
Массивы с постоянным числом элементов постоянным размером и расположением выделенной памяти
Очень часто возникают задачи обработки массивов данных, размерность которых заранее неизвестна. В этом случае возможно использование одного из двух подходов:
- выделение памяти под статический массив, содержащий максимально возможное число элементов, однако в этом случае память расходуется не рационально;
- динамическое выделение памяти для хранение массива данных.
Для использования функций динамического выделения памяти необходимо описать указатель, представляющий собой начальный адрес хранения элементов массива.
Начальный адрес статического массива определяется компилятором в момент его объявления и не может быть изменен.
Для динамического массива начальный адрес присваивается объявленному указателю на массив в процессе выполнения программы.
Многомерные массивы
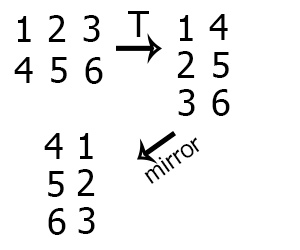
В языке Си могут быть также объявлены многомерные массивы. Отличие многомерного массива от одномерного состоит в том, что в одномерном массиве положение элемента определяется одним индексом, а в многомерном — несколькими. Примером многомерного массива является матрица.
Общая форма объявления многомерного массива
Элементы многомерного массива располагаются в последовательных ячейках оперативной памяти по возрастанию адресов. В памяти компьютера элементы многомерного массива располагаются подряд, например массив, имеющий 2 строки и 3 столбца,

Общее количество элементов в приведенном двумерном массиве определится как
КоличествоСтрок * КоличествоСтолбцов = 2 * 3 = 6.
Количество байт памяти, требуемых для размещения массива, определится как
КоличествоЭлементов * РазмерЭлемента = 6 * 4 = 24 байта.
Динамическое выделение памяти для двумерных массивов
Пусть требуется разместить в динамической памяти матрицу, содержащую n строк и m столбцов. Двумерная матрица будет располагаться в оперативной памяти в форме ленты, состоящей из элементов строк. При этом индекс любого элемента двумерной матрицы можно получить по формуле
index = i*m+j;
где i - номер текущей строки; j - номер текущего столбца.

Рассмотрим матрицу 3x4 (см. рис.)
Индекс выделенного элемента определится как
index = 1*4+2=6
Объем памяти, требуемый для размещения двумерного массива, определится как
n·m·(размер элемента)
Однако поскольку при таком объявлении компилятору явно не указывается количество элементов в строке и столбце двумерного массива, традиционное обращение к элементу путем указания индекса строки и индекса столбца является некорректным:
Правильное обращение к элементу с использованием указателя будет выглядеть как
- p - указатель на массив,
- m - количество столбцов,
- i - индекс строки,
- j - индекс столбца.
Пример на Си Ввод и вывод значений динамического двумерного массива

Результат выполнения
Возможен также другой способ динамического выделения памяти под двумерный массив - с использованием массива указателей. Для этого необходимо:
- выделить блок оперативной памяти под массив указателей;
- выделить блоки оперативной памяти под одномерные массивы, представляющие собой строки искомой матрицы;
- записать адреса строк в массив указателей.


Графически такой способ выделения памяти можно представить следующим образом.
При таком способе выделения памяти компилятору явно указано количество строк и количество столбцов в массиве.
Пример на Си
Результат выполнения программы аналогичен предыдущему случаю.
С помощью динамического выделения памяти под указатели строк можно размещать свободные массивы. Свободным называется двухмерный массив (матрица), размер строк которого может быть различным. Преимущество использования свободного массива заключается в том, что не требуется отводить память компьютера с запасом для размещения строки максимально возможной длины. Фактически свободный массив представляет собой одномерный массив указателей на одномерные массивы данных.
Для размещения в оперативной памяти матрицы со строками разной длины необходимо ввести дополнительный массив m , в котором будут храниться размеры строк.
Пример на Си : Свободный массив
Передача массива в функцию
Обработку массивов удобно организовывать с помощью специальных функций. Для обработки массива в качестве аргументов функции необходимо передать
Исключение составляют функции обработки строк, в которые достаточно передать только адрес.
При передаче переменные в качестве аргументов функции данные передаются как копии. Это означает, что если внутри функции произойдет изменение значения параметра, то это никак не повлияет на его значение внутри вызывающей функции.
Если в функцию передается адрес переменной (или адрес массива), то все операции, выполняемые в функции с данными, находящимися в пределах видимости указанного адреса, производятся над оригиналом данных, поэтому исходный массив (или значение переменной) может быть изменено вызываемой функцией.
Пример на Си Дан массив из 10 элементов. Поменять местами наибольший и начальный элементы массива. Для операций поиска максимального элемента и обмена использовать функцию.

Результат выполнения
Пример на Си Дан массив размерности n. Вычислить произведение четных элементов

Результат выполнения
Помогите пожалуйста. Задание:Найти 2 первых элемента в массиве С(n), значения которых не попадают в заданный с клавиатуры диапазон [a, b]. Поменять их местами.Со вводом нет проблем ,а вот найти два первых значения и поменять их местами, никак не могу сделать вывод.
<
int choice; //обраний пункт меню
double arr_C[100]; //одновимірний масив c
int n; //кількість елементів масиву c
double a, b;
int j;
int index;
double k;
//введення кількості елементів масиву B
printf( "\nУведіть кількість елементів масиву C(n)-(максимум 100) = " );
while (1)
<
if (scanf( "%d" , &n)!=1 n //якщо не виконуються умови-виведення запиту на повторне введення
printf( "Ви ввели неправильне значення. Спробуйте ще раз:\n" );
while (getchar() != '\n') //очистка буфера вводу та очікуання на правильний результат
continue;
>
else if (n > 100)
//якщо переповнення масиву-виведення запиту на повторне введення
printf( "Забагато елементів. Спробуйте ще раз:\n" );
while (getchar() != '\n') //очистка буфера вводу та очікуання на правильний результат
continue;
>
else
break ;
>
//введення елементів масиву B
for ( int i = 0; i < n; i++) printf( "arr_C[%d] = " , i);
while (scanf( "%lf" , &arr_C[i])!=1)
//якщо не виконуються умови-виведення запиту на повторне введення
printf( "Ви ввели неправильне значення. Спробуйте ще раз:\n" );
while (getchar() != '\n') //очистка буфера вводу та очікуання на правильний результат
continue;
>
>
a = DInput( "Введіть a:" );
b = DInput( "Введіть b:" );
Здравствуйте, подскажите пожалуйста, появились проблемы с написанием кода, не очень понимаю, как его написать, вот задача «Есть массив монет и купюр, содержащихся в кошельке. Подсчитать сумму наличных. Сортировка массива по методу «Сортировка пузырем» Буду благодарна за помочь
Здравствуйте !Подскажите пожалуйста, как в заполненном одномерном массиве найти номера элементов, которые больше 10, и количество таких элементов? А обнаруженные номера вывести в порядке их роста.
В цикле сравнить каждый элемент массива с 10. Если больше, вывести номер и увеличить количество на 1.
Добрый день) Хоть убейте но не могу сделать задачу: создать 3х7 массив чтобы считало температуру в трех городах (Моска, Питер, Ростов) всю неделю с соотвевтсвующим выводом информации (Самую высокую и низкую темпиратуру среди всех трех городов за все дни недели, самую низкую темпиратуру в Москве, город с самой большой температурой в среду, самую низкую и высокую среднею температуру и в каком городе) Дошел до вот этого момента, а дальше вывод информации, привязка дней недели итд я не помню((
int i, j, min, imin, jmin, max, imax, jmax;
int a [3][7];
printf( "Maximum temperature %d and its in %d and in column %d \n " , max, imax+1, jmax+1);
printf(Minimum temperature %d and its in %d and in column %d \n ", min, imin+1, jmin+1);
Пока не пойму, в чем сложность? Температуру в Москве найти? Или в среду? Индексы соответствуют дням недели. Неделя в какой день начинается? И какой по счету день "среда"? Сравниваем a[0][среда], a[1][среда] и a[2][среда]
Здраствуйте Елена! Помогите пожалуйста с заданием : Сформировать массив из м (м
Чтобы изменять размер массива, можно воспользоваться динамическим выделением памяти.
Чтобы случайные числа не повторялись - возможно два варианта
1. Перетасовать случайным образом последовательность чисел. 2. При генерации следующего случайного числа сравнивать его со всеми предыдущими.
Вопрос по поводу работы с массивом из функции: Что произойдёт с данными исходного массива, если я: - передам указатель на массив и его размер в функцию - внутри функции создам копию исходного массива и изменю её - изменю указатель так, чтобы он ссылался на изменённую копию исходного массива Эти данные просто станут "мусорными" значениями или удаляться (как в Python)?
Так лучше не делать! Выделенная память не будет корректно освобождена до завершения работы программы.
Добрый день. Вопрос по поводу указания размера массива. Я считал, что память под статический массив выделяется при компиляции и размер массива должен быть указан константой (как минимум в соответствии с требованиями стандарта ANSI C). Однако к моему удивлению при объявлении массива размера n (неизвестного на этапе компиляции) компилятор (mingw64 под Win) не выдает ни ошибок, ни предупреждений причем при разных стандартах (-std=c89,c90,c99. ) и включении отображения ошибок (-Wall):
int i, a[n]; // Почему не ругается?
Здравствуйте! Компилятор gcc 5.1.0 c11. int a = 10; int arr[a]; Ошибки нет. Стивен Прата в книге "Язык программирования С лекции и упражнения" 6 издание пишет: "int n = 5; float a8[n]; // не было разрешено до появления стандарта С99".
Здравствуйте, Елена! Спасибо Вам за статью! У меня есть один вопрос по массивам переменной длины. В одной книге прочел "Понятие переменный в массиве переменной длины вовсе не означает возможность изменения длины массива после его создания. Будучи созданным, массив переменной длины сохраняет тот же самый размер. В действительности понятие переменный означает, что при указании размерностей при первоначальном создании массива можно использовать переменные" Я выполнил упражнение из книги в DevC++, у меня программа запрашивает ввод количества строк и столбцов двумерного массива. Потом производит операции с массивом: вычисляет среднее значение, наибольшее значение в каждом одномерном массиве, наибольшее значение среди всех одномерных массивов и выводит данные на экран. Все это происходит в бесконечном цикле while (1) пока пользователь на запрос не введет значение отличное от 1 - тогда сработает оператор break. У меня в цикле while() каждый раз размер массива вводится с помощью scanf ("%lf", &str ), scanf ("%lf", &stlb ) без всякой динамической памяти и нормально программа работает т.е. пользователь может менять размер массива много раз и код компилируется. Вопрос - почему размер массива меняется и ошибки не выдается? Мне вот это непонятно. Заранее благодарен.
int vvod_massiva ( const double [][stlb]);
double srednee_znach ( const double [][stlb], int n);
double srednee_znach_vseh ( const double [][stlb]);
double bolshee_znach ( const double [][stlb]);
int vuvod_znach ( const double [][stlb], double [], double , double );
int main( void )
const double massiv[str][stlb];
double sred [stlb];
double c;
double d;
int i=0;
int j=0;
int ch;
while (1)
printf ( "Введите количество строк\n" );
scanf( "%d" , &str);
printf ( "Введите количество столбцов\n" , stlb);
scanf( "%d" , &stlb);
printf ( "Введите %d массива по %d элементов типа double каждый\n" , str, stlb );
for (i=0, j=0; i
c=srednee_znach_vseh (massiv);
d=bolshee_znach (massiv);
vuvod_znach (massiv, sred, c, d );
printf ( "Для повтора программы нажмите -1. Для завершения - 2\n" );
scanf( "%d" , &ch);
if (ch!=1)
break ;
>
int vvod_massiva ( const double a[][stlb])
int stroka;
int stolbets;
double srednee_znach ( const double a[][stlb], int n)
double sum=0;
double srednee=0;
int i;
double srednee_znach_vseh ( const double a[][stlb])
int stroka;
int stolbets;
double sum=0;
double srednee;
for (stroka=0; stroka for (stolbets=0; stolbets sum+=a[stroka][stolbets];
>
srednee=sum/(str*stlb);
printf( "%f\n" , sum );
return srednee;
>
> int stroka; for (stolbets=0; stolbets printf( "%f " , a[stroka][stolbets]); printf( "Среднее значение %d - массива равно %f\n" , i+1, b[i] ); printf( "Среднее значение из %d равно %f\n" , (str*stlb), c ); Мне тоже непонятно, что это за компилятор такой. Visual Studio 2019 на этот код 14 ошибок показывает. Массив в памяти хранится в виде вектора, т.е. все элементы размещаются в смежных участках памяти подряд, начиная с адреса, соответствующего началу массива. Элементы двухмерного массива размещаются либо по строкам, когда наиболее быстро меняется последний индекс (Паскаль, Си), либо по столбцам, когда наиболее быстро меняется первый индекс (Фортран). Размерность массива — это количество индексов, необходимое для однозначной идентификации любого элемента массива. Массив, элемент которого — переменная с одним индексом, называется одномерным массивом, с двумя индексами — двумерным и т.д. Этой информации достаточно как для доступа к элементам массива, так и для контроля над тем, чтобы значения индексов не выходили за установленные диапазоны. То, что размеры массива, формируемого транслятором, фиксированы, может явиться ограничивающим фактором применения готовой программы. Действительно, требуется, чтобы память для массива выделялась в размерах, необходимых для решении конкретной задачи, а каковы будут ее потребности, заранее может быть неизвестно. В таких ситуациях массив можно строить в динамической памяти, получаемой с помощью средств управления памятью операционной системы. Управление доступом к элементам таких массивов осуществляется самой программой по вычисляемым индексам (адресам) элементов с использованием указателя. Строка — это линейно упорядоченная последовательность символов, принадлежащих конечному множеству символов, называемому алфавитом. В зависимости от особенности задачи, свойств применяемого алфавита и представляемого им языка и свойств носителей информации могут применяться различные способы кодирования символов. В современных вычислительных системах общепринятой является кодировка всего множества символов на разрядной сетке фиксированного размера (в 1 байт). Хотя строки являются полустатическими структурами данных, в тех или иных конкретных задачах изменчивость строк может варьироваться от полного ее отсутствия до практически неограниченных возможностей изменения. Ориентация на ту или иную степень изменчивости строк определяет и физическое представление их в памяти и особенности выполнения операций над ними. В большинстве языков программирования (Си, Паскаль и др.) строки представляются именно как полустатические структуры. В зависимости от ориентации языка программирования средства работы со строками занимают в языке более или менее значительное место. В Паскале длина строки может меняться от 0 до n. Основные операции над строками реализованы как простые операции или встроенные функции. Возможны также библиотеки, обеспечивающие расширенный набор строковых операций. Операция сравнения строк имеет тот же смысл, что и для других типов данных. Сравнение строк производится по следующим правилам. Сравниваются первые символы двух строк. Если символы не равны, то строка, содержащая символ, место которого в алфавите ближе к началу, считается меньшей. Если символы равны, сравниваются вторые, третьи и т.д. символы. При достижении одного конца одной из строк строка меньшей длины считается меньшей. При равенстве длин строк и попарном равенстве всех символов в них строки считаются равными. Результатом операции сцепления двух строк является строка, длина которой равна суммарной длине строк-операндов, а значение соответствует значению первого операнда, за которым непосредственно следует значение второго операнда. Операция сцепления дает результат, длина которого в общем случае больше длин операндов. Как и во всех операциях над строками, которые могут увеличивать длину строки (присваивание, сцепление, сложные операции), возможен случай, когда длина результата окажется большей, чем отведенный для него объем памяти. Естественно, эта проблема возникает только в тех языках, где длина строки ограничивается. Возможны три варианта решения этой проблемы, определяемые правилами языка или режимами компиляции: На основе базовых операций могут быть реализованы и любые другие, даже сложные операции над строками. Например, операция удаления из строки символов с номерами от n1 включительно n2 может быть реализована как последовательность следующих шагов: Представление строк в памяти зависит от того, насколько изменчивыми являются строки в каждой конкретной задаче, и средства такого представления варьируются от абсолютно статического до динамического. Универсальные языки программирования в основном обеспечивают работу со строками переменной длины, но максимальная длина строки должна быть указана при ее создании. Если программиста не устраивают возможности или эффективность тех средств работы со строками, которые предоставляет ему язык программирования, то он может либо определить свой тип данных "строка" и использовать для его представления средства динамической работы с памятью, либо сменить язык программирования на специально ориентированный на обработку текста, в которых представление строк базируется на динамическом управлении памятью. Представление строк в виде векторов, принятое в большинстве универсальных языков программирования, позволяет работать со строками, размещенными в статической памяти. Кроме того, векторное представление позволяет легко обращаться к отдельным символам строки, как к элементам вектора, по индексу. Самым простым способом является представление строки в виде вектора постоянной длины. При этом в памяти отводится фиксированное количество байт, в которые записываются символы строки. Если строка меньше отводимого под нее вектора, то лишние места заполняются пробелами, а если строка выходит за пределы вектора, то лишние (обычно справа строки) символы должны быть отброшены. Этот и все последующие за ним методы учитывают переменную длину строк. Признак конца строки — это особый символ, принадлежащий алфавиту (таким образом, полезный алфавит оказывается меньше на один символ), и занимает то же количество разрядов, что и все остальные символы. Издержки памяти при этом способе составляют 1 символ на строку. Счетчик символов — это целое число, и для него отводится достаточное количество битов, чтобы их с избытком хватало для представления длины самой длинной строки,какую только можно представить в данной машине. Обычно для счетчика отводят от 8 до 16 битов. Тогда при таком представлении издержки памяти в расчете на одну строку составляют 1-2 символа. При использовании счетчика символов возможен произвольный доступ к символам в пределах строки, поскольку можно легко проверить, что обращение не выходит за пределы строки. Счетчик размещается в таком месте, где он может быть легко доступен — начале строки или в дескрипторе строки. Максимально возможная длина строки, таким образом, ограничена разрядностью счетчика. В Паскале, например, строка представляется в виде массива символов, индексация в котором начинается с 0, а однобайтный счетчик числа символов в строке является нулевым элементом этого массива. И счетчик символов, и признак конца могут быть доступны для программиста как элементы вектора. В двух предыдущих вариантах обеспечивалось максимально эффективное расходование памяти (1-2 "лишних" символа на строку), но изменчивость строки обеспечивалась крайне неэффективно. Поскольку вектор — статическая структура, каждое изменение длины строки требует создания нового вектора, пересылки в него неизменяемой части строки и уничтожения старого вектора. Это сводит на нет все преимущества работы со статической памятью. Поэтому наиболее популярным способом представления строк в памяти являются векторы с управляемой длиной. Память под вектор с управляемой длиной отводится при создании строки. Ее размер и размещение остаются неизменными все время существования строки. В дескрипторе такого вектора-строки может отсутствовать начальный индекс, так как он может быть зафиксирован раз и навсегда установленными соглашениями, но появляется поле текущей длины строки. Размер строки, таким образом, может изменяться от 0 до значения максимального индекса вектора. "Лишняя" часть отводимой памяти может быть заполнена любыми кодами — она не принимается во внимание при оперировании со строкой. Поле конечного индекса может быть использовано для контроля превышения длиной строки объема отведенной памяти. Хотя такое представление строк не обеспечивает экономии памяти, проектировщики систем программирования, возможно, считают это приемлемой платой за возможность работать с изменчивыми строками в статической памяти. В двунаправленном линейном списке в каждый элемент списка добавляется также указатель на предыдущий элемент. Двустороннее сцепление допускает двустороннее движение вдоль списка, что может значительно повысить эффективность выполнения некоторых строковых операция. При этом на каждый символ строки необходимо два указателя , т.е. 4-8 байт. Блочно-связное представление строк позволяет в большинстве операций избежать затрат, связанных с управлением динамической памятью, но в то же время обеспечивает достаточно эффективное использование памяти при работе со строками переменной длины. Многосимвольные группы (звенья) организуются в список, так что каждый элемент списка, кроме последнего, содержит группу элементов строки и указатель следующего элемента списка. Поле указателя последнего элемента списка хранит признак конца — пустой указатель. В процессе обработки строки из любой ее позиции могут быть исключены или в любом месте вставлены элементы, в результате чего звенья могут содержать меньшее число элементов, чем было первоначально. По этой причине необходим специальный символ, который означал бы отсутствие элемента в соответствующей позиции строки. Представление строки многосимвольными звеньями постоянной длины обеспечивает более эффективное использование памяти, чем символьно-связное. Операции вставки/удаления в ряде случаев могут сводиться к вставке/удалению целых блоков. Однако, при удалении одиночных символов в блоках могут накапливаться пустые символы emp, что может привести даже к худшему использованию памяти, чем в символьно-связном представлении. В многосимвольных звеньях переменной длины п еременная длина блока дает возможность избавиться от пустых символов и тем самым экономить память для строки. Однако появляется потребность в специальном символе — признаке указателя. С увеличением длины групп символом, хранящихся в блоках, эффективность использования памяти повышается. Однако негативной характеристикой рассматриваемого метода является усложнение операций по резервированию памяти для элементов списка и возврату освободившихся элементов в общий список доступной памяти. Такой метод спискового представления строк особенно удобен в задачах редактирования текста, когда большая часть операций приходится на изменение, вставку и удаление целых слов. Поэтому в этих задачах целесообразно список организовать так, чтобы каждый его элемент содержал одно слово текста. Символы пробела между словами в памяти могут не представляться. Рассмотрим многосимвольные звенья с управляемой длиной. Память выделяется блоками фиксированной длины. В каждом блоке помимо символов строки и указателя на следующий блок содержится номера первого и последнего символов в блоке. При обработке строки в каждом блоке обрабатываются только символы, расположенные между этими номерами. Признак пустого символа не используется: при удалении символа из строки оставшиеся в блоке символы уплотняются и корректируются граничные номера. Вставка символа может быть выполнена за счет имеющегося в блоке свободного места, а при отсутствии такового — выделением нового блока. Хотя операции вставки/удаления требуют пересылки символов, диапазон пересылок ограничивается одним блоком. При каждой операции изменения может быть проанализирована заполненность соседних блоков и два полупустых соседних блока могут быть переформированы в один блок. Для определения конца строки может использоваться как пустой указатель в последнем блоке, так и указатель на последний блок в дескрипторе строки. Последнее может быть весьма полезным при выполнении некоторых операций, например, сцепления. В дескрипторе может храниться также и длина строки: считывать ее из дескриптора удобнее, чем подсчитывать ее перебором всех блоков строки. Я не буду здесь писать про алгоритмы сортировки и алгоритмы поиска, так как найти код для почти любого из этих алгоритмов не составит труда. Изображения - это целый комплекс из разных заголовков и информации о изображении, и самого изображения хранящемся в виде двухмерного массива. Обработка изображений хорошо научит работать с двумерными массивами. Вот некоторые алгоритмы, которые пригодились мне для обработки изображений: 1) Зеркальное отражение. Для того чтобы перевернуть изображение по горизонтали нужно всего лишь читать массив, в котором оно содержится сверху вниз и справа налево. По такому же принципу выполняется переворот изображения по вертикали. 2) Поворот изображения на 90 градусов. Для поворота изображения нужно повернуть сам двухмерный массив, а чтобы повернуть массив нужно транспонировать двухмерный массив, а затем зеркально отразить по горизонтали. Пошаговое выполнение алгоритма Такой алгоритм появился, когда я нарисовал график координат c точками. График, приведший к решению Хочу обратить ваше внимание, что здесь я применяю другой способ переворота изображения. Вместо выделения памяти под новый массив, здесь просто меняем местами первые и последние элементы. Примечание: создать массив размерностью высоты и ширины реального изображения на стеке не выйдет. Только на куче с помощью оператора new. Функции динамического выделения памяти находят в оперативной памяти непрерывный участок требуемой длины и возвращают начальный адрес этого участка. Функции динамического распределения памяти: Для использования функций динамического распределения памяти необходимо подключение библиотеки : Поскольку обе представленные функции в качестве возвращаемого значения имеют указатель на пустой тип void , требуется явное приведение типа возвращаемого значения. Для определения размера массива в байтах, используемого в качестве аргумента функции malloc() требуется количество элементов умножить на размер одного элемента. Поскольку элементами массива могут быть как данные простых типов, так и составных типов (например, структуры), для точного определения размера элемента в общем случае рекомендуется использование функции Память, динамически выделенная с использованием функций calloc(), malloc() , может быть освобождена с использованием функции «Правилом хорошего тона» в программировании является освобождение динамически выделенной памяти в случае отсутствия ее дальнейшего использования. Однако если динамически выделенная память не освобождается явным образом, она будет освобождена по завершении выполнения программы. Массив - это структура однотипных данных, расположенная в памяти одним неразрывным блоком. Расположение одномерного массива в памяти Многомерные массивы хранятся точно также. Расположение двухмерного массива в памяти Знание этого позволяет нам по-другому обращаться к элементам массива. Например, у нас есть двухмерный массив из 9 элементов 3х3. Так что есть, как минимум два способа вывести его правильно: 1-й вариант (Самый простой): 2-й вариант (Посложнее): Формула для обращения к элементу 2-размерного массива, где width - ширина массива, col - нужный нам столбец, а row - нужная нам строчка: Зная второй вариант, необязательно пользоваться им постоянно, но все же знать стоит. Например, он может быть полезен, когда нужно избавиться А вот так можно работать с трехмерным массивом Этим способом можно обходить трехмерные объекты, например. Формула доступа к элементам в трехмерном массиве, где height - высота массива, width - ширина массива, depth - глубина элемента(наше новое пространство), col - столбец элемента, а row - строка элемента: Для получения доступа к элементам массива большей размерности по аналогии в формулу добавляем новые пространства. Специальных средств описания массивов в программах ассемблера, конечно, нет. При необходимости использовать массив в программе его нужно моделировать одним из следующих способов: 1. Перечислением элементов массива в поле операндов одной из директив описания данных. При перечислении элементы разделяются запятыми. К примеру: ;массив из 5 элементов.Размер каждого элемента 4 байта: 2. Используя оператор повторения dup. К примеру: ;массив из 5 нулевых элементов. ;Размер каждого элемента 2 байта: Такой способ определения используется для резервирования памяти с целью размещения и инициализации элементов массива. 3. Используя директивы labelиrept. Пара этих директив может облегчить описание больших массивов в памяти и повысить наглядность такого описания. Директиваreptотносится к макросредствам языка ассемблера и вызывает повторение указанное число раз строк, заключенных между директивой и строкой endm. К примеру, определим массив байт в области памяти, обозначенной идентификаторомmas_b. В данном случае директиваlabelопределяет символическое имяmas_b, аналогично тому, как это делают директивы резервирования и инициализации памяти. Достоинство директивыlabelв том, что она не резервирует память, а лишь определяет характеристики объекта. В данном случае объект — это ячейка памяти. Используя несколько директивlabel, записанных одна за другой, можно присвоить одной и той же области памяти разные имена и разный тип, что и сделано в следующем фрагменте: mas_b label byte mas_w label word В результате в памяти будет создана последовательность из четырех слов f1f0. Эту последовательность можно трактовать как массив байт или слов в зависимости от того, какое имя области мы будем использовать в программе —mas_bилиmas_w. 4. Использование цикла для инициализации значениями области памяти, которую можно будет впоследствии трактовать как массив. 5. Посмотрим на примере листинга 2, каким образом это делается. Листинг 2 Инициализация массива в цикле mes db 0ah,0dh,'Массив- ','$' mas db 10 dup (?) ;исходный массив xor ax,ax ;обнуление ax mov cx,10 ;значение счетчика цикла в cx mov si,0 ;индекс начального элемента в cx go: ;цикл инициализации mov mas[si],bh ;запись в массив i inc i ;инкремент i inc si ;продвижение к следующему элементу массива loop go ;повторить цикл ;вывод на экран получившегося массива mov ah,02h ;функция вывода значения из al на экран add dl,30h ;преобразование числа в символ mov ax,4c00h ;стандартный выход end main ;конец программы При работе с массивами необходимо четко представлять себе, что все элементы массива располагаются в памяти компьютера последовательно. Само по себе такое расположение ничего не говорит о назначении и порядке использования этих элементов. И только лишь программист с помощью составленного им алгоритма обработки определяет, как нужно трактовать эту последовательность байт, составляющих массив. Так, одну и ту же область памяти можно трактовать как одномерный массив, и одновременно те же самые данные могут трактоваться как двухмерный массив. Все зависит только от алгоритма обработки этих данных в конкретной программе. Сами по себе данные не несут никакой информации о своем “смысловом”, или логическом, типе. Помните об этом принципиальном моменте. Эти же соображения можно распространить и на индексы элементов массива. Ассемблер не подозревает об их существовании и ему абсолютно все равно, каковы их численные смысловые значения. Для того чтобы локализовать определенный элемент массива, к его имени нужно добавить индекс. Так как мы моделируем массив, то должны позаботиться и о моделировании индекса. В языке ассемблера индексы массивов — это обычные адреса, но с ними работают особым образом. Другими словами, когда при программировании на ассемблере мы говорим об индексе, то скорее подразумеваем под этим не номер элемента в массиве, а некоторый адрес. Давайте еще раз обратимся к описанию массива. К примеру, в программе статически определена последовательность данных: Пусть эта последовательность чисел трактуется как одномерный массив. Размерность каждого элемента определяется директивой dw, то есть она равна2байта. Чтобы получить доступ к третьему элементу, нужно к адресу массива прибавить6. Нумерация элементов массива в ассемблере начинается с нуля. То есть в нашем случае речь, фактически, идет о 4-м элементе массива — 3, но об этом знает только программист; микропроцессору в данном случае все равно — ему нужен только адрес. В общем случае для получения адреса элемента в массиве необходимо начальный (базовый) адрес массива сложить с произведением индекса (номер элемента минус единица) этого элемента на размер элемента массива: база + (индекс*размер элемента) Архитектура микропроцессора предоставляет достаточно удобные программно-аппаратные средства для работы с массивами. К ним относятся базовые и индексные регистры, позволяющие реализовать несколько режимов адресации данных. Используя данные режимы адресации, можно организовать эффективную работу с массивами в памяти. Вспомним эти режимы: · индексная адресация со смещением — режим адресации, при котором эффективный адрес формируется из двух компонентов: o постоянного (базового)— указанием прямого адреса массива в виде имени идентификатора, обозначающего начало массива; o переменного (индексного)— указанием имени индексного регистра. ;поместить 3-й элемент массива mas в регистр ax: · базовая индексная адресация со смещением — режим адресации, при котором эффективный адрес формируется максимум из трех компонентов: o постоянного(необязательный компонент), в качестве которой может выступать прямой адрес массива в виде имени идентификатора, обозначающего начало массива, или непосредственное значение; o переменного (базового)— указанием имени базового регистра; o переменного (индексного)— указанием имени индексного регистра. Этот вид адресации удобно использовать при обработке двухмерных массивов. Пример использования этой адресации мы рассмотрим далее при изучении особенностей работы с двухмерными массивами. Напомним, что в качестве базового регистра может использоваться любой из восьми регистров общего назначения. В качестве индексного регистра также можно использовать любой регистр общего назначения, за исключением esp/sp. Микропроцессор позволяет масштабировать индекс. Это означает, что если указать после имени индексного регистра знак умножения “*” с последующей цифрой 2, 4 или 8, то содержимое индексного регистра будет умножаться на 2, 4 или 8, то есть масштабироваться. Применение масштабирования облегчает работу с массивами, которые имеют размер элементов, равный 2, 4 или 8 байт, так как микропроцессор сам производит коррекцию индекса для получения адреса очередного элемента массива. Нам нужно лишь загрузить в индексный регистр значение требуемого индекса (считая от 0). Кстати сказать, возможность масштабирования появилась в микропроцессорах Intel, начиная с модели i486. По этой причине в рассматриваемом здесь примере программы стоит директива .486. Ее назначение, как и ранее использовавшейся директивы.386, в том, чтобы указать ассемблеру при формировании машинных команд на необходимость учета и использования дополнительных возможностей системы команд новых моделей микропроцессоров. Листинг 3. Просмотр массива слов с использованием .data ;начало сегмента данных mes1 db 'не равен 0!$',0ah,0dh mes2 db 'равен 0!$',0ah,0dh mes3 db 0ah,0dh,'Элемент $' mas dw 2,7,0,0,1,9,3,6,0,8 ;исходный массив .486 ;это обязательно mov ds,ax ;связка ds с сегментом данных xor ax,ax ;обнуление ax mov cx,10 ;значение счетчика цикла в cx mov esi,0 ;индекс в esi mov dx,mas[esi*2] ;первый элемент массива в dx cmp dx,0 ;сравнение dx c 0 je equal ;переход, если равно not_equal: ;не равно mov ah,02h ;вывод номера элемента массива на экран inc esi ;на следующий элемент dec cx ;условие для выхода из цикла jcxz exit ;cx=0? Если да — на выход jmp compare ;нет — повторить цикл inc esi ;на следующий элемент dec cx ;все элементы обработаны? mov ax,4c00h ;стандартный выход end main ;конец программы Еще несколько слов о соглашениях: · Если для описания адреса используется только один регистр, то речь идет о базовой адресациии этот регистр рассматривается какбазовый: ;переслать байт из области данных, адрес которой находится в регистре ebx: · Если для задания адреса в команде используется прямая адресация(в виде идентификатора) в сочетании с одним регистром, то речь идет обиндексной адресации. Регистр считаетсяиндексным, и поэтому можно использовать масштабирование для получения адреса нужного элемента массива: ;сложить содержимое eax с двойным словом в памяти ;по адресу mas + (ebx)*4 · Если для описания адреса используются два регистра, то речь идет о базово-индексной адресации. Левый регистр рассматривается как базовый, а правый — как индексный. В общем случае это не принципиально, но если мы используем масштабирование с одним из регистров, то он всегда являетсяиндексным. Но лучше придерживаться определенных соглашений. · Помните, что применение регистров ebp/bpиesp/spпо умолчанию подразумевает, что сегментная составляющая адреса находится в регистреss. Заметим, что базово-индексную адресацию не возбраняется сочетать с прямой адресацией или указанием непосредственного значения. Адрес тогда будет формироваться как сумма всех компонентов. ;адрес операнда равен [mas+(ebx)+(ecx)*2] ;адрес операнда равен [(ebx)+8+(ecx)*4] Но имейте в виду, что масштабирование эффективно лишь тогда, когда размерность элементов массива равна 2, 4 или 8 байт. Если же размерность элементов другая, то организовывать обращение к элементам массива нужно обычным способом, как описано ранее. Рассмотрим пример работы с массивом из пяти трехбайтовых элементов (листинг 4). Младший байт в каждом из этих элементов представляет собой некий счетчик, а старшие два байта — что-то еще, для нас не имеющее никакого значения. Необходимо последовательно обработать элементы данного массива, увеличив значения счетчиков на единицу. При решении задач с большим количеством данных одинакового типа использование переменных с различными именами, не упорядоченных по адресам памяти, затрудняет программирование. В подобных случаях в языке Си используют объекты, называемые массивами. Массив — это непрерывный участок памяти, содержащий последовательность объектов одинакового типа, обозначаемый одним именем. Массив характеризуется следующими основными понятиями: Элемент массива (значение элемента массива) – значение, хранящееся в определенной ячейке памяти, расположенной в пределах массива, а также адрес этой ячейки памяти. Имя массива – идентификатор, используемый для обращения к элементам массива. Размер массива – количество элементов массива Размер элемента – количество байт, занимаемых одним элементом массива. Графически расположение массива в памяти компьютера можно представить в виде непрерывной ленты адресов. Представленный на рисунке массив содержит q элементов с индексами от 0 до q-1 . Каждый элемент занимает в памяти компьютера k байт, причем расположение элементов в памяти последовательное. Адреса i -го элемента массива имеет значение n+k·i Адрес массива представляет собой адрес начального (нулевого) элемента массива. Для обращения к элементам массива используется порядковый номер (индекс) элемента, начальное значение которого равно 0 . Так, если массив содержит q элементов, то индексы элементов массива меняются в пределах от 0 до q-1 . Длина массива – количество байт, отводимое в памяти для хранения всех элементов массива. ДлинаМассива = РазмерЭлемента * КоличествоЭлементов Для определения размера элемента массива может использоваться функция Значения элементов многомерного массива, как и в одномерном случае, могут быть заданы константными значениями при объявлении, заключенными в фигурные скобки <> . Однако в этом случае указание количества элементов в строках и столбцах должно быть обязательно указано в квадратных скобках [] . Однако чаще требуется вводить значения элементов многомерного массива в процессе выполнения программы. С этой целью удобно использовать вложенный параметрический цикл. Результат выполнения Форма обращения к элементам массива с помощью указателей имеет следующий вид: int a[10], *p; // описываем статический массив и указатель Пример на Си : Организация динамического одномерного массива и ввод его элементов. Результат выполнения программы: Для объявления массива в языке Си используется следующий синтаксис: тип имя[размерность]=; Инициализация представляет собой набор начальных значений элементов массива, указанных в фигурных скобках, и разделенных запятыми. Если количество инициализирующих значений, указанных в фигурных скобках, меньше, чем количество элементов массива, указанное в квадратных скобках, то все оставшиеся элементы в массиве (для которых не хватило инициализирующих значений) будут равны нулю. Это свойство удобно использовать для задания нулевых значений всем элементам массива. Если массив проинициализирован при объявлении, то константные начальные значения его элементов указываются через запятую в фигурных скобках. В этом случае количество элементов в квадратных скобках может быть опущено. При обращении к элементам массива индекс требуемого элемента указывается в квадратных скобках [] . Однако часто требуется задавать значения элементов массива в процессе выполнения программы. При этом используется объявление массива без инициализации. В таком случае указание количества элементов в квадратных скобках обязательно. Для задания начальных значений элементов массива очень часто используется параметрический цикл: Результат выполнения программы Этот небольшой пост не претендует на невероятные открытия мира информатики, но надеюсь успешно поможет немного вникнуть в устройство массивов падаванам мира IT. Как я сказал в начале, здесь я собрал частичку того, чего не хватало мне при изучении программирования. Как бы эти вещи не казались бесполезными, все студенты университетов, изучающие информационные технологии проходят через это, и не напрасно — это помогает развивать логику и решать более сложные задачи, которые ждут далее. Приведенные выше примеры показывают некоторые важные способы взаимодействия с массивами. Я надеюсь этот пост будет полезен, и если это будет так, то я напишу продолжение этой темы. Для того чтобы разобраться в возможностях и особенностях обработки массивов в программах на ассемблере, нужно ответить на следующие вопросы: · Как описать массивв программе? · Как инициализировать массив, то есть как задать начальные значения его элементов? · Как организовать доступк элементам массива? · Как организовать массивыс размерностью более одной? · Как организовать выполнениетиповых операций с массивами? Если размер выделяемой памяти нельзя задать заранее, например при вводе последовательности значений до определенной команды, то для увеличения размера массива при вводе следующего значения необходимо выполнить следующие действия: Все перечисленные выше действия (кроме последнего) выполняет функция Размер блока памяти, на который ссылается параметр ptr изменяется на size байтов. Блок памяти может уменьшаться или увеличиваться в размере. Содержимое блока памяти сохраняется даже если новый блок имеет меньший размер, чем старый. Но отбрасываются те данные, которые выходят за рамки нового блока. Если новый блок памяти больше старого, то содержимое вновь выделенной памяти будет неопределенным. Массив — структура, стоявшая у истоков программирования. Но, несмотря на то, что массивам уделяется внимание в каждом курсе уроков по любому языку программирования, от новичков все равно ускользает много важной информации, связанной с логикой взаимодействия с этой структурой. Цель этого поста — собрать некоторую информацию о массивах, которой когда-то не хватало мне. Пост для новичков.
double bolshee_znach ( const double a[][stlb])
<
int i=0;
int j;
int n=1;
int p1=1;
double massiv [str];
int k;
for (j=0, k=0; j p1=1;
i=0;
while (p1
int vuvod_znach ( const double a[][stlb], double b[], double c, double d)
int stolbets;
int i;
int j;
printf( "большее значение из %d равно %f\n" , (str*stlb), d );

Списковое представление строк в памяти обеспечивает гибкость в выполнении разнообразных операций над строками (в частности, операций включения и исключения отдельных символов и целых цепочек) и использование системных средств управления памятью при выделении необходимого объема памяти для строки. Однако, при этом возникают дополнительные расходы памяти. Другим недостатком спискового представления строки является то, что логически соседние элементы строки не являются физически соседними в памяти. Это усложняет доступ к группам элементов строки по сравнению с доступом в векторном представлении строки.
В однонаправленном линейном списке каждый символ строки представляется в виде элемента связного списка; элемент содержит код символа и указатель на следующий элемент. Одностороннее сцепление представляет доступ только в одном направлении вдоль строки. На каждый символ строки необходим один указатель, который обычно занимает 2-4 байта.


Алгоритмы обработки массивов

Стандартные функции динамического выделения памяти
Что такое массив?
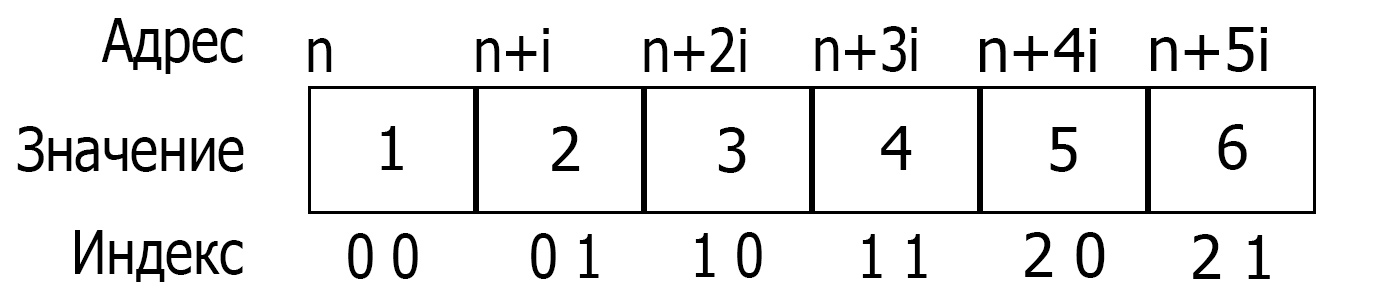
от лишних звездочек от указателей на указатели на указатели.Описание и инициализация массива в программе
Каждый элемент массива характеризуется тремя величинами:
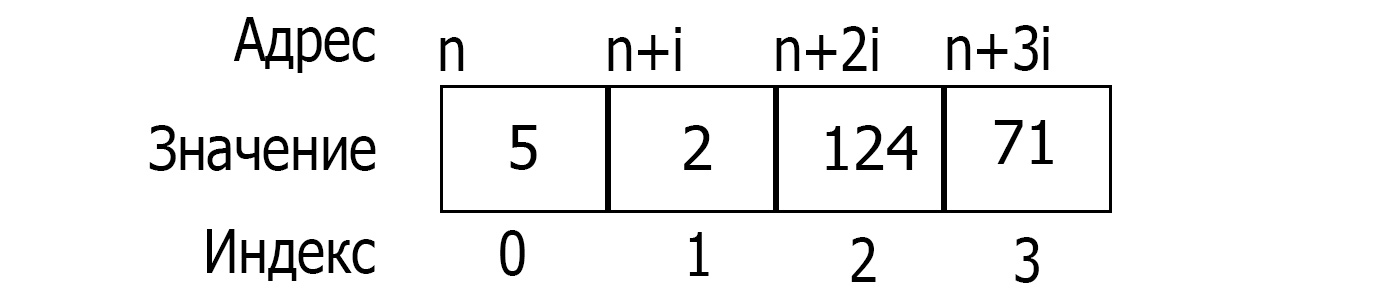
Адрес массива – адрес начального элемента массива.
Инициализация многомерных массивов

Динамическое выделение памяти для одномерных массивов
int b;
p = a; // присваиваем указателю начальный адрес массива
. // ввод элементов массива
b = *p; // b = a[0];
b = *(p+i) // b = a[i]; 
Объявление и инициализация массивов

Заключение
Перераспределение памяти
Пример на Си Выделить память для ввода массива целых чисел. После ввода каждого значения задавать вопрос о вводе следующего значения.
Читайте также: