
Mdadm восстановление массива raid 1
Восстановление таблицы разделов на mdadm
Просто подмонтировать запущенный mdadm массив к системе не получилось.
Я так понял, что тут либо таблица разделов так же была уничтожена, либо файловая система. Я не знал, как был разбит на разделы сам массив, поэтому просто решил еще раз прогнать анализ таблицы разделов уже массива md2 через утилиту testdisk.
К счастью, она нашла единственный раздел на диске и восстановила его. Таким образом у меня получилось устройство /dev/md2p1. Дальше я успешно смонтировал этот раздел в /mnt и получил доступ к данным. Они все были на месте.
В заключении я к этой же системе подмонтировал сетевой диск через cifs и начал копировать данные.
Как заменить вышедший из строя накопитель RAID 1 в Linux?
Эту часть статьи очень важно прочесть начинающим пользователям, так как часто они не умеют правильно заменять поломанный диск и либо запускают процесс инициализации массива, либо перестраивают массив заново. Каждое из этих действий неизменно ведет к потере данных.
Прежде всего, вам следует ознакомится с процессом замены диска для вашего уровня, так как процедура замены будет отличаться в зависимости от типа контроллера и уровня RAID массива. Например, в первую очередь ознакомитесь поддерживает ли ваш контроллер горячую замену диска, так как от этого зависит то, будете ли вы отключать питание массива.
Итак, процедура замены поврежденного диска в RAID 1 выглядит следующим образом:
-
Сделайте резервную копию всех важных данных, так как пользователи часто теряют информацию именно в процессе замены поврежденного диска.
Если ваш RAID 1 массив находится в рабочем состоянии – вы можете просто скопировать нужные файлы в другое место. Если же ваш массив выдал ошибку и не запускается – восстановите данные с помощью – RS RAID Retrieve. Процесс восстановления информации детально расписан в последнем пункте этой статьи.
Стоит отметить, что sdb2 это диск, который подключен к второму SATA порту. На всякий случай напомним, что в операционной системе Linux диски идентифицируются следующим образом:
sd – буквы, которые обозначают тип подключения SATA; a – номер диска. Например, a – это первый диск, b – второй, c – третий и т.д. 2 – это номер раздела на диске;
То есть sda2 это второй раздел на первом SATA диске.
где /dev/sda2 — это источник, а /dev/sdb — новый диск, на который копируется таблица разделов.
Если в вашей системе sfdisk отсутствует – установить ее можно выполнив в терминале команду:
После этого, начнется процесс перестройки вашего массива. Ни в коем случае не отключайте питание пока он не закончится. После того, как новый диск будет добавлен – вы снова сможете использовать ваш RAID 1 массив как и раньше.
2.3. Случайная инициализация RAID массива
Под инициализацией RAID массива подразумевается первоначальная настройка, сборка и запуск массива. То есть диски форматируются, и на них создается новая логическая структура. Естественно это ведёт к потере всех данных.
К сожалению, в такой ситуации встроенные средства Linux никакой пользы не приносят, а еще больше усугубляют ситуацию.
Чтобы понять почему это так следует разобраться как именно операционная система удаляет данные.
При удалении информации Linux не удаляет данные физически, а только ссылку на файл, делая его невидимым и тем самым позволяя перезаписать его другими данными. (К стати это является причиной, почему информация удаляется намного быстрее чем записываются).
Соответственно, каждая лишняя манипуляция повышает риск перезаписи важного файла другими данными.
К сожалению, в Linux пока что отсутствует утилита для восстановления информации, однако, если использовать RS RAID Retrieve — вы без проблем можете сохранить данные и восстановить работоспособность вашего массива.
Таким образом, как только обнаружили проблему с дистрибутивом Linux или с RAID массивом — немедленно восстановите данные в безопасное место при помощи RS RAID Retrieve.
Стоит отметить, что чаще всего инициализация RAID массива происходит из-за действий пользователя. Реже — из-за системных сбоев Linux.
Поэтому проводите только те операции, в которых вы на 100% уверенны и регулярно обслуживайте ваш Linux дистрибутив.
2.2. Проблемы с RAID контроллером в Linux
RAID-контроллер является самым важным элементом RAID массива. В некоторых случаях даже более важным, чем сами диски. Именно он занимается распределением данных между дисками, помнит порядок дисков и местоположение начальных блоков данных, с которых начинается чтение всей информации, и многое другое.
Соответственно, если что-то случится с диском вы с лёгкостью сможете его заменить. Но если что-то случится с контроллером — упадёт весь RAID массив независимо от его типа и количества дисков.
Проблема в том, что операционная система Linux не будет знать где хранится начальный блок информации и соответственно не сможет собрать RAID массив.
Естественно, что команда принудительного сбора массива не работает.
Восстановить сломанный RAID контроллер при помощи встроенных средств Linux нельзя. Нету смысла даже пытаться. Тут однозначно нужно профессиональное по для восстановления RAID массивов. Мы рекомендуем RS RAID Retrieve. Процесс восстановления был детально расписан в предыдущем пункте этой статьи.
Чаще всего RAID массивы ломаются именно из-за выхода из строя контроллера. Особенно это актуально для программных RAID контроллеров, поскольку они целиком и полностью зависят от работоспособности операционной системы.
Таким образом, чтобы предотвратить поломки RAID контроллера используйте только лицензионное программное обеспечение и тщательно следите за состоянием вашего дистрибутива Linux.
Основной причиной поломок контроллера являются перепады напряжения и резкое отключение питания. Реже — проблемы с дистрибутивом Linux.
Стоит отметить, что аппаратные RAID контролеры обычно обладают встроенным аккумулятором. Благодаря этому, они менее чувствительны к перепадам напряжения. Но и стоят они на порядок дороже. Ведь как ни крути — программный RAID контроллер практически бесплатный.
Часто задаваемые вопросы
Не обязательно. Все зависит от типа контроллера, который вы используете. Так например многие аппаратные контроллеры поддерживают функцию горячей замены диска. Однако, мы рекомендуем отключать питание, если есть такая возможность. Это позволит более безопасно работать с накопителями.
Мой RAID 1 массив перестал запускаться. Сможет ли RS RAID Retrieve восстановить ценную для меня информацию?
Да. RS RAID Retrieve восстановит ваши данные. Процесс восстановления информации детально расписан на нашем сайте.
Среди наиболее значимых недостатков массива RAID 1 можно выделить низкую скорость записи данных и высокую цену за Гигабайт памяти.
Максимальное количество дисков в массиве RAID 1 ограничено только мощностью вашего компьютера/сервера/NAS, так как чем большее количество дисков используется, тем ниже будет скорость записи информации. При слишком большом количестве накопителей из за нехватки вычислительной мощности контроллера скорость записи может упасть настолько, что массивом будет очень неудобно пользоваться.
Замена диска
В случае выхода из строя одного из дисков массива, команда cat /proc/mdstat покажет следующее:
Personalities : [raid1]
md0 : active raid1 sdb[0]
1046528 blocks super 1.2 [2/1] [U_]
* о наличии проблемы нам говорит нижнее подчеркивание вместо U — [U_] вместо [UU].
.
Update Time : Thu Mar 7 20:20:40 2019
State : clean, degraded
.
* статус degraded говорит о проблемах с RAID.
Для восстановления, сначала удалим сбойный диск, например:
mdadm /dev/md0 --remove /dev/sdc
Теперь добавим новый:
mdadm /dev/md0 --add /dev/sde
Смотрим состояние массива:
.
Update Time : Thu Mar 7 20:57:13 2019
State : clean, degraded, recovering
.
Rebuild Status : 40% complete
.
* recovering говорит, что RAID восстанавливается; Rebuild Status — текущее состояние восстановления массива (в данном примере он восстановлен на 40%).
Если синхронизация выполняется слишком медленно, можно увеличить ее скорость. Для изменения скорости синхронизации вводим:
echo '10000' > /proc/sys/dev/raid/speed_limit_min
* по умолчанию скорость speed_limit_min = 1000 Кб, speed_limit_max — 200000 Кб. Для изменения скорости, можно поменять только минимальную.
О Den Broosen
Автор и инженер компании RecoverySoftware. В статьях делится опытом восстановлению данных на ПК и безопасному хранению информации на жестких дисках и на RAID массивах .
mdadm — утилита для работы с программными RAID-массивами различных уровней. В данной инструкции рассмотрим примеры ее использования.
Причины выхода массива RAID 1 из строя
Причин, способных вывести RAID 1 из строя не так уж и много, однако они существуют. Первой и одной из наиболее значимых являются перепады электричества и внезапное отключение питания. Из-за перебоев с электричеством нередко выходит из строя контроллер, который отвечает за распределение данных.
Для того, чтобы восстановить работоспособность массива придется использовать контроллер точно такой же фирмы или операционной системы, так как они не взаимозаменяемы, ведь восстановить данные просто подключив накопитель как обычный диск не получится.
Кроме того, нет никакой гарантии, что после замены контроллера (даже если это будет точно такая же модель) данные снова будут доступны. Все дело в том, что в новый контроллер может не «знать», где именно на диске находится начальный блок информации и не сможет правильно построить RAID массив.
В такой ситуации лучше извлечь данные с накопителей, создать массив заново и скопировать данные из восстановленной копии обратно. О том, как восстановить данные с массива RAID 1 читайте в последнем пункте этой статьи.
Иногда бывают случаи, когда перепады электроэнергии выводят из строя сразу все диски. В такой ситуации процесс восстановления данных сильно усложняется, так как нужно сначала устранить физическую проблему накопителя заменив сломанные детали и уже тогда приступать к восстановлению данных.
Еще одной причиной потери информации (и, пожалуй, самой распространенной) является человеческий фактор. Нередко системные администраторы халатно относятся к своей работе из-за чего пользователи теряют важные данные как следствие случайного удаления или форматирования целого массива диска или раздела. В этой ситуации вернуть данные штатным способом не получится. Придется использовать стороннее ПО для восстановления данных.
Принцип работы массива RAID 1
RAID 1 являет собой тип дискового массива, в котором каждый накопитель является точной копией предыдущего. Именно поэтому его еще называют «зеркалированием». То есть это не резервная копия данных, а избыточность томов на дисках. Когда производится запись информации – контроллер одновременно записывает ее на несколько дисков (а не на один как обычно). Отсюда сильное снижение скорости записи данных. Например, если запись архива размером 10 ГБ на обычный жесткий диск занимает 5 мин, то запись этого же файла на массив RAID 1, состоящий из трех дисков займет 15 мин соответственно (так как система запишет 30 ГБ данных (три раза по 10 ГБ)). В то же время, считывание информации будет происходить в три раза быстрее, так как информация считывается одновременно с трех дисков (как в случае с RAID 0). Принцип записи информации изображен на иллюстрации ниже.
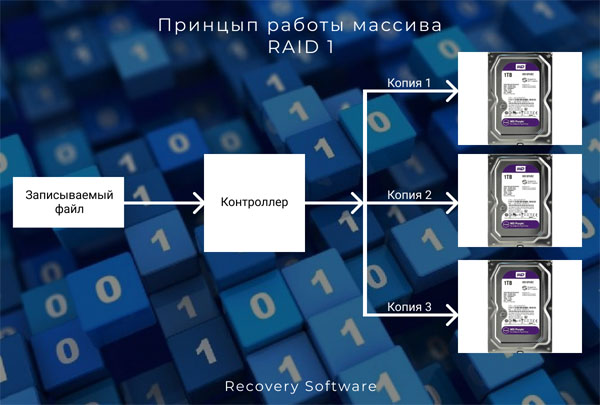
Отсюда можно сделать вывод, что массив RAID 1 подходит для пользователей, которые хранят ценную информацию и заботятся о ее сохранности в первую очередь, не смотря на низкую скорость записи данных. Поэтому, если для вас важны скорость передачи информации – вам стоит присмотреться к другим типам RAID. О всех преимуществах и недостатках разных конфигураций RAID массивов вы можете прочесть в статье «RAID — типы массивов, их преимущества и недостатки»
Восстановление RAID
Рассмотрим два варианта восстановлении массива.
Что делать если RAID 1 не может активировать Spare Disk (запасной диск)?
Операционная система Linux поддерживает добавление так называемых Spare дисков. Spare Disk — это накопитель, который используется в массиве как запасной и в случае поломки одного из дисков он автоматически задействуется и все данные копируются на него.
Случаться это может по следующим причинам:
Как заменить вышедший из строя накопитель RAID 1 в Windows?
В операционной системе Windows, если диск массива выходит из строя, то в диспетчере дисков он получает статус неисправного накопителя «Отказавшая избыточность».
Алгоритм замены диска выглядит следующим образом:
- Сделайте резервную копию всех важных файлов, чтобы не потерять информацию, в случае если что-то пойдет не так.
- Отключите питание, затем замените поврежденный накопитель на новый. После этого снова включите питание компьютера. Щелкните правой кнопкой мыши по «Пуск» и выберите «Управление дисками».
После этого появится окно с предупреждением, что выбранные диски буду конвертированы в динамические. Нажмите «ОК», после чего ваш новый диск будет успешно добавлен к массиву RAID 1.
Установка mdadm
Утилита mdadm может быть установлена одной командой.
Если используем CentOS / Red Hat:
yum install mdadm
Если используем Ubuntu / Debian:
apt-get install mdadm
Содержание:
Операционная система Linux позволяет работать как с аппаратными RAID массивами, так и с программными. Причем Linux изначально поддерживает несколько основных типов RAID массивов. Больше информации об уровнях RAID вы можете найти в статье «RAID массивы — что это такое, типы, как использовать?»
Если вы хотите узнать больше информации о создании программного RAID в Linux — вы можете прочесть статью «Как создать программный RAID массив в операционной системе Linux?» В этой же статье вы найдете инструкцию по созданию комбинированных типов RAID (например, RAID 10).
Содержание:
Многие пользователи, которые беспокоятся о сохранности важных данных выбирают массив RAID 1 в качестве основного хранилища. Например, этот тип RAID используют финансисты для хранения финансовых отчетов и небольших баз данных, которые они используют в своей повседневной работе и которые имеют большое значение. Это объясняется высокой надежностью массива RAID 1. В то же время, несмотря на всю кажущуюся надежность нельзя пренебрегать резервным копированием важных данных, ведь даже RAID 1 не способен гарантировать сохранность данных. Для того, чтобы разобраться почему это так – давайте рассмотрим устройство массива RAID 1, преимущества и недостатки, а также возможные риски потери важной информации.
Ситуации, когда лучше сразу же использовать RS RAID Retrieve и причины их возникновения.
Как уже упоминалось выше иногда возникают ситуации, когда лучше не тратить свое время зря и сразу же использовать профессиональные приложения сторонних разработчиков для восстановления работоспособности RAID массива. Примеры таких ситуаций описаны ниже.
Восстановление mdadm массива
Установил в live систему mdadm:
Первым делом проверил суперблоки на восстановленном разделе:

На вид все было в порядке. Дальше рассчитывал сразу найти массив и примонтировать его.

Тут я приуныл, потому что не мог понять, в чем проблема. Пробовал разные команды для запуска массива, но он упорно не стартовал. При этом на вид все было в порядке. Потом в какой-то момент я додумался посмотреть dmesg.

Решение этой ошибки достаточно быстро нагуглилось.

После этого массив нормально стартовал и cat /proc/mdstat показывал его состояние. Тут я думал, что мои мучения окончены и я сейчас получу свои данные. Но это тоже было еще не все.
Создание файловой системы и монтирование массива
Создание файловой системы для массива выполняется также, как для раздела:
* данной командой мы создаем на md0 файловую систему ext4.
Примонтировать раздел можно командой:
mount /dev/md0 /mnt
* в данном случае мы примонтировали наш массив в каталог /mnt.
Чтобы данный раздел также монтировался при загрузке системы, добавляем в fstab следующее:
/dev/md0 /mnt ext4 defaults 1 2
Для проверки правильности fstab, вводим:
Мы должны увидеть примонтированный раздел md, например:
/dev/md0 990M 2,6M 921M 1% /mnt
You are in emergency mode
У меня много примеров того, как я восстанавливал загрузку сломавшихся linux дистрибутивов.
В данной ситуации с mdadm я был уверен, что все получится, так как сам массив с системой жив, данные доступны. Надо только разобраться, почему система не загружается. Напомню, что ошибка загрузки была следующая.
Дальше нужно ввести пароль root и вы окажетесь в системной консоли. Первым делом я проверил состояние массива mdadm.
Состояние массива md0, на котором располагается раздел /boot - inactive. Вот, собственно, и причина того, почему сервер не загружается. Судя по всему, когда был подключен сбойный диск, mdadm отключил массив, чтобы предотвратить повреждение данных. Не понятно, почему именно на разделе /boot, но по факту было именно это. Из-за того, что массив остановлен, загрузиться с него не получалось. Я остановил массив и запустил снова.
После этого массив вышел из режима inactive и стал доступен для дальнейшей работы с ним. Я перезагрузил сервер и убедился, что он нормально загружается. Сервер фактически был в рабочем состоянии, просто с развалившимся массивом mdadm, без одного диска.
Если вам это не поможет, предлагаю еще несколько советов, что можно предпринять, чтобы починить загрузку. Первым делом проверьте файл /etc/fstab и посмотрите, какие разделы и как там монтируются. Вот мой пример этого файла.
Вам нужно убедиться, что указанные lvm разделы /dev/mapper/vg0-root и /dev/mapper/vg0-swap_1 действительно существуют. Для этого используйте команду:
Подробно об этой команде, о работе с lvm и вообще с дисками я рассказываю в отдельной статье - настройка диска в debian. Если с lvm разделами все нормально, проверьте /boot. У меня он монтируется по uuid. Посмотреть список uuid всех разделов можно командой.
Как вы видите, у меня uuid раздела для загрузки полностью совпадает с тем, что указано в fstab. Если по какой-то причине uuid изменился (разобрали и собрали новый массив), отредактируйте fstab.
Все дальнейшие действия я делал уже по ssh. Скопировал таблицу разделов с рабочего диска sda на чистый sdb.
Проверил таблицы разделов и убедился, что они идентичные.

Скопировал раздел BIOS boot partition с рабочего диска на новый.
Потом добавил разделы диска sdb2 и sdb3 в рейд массив.
Дождался окончания ребилда и убедился, что он прошел. Проверил состояние массива.

В завершении устанавливаем загрузчик на оба диска.
После этого я перезагрузился и убедился, что все работает нормально. По хорошему, теперь надо было бы поменять загрузочный диск с первого на второй и убедиться, что со второго тоже нормально грузится. Я не стал этого делать, и так простой и так был велик. Главное, чтобы массив был на месте, а починить загрузку, если что, дело техники.
Вот и все по замене диска в массиве mdadm. После доступа к консоли сервера, мне потребовалось минут 10, чтобы вернуть сервер в рабочее состояние.
Введение
Симптомы поломки были следующие. Заметил, что пропал сетевой диск. Зашел на сервер и увидел, что диск не инициализирован. Таблица разделов пустая. При этом, диск работал нормально и SMART ошибок не показывал. Я сразу заподозрил, что проблема именно с таблицей разделов. Данные должны быть на месте.
Дополнительная важная информация - диск был в составе mdadm массива, состоящим из одного диска. LVM не использовался.
Я подключил сбойный диск в обычный системник. Сделал загрузочную флешку с Ubuntu Live CD и загрузился с нее. Настроил там сеть, стандартные репозитории.
Создание рейда
Для сборки избыточного массива применяем следующую команду:
mdadm --create --verbose /dev/md0 -l 1 -n 2 /dev/sd
- /dev/md0 — устройство RAID, которое появится после сборки;
- -l 1 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd — сборка выполняется из дисков sdb и sdc.
Мы должны увидеть что-то на подобие:
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
mdadm: size set to 1046528K
Также система задаст контрольный вопрос, хотим ли мы продолжить и создать RAID — нужно ответить y:
Continue creating array? y
Мы увидим что-то на подобие:
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
. и находим информацию о том, что у наших дисков sdb и sdc появился раздел md0, например:
.
sdb 8:16 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
sdc 8:32 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
.
* в примере мы видим собранный raid1 из дисков sdb и sdc.
Проверка целостности
Для проверки целостности вводим:
echo 'check' > /sys/block/md0/md/sync_action
Результат проверки смотрим командой:
* если команда возвращает 0, то с массивом все в порядке.
echo 'idle' > /sys/block/md0/md/sync_action
Введение
Когда первый раз сталкиваешься с рукожопством сотрудников техподдержки дата центра, впадаешь в ступор и думаешь, ну как так то? Сейчас я спокойно отношусь к таким ситуациям и действую исходя из самых худших ожиданий. На днях я столкнулся с ситуацией, когда мне заменили не тот диск в сервере с RAID1. Вместо сбойного диска вынули рабочий и заменили чистым. К счастью все закончилось хорошо, но обо всем по порядку.
Не скажу, что у меня прям большой опыт аренды серверов, но он есть. Я регулярно обслуживаю 10-15 серверов, расположенных в разных дата центрах, как российских, так и европейских. Первый негативный опыт я получил именно в Европе и был очень сильно удивлен и озадачен. Я, как и многие, был под влиянием либеральной пропаганды на тему того, что у нас все плохо, а вот Европа образец надежности, стабильности и сервиса. Как же я ошибался. Сейчас отдам предпочтение нашим дата центрам. По моему мнению и опыту, у нас тех поддержка и сервис в целом лучше, чем там, без привязки к стоимости. В Европе дешевле схожие услуги, так как там масштабы сервисов в разы больше.
Приведу несколько примеров косяков саппорта, с которыми сталкивался.
Было много всяких инцидентов помельче, нет смысла описывать. Хотя нет, один все же опишу. Устанавливал свой сервер в ЦОД. Решил пойти в маш зал и проконтролировать монтаж. Если есть такая возможность, крайне рекомендую ей воспользоваться. Местный рукожоп неправильно прикрепил салазки и сервер во время монтажа стал падать. Я его поймал, тем спас его и сервера других клиентов. В итоге помог с монтажом. Сам бы он просто не справился. Я не представляю, что было, если бы я не пошел в машзал. К чести руководства, я написал претензию, где подробно описал данный случай и попросил бесплатно месячную аренду. Мне ее предоставили. Советую всем так поступать. Зачастую, руководство может быть не в курсе того, что происходит в реальности. Надо давать обратную связь.
Уровень моего доверия к тех поддержке дата центров и хостингов вы примерно представляете :) Ну и вот случилось очередное ЧП. Подробнее остановлюсь на этой ситуации, так как она случилась вчера, свежи воспоминания.
Пересборка массива
Если нам нужно вернуть ранее разобранный или развалившийся массив из дисков, которые уже входили в состав RAID, вводим:
mdadm --assemble --scan
* данная команда сама найдет необходимую конфигурацию и восстановит RAID.
Также, мы можем указать, из каких дисков пересобрать массив:
mdadm --assemble /dev/md0 /dev/sdb /dev/sdc
Часто задаваемые вопросы
Это возможно, но это очень сложно. Кроме того, на практике суперблок можно восстановить примерно в 40% случаев. Многое зависит от вашей файловой системы. Поэтому имеет смысл использовать профессиональное программное обеспечение для восстановления RAID.
Встроенные средства Linux не будут работать при сбое суперблока RAID 0, сбое контроллера RAID, случайной инициализации RAID и т. д. То есть, как только возникнут более серьезные проблемы с RAID-массивом, лучше всего использовать профессиональные RAID программное обеспечение для восстановления прямо сейчас.
Воспользуйтесь программой для восстановления RAID, чтобы восстановить работоспособность массива RAID. Процесс восстановления прост.
Сначала остановите массив RAID с помощью «$ sudo mdadm --stop /dev/md2», а затем запустите «$ sudo mdadm --assemble --scan -force», чтобы автоматически собрать массив. Если ничего не помогает - на нашем сайте вы найдете инструкцию, как пересобрать RAID-массив.

Удаление массива
При удалении массива внимателнее смотрите на имена массива и дисков и подставляйте свои значения.
Если нам нужно полностью разобрать RAID, сначала размонтируем и остановим его:
* где /mnt — каталог монтирования нашего RAID.
* где /dev/md0 — массив, который мы хотим разобрать.
* если мы получим ошибку mdadm: fail to stop array /dev/md0: Device or resource busy, с помощью команды lsof -f -- /dev/md0 смотрим процессы, которые используют раздел и останавливаем их.
Затем очищаем суперблоки на всех дисках, из которых он был собран:
mdadm --zero-superblock /dev/sdb
mdadm --zero-superblock /dev/sdc
mdadm --zero-superblock /dev/sdd
* где диски /dev/sdb, /dev/sdc, /dev/sdd были частью массива md0.
Хочу рассказать поучительную историю, которая случилась со мной на днях. На одном из серверов в ЦОД вышел из строя диск в составе рейда mdadm. Ситуация типовая, с которой регулярно сталкиваюсь. Оставил заявку в техподдержку на замену диска с указанием диска, который надо поменять. В цоде заменили рабочий диск и оставили сбойный. Дальше история, как я решал возникшую проблему.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курcе по администрированию MikroTik. Автор курcа, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Замена диска в рейде mdadm

Речь пойдет о дешевых дедиках от selectel. Я их много где использую и в целом готов рекомендовать. Это обычные десктопные системники за скромные деньги. Свое мнение об этих серверах, а так же сравнение с полноценными серверами сделаю в конце, в отдельном разделе.
На сервере была установлена система Debian из стандартного шаблона Selectel. Вот особенности дисковой подсистемы этих серверов и шаблона.
- 2 ssd диска, объединенные в mdadm
- /boot раздел на /dev/md0 размером 1G
- корень / на /dev/md1 и поверх lvm на весь массив
В целом, хорошая и надежная разбивка, чему будет подтверждение дальше. На сервере был установлен proxmox, настроен мониторинг mdadm. Мониторинг дисков не сделал. В какой-то момент получил уведомление в zabbix, что mdadm развалился. Сервер при этом продолжал работать. Ситуация штатная. Пошел в консоль сервера, чтобы все проверить. Посмотрел состояние рейда.
Убедился, что один диск выпал из массива. В системном логе увидел следующее.

Попробовал посмотреть информацию о выпавшем диске.
Информации не было, утилита показывала ошибку обращения к диску. Получилось посмотреть модель и серийный номер только работающего диска.
Я не стал разбираться, что там к чему с диском. Если вижу проблемы, сразу меняю. Предупредил заказчика, что с диском проблемы, нужно планировать замену. Так как железо десктопное, "сервер" надо выключать. Согласовали время после 22 часов. Я в это время уже сплю, поэтому написал тикет в тех поддержку, где указал время и серийный номер диска, который нужно было оставить. Я сделал на этом акцент, объяснил, что сбойный диск не отвечает, поэтому его серийник посмотреть не могу. Расписал все очень подробно, чтобы не оставить почвы для недопонимания или двойного толкования. Я в этом уже спец, но все равно не помогло.
Я спокойно согласился на эту операцию, потому что часто делаются бэкапы и они гарантированно рабочие. Настроен мониторинг бэкапов и делается регулярное полуручное восстановление из них. Договоренность была такая, что хостер после замены дожидается появления окна логина, а заказчик проверяет, что сайт работает. Все так и получилось - сервер загрузился, виртуалки поднялись, сайт заработал. На том завершили работы.
Утром я встал и увидел, что весь системный лог в ошибках диска, рабочего диска в системе нет, а есть один глючный и один новый. Сразу же запустил на всякий случай ребилд массива и он вроде как даже прошел без ошибок. Перезагрузка временно оживила сбойный диск. В принципе, на этом можно было бы остановиться, заменить таки сбойный диск и успокоиться. Но смысл в том, что этот сбойный диск почти сутки не был в работе и данные на нем старые. Это не устраивало. Потом пришлось бы как-то склеивать эти данные с данными из бэкапов. В случае с базой данных это не тривиальная процедура. Созвонился с заказчиком и решили откатываться на рабочий диск, который вытащили накануне ночью.
Я создал тикет и попросил вернуть рабочий диск на место. К счастью, он сохранился. К нему добавить еще один полностью чистый. Хостер оперативно все сделал и извинился. В завершении прислал скриншот экрана сервера.
И самоустранился. Дальше решать проблему загрузки он предложил загрузившись в режиме rescue. Этот режим доступен через панель управления сервером в админке, даже если сервер не имеет ipmi консоли. Как я понял, по сети загружается какой-то live cd для восстановления. Я в нем загрузился, убедился, что данные на месте, но понять причину ошибки не смог. Может быть и смог бы, если бы дольше покопался, но это очень неудобно делать, не видя реальной консоли сервера. Я попросил подключить к серверу kvm over ip, чтобы я мог подключиться к консоли. Тех поддержка без лишних вопросов оперативно это сделала.
К слову, мне известны случаи, когда техподдержка selectel потом сама чинила загрузку и возвращала mdadm в рабочее состояние. Видел такие переписки в тикетах у своих клиентов до того, как они обращались ко мне. Но я не стал настаивать на таком решении проблемы, так как боялся, что будет хуже. К тому же это было утро воскресенья и специалистов, способных это сделать, могло просто не быть. Плюс, я не думаю, что они обладали бы большими компетенциями, чем я. Я бы за их зарплату не пошел работать в ЦОД.
После того, как я подключился к консоли сервера, восстановление загрузки было делом техники.
Заключение
Надеюсь, моя статья была интересной. Для тех, кто никогда не работал с ЦОДами будет полезно узнать, чего можно от них ожидать. Я скучаю по временам, когда все сервера, которые я администрировал, были в серверной, куда никому не было доступа и куда я мог в любой момент попасть и проверить их. Сейчас все стало не так. И твои сервера уже не твои. Их может сломать, уронить, что-то перепутать сотрудник тех поддержки дата центра.
Сейчас большой тренд на переход в облака. Я смотрю на эти облака и не понимаю, как с ними можно нормально взаимодействовать. Заявленная производительность не гарантированная, нагрузка плавает в течении суток. Упасть может в любой момент и ты не будешь понимать вообще в чем проблема. Твои виртуалки могут быть по ошибке удалены и кроме извинений и компенсации в 3 копейки ты ничего не получить. Каждое обращение в ТП как лотерея. Думаешь, что сломают в этот раз. Если сервера железные, то когда пишу тикет на доступ к железу, я морально и технически всегда готов к тому, что этот сервер сейчас отключится и я больше не смогу к нему подключиться.
В целом, опыт работы с облаками у меня негативный. Несколько раз пробовал для сайтов и все время съезжал. Нет гарантированного времени отклика. А это сейчас фактор ранжирования. Для очень быстрого сайта остается только один вариант - свое железо, а дальше уже кому какое по карману. Зависит от надежности и допустимого времени простоя.
Я про облака заговорил, потому что тенденции к тому, что от железных серверов надо отказываться и все переносить в облака. С одной стороны удобно должно быть. Как минимум, не будет указанных выше в статье проблем. А с другой стороны добавляется куча других проблем. Я пока сижу на железяках разного качества и стоимости. А у вас как?
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите подробнее программу ссылке.
В моем домашнем NAS внезапно отказал один из дисков. Это был единственный диск не в raid, данные на котором вроде как не важные (торренты, софт и т.д., все, что можно заново выкачать из инетрнета), поэтому диск не дублировался. Ничего критичного не произошло, но мне все равно стало жалко данные, поэтому я заменил диск, а этот отложил в сторонку, чтобы попытаться восстановить информацию. У меня это получилось, поэтому решил задокументировать результат, чтобы самому не забыть и с вами поделиться.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужно пройти вступительный теcт.
Запасной диск (Hot Spare)
Если в массиве будет запасной диск для горячей замены, при выходе из строя одного из основных дисков, его место займет запасной.
Диском Hot Spare станет тот, который просто будет добавлен к массиву:
mdadm /dev/md0 --add /dev/sdd
Информация о массиве изменится, например:
.
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
2 8 48 1 active sync /dev/sdc
3 8 32 - spare /dev/sdd
Проверить работоспособность резерва можно вручную, симулировав выход из строя одного из дисков:
mdadm /dev/md0 --fail /dev/sdb
И смотрим состояние:
.
Rebuild Status : 37% complete
.
Number Major Minor RaidDevice State
3 8 32 0 spare rebuilding /dev/sdd
2 8 48 1 active sync /dev/sdc
0 8 16 - faulty /dev/sdb
.
* как видим, начинается ребилд. На замену вышедшему из строя sdb встал hot-spare sdd.
Заключение
Непонятной осталась причина сбоя, и это хуже всего. На вид все в порядке, но я теряю доступ к данным. Любой другой пользователь, не разбирающийся в linux, просто потерял бы данные, либо пришлось обращаться в специализированные фирмы по восстановлению информации, а это стоит дорого. И еще, как я понял, я точно так же мог потерять доступ и к массиву из нескольких дисков. К слову, потерпевший NAS это Synology, где под капотом обычный linux и mdadm, поэтому я понимал, как надо действовать. На этом же устройстве есть несколько массивов на много Tb и если бы кто-то из них сглючил, то было бы плохо.
Несколько моих статей по восстановлению загрузки linux после различных сбоев:
Надеюсь, вам они не пригодятся.
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, научиться непрерывной поставке ПО, мониторингу и логированию web приложений, рекомендую познакомиться с онлайн-курсом «DevOps практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Проверьте себя на вступительном тесте и смотрите подробнее программу ссылке.
Массив RAID 1 это, пожалуй, самый надежный тип RAID, однако даже он может выходить из строя. В этой статье мы рассмотрим, главные причины выхода из строя и как восстановить данные c RAID 1 массива в случае непредвиденных ситуаций его работе.
Восстановление таблицы разделов
Я давно знаю утилиту testdisk. С ее помощью мне уже удавалось восстанавливать данные в linux. Она есть в репозиториях ubuntu, так что я ее установил. Далее все было просто. К сожалению, скриншотов нет, так как делал все на отдельном системнике. Расскажу на словах, что сделал:
- Запустил утилиту. Она вывела список всех подключенных дисков. В моем случае диск был /dev/sda.
- Выбрал нужный диск, указал в выборе partition table types первый вариант - Intel.
- Запустил сканирование. Утилита нашла разделы, которые там были ранее. Я прикинул, вроде бы то, что и должно быть.
- Записал таблицу разделов на диск.
Далее через fdisk я увидел разделы диска sda, в том числе тот, что меня интересовал - Linux raid autodetect.

Если восстанавливаете таблицу разделов обычного диска, то уже сейчас можно было бы смонтировать найденный раздел и попытаться прочитать данные. В моем же случае, нужно было собрать mdadm массив и подмонтировать уже его. Вот тут и начались самые сложности, с которыми больше всего провозился.
2.4. Ошибки сбора RAID массива
Иногда пользователи могут наблюдать ситуацию, когда RAID-массив не хочет собираться. В некоторых случаях помогает команда:
Инструкцию по применению команды и восстановлению автоматической сборки RAID массива после перезагрузки вы можете найти в статье «Как собрать программный RAID в linux?»
Но, к сожалению, довольно часто собрать RAID массив так и не удается, а встроенные средства Linux абсолютно бессильны. В такой ситуации однозначно лучше не тратить время зря и сразу же обратиться к профессиональной программе для восстановления работоспособности RAID массивов от сторонних разработчиков. О том, как проще всего восстановить сломанный RAID массив вы можете прочесть в первом пункте этой статьи.
Цели статьи
- Рассказать поучительную историю о том, какие могут быть проблемы при аренде серверов в ЦОД.
- Показать на примере, как надо действовать при выходе из строя диска в рейде mdadm.
- Простыми словами объяснить, в чем разница между программным и аппаратным рейдом.
В чем отличия программного и аппаратного рейда
Сейчас расскажу, чем принципиально отличается программный рейд контроллер (mdadm) от аппаратного, для тех, кто этого до конца не понимает. Если бы у меня вышел из строя диск на аппаратном рейд контроллере, установленном в полноценный сервер, проблема по замене сбойного диска в RAID решалась бы в следующей последовательности:
- Рейд контроллер оповещает о том, что с диском проблемы и выводит его из работы. В случае с софтовым рейдом система может зависнуть в случае проблем с диском, прежде чем пометит его как проблемный и перестанет к нему обращаться.
- Я оставляю тикет в тех поддержку, где прошу заменить сбойный диск. Информацию о нем я посмотрю в панели управления рейд контроллером.
- Сотрудник тех поддержки видит сбойный диск, так как индикация на нем, скорее всего, будет мигать красной лампочкой. Это не гарантия того, что рукожоп все сделает правильно, но тем не менее, шансов, что он ошибется, меньше. Я сталкивался с ситуацией, когда и в этом случае диск меняли не тот.
- При появлении нового диска raid контроллер автоматически начинает ребил массива.
Если же у вас в сервере уже установлен запасной диск на случай выхода из строя диска в составе raid массива, то все еще проще:
- При выходе из строя диска, контроллер помечает его как сбойный, вводит в работу запасной диск и начинает ребилд.
- Вы получаете оповещение о том, что вышел из строя диск и оставляете тикет в тех поддержку на замену запасного диска.
И это все. В обоих случаях у вас вообще нет простоя. Вот принципиальная разница между mdadm и железным raid контроллером. Стоимость полноценного сервера с контроллером и постоянным ipmi доступом к консоли в среднем в 3 раза выше, чем у сервера на десткопном железе с софтовым рейдом при схожей производительности. Это все при условии, что вам достаточно одного процессора и 64G памяти. Это потолок для десктопных конфигураций. Дальше считайте сами, что вам выгоднее. Если возможен простой в несколько часов на замену диска или других комплектующих, то смело можно использовать десктопное железо. Mdadm обеспечивает сопоставимую гарантию сохранности данных в сравнении с железным контроллером. Вопрос лишь в простое и производительности. Ну и своевременные бэкапы добавляют уверенности в том, что вы переживете неполадки с железом.
При использовании железного рейда на hdd дисках, есть возможно получить очень значительный прирост скорости за счет кэша контроллера. Для ssd дисков я особо не замечал разницы. Но это все на глазок, никаких замеров и сравнений я не делал. Нужно еще понимать, что десктопное железо в целом менее надежное. К примеру, в том же селектеле на дешевых серверах я ловил перегрев или очень высокую температуру дисков. Прыгала в районе 55-65 градусов. Все, что ниже 60-ти, тех поддержка футболила, говоря, что это допустимая температура, судя по документации к дискам. Это так и есть, но мы же понимаем, что диск, постоянно работающий на 59 градусах с бОльшей долей вероятности выйдет из строя.
Вот еще пример разницы в железе. Если у вас в нормальном сервере выйдет из строя планка памяти, сервер просто пометит ее как сбойную и выведет из работы. Информацию об этом вы увидите в консоли управления - ilo, idrac и т.д. В десктопном железе у вас просто будет постоянно виснуть сервер и вам придется долго выяснять, в чем же проблема, так как доступа к железу у вас нет, чтобы проще было запланировать тестирование сервера. А если вы закажете это у тех поддержки, то есть ненулевая вероятность, что станет хуже - сервер уронят, перепутают провода подключения дисков и т.д. В общем, это всегда риск. Проще сразу съезжать с такой железки на другую.
2.1. Проблемы с суперблоком в Linux
Актуально только для массивов без избыточности (RAID 0). Часто операционная система Linux автоматически удаляет суперблок на диске, причём предвидеть удаления невозможно. Причины могут быть самыми разными, начиная от действий пользователя и заканчивая сбоями в самой операционной системе. Кроме того, часто причинами удаления суперблока являются перебои электропитания, которые в свою очередь приводят к системным сбоям, повреждающим суперблок.
Чтобы предотвратит повреждение суперблока тщательно следите за состоянием дисков RAID массива и всей операционной системы.
Нередко причинами сбоев являются логические ошибки или большое количество битых секторов. Соответственно регулярное сканирование дисков явно не будет лишним.
Позаботьтесь также об источники бесперебойного питания. Он поможет защитить вас от многих проблем в будущем.
Позаботьтесь также об источнике бесперебойного питания. Он поможет защитить вас от многих проблем в будущем.
Добавить диск к массиву
В данном примере рассмотрим вариант добавления активного диска к RAID, который будет использоваться для работы, а не в качестве запасного.
Добавляем диск к массиву:
mdadm /dev/md0 --add /dev/sde
4 8 16 - spare /dev/sde
Теперь расширяем RAID:
mdadm -G /dev/md0 --raid-devices=3
* в данном примере подразумевается, что у нас RAID 1 и мы добавили к нему 3-й диск.
Заключение
Если вы обнаружили проблемы с вашим RAID массивом в первую очередь проанализируйте хранились ли важные данные на дисках. Ведь зачастую стоимость информации в разы превышает стоимость оборудования. Более того, нередко потеря данных влечет за собой финансовые потери. Именно поэтому более целесообразно использовать RS RAID Recovery, которая на 100% восстановит утерянные данные, нежели рисковать потерять всю информацию.
Ведь если бы речь не шла о ценной информации можно было бы просто отформатировать диски и заново создать RAID массив, не правда ли? Но на практике, технический прогресс привел к тому, что и с каждым годом данные становятся все более ценными.
Не теряйте ваши данные, а если такое все же произойдет – используйте только профессиональные программы для восстановления вашего RAID массива.
Как восстановить RAID массив если встроенные средства Linux не помогают?
В операционной системе Linux для управления RAID массивом существует утилита под названием mdadm. Она обладает неплохой функциональностью, однако иногда возникают ситуации, когда восстановление RAID массива невозможно при помощи встроенных средств, или же для восстановления нужно потратить огромное количество времени. Особенно это актуально для неопытных пользователей, которые используют RAID массив для домашних целей.
К примеру, нередко возникает ситуация, когда система случайно удаляет суперблок с диска. В результате Linux не знает, как правильно построить RAID массив, и он перестает работать.
Такую ситуацию можно наблюдать при работе с RAID 0, когда пользователь хочет получить максимальную скорость работы за счет чередования.
Казалось бы, проблема не сильно большая, так как некоторые файловые системы создают две копии суперблока (или больше) — в начале и в конце диска. Однако на самом деле, чтобы восстановить суперблок нужно обладать достаточно глубокими знаниями и немалым количеством времени чтобы восстановить работоспособность массива.
К примеру, восстановить суперблок можно использовать следующий алгоритм:
Шаг 1: Запустите терминал. В GNU для этого используется комбинация клавиш «Ctrl + Alt + T»
Шаг 2: В открывшемся терминале выполните следующую команду:
…где ext4 – это ваша файловая система, -n – это параметр, который выводит информацию о файловой системе, в том числе и о копиях суперблока, а /dev/sda1 – это ваш диск.
Важно: размер блока должен быть таким же, как и в оригинальной файловой системе. Если он будет отличаться – метод не сработает.
Шаг 3: На скриншоте выше вы можете наблюдать шесть резервных копий суперблока (каждое число — это номер блока, в котором хранится копия суперблока). Выберите любой из них, а затем выполните команду:
Подсказка: если попытка восстановления завершится неудачей – повторите команду выше для каждой резервной копии сурерблока.
После этого, система восстановит ваш суперблок.
Казалось бы, все предельно просто, но к сожалению, это только в теории так просто. На практике же очень часто этот метод не работает. Более того, при каждой попытке восстановить суперблок – риск потери всех данных на диске становится все выше.
В такой ситуации более разумно использовать стороннее ПО для восстановления RAID массива, так как это позволяет существенно сэкономить время и нервы. Плюс вы получаете практически стопроцентную гарантию восстановления данных.
Лучше всего воспользоваться программой RS RAID Retrieve. Программа невероятно проста в использовании благодаря наличию встроенного RAID конструктора с поддержкой автоматического режима. Он соберет ваш RAID массив самостоятельно.
Если есть такая необходимость — вы можете указать нужные параметры вручную в полуавтоматическом или ручном режиме.
Нельзя не отметить поддержку ВСЕХ современных файловых систем. Благодаря этому, вы сможете извлечь ваши данные и восстановить работоспособность RAID массива независимо от того, в какой операционной системе он работал.
Полный список ситуаций, когда не стоит мучиться и лучше сразу использовать RS RAID Retrieve вы найдете в следующем пункте этой статьи. А пока что давайте рассмотрим, как выглядит процесс восстановления работоспособности RAID массива, независимо от его типа:
Восстановление данных с любых RAID массивов
- Установите и запустите приложение RS RAID Retrieve.
- Выберите тип добавления RAID массива для сканирования. RS RAID Retrieve предлагает на выбор три варианта:
Автоматический режим – позволяет просто указать диски, из которых состоял массив, и программа автоматически определит их порядок, тип массива и остальные параметры;
Поиск по производителю – эту опцию следует выбрать, если вам известен производитель вашего RAID контроллера. Эта опция также автоматическая и не требует каких-либо знаний о структуре RAID массива. Наличие данных о производителе позволяют сократить время на построение массива, соответственно она быстрее предыдущей;
Создание вручную – эту опцию стоит использовать если вы знаете какой тип RAID массива вы используете. В этом случае вы можете указать все параметры, которые вам известны, а те, которых вы не знаете – программа определит автоматически.
После того, как выберите подходящий вариант – нажмите «Далее«
Вам будет доступно две опции: быстрое сканирование и полный анализ массива. Выберите нужный вариант. Затем укажите тип файловой системы, которая использовалась в вашем массиве. Если эта информация вам не известна — отметьте галочкой все доступные варианты как на скриншоте. Стоит отметить, что RS RAID Retrieve поддерживает ВСЕ современные файловые системы.
Когда все настроено — нажмите «Далее«
После нажатия кнопки «Далее» программа начнет процесс восстановления. Когда он завершится — выбранные файлы будут в указанном месте.
После того, как все файлы успешно восстановлены — создайте заново RAID 01 массив, а затем скопируйте файлы обратно.
Как видите, процесс восстановления данных с массива RAID 01 достаточно прост и не требует глубоких знаний ПК, соответственно RS RAID Retrieve является отличным приложением как для профессионалов, так и для начинающих пользователей.
Сборка RAID
Перед сборкой, стоит подготовить наши носители. Затем можно приступать к созданию рейд-массива.
Создание файла mdadm.conf
В файле mdadm.conf находится информация о RAID-массивах и компонентах, которые в них входят. Для его создания выполняем следующие команды:
echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
mdadm --detail --scan --verbose | awk '/ARRAY/ ' >> /etc/mdadm/mdadm.conf
DEVICE partitions
ARRAY /dev/md0 level=raid1 num-devices=2 metadata=1.2 name=proxy.dmosk.local:0 UUID=411f9848:0fae25f9:85736344:ff18e41d
* в данном примере хранится информация о массиве /dev/md0 — его уровень 1, он собирается из 2-х дисков.
Информация о RAID
Посмотреть состояние всех RAID можно командой:
В ответ мы получим что-то на подобие:
md0 : active raid1 sdc[1] sdb[0]
1046528 blocks super 1.2 [2/2] [UU]
* где md0 — имя RAID устройства; raid1 sdc[1] sdb[0] — уровень избыточности и из каких дисков собран; 1046528 blocks — размер массива; [2/2] [UU] — количество юнитов, которые на данный момент используются.
** мы можем увидеть строку md0 : active(auto-read-only) — это означает, что после монтирования массива, он не использовался для записи.
Подробную информацию о конкретном массиве можно посмотреть командой:
* где /dev/md0 — имя RAID устройства.
Version : 1.2
Creation Time : Wed Mar 6 09:41:06 2019
Raid Level : raid1
Array Size : 1046528 (1022.00 MiB 1071.64 MB)
Used Dev Size : 1046528 (1022.00 MiB 1071.64 MB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Wed Mar 6 09:41:26 2019
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : proxy.dmosk.local:0 (local to host proxy.dmosk.local)
UUID : 304ad447:a04cda4a:90457d04:d9a4e884
Events : 17
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
- Version — версия метаданных.
- Creation Time — дата в время создания массива.
- Raid Level — уровень RAID.
- Array Size — объем дискового пространства для RAID.
- Used Dev Size — используемый объем для устройств. Для каждого уровня будет индивидуальный расчет: RAID1 — равен половине общего размера дисков, RAID5 — равен размеру, используемому для контроля четности.
- Raid Devices — количество используемых устройств для RAID.
- Total Devices — количество добавленных в RAID устройств.
- Update Time — дата и время последнего изменения массива.
- State — текущее состояние. clean — все в порядке.
- Active Devices — количество работающих в массиве устройств.
- Working Devices — количество добавленных в массив устройств в рабочем состоянии.
- Failed Devices — количество сбойных устройств.
- Spare Devices — количество запасных устройств.
- Consistency Policy — политика согласованности активного массива (при неожиданном сбое). По умолчанию используется resync — полная ресинхронизация после восстановления. Также могут быть bitmap, journal, ppl.
- Name — имя компьютера.
- UUID — идентификатор для массива.
- Events — количество событий обновления.
- Chunk Size (для RAID5) — размер блока в килобайтах, который пишется на разные диски.
Подробнее про каждый параметр можно прочитать в мануале для mdadm:
Также, информацию о разделах и дисковом пространстве массива можно посмотреть командой fdisk:
Подготовка носителей
Сначала необходимо занулить суперблоки на дисках, которые мы будем использовать для построения RAID (если диски ранее использовались, их суперблоки могут содержать служебную информацию о других RAID):
mdadm --zero-superblock --force /dev/sd
* в данном примере мы зануляем суперблоки для дисков sdb и sdc.
Если мы получили ответ:
mdadm: Unrecognised md component device - /dev/sdb
mdadm: Unrecognised md component device - /dev/sdc
. то значит, что диски не использовались ранее для RAID. Просто продолжаем настройку.
Далее нужно удалить старые метаданные и подпись на дисках:
wipefs --all --force /dev/sd
Как восстановить данные в случае выхода из строя массива RAID 1?
Несмотря на всю надежность массива RAID 1 пользователи иногда теряют ценную информацию. Причин тому может быть достаточно много – начиная случайным удалением данных или форматированием массива и заканчивая потерей данных во время замены поврежденного диска. В любом случае, перед тем как предпринимать любые меры – следует позаботится о безопасности информации. Например, даже если ваш массив перестал запускаться – следует в первую очередь извлечь данные с дисков массива и уже потом приступать к разного рода манипуляциям с дисками массива или контроллером.
Для того, чтобы восстановить данные с массива RAID 1 следует:
Шаг 1: Скачайте и установите программу RS RAID Retrieve. Запустите приложение после установки. Перед вами откроется встроенный RAID конструктор. Нажмите Далее.
Восстановление данных с любых RAID массивов
Шаг 2: Выберите тип добавления RAID массива для сканирования. RS RAID Retrieve предлагает на выбор три варианта:
- Автоматический режим – позволяет просто указать диски, из которых состоял массив, и программа автоматически определит их порядок, тип массива и остальные параметры;
- Поиск по производителю – эту опцию следует выбрать, если вам известен производитель вашего RAID контроллера. Эта опция также автоматическая и не требует каких-либо знаний о структуре RAID массива. Наличие данных о производителе позволяют сократить время на построение массива, соответственно она быстрее предыдущей;
- Создание вручную – эту опцию стоит использовать если вы знаете какой тип RAID массива вы используете. В этом случае вы можете указать все параметры, которые вам известны, а те, которых вы не знаете – программа определит автоматически.
После того, как выберите подходящий вариант – нажмите Далее.
Шаг 3: Выберите диски, из которых состоял RAID массив и нажмите Далее. После этого начнется процесс обнаружения конфигураций массива. После его завершения нажмите Готово.
Шаг 4: После того, как конструктор соберет массив — он будет отображаться как обыкновенный накопитель. Дважды щелкните на нем. Перед вами откроется Мастер восстановления файлов. Нажмите Далее.
Шаг 5: RS RAID Retrieve предложит просканировать ваш массив на наличие файлов для восстановления. Вам будет доступно две опции: быстрое сканирование и полный анализ массива. Выберите нужный вариант. Затем укажите тип файловой системы, которая использовалась в вашем массиве. Если эта информация вам не известна — отметьте галочкой все доступные варианты как на скриншоте. Стоит отметить, что RS RAID Retrieve поддерживает ВСЕ современные файловые системы.
Когда все настроено — нажмите Далее.
Шаг 6: Начнется процесс сканирования массива. Когда он закончится вы увидите прежнюю структуру файлов и папок. Найдите необходимые файлы, щелкните на них правой кнопкой мыши и выберите Восстановить.
Шаг 7: Укажите место куда будут записаны восстановленные файлы. Это может быть жесткий диск, ZIP-архив или FTP-сервер. Нажмите Далее.
После нажатия кнопки «Далее» программа начнет процесс восстановления. Когда он завершится — выбранные файлы будут в указанном месте.
После того, как все файлы успешно восстановлены — создайте заново RAID 1 массив, а затем скопируйте файлы обратно.
Как видите, процесс восстановления данных с RAID 1 массива достаточно прост и не требует глубоких знаний ПК, соответственно RS RAID Retrieve является отличным приложением как для профессионалов, так и для начинающих пользователей.
Главные недостатки массива RAID 1
Несмотря на высокий уровень сохранности данных массив RAID 1 обладает определенными недостатками. В первую очередь стоит сказать, что если вы хотите увеличить уровень надежности в массиве RAID 1 – вы можете использовать более двух дисков. Чем выше количество накопителей – тем выше надежность. Однако отсюда же вытекает первый недостаток RAID 1 – цена за Гигабайт памяти.
Все дело в том, что независимо от того, какое количество дисков вы добавили в массив – вам будет доступен объем памяти наименьшего из накопителей (к стати стоит отметить, что рекомендуется использовать диски с одинаковыми характеристиками). Все остальные деньги будут потрачены на обеспечение безопасности данных, так как на оставшихся накопителях будут хранится копии информации, а значит они не будут доступны для пользователя.
Еще одним недостатком является (как уже упоминалось выше) – скорость записи информации. То есть, чем больше накопителей вы будете использовать – тем ниже будет скорость записи данных. Кроме того, максимальная скорость записи информации напрямую будет зависеть от самого медленного накопителя, так как пока один блок информации не будет записан на все диски – запись второго блока не начнется. К стати, это еще одна причина, почему настоятельно рекомендуется использовать идентичные накопители.
Многие программные контроллеры не поддерживают «горячую замену» вышедшего из строя накопителя. Соответственно, для того чтобы заменить поврежденный диск придется отключить питание. Это делает крайне неудобным использование массива RAID 1 в серверах, которые использует большое количество людей, так как отключение питания приведет к недоступности данных. Лучше всего в для этих целей использовать аппаратные контроллеры, которые могут обеспечить поддержку «горячей замены» дисков.
Однако аппаратные контроллеры дороже программных, что также отразится на общей стоимости массива RAID 1.
Этот уровень RAID отлично подходит для домашних серверов с важной информацией, для которых достаточно двух дисков. В этом случае цена массива будет не слишком велика, плюс можно использовать программный контроллер, что позволит снизить общую стоимость массива.
Читайте также: