
Могут ли два процесса в ос unix одновременно держать открытым один и тот же файл
Предположим, что один из файлов в ОС Unix жестко связан с двумя различными каталогами, принадлежащими различным пользователям. Что произойдет, если один из пользователей удалит файл?
Сколько процессов могут одновременно использовать одно и то же средство связи, пользуясь симметричной прямой адресацией?
Известно, что для организации списка прав доступа (ACL) к файлу требуется перечислить всех пользователей, которые могут иметь доступ к нему, и допустимые операции над этим файлом. Какой объем дисковой памяти использует ОС Unix для хранения списка прав доступа?
При модернизации некоторой операционной системы, поддерживающей только три состояния процессов: готовность, исполнение, ожидание, решено ввести два новых системных вызова. Один из этих вызовов позволяет любому процессу приостановить жизнедеятельность любого другого процесса (кроме самого себя), до тех пор, пока какой-либо процесс не выполнит второй системный вызов. Сколько новых операций над процессами появится в системе?
При модернизации некоторой операционной системы, поддерживающей только три состояния процессов: готовность, исполнение, ожидание, принято решение ввести два новых системных вызова. Один из этих вызовов позволяет любому процессу приостановить жизнедеятельность любого другого процесса (кроме самого себя), до тех пор, пока какой-либо процесс не выполнит второй системный вызов. Сколько новых состояний процессов появится в системе?
При модернизации некоторой операционной системы, поддерживающей только три состояния процессов: готовность, исполнение, ожидание, решено ввести два новых системных вызова. Один из этих вызовов позволяет любому процессу приостановить жизнедеятельность любого другого процесса (кроме самого себя), до тех пор, пока какой-либо процесс не выполнит второй системный вызов. Сколько новых переходов из состояния исполнение появится в системе?
Для некоторого процесса известна следующая строка запросов страниц памяти
Сколько ситуаций отказа страницы (page fault) возникнет для данного процесса при использовании алгоритма замещения страниц LRU (the Least Recently Used) и трех страничных кадрах?
Для некоторого процесса известна следующая строка запросов страниц памяти
Сколько ситуаций отказа страницы (page fault) возникнет для данного процесса при использовании алгоритма замещения страниц OPT (оптимальный алгоритм) и трех страничных кадрах?
Для некоторого процесса известна следующая строка запросов страниц памяти
Сколько ситуаций отказа страницы (page fault) возникнет для данного процесса при использовании алгоритма замещения страниц FIFO (First Input First Output) и трех страничных кадрах?
Когда различные пользователи работают вместе над проектом, они часто нуждаются в разделении файлов.
Разделяемый файл - разделяемый ресурс . Как и в случае любого совместно используемого ресурса, процессы должны синхронизировать доступ к совместно используемым файлам, каталогам, чтобы избежать тупиковых ситуаций, дискриминации отдельных процессов и снижения производительности системы.
Например, если несколько пользователей одновременно редактируют какой-либо файл и не принято специальных мер, то результат будет непредсказуем и зависит от того, в каком порядке осуществлялись записи в файл . Между двумя операциями read одного процесса другой процесс может модифицировать данные, что для многих приложений неприемлемо. Простейшее решение данной проблемы - предоставить возможность одному из процессов захватить файл , то есть блокировать доступ к разделяемому файлу других процессов на все время, пока файл остается открытым для данного процесса. Однако это было бы недостаточно гибко и не соответствовало бы характеру поставленной задачи.
Рассмотрим вначале грубый подход, то есть временный захват пользовательским процессом файла или записи (части файла между указанными позициями).
Системный вызов , позволяющий установить и проверить блокировки на файл , является неотъемлемым атрибутом современных многопользовательских ОС. В принципе, было бы логично связать синхронизацию доступа к файлу как к единому целому с системным вызовом open (т. е., например, открытие файла в режиме записи или обновления могло бы означать его монопольную блокировку соответствующим процессом, а открытие в режиме чтения - совместную блокировку). Так поступают во многих операционных системах (начиная с ОС Multics ). В ОС Unix это не так, что имеет исторические причины.
В первой версии системы Unix, разработанной Томпсоном и Ричи, механизм захвата файла отсутствовал. Применялся очень простой подход к обеспечению параллельного (от нескольких процессов) доступа к файлам: система позволяла любому числу процессов одновременно открывать один и тот же файл в любом режиме (чтения, записи или обновления) и не предпринимала никаких синхронизационных действий. Вся ответственность за корректность совместной обработки файла ложилась на использующие его процессы, и система даже не предоставляла каких-либо особых средств для синхронизации доступа процессов к файлу. Однако впоследствии для того, чтобы повысить привлекательность системы для коммерческих пользователей, работающих с базами данных, в версию V системы были включены механизмы захвата файла и записи, базирующиеся на системном вызове fcntl .
Допускается два варианта синхронизации: с ожиданием, когда требование блокировки может привести к откладыванию процесса до того момента, когда это требование может быть удовлетворено, и без ожидания, когда процесс немедленно оповещается об удовлетворении требования блокировки или о невозможности ее удовлетворения в данный момент.
Установленные блокировки относятся только к тому процессу, который их установил, и не наследуются процессами-потомками этого процесса. Более того, даже если некоторый процесс пользуется синхронизационными возможностями системного вызова fcntl , другие процессы по-прежнему могут работать с тем файлом без всякой синхронизации. Другими словами, это дело группы процессов, совместно использующих файл , - договориться о способе синхронизации параллельного доступа.
Более тонкий подход заключается в прозрачной для пользователя блокировке отдельных структур ядра, отвечающих за работу с файлами части пользовательских данных. Например, в ОС Unix во время системного вызова, осуществляющего ту или иную операцию с файлом, как правило, происходит блокирование индексного узла , содержащего адреса блоков данных файла. Может показаться, что организация блокировок или запрета более чем одному процессу работать с файлом во время выполнения системного вызова является излишней, так как в подавляющем большинстве случаев выполнение системных вызовов и так не прерывается, то есть ядро работает в условиях невытесняющей многозадачности. Однако в данном случае это не совсем так. Операции чтения и записи занимают продолжительное время и лишь инициируются центральным процессором, а осуществляются по независимым каналам, поэтому установка блокировок на время системного вызова является необходимой гарантией атомарности операций чтения и записи. На практике оказывается достаточным заблокировать один из буферов кэша диска, в заголовке которого ведется список процессов, ожидающих освобождения данного буфера. Таким образом, в соответствии с семантикой Unix изменения, сделанные одним пользователем, немедленно становятся "видны" другому пользователю, который держит данный файл открытым одновременно с первым.
Примеры разрешения коллизий и тупиковых ситуаций
Логика работы системы в сложных ситуациях может проиллюстрировать особенности организации мультидоступа.
Рассмотрим в качестве примера образование потенциального тупика при создании связи ( link ), когда разрешен совместный доступ к файлу [Bach, 1986].
Два процесса, выполняющие одновременно следующие функции:
могут зайти в тупик. Предположим, что процесс A обнаружил индекс файла "a/b/c/d" в тот самый момент, когда процесс B обнаружил индекс файла "e/f" . Фраза "в тот же самый момент" означает, что системой достигнуто состояние, при котором каждый процесс получил искомый индекс. Когда же теперь процесс A попытается получить индекс файла "e/f" , он приостановит свое выполнение до тех пор, пока индекс файла "f" не освободится. В то же время процесс B пытается получить индекс каталога "a/b/c/d" и приостанавливается в ожидании освобождения индекса файла "d" . Процесс A будет удерживать заблокированным индекс, нужный процессу B, а процесс B, в свою очередь, будет удерживать заблокированным индекс, необходимый процессу A.
Для предотвращения этого классического примера взаимной блокировки в файловой системе принято, чтобы ядро освобождало индекс исходного файла после увеличения значения счетчика связей . Тогда, поскольку первый из ресурсов (индекс) свободен при обращении к следующему ресурсу, взаимной блокировки не происходит.
Поводов для нежелательной конкуренции между процессами много, особенно при удалении имен каталогов. Предположим, что один процесс пытается найти данные файла по его полному символическому имени, последовательно проходя компонент за компонентом, а другой процесс удаляет каталог, имя которого входит в путь поиска. Допустим, процесс A делает разбор имени "a/b/c/d" и приостанавливается во время получения индексного узла для файла "c" . Он может приостановиться при попытке заблокировать индексный узел или при попытке обратиться к дисковому блоку, где этот индексный узел хранится. Если процессу B нужно удалить связь для каталога с именем "c" , он может приостановиться по той же самой причине, что и процесс A. Пусть ядро впоследствии решит возобновить процесс B раньше процесса A. Прежде чем процесс A продолжит свое выполнение, процесс B завершится, удалив связь каталога "c" и его содержимое по этой связи . Позднее процесс A попытается обратиться к несуществующему индексному узлу , который уже был удален. Алгоритм поиска файла, проверяющий в первую очередь неравенство значения счетчика связей нулю, должен сообщить об ошибке.
Можно привести и другие примеры, которые демонстрируют необходимость тщательного проектирования файловой системы для ее последующей надежной работы.
Когда различные пользователи работают вместе над проектом, они часто нуждаются в разделении файлов.
Разделяемый файл - разделяемый ресурс . Как и в случае любого совместно используемого ресурса, процессы должны синхронизировать доступ к совместно используемым файлам, каталогам, чтобы избежать тупиковых ситуаций, дискриминации отдельных процессов и снижения производительности системы.
Например, если несколько пользователей одновременно редактируют какой-либо файл и не принято специальных мер, то результат будет непредсказуем и зависит от того, в каком порядке осуществлялись записи в файл . Между двумя операциями read одного процесса другой процесс может модифицировать данные, что для многих приложений неприемлемо. Простейшее решение данной проблемы - предоставить возможность одному из процессов захватить файл , то есть блокировать доступ к разделяемому файлу других процессов на все время, пока файл остается открытым для данного процесса. Однако это было бы недостаточно гибко и не соответствовало бы характеру поставленной задачи.
Рассмотрим вначале грубый подход, то есть временный захват пользовательским процессом файла или записи (части файла между указанными позициями).
Системный вызов , позволяющий установить и проверить блокировки на файл , является неотъемлемым атрибутом современных многопользовательских ОС. В принципе, было бы логично связать синхронизацию доступа к файлу как к единому целому с системным вызовом open (т. е., например, открытие файла в режиме записи или обновления могло бы означать его монопольную блокировку соответствующим процессом, а открытие в режиме чтения - совместную блокировку). Так поступают во многих операционных системах (начиная с ОС Multics ). В ОС Unix это не так, что имеет исторические причины.
В первой версии системы Unix, разработанной Томпсоном и Ричи, механизм захвата файла отсутствовал. Применялся очень простой подход к обеспечению параллельного (от нескольких процессов) доступа к файлам: система позволяла любому числу процессов одновременно открывать один и тот же файл в любом режиме (чтения, записи или обновления) и не предпринимала никаких синхронизационных действий. Вся ответственность за корректность совместной обработки файла ложилась на использующие его процессы, и система даже не предоставляла каких-либо особых средств для синхронизации доступа процессов к файлу. Однако впоследствии для того, чтобы повысить привлекательность системы для коммерческих пользователей, работающих с базами данных, в версию V системы были включены механизмы захвата файла и записи, базирующиеся на системном вызове fcntl .
Допускается два варианта синхронизации: с ожиданием, когда требование блокировки может привести к откладыванию процесса до того момента, когда это требование может быть удовлетворено, и без ожидания, когда процесс немедленно оповещается об удовлетворении требования блокировки или о невозможности ее удовлетворения в данный момент.
Установленные блокировки относятся только к тому процессу, который их установил, и не наследуются процессами-потомками этого процесса. Более того, даже если некоторый процесс пользуется синхронизационными возможностями системного вызова fcntl , другие процессы по-прежнему могут работать с тем файлом без всякой синхронизации. Другими словами, это дело группы процессов, совместно использующих файл , - договориться о способе синхронизации параллельного доступа.
Более тонкий подход заключается в прозрачной для пользователя блокировке отдельных структур ядра, отвечающих за работу с файлами части пользовательских данных. Например, в ОС Unix во время системного вызова, осуществляющего ту или иную операцию с файлом, как правило, происходит блокирование индексного узла , содержащего адреса блоков данных файла. Может показаться, что организация блокировок или запрета более чем одному процессу работать с файлом во время выполнения системного вызова является излишней, так как в подавляющем большинстве случаев выполнение системных вызовов и так не прерывается, то есть ядро работает в условиях невытесняющей многозадачности. Однако в данном случае это не совсем так. Операции чтения и записи занимают продолжительное время и лишь инициируются центральным процессором, а осуществляются по независимым каналам, поэтому установка блокировок на время системного вызова является необходимой гарантией атомарности операций чтения и записи. На практике оказывается достаточным заблокировать один из буферов кэша диска, в заголовке которого ведется список процессов, ожидающих освобождения данного буфера. Таким образом, в соответствии с семантикой Unix изменения, сделанные одним пользователем, немедленно становятся "видны" другому пользователю, который держит данный файл открытым одновременно с первым.
Примеры разрешения коллизий и тупиковых ситуаций
Логика работы системы в сложных ситуациях может проиллюстрировать особенности организации мультидоступа.
Рассмотрим в качестве примера образование потенциального тупика при создании связи ( link ), когда разрешен совместный доступ к файлу [Bach, 1986].
Два процесса, выполняющие одновременно следующие функции:
могут зайти в тупик. Предположим, что процесс A обнаружил индекс файла "a/b/c/d" в тот самый момент, когда процесс B обнаружил индекс файла "e/f" . Фраза "в тот же самый момент" означает, что системой достигнуто состояние, при котором каждый процесс получил искомый индекс. Когда же теперь процесс A попытается получить индекс файла "e/f" , он приостановит свое выполнение до тех пор, пока индекс файла "f" не освободится. В то же время процесс B пытается получить индекс каталога "a/b/c/d" и приостанавливается в ожидании освобождения индекса файла "d" . Процесс A будет удерживать заблокированным индекс, нужный процессу B, а процесс B, в свою очередь, будет удерживать заблокированным индекс, необходимый процессу A.
Для предотвращения этого классического примера взаимной блокировки в файловой системе принято, чтобы ядро освобождало индекс исходного файла после увеличения значения счетчика связей . Тогда, поскольку первый из ресурсов (индекс) свободен при обращении к следующему ресурсу, взаимной блокировки не происходит.
Поводов для нежелательной конкуренции между процессами много, особенно при удалении имен каталогов. Предположим, что один процесс пытается найти данные файла по его полному символическому имени, последовательно проходя компонент за компонентом, а другой процесс удаляет каталог, имя которого входит в путь поиска. Допустим, процесс A делает разбор имени "a/b/c/d" и приостанавливается во время получения индексного узла для файла "c" . Он может приостановиться при попытке заблокировать индексный узел или при попытке обратиться к дисковому блоку, где этот индексный узел хранится. Если процессу B нужно удалить связь для каталога с именем "c" , он может приостановиться по той же самой причине, что и процесс A. Пусть ядро впоследствии решит возобновить процесс B раньше процесса A. Прежде чем процесс A продолжит свое выполнение, процесс B завершится, удалив связь каталога "c" и его содержимое по этой связи . Позднее процесс A попытается обратиться к несуществующему индексному узлу , который уже был удален. Алгоритм поиска файла, проверяющий в первую очередь неравенство значения счетчика связей нулю, должен сообщить об ошибке.
Можно привести и другие примеры, которые демонстрируют необходимость тщательного проектирования файловой системы для ее последующей надежной работы.
Создать процесс – это, прежде всего, создать описатель процесса: несколько информационных структур, содержащих все сведения (атрибуты) о процессе, необходимые операционной системе для управления им. В число таких сведений могут входить: идентификатор процесса, данные о расположении в памяти исполняемого модуля, степень привилегированности процесса (приоритет и права доступа) и т.п.
Примерами таких описателей процесса являются [10, 17]:
- блок управления задачей (ТСВ – Task Control Block ) в OS/360;
- управляющий блок процесса ( PCB – Process Control Block) в OS/2;
- дескриптор процесса в UNIX;
- объект-процесс (object-process) в Windows NT/2000/2003.
Создание процесса включает загрузку кодов и данных исполняемой программы данного процесса с диска в операционную память . Для этого нужно найти эту программу на диске, перераспределить оперативную память и выделить память исполняемой программе нового процесса. Кроме того, при работе программы обычно используется стек , с помощью которого реализуются вызовы процедур и передача параметров .
Множество, в которое входят программа , данные, стеки и атрибуты процесса, называется образом процесса.
Типичные элементы образа процесса приведены ниже.
Местонахождение образа процесса зависит от используемой схемы управления памятью. В большинстве современных ОС с виртуальной памятью образ процесса состоит из набора блоков ( сегменты , страницы или их комбинация), не обязательно расположенных последовательно. Такая организация памяти позволяет иметь в основной памяти лишь часть образа процесса (активная часть), в то время как во вторичной памяти находится полный образ. Когда в основную память загружается часть образа, она туда не переносится, а копируется. Однако если часть образа в основной памяти модифицируется, она должна быть скопирована на диск .
При управлении процессами ОС использует два основных типа информационных структур: блок управления процессом ( дескриптор процесса) и контекст процесса. Дескрипторы процессов объединяются в таблицу процессов, которая размещается в области ядра. На основании информации, содержащейся в таблице процессов, ОС осуществляет планирование и синхронизацию процессов.
В дескрипторе ( блоке управления) процесса содержится такая информация о процессе, которая необходима ядру в течение всего жизненного цикла процесса независимо от того, находится он в активном или пассивном состоянии и находится ли образ в оперативной памяти или на диске. Эту информацию можно разделить на три категории:
- информация по идентификации процесса;
- информация по состоянию процесса;
- информация, используемая при управлении процессом.
Информация по состоянию и управлению процессом включает следующие основные данные:
Контекст процесса содержит информацию, позволяющую системе приостанавливать и возобновлять выполнение процесса с прерванного места.
В контексте процесса содержится следующая основная информация [10]:
- содержимое регистров процессора, доступных пользователю;
- содержимое счетчика команд;
- состояние управляющих регистров и регистров состояния;
- коды условий, отражающие результат выполнения последней арифметической или логической операции (например, знак равенства нулю, переполнения);
- указатели вершин стеков, хранящие параметры и адреса вызова процедур и системных служб.
Следует заметить, что часть этой информации, известная как " слово состояния программы" (Program Status Word – PSW ), фиксируется в специальном регистре процессора (например, в регистре EFLAGS в процессорах Pentium).
Самую простую модель процесса можно построить исходя из того, что в любой момент времени процесс либо выполняется, либо не выполняется, т.е. имеет только два состояния. Если бы все процессы были бы всегда готовы к выполнению, то очередь по этой схеме могла бы работать вполне эффективно. Такая очередь работает по принципу обработки в порядке поступления, а процессор обслуживает имеющиеся в наличии процессы круговым методом ( Round-robin ). Каждому процессу отводится определенный промежуток времени, по истечении которого он возвращается в очередь .
Однако в таком простом примере подобная реализация не является адекватной: часть процессов готова к выполнению, а часть заблокирована, например, по причине ожидания ввода-вывода. Поэтому при наличии одной очереди диспетчер не может просто выбрать для выполнения первый процесс из очереди. Перед этим он должен будет просматривать весь список , отыскивая незаблокированный процесс, который находится в очереди дальше других. Отсюда представляется естественным разделить все невыполняющиеся процессы на два типа: готовые к выполнению и заблокированные. Полезно добавить еще два состояния, как показано на рис. 5.6.
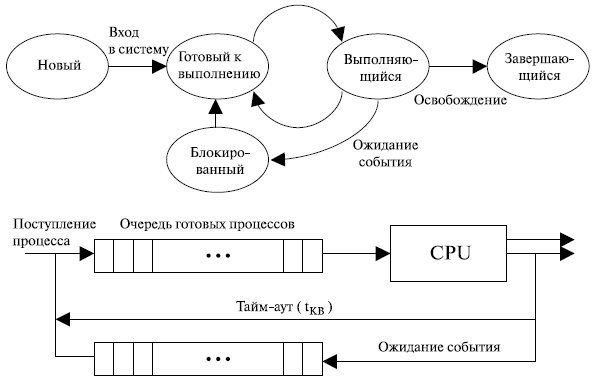
В чем достоинства и недостатки такой модели и как устранить эти недостатки? Поскольку процессор работает намного быстрее выполнения операций ввода-вывода, то вскоре все находящиеся в памяти процессы оказываются в состоянии ожидания ввода-вывода. Таким образом, процессор может простаивать даже в многозадачной системе. Что делать? Можно увеличить емкость основной памяти, чтобы в ней умещалось больше процессов.
Но такой подход имеет два недостатка: во-первых, возрастает стоимость памяти, а во-вторых, "аппетит" программиста в использовании памяти возрастает пропорционально ее объему, так что увеличение объема памяти приводит к увеличению размера процессов, а не к росту их числа. Другое решение проблемы – свопинг , перенос части процессов из оперативной памяти на диск и загрузка другого процесса из очереди приостановленных (но не блокированных!) процессов , находящихся во внешней памяти. На этом мы прервем рассмотрение модели процессов и их выполнения. Как уже отмечалось, более эффективными являются многопоточные системы . В таких системах при создании процесса ОС создается для каждого процесса минимум один поток выполнения.
При создании потоков, так же как и при создании процессов, ОС генерирует специальную информационную структуру – описатель потока, который содержит идентификатор потока, данные о правах доступа и приоритете, о состоянии потока и другую информацию. Описатель потока можно разделить на две части: атрибуты блока управления и контекст потока. Заметим, что в случае многопоточной системы процессы контекста не имеют, так как им не выделяется процессор .
Есть два способа реализации пакета потоков [17]:
- в пространстве пользователя или на уровне пользователя (User-level threads – ULT);
- в ядре или на уровне ядра (kernel-level threads – KLT).
Рассмотрим эти способы, их преимущества и недостатки.
В программе, полностью состоящей из ULT-потоков, все действия по управлению потоками выполняются самим приложением. Ядро о потоках ничего не знает и управляет обычными однопоточными процессами (рис. 5.7).
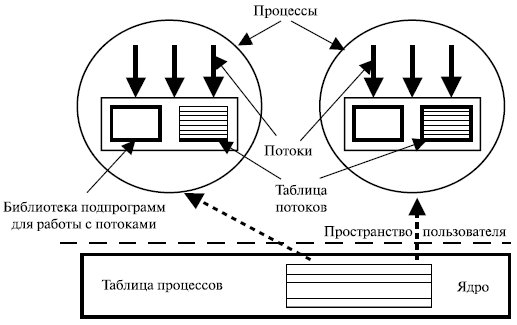
Наиболее явное преимущество этого подхода состоит в том, что пакет потоков на уровне пользователя можно реализовать даже в ОС, не поддерживающей потоки.
Если управление потоками происходит в пространстве пользователя, каждому процессу необходима собственная таблица потоков. Она аналогична таблице процессов с той лишь разницей, что отслеживает такие характеристики потоков, как счетчик команд, указатель вершины стека, регистры состояния и т. п. Когда поток переходит в состояние готовности или блокировки, вся информация , необходимая для повторного запуска, хранится в таблице потоков.
По умолчанию приложение в начале своей работы состоит из одного потока и его выполнение начинается как выполнение этого потока. Такое приложение вместе с составляющим его потоком размещается в одном процессе, который управляется ядром. Выполняющийся поток может породить новый поток , который будет выполняться в пределах того же процесса. Новый поток создается с помощью вызова специальной подпрограммы из библиотеки, предназначенной для работы с потоками. Передача управления этой программе происходит в результате вызова соответствующей процедуры.
Таких процедур может быть по крайней мере четыре: thread-create, thread-exit, thread-wait и thread- yield , но обычно их больше. Библиотека подпрограмм для работы с потоками создает структуру данных для нового потока, а потом передает управление одному из готовых к выполнению потоков данного процесса, руководствуясь некоторым алгоритмом планирования. Когда управление переходит к библиотечной программе, контекст текущего процесса сохраняется в таблице потоков, а когда управление возвращается к потоку, его контекст восстанавливается. Все эти события происходят в пользовательском пространстве в рамках одного процесса. Ядро даже "не подозревает" об этой деятельности и продолжает осуществлять планирование процесса как единого целого и приписывать ему единое состояние выполнения.
Использование потоков на уровне пользователя имеет следующие преимущества [17]:
- высокая производительность, поскольку для управления потоками процессу не нужно переключаться в режим ядра и обратно. Процедура, сохраняющая информацию о потоке, и планировщики являются локальными процедурами, их вызов существенно более эффективен, чем вызов ядра;
- имеется возможность использования различных алгоритмов планирования потоков в различных приложениях (процессах) с учетом их специфики;
- использование потоков на пользовательском уровне применимо для любой операционной системы. Для их поддержки в ядро системы не требуется вносить каких-либо изменений.
Однако имеются и недостатки по сравнению с использованием потоков на уровне ядра:
- в типичной ОС многие системные вызовы являются блокирующими. Когда в потоке, работающем на пользовательском уровне, выполняется системный вызов, блокируется не только этот поток, но и все потоки того процесса, к которому он относится;
- в стратегии с наличием потоков только на пользовательском уровне приложение не может воспользоваться преимуществом многопроцессорной системы, так как ядро закрепляет за каждым процессом только один процессор. Поэтому несколько потоков одного и того же процесса не могут выполняться одновременно. В сущности, получается мультипрограммирование в рамках одного процесса;
- при запуске одного потока ни один другой поток не будет запущен, пока первый добровольно не отдаст процессор. Внутри одного процесса нет прерываний по таймеру, в результате чего невозможно создать планировщик для поочередного выполнения потоков.
Рассмотрим теперь потоки на уровне ядра. В этом случае в области приложения система поддержки исполнения программ не нужна, нет необходимости и в таблицах потоков в каждом процессе. Вместо этого есть единая таблица потоков, отслеживающая все потоки в системе. Если потоку необходимо создать новый поток или завершить имеющийся, он выполняет запрос ядра, который создает или завершает поток , внося изменения в таблицу потоков (рис. 5.8).
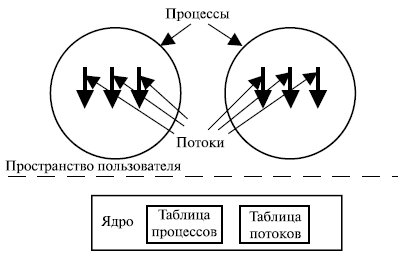
Любое приложение можно запрограммировать как многопоточное, при этом все потоки приложения поддерживаются в рамках единого процесса. Ядро поддерживается информацией контекста процесса как единого целого, а также контекстами каждого отдельного потока процесса. Планирование осуществляется ядром, исходя из состояния потоков. С помощью такого подхода удается избавиться от основных недостатков потоков пользовательского уровня.
Возможно планирование работы нескольких потоков одного и того же процесса на нескольких процессорах:
- реализуется мультипрограммирование в режимах нескольких процессов (вообще – всех);
- при блокировке одного из потоков процесса ядро может выбрать для выполнения другой поток этого же процесса;
- процедуры ядра могут быть многопоточными.
Главный недостаток связан с необходимостью двукратного переключения режимов пользовательский – ядро , ядро – пользовательский для передачи одного потока к другому в рамках одного и того же процесса.
Два процесса обращаются к одному и тому же файлу одновременно
Чтобы несколько процессов открывали один и тот же файл, Каждый процесс имеет свою собственную запись в файловой таблице (файловый объект) , Который имеет собственное смещение файла, поэтому дляПри чтении одного файла могут корректно работать несколько процессов. Однако когда несколько процессов записывают один и тот же файл, это может привести к неожиданным результатам.(Можно использовать pread, pwrite).
подводить итоги: Два независимых процесса открывают один и тот же файл, соответствующий разным файловым объектам, каждый процесс, вызывающий close, влияет только на «счетчик открытых файлов» (счетчик ссылок файлового объекта) процесса.
Вы можете сначала открыть файл, перейти к его концу, а затем дождаться завершения процесса записи (сигнализации) перед чтением.
Совместное использование файлов в Linux (2) - два независимых процесса открывают один и тот же файл
Если два независимых процесса открывают один и тот же файл, то это показано на рисунке 3-2. Мы предполагаем, что первый процесс открывает файл в файловом дескрипторе 3, а другой процесс открывает файл в файловом дескрипторе 4. Каждый процесс, открывающий этот файл, получает объект файла, но для данного файла есть только одна запись в таблице v-node. Есть одна причина, по которой каждый процесс имеет свой собственный файловый объект: такое расположение позволяет каждому процессу иметь собственное текущее смещение файла. Эта ситуация не увеличит соответствующее количество ссылок на открытый файл, но увеличит количество ссылок на dentry.

После представления этих структур данных мы продолжим объяснять операции, описанные выше.
(1) После завершения каждой записи , Текущее смещение файла в записи таблицы файлов увеличивает количество записываемых байтов. . Если это приводит к тому, что текущее смещение файла превышает текущую длину файла, текущая длина файла в представлении i-узла устанавливается равной текущему смещению файла (то есть файл удлиняется).
(2) Если файл открывается с флагом O_APPEND, соответствующий флаг также устанавливается во флаге состояния файла записи таблицы файлов (объект файла). Каждый раз, когда выполняется операция записи в такой файл с флагом заполнения, текущее смещение файла в записи таблицы файлов сначала устанавливается равным длине файла в записи таблицы i-узлов. Это позволяет добавлять данные, записываемые каждый раз, в текущий конец файла.
(3) Значение lseek изменяет текущее смещение файла в записи таблицы файлов без каких-либо операций ввода-вывода. (Не влияет на i-узел, только на объект файла. Подробный анализ см. В блоге lvyilong316: пустой файл)
(4) Если файл расположен в конце текущего файла с помощью lseek, текущее смещение файла в записи таблицы файлов устанавливается равным текущей длине файла в записи таблицы i-узлов.
Преобразуйте рисунок 3-2 в конкретную реализацию под Linux, как показано на следующем рисунке.

Примечание. Зеленая часть - это частный ресурс процесса 1, часть ××× - частный ресурс процесса 2, а синяя часть - общий ресурс процесса 1 и процесса 2.
(1) Используйте лук-порей, чтобы найти конец текущего файла, разницу между записью в файл (запись) и использованием O_APPEND для открытия (открытия) файла, а затем записи (записи):
Первая является «неатомарной» операцией. Если оба процесса используют первый метод для записи данных в конец файла, можно создать такую последовательность планирования:
Процесс A: лук-порей Процесс B: лук-порей Процесс A: запись Процесс B: запись
После записи первым процессом смещение файла (i-узла) было изменено, а второй процесс записывает снова, чтобы перезаписать содержимое, только что записанное первым процессом. Вместо этого используйте открытие O_APPEND, чтобы ядро устанавливало текущее смещение процесса (в файловом объекте) на конец файла (текущую длину файла i-узла) каждый раз перед записью в файл.
Примечание. Чтобы несколько процессов открывали один и тот же файл, каждый процесс имеет свою собственную запись в таблице файлов (файловый объект), которая имеет собственное смещение файла, поэтому он может правильно работать для нескольких процессов при чтении одного файла. Однако когда несколько процессов записывают один и тот же файл, это может привести к неожиданным результатам. (Можно использовать pread, pwrite).
Описание: Два независимых процесса открывают один и тот же файл, соответствующий разным файловым объектам, каждый процесс, вызывающий close, влияет только на «счетчик открытых файлов» (счетчик ссылок файлового объекта) процесса.
Читайте также: