
Model execution framework что это
Platform V – российская облачная цифровая платформа для разработки бизнес-решений enterprise-уровня от Сбера.
Платформа содержит все, что нужно для создания промышленных приложений любого масштаба и сложности: более 60 продуктов, компонентов и инструментов, среду разработки, алгоритмы и методологии — в том числе базы данных, решения для интеграции, обеспечения производственного процесса, аналитики, виртуализации и контейнеризации. По словам разработчиков, работающие на платформе бизнес-приложения имеют отказоустойчивость 99,99%, защищены от кибератак, готовы к неограниченному масштабированию и высоким нагрузкам (данные на март 2022г.).
Мигрировать на Platform V могут организации из разных сфер с любым ИТ-ландшафтом. Возможен бесшовный переход на платформу с legacy-архитектуры. Продукт может быть доработан под задачи заказчика. Platform V и ее компоненты поставляются по модели PaaS или on-premise с гибкими лицензионными и финансовыми условиями.
Scope
The MXF will build extensible frameworks and exemplary tools for executable models, e.g. an editor to define metamodels and runtime models and their behavior in terms of an action language. An interpreter and debugger will support the execution and testing of these models as well as recording of simulation runs for further analysis. The language for operational semantics might have a graphical and textual syntax and shall integrate other languages by means of black-box operations, library implementations, and so on. The common execution infrastructure will define common concepts on top of the Eclipse debugging framework and will enable applications to share runtime models, adapters for specific editors and debuggers, tracing capabilities, and more. MXF will provide integration with GMF for building DSL simulators that are seamlessly integrated into a generated editor.
Proposed Components
- Graphical Editor A graphical editor capable of specifying the operational semantics of EMF models. The definitions will include the abstract syntax of a language, the runtime model (both EMF models) as well as the behavior model.
- Interpreter and execution environment Reflective execution environment to interpret the models.
- Generic debugger A debugger for the interpreter.
- Execution Trace model A generic trace model and adapter concept to record execution runs.
- Sample trace recorder An implementation that performs recording of runs, either file-based or via database.
In the long term, language-specific simulator-/debugger-generators will be developed that optimize runtime performance of the generic model interpreter. Moreover, a set of resuable models/runtime libraries might be developed to support rapid development of simulators for new languages.
Caffe

Caffe — фреймворк глубинного обучения. Он сделан «с расчётом на выразительность, скорость и модульность». Изначально фреймворк создавался для проектов машинного зрения, но с тех пор развился и теперь применяется и для других задач, в том числе для распознавания речи и работы с мультимедиа.
Главное преимущество Caffe — скорость. Фреймворк целиком написан на С++, поддерживает CUDA, и при необходимости умеет переключать поток обработки между процессором и видеокартой. В пакет поставки входит набор бесплатных и open source референсных моделей для стандартных задач по классификации. Также немало моделей создано сообществом пользователей Caffe.
Инструментарий для создания вычислительных сетей Microsoft (Microsoft Computational Network Toolkit)

По горячим следам DMTK Microsoft выпустила ещё один инструментарий для машинного обучения — CNTK.
CNTK аналогичен Google TensorFlow, он позволяет создавать нейронные сети посредством ориентированных графов. Microsoft сравнивает этот фреймворк с такими продуктами, как Caffe, Theano и Torch. Его главное преимущество — скорость, особенно когда речь идёт о параллельном использовании нескольких процессоров и видеокарт. Microsoft утверждает, что использование CNTK в сочетании с GPU-кластерами на базе Azure позволяет на порядок ускорить тренировку по распознаванию речи виртуальным помощником Cortana.
Изначально CNTK разрабатывался как часть исследовательской программы по распознаванию речи и предлагался в виде open source-проекта, но с тех пор компания перевыпустила его на GitHub под гораздо более либеральной лицензией.
Veles (Samsung)

Veles — это распределённая платформа для создания приложения глубокого обучения. Как и TensorFlow и DMTK, она написана на С++, хотя для автоматизации и координации узлов используется Python. Прежде чем скармливаться кластеру выборки данных, их можно анализировать и автоматически нормализовать. REST API позволяет немедленно использовать натренированные модели в рабочих проектах (если у вас достаточно мощное оборудование).
Использование Python в Veles выходит за пределы «склеивающего кода». Например, IPython (теперь Jupyter), инструмент для визуализации и анализа данных, может выводить данные из кластера Veles. Samsung надеется, что статус open source поможет стимулировать дальнейшее развитие продукта, как и портирование под Windows и Mac OS X.
3.3. Set the package
Open the webpage.genmodel and select the Webpage node. Set the base package property to com.vogella.emf.webpage.model.
Tentative Plan

В последние годы машинное обучение превратилось в мейнстрим небывалой силы. Эта тенденция подпитывается не только дешевизной облачных сред, но и доступностью мощнейших видеокарт, применяемых для подобных вычислений, — появилась ещё и масса фреймворков для машинного обучения. Почти все из них open source, но куда важнее то, что эти фреймворки проектируются таким образом, чтобы абстрагироваться от самых трудных частей машинного обучения, делая эти технологии более доступными широкому классу разработчиков. Под катом представлена подборка фреймворков для машинного обучения, как недавно созданных, так переработанных в уходящем году. Если у вас все хорошо с английским, то статья в оригинале доступна здесь.
Создание интегратора Integrity Solutions для внедрения Platform V на внешнем рынке
28 декабря 2020 года Сбер сообщил TAdviser о том, что Luxoft создала компанию-интегратора — Integrity Solutions для внедрения цифровой платформы Сбера Platform V на внешнем рынке. Подробнее здесь.
1.3. Generate data from an EMF model
The information stored in the EMF models can be used to generate derived output. A typical use case is that you use EMF to define the domain model of your application and that you generate the corresponding Java implementation classes from this model. The EMF framework supports that the generated code can be safely extended by hand.
The EMF model (which holds real data based on the model structure) can also be used to generate different output, e.g., HTML pages, or it can be interpreted at runtime within an application.
Инструментарий для распределённого машинного обучения Microsoft (Microsoft Distributed Machine Learning Toolkit)

Чем больше компьютеров вы можете задействовать для решения проблемы машинного обучения, тем лучше. Но объединение большого парка машин и создание ML-приложений, которые эффективно на них выполняются, может быть непростой задачей. Фреймворк DMTK (Distributed Machine Learning Toolkit) предназначен для решения проблемы распределения различных ML-операций по кластеру систем.
DMTK считается именно фреймворком, а не полномасштабным коробочным решением, поэтому с ним идёт небольшое количество алгоритмов. Но архитектура DMTK позволяет расширять его, а также выжимать всё возможное из кластеров с ограниченными ресурсами. Например, каждый узел кластера имеет собственный кэш, что уменьшает объём обмена данными с центральным узлом, предоставляющим по запросам параметры для выполнения задач.
3.1. Project and initial model creation
Create a new project called com.vogella.emf.webpage.model via File New Project… Ecore Modeling Project .

Enter webpage.ecore as the Domain File Name parameter.


This should open a visual editor for creating EMF models.

Open the Properties view via the menu Window Show View Other… Properties . This view allows you to modify the attributes of your model elements.
Click on Class and click into the editor to create a new class. Create the MyWeb , Webpage , Category and Article EClasses.

Use the Attribute node to assign the attribute called name to each object. This attribute should have the EString type.

Add the title, description, and keywords attributes to the Web and Webpage model elements.

We want to use the data type calendar in our model. Select Datatype and drag it into your model. Assign the name Calendar to it. Use java.util.Calendar as type parameter.

Add a new Attribute called created to Article and use the new type Calendar.
Select References and create an arrow similar to the following picture. Make sure the upper bound is set to * and that the Containment property is flagged.

Background and Motivation
Over the last years, the eclipse modeling projects have been successfully applied — in both, academic and industry — to develop and integrate model-driven tooling, especially for domain specific languages (DSLs). While EMF is used as core to specify (meta-)models in conjunction with OCL for constraints, supplementary components support the quick development of tooling by means of editors (textual or graphical), model transformations, code generators, and so on. However, there is currently no component to specify execution semantics (i.e. operational semantics) and interpret these definitions. We see the need for a framework that supports the definition of executable models and that instantly supports design validation by running those models.
Mentors
- Ed Merks (Macro Modeling)
- Richard Gronback (Borland)
3.2. View Ecore diagram
Close the diagram and open the webpage.ecore file. The result should look like the following screenshot.

Зависимости
И так, начнём. Первым делом нам нужно создать проект с поддержкой Maven и описать в нём следующие зависимости:
* This source code was highlighted with Source Code Highlighter .
Первые две зависимости (репозитарии для maven’a описаны тут) подключают ядро Activiti и набор утилит для интеграции со Spring’ом (подключение Spring’a не описано для экономии места). Вторая группа зависимостей подключает БД (в нашем случае будет использована in-memory) и пул для работы с ней.
База данных нужна Activiti для хранения информации о процессах, их состоянии, пользователях, истории и многом-многом другом.
Marvin

Ещё один относительно свежий продукт. Marvin — это фреймворк для нейронных сетей, созданный в Princeton Vision Group. В его основе всего несколько файлов, написанных на С++, и CUDA-фреймворк. Несмотря на минимализм кода, Marvin поставляется с неплохим количеством предварительно натренированных моделей, которые можно использовать с надлежащим цитированием и внедрять с помощью pull request’ов, как и код самого проекта.

Компания Nervana создаёт программно-аппаратную платформу для глубокого обучения. И в качестве open source-проекта предлагает фреймворк Neon. С помощью подключаемых модулей он может выполнять тяжёлые вычисления на процессорах, видеокартах или оборудовании, созданном Nervana.
Neon написан на Python, с несколькими кусками на С++ и ассемблере. Так что если вы делаете научную работу на Python, или используете какой-то иной фреймворк, имеющий Python-биндинги, то можете сразу же использовать Neon.
В заключение хочется сказать, что конечно же это далеко не все популярные фреймворки. Наверняка в ваших закромах водится дюжина любимых инструментов. Не стесняйтесь, делитесь своими находками в комментариях к данной статье.
В данной статье я хочу рассмотреть пример создания простого приложения с использованием движка Activiti.
“Activiti” — это легковесная платформа (framework) для работы с бизнес-процессами (Business Process Managment), адаптированная для деловых людей, разработчиков и системных администраторов. Платформа основана на быстром и надёжном java-движке BPMN2-процессов. Проект OpenSource’ный и распространяется под лицензией Apache. Activiti может запускаться либо как часть вашего java-приложения, либо самостоятельно на сервере, кластере или облаке. Кроме того, она прекрасно интегрируется со Spring’ом.
По скольку проект обладает прекрасной документацией, я не буду описывать его основные концепции. Замечу только, что, как уже говорилось выше, мы можем использовать Activiti как самостоятельное приложение, а можем как движок/библиотеку для обработки бизнес-процессов, встраиваемый в приложение. Подробности можно посмотреть тут.
2. Installation
Install EMF via the Help Install New Software… menu entry in Eclipse. Select Modeling and install EMF - Eclipse Modeling Framework SDK and the Ecore Diagram Editor (SDK). The second entry allows you to create models.

Restart your Eclipse IDE after the installation.
Apache Spark MLlib

Apache Spark больше всего известен благодаря своей причастности к семейству Hadoop. Но этот фреймворк для обработки данных внутри памяти (in-memory) появился вне Hadoop, и до сих пор продолжает зарабатывать себе репутацию за пределами этой экосистемы. Spark превратился в привычный инструмент для машинного обучения благодаря растущей библиотеке алгоритмов, которые можно быстро применять к находящимся в памяти данным.
Spark не застыл в своём развитии, его алгоритмы постоянно расширяются и пересматриваются. В релизе 1.5 добавлено много новых алгоритмов, улучшены существующие, а также в Python усилена поддержка MLlib, основной платформы для решения математических и статистических задач. В Spark 1.6, помимо прочего, благодаря непрерывным конвейерам (persistent pipelines) появилась возможность приостановки и продолжения выполнения задач Spark ML.
TAdviser SummIT 2021: Матвей Ульянычев Platform V
В докладе директор по развитию Platform V 26 мая на TAdviser SummIT 2021 расскажет о том, какие конкурентные преимущества вы можете получить, используя Платформу, и познакомит вас с основными продуктами.
Code Contributions
Apache Singa

Фреймворки «глубинного обучения» используются для решения тяжёлых задач машинного обучения, вроде обработки естественных языков и распознавания изображений. Недавно в инкубатор Apache был принят open source-фреймворк Singa, предназначенный для облегчения тренировок моделей глубокого обучения на больших объёмах данных.
Singa обеспечивает простую программную модель для тренировки сетей на базе кластера машин, а также поддерживает многие стандартные виды тренировочных заданий: свёрточные нейронные сети, ограниченные машины Больцмана и рекуррентные нейронные сети. Модели можно тренировать синхронно (одну за другой) и асинхронно (совместно), в зависимости от того, что лучше подходит для данной проблемы. Также Singa облегчает процесс настройки кластера с помощью Apache Zookeeper.
3. Exercise: Define a new EMF model and create Java code from it
Настройки
Теперь для, того что бы мы могли запустить процесс с помощью Activiti, необходимо настроить и инициализировать основные элементы ядра Activity. По скольку мы используем Spring, для нас настройка сведётся к конфигурации соответствующих bean’ов:
* This source code was highlighted with Source Code Highlighter .
Важно отметить свойство deploymentResources bean’а processEngineConfiguration — оно указывает конфигуратору, где расположены файлы описания наших процессов. Каждый раз при старте приложения, необходимо “выложить” (deploy) эти процессы в движок Activiti. Подробнее deployment описан тут.
Brainstorm

Проект Brainstorm разработан аспирантами из швейцарского института IDSIA (Institute Dalle Molle for Artificial Intelligence). Он создавался «для того, чтобы сделать нейронные сети глубокого обучения быстрее, гибче и интереснее». Уже есть поддержка различных рекуррентных нейронных сетей, например, LSTM.
В Brainstorm используется Python для реализации двух «обработчиков» — API управления данными: один для процессорных вычислений с помощью библиотеки Numpy, а второй для использования видеокарт с помощью CUDA. Большая часть работы выполняется в Python-скриптах, поэтому не ожидайте роскошного фронтенд-интерфейса, если только не прикрутите что-то своё. Но у авторов есть далеко идущие планы по «извлечению уроков из более ранних open source-проектов» и использованию «новых элементов дизайна, совместимых с различными платформами и вычислительными бэкендами».
Google TensorFlow

Как и Microsoft DMTK, Google TensorFlow — это фреймворк машинного обучения, созданный для распределения вычислений в рамках кластера. Наряду с Google Kubernetes этот фреймворк разрабатывался для решения внутренних проблем Google, но в конце концов компания выпустила его в открытое плавание в виде open source-продукта.
TensorFlow реализует графы потоков данных (data flow graphs), когда порции данных («тензоры») могут обрабатываться серией описанных графом алгоритмов. Перемещение данных по системе называется «потоками». Графы можно собираться с помощью С++ или Python, и обрабатывать процессором или видеокартой. У Google есть долгосрочные планы по развитию TensorFlow силами сторонних разработчиков.
Proposed initial committers
- Michael Soden (ikv++ technologies ag), proposed project lead
- Hajo Eichler (ikv++ technologies ag), proposed project co-lead
- Markus Scheidgen (Humboldt University Berlin), Committer (to be confirmed)
Amazon Machine Learning

У Amazon есть свой стандартный подход к предоставлению облачных сервисов: сначала заинтересованной аудитории предоставляется базовая функциональность, эта аудитория что-то из неё лепит, а компания выясняет, что же на самом деле нужно людям.
То же самое можно сказать и про Amazon Machine Learning. Сервис подключается к данным, хранящимся в Amazon S3, Redshift или RDS, он может выполнять двоичную классификацию, многоклассовую категоризацию, а также регрессию по указанным данным для создания модели. Однако этот сервис завязан на Amazon. Мало того, что он использует данные, лежащие в принадлежащих компании хранилищах, так ещё и модели нельзя импортировать или экспортировать, а выборки данных для тренировок не могут быть больше 100 Гб. Но всё же это хороший инструмент для начала, иллюстрирующий, что машинное обучение превращается из роскоши в практический инструмент.
Interested parties
The following companies and organizations have expressed interest in this project. Key contacts listed.
1.4. Meta models - Ecore and Genmodel
The EMF meta-model consists of two parts; the ecore and the genmodel description files.
The ecore file contains the information about the defined classes. The genmodel file contains additional information for the code generation, e.g., the path and file information. The genmodel file also contains the control parameter how the code should be generated.
Organization
We propose to develop this technology as a new project under the Eclipse Modeling Framework Technology project.
mlpack 2

Многие проекты по машинному обучению используют mlpack, написанную на С++ библиотеку, созданную в 2011 году и предназначенную для «масштабирования, ускорения и упрощения использования». Внедрить mlpack для выполнения сделанных на скорую руку операций типа «чёрный ящик» можно с помощью кэша файлов, исполняемых через командную строку, а для более сложных работ — с помощью API C++.
В mlpack 2.0 был проведён большой объём работы по рефакторингу и внедрению новых алгоритмов, переработке, ускорению и избавлению от неэффективных старых алгоритмов. Например, для нативных функций генерирования случайных чисел C++11 была исключён генератор библиотеки Boost.
Одним из давних недостатков mlpack является нехватка биндингов для любых других языков, за исключением С++. Поэтому программисты, пишущие на этих других языках, не могут использовать mlpack, пока кто-то не выкатит соответствующую обёртку. Была добавлена поддержка MATLAB, но подобные проекты больше всего выигрывают в тех случаях, когда они напрямую полезны в основных окружениях, где и используется машинное обучение.
Microsoft Azure ML Studio

Учитывая огромный объём данных и вычислительной мощности, необходимый для машинного обучения, облака являются идеальной средой для ML-приложений. Microsoft оснастила Azure собственным сервисом машинного обучения, за который можно платить только по факту использования — Azure ML Studio. Доступны версии с помесячной и почасовой оплатой, а также бесплатная (free-tier). В частности, с помощью этой системы создан проект HowOldRobot.
Azure ML Studio позволяет создавать и тренировать модели, превращать их в API для предоставления другим сервисам. На один пользовательский аккаунт может выделяться до 10 Гб места ля хранения данных, хотя можно подключить и собственное Azure-хранилище. Доступен широкий спектр алгоритмов, созданных Microsoft и сторонними компаниями. Чтобы попробовать сервис, не надо даже создавать аккаунт, достаточно войти анонимно, и можно гонять Azure ML Studio в течение восьми часов.
PaaS-сервисы для быстрого создания и исполнения промышленных приложений в облаке
На май 2021 года пользователям Platform V, облачной технологической платформы Сбера, доступен следующий набор PaaS-сервисов для быстрого создания и исполнения промышленных приложений в облаке:
1.2. Eclipse Modeling Framework (EMF)
The Eclipse Modeling Framework (EMF) is a set of Eclipse plug-ins which can be used to model a data model and to generated code or other output based on this mode. EMF has a distinction between the meta-model and the actual model. The meta-model describes the structure of the model. A model is a concrete instance of this meta-model.
EMF allows the developer to create the meta-model via different means, e.g., XMI, Java annotations, UML or an XML scheme. It also allows to persists the model data; the default implementation uses a data format called XML Metadata Interchange.
Анонс Platform V
30 ноября 2020 года Сбербанк объявил о создании собственной технологической платформы — Platform V.
Разработка выступает фундаментальной составляющей стратегии, на которой базируются все планы развития финансового и нефинансового бизнеса Сбера. Она уже позволила сократить время вывода продуктов на рынок в семь раз. Благодаря внедрению платформы средняя стоимость транзакции снизилась в два раза.
По состоянию на 30 ноября на Platform V работает более 3000 agile-команд, и Сбер начал миграцию на неё своего ключевого бизнеса.
По информации банка, основная функциональность Platform V реализована на базе Open Source — решений с открытым программным кодом. При этом она позволяет использовать и коммерческие продукты. По словам разработчиков, Platform V увеличивает скорость тестирования продуктовых гипотез — в том числе благодаря развитию Low Code технологий, которые снижают порог входа для работы с ней.
The Model Execution Framework (MXF) is a proposed open source project under the Eclipse Modeling Framework Technology (EMFT). The main aim of MXF is to provide a framework for development, execution and debugging of models with operational semantics.
You are invited to comment and/or join the project. Please send all feedback to the emft newsgroup.
Бизнес-процесс
- с помощью плагина к Eclipse (скудная палитра компонентов);
- с помощью специального приложения Activiti Modeler (нет возможности загрузки диаграмм, крайне странно ведёт себя сохранение);
- руками через XML-редактор.
В результате у меня получилась следующая диаграмма:
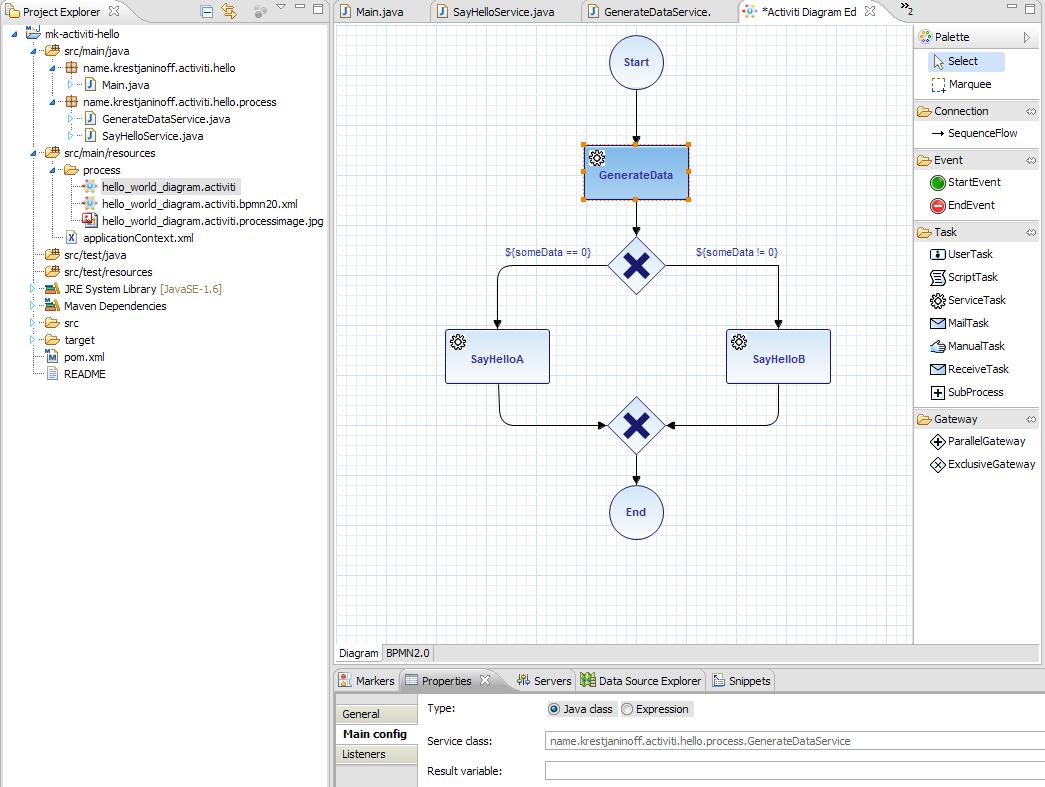
ServiceTask “GenerateData” генерирует псевдослучайные данные (реализация с помощью класса GenerateDataService, имплементирующего интерфейс JavaDelegate)
@Service
public class GenerateDataService implements JavaDelegate
public void execute(DelegateExecution execution) throws Exception Long someData = Calendar.getInstance().getTimeInMillis() % 2;
execution.setVariable( "someData" , someData);
>
>
* This source code was highlighted with Source Code Highlighter .
в зависимости от которых выполняется либо ServiceTask “SayHelloA”, либо ServiceTask “SayHelloB”. Оба эти ServiceTask’a сводятся к вызову соответствующего метода службы SayHelloService (реализация на основе UEL-выражения "$ public void printMessageA(ActivityExecution execution) System. out .println( "Hello world: variant A" ); public void printMessageB(ActivityExecution execution) System. out .println( "Hello world: variant B" ); * This source code was highlighted with Source Code Highlighter . В XML-виде (то есть в формате BPMN 2.0), а именно он нужен движку Activiti для интерпретации, процесс выглядит следующим образом: You can create a graphical representation of an existing ecore model via the context menu of an .ecore file and by selecting Initialize Ecore Diagram…. На март 2022 года пользователям Platform V доступен следующий набор PaaS-сервисов для быстрого создания и исполнения промышленных приложений в облаке: Платформа стала фундаментом цифровой трансформации Сбера. Все основные сервисы компании мигрировали на Platform V, отказавшись от зарубежных баз данных, интеграционных шин, сред виртуализации и контейнеризации. С 2021 года решение начали использовать и другие компании, а также государственные структуры. И так, основная работа уже сделана. Теперь для запуска приложения нам останется лишь создать контекст Spring’a и запустить нужный процесс: // Create Spring context // Start process * This source code was highlighted with Source Code Highlighter . A data model, sometimes also called domain model, represents the data you want to work with. For example, if you develop an online flight booking application, you might model your domain model with objects like Person , Flight , Booking etc. The EMF tooling allows you to create UML diagrams. A good practice is to model the data model of an application independently of the application logic or user interface. This approach leads to classes with almost no logic and a lot of properties, e.g., a Person class could have the firstName , lastName , Address properties, etc. With EMF you define your domain model explicitly. This helps to provide clear visibility of the model. The code generator for EMF models can be adjusted and in its default setting. It provides change notification functionality to the model in case of model changes. EMF generates interfaces and a factory to create your objects; therefore, it helps you to keep your application clean from the individual implementation classes. Another advantage is that you can regenerate the Java code from the model at any point in time. The ecore file allows to define the following elements. EClass : represents a class, with zero or more attributes and zero or more references. EAttribute : represents an attribute which has a name and a type. EReference : represents one end of an association between two classes. It has flags to indicate if it represents a containment and a reference class to which it points. EDataType : represents the type of an attribute, e.g., int , float or java.util.Date The Ecore model shows a root object representing the whole model. This model has children which represent the packages, whose children represent the classes, while the children of the classes represent the attributes of these classes.@Service
public class SayHelloService
>
>
>1.6. Ecore description file

2022: PaaS-сервисы в составе Platform V
Запуск приложения
public class Main public static void main( String [] args)
ClassPathXmlApplicationContext applicationContext =
new ClassPathXmlApplicationContext( "applicationContext.xml" );
RuntimeService runtimeService = (RuntimeService) applicationContext.
getBean( "runtimeService" );
runtimeService.startProcessInstanceByKey( "helloWorldProcess" );
>
>1.5. Ecore description file
Читайте также: