как это способен делать человеческих мозг [4].
Лексические анализы переведенных текстов показали, что по большей части электронные переводчики адекватно переводят простые части речи, но допускают ошибки в переводе падежей, принадлежности прилагательных, речевых оборотов, построения предложения.
Недостатком некоторых переводчиков является неточность перевода слов, имеющих несколько значений. Для более адекватного перевода в перспективе можно предложить более глубокий эвристический анализ грамматического построения предложения, с улучшением качества перевода различных частей речи и их грамматических характеристик, а так же исключить конфликт словарей при переводе специализированных текстов.
Грамматический анализ текстов показывает, что электронный переводчик справляется с переводом слов во множественном и единственном числе, но имеется определенная трудность в переводе падежей и постановки глаголов в нужное число. Это объясняется различной интерпретацией падежей в русском и английском языках: в русском – через окончание, в английском – через предлоги [5].
Наряду с установленными правилами построения предложения в каждом языке существуют и свои неписаные законы, которые иногда называются красотами языка. Например, предложение на английском языке «This is my book» дословно переводится «Это есть моя книга», и формально это будет правильным, но по-русски так не говорят. В данном случае можно сказать, что предложение «написано так, будто его составил иностранец». Конечно, приведенный пример является простейшим, и возможность исключения слова «is» очень просто отражается в программе машинного перевода. Но на практике получившийся перевод похож на текст, написанный иностранцем.
Текст также может содержать слова, которые нужно понимать в контексте образа жизни людей в конкретной стране. Например, под словом «демократ» в США подразумеваются политики, выступающие за большее вмешательство государства в экономику, а в России те, кто выступает за большую свободу рынка. Это разные понятия [6].
В настоящее время сфера использования машинного перевода сводится к промышленному переводу. Он может помочь в рутинной переводческой работе, когда быстрота выполнения перевода важнее его качества. Например, он может оказаться кстати для специалиста, не владеющего тем или иным иностранным языком, на котором ему нужно прочитать интересующий его текст. Хотя машинный перевод, как правило, оказывается полным ошибок и неувязок, человек вполне может получить общее представление о содержании текста, что поможет ему решить, стоит ли заказывать более качественный перевод или попытаться отредактировать полученный. Таким образом, машинный перевод позволяет получить то, что И. С. Алексеева условно назвала « сигнальным переводом » [1].
С 1976 г. машинный перевод используется для перевода прогнозов погоды с английского языка на французский в Канаде. Система работает со скоростью 1000 слов в минуту. Каждый день машины переводят до 30000 слов, работая при этом всего полчаса в день. Успех программы объясняется тем, что в текстах метеорологических сводок используется ограниченная по тематике лексика, а также стандартные синтаксические конструкции [1].
Таким образом, результаты машинного перевода почти всегда требуют редактирования. А то, насколько адекватными можно считать результаты перевода на компьютере, определяется не только качеством системы машинного перевода, но и качеством последующего редактирования [6].
Илон Маск не тратит время своих детей на изучение иностранных языков. Он верит, что они-то – уж точно доживут до фантастически достоверного и полезного машинного перевода. Действительно, у нас на глазах научная фантастика становится реальностью: «умные» дома встречают нас с работы горячим ужином, голосовые помощники шутят с нами в чатах, а антропоморфные роботы поддерживают диалог на нескольких языках. Так когда же уже равноценный человеку переводчик появится в каждом смартфоне?

Никогда! Или очень нескоро – вот первая неутешительная новость. Дело в том, что люди, владеющие языками, способны передавать смысл написанного своими словами, не привязываясь к структуре исходника. Машины же переводят пословно или пофразово и научить их оперировать не словами, а образами – это все равно, что изобрести искусственный интеллект. Что значит «оперировать образами?» Это значит – понимать переводимый текст, интерпретировать его. То есть, ни больше, ни меньше – обладать сознанием.
Хорошая новость в том, что за более чем 70 лет существования машинного перевода мы уже прошли довольно большой путь от статистических методов до искусственных нейронных сетей.
Сети умеют читать предложения и слева направо, и справа налево, побуквенно транслитерируют собственные имена и вместо того, чтобы запоминать множество вариантов перевода, оперируют семантикой целого текста, разбивая его на сегменты, после чего анализируют и синтезируют их. Результат получается достойный, причем, в некоторых случаях, система переводит даже фразеологизмы.
Нейронный машинный перевод
Подход к организации нейронного машинного перевода кардинально отличается от предыдущего и, опираясь на треугольник Вокуа, его можно описать следующим образом:
Нейронный машинный перевод имеет следующие особенности:
- «Анализ» называется кодированием, а его результатом является загадочная последовательность векторов.
- «Перенос» называется декодированием и непосредственно генерирует целевую форму без какой-либо фазы генерации. Это не строгое ограничение и, возможно, имеются вариации, но базовая технология работает именно так.
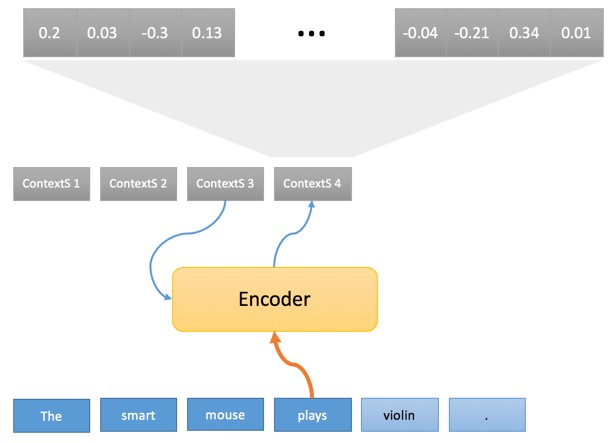
Последовательность исходных контекстов (ContextS 1,… ContextS 5) являет внутренней интерпретацией исходного предложения по треугольнику Вокуа и, как упоминалось выше, представляет из себя последовательность чисел с плавающей запятой (обычно 1000 чисел с плавающей запятой, связанных с каждым исходным словом). Пока мы не будем обсуждать, как кодировщик выполняет это преобразование, но хотелось бы отметить, что особенно любопытным является первоначальное преобразование слов в векторе «float».
На самом деле это технический блок, как и в случае с основанной на правилах системой перевода, где каждое слово сначала сравнивается со словарем, первым шагом кодера является поиск каждого исходного слова внутри таблицы.
Предположим, что вам нужно вообразить разные объекты с вариациями по форме и цвету в двумерном пространстве. При этом объекты, находящиеся ближе всего друг к другу должны быть похожи. Ниже приведен пример:
На оси абсцисс представлены фигуры и там мы стараемся поместить наиболее близкие по этому параметру объекты другой формы (нам нужно будет указать, что делает фигуры похожими, но в случае этого примера это кажется интуитивным). По оси ординат располагается цвет — зеленый между желтым и синим (расположено так, потому что зеленый является результатом смешения желтого и синего цветов, прим. пер.) Если бы у наших фигур были разные размеры, мы бы могли добавить этот третий параметр следующим образом:
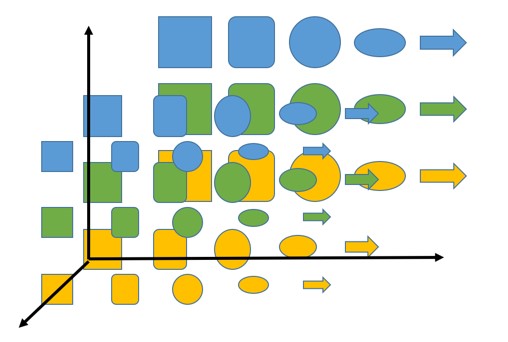
Если мы добавим больше цветов или фигур, мы также сможем увеличить и число измерений, чтобы любая точка могла представлять разные объекты и расстояние между ними, которое отражает степень их сходства.
Основная идея в том, что это работает и в случае размещения слов. Вместо фигур есть слова, пространство намного больше — например, мы используем 800 измерений, но идея заключается в том, что слова могут быть представлены в этих пространствах с теми же свойствами, что и фигуры.
Следовательно, слова, обладающие общими свойствами и признаками будут расположены близко друг к другу. Например, можно представить, что слова определенной части речи — это одно измерение, слова по признаку пола (если таковой имеется) — другое, может быть признак положительности или отрицательности значения и так далее.
Мы точно не знаем, как формируются эти вложения. В другой статье мы будем более подробно анализировать вложения, но сама идея также проста, как и организация фигур в пространстве.
Вернемся к процессу перевода. Второй шаг имеет следующий вид:
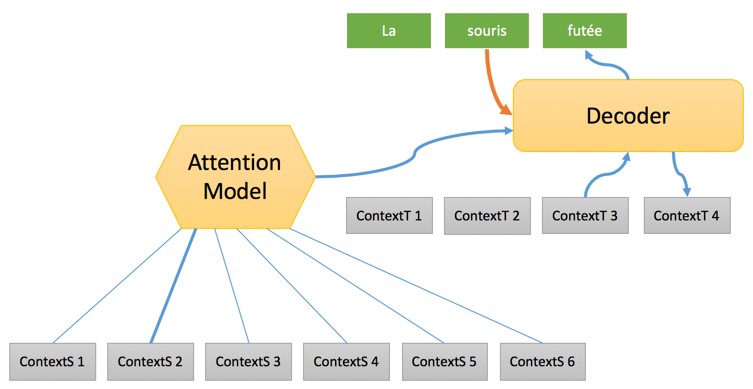
На этом этапе формируется полная последовательность с упором на «исходный контекст», после чего один за другим целевые слова генерируются с использованием:
- «Целевого контекста», сформированного в связке с предыдущим словом и предоставляющего некоторую информацию о состоянии процесса перевода.
- Значимости «контекстного источника», который представляет собой смесь различных «исходных контекстов» опираясь на конкретную модель под названием «Модель внимания» (Attention Model). Что это такое мы разберем в другой статье. Если кратко, то «Модели внимания» выбирают исходное слово для использование в переводе на любом этапе процесса.
- Ранее приведенного слова с использованием вложения слов для преобразования его в вектор, который будет обрабатываться декодером.
Весь процесс, несомненно, весьма загадочен и нам потребуется несколько публикаций, чтобы рассмотреть работу его отдельных частей. Главное, о чем следует помнить — это то, что операции процесса нейронного машинного перевода выстроены в той же последовательности, что и в случае машинного перевода на базе правил, однако характер операций и обработка объектов полностью отличается. И начинаются эти отличия с преобразования слов в векторы через их вложение в таблицы. Понимания этого момента достаточно для того, чтобы осознать, что происходит в следующих примерах.
Машинный перевод на базе фраз
Машинный перевод на базе фраз — это самая простая и популярная версия статистического машинного перевода. Сегодня он по-прежнему является основной «рабочей лошадкой» и используется в крупных онлайн-сервисах по переводу.
Выражаясь технически, машинный перевод на базе фраз не следует процессу, сформулированному Вокуа. Мало того, в процессе этого типа машинного перевода не проводится никакого анализа или генерации, но, что более важно, придаточная часть не является детерминированной. Это означает, что технология может генерировать несколько разных переводов одного и того же предложения из одного и того же источника, а суть подхода заключается в выборе наилучшего варианта.
Эта модель перевода основана на трех базовых методах:
- Использование фразы-таблицы, которая дает варианты перевода и вероятность их употребления в этой последовательности на исходном языке.
- Таблица изменения порядка, которая указывает, как могут быть переставлены слова при переносе с исходного на целевой язык.
- Языковая модель, которая показывает вероятность для каждой возможной последовательности слов на целевом языке.
Далее из этой таблицы генерируются тысячи возможных вариантов перевода предложения, например:
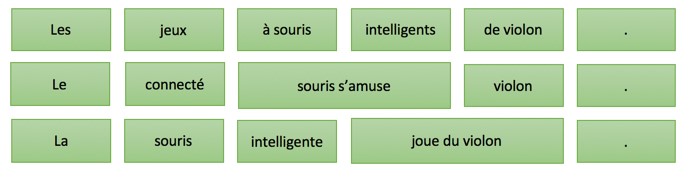
Однако благодаря интеллектуальным вычислениям вероятности и использованию более совершенных алгоритмов поиска, будет рассмотрен только наиболее вероятные варианты перевода, а лучший сохранится в качестве итогового.
В этом подходе целевая языковая модель крайне важна и мы можем получить представление о качестве результата, просто поискав в Интернете:

Поисковые алгоритмы интуитивно предпочитают использовать последовательности слов, которые являются наиболее вероятными переводами исходных с учетом таблицы изменения порядка. Это позволяет с высокой точностью генерировать правильную последовательность слов на целевом языке.
В этом подходе нет явного или неявного лингвистического или семантического анализа. Нам было предложено множество вариантов. Некоторые из них лучше, другие — хуже, но, на сколько нам известно, основные онлайн-сервисы перевода используют именно эту технологию.
Для чего и для кого годится машинный перевод?
Для не знающих язык людей, которым нужно в самых общих чертах понять содержание какого-то текста. Для переводчиков, которым необходим «шаблон» для редактирования. Ну, и конечно, для бизнеса, которому нужно ускорять процессы межкультурных коммуникаций.

Другое дело, что машинный перевод все равно придется редактировать человеку, а для этого нужно уметь замечать и исправлять ошибки, сделанные машиной. Это отдельный трудоемкий процесс, который требует специфического навыка. Этот навык – базовый для филолога, а вот обычного студента обучить ему почти так же трудозатратно, как… английскому языку в степени, необходимой для понимания большинства текстов.
GENERAL CHARACTERISTIC OF AUTOMATIC AND MACHINE TRANSLATION PROGRAMS
the article examines the role of computer programs in translation . The aim of the research is to analyze the use of modern automatic and machine translation programs in the professional activity of a translator. An assessment of the effectiveness of the application of such programs and the direction of their further development are given
Системы перевода
Высокий уровень развития технологий, обеспечивающих реализацию информационных процессов хранения и поиска информации, способствовал популяризации программ-переводчиков.
Программа переводчик представляет собой программный продукт, который позволяет осуществлять перевод с одного языка на другой отдельных слов, словосочетаний и предложений. Действие таких систем перевода строится на применении правил построения словосочетаний и предложений естественного языка. Переводчик анализирует текст на исходном языке, а затем составляет такой же текст на новом языке.
Как правило, такие программные продукты можно устанавливать на свой персональный компьютер как отдельные приложения (например, ABBYY Lingvo), но чаще их используют в режиме on-line в сети интернет. Свои услуги по переводу предлагают Яндекс-переводчик, Google-переводчик. Объем переводимого текста в Google может достигать до 5000 знаков, программа позволяет осуществлять перевод с 103 языков.
С 2017 года компания Google использует технологию перевода, основанную на применении нейросетей. Такой механизм позволяет предлагать более точные по смыслу, с учетом различных тонкостей языков, варианты слов.
Рис. 3. Логотип переводчика Google Translate.
Примеры перевода для сравнения
Давайте разберем некоторые примеры перевода и обсудим, как и почему некоторые из предложенных вариантов не работают в случае разных технологий. Мы выбрали несколько полисемических (т.е. многозначных, прим. пер.) глаголов английского языка и изучим их перевод на французский.

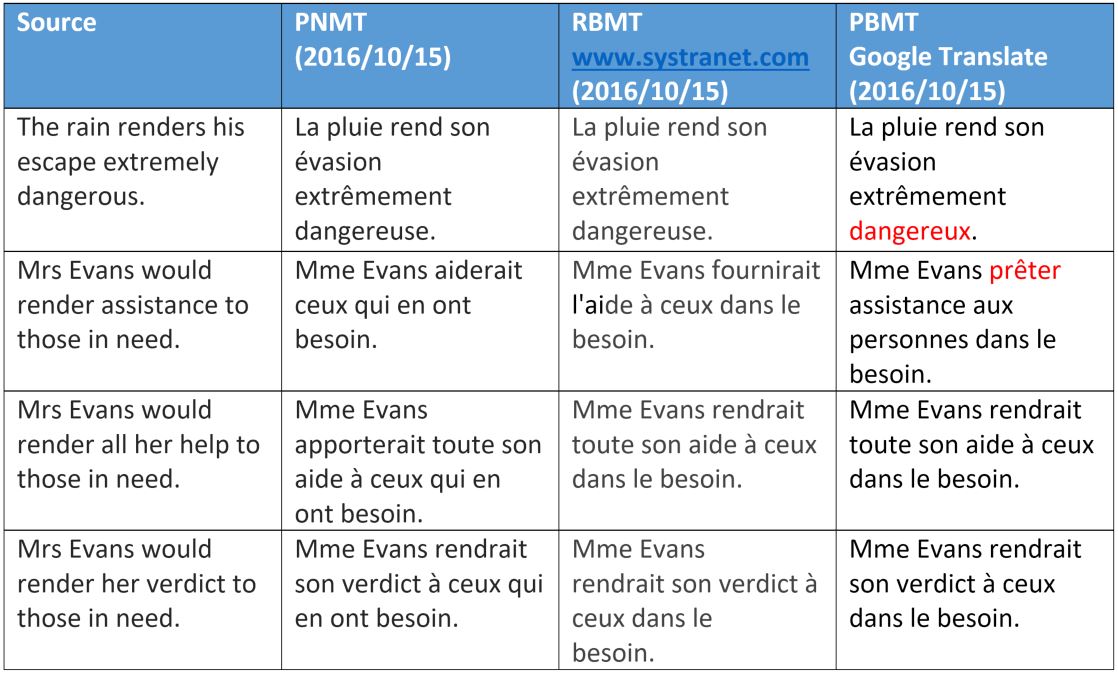
Мы видим, что машинный перевод на базе фраз, интерпретирует «render» как смысл — за исключением очень идиоматического варианта «оказание помощи». Это можно легко объяснить. Выбор значения зависит либо от проверки синтаксического значения структуре предложения, либо от семантической категории объекта.
Для нейронного машинного перевода видно, что слова «help» и «assistance» обрабатываются правильно, что показывает некоторое превосходство, а также очевидную способность этого метода получать синтаксические данные на большом расстоянии между словами, что мы более детально рассмотрим в другой публикации.

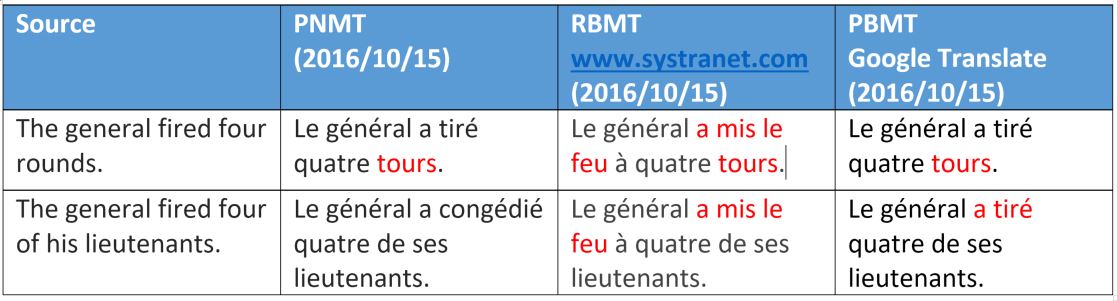
На этом примере опять видно, что нейронный машинный перевод имеет семантические различия с двумя другими способами (в основном они касаются одушевленности, обозначает слово человека или нет).
Однако отметим, что было неправильно переведено слово «rounds», которое в данном контексте имеет значение слова «bullet». Мы объясним этот типа интерпретации в другой статье, посвященной тренировке нейронных сетей. Что касается перевода на базе правил, то он распознал только третий смысл слова «rounds», который применяется в отношении ракет, а не пуль.

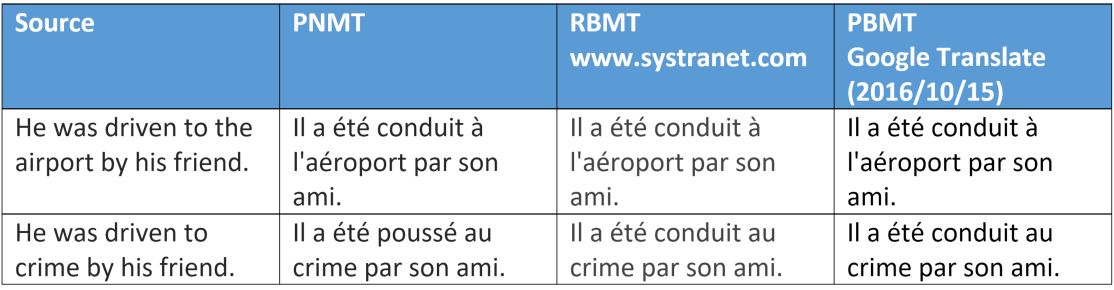
Выше еще один интересный пример того, как смысловые вариации глагола в ходе нейронного перевода взаимодействуют с объектом в случае однозначного употребления предлагаемого к переводу слова (crime или destination).
Другие варианты со словом «crime» показали тот же результат…
Переводчики работающие на базе слов и фраз так же не ошиблись, так как использовали те же глаголы, приемлемые в обоих контекстах.
Нейронные сети не справляются
Язык – это очень гибкая система с неограниченным набором размытых правил. И хотя нейронные сети уже схватывают семантические и синтаксические связи в предложениях и даже распознают акцент говорящего, они не умеют (и, скорее всего, не научатся) учитывать культурологические, когнитивные, литературные и прочие аспекты перевода. Иными словами, контекст может кардинальным образом нарушить коммуникацию, потому что:
Компьютер не может понять культуру:

Компьютер плохо переводит идиомы:

Компьютер не способен передать эмоции песен и стихов:
Эмоционально-окрашенные тексты, фразеологические обороты, культурный подтекст – это тоже не к машине:

Договоры, гарантийные письма, маркетинговые материалы, медицинские документы, ошибка в которых может стоить кому-то жизни – это не к машине:

Рекламные лозунги, любые художественные тексты – это слишком тяжело, многозначно и не формализовано для машинного перевода. Да и сам термин «перевод» по отношению к литературному тексту, вероятно, не вполне корректен. Здесь задача переводчика – не декодировать текст, а найти эквивалентную по значению лексику в языке перевода. Переводчик работает со смыслами, а не со словами и в работе полагается на литературное чутье:
Ведь земля совершает оборот за двадцать четыре часа…
– Оборот? – повторила Герцогиня задумчиво.
И, повернувшись к кухарке, прибавила:
– Возьми-ка ее в оборот! Для начала оттяпай ей голову!

Доверяя машине, мы отрезаем от текстов всю потрясающую лингвистическую игру, на которой строится юмор известных шоу, фильмов и сериалов, из которой вырастает сентиментальное послевкусие любимых песен:

Текст научной работы на тему «ОБЩАЯ ХАРАКТЕРИСТИКА ПРОГРАММ АВТОМАТИЗИРОВАННОГО И МАШИННОГО ПЕРЕВОДА»
8. Демичев А.В. Deathнейленд // Фигуры Танатоса: Искусство умирания. -СПб.: Изд-во СПбГУ, 1998. - С. 51-57.
Худинский Марк Викторович Hudinskiy Mark Viktorovich
Военный университет Министерства обороны Российской Федерации Military University of the Ministry of Defense of the Russian Federation
ОБЩАЯ ХАРАКТЕРИСТИКА ПРОГРАММ АВТОМАТИЗИРОВАННОГО
И МАШИННОГО ПЕРЕВОДА
GENERAL CHARACTERISTIC OF AUTOMATIC AND MACHINE
Аннотация: в статье рассматривается роль компьютерных программ в переводческой деятельности. Целью исследования является анализ использования современных автоматизированных и машинных программ перевода в профессиональной деятельности
VМеждународная научно-практическая конференция переводчика. Дана оценка эффективности применения подобных программ и направление их дальнейшего развития.
Abstract, the article examines the role of computer programs in translation. The aim of the research is to analyze the use of modern automatic and machine translation programs in the professional activity of a translator. An assessment of the effectiveness of the application of such programs and the direction of their further development are given.
Ключевые слова: автоматизированный перевод; машинный перевод; качество перевода; помощь переводчику.
Key words: automatic translation; machine translate; translation quality; assistance to the translator.
В своей профессиональной деятельности переводчик использует различные компьютерные программы. По своему применению и принципу работы они различаются на программы машинного и автоматизированного перевода.
Машинный перевод - это процесс перевода текста с одного естественного языка на другой, полностью реализуемый компьютером [1, с. 8]. На данный момент программы машинного перевода подразделяются на три категории[2, с. 139]:
Полностью автоматический перевод;
Автоматизированный машинный перевод при участии человека;
Перевод, осуществляемый человеком с использованием компьютера.
Полностью автоматический перевод осуществим только в будущем, так как до сих пор невозможно создать программные алгоритмы автоматического понимания, перевода и синтеза текстов.
Программы второй категории имеют название «Machine Translation» (машинный перевод - MT). Примером является программа «Meteo», посредством которой происходит перевод метеопрогнозов с французского языка на английский и обратно. Также системы машинного перевода фирмы PROMT для перевода и просмотра Web-страниц относятся к переводческим программам данного типа.
Программы третьей категории носят название «translation memory» (память перевода - TM). Их зачастую используют профессиональные переводчики, которые пользуются выгодой приносимой автоматизированным переводом. К подобным программам относятся специализированные словари, которые соответствуют необходимой тематике переводимого текста. После чего пользователь вносит свои корректировки, выбирает необходимый ему вариант и система запоминает полученный перевод, который может быть использован в будущем. Также их использование позволяет исключить повторный перевод идентичных фрагментов текста, так как программа запоминает выполненный перевод и соотносит его в дальнейшем. Поэтому подобные системы особенно популярны в больших компаниях и коллективных проектах. Наиболее известными являются: Transit, Trados, Translation Manager, Eurolang Optimizer и
Программы данного типа имеют следующие общие функции:
- сопоставления, то есть использование уже переведённых материалов по одной тематике. Происходит сегментное сопоставление файлов оригинала и перевода внутри базы данных;
- работа фильтром импорта - экспорта. За счёт этого осуществляется совместимость с текстовыми процессорами и издательскими системами, то есть работа с различным ПО;
- поиск неполных или полных совпадений;
- поддержка тематических словарей;
- средства поиска фрагментов текста;
Системы машинного перевода представлены множеством программ и интернет-сервисов, которые осуществляют перевод текста с одного языка на другой без участия человека; он только редактирует полученный результат. Наиболее известными программами являются: PROMT, Google translate, Яндекс.Переводчик и др.
Отдельно стоит отметить программу перевода «Google Translate», которая работает на принципе использования статистического уникального машинного
VМеждународная научно-практическая конференция перевода текста (Statistical Machine Translation - SMT). Особенностью данной программы является метод перевода, который основан на поиске языковых соответствий, а не на анализе правил грамматики [4, с. 2]. В данном случае происходит поиск языковых соответствий между переводимым текстом и большим массивом информации сервиса, который включает в себя слова, вносимые пользователями ранее. Для примера берутся все достоверно оцененные источники, как, например, документы международных организаций. Это особенно удобно, так как документы, к примеру, Организации объединённых наций ведутся на разных языках.
В 2016 году были созданы первые системы машинного перевода, спрограммированные на основе механизма двунаправленных рекуррентных нейронных сетей[5]. Они также обучаются на основе двуязычных корпусов, но в отличии от «SMT», построены на матричных вычислениях, оперируют целыми предложениями и создают более сложные вероятностные модели. В результате, слова в предложении согласованы между собой и стоят в правильном порядке. Данный вариант перевода является наиболее перспективным в настоящее время.
Системы автоматизированного перевода - это специализированные программы и интернет-сервисы, посредством которых человек осуществляет перевод текстов с одного языка на другой. Их часто применяют для работы над художественными, юридическими и техническими тестами. Переводчик использует их в качестве инструмента и помощи, в то время, как он сам занимается переводом. К таким программам относятся:
встроенные или отдельные редакторы, которые автоматически проверяют грамматику текстов и правописание слов (Hemungway App, Microsoft Word, Grammarly и др.);
таблицы, текстовые редакторы и ПО, которые обеспечивают управление терминологией. С помощью них переводчик загружает необходимую ему информацию, а также создаёт свои собственные термины, которые запомнит программа (MultiTerm, LogiTerm, TermStar, Termex и др.);
«Инновационные аспекты развития науки и техники» ПО для осуществления менеджмента переводческих проектов, чтобы назначать и контролировать лингвистические задачи и их выполнение при работе с многочисленным персоналом (Freedcamp, Asana, MeisterTask);
системы конкорданса, используемые для поиска примеров слов и выражений в требуемом контексте (Ontos, Russian Context Optimiaer, Арион);
САТ-инструменты (Computer Aided Translation tools), которые применяют систему «памяти переводов» и включающие в себя образцы ранее переведённых предложений и текстов (Trados, DéjáVu, MemoQ, MemSource, Wordfast и др.);
корпусы текстов с использованием одного или нескольких языков и программы переводческой памяти. Они позволяют составить минимальное описание употребления слов и выражений в основных случаях употребления, а также с поправками на использование конкретной предметной темы (Корпус английского, русского, бурятского языков и др.).
двуязычные электронные словари (ABBYY Lingvo, Multitran, Reverso и
Автоматизированные программы при осуществлении профессионального перевода являются приоритетными. Их преимущество хорошо выражено при сравнении бумажных и электронных словарей. Во-первых, электронные словари постоянно обновляются, пополняясь лексикой даже из узкоспециализированных отраслей. Что касается бумажных словарей, с такой же скоростью выпускать их и постоянно обновлять не представляется возможным. Во-вторых, сокращается время на поиск необходимой информации, ведь большие бумажные словари не всегда доступны. В-третьих, в отличие от бумажных словарей, которые делятся на различные тематические направления, электронные словари включают в себя весь возможный лексический ресурс используемого языка. Таким образом, в ходе перевода иностранного текста, переводчик использует сразу несколько автоматизированных программ, которые облегчают его работу. Применяются редакторы для проверки грамматики, системы конкорданса для верного перевода слова в конкретном контексте, различные CAT-инструменты для нахождения
VМеждународная научно-практическая конференция наиболее подходящего варианта и электронные словари для нахождения значения незнакомых слов.
Таким образом, программы автоматизированного и машинного перевода имеют общие используемые в ходе работы алгоритмы. На сегодняшний день значимость применения данных программ в переводческой деятельности продолжает расти. Однако, в профессиональной деятельности переводчика необходимы оба типа программ. Они занимают важное место в современной переводческой деятельности, но в конечном счёте окончательное решение при выборе наиболее оптимального варианта перевода остаётся за переводчиком, так как ни одна компьютерная программа не может избавить его от необходимости принимать самостоятельные решения.
2. Дроздова К. А. Машинный перевод: история, классификация, методы // Филологические науки в России и за рубежом: материалы III Междунар. науч. конф. СПб, 2015. С. 139-141.
3. Каримова Р.Ф. Системы автоматизированного перевода и машинный перевод // Статья. Казань, 2020. С. 2-4
©М.В. Худинский, 2021
Зорькина Алина Юрьевна, Николенко Александра Алексеевна Zorkinа Alina Yur'evna, Nikolenko Alexandra Alekseevna
Ломакина Ирина Геннадьевна Lomakina Irina Gennadievna

Основные приемы работы с текстом заключаются не только в создании, редактировании и оформлении текстового материала, которые реализуют текстовые редакторы. Существует ряд специальных приложений, автоматизирующих действия по обработке текстов. Кратко о системах перевода и распознавания текста можно прочитать в данной статье.
Что такое системы перевода и распознавания текста
Для упрощения работы с текстом разработчики программного обеспечения создали специальные приложения, позволяющие автоматизировать ввод больших объемов текстовых данных. Также текст большими объемами можно не только вводить, но и переводить. Для автоматизации процессов работы с текстом используются системы перевода и распознавания текста.
Какие выводы?
Машинный перевод может послужить хорошим бойцом в формальной деловой переписке, но предаст вас в живой коммуникации. Полагаясь на машинный перевод, мы вообще лишаем себя элементарной радости общения, ведь никто не хочет разговаривать со смартфоном – во всяком случае, пока он не торчит на месте вашей собственной головы. Но такого нам даже научная фантастика не предсказывала.
Делая ставку на машинный перевод, мы фактически ставим на скорое появление сознания у компьютеров, подобного человеческому. То есть, самосознания, позволившего бы машине понять, что именно она «читает» и перевести это по-человечески. Все ли процессы человеческого мозга можно свести к алгоритмам? Маловероятно, что этот вопрос будет решен в ближайшее время. А вот изучение английского языка с применением всех достижений научного прогресса – вещь быстрая и результативная.

Для тех, кто не готов променять теплое живое общение с прекрасными людьми по всему миру на бездушный машинный перевод, мы кое-что приготовили. По ссылке – запись на бесплатное занятие по английскому языку в школе Skyeng. Введите при регистрации промокод HABR2: в подарок добавятся 2 урока при первой оплате.

В этой публикации нашего цикла step-by-step статей мы объясним, как работает нейронный машинный перевод и сравним его с другими методами: технологией перевода на базе правил и технологией фреймового перевода (PBMT, наиболее популярным подмножеством которого является статистический машинный перевод — SMT).
Результаты исследования, полученные Neural Machine Translation, удивительны в части того, что касается расшифровки нейросети. Создается впечатление, что сеть на самом деле «понимает» предложение, когда переводит его. В этой статье мы разберем вопрос семантического подхода, который используют нейронные сети для перевода.
Давайте начнем с того, что рассмотрим методы работы всех трех технологий на различных этапах процесса перевода, а также методы, которые используются в каждом из случаев. Далее мы познакомимся с некоторыми примерами и сравним, что каждая из технологий делает для того, чтобы выдать максимально правильный перевод.
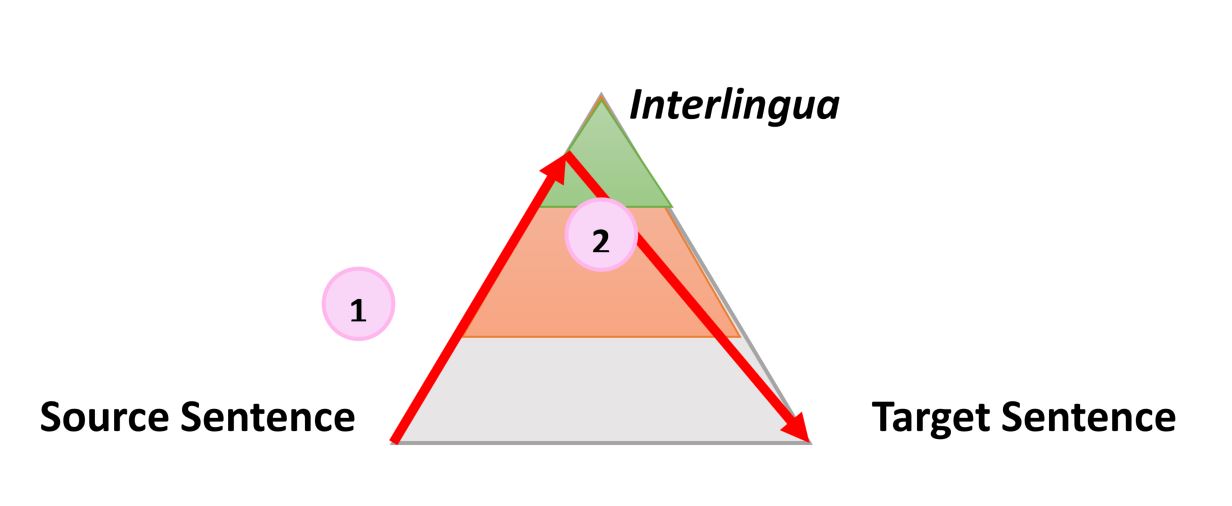
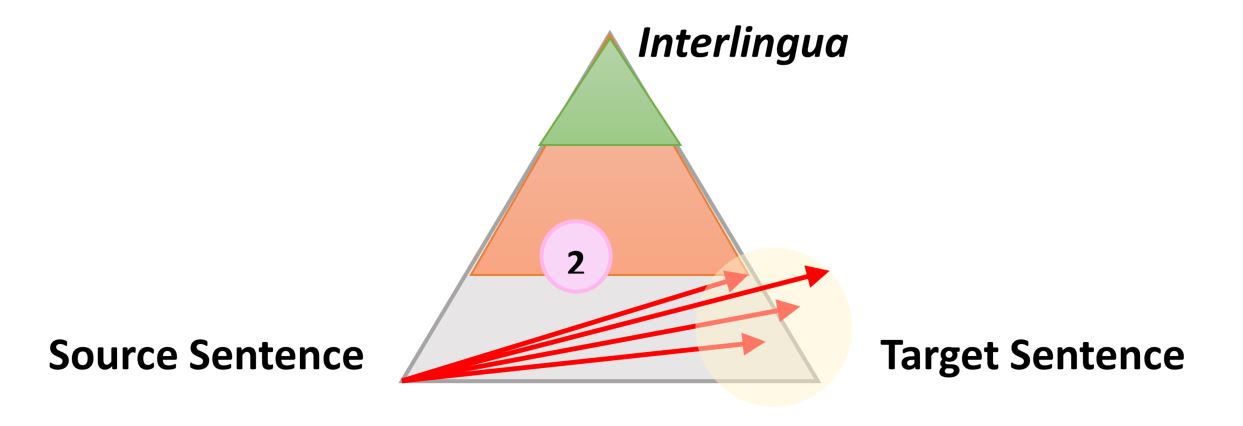
Очень простой, но все же полезной информацией о процессе любого типа автоматического перевода является следующий треугольник, который был сформулирован французским исследователем Бернардом Вокуа (Bernard Vauquois) в 1968 году:
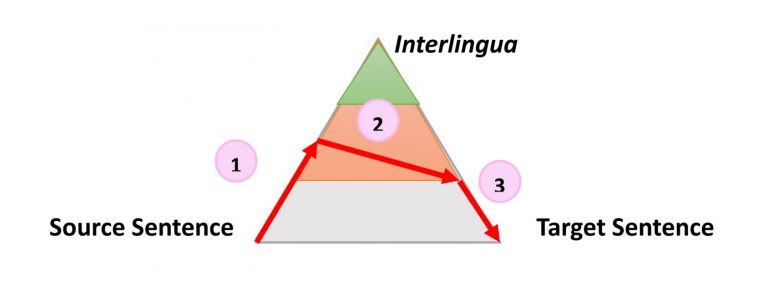
В этом треугольнике отображен процесс преобразования исходного предложения в целевое тремя разными путями.
Левая часть треугольника характеризует исходный язык, когда как правая — целевой. Разница в уровнях внутри треугольника представляет глубину процесса анализа исходного предложения, например синтаксического или семантического. Теперь мы знаем, что не можем отдельно проводить синтаксический или семантический анализ, но теория заключается в том, что мы можем углубиться на каждом из направлений. Первая красная стрелка обозначает анализ предложения на языке оригинала. Из данного нам предложения, которое является просто последовательностью слов, мы сможем получить представление о внутренней структуре и степени возможной глубины анализа.
Например, на одном уровне мы можем определить части речи каждого слова (существительное, глагол и т.д.), а на другом — взаимодействие между ними. Например, какое именно слово или фраза является подлежащим.
Когда анализ завершен, предложение «переносится» вторым процессом с равной или меньшей глубиной анализа на целевой язык. Затем третий процесс, называемый «генерацией», формирует фактическое целевое предложение из этой интерпретации, то есть создает последовательность слов на целевом языке. Идея использования треугольника заключается в том, что чем выше (глубже) вы анализируете исходное предложение, тем проще проходит фаза переноса. В конечном итоге, если бы мы могли преобразовать исходный язык в какой-то универсальный «интерлингвизм» во время этого анализа, нам вообще не нужно было бы выполнять процедуру переноса. Понадобился бы только анализатор и генератор для каждого переводимого языка на любой другой язык (прямой перевод прим. пер.)
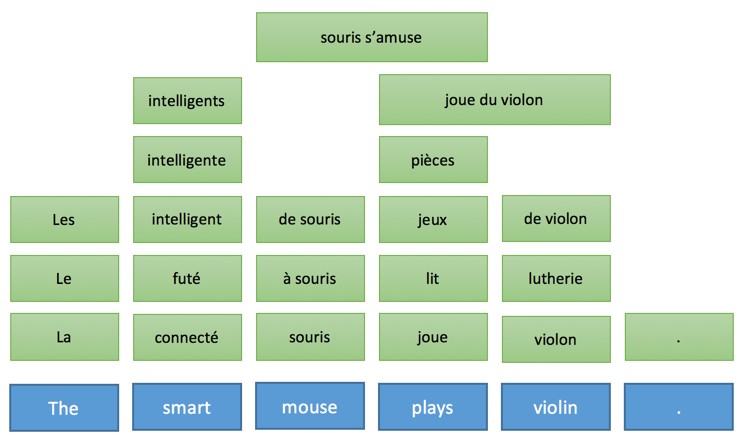
Эта общая идея и объясняет промежуточные этапы, когда машина переводит предложения пошагово. Что еще более важно, эта модель описывает характер действий во время перевода. Давайте проиллюстрируем, как эта идея работает для трех разных технологий, используя в качестве примера предложение «The smart mouse plays violin» (Выбранное авторами публикации предложение содержит небольшой подвох, так как слово «Smart» в английском языке, кроме самого распространенного смысла «умный», имеет по словарю в качестве прилагательного еще 17 значений, например «проворный» или «ловкий» прим. пер.)
Машинный перевод на базе правил
Машинный перевод на базе правил является самым старым подходом и охватывает самые разные технологии. Однако, в основе всех их обычно лежат следующие постулаты:
- Процесс строго следует треугольнику Вокуа, анализ очень часто завышен, а процесс генерации сводится к минимальному;
- Все три этапа перевода используют базу данных правил и лексических элементов, на которые распространяются эти правила;
- Правила и лексические элементы заданы однозначно, но могут быть изменены лингвистом.
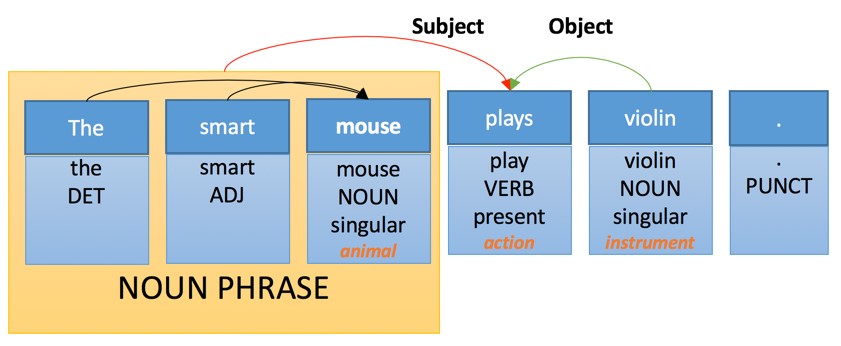
Тут мы видим несколько простых уровней анализа:
- Таргеритование частей речи. Каждому слову присваивается своя «часть речи», которая является грамматической категорией.
- Морфологический анализ: слово «plays» распознается как искажение от третьего лица и представляет форму глагола «Play».
- Семантический анализ: некоторым словам присваивается семантическая категория. Например, «Violin» — инструмент.
- Составной анализ: некоторые слова сгруппированы. «Smart mouse» — это существительное.
- Анализ зависимостей: слова и фразы связаны с «ссылками», при помощи которых происходит идентификация объекта и субъекта действия основного глагола «Plays».

Применение этих правил приведет к следующей интерпретации на целевом языке перевода:
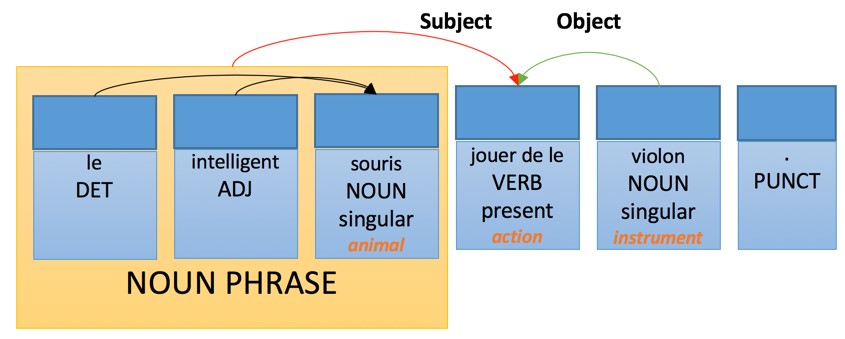
Тогда как правила генерации на французском будут иметь следующий вид:
- Прилагательное, выраженное словосочетанием, следует за существительным — с несколькими перечисленными исключениями.
- Определяющее слово согласованно по числу и роду с существительным, которое оно модифицирует.
- Прилагательное согласовано по числу и полу с существительным, которое оно модифицирует.
- Глагол согласован с подлежащим.
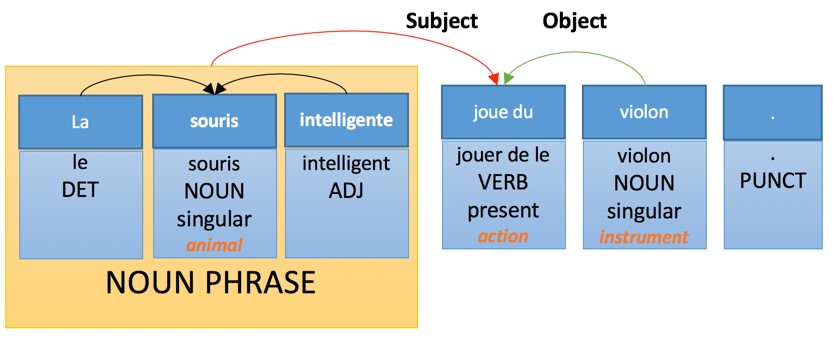
Читайте также: