
Ли седоль против компьютера
Продолжаем разбирать матч, в котором компьютер наконец умудрился победить человека, играя в го. Начало здесь:
Вторая партия
Ли всё ещё в шоке, но сохраняет оптимизм. Во второй партии Альфа играет уже чёрными.
На этот раз Ли должно быть решил играть спокойно, мирно, в классической манере.
Го это игра балланса, например можно построить надёжные укрепления, которые не дают много очков, но в будущей битве эти укрепления сильно помогут и полностью окупят себя.
Начало было необычным - 13-м ходом Альфа, не закончив классическое дзёсэки, сыграла в другой части доски.
Наверно стоит объяснить этот термин. Дзёсэки - это стандартный обмен ходами в углу.
За сотни лет истории го люди вычислили наиболее оптимальные и правильные последовательности ходов, которыми следует обмениваться, сражаясь за угол. Дзёсэк тысячи (и у каждой может быть немало вариаций), но есть пара десятков дзёсэк, что известны всем. Эта дзёсэка как раз входит в эти два десятка, её очень часто играют.

Так вот, Альфа просто проигнорировала эту дзёсэку (если верить базам партий, такого у профессиональных игроков ещё не встречалось), и построила вместо этого крепость в верхней части доски (такую позицию, кстати, называют китайским фусеки).
Обычно после такого стоит атаковать не законченную структуру чёрных, но Ли вместо этого поставил камень в левой части доски (наверно опасаясь что Альфа проигнорирует атаку и сама туда сыграет, сделав свою крепость ещё неприступнее). Он словно боялся атаковать.
15-м ходом Альфа сыграла угрозу разрезания - и все комментаторы дружно признали этот ход ошибочным. Считается, что такой обмен нужно делать только если есть причина для него, Альфа же сделала его на пустой доске, лишив себя адзи (то есть обрезав себе несколько возможных дальнейших вариантов игры)

Сразу после этого Альфа атаковала левый нижний угол доски, захватила его, отдав взамен белым влияние, но при этом успела погасить это влияние ходом 29, закончив наконец свою позицию снизу. При этом она сыграла высоко, по четвёртой линии, нацеливаясь в будущем на атаку белой стенки.
И вроде игра пока была мирной, но выглядит всё уже как то не здорово для Ли.
Динерштейн по этому поводу недоумевал - мол зачем Ли не выбрал другое дзёсэки?
После этого пошёл обмен ходами, при котором Ли играл надёжно и скромно.
И тут 37-м ходом Альфа надавила на белых по 4-й линии, после чего все комментаторы дружно заявили что комп свихнулся! Человеку такой ход бы в голову не пришёл. Лично мне сложно судить - слишком хитрый и сложный ход, с трудом вижу его смысл, но есть мнение что он был гениальным. Выглядит так, будто Альфа хотела посмотреть как ответит Ли, чтобы определиться с дальнейшими действиями.

Ли отбросил Альфу вверх, после чего альфа начала атаку белой стенки, чтобы воспользоваться отброшенными камнями и получить территорию в центре.
После атаки всё выглядит грустно для белых - очков с гулькин нос, а влияние погашено.
Комментаторы, впрочем, всю партию говорили о том, что позиция равная - они будто видели только ошибки чёрных, а на ошибки белых закрывали глаза.
Ходом 65 Альфа закрывает свой угол после чего усиливает свою крепость наверху, получая приятную позицию: всё крепко, очков много.

Не буду утомлять дальнейшими ходами - были атаки, контратаки, внедрения, мелкие ошибки, но ничего неожиданного. Вскоре кончилось время, и игроки стали тратить не более минуты на ход. В конечном итоге Ли сдался - Альфа лидировала очков на 7 вперёд.
Что в итоге: Если в первой партии было впечатление что Ли Седоля подловили, что он зевнул, но вообще играет не хуже, то во второй партии компьютер его спокойно и последовательно задавил. Да, Альфа ошибалась, но её ошибки были мелкими, Ли же ошибался более глобально.
Глава DeepMind Хассабис сказал про эту партию что AlphaGo была уверена в победе ещё где-то с середины игры. Сам же Ли Седоль сказал, что всё здесь было плохо с первого хода. Он ни разу не чувствовал что у него был перевес. Похоже что комментаторы, которые говорили как у него всё здорово, просто болели за него.
Один восьмой дан даже извинился в твиттере, мол желание чтобы Ли победил затуманило ему понимание игры.
Третья партия
Ли Сеголь играет чёрными.
Эта партия могла стать решающей - ещё одно поражение и победить в этом матче уже будет нельзя. Поэтому Ли подошёл к ней серьёзно. Он не спал ночами - анализировал в окружении своих коллег сыгранные партии и готовился к битве.
В Сеул же прибыл сооснователь Google Сергей Брин - тот который справа, самый довольный.

Слева направо: основатель DeepMind Демис Хассабис, Ли Седоль, Сергей Брин.
Замечу что в го самой сложной для компьютеров проблемой считается ко-борьба. Это ситуация, при которой локальная борьба может влиять на самые разные участки доски. Все без исключения программы (по крайней мере до Альфы) можно было подловить навязав им ко-борьбу.
Ли, должно быть, решил воспользоваться этой ахиллесовой/компьютерной пятой и устроить ко-борьбу в конце партии, как он это обычно любит делать.
В начале партии Ли решил использовать китайское фусеки. Возможно потому что в прошлой партии Альфа использовала китайское фусеки против него самого. Вот эти 3 чёрных камня на верхней стороне называются “Высокий Китай”. Так часто играют.

Вскоре начинается борьба в левом верхнем углу - видно как 2 безглазые группы пытаются окружить и задушить друг дружку.

И вот, к 112-му ходу видно что белые окружили здоровенный кусок территории внизу, и обеспечили жизнь своей белой группе. У них всё в порядке.
У чёрных же немножко территории тут, немножко там.

Делать нечего, Ли высаживает десант на огромную территорию белых. При этом действует необыкновенно искусно и круто. Он умудряется провести эффективную атаку и устроить очень сложную ко-борьбу. Но увы, Альфа показала, что умеет работать и с ко-борьбой.
В результате 3-е поражение подряд.
На пресс-конференции после игры Ли сказал что слабые места у Альфы были и извинился перед корейской нацией и сообществом игроков го за показанный результат.
Итак, компьютерный бот захватил очередной бастион человечества, который сопротивлялся ботам так долго.
Мир го это огромная система - здесь есть мастера, школы, академии, легенды, великие традиции, тысячи лет истории, море книг. И вдруг в него попадает робот. В нём нет ни страха, ни жадности, ни сомнений. Он не ведёт диалог, ничего не объясняет - он просто делает единственно правильные ходы. То есть если люди, обсуждая партию могут рассматривать несколько возможных ходов, которые выглядят неплохо, то робот просто сделает один ход и всё. Почему этот ход а не тот? Да потому что этот ход правильный, а тот нет. И при этом он всегда прав. Сражаться с ним - всё равно что бить кулаком о бетонную стену. Го скоро постигнет грустная судьба шахмат.
Такое вот впечатление возникает поначалу. Так ли это?
Возможно всё проясниться в следующей части, когда мы посмотрим на заключительные партии!

> здесь есть мастера, школы, академии, легенды, великие традиции, тысячи лет истории, море книг. И вдруг в него попадает робот
Этот робот обучался первоначально на партиях людей, которые за эту тысячу лет накопились.
Читаю ваши посты про Альфу vs Ли словно остросюжетный детектив. И со своих низин го-нуба восхищаюсь игроками.
И тут пришел Pluribus
Новую разработку университет Карнеги Меллон делал вместе с Facebook. В 2019 году Pluribus сыграл два матча: в одном он сражался с пятью профессионалами, в другом – профессионалы сражались с пятью копиями AI, которые не передавали информацию друг другу. Иными словами, Pluribus решил победить самый популярный тип покера.
За 12 дней компьютер сыграл 10 тысяч раздач и оказался успешен в обеих дисциплинах – покерные игроки не могли подобрать ключ к искусственному интеллекту ни в одиночку, ни когда все были за столом. Pluribus постоянно менял стратегии, не давая возможности различить паттерны в его действиях. Кроме того, он делал шаги, которые в покере считаются минусовыми и ассоциируются с действиями новичков. В частности, обсуждались его частые «донк-беты»: компьютер играл пассивно, а когда на столе появлялась следующая карта, вдруг ставил в оппонента, который до этого был агрессором (как правило, такие ставки считаются показателем блефа и легко раскусываются даже непрофессиональными игроками).
Из комментариев профессиональных игроков мы знаем, что все AI играют не только непредсказуемо, но и очень агрессивно: чтобы проверять их блефы или полублефы, игрокам надо жертвовать значительным количеством фишек. Кроме того, в его модель было заложено, чтобы Pluribus в основном сосредотачивался на следующих двух-трех шагах, а не на долгосрочной стратегии – и это дало неожиданно хорошие результаты.

«Можно с уверенностью сказать, что он играет на сверхчеловеческом уровне. И это уже не поменяется», – уверен один из разработчиков Pluribus Ноам Браун.
Теоретически еще остались виды покера, в которых искусственному интеллекту предстоит доказать свою состоятельность – например, в больших турнирах, где стратегию необходимо адаптировать к постоянному увеличению обязательных ставок. Тем не менее, уже сейчас можно сказать, что покер стал «решенной» игрой.
Разработчики Pluribus не планируют зарабатывать на покере: их модель перестала обновляться, и можно надеяться, что по крайней мере какое-то время такие AI не выйдут из стен научных лабораторий и не убьют онлайн-покер. Сами ученые считают, что похожие на Pluribus системы пригодятся в кибербезопасности, в финансовых переговорах, для предотвращения преступлений или будут помогать компьютерам в беспилотных автомобилях – в общем, везде, где приходится сталкиваться с решением задач с неполной информацией.
Ну а игрокам в покер остается только изучать раздачи Pluribus и других AI и подмечать в них что-то, что сделает их похожим на суперкомпьютер. А также соревноваться в онлайн и офлайн-турнирах по типу WSOP, Мировой серии покера для живых людей (искусственному интеллекту вход запрещен), которая в этом году проходила в покер-руме GGпокерок. За время серии общий призовой фонд превысил несколько десятков миллионов долларов.
Великая Французская революция началась на (почти) теннисном корте. Там буржуазия бросила вызов королю
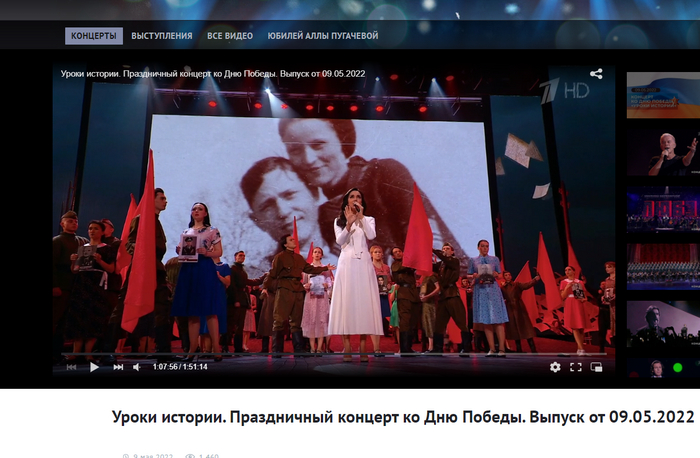
Бонни и Клайд на Первом канале
Сегодня прошел праздничный концерт, приуроченный к 77-летию Победы в Великой Отечественной войне. Под исполнение композиции "Если б не было войны" из фильма "Приказ: огонь не открывать" на экране мелькали фотографии молодых людей (военные и довоенные фото) и вдруг мелькает Бонни, и мать его, Клайд собственной персоной. При чем тут они? Вы там на Первом совсем с ума сошли??
upd: 22:37. Концерт удален по текущей ссылке


Посла Российской Федерации в Польше облили краской
Посла Российской Федерации в Польше облили краской во время возложения цветов на кладбище советских солдат. Украинские телеграмм-каналы радостно улюлюкают и поддерживают варварские действия.

И снова человек потерпел поражение: Libratus отомстил за Claudico
В 2016-м произошло важное событие не из мира покера, после которого стало понятно, что победа в безлимитной игре – вопрос времени. В 2016-м компьютер AlphaGo победил в го лучшего игрока планеты Ли Седоля.

Особенность той победы в том, что компьютер не перебирал комбинации, а учился «думать». Позднее в усовершенствованные AI системы AlphaGo вообще перестали загружать партии с людьми – искусственный интеллект учился только на партиях с самим собой (последняя версия AlphaGo обыграла ту, против которой сражался Ли Седоль, со счетом 100:0).
Одновременно с этим происходила работа над «решением» покера. Наиболее значительных результатов добились в Университете Карнеги Меллон. Сначала там создали Claudico, который в 2015 году сразился с четырьмя профессионалами в хедз-ап покер и проиграл – три из четырех профессионалов обыграли искусственный интеллект на дистанции в 80 тысяч раздач, на время подтвердив, что компьютеру не дается блеф.
За Claudico отомстил Libratus, разработка того же университета. В 2017 году он сразился также против четырех профессионалов, на этот раз количество раздач было увеличено до 120 тысяч, это заняло 20 дней. Уже в начале стало понятно, что профи соревнуются не с Libratus, а между собой – кто проиграет меньше всех. Компьютер легко обыграл всех четверых, зарабатывая по 14,7 больших блайнда за 100 раздач.
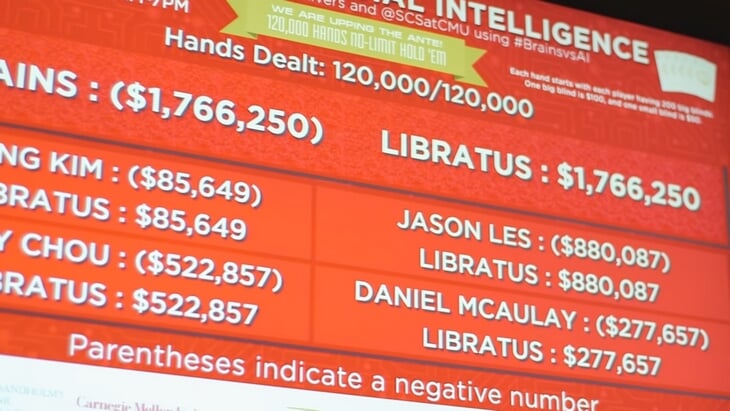
Теперь ученым предстояло самое сложное: допустить компьютер до покера, в котором играет больше двух человек. AI должен был не только научиться держать в голове несколько стратегий разных оппонентов, но и разыгрывать мультипоты – когда до вскрытия могут дойти сразу несколько человек.
Го долго не давалась компьютерам: все ходы не просчитать, нужны интуиция и абстрактное мышление
Программисты уже давно проверяют мощь искусственного интеллекта в сложных играх с лучшими из людей. Разработанный IBM компьютер Deep Blue обыграл Гарри Каспарова в шахматы еще в 1997 году. Перед матчем Каспаров думал: «Это просто машина. Машины глупые». Но после поражения признавался: «Я чувствовал – чуял, – что за столом был новый тип разума».
Чтобы победить Каспарова, Deep Blue использовал грубую вычислительную силу: после каждого хода программа просчитывала все возможные варианты развития событий и принимала решение на основе этих данных.

Но с го такой подход не работает из-за объема данных, которые нужно обрабатывать. В го игроки по очереди ставят черные и белые камни на доску 19 на 19. Задача игры – занять как можно больше территории, при этом запирая камни противника, не давая ему получить преимущество. В целом го похожа на знакомую многим по школе игру в точки – только сложнее.
Из-за размера доски уже для первого хода, который делают черные камни, возможен 361 вариант (в шахматах – всего 20). Соответственно, с каждым ходом древо потенциальных расстановок только разрастается. После первых двух ходов в шахматах существует 400 возможных развитий событий, в го – 129 960. В блоге Google, разработавшего AlphaGo, писали, что в целом количество возможных комбинаций больше, чем атомов во вселенной. Математик Джон Тромп подсчитал, что это будет 171-значное число.
Поэтому от людей в игре в го требуется не только интеллект и способность к расчетам, но и мощное абстрактное мышление, сильная интуиция – качества, которые слабо развиты у компьютеров. Один из разработчиков AlphaGo Демис Хассабис рассказывал: «Это очень интуитивная игра. Мастера го часто говорят, что сделали тот или иной ход, потому что он казался правильным». По его словам, у мастеров развивается особое эстетическое чувство, и хорошая позиция просто выглядит красиво.

Несмотря на то, что процессоры с каждым годом становятся все мощнее и быстрее, поиск ходов на древе возможностей помог искусственному интеллекту достичь в го только уровня сильного любителя. Компьютеры обыгрывали людей, но только получив фору в несколько камней.
В 2014-м Дэвид Фотланд, один из первопроходцев го для компьютеров, рассказывал, что программы сталкиваются с той же проблемой, что и люди: «Многие игроки достигают определенного любительского пика и не могут стать сильнее. Чтобы преодолеть это плато, нужно сделать какой-то ментальный скачок, и у программ возникают те же проблемы. Нужно смотреть на всю доску, а не только на локальные битвы».
Чтобы преодолеть этот интеллектуальный барьер и симулировать интуицию и эстетическое чувство профессионалов, разработчики AlphaGo подключили нейросети (сети процессоров и софта, симулирующие работу нейронов человеческого мозга) и алгоритмы глубинного обучения.
Сначала в нейросети AlphaGo скормили базу данных человеческих игр, в которую входило примерно 30 миллионов ходов. После этого он научился правильно предсказывать ход человека в 57% случаев, хотя предыдущий рекорд ИИ составлял 44%. Затем разработчики научили AlphaGo играть против самого себя – так компьютер научился еще лучше выделять максимально выгодные ходы и разрабатывать новые стратегии.
Все это помогло рационализировать процессы, на которых работал обыгравший Каспарова Deep Blue. Теперь система не просто разыгрывает все возможные комбинации, а умеет сосредотачиваться на наиболее перспективных вариантах развития событий. Кроме того, она ориентируется даже в ситуациях, с которыми еще никогда не сталкивалась. А такие из-за масштабности го оставались. За счет нового механизма AlphaGo обыграл всех ранее созданных компьютерных игроков (при этом давая им фору в четыре камня) и начал побеждать людей-профессионалов.

В октябре 2015-го AlphaGo разгромил двукратного чемпиона Европы француза Фань Хуэя. Они сыграли пять партий, никто не получал фору, и компьютер выиграл все пять. Это был первый случай, когда машина победила профессионального человека. После матча Хуэй рассказывал, что многому научился, и эти знания помогли ему прибавить и подняться в международном рейтинге.
А в 2016-м AlphaGo играл с Ли Седолем и победил 4:1. Этот матч, который только в Китае смотрели 60 миллионов человек, получился историческим по ряду причин.
Одинокая блондинка или рассказ как я провела выходной
Солнце соблазнило выехать на природу.
Не с кем, подумала я😔
ну и х. с ним, в тишине одиночества есть свой кайф, да и скотина напросилась со мной на прогулку

Собственно вот и она, моя Мойша

Ну и конечно как же без мяса на природе 😋

Тихо, сплошная благодать😇

😅 ну по фото видно, что рыбак я от бога 😂

Закат солнца меня просто завораживает 🤩

Вот и день пролетел.
Пора ехать домой

Спасибо за внимание 🤗😘
Всем хороших выходных и конечно с праздником победы!
Компьютер научился играть творчески, но креативность человека сбила алгоритм
Во-первых, как и Каспаров, Ли оказался не готов к тому, как хорошо играет компьютер. По его собственному признанию, первую партию он проиграл из-за этого.
Во-вторых, во второй партии компьютер продемонстрировал приобретенную креативность. В историю го этот момент вошел, как «Ход 37». Многим комментаторам он показался ошибкой – казалось, что ход машины никак не был связан со всем, что она делала раньше.

Но эксперты оценили. Фань Хуэй, работавший судьей на матче, потом рассказывал: «Это не человеческий ход. Я никогда не видел такой ход в исполнении человека. Так красиво». Обратите внимание на эстетический эпитет.
Ли после матча наоборот утверждал, что это был не компьютерный ход: «Я думал, что меня ждет очень эффективная машина, которая будет из сохраненных данных высчитывать лучший ход для каждой конкретной ситуации. Но некоторые ходы мне показались очень творческими. Они показывали красоту го, которую способны создавать только люди».
Этот ход подчеркнул проделанный искусственным интеллектом путь от простого перебора возможностей к мышлению. AlphaGo заточен на довольно консервативную игру, и если вероятность победы с небольшим преимущество составит 95%, а вероятность разгрома – 80%, компьютер выбирает первый путь.
Но Ход 37 не был консервативным. Разработчики AlphaGo позже посмотрели логи, чтобы понять, почему машина его выполнила. Оказалось, она понимала: вероятность того, что человек так поставит свой камень, составляла 1 к 10 000. Но AlphaGo принял такое решение, потому что посчитал его оптимальным для решения поставленной задачи. А еще потому, что оно поставило Ли в тупик – он на 15 минут отошел от стола и долго думал над ответом.
В целом кореец потом рассказывал, что по ходу второй партии у него никогда не было ощущения, что он ведет игру.

В итоге машина не смогла к этому адаптироваться, допустила несколько ошибок, и за следующие 10 ходов вероятность ее победы, по ее собственным расчетам, упала с 70% до меньше 50% и выше этой отметки уже не поднималась. Комментаторы назвали действия Ли божественными.
Разработчики AlphaGo учли поражение и Ход 78, продолжили работу над алгоритмом и в 2017-м отправили обновленную систему играть с мастерами го онлайн. Результат? 60 побед, ноль поражений и одна ничья, которая случилась, потому что человек отключился от интернета. Своего предшественника модернизированный AlphaGo вынес в 100 партиях из 100, используя при этом куда меньше оборудования и вычислительных мощностей.
До искусственного разума еще далеко, хотя победа в го и прорыв
Не у всех победы компьютера вызывают такую же драматичную реакцию, как у Ли. Многие, наоборот, видят в них возможность для сотрудничества, которое в итоге принесет пользу человеку. Например, один из сильнейших игроков в мире Не Вэйпин, проиграв AlphaGo в интернете, сказал: «Го – не такая простая игра, как нам казалось. Людям еще многое в ней нужно исследовать. И бог го прислал эту машину, чтобы она помогла людям это сделать».
Другой китайский гроссмейстер Кэ Цзе тоже указывал на возможные прорывы: «Я полтора года изучал программы, теорию и применял все это на практике. Люди тысячелетиями развивались в игре, но теперь компьютеры говорят, что люди ничего не понимают. Думаю, вообще никто даже близко не приблизился к пониманию основ го».
Сейчас этот компьютер считается лучшим игроком в го в мире и, возможно, когда-нибудь приблизится к пониманию основ игры. Но у разработчиков другие цели. Команда DeepMind подчеркивает, что их искусственный интеллект не заточен только под го, а в будущем сможет решать совершенно не связанные с игрой задачи.

В целом специалисты указывают, что потенциально искусственный интеллект может привести к прорывам в робототехнике, научных исследованиях (вплоть до лекарства от рака), а в повседневной жизни могут появиться, например, не допускающие ошибок финансовые советники на основе ИИ и доступные всем беспилотные машины. А еще обещают, что нейросети будут писать музыку и книги не хуже людей.
С другой стороны, обещанные прорывы пока не наступают. Люди по-прежнему сами сидят за рулем, а американские политики обвиняют Россию в информационных диверсиях – хотя Марк Цукерберг больше года назад обещал Конгрессу, что искусственный интеллект решит проблему фэйковых новостей.
В целом консенсус такой: искусственный интеллект пока очень далек от того, что было показано в «Терминаторе», а мир все же в разы сложнее игры в го. До создания человекоподобных роботов еще очень далеко, потому что компьютеры сейчас даже не могут вести осознанный разговор и решать многие задачи, которые без проблем даются детям.
Но карьеру Ли Седоля компьютер уже завершил. Правда, не совсем. Кореец все еще консультирует разработчиков AlphaGo, а в декабре сыграет с корейским компьютером HanDol. Но в свою победу Ли не верит: «Даже с форой в два камня мне кажется, что я проиграю. Сейчас я даже не слежу за новостями го».
Краснодар-рай для перфекциониста!

Отреставрированный легкий танк МС-1 (Т-18), первый танк советской разработки, прошёл во главе колонны на Параде Победы в Уссурийске

И никто по сербски
России не дают экспортировать зерно в Африку. Украина не может. В Африке начнется голод
Белые гуманные люди приезжают и ставят детям прививки: раньше выживал 1 ребёнок из 10, сейчас все 10. А бананов как росло столько, так столько же как и раньше продолжило расти. Еды стало не хватать. Разразился голод.
Нгонга посадил съедобный кактус, поливал его, через месяц пошел продавать 1 кактус за 3 монетки.
Люди покупали и ели.
Нгонга нанял людей, стали вдесятером сажать кактусы.
Потом Нгонга накупил мотокультиваторов, насосов, лопаты, шланги, трактор.
Посадил в 100 раз больше кактусов.
Приехал с урожаем на рынок - 3 монетки за кактус .
Но уже никто не покупал результаты его трудов: белые люди, в 3 метрах от него, бесплатно-гуманитарно раздавали кучи еды "чтобы спасти африканских детей от голодной смерти" .
Зачем среднестатистическому африканцу тратить 3 монеты на съедобный кактус, если еду можно получить бесплатно?
Сельское хозяйство было убито.
Имани работала на фабрике, которая производила хлопковую ткань. Потом из неё пошивали легкую одежду сами жители.
Продавалась такая ткань не очень дорого и у людей была работа.
Приехали белые люди из Европы и с континента Америка и привезли свою старую поношенную одежду стали раздавать бесплатно. Европейцы купили новую коллекцию одежды. Не выбрасывать же старую! Надо отдать бедным жителя Чад, Конго и ЦАР. Заодно потешить свою "добродетель".
Зарождающаяся текстильная промышленность в Африке пошла по звизде. Имани осталась без работы.
Обычным способом увеличения объемов собранного каучука было введение квот для каждого селения. Те, кто не выполнил квоту, подвергались жестокому наказанию. В некоторых случаях целая деревня могла быть сожжена, если ее жители не собрали нужное количество каучука.
Конго превратилось в один огромный трудовой лагерь. Солдатам выдавалось фиксированное число патронов, и чтобы начальство было уверено в том, что патроны были использованы не зря, им приказали отрезать руки у жертв - после каждого выстрела. Иногда солдаты отрезали руки у живых работников, чтобы оправдаться за потраченный или потерявшийся патрон, из-за чего несчастная жертва оставалась покалеченной на всю жизнь. Даже женщины и дети не были исключены из этого правила. В каждом армейском подразделении был солдат, чей задачей было коптить и сохранять отрубленные руки.
Бельгия успела очень многое получить благодаря деньгам, заработанным королем на торговле каучуком, поэтому власти назвали его действия актом патриотизма и дипломатично скрыли болезненную правду прошлого. После смерти короля в 1909 году был создан новый образ Леопольда II как благодетеля и цивилизатора. Вся история была переписана, а пятна крови были тактично смыты новыми историями о человеколюбии.
Король Леопольд II
Король Леопольд II
Все другие ресурсы прекрасноокими и архицивилизованными европейцами выжимались из Африки точно такими же жертвами.
Кто-то в России сидит на диване и развязно размышляет: "пусть голодают, может хоть работать научатся".

Разбор полетов во время игры от профессионалов
В первой игре матча по го компьютерная система AlphaGo, разработанная сотрудниками DeepMind, победила сильнейшего в мире игрока в го Кэ Цзе. Чемпион из Китая ранее заявлял, что считает возможным переиграть компьютер. Но пока что у него это не получилось сделать. Спустя четыре часа и 15 минут после старта матча 19-летний мастер го был вынужден признать поражение. Сейчас счет 1-0 в пользу компьютера.
Глава компании DeepMind заявил, что сейчас с чемпионом играла обновленная система, архитектура которой была существенно модифицирована. Благодаря этому AlphaGo постоянно учится, причем, в основном, обучение происходит при игре с собой же. Так что от информации по результатам матчей чемпионов-людей система сейчас зависит гораздо меньше. В теории, платформа от DeepMind может обучиться почти всему, далеко не только игре в го.
В январе этого года система AlphaGo сразилась с сильнейшими игроками в серии онлайн-матчей. Разработчики выбрали простой и понятный ник для своей системы — Master. Кстати, среди чемпионов го в этом январском онлайн-матче был и Кэ Цзе, его система тогда тоже переиграла, как и всех других мастеров го.
Сейчас платформа развивает успех, победив чемпиона в первом сражении без особых проблем. Конечно, простой эту игру назвать нельзя, но компьютер с выгодой для себя использует любую ошибку противника. Кэ Цзе в начале матча решил играть черными. Это, в противоположность шахматам, означает возможность сделать первый ход. Он начал уверенно, воспользовавшись стратегией «3–3 point», которую использовал и сам компьютер в январе. Это достаточно неожиданное начало, которое удивило бы и сбило с толку почти любого игрока-человека. Но AlphaGo — не человек, поэтому растерянности практически не было.
Разработчики, кстати, утверждают, что Цзе использовал многие стратегические находки компьютера, которые были зафиксированы на январском матче. «Он (Кэ Цзе, прим. ред.) использует большое количество ходов Master», — заявил комментатор матча Майкл Редмонд, рассказывая об особенностях игры чемпиона. Но это не помогло. Спустя всего три с половиной часа стало очевидно, что компьютер доминирует на игровом поле. Также явно было видно, что система играет еще лучше, чем во время матча с Ли Седолем.
Интересно, что после того, как AlphaGo начала побеждать всех и каждого в онлайн-чемпионате, победы человека уже мало кто ждал. Всего полгода назад уверенных в победе Цзэ было гораздо больше.
Разработчики системы говорят, что теперь она использует ресурсы гораздо эффективнее. Известно, что в сражении система задействовала в 10 раз меньше ресурсов, чем в матче с Ли Седолем. Основа AlphaGo — TPU, кастомный процессор от Google.
В матче перевес был небольшим — AlphaGo стала чемпионом лишь благодаря половине очка. Тем не менее, лидерство системы было, как и говорилось выше, очень заметно. В конце матча Цзэ начал делать несколько странные ходы, которые не давали ему никаких преимуществ. Возможно, это было сделано для того, чтобы выиграть время. Но все равно, к концу игры у чемпиона оставалось всего 13 минут на обдумывание своих ходов, а у ИИ оставалось около полутора часов в запасе.
Кэ Цзе, ранее обыгравший Седоля, заявлял, что выиграет. Но теперь его мнение изменилось. Почти сразу после матча он сказал, что больше не собирается играть в одиночку против ИИ.
А ведь еще совсем недавно считалось, что игра го для компьютера если и не не доступна, то очень сложна. Здесь нужно играть с достаточно высоким уровнем абстракции, предвидеть возможные ходы противника. При этом комбинаций ходов в го больше, чем число атомов во всей Вселенной.

Специалисты говорят, что та версия AlphaGo, которая играет сейчас с китайским чемпионом, может дать три камня форы той версии, что играла с Ли Седолем. Все эксперты, следившие за ходом игры Кэ Цзе, сходятся во мнении, что у него просто не было шансов против компьютера. Возможно, кстати, что перевес в половину очка — это лишь желание создателей AlphaGo добавить драматизма. Если бы система разбила чемпиона в пух и прах в первые же пару часов, то зрелища бы не получилось.
Сражение с Цзэ произошло на празднике го, который проходит с 23 по 27 мая в Китае, городе Вужень, провинция Чжэцян. Alpha Go играет не против одного человека, а участвует в нескольких этапах соревнований, включая такие:
-
«Парное Go» — игра, где один из чемпионов го из Китая будет играть против другого… Все традиционно, кроме того, что у обоих будет собственный напарник AlphaGo. Ожидается, что в таком формате компьютер и человек смогут учиться друг у друга;
Кэ Цзе считает, что компьютерные технологии игры в го будут совершенствоваться, поэтому в будущем смысла сражаться с компьютером просто нет — машина будет побеждать.
С ним согласен и один из профессиональных игроков го Южной Кореи Мок Чинсока: «Мы ждем еще 2 и 3 партию матча AlphaGo с Кэ Цзе, но, вероятно, Ли Седоль станет последним человеком на Земле, кому удалось обыграть AlphaGo».
На прошлой неделе южнокорейский мастер игры в го и один из самых титулованных игроков в мире Ли Седоль объявил о завершении карьеры и сделал драматичное заявление: «После того, как искусственный интеллект начал играть в го, я понял, что не стану лучшим, даже если возглавлю рейтинг за счет безумных усилий. Теперь есть сущность, которую не одолеть».

Ли говорил о компьютере AlphaGo – разработке компании DeepMind, которую пять лет назад за 650 миллионов долларов купил Google. Машине кореец проиграл еще в 2016-м, но с тех пор искусственный интеллект стал только сильнее. А вообще победу компьютера над человеком в го считают настоящим прорывом, который потенциально может привести к масштабным изменения в мире.
Спасибо силовикам
Хочу выразить огромную благодарность полиции, ФСБ, службе внешней разведке, контрразведке и прочим причастным, за то, что в День Победы в нашей стране не произошло ни одного теракта. Они хорошо выполняют свою работу, хотя мы далеко не всегда видим её.
Первая победа: Cepheus

Сконструировать такой искусственный интеллект, который бы устойчиво обыгрывал людей в их любимые игры – одна из самых сложных задач современности, поэтому неудивительно, что ей занимаются в основном ученые. Программу Cepheus, названную то ли в честь персонажа греческой мифологии Кефея, то ли в честь созвездия (а скорее всего – в честь обоих), разработали еще в 2014 году эксперты из университета в Альберте.
Результаты их работы были опубликованы в Science: через 70 дней обучения Cepheus стал настолько хорошо играть в хедз-ап (=один на один) пот-лимит (=с фиксированными ставками) покер, что мог обыгрывать любого профессионала. Более того, он выбирал такие ходы, которые исключали, что человек, даже если будет играть с Cepheus всю жизнь, сможет достичь уровня компьютера. «Мы не говорим, что он будет выигрывать деньги каждую раздачу. Но на дистанции компьютер не может проиграть – будет ничья или победа AI», – радовался один из разработчиков Cepheus Майкл Боулинг.
Тогда казалось, что это еще не конец. В конце концов, покер с лимитированными ставками не настолько популярен, как безлимитный, к тому же понятно, что вариантов применить блеф там намного меньше. Поэтому победа Cepheus не оказала большого влияния на покерный мир, а ученые начали создавать такой компьютер, который бы умел играть в безлимитные игры.
С Днём Победы!

Фото стырено с Вк.
Шахматы – великая настолка СССР: моду задал Ленин, а играли даже в космосе и во время войны

Огромный плюс победы человека: мы увидели, как в интерфейсе AlphaGo выглядит признание поражения.
Сегодня прошла четвёртая партия матча Ли Седоль — AlphaGo. Играют известный 33-летний обладатель девятого профессионального дана и система компьютерного го от подразделения DeepMind компании Google. Сегодня Седоль выиграл.
AlphaGo — продукт от DeepMind, который комбинирует метод Монте-Карло с нейросетями политики и ценности. Играющая в Сеуле система является результатом двух лет работы, в том числе машинного обучения нейросетей на 160 тысячах партий с сервера KGS и в играх против самой себя. В прошлом октябре AlphaGo уже выигрывала у сильного игрока. Это был трехкратный европейский чемпион Фань Хуэй, который проиграл искусственному интеллекту в пяти из пяти партий.
Считается, что в Европе уровень владения го ниже, чем на родине игры, в Азии. Показать явное превосходство должен матч против Ли Седоля. Профессионал уже проиграл в трёх играх из пяти. Теперь ясен и исход серии, и судьба призового миллиона долларов — он уйдёт на благотворительность и организациям по развитию го. В последних двух партиях определится глубина поражения команды людей.
Вчера, после третьего поражения человека, одной из тем пресс-конференции был вопрос, есть ли у AlphaGo слабые места. Седоль упомянул, как чувствовал, что они есть. Он извинился перед корейской нацией и сообществом игроков го за показанный результат.
Человек играл белыми, то есть у ИИ было преимущество в виде хода первым. Как и в предыдущих играх, Седоль исчерпал время раньше оппонента. То есть в какой-то момент человек был вынужден тратить всего по минуте на ход. В свою очередь система AlphaGo хорошо распоряжалась временем — это результат добавления нейросети, которая помогает управлять им.
78 ход белых оказался отличным. Возможно, Седоль действительно нащупал слабое место компьютерной системы. AlphaGo ответила слабо. Как пишет глава DeepMind Демис Хассабис, на 79 ходу система допустила ошибку, но поняла это только на 87 ходу. После этого ИИ запутался.
AlphaGo начала делать откровенно слабые и ужасные ходы. Система признаёт поражение, когда оценка шанса победы падает ниже 20 процентов. Об этом инженер Google Дэвид Сильвер напомнил во время перерыва, который взял Ли Седоль. Сильвер отказался комментировать серию невнятных ходов системы. Игра продолжилась, и Седоль всё так же был вынужден работать в условиях недостатка времени. ИИ допустил ещё один промах, а чуть позже признал поражение. Результатом противостояния на 4,5 часа и 180 ходов стала победа человека. Седоль заявил, что его никогда не поздравляли так сильно за всего лишь один выигрыш.

Игр будет проведено пять, и счёт 3-1 уже поставил точку в вопросе о победителе. Но для оценки силы системы важен общий результат матча. Последняя, пятая партия пройдёт во вторник. Как и прошлые четыре, она будет транслироваться на канале DeepMind на YouTube. Интересно, что в октябре Фань Хуэй тоже выигрывал у AlphaGo. Европейский чемпион одержал победу два раза, но в неформальных играх.
Го — древняя восточноазиатская логическая игра. Каждому из двух игроков нужно отгородить камнями своего цвета территорию как можно большего размера. Исследователей искусственного интеллекта в го привлекает сложность: позиций слишком много, чтобы перебрать их. Компьютерные системы давно подчинили себе и шашки, и шахматы. К примеру, с 2005 года лучшие из людей проигрывают лучшим из компьютерных систем по игре в шахматы. Системы компьютерного го есть, но играют они на уровне любителей. До появления AlphaGo эксперты считали, что игра го останется неприступной ещё десяток лет.

Покер – одна из самых сложных игр для искусственного интеллекта. В отличие от шахмат или шашек, это игра с неполной информацией – компьютер не может точно знать, какие карты на руках у оппонента, он может только догадываться. Кроме того, в покере часто блефуют, что сложно поддается математическому анализу. Наконец, в покер играет, как правило, несколько человек с разными стратегиями – чтобы выигрывать, надо быть успешным против каждой.
Искусственный интеллект уже год как справился с этой задачей. Впрочем, сомнений в том, что это произойдет, не было по крайней мере с 2015 года, когда AI только начал свой путь к покорению покера. Это не повод для грусти – да, покер стал «решенной» игрой, но зато, как и в шахматах, изучение компьютерных стратегий обогатит игру и, возможно, приведет к пересмотру даже тех вещей, которые считаются аксиоматическими.
Расскажем обо всем по порядку, но сначала напомним, что играть в покер с живыми людьми лучше всего в покер-руме GGпокерок. Сейчас там идет мини-WSOP – серия турниров Good Game Series Of Poker для микролимитчиков, полностью повторяющая WSOP, только с небольшими бай-инами и высокими призовыми.
Норильск, 9 мая
Норильск, 9 мая, Парад Победы и Бессмертный полк сквозь метель.
Силовые или кардио

Ответ на пост «Посла Российской Федерации в Польше облили краской»
В нападении на Посла Российской Федерации в Польше созналась украинская журналистка и активистка Ирина Земляна
«Мы пошли к послу, порвали пакеты с искусственной кровью, и эта кровь попала на посла и его помощника. Они ушли смущенные, когда мы кричали «фашисты». Мы не дали им возложить цветы», — рассказывает Ирина.
Реакция поляков в твиттере:
Немного скриншотов с гуглопереводом

Читайте также: