
Mdmp 1c чем открыть
Случай из практики. 1С Розница «вылетает» при открытии некоторых чеков. Из раздела «Продажи — Чеки». Несколько позиций за прошлые даты. Их открытие приводит к падению тонкого клиента 1С в дамп.
Состав ПО: ОС WIndows 7 Prof x64 Service Pack 1, платформа 8.3.16.1063, локальная ИБ в файловом режиме.
Программа автоматически закрывается, а на экране на пару секунд появляется окно: « Подождите, пожалуйста! Выполняется сохранение информации об ошибке для возможности последующего анализа! ».
Как диагностировать ошибки платформы «1С:Предприятие 8»
- Способы диагностики некорректной работы платформы «1С:Предприятие 8»
- Алгоритм действий при аварийном завершении 1С
- Настройку технологического журнала для анализа «падений» процессов кластера серверов
Не секрет, что платформа «1С: Предприятие 8», как и любое другое программное обеспечение, содержит ошибки. Некоторые из них являются настолько серьезными, что вызывают аварийное завершение процессов сервера приложений 1С.
Последствия бывают весьма серьезными, к примеру, простои учетной системы в больших организациях обходятся достаточно дорого. Причем понять природу возникновения такой ошибки бывает сложно, но все же возможно.
Включение ТЖ
По умолчанию технологический журнал включен и работает, но собирает очень ограниченный объем данных.
Под минимальным объемом данных подразумеваются 2 вещи:
1) Формирование дампов минимального размера в случае аварийного завершения работы процессов кластера 1С (ragent, rmngr или rphost).
По умолчанию дамп создается в каталоге:
Если вы используете Windows Vista и выше, то будет использоваться каталог:
Для 8.3 вместо каталога 1Cv82 используется 1Cv8.
2) Для 8.3 в минимальный ТЖ входит формирование логов с одним событием SYSTEM с уровнем Error.
Логи сохраняются в каталоге:
Для Windows Vista и старше используется каталог:
Данные логи по умолчанию будут хранится 24 часа, после чего платформа будет удалять файлы логов, которые превышают этот порог.
Чаще всего информации из ТЖ по умолчанию недостаточно, и необходимо его настраивать вручную.
Чтобы произвести тонкую настройку ТЖ, необходимо создать файл logcfg.xml с определенной структурой в определенном месте.
Данный файл необходимо разместить в каталоге:
В этом случае настройки ТЖ будут действовать для всех версий 1С, которые установлены на данном компьютере, и для всех пользователей. Этот вариант используется чаще всего, и именно его рекомендуем применять.
При настройках ЦУПа, облачных сервисов контроля производительности и прочих инструментов, где надо указывать путь к logcfg, также лучше использовать именно этот каталог, иначе при обновлении платформы или изменении имени пользователя, под которым запущена служба сервера 1С, описанные инструменты перестанут работать и придется менять настройку.
Тем не менее есть и другие варианты, хотя и используются они гораздо реже. Опишу лишь то, что с наибольшей вероятностью вам может понадобится.
Чтобы настроить ТЖ только для одной версии платформы, размещаем logcfg.xml в каталоге:
Где 8.2.19.106 – это номер нужной вам версии.
Крайне редко, но все же, может возникнуть необходимость настроить ТЖ отдельно для каждого пользователя, под которым запущена служба сервера 1С.
Тогда размещаем logcfg в каталоге:
Для ОС Windows Vista и старше:
Это может потребоваться, если у вас, например, 1 служба сервера 1С используется как рабочая, а вторая для отладки. При необходимости можно запустить службы под разными пользователями и собирать ТЖ только для одной из них, чтобы не загружать второй сервер и не собирать в логах лишние данные, либо сделать для каждой из служб свои настройки ТЖ.
Настройки из logcfg считываются не моментально, а каждые 60 секунд, причем каждый из процессов кластера считывает файл настроек независимо от других процессов. Например, сначала могут появиться логи процесса rmngr и только через 45 секунды логи rphost.
Для выключения ТЖ достаточно удалить или переименовать файл logcfg.xml.
Бурмистров Андрей
В следующих статьях рассмотрим нюансы настройки ТЖ и практику использования.
А пока закрепите полученный материал на своей тестовой информационной базе :)
PDF-версия статьи для участников группы ВКонтакте
Если Вы еще не вступили в группу – сделайте это сейчас и в блоке ниже (на этой странице) появятся ссылка на скачивание материалов.
Статья в PDF-формате
Вы можете скачать эту статью в формате PDF по следующей ссылке:
Если Вы уже участник группы – нужно просто повторно авторизоваться в ВКонтакте, чтобы скрипт Вас узнал. В случае проблем решение стандартное: очистить кеш браузера или подписаться через другой браузер.
Если вы хотите узнать больше об оптимизации 1С и быть экспертом в этой области – пройдите наш новый курс «Оптимизация производительности 1С:Предприятие».

Что делать, если появится дамп?
Рассмотрим пример: в каталоге dumps появился файл: rphost_8.2.18.102_7c938235_20131025162441_3348.mdmp
Его имя построено по шаблону: ИмяПроцесса_Релиз_АдресОшибки_ГГГГММДДЧЧММСС_PIDПроцесса.mdmp
В котором ГГГГММДДЧЧММСС – это дата и время падения.
Каждая ошибка, из-за которой происходит падение, имеет свой уникальный АдресОшибки.
Причем если у двух дампов одинаковый процесс, релиз и адрес ошибки, то причина падения одна и та же. Исходя из названия файла дампа мы определяем время падения системы. Осталось узнать, что происходило в системе в указанное время, и тут нам пригодятся логи ТЖ.
ТЖ записывается для каждого процесса в свой отдельный каталог, имя которого задается по шаблону ИмяПроцесса_PIDПроцесса.
Имя файла лога задается следующим образом: ГГММДДЧЧ.log
Для определения причины падения системы переходим в каталог с логами аварийно завершившегося процесса. Это можно сделать по имени файла, в котором присутствуют имя и PID-процесса. В нашем случае это каталог rphost_3348.
Далее в искомом каталоге нужно взять тот лог, в который была записана информация в момент падения системы: определяем время падения из имени дампа и находим необходимый файл лога. В нашем случае это файл 13102516.log.
Затем открываем файл лога и находим строку rphost_8.2.18.102_7c938235_20131025162441_3348.
В моем логе отражено следующее:
0,EXCP,3,process=rphost,p:processName=Test,t:clientID=2,t:applicationName=1CV8C,t:computerName=AND-SERVER,t:connectID=196,SessionID=4,AppID=1CV8C,OSException=rphost_8.2.18.102_7c938235_20131025162441_3348,Context=’Форма.Вызов : ВнешняяОбработка.ВнешняяОбработка1.Форма.Форма.Модуль.Крах
Форма.Форма.Форма : 5 : Крах();
Форма.Форма.Форма : 5 : Крах();
Форма.Форма.Форма : 5 : Крах();
Форма.Форма.Форма : 5 : Крах();
……
Рассмотрим информацию данной строки:
EXCP – данное событие означает, что в системе возникло какое-либо исключение. Через запятую перечислены свойства этого события, приведем основные из них:
- Process – имя процесса, где возникло исключение
- processName – имя информационной базы
- applicationName – клиент с которого пришел вызов, приведший к падению, в данном случае это тонкий клиент
- computerName – имя компьютера, на котором был запущен клиент
- Context – код, который выполнялся в момент падения, это самое важное для нас событие
Иногда с помощью контекста удается установить причину возникновения ошибки. В нашем случае причина падения достаточно очевидна – бесконечная рекурсия.
Первым делом — правильные вопросы
- Когда это началось?
Вспомните, какие были последние изменения в программном и аппаратном обеспечении. Возможно, что они повлияли на стабильность работы 1С, и возврат к прежнему состоянию ПК — как один из выходов. - Где и при каких событиях появляется?
Вылет программы появляется у всех или же на одном рабочем месте. Проблема может идти от самой ИБ (сервера) или же связана с локальным окружением. - Повторяется ли ошибка для другой учетной записи?
Как на уровне ОС, так и в правах самой 1С. Проверьте, как ведет себя программа, открытая с полными правами (от имени администратора). Возникает ли ошибка, если повторить операции пользователя.
Дальнейшие действия направлены на поиск причины. Чтобы отсечь прочие факторы и сузить проблему до конкретных условий, при которых фиксируется сбой.
Общая информация
Технологический журнал является основным источником информации для всех инструментов анализа производительности платформы.
Ведение технологического журнала возможно как для сервера, так и для клиентских приложений. Так как клиентские логи и дампы, за редким исключением, не представляют практического интереса, вопрос мы будем рассматривать только со стороны сервера. Тем не менее, все сказанное ниже, будет верно и для клиента.
Технологический журнал может продуцировать два вида информации:
Первым делом — правильные вопросы
- Когда это началось?
Вспомните, какие были последние изменения в программном и аппаратном обеспечении. Возможно, что они повлияли на стабильность работы 1С, и возврат к прежнему состоянию ПК — как один из выходов. - Где и при каких событиях появляется?
Вылет программы появляется у всех или же на одном рабочем месте. Проблема может идти от самой ИБ (сервера) или же связана с локальным окружением. - Повторяется ли ошибка для другой учетной записи?
Как на уровне ОС, так и в правах самой 1С. Проверьте, как ведет себя программа, открытая с полными правами (от имени администратора). Возникает ли ошибка, если повторить операции пользователя.
Дальнейшие действия направлены на поиск причины. Чтобы отсечь прочие факторы и сузить проблему до конкретных условий, при которых фиксируется сбой.
Где взять дополнительную информацию
Для технически подкованных пользователей и администраторов. Кто желает идти вглубь и понять, в чем же все-таки проблема.
- Журнал ОС (через оснастку « Просмотр событий \ Журналы Windows \ Приложение ») — можно увидеть путь сбойного модуля и его расположение.
- Анализ файла дампа — например, с помощью Debugging Tools for Windows.
- Включение технологического журнала 1С и его разбор.
- Официальный сервис публикации ошибок (bugboard).
- Запрос в службу технической поддержки 1С.
✅ Для этого частного случая помогло обновление платформы до версии 8.3.18.1208.
⚡ Подписывайтесь на канал или задавайте вопрос на сайте — постараемся помочь всеми техническими силами. Безопасной и производительной работы в Windows и 1С.
Ни для кого не секрет, что платформа 1С содержит достаточно большое число ошибок, и иногда эти ошибки настолько критичны, что приводят к аварийному завершению процессов сервера приложений. О последствиях думаю рассказывать излишне. Расследовать такие ошибки самостоятельно сложно, но иногда все-таки можно, об этом и будет данная статья.
С чего начать?
Первое что необходимо сделать, это настроить технологический журнал (ТЖ).
Если кто не знает что это за зверь, то вам сюда.
Даже если у вас все хорошо, или вы думаете что у вас все хорошо, то все равно рекомендуется настроить сбор логов. Зачем?
1. Если вдруг проблемы возникнут, то у вас уже будут все данные для расследования.
2. Возможно, что проблемы у вас уже есть, например процессы «падают» раз в 2-3 месяца, но вы об этом просто не знаете, т.к. пользователям легче перезапустится и продолжить работу, чем связываться с программистами.
Файл настроек ТЖ, тот который logcfg.xml, должен выглядеть следующим образом:

Теперь давайте разберемся с тем, что здесь написано.
Во второй строке мы включаем запись дампа, т.е. в случае краха одного из процессов дамп будет записан в каталог «c:\v82\dumps» и при необходимости поможет разработчикам платформы найти причину ошибки.
Дамп образуется только в случае падения одного из процессов, т.е. если в каталоге damps появятся файлы, это значит, что у вас есть проблемы со стабильностью.
В третьей строке мы включаем запись логов ТЖ, как не трудно догадаться, логи будут записываться в каталог «c:\v82\logs» и храниться 48 часов.
Событие EXCP пишется в случае возникновения исключения, и нужно что бы узнать какой код выполнялся в момент ошибки.
События PROC и ADMIN могут пригодиться разработчикам платформы для расследования.
Что делать, если появится дамп?
Допустим в каталоге dumps появился файл rphost_8.2.18.102_7c938235_20131025162441_3348.mdmp
Имя дампа строится по следующему шаблону:
ГГГГММДДЧЧММСС – это дата и время падения, в нашем примере это 2013.10.25 16:24:41
Обычно каждая ошибка, из-за которой происходит падение, имеет свой уникальный АдресОшибки.
Т.е. если у двух дампов одинаковый процесс, релиз и адрес ошибки, то скорее всего причина падения одна и та же.
Из названия дампа, мы знаем точное время падения, теперь необходимо выяснить, что происходило в это время в системе, и здесь нам помогут логи ТЖ.
ТЖ пишется в отдельный каталог для каждого процесса, имя каталога формируется по шаблону ИмяПроцесса_PIDПроцесса.
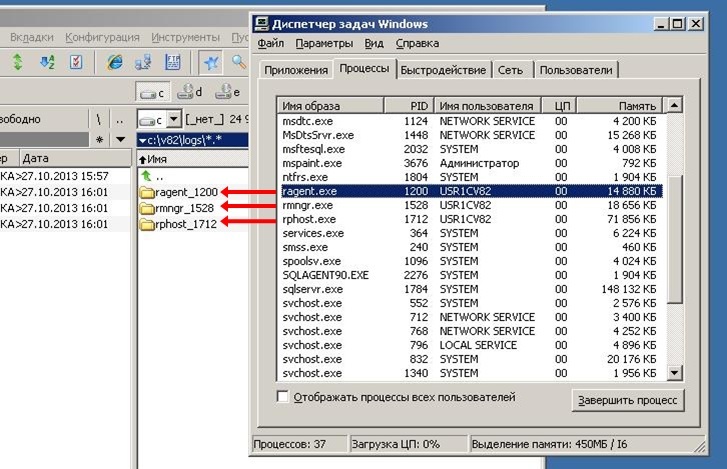
Имя файла лога формируется по следующему шаблону ГГММДДЧЧ.log
Что бы узнать, что привело к падению, находим каталог с логами покинувшего нас процесса. Мы легко это можем сделать т.к. в имени файла дампа есть имя и PID процесса.
В данном случае нам нужен каталог rphost_3348.
Теперь в указанном каталоге нужно найти тот лог, в который писалась информация в момент падения. Опять же берем время падения из имени дампа, и таким образом находим файл лога 13102516.log
Открываем файл лога и ищем строку rphost_8.2.18.102_7c938235_20131025162441_3348
В моем случае в логе написано следующее:
Форма.Форма.Форма : 5 : Крах();
Форма.Форма.Форма : 5 : Крах();
Форма.Форма.Форма : 5 : Крах();
Форма.Форма.Форма : 5 : Крах();
Форма.Форма.Форма : 5 : Крах();
EXCP – это событие означает, что в системе возникло какое-либо исключение, далее через запятую перечислены свойства этого события, перечислим основные из них.
Process – имя процесса, где возникло исключение
processName – имя информационной базы
applicationName – клиент с которого пришел вызов, приведший к падению, в данном случае это тонкий клиент
computerName – имя компьютера, на котором был запущен клиент
Context – код, который выполнялся в момент падения, это самое важное для нас событие.
С помощью контекста иногда (но реже чем хотелось бы) удается понять причину ошибки.
В моем случае причина падения очевидна, это бесконечная рекурсия.
Данный пример конечно слишком простой и достаточно редко встречается в реальной жизни, хотя иногда бывает.
Рассмотрим другой пример
В версии 8.2.13 есть одна очень популярная ошибка при работе с объектом «СистемнаяИнформация»
Контекст ТЖ выглядит примерно так:
Context=’Инфо = Новый СистемнаяИнформация;
Текст = "Версия 1С " + Инфо.ВерсияПриложения;’
На первый взгляд ничего криминального здесь нет, но надо помнить, что 1С это многопользовательская система, и объекты должны быть спроектированы с учетом параллельности работы пользователей, как раз здесь часто и ошибаются разработчики платформы.
Причем ошибки, возникающие в момент одновременного обращения к объекту нескольких пользователей, встречаются достаточно часто, и если у вас уже образовалось несколько дампов, и при этом в контексте фигурирует один и тот же объект (в данном примере СистемнаяИнформация), то скорее всего это как раз тот случай.
Обход проблемы очень прост, нужно просто закомментировать обращение к объекту. В данном случае это не проблема, т.к. обычно без системной информации вполне можно обойтись.
Что делать, если понять причину падения по логам самостоятельно не удается?
Вы конечно можете обратиться в тех. поддержку 1С, но это, мягко говоря, не самый быстрый способ :)
Если вы не работаете во франчайзи и у вас нет доступа на партнерский форум, то наверняка у вас есть друзья или знакомые, которые там работают.
Это намного более быстрый способ, чем обращение через тех. поддержку или решение проблемы методом научного тыка.
На партнерском форуме на ваши вопросы отвечают не только специалисты, которые возможно уже сталкивались с такой проблемой, но и сами разработчики платформы.
При обращении на форум, обязательно указывайте следующую информацию:
- Ссылки на архив с дампом и логами для скачивания
- Версию и разрядность серверной ОС
- Разрядность сервера 1С
- Количество серверов в кластере
- Количество запущенных рабочих процессов на сервере 1С
- Версию используемой СУБД
Что делать, если понять причину падения по логам самостоятельно не удается?
Прежде всего, Вы можете обратиться в техническую поддержку фирмы «1С». Но это не самый быстрый способ.
Это лучше, чем обращение через техническую поддержку или решение проблемы методом «научного тыка». На партнерском форуме Вам, возможно, ответят не только специалисты, которые, скорее всего, уже сталкивались с подобной проблемой, но и сами разработчики платформы. При обращении на форум обязательно указывайте следующую информацию:
- Версию и разрядность серверной ОС
- Разрядность сервера 1С
- Количество серверов в кластере
- Количество запущенных рабочих процессов на сервере 1С
- Версию используемой СУБД
- Ссылки на архив с дампом и логами для скачивания
Следует отметить, что этот вариант доступен только сотрудникам фирм-партнеров компании «1С».
PDF-версия статьи для участников группы ВКонтакте
Если Вы еще не вступили в группу – сделайте это сейчас и в блоке ниже (на этой странице) появятся ссылка на скачивание материалов.
Статья в PDF-формате
Если Вы уже участник группы – нужно просто повторно авторизоваться в ВКонтакте, чтобы скрипт Вас узнал. В случае проблем решение стандартное: очистить кеш браузера или подписаться через другой браузер.
35 учебных часов, подготовка к 1С:Эксперт, правильная настройка серверной части, оптимизация кода, мониторинг загруженности оборудования и прочие взрослые вещи.
Коллеги, начинаем серию статей, посвященных технологическому журналу.
В этой серии мы с вами рассмотрим практику использования полезного инструмента для расследования проблем производительности и стабильности 1С:Предприятие – технологического журнала.
Другие статьи из серии «Технологический журнал»:
«ТЖ: Настройка»
«ТЖ: Анализ логов»
«ТЖ: События и фильтры»
Комментарии / обсуждение (18):
Здравствуйте, Андрей. Вы написали “…необходимо создать файл logcfg.xml с определенной структурой в определенном месте.”, а как узнать о структуре файла? У пользователя периодически появляется ошибка блокировки HRESULT=80040E31, хотелось бы её причину отследить…
2. Периодически появляется ошибка блокировки HRESULT=80040E31
На самом деле для расследования этой проблемы исследовать логи ТЖ вам не нужно. Это проблема ожидания на блокировках причем на уровне СУБД, а для ее исследования вам нужен инструмента анализа ожиданий на блокировках. Вы можете для этих целей использовать платный ЦУП (Центр управления производительностью) или бесплатный сервис анализа блокировок от Гилева. С помощью одного из этих инструментов вы сможете определить причину ожиданий и если есть нужные знания решить проблему.
В самом ТЖ вы лишь увидите текст ошибки по таймауту из-за блокировки, хотя этот текст проще вам будет посмотреть в журнале регистрации (если он конечно включен).
Благодарю за Ваш ответ!
Пожалуйста!
Интересного обучения!
Подскажите, можно ли отловить в ТЖ изменения настроек Журнала регистрации, например, отключение записи событий?
Специального такого события нет, но можно посмотреть что настройки ЖР были изменены, хотя и нельзя определить что именно там было изменено.
В случае измерения настроек в ТЖ будет вот такая строка:
Вы можете сделать фильтр на свойства t:applicationName=Designer и MName=changeLogMngrInfo
Наберусь наглости задать еще один вопрос по журналу регистрации.
Если в кластере два центральных сервера, то как идет запись в ЖР?
Если ничего не настраивать, то журналы регистрации для одной и той же ИБ на серверах разные? Или дублируются? Как сделать так, чтобы все писалось только в одну папку в служебном каталоге кластера одного из серверов? Если помощью требований назначения функциональности запретить одному серверу работать с журналом регистрации, то события будут писаться в папку другого сервера или вообще не будут для сеансов на данном сервере?
>Если в кластере два центральных сервера, то как идет запись в ЖР?
Если ничего не настраивать, то журналы регистрации для одной и той же ИБ на серверах разные?
Журнал пишется только на одном из серверов если ничего дополнительно не настравивать.
>Или дублируются?
Нет, журнал не дублируется.
>Как сделать так, чтобы все писалось только в одну папку в служебном каталоге кластера одного из серверов?
Для этого необходимо с помощью требований назначения функциональности перенести сервис ЖР на какой-то один сервер.
>Если помощью требований назначения функциональности запретить одному серверу работать с журналом регистрации, то события будут писаться в папку другого сервера или вообще не будут для сеансов на данном сервере?
Будут писаться в папку другого сервера.
Рекомендуется закрепить ЖР за каким-то одним из серверов, что бы не получилась нижеописанная ситуация.
Допустим с помощью требований назначения функциональности указано что одна база работает на отдельном сервере, другие на другом. В этом случае ЖР действий по этой базе будет вестись на отдельном сервере, ЖР по другим базам будет на другом сервере, и это нужно учитывать при резервном копировании. Так же возможна ситуация когда работы с отдельной базой или рег. заданием вынесли на отдельный сервер, а потом вернули обработно. Тогда всей действия в этой базе или в этом рег. задании которые были за период пока они выполнялись на отдельном сервере, будут только в ЖР на этом отдельном сервере. С другими серверами кластера эта информация не синхронизируется. Поэтому что бы не рисковать, рекомендуется сделаять явное указание где хранить ЖР, в таком случае ЖР всегда будет храниться в одном месте при любых условиях.
Технологический журнал — это средство логирования действий платформы происходящих на самом низком уровне. Данные предоставляемые технологическим журналом позволяют выявить причины «тормозов», зависаний, утечек памяти и «падений» рабочих процессов.
Как действовать в общем случае
Делаем бэкап базы. Обязательно. Перед любыми действиями с базой — сделайте архивную копию. С помощью копирования файла 1Cv8.1CD или выгрузки dt-файла через Конфигуратор.
Этот этап можно пропустить, если проверяете на копии. Например, когда вы разворачиваете базу рядом с основной, по другому пути (адресу).
3. Очистка настроек пользователя
Не все, оставьте необходимые настройки. Либо проверьте работу под новым пользователем (тестовой учетной записью).
Чтобы исключить влияние модулей антивирусной защиты.
С помощью chdbfl, а также через проверки целостности в инструменте «Тестирование и исправление».
6. Другие разрядность и режим
Простая проверка в разных вариантах запуска — x86/x64, толстый/тонкий клиент.
Есть возможность опробовать работу на более новой платформе? Проверьте. А в некоторых случаях — даже откат на прежний релиз.
Специальные предложения









. и следить за ним, не отрывая глаз :) у нас при наших объёмах технологический журнал может сначала работать спокойно полдня, а потом резко (меньше, чем за час) съесть всё место на диске (100+ ГБ), что не только не даст ответа на вопрос, что рухнуло, но и порушит всё остальное. Перепробовали разные настройки - ничего нас не спасает пока что.
В среднем процессы падают 3-4 раза в неделю. Платформа 8.2.18.82, сервер 64х.
(1) baton_pk, Такой неравномерный рост файлов ТЖ, скорее всего, вызван спецификой работы Ваших пользователей. Ищите, что "особенное" происходит в периоды такого роста ТЖ. Для этого можно, например, настроить лог только части событий.
Я не спорю. Пишу лишь о том, что в нашем случае на это надо выделить целого человека на хороший промежуток времени, чего наша компания позволить себе не может. С наскоку одолеть не получается, настроек перепробовали довольно много. Пока что для нас целесообразней плюнуть на всё это - ну вылетает 3-4 раза за неделю один процесс из 8 - это ладно, а порушить экспериментами сразу весь сервер пару раз в неделю - это плохой вариант.
(1) baton_pk,
ТЖ может расти только по одной причине, у вас включена регистрация кучи событий, большинство из которых вам скорее всего не нужны.
Сделайте logcfg таким как написано в статье, тогда ТЖ не будет расти, т.к. эти события возникают редко.
После очередного падения пришлите мне собранные логи, возможно удастся что-то найти.
Пробовали весной такой лог. Никакой закономерности: процесс может рухнуть и без единого EXCP, процесс может быть повально завален EXCP (у нас тучи конфликтов блокировок), раздувать лог, занимать место, но работать всю неделю без сбоев.
Попробую на неделе - может, Вы увидите в этих логах больше, чем мы.
1 - именно поэтому я и написал в статье, что данное событие возникает при наличии исключения, а не при наличии ошибки. Исключение может возникать и в штатном режиме и никак не указывать на ошибку.
Надеюсь что в будущем эту ситуацию исправят, и сделают дополнительные события которые позволят более точно идентифицировать проблемы.
P.S.
И да, я подозревал что и здесь вы не упустите шанса попиарить свои разработки -)
(13) кажется, что здесь дан бесплатный полезный совет, коллега поделился опытом. Да и пиар - это вовсе не зло :)
(14) Evil Beaver,
Да я и не злюсь, просто удивляюсь этакой вездесущности :)
Кстати сам рекомендую пользоваться сервисами Вячаслава, благо они пока бесплатные.
(15) стараюсь всеми силами сохранить сервисы бесплатными (ошибки платформы, это не то, на чем надо зарабатывать имхо), единственное, что мы уже точно решили сделать платным - это старые архивы, данные набегают уже десятками террабайт
Про "уникальный АдресОшибки". Если правильно понимаю, на самом деле это адрес смещения в рабочем процессе, где возникло исключение. Но есть хоть и маленькая вероятность, но все же что причины исключения могут быть разными. В разных версиях платформы у одной и той же ошибки эти смещения могут меняться. Но это я так, скорее "поумничать". Мне вот сейчас идея пришла сделать классификатор этих смещений, но нужна коллективная помощь в заполнении интерпретаций. Сами в одиночку не осилю.
Именно поэтому я и написал что если процесс, версия и адрес одинаковые, тогда это скорее всего одна и та же ошибка, исключения бывают но это редкость.
Идея хорошая, в 1С такой классификатор есть, знали бы вы какого труда мне стоило его заполнить :)
Но файла этого у меня к сожалению нет, а если бы и был, то не уверен что было бы законно его публиковать в открытом доступе.
Согласен, но ситуация со стабильностью к сожалению оставляет желать лучшего, особенно в больших системах.
Вам не хуже меня известно, что иногда запускаются целые проекты не с целью ускорения, а с целью стабилизации системы. Проект с Enter яркий тому пример.
Если бы 1С публиковало такой же классификатор дампов, как публикует номера ошибок, это был бы большой плюс к карме, и возможно baton_pk сразу бы увидел решение или обход своей проблемы.
Это просто гейзенбаг какой-то! После включения журнала ни один процесс до сих пор внепланово не рухнул!
(22) (23) Gilev.Vyacheslav,
Одно ваше присутствие заставляет наш сервак пахать без перебоев уже третью неделю!
А если серьёзно, отключили за пару дней до этого один из наших злосчастных сделанных на скорую руку самописных COM-обменов - видимо, дело было в нём. Надо будет запустить его обратно после сдачи отчётности :-)
(25) baton_pk,
Действительно очень может быть из за COM-обмена.
Уже сейчас можете посмотреть если что-то похожее в списке ошибок для вашего релиза.
(27) baton_pk, Многие проблемы удалось избежать добавив пользователей в группу "Пользователь DCOM". К сожалению, не все проблемы решены.
(29) gorodok11,
у нас все COM-обмены работают в фоновых заданиях на сервере, служба сервера 1С работает под локальным админом, под клиентами COM-обменов нет.
(21) baton_pk, это хорошее имеет свойство заканчиваться, а плохое никогда само просто так не уходит, терпение мой друг, терпение.
Я рекомендую следующую стратегию использования техножурнала в случае, если он очень сильно растет. Сначала включаете запись только события EXCP и EXCPCNTX и накапливаете статистику по ним. Это обычно очень небольшой объем данных. Затем на основе анализа накопленных событий EXCP включаете и другие события в зависимости от типа исключения и ваших знаний о платформе, но при этом вы включаете узкую фильтрацию по свойствам этих событий, используя информацию из событий EXCP (например по имени пользователя, длительности, базе и т.д.).
Но признаюсь, что такой подход требует определенного опыта и даже в этом случае иногда оказывается неэффективен.
Таки рухнуло! Притом довольно жестоко - файлы с дампами забили всё свободное место (~80 ГБ).
Дампы пришлось убить, но ничего страшного - после перезапуска тут же снова рухнуло и дало ещё чуток дампов.
Полезу, посмотрю, чего там в журналах интересного.
(32)
0800 - тех.журнал до 08.00, я его запаковал и прибил. и дампы прибил - место надо было чистить
0950 - тех.журнал на текущий момент. есть дампы
В текстовом файле "бортовой журнал". Там выдержки из техжурнала и хронология падения процессов.
(34) baton_pk,
Настройка не отображается, лучше сделать скрин
По крайней мере удалось локализовать проблему, теперь известна причина
В принципе с этим уже можно обращаться на партнерский форум.
Ну, процентов на 99 мы и так грешили именно на COM-обмены :)
Дык надо сейчас как-то это обойти :) Негоже, чтобы обмены стояли целый день.
Запустил с клиента COM-обмен, процесс рухнул. Удалил из лога всё, что было ДО запуска, лог прикладываю.
Лог только упавшего процесса.
А нельзя отказаться от СОМ обменов? С точки зрения интеграции это самый большой костыль который можно представить. Если нужна онлайновость, то веб-сервисы как раз то, что надо.
(37) dmitry-gr,
Веб-сервисы ещё делать надо :) Это уже должно начальство решать. Моя смертная задача - решать возникшую проблему с существующими обменами. Но, да, COM-обмены - ещё то зло и надо от них уходить. С другой стороны, трудозатраты на перекраивание системы под веб-сервисы сильно превышают трудозатраты на периодические костыли при падениях.
Хотя может после нынешнего падения всё изменится. Первый раз так, что сижу уже четвёртый час и даже зацепок нет, какую заплатку и куда поставить!
(38) baton_pk,
У вас что полный тех. журнал пишется?
Зачем вам запросы и вызовы сервера, так никакого места на дисках не хватит.
По логам тут мало что видно к сожалению, т.к. это как раз тот случай когда контекста нет.
Все же я вам советую задать вопрос на форуме, возможно это уже известная проблема.
Всё оказалось банально просто: в выгрузке появился документ, которым с лохматых времён никто не пользовался и который пытается провестись и выдаёт ошибки. Опять же вернулись к пресловутому "Сообщить" под внешним соединением. Вот только если в первые разы я это отлавливал по тех.журналу, то сегодня пришлось работать методом тыка. Убрал из выгрузки данный вид документа и попёрло: 15 минут, полёт нормальный.
В основном проблемы возникают, когда при COM-обмене пытаемся провести документ и этот документ пытается нам чего-то сказать. В частности, когда не может провестись.
Попробую смоделировать ошибку и вышлю более подробные сведения.
Ну в вашем случае обход это единственно возможное решение -)
Если не считать переход на версию где эта ошибка исправлена.
Спасибо, Андрей! Статья на все времена - до скончания платформы 1С.
Вот только одно замечание: т.к. мы не собираемся анализировать дамп в отладчике (у нас ведь нет файлов .pdb с отладочной информацией), то надо использовать тип дампа "минимальный" - от дампа мы хотим получить только номер упавшего процесса.
Т.е. вместо
используйте
Значение type="0" указано для платформы 8.3.16, подробнее смотреть "Рук-во админа. Приложение 3"
3.21.2.5. Элемент
(47)
Если вы не собираетесь отправлять дапм в тех. поддержку, тогда да, достаточно и минимального. Но как правило дампы отправляются в 1С, а там требуют именно полные дампы для анализа.
Почему надо использовать тип дампа "минимальный" ? - содержимое дампа нам "до фонаря", из имени файла дампа получим имя модуля, время падения, адрес в памяти, номер (PID) упавшего процесса.
цитирую пункт "3.21.2.5. Элемент "
Атрибут "type" (применяется только для ОС Windows)
Тип дампа, произвольная комбинация приведенных ниже флажков (т.е. это битовая маска), представленная в десятичной или шестнадцатеричной системе. Значение атрибута "type" получается сложением значений, указанных ниже. Представление в шестнадцатеричной системе должно начинаться с символа ‘x’, например, x0002.
Доступны следующие значения:
0 (x0000) ‑ минимальный;
1 (x0001) ‑ дополнительный сегмент данных;
2 (x0002) ‑ содержимое всей памяти процесса;
4 (x0004) ‑ данные хэндлов;
8 (x0008) ‑ оставить в дампе только информацию, необходимую для восстановления стеков вызовов;
16 (x0010) ‑ если стек содержит ссылки на память модулей, то добавить флажок флаг 64 (0x0040);
32 (x0020) ‑ включить в дамп память из-под выгруженных модулей;
64 (x0040) ‑ включить в дамп память, на которую есть ссылки;
128 (x0080) ‑ добавить в дамп подробную информацию о файлах модулей;
256 (x0100) ‑ добавить в дамп локальные данные потоков;
512 (x0200) ‑ включение в дамп памяти из всего доступного виртуального адресного пространства.
конец цитаты из доки.
Включение в тип значения "2 (x0002) ‑ содержимое всей памяти процесса" резко увеличивает размер файла дампа.
Андрей слишком обобщает - анализировать содержимое дампа могут только сотрудники 1С , если вы решаете проблему краха процессов платформы 1С и собираете дампы и ТЖ под руководством службы техн.поддержки 1С, то мои замечания не важны абс-но, они написаны для тех, кто точно не будет обращаться в ТП 1С, а будет пытаться самостоятельно анализировать ТЖ - не так уж это сложно, хотя требует хороших навыков и "быстрого" (т.е. который не "тормозит") ума. Для избежания ситуации исчерпания дискового места файлами дампов, я бы даже сделал виндовое задание, которое по расписанию выполняло: 1) сохранить в текстовом файле список файлов дампов 2) удалить те дампы, которые на 1-м шаге были записаны в файл протокола.
Рассмотрим другой пример
В версии 8.2.13 платформы «1С:Предприятие» присутствует очень популярная ошибка при работе с объектом «СистемнаяИнформация». При этом контекст ТЖ выглядит следующим образом:
Context=’Инфо = Новый СистемнаяИнформация;
Текст = «Версия 1С » + Инфо.ВерсияПриложения;’
Заметим, что ошибки, проявляющиеся в при одновременном обращении к одному объекту нескольких пользователей, встречаются достаточно часто, и если образовалось несколько дампов, и в контексте указан один и тот же объект (в данном примере «СистемнаяИнформация»), то, скорее всего, это как раз тот случай.
Проблема решается тривиально: нужно закомментировать обращение к объекту. В нашем случае это не проблема, так как без системной информации можно обойтись.
Описание и включение технологического журнала
Что Вы узнаете из этой статьи?
- Описание и предназначение инструмента Технологический журнал
- Как включить Технологический журнал в 1С:Предприятие 8
- Принцип формирования и сохранения логов и дампов
Включение технологического журнала
По умолчанию технический журнал включен и работает, дампы хранятся здесь:
%LOCALAPPDATA%\1C\1cv8\dumps (пример: C:\Users\USR1CV8\AppData\Local\1C\1cv8\dumps )
%LOCALAPPDATA%\1C\1cv8\logs (пример: C:\Users\USR1CV8\AppData\Local\1C\1cv8\logs )
USR1CV8 — имя пользователя под которым работает сервер 1С. Логи хранятся 24 часа, при этом делятся на файлы — каждый час новый файл.
Собираемая таким образом информация минимальна — формируются дампы минимального размера при аварийном завершении работы рабочих процессов, а в логи попадают только события SYSTEM с уровнем Error.
В большинстве случаев этой информации недостаточно, следовательно нам необходимо самостоятельно указать какую информацию мы хотим видеть в логах. Для этого необходимо создать файл настроек тех. журнала (об этом ниже) с названием logcfg.xml и разместить его в одной из подходящих директорий.
Выбор директории зависит от задачи: если нужно настроить тех. журнал для всех версий 1С, то файл настроек нужно разместить здесь:
Если настроить нужно конкретную версию, то здесь (зависит от версии):
Иногда может потребовать включить тех. журнал для конкретного пользователя, из под которого запущен сервер 1С, в этом случае файл настроек следует разместить тут:
Перезагружать сервер не требуется, настройки считаются и будут применены не более чем через 60 секунд. Выключить тех. журнал еще проще — нужно переместить или переименовать файл настроек.
Создание файла настроек
Теперь перейдем к содержимому файла настроек logcfg.xml.
Описание ТЖ
Технологический журнал (далее ТЖ) – это средство для логирования работы платформы на низком уровне.
ТЖ предназначен для расследования ошибок, анализа и диагностики различных проблем в работе платформы 1С:Предприятие.
С помощью ТЖ можно выяснить, какие запросы работают медленно и откуда они вызываются, при выполнении какого кода «падают» рабочие процессы сервера, куда «утекает» память и многое, многое другое.
Все инструменты анализа производительности платформы используют ТЖ для получения информации. При желании и доскональном изучении вопроса с помощью ТЖ вы можете написать свой инструмент анализа производительности.
ТЖ можно собирать как для процессов сервера 1С, так и для клиентских приложений. Соответственно, и набор событий, которые можно фиксировать в ТЖ, будет отличаться.
Клиентские логи и дампы крайне редко вызывают интерес, поэтому в статье мы будем рассматривать ТЖ исключительно с точки зрения сервера. Тем не менее все, что здесь написано, также подходит и для клиентских логов.
С помощью ТЖ можно собирать логи и настраивать формирование дампов в случае аварийного завершения работы процесса.
Логи – это файлы с расширением .log, где информация хранится в текстовом виде.
С чего начать?
Представьте, что именно сегодня у Вас «вылетает 1С», то есть происходит самопроизвольная выгрузка из памяти процессов сервера приложений 1С. К тому же у части пользователей наблюдается аварийное завершение сеанса.
В данной ситуации для начала необходимо настроить технологический журнал (далее – ТЖ).
Даже если Вы не наблюдаете проблем, рекомендуется настроить сбор логов. Для чего?
1. При возникновении проблем у Вас уже будут данные для анализа причин плохого поведения системы.
2. Вполне вероятно, что проблемы все-таки есть, но Вы о них ничего не знаете. К примеру, процессы сервера «падают» раз в 3-4 месяца, но пользователи не сообщают Вам об этом, предпочитая просто перезапуститься.
Файл настроек logcfg.xml технологического журнала должен выглядеть так:
Рассмотрим более подробно, что в нем содержится.
Первая и последняя строка открывают и закрывают xml-файл настроек.
Вторая строка включат запись дампа: при крахе одного из процессов наш дамп будет записан в указанный каталог и может помочь разработчикам платформы найти причину возникновения ошибки. При этом необходимо понимать, что дамп создается только при падении одного из процессов.
Таким образом, наличие файлов в указанном каталоге c:\v82\dumps говорит о наличии проблем со стабильностью работы.
Третья строка включает запись логов ТЖ: логи будут храниться в указанном каталоге в течении 48 часов. Событие EXCP будет зафиксировано в случае возникновения исключения, это нужно, чтобы узнать, какой код выполнялся в момент ошибки.
События PROC и ADMIN вполне могут пригодиться разработчикам платформы для анализа проблем.
Вы должны учитывать, что сами логи могут занимать достаточно много места на диске. Хотя, в приведенной настройке ТЖ логи не должны сильно расти – благодаря ограничению по времени хранения логов.
Читайте также: