
Library cache mutex x oracle что это
Oracle 11.2.0.2 contains enhancements 9282521 and 9239863 named “Library cache: mutex X” for objects highly contended for. Part I and II. These enhancements introduce new interesting possibilities to tune some types of the mutex contention.
Contention for heavily accessed objects can now be divided between multiple copies of object in the library cache. According to notes 9282521.8 and 9239863.8 describing the patches, the enhancements should be used:
When there is true contention on a specific library cache object….
Let me investigate this deeper. I will use Oracle 11.2.0.2.2 for Solaris SPARC (64-bit) on 8Cores/32Threads Sun Fire T2000. I chose this platform in order to emphasize how the enhancements work.
Standard disclaimer: Production workloads are much more complex than testcases. Not yet officially supported technique described here may be or may be not applicable to your system. You must thoroughly investigate your workload and receive explicit approval of Oracle Support Services before implementing this in production system.
I. The “Library cache: mutex X” contention testcase.
First of all I need the reproducible testcase that will allow me to explore the “Library cache: mutex X” contention.
As I wrote in previous post about “Cursor: pin S” testcase the true contention arises when the same operator executes concurrently at high frequency. This differs from the contention induced by many versions of cursor. The testcase for “Library cache: mutex X” contention looks like:
The script uses PL/SQL loop to “execute immediate” the following anonymous PL/SQL block one million times:
Hash value of this block is 2253951259. The dbms_application_info.set_client_info() procedure is fast and does not need latches or other resources. This allows me to create pure testcase without unneeded contention. In addition, it is surprisingly common to see mutex contention for dbms_application_info in contemporary over-instrumented applications.
When executed alone, the script takes 3:20 min on average in T2000. Similarly to my previous post I will execute this script by several concurrent sessions. Each time the session ‘execute immediate’ the PL/SQL block, it needs to acquire corresponding “Cursor Pin” mutex to pin the block itself and “Library Cache” mutex to pin the dbms_application_info package in the Library Cache. This will induce the mutex contention.
Look at “library_cache_mutex_x_contention.sql” script. It spawns several sqlplus sessions to execute the above PL/SQL block concurrently. In addition, it takes AWR snapshots before and after the script execution. I will submit 30 concurrent sessions to thrash my 32 CMT T2000 server:
The following AWR report section confirms that testcase induced heavy “library cache: mutex X” contention:
…
Top 5 Timed Foreground Events
Host CPU (CPUs: 32 Cores: 8 Sockets: 1)
…
As expected the server runqueue raised to 30. Due to concurrency, the average time to execute the script increased 4 times from 3:20 min to 14:27 min.
For the discussion of mutex wait event parameters, diagnostics tools and scripts see my previous post. It is interesting that “library cache: mutex X” wait event is still absent in 11.2 documentation. Up to now the only official information source is MOS Note WAITEVENT: “library cache: mutex X” [ID 727400.1]. Look at mutex waits during contention peak:
| SAMPLE_TIME | SID | SQL_ID | EVENT | IDN | BLK_SID | LOC | MUTEX_OBJECT |
|---|---|---|---|---|---|---|---|
| 10:05:40 | 11 | d8dxvkk7hxvq0 | cursor: pin S | 2253951259 | 161 | 8 | begin dbms_application_info.set_client_i |
| 10:05:41 | 155 | d8dxvkk7hxvq0 | cursor: pin S | 2253951259 | 144 | 106 | begin dbms_application_info.set_client_i |
| 10:05:44 | 50 | 11c4s0a35j48v | library cache: mutex X | 791245243 | 169 | 0 | DBMS_APPLICATION_INFO |
| 10:05:46 | 203 | 11c4s0a35j48v | library cache: mutex X | 3225908833 | 26 | 0 | DBMS_APPLICATION_INFO |
| 10:05:47 | 11 | 11c4s0a35j48v | library cache: mutex X | 3225908833 | 114 | 0 | DBMS_APPLICATION_INFO |
| 10:05:49 | 155 | 11c4s0a35j48v | cursor: pin S | 2253951259 | 112 | 3 | begin dbms_application_info.set_client_i |
Most mutex waits occurred for heavily accessed PL/SQL anonymous block, package DBMS_APPLICATION_INFO and its body:
| CURSOR | ADDRESS | NAME | HASH_VALUE | TYPE | Locked | Pinned | Executed | NAMESPACE |
|---|---|---|---|---|---|---|---|---|
| Child 0 | 000000038B975DC8 | begin dbms_application_info.se | 2253951259 | CURSOR | 30 | 56602935 | 27766476 | 0 |
| Parent | 000000038D8DE8E8 | DBMS_APPLICATION_INFO | 791245243 | PACKAGE | 444 | 30000414 | 0 | 1 |
| Parent | 000000038D1DD3A8 | DBMS_APPLICATION_INFO | 3225908833 | PACKAGE BODY | 234 | 30000204 | 30000846 | 2 |
…
According to x$mutex_sleeps most mutex waits were occurred during library cache pin/unpin activity inside kglpin (“KGL: PIN heaps and load data pieces of an object”), kglpndl (“KGL PiN DeLete”) and kglpnal1 (“KGL PiN ALlOcate”) routines:
| MUTEX_TYPE | LOCATION_ID | LOCATION | SLEEPS | WAIT_TIME |
|---|---|---|---|---|
| Library Cache | 90 | kglpnal1 90 | 218814816 | 155840921 |
| Library Cache | 95 | kglpndl1 95 | 217545345 | 248695706 |
| Library Cache | 4 | kglpin1 4 | 209842796 | 155358935 |
| Cursor Pin | 9 | kksLockDelete [KKSCHLPIN6] | 26255 | 368250 |
| Cursor Pin | 8 | kksxsccmp [KKSCHLPIN5] | 17171 | 187894 |
| Cursor Pin | 3 | kksfbc [KKSCHLFSP2] | 9150 | 112699 |
II. Cloning the library cache objects
The root cause of this contention is the concurrent access to the same “hot” library cache objects. If each session would have its own copy of object there would be no contention! Before 11.2.0.2 this requires artificial tricks.
Enhancements 9282521 and 9239863 allow creation of multiple copies of specified library cache objects. Parameter “_kgl_hot_object_copies” controls the maximum number of copies. Complementary parameter _kgl_debug marks hot library cache objects as a candidate for cloning. Syntax of this parameter can be found in MOS descriptions of bugs 9684368, 11775293 and others. One form of such marking is:
“_kgl_debug”=”name=’schema=’ namespace= debug=33554432”
Both parameters are dynamic. However, my experiments showed that after dynamic change of parameters Oracle unevenly distributes mutex requests between hot object copies. This is why I will use these parameters in my demonstrations as static.
Let me make an experiment. In the above testcase the “library cache: mutex X” contention occurred for package DBMS_APPLICATION_INFO and its body. Corresponding library cache namespaces are 1 and 2. I can mark both the package and the body as “hot” using:
SQL>alter system set “_kgl_debug”=”name=’DBMS_APPLICATION_INFO’ schema=’SYS’ namespace=1 debug=33554432”, “name=’DBMS_APPLICATION_INFO’ schema=’SYS’ namespace=2 debug=33554432” scope=spfile;
If I allow only two copies of hot objects, the mutex contention will be halved. The average time to execute script will decrease from 14:27 min to 7:50 min. In order to demonstrate full-scale improvement I will go further and allow each concurrent session to have its copy of DBMS_APPLICATION_INFO:
SQL>alter system set “_kgl_hot_object_copies”= 255 scope=spfile;
SQL>@library_cache_mutex_x_contention 30
…
ORACLE instance started.
…
Now, the script takes 5:30 min to execute on average. The “library cache: mutex X” contention is magically disappeared:
Top 5 Timed Foreground Events
Now concurrently executed PL/SQL blocks do not interfere with each other. The library_cache_objects_heavily_accessed.sql script shows that library cache contains 30 DBMS_APPLICATION_INFO packages and 30 bodies. Each object was pinned one million times:
| CURSOR | ADDRESS | NAME | HASH_VALUE | TYPE | Locked | Pinned | Executed | NAMESPACE |
|---|---|---|---|---|---|---|---|---|
| Child 0 | 000000038BB05640 | begin dbms_applicati | 2253951259 | CURSOR | 30 | 22740992 | 10459264 | 0 |
| Parent | 000000038BAD6B08 | DBMS_APPLICATION_INF | 3759149138 | PACKAGE | 2 | 1000001 | 0 | 1 |
| Parent | 000000038BAD6D28 | DBMS_APPLICATION_INF | 778396835 | PACKAGE | 2 | 1000001 | 0 | 1 |
| Parent | 000000038BA0A0B0 | DBMS_APPLICATION_INF | 1977222849 | PACKAGE BODY | 1 | 1000000 | 1000000 | 2 |
| Parent | 000000038B9824E8 | DBMS_APPLICATION_INF | 2894603672 | PACKAGE | 1 | 1000000 | 0 | 1 |
…
Sessions execute independently after tuning. We have unleashed the full power of Oracle TSeries Chip Multithreading parallelism!
III. “Cursor: pin S” contention
Being inspired by successful resolution of “Library cache: mutex X” contention, I will use the same approach for “Cursor: pin S” waits. In my previous post, I published corresponding testcase. In T2000 environment the testcase load profile is:
Top 5 Timed Foreground Events
Now I need another form of _kgl_debug syntax to mark SQL cursor “select 1 from dual where 1=2” as ‘hot’:
“_kgl_debug”=”hash=’full hash value‘ debug=33554432″
The ordinary hash value of this SQL is 3222383532. However, we need a complete 128 bit hash value for library cache object here. You can find it in kglhahsv column of x$kglob:
Again the mutex waits disappeared from AWR report after tuning:
Top 5 Timed Foreground Events
The enhancements allow us to resolve the “Cursor: pin S” mutex contention also!
IV. No more underscores. The dbms_shared_pool.markhot() procedure.
I believe that supported way to use this functionality is not yet documented dbms_shared_pool.markhot() procedure. This new in 11.2.0.2 procedure takes two forms:
dbms_shared_pool.markhot(
schema IN VARCHAR2,
objname IN VARCHAR2,
namespace IN NUMBER DEFAULT 1, — library cache namespace to search
global IN BOOLEAN DEFAULT TRUE); — If TRUE mark hot on all RAC instances
and
dbms_shared_pool.markhot(
hash IN VARCHAR2, — 16-byte hash value for the object
namespace IN NUMBER DEFAULT 1,
global IN BOOLEAN DEFAULT TRUE);
corresponding to two _kgl_debug syntaxes described above. There is also dbms_shared_pool.unmarkhot() procedure to unmark the hot object.
I repeated the experiments now marking objects as ‘hot’ using:
exec dbms_shared_pool.markhot(‘SYS’,’DBMS_APPLICATION_INFO’,1);
exec dbms_shared_pool.markhot(‘SYS’,’DBMS_APPLICATION_INFO’,2);
exec dbms_shared_pool.markhot(hash=>’4d1ef2753f3bb11043fd2f61c011abac’, NAMESPACE=>0);
However, the results were not consistent enough in 11.2.0.2.2. Oracle created multiple copies of marked objects in library cache, but frequently uses only one of them. May be this depend upon history of object usage. To achieve more uniform distribution you should mark objects as hot immediately after the instance restart.
By default, Oracle created approximately “number of CPU Cores” hot objects copies. This observation should be further investigated. You can adjust this number by _kgl_hot_object_copies parameter.
Therefore if you prefer not to use hidden parameters, the dbms_shared_pool.markhot() can help you to resolve mutex contention.
In summary: Oracle 11.2.0.2 is the right patchset for mutexes. In this post I discussed how we can use new 11.2.0.2 features to “divide and conquer” the mutex contention which was caused by heavy concurrent access to library cache object.
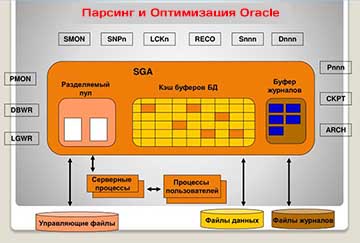
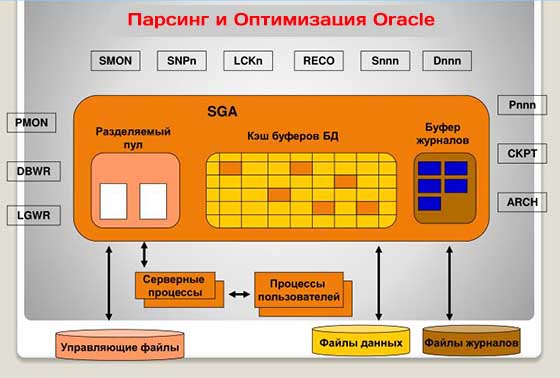
Теперь, познакомившись поближе с особенностями использования разделяемого пула для обслуживания содержимого библиотечного кэша, мы можем потратить некоторое время на исследование последовательности операций, выполняемых в ходе вызова parse для инструкции, которая прежде не была оптимизирована.
Выполняется проверка синтаксиса и определяется допустимость инструкции SQL.
Вычисляется хэш-значение для строки, определяется соответствующий хэш-блок в библиотечном кэше и проверяется наличие точно такой же строки в кэше.
В данном случае предполагается, что такая строка отсутствует, поэтому далее выполняется семантический анализ строки и проверяется присутствие в кэше словаря имен объектов, используемых в строке – это означает необходимость приобретения защелок кэша словаря и иногда выполнения некоторого кода SQL для загрузки определений в кэш.
Мы не будем останавливаться на парсинге, оптимизации и выполнении рекурсивных инструкций SQL, потому что мы уже в середине описания этого процесса. Достаточно будет сказать, что для загрузки определений в кэш может потребоваться освободить некоторую память из списка LRU в разделяемом пуле, вернуть ее в списки свободных фрагментов, затем найти свободные фрагменты и включить их в список LRU, и все это – удерживая кэш словаря строк.
После семантической проверки можно приступать к оптимизации инструкции, но при этом нужно гарантировать, что никакой другой сеанс не будет тратить свое время впустую, оптимизируя ту же инструкцию в то же время. Поэтому в данной точке приобретается некоторая память из списков свободных фрагментов (это снова означает, что может потребоваться сначала освободить некоторые объекты из списка LRU) и несколько фрагментов включается в список LRU, чтобы обеспечить удержание родительского и дочернего курсоров, а также некоторой информации о курсорах.
Примечание. Родительский курсор хранит обобщенную информацию об инструкции, дочерний курсор – информацию, касающуюся конкретного рабочего окружения, такую как имена таблиц, зависимости, окружение оптимизатора и окончательный план выполнения.
После получения родительского и дочернего курсоров они закрепляются в монопольном режиме, чтобы: (а) – они не ушли немедленно в «список LRU незакрепленных, воссоздаваемых фрагментов», оказавшись под угрозой удаления, и (б) – чтобы никакой другой сеанс не смог получить их, пока не завершится оптимизация. Если любой другой сеанс попытается оптимизировать ту же инструкцию в то же время, он перейдет в состояние ожидания ( cursor: pin S wait
on X – в последней версии Oracle, library cache pin – в более старых версиях).
В этот момент сеанс может сделать все необходимое для составления плана выполнения, но, поскольку я написал целую книгу, посвященную этой теме, я не буду описывать, как это происходит. Скажу лишь, что вся работа выполняется в основном в приватной памяти – после получения из кэша словаря информации о таблице, индексе и столбце, сеансу больше не потребуется обращаться к общей памяти, пока план выполнения не будет готов.
Примечание. Если описывать в общих чертах: оптимизатор находит лучший порядок соединения таблиц в запросе, определяет лучший метод соединения смежных пар таблиц и лучший метод доступа к каждой таблице. На каждом шаге выбор лучшей стратегии определяется оценкой объема данных и физической разбросанности этих данных.
В конечном итоге создается план выполнения, который должен быть сохранен в дочернем курсоре – в этот момент в разделяемом пуле приобретается дополнительная память (возможно с удалением некоторых объектов из списка LRU) и присоединяется к дочернему курсору. Планы выполнения могут быть очень большими, поэтому может потребоваться выделить несколько фрагментов памяти, из которых первый будет принадлежать классу recreate , а остальные – классу freeable .
В завершение родительский и дочерний курсоры открепляются, дочерний курсор закрепляется в разделяемом режиме, выполняется и открепляется. (Переход из монопольного в разделяемый режим означает, что любой сеанс, ожидавший окончания оптимизации той же инструкции, может теперь получить готовый к использованию план выполнения, приобрести собственное закрепление и выполнить инструкцию.)
Вы можете сами оценить, какой объем работы выполняется и сколько операций с разделяемым пулом производится в ходе поиска объектов, создания и приобретения фрагментов памяти. Причем этот цикл может выполняться неоднократно в процессе оптимизации единственной инструкции. Помните, что до того, как будет начато создание плана выполнения, должна быть проверена вся информация из кэша словаря, для чего может потребоваться приобрести (относительно) большие объемы памяти для объектов в библиотечном кэше. Оптимизация – это процедура, которой желательно избегать. Просто чтобы дать вам представление о сложности манипуляций с фрагментами памяти, на рис. 1 приводится упрощенная схема строения родительского курсора с двумя дочерними курсорами.

Рис. 1. Упрощенная схема строения родительского курсора с двумя дочерними курсорами
Схема на рис. 1 не совсем точно отражает способ выделения и связывания фрагментов памяти для курсоров, и различные элементы информации, такие как списки зависимостей, окружение оптимизатора и другие, в действительности не совсем так располагаются в памяти, как я показал – я позволил себе допустить поэтические отступления, только чтобы упростить картину.
Обратите внимание, что я изобразил на схеме два дочерних курсора и, взглянув на информацию, которую они несут (переменные связывания, окружение оптимизатора, списки зависимостей), вы легко поймете, как для одной инструкции SQL может быть создано несколько планов выполнения. В моем первоначальном описании процесса оптимизации не упоминалась возможность наличия сразу нескольких дочерних курсоров, но когда инструкция передается впервые, Oracle должен проверить – все ли в этой инструкции соответствует существующему дочернему курсору. Каждый дочерний курсор для данного родителя защищается той же самой защелкой библиотечного кэша, поэтому Oracle должен удерживать данную защелку на все время проверки. Очевидно, что это является одной из опасностей, которые влечет за собой установка параметра cursor_sharing в значение similar – в результате может получиться очень длинный список дочерних курсоров, подлежащих проверке.
В описании процедуры парсинга и оптимизации инструкции я пару раз упомянул закрепление (pinning). Закрепление также производится во время выполнения инструкции, и механизмы выполнения продолжали изменяться на протяжении последних нескольких выпусков Oracle, поэтому мы закончим копание в библиотечном кэше и в разделяемом пуле обсуждением выполнения, блокировки и закрепления.
В заключение
Сравнивая кэш буферов с разделяемым пулом, можно заметить, что им свойственны похожие проблемы, имеющие похожие пути решения. Своим назначением и поведением защелка цепочек LRU в кэше буферов похожа на защелку разделяемого пула. Точно так же имеются сходства между защелками цепочек в кэше буферов и защелками в библиотечном кэше.
Защелка разделяемого пула контролирует перемещение памяти из пула свободных фрагментов в пул занятых фрагментов, включая фрагменты в список LRU и исключая из него. Защелка цепочек LRU в кэше буферов также контролирует перемещение буферов между вспомогательным (с давно использовавшимися блоками) и основным (с недавно использовавшимися блоками) списками. Защелки в библиотечном кэше упорядочивают доступ к коду и метаданным объектов в соответствии с их хэш-значениями, и защелки цепочек в кэше буферов также упорядочивают доступ к блокам данных по их хэш-значениям.
Разумеется, имеются отличия в числе защелок и особенностями их использования, а также применяются разные стратегии закрепления и использования элементов. Так как кэш буферов (или, по крайней мере, каждый рабочий набор данных) работает с фрагментами памяти одного размера, управлять памятью в кэше буферов проще, чем в разделяемом пуле, где память может выделяться фрагментами практически любого размера. Из соображений производительности, в разделяемом пуле реализовано несколько списков свободных фрагментов (тогда как в кэше буферов имеется единственный вспомогательный список) и применяются разные стратегии минимизации фрагментации памяти.
Всегда рассматривайте парсинг и оптимизацию, как две отдельные операции. И помните о различиях между вызовами парсера и операцией парсинга.
Оптимизация является дорогостоящей процедурой, парсинг может быть дорогостоящей процедурой – в системах OLTP, где большую часть составляют легковесные запросы, возвращающие небольшие объемы данных, избегайте конструирования инструкций SQL путем конкатенации литеральных значений, потому что стоимость выполнения таких запросов выше.
Вызов парсера в вашем коде может:
- вообще ничего не сделать – особенно в коде PL/SQL;
- выполнить проверку синтаксиса, произвести поиск в библиотечном кэше, провести семантический анализ и оптимизацию;
- выполнить проверку синтаксиса и перейти к нужному курсору (в кэше курсоров сеанса);
- ничего не сделать и сразу перейти к нужному курсору (если имеется в кэше PL/SQL).
Для парсинга и оптимизации новой инструкции SQL Oracle должен посетить (и, возможно, загрузить) кэш словаря, для чего необходимо приобрести защелку кэша словаря и, возможно, выполнить некоторые операции с разделяемым пулом, чтобы выделить фрагмент памяти. Более того, при загрузке инструкции и курсора в библиотечный кэш, может потребоваться выполнить дополнительные операции с разделяемым пулом, чтобы вытеснить из памяти какие-либо объекты и объединить смежные фрагменты.
Несмотря на то, что оптимизация и кэширование призваны минимизировать стоимость выполнения, иногда вызовов парсера может оказаться полезным, особенно в высоконагруженных системах OLTP, когда ради уменьшения конфликтов имеет смысл явно создать и удерживать курсор, пусть и ценой усложнения кода.
All the connections are evenly distributed to both the nodes but we see more load on node-1 (95% CPU). node-1 is less than 50% CPU.
And in node-1 the CPU is high because of Concurrency --> library cache: mutex X wait. and there is no blocking sessions on the database. Dose anyone had similar issue?
C.3.11 BFILE open
The session waits for an external large object (LOB) to open.
Wait Time: The total elapsed time for the isopen call
C.3.12 BFILE read
The session waits for a read from a external large object (LOB) to complete.
Wait Time: The total elapsed time for the read to complete
C.3.14 broadcast mesg recovery queue transition
Processes enter "wait for broadcast mesg recovery queue transition" when cleaning up a publisher channel handle to a RELIABLE broadcast channel. The broadcasted message is in the recovery queue of another channel handle (for example, ch2). Process enters this wait, if the message is yet to be removed from the recovery queue of the ch2 channel handle. This wait event will most likely appear when an Oracle process is about to exit normally, or when PMON cleans up a dead process.
Wait Time: Varies
Publisher channel handle pointer
Broadcast message pointer
A number indicating the function in KSR where the process is waiting
C.3.9 BFILE get path object
The session is waiting on a call to find or generate the external path name of an external large object (LOB).
Wait Time: The total elapsed time for make external path to complete
C.3.4 BFILE check if exists
The session waits to check if an external large object (LOB) exists.
Wait Time: The total elapsed time for the exists call
C.3.5 BFILE check if open
The session waits for an external large object (LOB) to open.
Wait Time: The total elapsed time for the isopen call
C.3.14 broadcast mesg recovery queue transition
Processes enter "wait for broadcast mesg recovery queue transition" when cleaning up a publisher channel handle to a RELIABLE broadcast channel. The broadcasted message is in the recovery queue of another channel handle (for example, ch2). Process enters this wait, if the message is yet to be removed from the recovery queue of the ch2 channel handle. This wait event will most likely appear when an Oracle process is about to exit normally, or when PMON cleans up a dead process.
Wait Time: Varies
Publisher channel handle pointer
Broadcast message pointer
A number indicating the function in KSR where the process is waiting
C.3.7 BFILE get length
The session waits on a call to check the size of an external large object (LOB).
Wait Time: The total elapsed time for the call to check the LOB size
C.3.9 BFILE get path object
The session is waiting on a call to find or generate the external path name of an external large object (LOB).
Wait Time: The total elapsed time for make external path to complete
C.3.8 BFILE get name object
The session waits on a call to find or generate the external name of a external large object.
Wait Time: The total elapsed time for make external file name to complete
C.3.3 ASYNC Remote Write
Used to track the time (in centiseconds) for asynchronous streaming RFSWRITE operations. This includes stall reaps and streaming network submission time. This time is accumulated by TT nn (Redo Transport Slave) background processes.
Oracle Data Guard Concepts and Administration for more information about using RFS to manage standby redo logs.
Мьютексы
Как мне кажется, мьютексы в Oracle выполняют две функции. Прежде всего они используются в качестве защелок – мьютекс является очень маленькой структурой (примерно 24 байта) и обрабатывается очень простым кодом, включающим атомарные, непрерываемые операции для изменения значения мьютекса. То есть мьютекс можно использовать, чтобы сказать: «Мьютекс установлен в блокирующее значение – не трогайте объект X». Но мьютексы могут также использоваться как счетчики, то есть, с его помощью можно сказать: «Сейчас объект читают N пользователей – не изменяйте его».
В Oracle мьютексы были введены для защиты хэш-блоков, в частности – хэш-блоков в библиотечном кэше. Вспомните, что у нас было всего несколько защелок (от 3 до 67), охватывающих десятки тысяч хэш-блоков в библиотечном кэше. В 11.2 каждый хэш-блок получил свой мьютекс; такое решение позволило свести к минимуму конфликты за обладание защелок и устранило ложную конкуренцию (например, когда одному сеансу нужен хэш-блок с номером 1, а другому – с номером 131 071 и оба состязаются за обладание одной и той же защелкой). Это – пример использования мьютекса в роли защелки.
Примечание. Одно из важнейших отличий между мьютексами и защелками состоит в том, что Oracle всегда знает, где находятся все защелки – то есть внутренний код может накапливать информацию об использовании всех защелок. Мьютексы являются динамическими образованиями – когда сеанс создает новый дочерний курсор, он создает также новые мьютексы, как часть дочернего курсора. Это делает невозможным сбор информации об использовании всех мьютексов более или менее эффективным способом. Цена обхода связанного списка мьютексов могла бы оказаться слишком высокой, а если на мьютексы возложить задачу самим сохранять информацию в центральном пуле статистик, это привело бы к тем же самым проблемам конкуренции, для решения которых были созданы мьютексы. Поэтому мьютексы ведут только статистики, сообщающие о проблемах, которых, теоретически, должно быть не так много и тяжелых проблем с конкуренцией из-за этого не должно наблюдаться.
В этом блоге отмечалось, что мьютекс может удерживаться «продолжительное» время. Именно поэтому мьютексы могут занять место закрепления библиотечного кэша (library cache pin, x$kglpn ). Перед выполнением запроса, вместо присоединения структуры к дочернему курсору, чтобы закрепить Кучу 6 в памяти, сеанс может просто увеличить значение мьютекса (выполнив атомарную машинную инструкцию), являющегося частью этого дочернего курсора, а затем уменьшить его. В теории кажется возможным точно так же заменить блокировку библиотечного кэша (library cache lock, x$kgllk ) для Кучи 0, и это действительно так. Кроме того, в структуру дочернего курсора встроено два мьютекса – в действительности x$kglob (структура, являющаяся основой для представления v$sql ) сообщает о трех мьютексах, но я думаю, что один из них просто является ссылкой на мьютекс хэш-блока.
Несмотря на то, что мьютексы были введены в 11g для замены механизма закреплений, структура x$kglpn никуда не делась (как и x$kgllk ) и кое-где мьютексы еще не заменили закрепления. Например, если попытаться перекомпилировать процедуру PL/SQL в то время, как она выполняется, можно увидеть, что сеанс ожидает освобождения library cache pin . Возможно, вам интересно будет провести один стандартный тест, который я выполняю после обновления. Он заключается в том, чтобы скомпилировать и выполнить следующую хранимую процедуру:
Однажды вы можете обнаружить, что блокировки и закрепления просто исчезли из библиотечного кэша. Однако, имеются изменения и другого рода, коснувшиеся узких мест в механизмах распределения памяти и создания защелок, вообще устранившие потребность в блокировках и закреплениях. В 11g (и даже в 10g) сеанс один раз приобретает большой фрагмент памяти и затем создает в нем блокировки и закрепления, благодаря этому устраняется конкуренция за доступ к разделяемой памяти.
C.3.13 broadcast mesg queue transition
Processes enter "wait for broadcast mesg queue transition" when cleaning up a publisher channel handle to a RELIABLE broadcast channel. The publisher is responsible for moving the message to the free queue, but it cannot do so until the message is in the done queue. If the message is still not in the done queue, process enters this wait. This wait event will most likely appear when an Oracle process is about to exit normally, or when PMON cleans up a dead process.
Wait Time: Varies
publisher channel handle pointer
broadcast message pointer
A number indicating the function in KSR where the process is waiting
C.3.4 BFILE check if exists
The session waits to check if an external large object (LOB) exists.
Wait Time: The total elapsed time for the exists call
C.3.6 BFILE closure
The session waits for an external large object (LOB) to close.
Wait Time: The total elapsed time for the close call
C.3.8 BFILE get name object
The session waits on a call to find or generate the external name of a external large object.
Wait Time: The total elapsed time for make external file name to complete
Выполнение, блокировка и закрепление
Предположим, что мне требуется выполнить запрос, для которого в библиотечном кэше уже имеется подходящий дочерний курсор с готовым планом выполнения. В этой ситуации все равно придется выполнить некоторую работу, чтобы найти, подготовить и выполнить его. В худшем случае я просто передам в Oracle фрагмент текста с инструкцией. В ходе обработки текста Oracle выполнит синтаксический анализ, вычислит хэш-значение текста, найдет в библиотечном кэше соответствующий хэш-блок, просмотрит хэш-цепочку, найдет дочерний курсор, проверит его соответствие инструкции и выполнит план. В этой точке вполне может обнаружиться, что план был удален из памяти, и тогда Oracle вынужден будет повторно оптимизировать инструкцию – нарастить статистику parse count (hard) сеанса и увеличить Misses in library cache during execute , если в этот момент выполняется трассировка. Узнать, как часто такое случается, можно с помощью статистики v$librarycache.reloads для строки ‘SQL AREA’ .
Примечание. Представление v$librarycache сообщает о двух причинах повторной загрузки плана выполнения: либо план был вытолкнут из памяти по требованию, либо он стал недействительным из-за переопределения некоторого зависимого объекта. Ориентировочно разность reloads - invalidations позволит оценить, сколько работы приходится делать из-за проблем, связанных с нехваткой свободной памяти.
На разных этапах описываемого процесса необходимо также позаботиться о проблемах конкуренции. Следуя традиционным путем, можно было бы приобрести и удерживать защелку хэш-цепочки в библиотечном кэше в течение всего времени поиска подходящего курсора. Можно было бы создать блокировку библиотечного кэша (блокировку KGL) для кучи 0, чтобы гарантировать, невозможность выталкивания ее из памяти, или создать закрепление библиотечного кэша (закрепление KGL), чтобы исключить возможность выталкивания плана (Куча 6 / SQL Area) до окончания выполнения запроса. Однако, как вы помните, все эти защелки, связанные с библиотечным кэшем, появившиеся в 10g – такие как library cache pin allocation – закрепления и блокировки представляют собой небольшие фрагменты памяти, размещаемые в разделяемом пуле. То есть, для закрепления курсора требуется приобрести несколько защелок и выделить память. Это довольно дорого, особенно если к скорости выполнения предъявляются жесткие требования.
В Oracle реализовано множество стратегий для минимизации «инфраструктурных» затрат на поиск и выполнение инструкций. В 10.2, например, сеансы получили возможность кэширования закреплений KGL (скрытый параметр _session_kept_cursor_pins ), подобную возможности кэширования дескрипторов буферов. В 11g блокировки и закрепления KGL, которые может приобрести сеанс, размещаются страницами (а не по отдельности), за счет чего снижается число запросов на выделение памяти и ее фрагментация. Помимо этих последних нововведений, сохраняется также возможность удерживать курсоры открытыми, что по сути означает удержание блокировки библиотечного кэша в течение всего времени и закрепление Кучи 0 в памяти (хотя это не закрепление KGL, в данном случае под «закреплением» подразумевается флаг, установленный диспетчером кучи). Это – функция структуры x$kgllk , официально доступной через v$open_cursor . Имеется также кэш курсоров сеанса (session cursor cache), дающий библиотечным функциям возможность удерживать курсоры открытыми, даже когда пользовательское приложение не требует этого.
Можно сделать еще один шаг вперед, сохранив закрепление ( x$kglpn ) в куче 6 – план выполнения – установкой параметра cursor_space_for_time в значение true (не самое лучшее решение, если оно не основано на веских причинах, потому что побочный эффект закрепления кучи 6, когда уже закреплена куча 0, ограничивает число незакрепленных воссоздаваемых объектов, которые можно освободить в случае нехватки памяти). Однако, параметр cursor_space_for_time признан устаревшим в 11g, возможно потому, что в Oracle решили, что этот параметр был решением проблемы, которая отсутствует в новейшей стратегии закрепления (реализация которой начата в 10g и близка к завершению в 11g): мьютексах.
C.3.12 BFILE read
The session waits for a read from a external large object (LOB) to complete.
Wait Time: The total elapsed time for the read to complete
C.3.1 alter system set dispatcher
A session has issued a statement ALTER SYSTEM SET DISPATCHER = string and is waiting for the dispatchers to get started.
Wait Time: The session will wait 1 / 100 of a second and verify if the new dispatchers have started, else the session will wait again
Number of times that the session has waited 1 / 100 of a second
C.3.2 ARCH Remote Write
Used to track the time (in centiseconds) that ARC n background processes spend blocked waiting for network write operations to complete.
C.3.1 alter system set dispatcher
A session has issued a statement ALTER SYSTEM SET DISPATCHER = string and is waiting for the dispatchers to get started.
Wait Time: The session will wait 1 / 100 of a second and verify if the new dispatchers have started, else the session will wait again
Number of times that the session has waited 1 / 100 of a second
C.3.15 buffer busy waits
Wait until a buffer becomes available.
There are four reasons that a session cannot pin a buffer in the buffer cache, and a separate wait event exists for each reason:
"buffer busy waits": A session cannot pin the buffer in the buffer cache because another session has the buffer pinned.
"read by other session": A session cannot pin the buffer in the buffer cache because another session is reading the buffer from disk.
"gc buffer busy acquire": A session cannot pin the buffer in the buffer cache because another session is reading the buffer from the cache of another instance.
"gc buffer busy release": A session cannot pin the buffer in the buffer cache because another session on another instance is taking the buffer from this cache into its own cache so it can pin it.
Prior to release 10.1, all four reasons were covered by "buffer busy waits." In release 10.1, the "gc buffer busy" wait event covered both the "gc buffer busy acquire" and "gc buffer busy release" wait events.
Wait Time: Normal wait time is 1 second. If the session was waiting for a buffer during the last wait, then the next wait will be 3 seconds.
This section provides detailed descriptions for those wait events of greatest interest.
Where appropriate, pointers are provided to further information elsewhere in Oracle Database documentation. For a complete listing of wait events, in alphabetical order, you can issue the following SQL statement:
C.3.13 broadcast mesg queue transition
Processes enter "wait for broadcast mesg queue transition" when cleaning up a publisher channel handle to a RELIABLE broadcast channel. The publisher is responsible for moving the message to the free queue, but it cannot do so until the message is in the done queue. If the message is still not in the done queue, process enters this wait. This wait event will most likely appear when an Oracle process is about to exit normally, or when PMON cleans up a dead process.
Wait Time: Varies
publisher channel handle pointer
broadcast message pointer
A number indicating the function in KSR where the process is waiting
Answers
MR139 wrote:
And in node-1 the CPU is high because of Concurrency --> library cache: mutex X wait. and there is no blocking sessions on the database. Dose anyone had similar issue?
Some time back I came across this, where my AWR was showing very high "library cache: mutex X".
End of the analysis, that was due to many sessions trying to use/update same block. Certain set of processes were updating data in a way that was doing lot if index splitting and changes to the index, concurrently.
We stopped few of the processes and things were much better (later on we fixed our application).
Providing Instance effeciency percentages will help.Also look at cusror_sharing parameter and session cached cursors.
I encountered a issue similat to this after upgrade from 10g to 11g leaving cursor_sharing value to similar.(which shouldnot be).
This may be due to execessive soft parsing as well .Take a lool at session cached cusor value if it less you may need to increase
Edited by: rajdhanvi on Jul 4, 2012 8:37 AM
I think this wait event is not available in DOC.. I would recommend you see MOS Note WAITEVENT: 'library cache: mutex X' ID 727400.1
is it consistently this high? Can you post excepts from an AWR report for that node covering:
1) workload profile
2) top timed events
3) OS and instance CPU usage
4) top SQL
Also, please post some sample entries from the ASH.
Best regards,
Nikolay
I think its because of the Memory size. we have too low shared pool, so I thought of enabling AMM and increase the SGA Size. But I woild like to have some suggestions.
Your problem is quite obvious -- you are doing over 300 hard parses per second, i.e. 1 hard parse for every 3 executions (!!). Your hard parse time is accountable for most of the DB time ( 4,789.4 s out of 7,528.4 s). That, btw, could cause all sorts of library cache contention, including library cache: mutex X (and also explains why library cache: lock and library cache: pin are in the top-5 list, even though with rather small percentages).
Fix your parsing problem, and that will make all the differences in the world.
Best regards,
Nikolay
I really appreciate you time, I am sorry for not replying, Because I didn't get a chance to do any change/test in the database yesterday.
We did enabled AMM and increased shared pool to 1G. Now it looks better but not 100%. I am not sure how to find and resolve the hard parse, I guess need to check the application code, so we are working with s/w vendor.
Thank you so much for you help and sorry for late reply.
thanks for the update.
I don't think how this would be help you with your issue. In fact, don't the two parts of this sentence mutually exclude each other?
AMM means that memory is managed automatically, i.e. you don't get to decide how big your shared pool is, Oracle decides that for you.
I am not sure how to find and resolve the hard parse, I guess need to check the application code, so we are working with s/w vendor.
The first step would be to identify where all those unsharable SQL statements come from. The most likely possibility is not using binds, but there are
other possibilities as well (e.g. an ACS bug).
I would start by looking at:
1) SQL by parse calls
2) multiversioned cursors
3) statements with similar text, different sql_id's and same force_matching_signature
This section provides detailed descriptions for those wait events of greatest interest.
Where appropriate, pointers are provided to further information elsewhere in Oracle Database documentation. For a complete listing of wait events, in alphabetical order, you can issue the following SQL statement:
C.3.5 BFILE check if open
The session waits for an external large object (LOB) to open.
Wait Time: The total elapsed time for the isopen call
C.3.3 ASYNC Remote Write
Used to track the time (in centiseconds) for asynchronous streaming RFSWRITE operations. This includes stall reaps and streaming network submission time. This time is accumulated by TT nn (Redo Transport Slave) background processes.
Oracle Data Guard Concepts and Administration for more information about using RFS to manage standby redo logs.
C.3.2 ARCH Remote Write
Used to track the time (in centiseconds) that ARC n background processes spend blocked waiting for network write operations to complete.
C.3.11 BFILE open
The session waits for an external large object (LOB) to open.
Wait Time: The total elapsed time for the isopen call
C.3.15 buffer busy waits
Wait until a buffer becomes available.
There are four reasons that a session cannot pin a buffer in the buffer cache, and a separate wait event exists for each reason:
"buffer busy waits": A session cannot pin the buffer in the buffer cache because another session has the buffer pinned.
"read by other session": A session cannot pin the buffer in the buffer cache because another session is reading the buffer from disk.
"gc buffer busy acquire": A session cannot pin the buffer in the buffer cache because another session is reading the buffer from the cache of another instance.
"gc buffer busy release": A session cannot pin the buffer in the buffer cache because another session on another instance is taking the buffer from this cache into its own cache so it can pin it.
Prior to release 10.1, all four reasons were covered by "buffer busy waits." In release 10.1, the "gc buffer busy" wait event covered both the "gc buffer busy acquire" and "gc buffer busy release" wait events.
Wait Time: Normal wait time is 1 second. If the session was waiting for a buffer during the last wait, then the next wait will be 3 seconds.
C.3.7 BFILE get length
The session waits on a call to check the size of an external large object (LOB).
Wait Time: The total elapsed time for the call to check the LOB size
C.3.6 BFILE closure
The session waits for an external large object (LOB) to close.
Wait Time: The total elapsed time for the close call
C.3.10 BFILE internal seek
The session waits for a positioning call within the external large object (LOB) to complete.
Wait Time: The total elapsed time for the seek to complete
C.3.10 BFILE internal seek
The session waits for a positioning call within the external large object (LOB) to complete.
Wait Time: The total elapsed time for the seek to complete
Читайте также: