
Mtbf hdd что это
Facebook Если у вас не работает этот способ авторизации, сконвертируйте свой аккаунт по ссылке ВКонтакте Google RAMBLER&Co ID
Авторизуясь в LiveJournal с помощью стороннего сервиса вы принимаете условия Пользовательского соглашения LiveJournal
Time control (SCT ERC, TLER)
Миф №3.
"Наступил цифровой коммунизм. Я могу позволить себе сервер в одном из ваших корпусов Supermicro на 24 диска, соберу один большой RAID-5 или RAID-6 из недорогих домашних 3ТБ SATA дисков, 60-ти с лишним терабайт хватит надолго."
Знаете ли вы о том, что при определенном сочетании числа, объема и качества дисков в RAID-5 вы практически гарантированно потеряете свои данные во время ребилда? Детальному рассмотрению декларируемых показателей надежности жестких дисков будет посвящена оставшаяся часть этой статьи.
Миф №4. От низкой надежности десктопных дисков спасет RAID.
"Если десктопные диски столь ненадежны, то стоит просто закупить их побольше, поставить в RAID, пусть выходят из строя по 2-3-10% в год, будем менять"
Тут появляется еще одна проблема, связанная с качеством - UER (unrecoverable error rate). Означает вероятность появления невосстановимой ошибки чтения, по различным причинам: дефект поверхности, сбой в работе головки, контроллера и т.д. Для современных десктопных дисков значение UER составляет 1 x 10 -14 . Это означает, что при передаче 1 x 10 14 бит вы с очень большой вероятностью прочитаете с диска вовсе не то, что туда записали. Дальше начинается занимательная математика, опубликованная в одном из докладов SNIA:
Диск объемом 500ГБ содержит 1/25 x 10 14 бит. Допустим, у нас есть RAID-5 из шести таких десктопных дисков с UER равным 1 x 10 -14 . До определенного момента все работает хорошо, на дисках появляются и ремапятся сбойные сектора, к потере данных это не приводит, т.к. у нас RAID. И тут один из дисков выходит из строя. Меняем диск, начинается ребилд: c пяти дисков нужно считать страйпы и контрольные суммы, рассчитать и записать их на шестой диск.
Для пяти дисков вероятность получения невосстановимой ошибки чтения будет равна 1-(1-1/25) 5 =18.5%. 500ГБ по нынешним меркам - не очень много, в ходу диски по 1, 2, 3 и даже 4 терабайт. Для массива 8x1ГБ получаем 44.2%, а для "супер-большой-СХД-на-всю-жизнь" из 24-х десктопных дисков по 3ТБ получается шансов и вовсе не остается - 99.8%. Данную вероятность можно немного уменьшить, периодически запуская фоновую проверку целостности данных на массиве. Можно уменьшить ее значительно, на порядок, используя правильные диски nearline класса с UER = 1 x 10 -15 , но для больших массивов цифра получается все равно неприемлемой, ведь не учитывается вероятность полного выхода из строя второго диска во время ребилда, который при больших объемах и высокой нагрузке на массив может растянуться на несколько недель. Конечно, в реальности все будет не столь ужасно, так как значение UER производители HDD указывают с запасом, но основной смысл заключается в том, что при современных объемах мы не можем позволить себе оставлять массив в состоянии degrade, если данные не защищены дополнительными проверками целостности и/или механизмами распределенного хранения.
Вывод: при больших объемах современных дисков использовать RAID-5 нельзя. Даже для дисков enterprise класса (UER меньше еще на порядок - 1 x 10 -16 ) вероятность получить ошибку чтения при ребилде массива из восьми 450ГБ дисков составляет около 0,3%. Их емкость тоже растет. Если относительно недавно диски на 10000 и 15000 об/мин были объемами в 36-146ГБ, то сейчас это уже 900 и 1200ГБ. Что делать?
Во-первых, для enterprise дисков - не создавать больших дисковых групп в RAID-5, использовать RAID-50.
Во-вторых, переходить на RAID-6 и 60 для enterprise и nearline дисков.
Как все-таки быть с десктопными дисками? Может быть, для них подойдет RAID-6?
Нет, RAID-6 их тоже не спасет, так как появляется следующая проблема - несовместимость с аппаратными RAID контроллерами, одной из причин которой является неконтролируемое время доступа при возникновении ошибок:
Миллион часов MTBF - много или мало?
Что означает величина MTBF (Mean time between failures)? Для жестких дисков встречаются значения от 600-700 тыс. часов до 2-х миллионов. Рассмотрим для примера диск WD Red c MTBF равным миллиону часов. Неужели производитель гарантирует работу диска в течение 1000000/8760 = 114 лет и можно ни о чем не беспокоиться?
Вовсе нет. Значение MTBF (в случае HDD правильнее было бы использовать MTTF - mean time to failure) нельзя применить к одиночному изделию, это статистический показатель. Вот что пишет по этому поводу Hitachi:
MTBF target is based on a sample population and is estimated by statistical measurements and acceleration algorithms under median operating conditions. MTBF ratings are not intended to predict an individual drive’s reliability. MTBF does not constitute a warranty.
Это означает, что не один диск отработает 114 лет, а в партии из 114-ти дисков за 1 год можно ожидать выхода из строя одного диска. На практике, конечно, удобнее оперировать значением не MTBF, а AFR (annual failure rate - годовая интенсивность отказов). Упрощенная формула (если не принимать в расчет специфику распределения интенсивности отказов) выглядит так:
AFR=1/(MTBF/8760)
Т.е. для того же WD Red получаем величину AFR порядка 0,88%, причем она будет справедлива лишь в небольшой области на графике вероятности отказов. После 2-3-х лет работы в штатном для этого класса HDD режиме AFR будет нелинейно расти. А что будет, если режим отличается от штатного (например, при превышении температуры, уровня вибраций или круглосуточной эксплуатации бытовых дисков Seagate, для которых производитель рекомендует режим работы 8x5), и что вообще происходит в действительности? Ведь все это теоретические выкладки, может быть, рассказы о том, что "вот у меня дома старый Макстор работает почти десять лет без единого бэда" можно экстраполировать? Вот график из знаменитого отчета Google:

Он иллюстрирует статистику годовых отказов жестких дисков. Резкий рост значения AFR после одного года работы связан с тем, что Google использовал бытовые диски в режиме 24x7 (это была первая половина 2000-х, nearline класса еще не существовало). Итог: почти два процента в первый год, далее - рост до восьми с лишним процентов, что является результатом повышенной нагрузки. Кстати, вот распределение AFR в зависимости от нагруженности дисков:

Как видно из графика, тяжелые режимы работы резко увеличивают AFR, особенно в первые месяцы эксплуатации, когда высокая нагрузка помогает выявить диски со скрытыми производственными дефектами, и после четырех лет, когда нагрузка добивает изношенные диски.
Обратите внимание на спецификацию современных бытовых дисков Seagate: MTBF 700000 часов, при этом указан параметр Power-On Hours (POH) 2400 часов в год, что примерно соответствует режиму работы 8x5. Т.е. производитель обещает соответствие MTBF заявленному только при соблюдении данного режима работы. Хотите круглосуточной эксплуатации десктопных Seagate? Получите AFR в 8% вместо 1,25%. В руководстве есть еще одно уточнение:
Т.е. лимитируется еще и трафик, извольте читать/писать не больше 55ТБ в год. Не устраивает? Используйте диски nearline класса с MTBF от 1,2 млн часов и нелимитированным Power-On Hours.
Кстати, в целом статистика, предоставленная Google, соответствует классическому графику распределения отказов. Из-за характерной формы его еще называют bathtub curve:
В самом начале происходит большое число отказов изделий, имеющих скрытые производственные дефекты, т.н. "детская смертность". Затем частота отказов стабилизируется на период срока службы изделия, а потом начинает сказываться износ - отказы нелинейно растут.
Выводы:
Статистика - вещь упрямая. Не путайте MTBF и срок службы. Относитесь к дискам, как к расходным материалам, планируйте замену для отработавших под высокой нагрузкой в серверах по три-четыре года десктопных и nearline дисков. Вы вполне можете рассчитывать на AFR порядка 1% для nearline дисков, около 0,5% - для enterprise класса (10k/15k), разумеется, только в течение срока службы и при соблюдении всех условий эксплуатации. С десктопными дисками при высоких нагрузках гарантировать вообще ничего нельзя: температура, вибрация (в больших дисковых полках вибрация приобретает большое значение), повышенная нагрузка на блок головок сделают свое дело, и вы можете получить массовый падеж дисков уже после года работы.
Можно ли вообще использовать бытовые диски в серверах, если это делал Google? Все дело в том, как именно использовать. Google - это облачные технологии. Применительно к хранению данных это означает использование распределенной файловой системы, в данном случае - GFS, Google File System. Аналогичную архитектуру имеет, например, Parallels Cloud Storage. Данные разбиваются на блоки (chunks) размером в несколько мегабайт, эти блоки реплицируются между нескольким серверами. Серверы метаданных хранят информацию о распределении блоков и контролируют процессы чтения и записи блоков. Такой подход решает одну из проблем, связанных с эксплуатацией бытовых дисков - сравнительно высокую вероятность появления невосстановимых ошибок чтения (unrecoverable error rate), что приводит к большим сложностям при работе в RAID-массивах.
Влияние вибрации на производительность дисков

И последний аргумент: десктопные диски не рассчитаны на высокий уровень вибраций. Механика не та. Причины появления вибрационных нагрузок просты: большое количество дисков в одном корпусе (у Supermicro появился вариант на 72 3,5" диска в 4U) и вентиляторы по 5-9 тыс. оборотов в минуту. Так вот, замеры Seagate показали, что при нагрузке около 21 рад/с 2 десктопные диски испытывают очень большие сложности с позиционированием головок, теряют дорожку, производительность падает на 80 с лишним процентов.
Миф №2.
"RAID = бэкап. Я потратил на контроллер целых $600! Но данные при этом защитил, можно спать спокойно, бэкапы не нужны".
Потерять данные с избыточного массива не просто, а очень просто. Можно начать с простого человеческого фактора, который в статистике, регулярно собираемой разными агентствами, занимает львиную долю всех случаев потерь данных. Достаточно администратору СУБД снести пару таблиц в базе или какому-нибудь пользователю удалить несколько файлов на ресурсе с неправильно настроенными правами доступа. При работе с контроллером или СХД можно ошибочно удалить нужный том. Причиной катастрофы может послужить незащищенный кэш контроллера (включен write-back, батарейки нет или она неисправна, выходит из строя блок питания или PDU - и несколько десятков или сотен мегабайт не попавших на диски данных улетают в трубу).
Резервное копирование нужно всегда. Отсутствие бэкапов - преступление.
О надежности жестких дисков: MTBF – что это?
Originally published at Клуб IT профессионалов. Please leave any comments there.
Еще в 2007 году, на одной из конференций исследовательской группы USENIX (USENIX File and Storage Technologies, 2007 – FAST07) группа инженеров Google опубликовала результаты исследования показателей надежности дисков SATA и PATA. На сегодняшний день это самое крупное такое исследование по количеству наблюдавшихся «в естественной среде» жестких дисков. Результаты там, подчас, предстают самые неожиданные.
Инженеры Google собрали статистику по отказам для примерно 100 тысяч дисков в своих датацентрах. Особо интересно то, что Google использует у себя в серверах широкораспространенные consumer-series диски PATA и SATA (обеспечивая отказоустойчивость и надежность хранения инфраструктурно, за счет распределенной самописанной файловой системы хранения Google Filesystem), то есть все те самые диски, которые окружаю нас повседневно, а не какие-то особенные, "энтерпрайзные". Документ, озаглавленный Failure Trends in a Large Disk Drive Population (pdf 242 KB) содержит статистический анализ примерно за пять лет их срока службы, при этом непосредственное наблюдение и снятие показателей заняло 9 месяцев. Несколько интересных, а подчас и неожиданных тем, обнаруженных при прочтении:
1. MTBF – Mean Time Between Failure – ожидаемый срок службы до сбоя. Что это?
MTBF - это традиционно приводимый производителям параметр, долженствующий, по их мнению, характеризовать надежность выпускаемых ими жестких дисков. Это искусственно вычисляемый срок в часах работы, которые ожидаемо должны проходить от одного отказа до другого, в случае соблюдения эксплуатационных норм (в том числе смены диска на новый, при окончании его гарантийного срока!). Эта величина, как очевидно, предполагает некую линейность в вероятности отказов. Так ли это на самом деле? Нет. Результаты Google показывают, что Annual Failure Rate, ежегодный процент отказов, для жестких дисков нелинеен в зависимости от их срока службы.
В принципе, приведенный в работе график вероятности отказов не содержит какого-то откровения. Первоначальный пик в первые три месяца достаточно хорошо известен для любой техники, как "период обкатки". Если оборудование пережило этот неприятный первоначальный период, то в дальнейшем вероятность отказов заметно снижается. Отказы начинают нарастать к окончанию планового срока службы, "гарантийному сроку", в результате "механического износа", чем бы он ни вызывался. Но интересно, что диски двух- и трехлетнего возраста имеют вероятность отказа в четыре раза(!) выше, чем диски первого года службы.
Следует, однако, отметить, что значительный “выброс” в районе 2-3 года, по утверждениям Google, сильно зависит от марок и производителей жестких дисков. В частности, утверждается, что это связано с тем, что более новые модели (следовательно, прослужившие малые сроки), поступающие в датацентры, оказывались объективно более надежными, что вызвало снижение количества отказов в эти периоды. По понятным причинам в работе не называются более или менее надежные марки и производители.
Интересен спад отказов в 4 год, возможно вызванный просто "снижением поголовья". Дальнейший рост, однако, с большим разбросом (т-образный значок на верхней границе столбика), говорит уже о простом механическом износе оставшихся экземпляров.
Практический вывод для администратора систем хранения и серверов не находящихся на вендорской гарантии: Если есть такая возможность, регулярно списывайте и меняйте ваши жесткие диски по прошествии года, или двух лет службы. Замена дисков, во многих случаях, с учетом постоянного снижения их цены, обойдется дешевле, чем постоянно повышающийся риск их отказа. Для оборудования на вендорской гарантии, всерьез рассмотрите необходимость эксплуатации дисковых систем на критичных участках инфраструктуры за пределами их гарантийного трехлетнего срока. Малое число отказов за прошедшие два-три года не означают продолжение такой практики на четвертый год. Возможно имеет смысл всерьез задуматься об обновлении парка, или вложиться в расширенную гарантию.
Однако же про MTBF. Для consumer-series дисков периода 2002-2007 годов, обычно указывался MTBF равный 300.000 часов (для сегодняшних моделей указывается 600.000, 1.000.000 и даже 1.200.000 MTBF). 300.000 часов это 34 года непрерывной работы (300.000/24/365)! Если предположить, что MTBF имеет линейную природу, то это должно было бы означать AFR равный 1,46%, что, очевидно, не выполняется никогда, даже в лучшие периоды. Нетрудно посчитать, что, от партии в 100.000 штук, всего за пять лет, при приведенных в работе Google показателях отказов, останутся в живых только примерно 70% дисков.
Мы видим, что использовать его для реальной оценки надежности дисков нельзя.

В серии статей SSD 101 мы рассмотрели SSD со всех сторон. А теперь проверим главный аргумент фанатов SSD — что эти устройства выходят из строя гораздо реже, чем старые добрые HDD. Они обычно объясняют, что в SSD нет движущихся частей, и предъявляют документы от производителей с мутными расчётами среднего времени до отказа (MTBF). Всё это хорошо для рекламы, но мы предпочитаем реальную статистику частоты отказов.
В своих ежеквартальных отчётах Drive Stats мы определяем отказ диска или как реактивный (диск не работает), или как проактивный (мы считаем, что отказ неизбежен). В случае HDD мы определяем проактивный отказ по специфической статистике SMART, которую сообщает сам диск и которую мы отслеживаем.
SMART, или S.M.A.R.T., расшифровывается как Self-monitoring, Analysis, and Reporting Technology и представляет собой систему мониторинга, встроенную в HDD и SDD. Основная функция — сообщать различные показатели, связанные с надёжностью диска, для предсказания отказов. Backblaze каждый день записывает атрибуты SMART всех работающих дисков.
То же самое для SSD. Различные модели сообщают разные показатели SMART, но некоторые совпадают. На сегодняшний день для SSD мы регистрируем 31 атрибут SMART-статистики. 25 из них перечислены ниже.
Оставшиеся шесть (16, 17, 168, 170, 218 и 245) мы не можем найти. Пожалуйста, напишите в комментариях, если у вас есть информация по отсутствующим атрибутам.
Мы только начинаем использовать статистику SMART для предупреждения отказов SSD. Многие атрибуты зависят от модели диска или производителя. Кроме того, у нас было пока мало отказов SSD, как вы увидите ниже. Это ограничивает количество данных для исследования. Так что в реальности мы пока не смогли предсказать ни одного отказа.
В серверах хранения данных в качестве загрузочных дисков работают и SSD, и HDD. В нашем случае называть их загрузочными неверно, поскольку они также хранят различные логи и т. д. Другими словами, регулярно читают, записывают и удаляют файлы, а не только выполняют загрузку сервера.
В первых серверах хранения данных мы использовали только HDD, поскольку они были дешёвыми и выполняли свою функцию. Так продолжалось до середины 2018 года, когда мы смогли купить SSD на 200 ГБ по цене около $50, что в нашем понимании было верхней ценовой границей для загрузочных дисков серверов хранения данных. Это был эксперимент, но всё получилось настолько хорошо, что с середины 2018 года мы перешли на использование только SSD и заменяли вышедшие из строя загрузочные HDD на SSD.
Итак, у нас две группы дисков — SSD и HDD — которые выполняют одинаковые функции, имеют одинаковую рабочую нагрузку и работают в одинаковых условиях в течение долгого времени. Естественно, мы решили сравнить частоту отказов загрузочных дисков SSD и HDD. Ниже приведены показатели отказов за весь срок службы для каждой группы по состоянию на II кв. 2021 года.
Годовая частота сбоев (AFR)
| Количество дисков | Средний возраст (мес.) | Дней работы | Всего сбоев | AFR | |
|---|---|---|---|---|---|
| SSD | 1666 | 14,2 | 591 501 | 17 | 1,05% |
| HDD | 1607 | 52,4 | 3 523 610 | 619 | 6,41% |
Загрузочные диски. Отчётный период: апрель 2013 — июнь 2021
Всё понятно, SSD победили. Можно положить HDD на полку или на пол как ограничитель для двери. Но погодите, давайте сначала учтём несколько моментов, которые не вошли в таблицу.
- Средний возраст SSD составляет 14,2 месяца, а средний возраст HDD — 52,4 месяца.
- Возраст самых старых SSD — около 33 месяцев, а самых новых HDD — 27 месяцев.
Другим фактором является количество дней, сколько диски каждой группы проработали без сбоев. Большой разброс в количестве дней работы приводит к значительной разнице в доверительных интервалах двух групп, поскольку существенно различается количество наблюдений (т.е. дней работы).
Чтобы провести более точное сравнение, попробуем привести к общему знаменателю средний возраст и количество дней работы для SSD и HDD. Для этого можем перенестись назад во времени, когда группа HDD соответствовала группе SSD из II кв. 2021 года по среднему возрасту и количеству дней работы. Это позволит сравнить группы в один и тот же период жизненного цикла.
Взяв данные по HDD за IV кв. 2016 года, мы смогли сделать следующее сравнение.
Годовая частота сбоев (AFR)
| Количество дисков | Средний возраст (мес.) | Дней работы | Всего сбоев | AFR | |
|---|---|---|---|---|---|
| SSD на II кв. 2021 | 1666 | 14,2 | 591 501 | 17 | 1,05% |
| HDD на IV кв. 2016 | 1297 | 14,3 | 659 526 | 25 | 1,38% |
Загрузочные диски. Отчётный период: апрель 2013 — указанный период
Неожиданно разница в AFR оказалась не такой уж большой. На самом деле статистика каждой группы находится в пределах 95%-ного доверительного интервала другой группы. Окно довольно широкое (плюс-минус 0,5%) из-за относительно небольшого количества дней работы накопителей.
Что же в итоге? Мы получили некоторые свидетельства, что в начале работы (в среднем до 14 месяцев в данном случае) SSD выходят из строя реже, но не намного. Но вы же покупаете диск не на 14 месяцев, а на годы. Что мы знаем об этом?
У нас есть данные по загрузочным HDD с 2013 года и по загрузочным SSD с 2018 года. На диаграмме показан Lifetime AFR каждого типа дисков до II кв. 2021 года.

Как видно, с 2018 года частота сбоев загрузочных HDD стала расти. Тенденция сохранялась в 2019 и 2020 годах, а в 2021 году (пока что) остановилась. Очевидно, что с увеличением возраста HDD увеличивается и частота отказов.
Интересно сравнить кривые в первых четырёх точках. Для флота HDD пятый год (2018) знаменовал резкий рост частоты отказов. Ждёт ли та же участь SSD в их пятый год? Хотя мы можем ожидать некоторого увеличения AFR по мере старения SSD, но будет ли оно таким же резким, как в случае с HDD?
Что же нам покупать: SSD или HDD? Учитывая то, что мы знаем на сегодняшний день, вряд ли можно использовать AFR как фактор при принятии решения. С учётом возраста и количества дней работы оба типа накопителей схожи, а разница недостаточна, чтобы оправдать дополнительные затраты на покупку SSD вместо HDD. На данном этапе лучше принимать решение на основе других факторов: стоимость, требуемая скорость, энергопотребление, требования к форм-фактору и так далее.
В ближайшие пару лет мы получим более полное представление об AFR для SSD. И тогда сможем решить, насколько велика разница в частоте отказов SSD и HDD. А сейчас мы не видим, чтобы она была значительной.

Просто удивительно то, насколько велико непонимание вокруг такого широко распространенного понятия, как MTBF (Mean Time Between Failure — «Время между сбоями» или «наработка на отказ» ), насколько смысла этой величины не понимают, зачастую, даже специалисты в области хранения данных.
Казалось бы — что может быть проще. «Наработка на отказ» это время беспроблемной работы, от первого включения нового диска, до момента отказа, посчитанная в часах.
Почти любой, кто поинтересуется значением, приводимым производителями, в качестве MTBF современных дисков, и с легкостью сделает несложные подсчеты, будет удивлен странной его величиной.
На сегодня величина MTBF приводится в миллион или даже полтора миллиона часов.
В году — примерно 8760 часов, значит, исходя из нашего понимания «физического смысла» этого значения, производитель планирует «наработку на отказ» для любого такого диска более ста лет (114 лет, для миллиона часов MTBF), что является очевидной нелепостью для каждого, у кого подыхали жесткие диски.
Тогда что это за «миллион часов», где и каким образом он измерен?
Конечно же производитель не гоняет диск 114 лет, оценка производится искусственно, но откуда вообще взялась величина в «миллион часов»?
Дело в том, что MTBF измеряется для всей эксплуатируемой «дисковой популяции», и распространяется на период объявленного гарантийного срока для данного типа дисков. Оба выделенных момента являются важными, и часто опускаются в описании, что и приводит к принципиальному непониманию.
Или же представим себе чуть более приближенную к реальности ситуацию.
Допустим, для простоты подсчета, у нас есть система хранения на 115 дисков. Для каждого диска производитель приводит MTBF равный миллиону часов. Но надо принять во внимание то, что в большой дисковой популяции общий MTBF, то есть вероятность отказа, растет, с увеличением количества используемых дисков.
Для 115 дисков, исходя из приводимой вендором величины MTBF, мы вправе ожидать, что хотя бы один диск из популяции в 115 выйдет из строя до конца трехлетнего гарантийного срока.
Этот вариант уже куда более похож на правду.
Строго говоря, на практике, вместо MTBF гораздо практичнее пользоваться параметром AFR — Annual Failure Rate, или «ежегодная вероятность сбоев», выводимом из MTBF.
Он вычисляется как: AFR = 1-exp(-8760/MTBF)
Величина AFR для диска с миллионом часов MTBF составляет 0,87%, что, в принципе, хоть и чуть завышено (Google в известном исследовании 2007 года показывает для новых дисков в пределах гарантийного срока как раз AFR в районе 1%), но, все же уже довольно хорошо согласуется с практикой.
Любопытно, что, например, такой производитель жестких дисков как WD теперь вовсе перестал указывать величину MTBF, перейдя на указание другого параметра: «power on/off cycles», по видимому не в последнюю очередь именно в связи с явно видимым непониманием и неочевидностью применения указываемой величины MTBF пользователями.
Это одна из историй о технологиях, которые отличают серию WD Red от обычных дисков. Они помогают повысить отклик системы, не дают выпасть диску из массива и позволяют ему беспроблемно работать в круглосуточном режиме. Плюс мы сделали базовые тесты производительности самих дисков и их работы в WD MY CLOUD DL2100.

Накопители WD Red за пять лет своего существования на рынке успели завоевать определенную репутацию и четко закрепиться в сегменте решений для NAS-систем в качестве надежных устройств хранения с разумной общей стоимостью владения. Серия оказалась настолько удачной, что все эти годы — начиная с анонса первой модели в 2012 году — Western Digital регулярно пополняла семейство WD Red очередными новинками, а в середине мая представила новые накопители WD Red и WD Red Pro с рекордной для серии емкостью 10 ТБ.

Сегодня NAS-системы, то есть сетевые системы хранения данных (Network Attached Storage), являются привычным и обязательным компонентом любой компьютерной сети — от сложных корпоративных инфраструктур до небольших офисов, от производства до обычных домашних сеток. И в любом из этих сценариев для сетевой системы хранения будут важны одни и те же критерии: надежность, стабильность, круглосуточный доступ к данным. Да, именно так — в любом сценарии, поскольку вряд ли кто-то убедит домашнего пользователя в том, что его личные фотки и записи менее ценны, чем какая-то корпоративная информация.

Western Digital позиционирует жесткие диски WD Red в качестве решений для работы в NAS-системах различной конфигурации с количеством отсеков от одного до шестнадцати, в режиме 24/7, с малым уровнем шума, нагрева и низким потреблением энергии. Диски WD Red поддерживают ряд аппаратных и программных технологий, оптимизирующих работу этих накопителей в составе NAS систем.
При этом накопители WD Red позиционируются в рознице несколько дороже, чем представители «бытовых» серий WD аналогичной емкости. Например, винчестер WD Red может обойтись дороже, чем накопитель WD Blue аналогичной емкости, на 25% и более, а ценовая разница с WD Red Pro может превышать 50%.
Так что сегодня мы заодно выясним, стоит ли овчинка выделки, и за что именно мы платим, выбирая WD Red.
Винчестеры семейства WD Red представляют собой самую что ни на есть классику накопителей на жестких магнитных дисках: корпус, двигатель, вращающийся шпиндель, на который «надеты» алюминиевые или стеклянные пластины со специальным магнитным покрытием. Над пластинами — на расстоянии нескольких нанометров от поверхности, расположены пишуще-считывающие магнитные головки.
Обычные жесткие диски выпускаются в негерметичных корпусах — через отверстие и систему внутренних фильтров воздух сообщается с атмосферой. Накопители WD Red, начиная с емкости в 8 ТБ, отличаются от привычных дисков: корпуса их полностью герметичны, верхняя крышка приварена к основанию лазером, а внутри вместо воздуха находится инертный газ гелий.
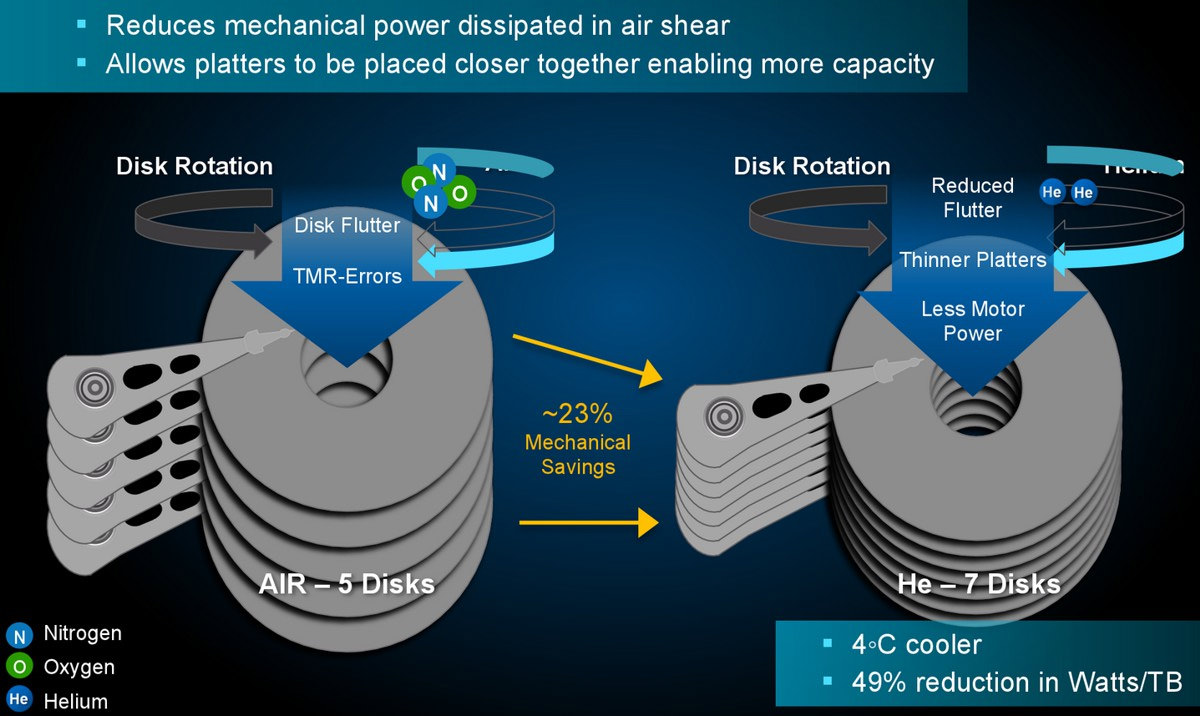
Воздух внутри корпуса винчестера вызывает нагрев устройства из-за быстрого вращения пластин, тепловыделения контроллера и силовых цепей. Воздух также является ограничением для наращивания количества пластин или уменьшения расстояния между считывающей головкой и поверхностью.
Гелий обладает лучшей тепловодностью и меньшей плотностью, нежели обычный воздух. Заполнение внутреннего объема дисков гелием позволило разместить внутри до семи пластин (в перспективе восемь), снизить за счет свойств инертного газа тепловыделение, энергопотребление и вибрацию.
Технология наполнения дисков гелием, разработанная в Western Digital, получила название HelioSeal. Сегодня она используется для производства накопителей объемом 8 — 10 ТБ, и не только в серии WD Red.
Минус применения гелия (если его вообще можно считать минусом) только один: из-за высокой текучести газа верхнюю крышку и стенки корпуса в дисках WD Red приходится делать толще, так что в результате накопители получаются несколько более увесистыми.
К весне 2017 года, по официальным данным Western Digital, компания поставила более 15 млн наполненных гелием дисковых накопителей высокой емкости для самых различных областей применения, в том числе в серии WD Red для NAS-систем.
Особенностью накопителей серии WD Red является поддержка фирменной технологии балансировки пластин 3D Active Balance Plus. В упрощенном виде работу этой технологии можно представить по аналогии с балансировкой колес автомобиля.

Технология 3D Active Balance Plus представляет собой механизм управления балансировкой в двух плоскостях. Блок магнитных дисков в накопителе крепится на шпинделе с помощью нескольких винтов. Чем точнее выставлена длина этих винтов, тем выше будет качество балансировки, стабильность, надежность и производительность накопителя при одновременном снижении побочных вибраций и шума. Особенно эти параметры критичны в средах систем NAS или массивов RAID.
Накопители серии WD Red поддерживают фирменную технологию NASware, обеспечивающую полную оптимизацию работы устройства в зависимости от режима нагрузки. В каком-то смысле прошивку NASware 3.0 можно назвать своеобразной операционной системой, управляющей комплексом технологий и утилит для повышения надежности, производительности, минимизации времени простоя и упрощения процесса интеграции систем NAS и массивов RAID.
NASware гарантирует отсутствие «выпадений» накопителей из RAID, снижает шансы искажения или потери данных. Технология удержания головок StableTrac, работающая под общим управлением NASware, обеспечивает максимальную для 3,5-дюймового форм-фактора плотность записи данных на пластину.
Характерной особенностью прошивки NASware для дисков WD Red, отличающей ее от других серий накопителей, является режим работы без частой парковки головок. В обычных накопителях, ориентированных на работу в составе ПК, время ожидания в бездействии перед парковкой блока головок (APM — Advanced Power Management) ставится небольшим — именно так достигается экономия энергии. Обратная сторона медали — значительная задержка реагирования накопителя при последующем обращении к диску и ускоренный расход запаса циклов парковки.
В накопителях WD Red парковка головок в рабочем режиме отключена полностью, и только при отключении питания парковка производится в автоматическом режиме. Та же история с вращением шпинделя: в прошивке WD Red установлено нулевое значение spindown (standbly) timer (тайм-аут остановки двигателя), полностью запрещающее останавливать двигатель в рабочем режиме. Расчетное количество циклов парковки головок у линейки WD Red составляет 600 тысяч (для сравнения: для серии WD Blue заявлено 300 тысяч циклов парковки головок).
В обычных накопителях для настольных ПК параметры APM и standby timer настраиваются с помощью ATA-команд. В случае с WD Red жесткие настройки NASware гарантируют показатель латентности реакции накопителя в любой момент обращения к диску на минимальном уровне в режиме 24/7.
Дополнительно линейка накопителей WD Red также поддерживает функцию SCT ERC (SMART Command Transport Error Recovery Control), которую в WD называют Time Limited Error Recovery (TLER). В случае обнаружения сбойных секторов традиционные накопители для настольных ПК, у которых очень редко присутствует настройка тайм-аута коррекции ошибок, могут в попытке считывания сбойного сектора «зависнуть» на некоторое время. Для диска в RAID-массиве с избыточностью такое поведение с большой долей вероятности приведет к тому, что контроллер «выкинет» его из массива.
У накопителей WD Red параметр SCT ERC отрегулирован и, как правило, установлен по умолчанию на семь секунд. RAID-контроллер не теряет контроль за таким диском, при этом данные из сбойных секторов восстанавливаются из соседних дисков.
Наконец, серия накопителей WD Red полностью поддерживает набор дополнительных потоковых инструкций ATA Streaming Feature Set. Если операционная система вашего NAS имеет поддержку набора этих команд (большинство современных бытовых NAS, как правило, имеют), система обеспечит гарантированную и бесперебойную трансляцию потокового медиаконтента на все устройства сети практически без снижения скорости обслуживания всех остальных обращений.

Мы живем в эпоху расцвета HDD: объемы достигли 4ТБ на диск (и это не предел), цены на большие (1-4ТБ, 7200 тыс. оборотов/мин) и быстрые (10/15 тыс. оборотов/мин) HDD снижаются, повсеместно используются SSD, растет производительность и наращивается функционал аппаратных RAID контроллеров, давно "повзрослели" решения на базе ZFS. Появилась проблема: массивы на несколько десятков терабайт стали доступны сравнительно небольшим организациям, но уровень знаний правил и рекомендаций по хранению данных остался невысоким. Ведет это к весьма плачевным последствиям - прямым начальным денежным потерям (результат самодеятельности в выборе оборудования) и дальнейшему ущербу от потери данных.
В данной статье мы рассмотрим несколько проблем и мифов, связанных с хранением данных. Мифов накопилось предостаточно и они продолжают жить, несмотря на огромное количество трагичных историй:
Миф №1.
Самый радикальный: "RAID вообще не нужен (как вариант - можно использовать RAID-0 + бэкапы). Современные диски достаточно надежны, у меня дома все работает годами".
Встречается, в основном, у начинающих неопытных IT-специалистов. Причина существования данного мифа проста - непонимание того, что такое информация вообще, и какое отношение имеет RAID к защите целостности информации. Дело в том, что RAID защищает не только от полной потери диска. Окончательный выход диска из строя - это лишь конечная точка его непростого существования, и до момента потери информации на всем диске мы можем терять небольшие фрагменты по мере появления сбойных секторов. Для бытового применения потеря (или искажение) участка в 512 байт обычно не является большой проблемой. Дома большую часть дискового пространства занимают мультимедийные файлы: изображения, звук и видео, так что потеря ничтожно малого фрагмента никак не отражается на воспринимаемом качестве, например, видео-файла. Для хранения структурированной информации (например, базы данных) любое искажение является недопустимым и появление любого "бэда" (нечитаемого сбойного сектора) означает полную потерю файла или тома. Статистическую вероятность наступления такого события мы рассмотрим позже.
Вывод: пользовательские данные нельзя хранить на одиночных дисках или в массивах, не обеспечивающих избыточности.
Читайте также: