
Можно ли проводить параллельные вычисления на одном компьютере
Аннотация: Лекция расскажет какие преимущества есть у параллельных вычислений, и какие проблемы ждут программиста при создании программ, ориентированных на параллельные вычисления.
Мир параллельных вычислений
Первый вопрос, на который следует дать ответ, - какие вычисления программы на компьютере следует называть параллельными. Но это не единственный вопрос, на который хотелось бы получить ответ. Не менее важно понять, зачем вообще переходить из простого, хорошо знакомого, понятного мира последовательных вычислений к сложному для понимания миру параллельных вычислений. Какие преимущества есть у параллельных вычислений, и какие проблемы ждут программиста при создании программ, ориентированных на параллельные вычисления. Чтобы ответить на эти вопросы, давайте совершим небольшой экскурс в историю развития компьютеров.
Первые компьютеры были построены в соответствии с принципами, сформулированными Фон-Нейманом. Они имели три главных компонента - память , процессор и некоторый набор внешних устройств, обеспечивающих ввод и вывод информации.
Память была многоуровневой и для первых компьютеров содержала внешнюю память и внутреннюю память - оперативную и регистровую. Внешняя память (на магнитных лентах, перфокартах, дисках) позволяла сохранять программы и данные вне зависимости от того, включен компьютер или нет. Внутренняя память хранила информацию только на период сеанса работы с компьютером. При отключении компьютера содержимое внутренней памяти исчезало.
Для того чтобы программа могла быть выполнена на компьютере, она должна была быть загружена в оперативную память . Хранилась она там точно также как и данные, обрабатываемые этой программой. Принцип хранимой в памяти программы - один из главных принципов Фон-Неймановских компьютеров.
Регистровая память использовалась в момент выполнения вычислений. Прежде, чем выполнить некоторую операцию над данными, данные должны быть размещены на регистрах. Этот самый быстрый вид памяти обеспечивал необходимое быстродействие при выполнении операций над данными.
Выполнение всех операций - операций над данными и операций по управлению процессом вычислений - осуществлял процессор . Процессор компьютера обладал определенным набором команд. Этот набор был достаточно универсальным, чтобы вычислить любую потенциально вычислимую функцию. С другой стороны этот набор обеспечивал относительную простоту написания программ человеком.
Программы для первых компьютеров представляли последовательность команд, входящих в допустимый набор команд процессора. Выполнение программы на компьютере осуществлялось достаточно просто. В каждый момент времени на компьютере выполнялась одна программа . Процессор , в соответствии с программой, последовательно выполнял одну команду за другой. Все ресурсы компьютера - память , время процессора, все устройства - были в полном распоряжении программы, и ничто не могло вмешаться в ее работу (не считая конечно человека). Параллелизма не было и в помине.
Такая идиллия продолжалась недолго по причине неэффективного использования ресурсов крайне дорогих в те времена компьютеров. Компьютеры тогда не выключались, - одна программа сменяла другую.
Достаточно скоро у компьютера наряду с процессором, который стал называться центральным процессором, появились дополнительные процессоры, в первую очередь специализированные процессоры устройств ввода-вывода информации, отвечающие за выполнение наиболее медленных команд. Это дало возможность организации пакетного режима выполнения программ, когда на компьютере одновременно выполнялись несколько программ - одна программа могла печатать результаты работы, другая - выполняться, третья - вводить необходимые ей данные, например с магнитной ленты или другого внешнего носителя.
Революционным шагом было появление в 1964 году операционной системы фирмы IBM - OS 360. Появившаяся у компьютера операционная система стала его полновластным хозяином - распорядителем всех его ресурсов. Теперь программа пользователя могла быть выполнена только под управлением операционной системы. Операционная система позволяла решить две важные задачи - с одной стороны обеспечить необходимый сервис всем программам, одновременно выполняемым на компьютере, с другой - эффективно использовать и распределять существующие ресурсы между программами, претендующими на эти ресурсы. Появление операционных систем привело к переходу от однопрограммного режима работы к мультипрограммному, когда на одном компьютере одновременно выполняются несколько программ. Мультипрограммирование это еще не параллельное программирование , но это шаг в направлении параллельных вычислений.
Мультипрограммирование - параллельное выполнение нескольких программ. Мультипрограммирование позволяет уменьшить общее время их выполнения.
Под параллельными вычислениями понимается параллельное выполнение одной и той же программы. Параллельные вычисления позволяют уменьшить время выполнения одной программы.
Заметим, что наличие у компьютера нескольких процессоров является необходимым условием для мультипрограммирования. Существование операционной системы, организующей взаимную работу процессоров, достаточно для реализации мультипрограммирования. Для параллельных вычислений накладывается дополнительное требование - это требование к самой программе, - программа должна допускать возможность распараллеливания вычислений.
Появление операционной системы означало, что компьютер нельзя рассматривать только как "железо" ( память , процессоры, другие устройства). Теперь у него две составляющие - хард ( hard ) и софт ( soft ) - аппаратная и программная составляющие, взаимно дополняющие друг друга. За полвека существования компьютеров оба компонента стремительно развивались.
Для аппаратуры характерен экспоненциальный рост, что нашло отражение в известном эмпирическом законе Мура, - экспоненциально росли все важнейшие характеристики - объем памяти на всех уровнях, уменьшение времени доступа к памяти, быстродействие процессоров. Согласно закону Мура (Гордон Мур - один из основателей фирмы Intel) каждые полтора года значения характеристик увеличивались вдвое. Росло и число процессоров, включаемых в состав компьютера. Изменялась и архитектура компьютера . Эти изменения во многом были шагами в сторону распараллеливания вычислений. Вот лишь некоторые изменения в архитектуре процессоров, связанные непосредственно с процессом распараллеливания:
- Конвейерная обработка команд. Процесс выполнения потока команд процессором уже не рассматривался как последовательное выполнение команды за командой. Обработка потока команд выполнялась на конвейере, так что сразу несколько команд готовились к выполнению. При конвейерной обработке команды, не связанные между собой по данным, могли выполняться одновременно, что является уже настоящим параллелизмом.
- "Длинные команды". Архитектура некоторых компьютеров включала несколько процессоров, позволяющих выполнять логические и арифметические операции над целыми числами, несколько процессоров, выполняющих операции над числами с плавающей точкой. Длинная команда позволяла указать в одной команде действия, которые должен выполнить каждый из существующих процессоров. Опять таки, это позволяло реализовать параллелизм на аппаратном уровне.
- Векторные и матричные процессоры. В набор команд таких процессоров включаются базисные операции над векторами и матрицами. Одной командой, например, можно сложить две матрицы. Такая команда фактически реализует параллельные вычисления. Приложения, где эти операции составляют основу обработки данных, широко распространены. Реализуемая аппаратно параллельная обработка данных позволяет существенно повысить эффективность работы приложений этого класса.
- Графические процессоры. Еще одним важным видом приложений, где на аппаратном уровне происходит параллельное выполнение, являются приложения, интенсивно работающие с графическими изображениями. Эту обработку осуществляют графические процессоры. Графическое изображение можно рассматривать как набор точек. Обработка изображения зачастую сводится к выполнению одной и той же операции над всеми точками. Распараллеливание по данным легко реализуется в такой ситуации. Поэтому графические процессоры давно уже стали многоядерными, что позволяет распараллелить обработку и эффективно обрабатывать изображение.
- Суперкомпьютеры. К суперкомпьютерам относят компьютеры с максимальными характеристиками производительности на данный момент. В их состав входят сотни тысяч процессоров. Эффективное использование суперкомпьютеров предполагает самое широкое распараллеливание вычислений.
В научных исследованиях и в новых технологиях всегда есть задачи, которым требуется вся мощь существующих вычислительных комплексов. Научный потенциал страны во многом определяется существованием у нее суперкомпьютеров. Понятие суперкомпьютера это относительное понятие. Характеристики суперкомпьютера десятилетней давности сегодня соответствуют характеристикам рядового компьютера. Сегодняшние суперкомпьютеры имеют производительность , измеряемую в петафлопсах (10 15 операций с плавающей точкой в секунду). К 2020 году ожидается, что производительность суперкомпьютеров повысится в 1000 раз и будет измеряться в экзафлопсах.
Классификация компьютеров
Мир компьютеров многообразен, начиная от миниатюрных встроенных компьютеров до многотонных суперкомпьютеров, занимающих отдельные здания. Классифицировать их можно по-разному. Рассмотрим одну из первых и простейших классификаций - классификацию Флинна, основанную на том, как устроена в компьютере обработка данных. Согласно этой классификации все компьютеры (вычислительные комплексы) можно разделить на четыре класса - компьютеры с архитектурой:
- SISD (Single Instruction stream - Single Data stream) - одиночный поток команд - одиночный поток данных. К этому классу относятся обычные "последовательные" компьютеры с фон-Неймановской архитектурой, когда команды программы выполняются последовательно, обрабатывая очередной элемент данных.
- SIMD (Single Instruction stream - Multiple Data stream) - одиночный поток команд - множественный поток данных. К этому типу относятся компьютеры с векторными и матричными процессорами.
- MISD (Multiple Instruction stream - Single Data stream) - множественный поток команд - одиночный поток данных. К этому типу можно отнести компьютеры с конвейерным типом обработки данных. Однако, многие полагают, что такие компьютеры следует относить к первому типу, а компьютеры класса MISD пока не созданы.
- MIMD (Multiple Instruction stream - Multiple Data stream) - множественный поток команд - множественный поток данных. Класс MIMD чрезвычайно широк и в настоящее время в него попадают многие компьютеры достаточно разной архитектуры. Поэтому предлагаются другие классификации, позволяющие более точно классифицировать компьютеры, входящие в класс MIMD.
Мы не будем рассматривать подробную классификацию компьютеров класса MIMD. Остановимся только на другом способе разделения компьютеров на три класса:
Сейчас почти невозможно найти современную компьютерную систему без многоядерного процессора. Даже недорогие мобильные телефоны предлагают пару ядер под капотом. Идея многоядерных систем проста: это относительно эффективная технология для масштабирования потенциальной производительности процессора. Эта технология стала широкодоступной около двадцати лет назад, и теперь каждый современный разработчик способен создать приложение с параллельным выполнением для использования такой системы. На наш взгляд, сложность параллельного программирования часто недооценивается.
В этой статье мы попробуем разработать простейшее приложение, использующее для распараллеливания средства C++ и сравнить его с версией, использующей Intel oneTBB.
Операционные системы и язык C++ предоставляют интерфейсы для создания потоков, которые потенциально могут выполнять один и тот же или различные наборы инструкций одновременно.
Основными источниками проблем многопоточного выполнения являются data races (гонки данных) и race conditions (состояние гонки). Простыми словами, C++ определяет data race как одновременные и несинхронизированные доступы к одной и той же ячейке памяти, при этом один из доступов модифицирует данные. В то время как race conditions является более общим термином, описывающим ситуацию, когда результат выполнения программы зависит от последовательности или времени выполнения потоков.
Основная проблема race conditions заключается в том, что они могут быть незаметны во время разработки программного обеспечения и могут исчезнуть во время отладки. Такое поведение часто приводит к ситуации, когда приложение считается законченным и корректным, но у конечного пользователя периодически возникают проблемы, часто неясного характера. Для решения проблемы data race, C++ предоставляет набор интерфейсов, таких как атомарные операции и примитивы для создания критических секций (мьютексы).
Атомарные операции — это мощный инструмент, который позволяет избежать data races и создавать эффективные алгоритмы синхронизации. Однако, это создает замысловатую модель памяти C++, которая представляет собой еще один уровень сложности.
Использование мьютекса зачастую намного проще, чем использование атомарных операций. Он позволяет создать критическую секцию, которая может быть выполнена не более чем одним потоком в любой данный момент времени. Кроме того, продвинутые мьютексы, такие как shared_lock , в некоторых случаях могут повысить эффективность, позволяя группе потоков исполнять критическую секцию, если мьютекс не захвачен в эксклюзивное использование.
Давайте попытаемся распараллелить простую задачу вычисления суммы элементов массива. Решение этой проблемы в однопоточной программе может выглядеть следующим образом:
int summarize(const std::vector& vec)
Выполнение алгоритма в однопоточной программе:
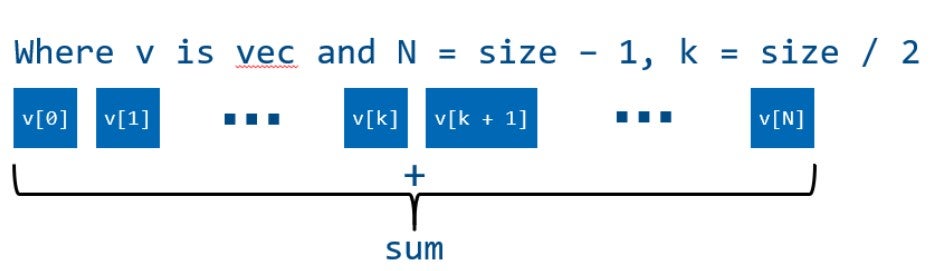
Для того чтобы исполнить алгоритм параллельно, нам нужно разделить его на независимые части, которые могут обрабатываться независимо друг от друга. Самый простой подход состоит в том, чтобы разделить обрабатываемые элементы на несколько частей и обработать каждую часть в своем собственном потоке.
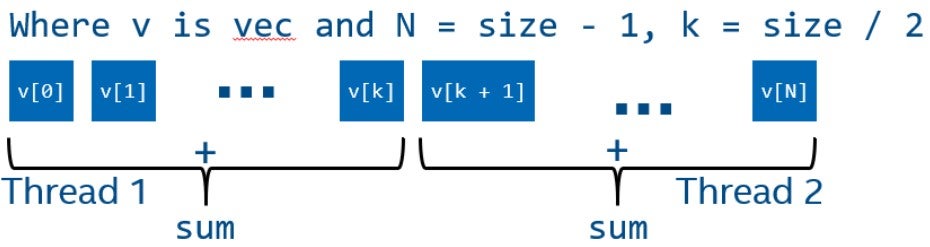
Однако в этом коде есть сложность, которая не позволяет нам просто разделить массив на две равные части и обрабатывать его параллельно. Все элементы суммируются в одну переменную, доступ к которой приведёт к data race, потому что один из потоков может записывать эту переменную одновременно с другим потоком, считывающим или записывающим в данную переменную.
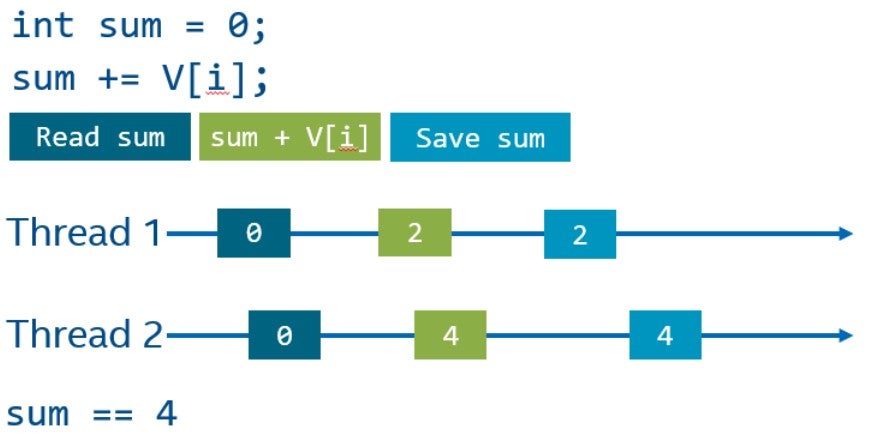
Составной оператор (оператор +=), по сути, состоит из трех операций: чтение из памяти, операция сложения и сохранение результата в памяти. Эти операции могут выполняться параллельно разными потоками, что может привести к неожиданным результатам. На следующем рисунке показан возможный порядок операций на временной шкале двух потоков. Основная сложность заключается в том, что оба потока могут не получить результат операций другого потока и перезаписать данные. C++ трактует такие ситуации как data race, и поведение программы, в таких случаях, не определено. Например, в результате мы можем получить четыре, ожидая шесть (как показано на рисунке). В худшем случае данные могут быть в непредсказуемом состоянии.
Существует много способов борьбы с data race, давайте рассмотрим самый простой из них - мьютекс.
Мьютекс имеет два основных интерфейса: блокировка (lock) и разблокировка (unclock). Блокировка переводит мьютекс в эксклюзивное владение, а разблокировка освобождает его, делая доступным для других потоков. Поток, который не может заблокировать мьютекс, будет остановлен, ожидая, пока другой поток освободит данный мьютекс.
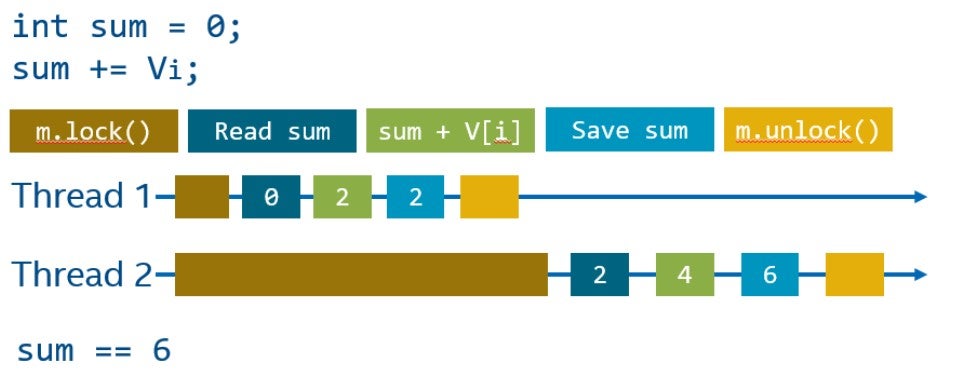
Код, защищенный мьютексом, также называется критической секцией. Важное наблюдение состоит в том, что второй поток, который не смог заблокировать мьютекс, не будет делать ничего полезного, во время того, пока первый поток находится в критической секции. Таким образом, размер критической секции может значительно повлиять на общую производительность системы.
Давайте попробуем сделать наш последовательный пример параллельным. Для создания потоков используем библиотеку из стандартной библиотеки C++.
int summarize(const std::vector& vec)
int num_threads = 2;
auto thread_func = [&sum, &vec, &m] (int thread_id)
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// - мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// - мьютекс освобождается в деструкторе (т.е. вызван mutex.unlock())
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
// Нам нужно дождаться всех потоков
// до разрушения std::vector
Запустив нашу программу, мы, вероятно, увидим неверный результат. Причина в том, что с помощью мьютекса мы защитили себя от data race при вычислении суммы, но основной поток может считывать переменную sum, в то время как другие потоки изменяют ее. Даже если мы защитим чтение с помощью мьютекса, это приведет к другой неочевидной сложности, называемой race condition: чтение, защищённое с помощью мьютекса, не гарантирует логическую корректность алгоритма. В нашем случае мы не дожидаемся полного завершения вычислений. Чтобы решить эту проблему, мы должны дождаться завершения потоков, прежде чем считывать результат. Однако, в данном случае мьютекс не требуется для чтения общей суммы , потому что синхронизация вычислений выполняется во время ожидания потоков (с помощью функции join).
int summarize(const std::vector& vec)
int num_threads = 2;
auto thread_func = [&sum, &vec, &m] (int thread_id)
// Делим итерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// - мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// - мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
// Запускаем поток со стартовой функцией `thread_func`
// и аргументом функции ` thread_id`
threads[thread_id] = std::thread(thread_func, thread_id);
// Нам нужно дождатьсявсех потоков до
Этот подход к распараллеливанию, очевидно, будет работать медленнее, чем последовательная версия, потому что для каждого sum += vec[i] мы берем мьютекс std:: lock_guard lock (m) . Таким образом, мы полностью упорядочиваем вычисления, т. е. разрешаем работать только одному потоку в любой момент времени. Чтобы избежать этого, мы можем сначала выполнить локальное суммирование в каждом потоке, а в конце вычислений добавить результат к глобальной сумме.
auto thread_func = [&sum, &vec, &m] (int thread_id)
// Делим origin rangeитерационное пространство на 2 части
int start_index = vec.size() / 2 * thread_id;
int end_index = vec.size() / 2 * (thread_id + 1);
int local_sum = 0;
for (int i = start_index; i < end_index; ++i)
// Используем lock_guard, имплементирующий RAII идиому:
// - мьютекс блокируется в конструкторе
// (т.е. вызван mutex.lock())
// - мьютекс освобождается в деструкторе
// (т.е. вызван mutex.unlock())
Этот простой пример демонстрирует, что параллельное программирование приводит к ряду проблем, которые невозможно наблюдать в последовательной программе. Более того, эти проблемы не всегда легко обнаружить, и они не всегда очевидны. Библиотеки, такие как oneTBB, упрощают параллельное программирование во многих аспектах. Для наглядности наш пример можно переписать с помощью parallel_reduce , который не требует каких-либо специальных синхронизаций и механизмов, чтобы избежать race conditions:
int summarize(const std::vector& vec)
int sum = tbb::parallel_reduce(tbb::blocked_range, 0,
[&vec] (const auto& r, int init)
for (auto i = r.begin(); i != r.end(); ++i)
Хотя этот пример относительно небольшой, он показывает набор значительных упрощений, которые предоставляет oneTBB. Например, oneTBB автоматически создаст набор потоков, которые будут повторно использоваться между несколькими вызовами параллельных алгоритмов. Кроме того, parallel_reduce реализует все необходимые синхронизации, а пользователю достаточно описать требуемую операцию свертки, например, std::plus .
oneTBB использует подход, основанный на work stealing алгоритме распределения задач, предоставляя обобщенные параллельные алгоритмы, применимые для широкого спектра приложений. Основное преимущество подхода oneTBB заключается в том, что он позволяет легко создавать параллелизм в различных независимых компонентах приложения.
В нашей серии статей мы продемонстрируем, как oneTBB можно использовать для динамической балансировки нагрузки и распараллеливания графов. Помимо параллелизма задач на процессоре, мы покажем, как oneTBB можно использовать в качестве уровня абстракции для балансировки вычислений между несколькими разнородными устройствами, такими как GPU.
Параллельной машиной называют, грубо говоря, набор процессоров, памяти и некоторые методы коммуникации между ними. Это может быть двухядерный процессор в вашем (уже не новом) ноутбуке, многопроцессорный сервер или, например, кластер (суперкомпьютер). Вы можете ничего не знать о таких компьютерах, но вы точно знаете, зачем их строят: скорость, скорость и еще раз скорость. Однако скорость — не единственное преимущество.
После выполнения не самой тривиальной задачи по созданию такого аппарата, дизайнерам и разработчикам приходится еще думать о том, его заставить работать. Ведь приемы и алгоритмы, применяемые для старых, однопроцессорных однопотоковых машин, как правило, не подходят.
Что самое удивительное, в университетах пока не спешат переводить программы обучения в русло параллельных вычислений! При этом сегодня нужно постараться, чтобы найти компьютер с одним ядром. В моем родном Carleton University курсы по параллельным вычислениям не входят в обязательную программу Bachelor of Computer Science, и доступны лишь для тех, кто прошел основные курсы первых трех лет. На том же уровне находятся курсы по распределенным вычислениям, и некоторых могут сбить с толку.
В чем разница? В параллельных вычислениях участвует оборудование, находящееся, как правило, в одном физическом месте, они тесно соединены между собой и все параметры их работы известны программисту. В распределенных вычислениях нет тесной постоянной связи между узлами, соответственно названию, они распределены по некоторой территории и параметры работы этой системы динамичны и не всегда известны.
Классические алгоритмы, которым обучают последние пол века, уже не подойдут для параллельных систем. Как можно догадаться, алгоритм для параллельной машины называют параллельным алгоритмом. Он зачастую сильно зависит от архитектуры конкретной машины и не так универсален, как его классический предок.
Вы можете спросить: а зачем нужно было придумывать новую структуру, потом корпеть над новыми алгоритмами, и нельзя ли было продолжать ускорять обычные компьютеры? Во-первых, пока нет возможности сделать один супер-быстрый процессор, который можно было бы сравнить с современными параллельными супер-компьютерами; а если и есть, то ресурсов на это уйдет уйма. К тому же, многие задачи хорошо решаются паралелльными машинами в первую очередь благодаря такой структуре! Расчет сложных хаотических систем вроде погоды, симуляции взаимодействий элементарных частиц в физике, моделирование на нано-уровне (да, да, нанотехнологии!), data mining (про который у нас на сайте есть блог), криптография… список можно долго продолжать.
Для программиста, как конечного “пользователя” параллельной машины, возможны два варианта: параллельность ему может быть “видна”, а может и нет. В первом случае программист пишет программы с расчетом на архитектуру компьютера, берет в расчет параметры этой конкретной машины. Во втором программист может и не знать, что перед ним не-классический компьютер, а все его классические методы умудряются работать благодаря продуманности самой системы.
Вот пример многоядерного процессора — любимый многими SUN UltraSPARC T1/T2:
8 ядер, каждое поддерживает 4 (у Т1) или 8 (у Т2) аппаратных потоков (thread), что простым умножением дает нам 32/64 (соответственно) потоков в процессоре. Теоретически это означает, что такой процессор может выполнять 32/64 задачи однопотокового процессора за то же время. Но, конечно же, много ресурсов тратится на переключение между потоками и прочую “внутреннюю кухню”.
А вот, например, знаменитые крутейшие графические юниты вроде nVidia GeForce 9600 GT, на борту которого 64 ядра.

Последние GPU имеют до тысячи ядер! О том, почему у графических юнитов так много ядер мы поговорим чуть позже. А сейчас посмотрите лучше на пример иерархии параллельности в суперкомпьютерах:

Понятно, что набрать кучу мощных компьютеров — не проблема. Проблема заставить их работать вместе, то есть соединить в быструю сеть. Часто в таких кластерах используют высокоскоростной свитч и все компьютеры просто соединяются в быструю локальную сеть. Вот такой, например, стоит в нашем университете:

256 ядер: 64 юнита, в каждом 4 ядра по 2.2 Ггц и по 8 гигабайт ОЗУ. Для соединения используется свитч Foundry SuperX и гигабитная сеть. ОС — Linux Rocks. Самым дорогим элементом часто является именно свитч: попробуйте найти быстрый свитч на 64 порта! Это пример одной из самых больших проблем параллельных компьютеров: скорость обмена информацией. Процессоры стали очень быстрыми, а память и шины все еще медленные. Не говоря уже о жестких дисках — по сравнению с процессорами они выглядят как орудия каменного века!
Классификация
Давайте наконец разберемся в типах паралельных машин. Они различаются по типу памяти — общая (shared) или распределенная (distributed), и по типу управления — SIMD и MIMD. Получается, четыре типа параллельных машин.
Общая память
Классический компьютер выглядит так:

И самый очевидный способ расширить эту схему с учетом нескольких процессоров таков:

Вместо одного процессора — несколько, памяти соответственно больше, но в целом — та же схема. Получается, все процессоры делят общую память и если процессору 2 нужна какая-то информация, над которой работает процессор 3, то он получит ее из общей памяти с той же скоростью.
Вот как выглядит построенный по такой схеме Quad Pentium:

Распределенная память
Как вы наверное и сами догадались, в этом случае у каждого процессора “своя” память (напомню, что речь идет не о внутренней памяти процессора).

Примером может служить описанный выше кластер: он по сути является кучей отдельных компьютеров, каждый из которых имеет свою память. В таком случае если процессору (или компьютеру) 2 нужна информация от компьютера 3, то это займет уже больше времени: нужно будет запросить информацию и передать ее (в случае кластера — по локальной сети). Топология сети будет влиять на скорость обмена информацией, поэтому были разработаны разные типы структур.
Самый простой вариант, который приходит на ум, это простой двумерный массив (mesh):


Похожей структурой обладает IBM Blue Gene, потомок знаменитого IBM Deep Blue, обыгравшего человека в шахматы. Похожей, потому что на самом деле Blue Gene это не куб, а тор — крайние элементы соединены:

Кстати, его назвали Gene, потому что он активно применяется в генетических исследованиях.
Другая интересная структура, которая должна была придти кому-то в голову, это любимое всеми дерево:

Так как глубина (или высота) бинарного дерева это logn, передача информации от двух наиболее удаленных узлов будет проходить расстояние 2*logn, что очень хорошо, но такая структура все равно используется не часто. Во-первых, чтобы разделить такую сеть на две изолированные подсети достаточно разрезать один провод (помните проблему min-cut?) В случае двумерного массива нужно разрезать sqrt(n) проводов! У куба посчитайте сами. А во-вторых, через корневой узел проходит слишком много трафика!
В 80е были популярны четырехмерные гиперкубы:

Это два трехмерных куба с соединенными соответственными вершинами. Строили кубы и еще большей размерности, однако сейчас почти не используются, в том числе и потому что это огромное количество проводов!
Вообще, дизайн сети для решения какой-то задачи — тема интересная. Вот, например, так называемая Omega Network:

С памятью разобрались, теперь об управлении.
SIMD vs. MIMD
SIMD — Singe Instruction stream, Multiple Data stream. Управляющий узел один, он отправляет инструкции всем остальным процессорам. Каждый процессор имеет свой набор данных для работы.
MIMD — Multiple Instruction stream, Multiple Data Stream. Каждый процессор имеет свой собственный управляющий юнит, каждый процессор может выполнять разные инструкции.
SIMD-системы обычно используются для конкретных задач, требующих, как правило, не столько гибкости и универсальности вычислительной машины, сколько самой вычислительной силы. Обработка медиа, научные исследования (те же симуляции и моделирование), или, например, трансформации Фурье гигантских матриц. Поэтому в графических юнитах такое бешенное количество ядер: это SIMD-системы, и по-настоящему “умный” процессор (такой, как в вашем компьютере) там как правило один: он управляет кучей простых и не-универсальных ядер.

Так как “управляющий” процессор отправляет одни и те же инструкции всем “рабочим” процессорам, программирование таких систем требует некоторой сноровки. Вот простой пример:
if (B == 0)
then C = A
else C = A/B
Начальное состоянии памяти процессоров такое:

Первая строчка выполнилась, данные считались, теперь запускается вторая строка: then

При этом второй и третий процессоры ничего не делают, потому что переменная B у них не подходит под условие. Соответственно, далее выполняется третья строка, и на этот раз “отдыхают” другие два процессора:

Примеры SIMD-машин это старые ILLiac IV, MPP, DAP, Connection Machine CM-1/2, современные векторные юниты, специфичные сопроцессоры и графические юниты вроде nVidia GPU.
MIMD-машины обладают более широким функционалом, поэтому в наших пользовательских компьютерах используются именно они. Если у вас хотя бы двухядерный процессор в лаптопе — вы счастливый обладатель MIMD-машины с общей памятью! MIMD распределенной памятью это суперкомпьютеры вроде IBM Blue Gene, о которых мы говорили выше, или кластеры.
Вот итог всей классификации:

На этом введение в тему можно считать завершенным. В следующий раз мы поговорим о том, как расчитываются скорости параллельных машин, напишем свою первую параллельную программу с использованием рекурсии, запустим ее в небольшом кластере и научимся анализировать ее скорость и ресурсоемкость.
Аннотация: Архитектура ВС. Классификация вычислительных систем. Пути достижения параллелизма. Параллелизм на уровне команд, потоков, приложений. Анализ эффективности параллельных вычислений. Закон Амдала.
Мотивы параллелизма
- Параллельность повышает производительность системы из-за более эффективного расходования системных ресурсов. Например, во время ожидания появления данных по сети, вычислительная система может использоваться для решения локальных задач.
- Параллельность повышает отзывчивость приложения. Если один поток занят расчетом или выполнением каких-то запросов, то другой поток может реагировать на действия пользователя.
- Параллельность облегчает реализацию многих приложений. Множество приложений типа "клиент-сервер", "производитель-потребитель" обладают внутренним параллелизмом. Последовательная реализация таких приложений более трудоемка, чем описание функциональности каждого участника по отдельности.
Классификация вычислительных систем
Одной из наиболее распространенных классификаций вычислительных систем является классификация Флинна. Четыре класса вычислительных систем выделяются в соответствие с двумя измерениями – характеристиками систем: поток команд, которые данная архитектура способна выполнить в единицу времени (одиночный или множественный) и поток данных, которые могут быть обработаны в единицу времени (одиночный или множественный).
- SISD (Single Instruction, Single Data) – системы, в которых существует одиночный поток команд и одиночный поток данных. В каждый момент времени процессор обрабатывает одиночный поток команд над одиночным потоком данных. К данному типу систем относятся последовательные персональные компьютеры с одноядерными процессорами.
- SIMD (Single Instruction, Multiple Data) – системы с одиночным потоком команд и с множественным потоком данных; подобный класс составляют многопроцессорные системы, в которых в каждый момент времени может выполняться одна и та же команда для обработки нескольких информационных элементов. Такая архитектура позволяет выполнять одну арифметическую операцию над элементами вектора. Современные компьютеры реализуют некоторые команды типа SIMD (векторные команды), позволяющие обрабатывать несколько элементов данных за один такт.
- MISD (Multiple Instructions, Single Data) – системы, в которых существует множественный поток команд и одиночный поток данных; к данному классу относят систолические вычислительные системы и конвейерные системы;
- MIMD (Multiple Instructions, Multiple Data) – системы с множественным потоком команд и множественных потоком данных; к данному классу относится большинство параллельных вычислительных систем.
Классификация Флинна относит почти все параллельные вычислительные системы к одному классу – MIMD . Для выделения разных типов параллельных вычислительных систем применяется классификация Джонсона, в которой дальнейшее разделение многопроцессорных систем основывается на используемых способах организации оперативной памяти в этих системах. Данный подход позволяет различать два важных типа многопроцессорных систем: multiprocessors (мультипроцессорные или системы с общей разделяемой памятью) и multicomputers (мультикомпьютеры или системы с распределенной памятью).

Архитектура однопроцессорной машины
Современная однопроцессорная машина состоит из нескольких компонентов: центрального процессорного устройства (ЦПУ), первичной памяти, одного или нескольких уровней кэш -памяти ( кэш ), вторичной (дисковой) памяти и набора периферийных устройств ( дисплей , клавиатура, мышь , модем , CD, принтер и т.д.). Основными компонентами для выполнения программ являются ЦПУ, кэш и память .

Процессор выбирает инструкции из памяти, декодирует их и выполняет. Он содержит управляющее устройство (УУ), арифметико-логическое устройство ( АЛУ ) и регистры. УУ вырабатывает сигналы, управляющие действиями АЛУ , системой памяти и внешними устройствами. АЛУ выполняет арифметические и логические инструкции, определяемые набором инструкций процессора. В регистрах хранятся инструкции, данные и состояние машины (включая счетчик команд ).
Мультикомпьютеры с распределенной памятью

Мультикомпьютер (многомашинная система) – мультипроцессор с распределенной памятью, в котором процессоры и сеть расположены физически близко (в одном помещении). Также называют тесно связанной машинной. Она одновременно используется одним или небольшим числом приложений; каждое приложение задействует выделенный набор процессоров. Соединительная сеть с большой пропускной способностью предоставляет высокоскоростной путь связи между процессорами.
Мультипроцессор с разделяемой памятью
В мультипроцессоре и в многоядерной системе исполнительные устройства (процессоры и ядра процессоров) имеют доступ к разделяемой оперативной памяти. Процессоры совместно используют оперативную память .

У каждого процессора есть собственный кэш . Если два процессора ссылаются на разные области памяти, их содержимое можно безопасно поместить в кэш каждого из них. Проблема возникает, когда два процессора обращаются к одной области памяти. Если оба процессора только считывают данные, в кэш каждого из них можно поместить копию данных. Но если один из процессоров записывает в память , возникает проблема согласованности кэша: в кэш -памяти другого процессора теперь содержатся неверные данные. Необходимо либо обновить кэш другого процессора, либо признать содержимое кэша недействительным. Обеспечение однозначности кэшей реализуется на аппаратном уровне – для этого после изменения значения общей переменной все копии этой переменной в кэшах отмечаются как недействительные и последующий доступ к переменной потребует обязательного обращения к основной памяти. Необходимость обеспечения когерентности приводит к некоторому снижению скорости вычислений и затрудняет создание систем с достаточно большим количеством процессоров.
Наличие общих данных при выполнении параллельных вычислений приводит к необходимости синхронизации взаимодействия одновременно выполняемых потоков команд. Так, например, если изменение общих данных требует для своего выполнения некоторой последовательности действий, то необходимо обеспечить взаимоисключение с тем, чтобы эти изменения в любой момент времени мог выполнять только один командный поток . Задачи взаимоисключения и синхронизации относятся к числу классических проблем, и их рассмотрение при разработке параллельных программ является одним из основных вопросов параллельного программирования.
Режимы выполнения независимых частей программы
При рассмотрении проблемы организации параллельных вычислений следует различать следующие возможные режимы выполнения независимых частей программы:
1) Режим разделения времени (многозадачный режим)
Режим разделения времени предполагает, что число подзадач (процессов или потоков одного процесса) больше, чем число исполнительных устройств. Данный режим является псевдопараллельным, когда активным (исполняемым) может быть одна единственнаяподзадача, а все остальные процессы (потоки) находятся в состоянии ожидания своей очереди на использование процессора; использование режима разделения времени может повысить эффективность организации вычислений (например, если один из процессов не может выполняться из-за ожидания вводимых данных, процессор может быть задействован для выполнения другого, готового к исполнению процесса), кроме того в данном режиме проявляются многие эффекты параллельных вычислений (необходимость взаимоисключения и синхронизации процессов и др.).
Многопоточность приложений в операционных системах с разделением времени применяется даже в однопроцессорных системах. Например, в Windows-приложениях многопоточность повышает отзывчивость приложения – если основной поток занят выполнением каких-то расчетов или запросов, другой поток позволяет реагировать на действия пользователя. Многопоточность упрощает разработку приложения. Каждый поток может планироваться и выполняться независимо. Например, когда пользователь нажимает кнопку мышки персонального компьютера, посылается сигнал процессу, управляющему окном, в котором в данный момент находится курсор мыши. Этот процесс ( поток ) может выполняться и отвечать на щелчок мыши. Приложения в других окнах могут продолжать при этом свое выполнение в фоновом режиме.
2) Распределенные вычисления
Такие системы пишутся для распределения обработки (как в файловых серверах), обеспечения доступа к удаленным данным (как в базах данных и в Web ), интеграции и управления данными, распределенными по своей сути (как в промышленных системах), или повышения надежности (как в отказоустойчивых системах). Многие распределенные системы организованы как системы типа клиент- сервер . Например, файловый сервер предоставляет файлы данных для процессов, выполняемых на клиентских машинах. Компоненты распределенных систем часто сами являются многопоточными.
3) Синхронные параллельные вычисления.
Их цель – быстро решать данную задачу или за то же время решить большую задачу. Примеры синхронных вычислений:
- научные вычисления, которые моделируют и имитируют такие явления, как глобальный климат, эволюция солнечной системы или результат действия нового лекарства;
- графика и обработка изображений, включая создание спецэффектов в кино;
- крупные комбинаторные или оптимизационные задачи, например, планирование авиаперелетов или экономическое моделирование.
Программы решения таких задач требуют эффективного использования доступных вычислительных ресурсов системы. Число подзадач должно быть оптимизировано с учетом числа исполнительных устройств в системе (процессоров, ядер процессоров).
Уровни параллелизма в многоядерных архитектурах
Параллелизм на уровне команд (InstructionLevelParallelism, ILP ) позволяет процессору выполнять несколько команд за один такт. Зависимости между командами ограничивают количество доступных для выполнения команд, снижая объем параллельных вычислений. Технология ILP позволяет процессору переупорядочить команды оптимальным образом с целью исключить остановки вычислительного конвейера и увеличить количество команд, выполняемых процессором за один такт. Современные процессоры поддерживают определенный набор команд, которые могут выполняться параллельно.
Параллелизм на уровне потоков процесса. Потоки позволяют выделить независимые потоки исполнения команд в рамках одного процесса. Потоки поддерживаются на уровне операционной системы. Операционная система распределяет потоки процессов по ядрам процессора с учетом приоритетов. С помощью потоков приложение может максимально задействовать свободные вычислительные ресурсы.
Параллелизм на уровне приложений.Одновременное выполнение нескольких программ осуществляется во всех операционных системах, поддерживающих режим разделения времени . Даже на однопроцессорной системе независимые программы выполняются одновременно. Параллельность достигается за счет выделение каждому приложению кванта процессорного времени.
Анализ эффективности параллельных вычислений
Анализ эффективности параллельных вычислений

Эффективность параллельного алгоритма определяется следующим образом:

Эффективность показывает, насколько задействованы вычислительные ресурсы системы; идеальное теоретическое значение эффективности равно единице.
Пределы параллелизма
Достижению максимального ускорения может препятствовать существование в выполняемых вычислениях последовательных расчетов, которые не могут быть распараллелены. Джин Амдал (GeneAmdahl)показал, что верхняя граница для ускорения определяется долей последовательных вычислений алгоритма:

– доля последовательных вычислений в применяемом алгоритме обработки данных, – число процессоров.
Например, если доля последовательных вычислений составляет 25%, то максимально достижимое ускорение для параллельного алгоритма равно:

В "законе Амдала"имеется несколько допущений, которые в реальных приложениях могут быть неверными. Одно из допущений заключается в том, что доля последовательных расчетов является постоянной величиной и не зависит от вычислительной сложности решаемой задачи. Однако, для большинства задач является убывающей функцией от , где –параметр сложности задачи.В этом случае ускорение может быть увеличено при увеличении вычислительной сложности задачи. Нарушение "закона Амдала" также может быть связано с архитектурными особенностями параллельной вычислительной системы. Например, параллельный алгоритм уменьшает объем данных, используемых каждым процессором, и повышает эффективность использования кэш -памяти каждого процессора. Оптимальная работа с кэш -памятью может сильно увеличить быстродействие алгоритма.
Параллельный алгоритм называется масштабируемым, если при росте числа процессоров он обеспечивает увеличение ускорения при сохранении постоянного уровня эффективности использования процессоров.
Аннотация: В рамках данной лекции будут рассмотрены следующие вопросы: определение, назначение параллельного программирования; многоядерные вычисления; множественные потоки команд/данных; ускорение; закон Амадал; закон Густафсона-Барсиса.
Определение, назначение параллельного программирования
Существуют различные способы написания программ, которые условно можно разделить на три группы:
- Последовательное программирование с дальнейшим автоматическим распараллеливанием.
- Непосредственное формирование потоков параллельного управления, с учетом особенностей архитектур параллельных вычислительных систем или операционных систем.
- Описание параллелизма без использования явного управления обеспечивается заданием только информационных связей. Предполагается, что программа будет выполняться на вычислительных системах с бесконечными ресурсами, операторы будут запускаться немедленно по готовности их исходных данных.
Каждый из перечисленных подходов обладает своими достоинствами и недостатками параллельное программирование .
Параллельные вычисления - способ организации компьютерных вычислений, при котором программы разрабатываются, как набор взаимодействующих вычислительных процессов, работающих асинхронно и при этом одновременно.
Параллельное программирование - это техника программирования, которая использует преимущества многоядерных или многопроцессорных компьютеров и является подмножеством более широкого понятия многопоточности ( multithreading ).
Многоядерные вычисления
Использование параллельного программирования становится наиболее необходимым, поскольку позволяет максимально эффективно использовать возможности многоядерных процессоров и многопроцессорных систем. По ряду причин, включая повышение потребления энергии и ограничения пропускной способности памяти, увеличивать тактовую частоту современных процессоров стало невозможно. Вместо этого производители процессоров стали увеличивать их производительность за счет размещения в одном чипе нескольких вычислительных ядер, не меняя или даже снижая тактовую частоту. Поэтому для увеличения скорости работы приложений теперь следует по -новому подходить к организации кода, а именно - оптимизировать программы под многоядерные системы.
Множественные потоки команд/данных (Классификация М.Флинна)
Самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD , MISD , SIMD , MIMD . Описание классов приведено в Табл. 1.1.
На основании Табл. 1.1 можно проранжировать архитектуры на однопоточность/многопоточность (Табл. 1.2).
Ускорение (Speedup)
Ускорением параллельного алгоритма называется отношение :

где - время вычисления задачи на n процессорах, - время выполнения однопоточной программы

, если параллельная версия алгоритма эффективна.

, если накладные расходы (издержки) реализации параллельной версии алгоритма чрезмерно велики.
С ускорением связана эффективность параллельного алгоритма. Эффективностью параллельного алгоритма называется величина:

По определению, . Теоретически должно быть и . Если алгоритм достигает максимального ускорения , то . На практике эффективность убывает при увеличении числа процессоров.

(суперлинейное ускорение). Эта аномалия вызвана, чаще всего, двумя причинами:
- В качестве последовательного алгоритма был применён не самый быстрый алгоритм из существующих.
- С увеличением количества вычислителей растёт суммарный объём их оперативной и кэш памяти. Поэтому всё большая часть данных задачи умещается в оперативной памяти и не требует подкачки с диска, или (чаще всего) умещается в кэше.
Закон Амдала
Закон Амдала (1967 год), описывает максимальный теоретический выигрыш в производительности параллельного решения по отношению к лучшему последовательному решению. Закон Амдала описывается следующей математической формулой:

где - во сколько раз можно ускорить вычисления (ускорение), n - количество процессоров (ядер), - доля последовательно вычисляемого кода ().
Закон Амдаля, несмотря на то, что он не учитывает многих факторов, накладывает ограничения на максимально достижимую эффективность параллельного алгоритма.
Предположим, например, что " />
, то есть две трети операций в алгоритме могут выполняться параллельно, а треть - нет. Тогда ускоре-ние . Таким образом, независимо от количества процессоров (ядер) и даже при игнорировании всех затрат на подготовку данных нельзя ускорить решение задачи более, чем в три раза.
Закон Густафсона-Барсиса
Закон Густафсона - Барсиса (1988г) оценивает максимально допустимое ускорение выполнения параллельной программы, в зависимости от количества одновременно выполняемых потоков вычислений и доли последовательных расчётов. Формула Густафсона - Барсиса выглядит следующим образом:

Где - доля последовательных расчётов в программе, - количество процессоров.
Густафсон заметил, что, работая на многопроцессорных системах, пользователи склонны к изменению тактики решения задачи. Теперь снижение общего времени исполнения программы уступает объёму решаемой задачи. Такое изменение цели обусловливает переход от закона Амдала к закону Густафсона. К примеру, на 100 процессорах программа выполняется 20 минут. При переходе на систему с 1000 процессорами можно достичь времени исполнения порядка двух минут. Однако для получения большей точности решения имеет смысл увеличить объём решаемой задачи, т.е. при сохранении общего времени исполнения пользователи стремятся получить более точный результат. Увеличение объёма решаемой задачи приводит к увеличению доли параллельной части, так как последовательная часть ( ввод/вывод , менеджмент потоков, точки синхронизации и т.п.) не изменяется.
Читайте также: