
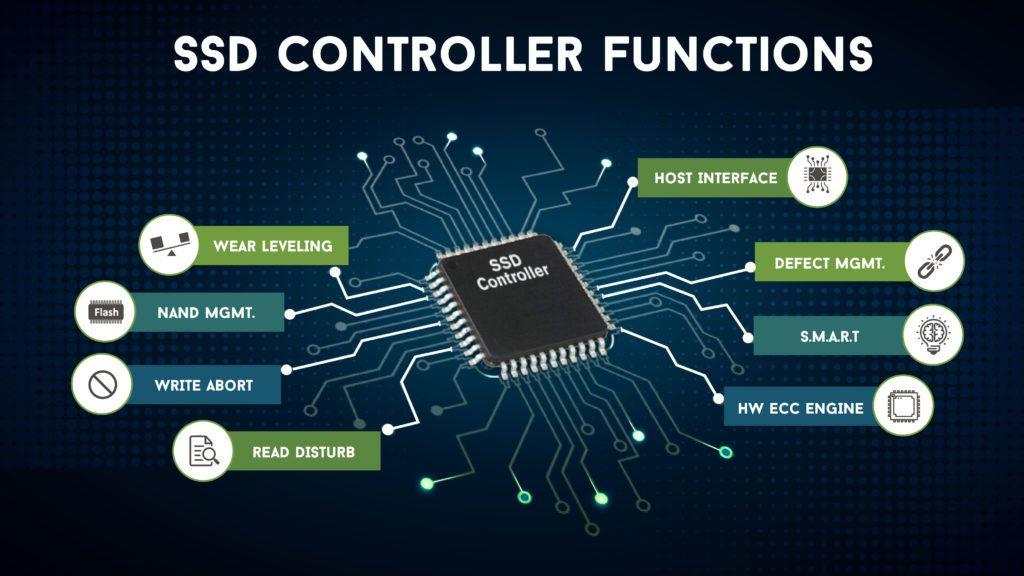
Ldpc ecc что это такое
Конечно, вы слышали (или читали) говорить о Код исправления ошибок ECC во многих аппаратных компонентах, связанных с памятью (либо Оперативная память или хранилище), хотя очень немногие понимают его важность. По этой причине в этой статье мы собираемся объяснить, как работает ECC в SSD контроллер и как благодаря этому можно увеличить продолжительность жизни и сделать большую разницу в срок службы твердотельных накопителей .
Каждому устройству, использующему флэш-память NAND, необходим код с исправлением случайных битов (известный как «мягкая» ошибка). Это потому что много электрический шум производится внутри чипа NAND, а уровни сигналов битов, проходящих через цепочку чипов NAND, очень слабые.
Один из способов, которым NAND память стали самый дешевый всего, потому что это требует, чтобы исправление ошибок было выполнено от элемента вне самого чипа NAND; В случае SSD, ECC выполняется на контроллере .
Как ECC работает на контроллере SSD
Хотя это понятие не является слишком широким, сопротивление флэш-памяти является мерой того, сколько циклов стирания / записи может выдержать блок флэш-памяти, прежде чем начнут появляться «серьезные» ошибки. Очень часто эти сбои происходят только в отдельных битах, и очень редко происходит сбой всего блока. При достаточно высоком числе стирания / записи «мягкая» частота ошибок также увеличивается из-за ряда других механизмов в самом SSD.
Давайте рассмотрим пример: допустим, что неиспользуемый чип NAND имеет достаточно «мягких» ошибок, чтобы требовать 8 бит ECC, то есть при каждом считывании страницы может быть до 8 бит, которые были случайно повреждены (обычно из-за электрических помех, которые мы говорили о). вначале). ECC, используемый в этом чипе, может исправлять 12-битные ошибки, так что ECC не может решить эту проблему мы должны найти 8 «мягких» ошибок, связанных с электрическим шумом, плюс еще 5 «мягких» из-за износа.
Теперь производители флэш-памяти гарантируют, что первый из этих 5 сбоев произойдет через некоторое время после спецификации прочности SSD. Это означает, что ни один бит не выйдет из строя из-за износа, пока не будут превышены циклы стирания / записи, указанные производителем. Теперь имейте в виду, что спецификации не достаточно точны, чтобы предсказать, когда следующий бит выйдет из строя, и на самом деле это может занять несколько тысяч циклов стирания / записи выше спецификации, чтобы это произошло; помните, что производитель гарантирует, что это не произойдет до X циклов, но не тогда, когда это произойдет после их превышения.

Это означает, что это может занять много времени, прежде чем блок становится настолько коррумпированным что его необходимо удалить из службы (а также для этого на SSD обычно есть «дополнительные» блоки для замены поврежденных), что, в свою очередь, означает, что сопротивление исправлен от ошибок блок может быть во много раз больше указанного сопротивления, в зависимости от количества избыточных ошибок, которые ECC предназначен для исправления.
Какое влияние оказывает код исправления ошибок на SSD?
Как мы объясняли ранее, флэш-память настолько дешева, потому что она не включает в себя ECC в самих чипах, но интегрирована в другое внешнее оборудование, и, как вы предположите, это имеет свою цену. Более сложный ECC требует большей вычислительной мощности на контроллере и может быть медленнее, если алгоритмы не очень современные. Кроме того, количество ошибок, которые могут быть исправлены, будет зависеть от того, насколько большой сектор памяти исправляется, поэтому контроллер SSD со сложным алгоритмом ECC, вероятно, будет использовать много ресурсов, снижение общий SSD производительность , Эти улучшения также делают контроллер дороже .

Алгоритмы ECC имеют свое собственное математическое состояние в зависимости от контроллера (другими словами, нет никакого стандарта), и даже самые базовые кодировки ECC (Рида-Соломона и LDPC) довольно сложны для понимания. Когда кто-то говорит о пределе Шеннона (максимальное количество битов, которое может быть исправлено), это величина, которую, как вы не знаете от производителя в технических характеристиках, чрезвычайно сложно вычислить.
Просто придерживайтесь этого: большее количество корректирующих битов увеличивает срок службы SSD, но также оказывает некоторое влияние на производительность или даже цену продукта, так как требует более мощный контроллер.

В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.

LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.

В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
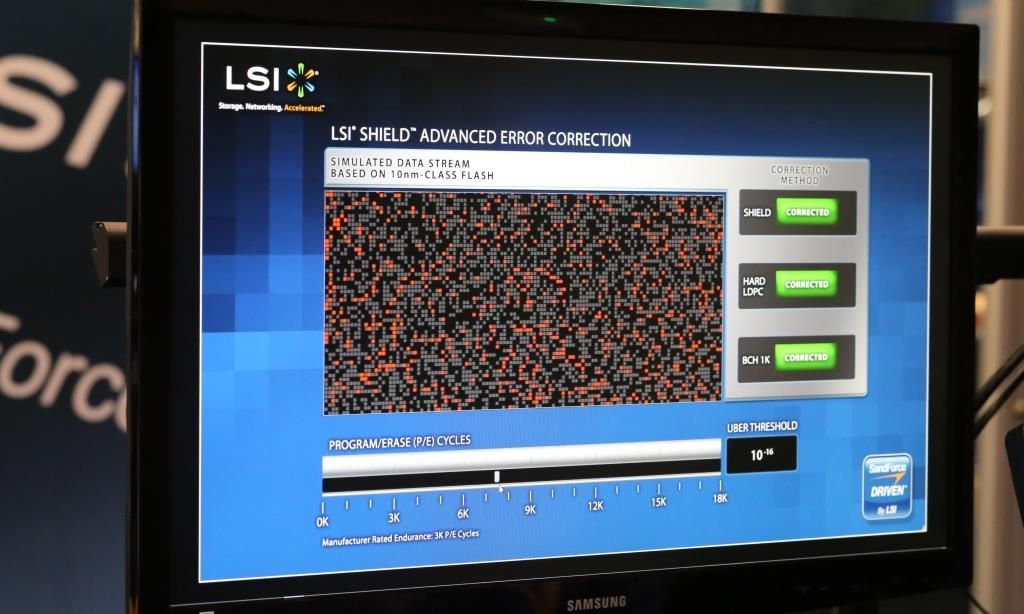
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.
В настоящее время код исправления ошибок ECC является в основном два BCH и LDPCS в SSD. Однако, поскольку SSDS становятся более высокими и выше для коррекции ошибок ECC, код исправления ошибок BCH начинает некоторую трудную силу, поэтому код исправления ошибок LDPC представляет собой тенденцию разработки и последним и самым основным кодом исправления ошибок.
Давайте посмотрим на основы Nand Flash-памяти. Вот пример MLC Nand здесь. В MLC NAND есть четыре уровня VT. Как показано ниже,

В качестве циклов P / E увеличивается, распределение напряжения VT MLC NAN стало большим, как показано ниже,

Когда цикл P / E имеет определенное значение, будет пересекаться между MLC NAND, что приведет к ошибке чтения данных. В это время необходимо задать код исправления ошибок LDPC.

LDPC, является аббревиатурой кода проверки четности с низкой плотностью, переведенным на китайский, - это «код паритета низкой плотности». В 1963 году ЛДПЦ появился в документах, опубликованных доктором R.GALLAGER. Код LDPC является редким кодом пакетов матрицы калибра. Почему это называется «редким»? Поскольку 1 чехл матрицы намного меньше 0, то преимущество состоит в том, что сложность декодирования низкая, а структура очень гибкая.
В кодировке LDPC используется контрольная матрица, называемая H матрицами, например, давайте возьмем форму H Matrix:

Чтобы понять матрицу H более интуитивным, матрица H может быть представлена диаграммой Tanner:

Левый V1 до V7 представляет собой переменный узел, а правая сторона C1 к C3 является контрольным узлом. Кабель между переменного узлом и контрольным узлом называется краем (кромки), а также представляет количество соединительных линий (ребра) на каждом узле в этой матрице H. Степень.
Кодирование LDPC разделено на регулярное кодирование и не регулярное кодирование. В регулярном кодировании число поперечного и продольного направления фиксировано. В несправедливой кодировании число поперечного и продольного направления не фиксируется. Например, обычная матрица кодирования LDPC:

В этой регулярной матрице H боковое измерение DR = 4, продольный размер DC = 3. Длина кодового слова = 20.
Матрица с помощью матричной матрицы H, называемая матрицей G, также является матрицей. Создание отличной матрицы Halibration H - это основное содержание разного основного контроллера SSD, чтобы реализовать содержание основного содержания ЛДПЦ, каждый с собственными патентами.
Во время процесса декодирования LDPC внутри SSD два аспекта содержания: жесткие декоды и мягкие декодирования. Способ декодирования LDPC состоит в том, чтобы получить кодовое слово, умноженное с помощью матрицы проверки H, если это матрица 0, то правильное кодовое слово получен. И наоборот, код не является правильным, а затем дальнейшая коррекция ошибок выполняется в соответствии с результатами множителя.

Messag Passing - это общий метод жесткого декодирования LDPC. Проверьте узел и переменные узлы передают информацию, и она итерации, пока все паритеты не равно 0, то декодирование успешно.
Итерация 1: после первой итерации передачи информации, жесткий декодированный декодированный, в это время N0, N4, N6 по-прежнему 1.



Принцип мягкого декодирования состоит в том, чтобы отрегулировать различные уровни чтения, определить, что бит составляет 1 или 0 вероятность в соответствии с результатом чтения, а затем реализовал мягкий декодирующий в соответствии с вероятностью 1 или 0, как показано ниже.

Код проверки низкой плотности (код LDPC) - это код прямого исправления ошибок. Код LDPC был впервые предложен Галлагером в его докторской диссертации в 1960-х годах, но он был ограничен техническими условиями того времени и не имел возможных алгоритмов декодирования. Люди в основном игнорировали 35 лет, в течение которых Таннер продвигал код LDPC в 1981 году и дал графическое представление кода LDPC, которое позже было названо графом Таннера. В 1993 году Берроу и др. Открыли турбо-коды. На этой основе Маккей и Нил и др. Повторно исследовали коды LDPC примерно в 1995 году и выдвинули возможные алгоритмы декодирования, тем самым еще больше открыв хорошую производительность кодов LDPC. и большое внимание. После более чем десяти лет исследований и разработок исследователи совершили прорывы во всех аспектах, а соответствующие технологии кодов LDPC стали более зрелыми, и они даже начали получать результаты для коммерческого применения, а также вошли в беспроводную связь и другие смежные области. Стандарты.
Диаграмма Таннера
Коды LDPC часто представлены графиками, а то, что представляют графики Таннера, на самом деле является проверочной матрицей кодов LDPC. Граф Таннера содержит два типа вершин: n битовых вершин кодового слова (называемые битовыми узлами), соответствующие каждому столбцу проверочной матрицы, и m вершин проверочного уравнения (называемые проверочными узлами), соответственно, и проверочная матрица, соответствующая каждой строке. Каждая строка проверочной матрицы представляет собой проверочное уравнение, а каждый столбец представляет бит кодового слова. Следовательно, если бит кодового слова включен в соответствующее проверочное уравнение, то соединение используется для соединения задействованного битового узла и проверочного узла, так что количество соединений в графе Таннера в проверочной матрице равно 1. Число из того же. На следующем рисунке изображен граф Таннера матрицы, в котором битовый узел представлен круговым узлом, контрольный узел представлен квадратным узлом, а черная линия показывает 6 циклов:
Цикл в графе Таннера состоит из группы вершин, соединенных друг с другом в графе. Цикл использует одну из групп вершин в качестве начала и конца одновременно, и проходит через каждую вершину только один раз. Длина цикла определяется как количество строк, которые он содержит, а обхват графа, который также можно назвать размером графа, определяется как наименьшая длина цикла в графе. Как показано на рисунке выше, размер фигуры, то есть обхват, равен 6, как показано черной линией.
Кодирование LDPC
- Схема прямого кодирования на основе проверочной матрицы H
Сначала выведите уравнение, закодированное непосредственно в соответствии с проверочной матрицей. Запишите контрольную матрицу размера (m, n) в следующем виде:
H = [ H 1 H 2 ] H=[H_1 \ H_2] H = [ H 1 H 2 ]
где H 1 H_1 H 1 Размер m ∗ k m*k m ∗ k , H 2 H_2 H 2 Размер m ∗ m m*m m ∗ m . Пусть вектор-строка кодового слова после кодирования будет c c c , Его длина равна n, запишите его в следующем виде
c = [ s p ] c=[s \ p] c = [ s p ]
, где s - вектор-строка информационного кода, длина - k, p - вектор контрольной строки, длина - m, согласно формуле проверки.
H ∗ c T = 0 H*c^T=0 H ∗ c T = 0
Приведенная выше формула раскрывается
[ H 1 H 2 ] [ s T p T ] = 0 [H_1 \ H_2] \begin s^T \\ p^T \\ \end=0 [ H 1 H 2 ] [ s T p T ] = 0
Раскройте матричное уравнение и учитывая, что операция выполняется в GF (2), получаем
p ∗ H 2 T = s ∗ H 1 T p*H^T_2=s*H^T_1 p ∗ H 2 T = s ∗ H 1 T
Если проверочная матрица H неособая, она имеет полный ранг, поэтому
p = s ∗ H 1 T ∗ H 2 − T p=s*H^T_1*H^_2 p = s ∗ H 1 T ∗ H 2 − T
Таким образом вычисляется контрольная цифра кодового слова. Этот метод должен быть гарантирован H 2 H_2 H 2 Это обратимо, и квазициклический код LDPC может гарантировать это условие из-за своих структурных характеристик. - Схема кодирования на основе образующей матрицы G
Пусть проверочная матрица H кода LDPC будет разделена на две части:
H = [ Q c ∗ m P c ∗ c ] H=[Q_ \ P_] H = [ Q c ∗ m P c ∗ c ]
, где размер подматрицы P равен c × c, а размер Q равен c × m. Расчет
W = ( P c ∗ c − 1 Q c ∗ m ) T W=(P^_ \ Q_)^T W = ( P c ∗ c − 1 Q c ∗ m ) T
Операция с матрицей представляет собой модульную операцию над двумя. Полученная матрица W размера m × c должна быть плотной квазикруглой структурной матрицей. Образующая матрица может быть получена из плотной матрицы квазикруглой структуры W:
G = [ I m ∗ m W ] G=[I_\ W] G = [ I m ∗ m W ]
где I I I Единичная матрица размера m × m. Видно, что образующая матрица имеет характерную квазициклическую структуру. После получения порождающей матрицы G кодовое слово X умножается на C = X * G, чтобы получить кодированное кодовое слово C. Умножение здесь должно удовлетворять правилу умножения конечного поля.
Декодирование LDPC
При описании кодов LDPC Галлагер предложил два алгоритма декодирования: алгоритмы декодирования с жестким решением и алгоритмы декодирования с мягким решением. После непрерывного развития современные алгоритмы жестких решений в значительной степени развиваются на основе алгоритма Галлагера, включая множество алгоритмов взвешенного декодирования с переворотом битов и их улучшенные формы. Твердые суждения и мягкие суждения имеют свои преимущества и недостатки и могут применяться к различным приложениям.

- Алгоритм переворота битов (BF)
Алгоритм декодирования жесткого решения изначально был дополнением к Галлагеру, когда он предложил алгоритм мягкого решения кода LDPC. Основное предположение декодирования с жестким решением состоит в том, что, когда контрольное уравнение не выполняется, это означает, что в это время должна быть ошибка в бите, и среди всех битов, которые могут иметь ошибки, бит, который не удовлетворяет Уравнение проверки имеет наибольшую вероятность ошибки. На каждой итерации бит с наибольшей вероятностью ошибки переворачивается и снова декодируется с обновленным кодовым словом. Конкретные шаги заключаются в следующем:
- Задайте начальное количество итераций k1 и его верхний предел kmax. Для полученного кодового слова y = (y1, y2 . yn) разверните двоичное жесткое решение согласно следующей формуле, чтобы получить последовательность жесткого решения Zn принятого кодового слова.
- Если k 1 = k m a x k_1=k_ k 1 = k m a x , Декодирование заканчивается. В противном случае вычислите синдром s = (s0, s1, . sm-1), где sm представляет собой значение m-го калибровочного уравнения. Если все значения синдромов равны 0, это означает, что кодовое слово правильное и декодирование выполнено успешно. В противном случае возникает битовая ошибка. Переходите к шагу 3.
- Для каждого бита подсчитайте число fn, которое не удовлетворяет контрольному уравнению (1

4. Будет самым большим f n f_n f n Соответствующий бит переворачивается, затем k = k + 1 и возвращается к шагу 2.
Теоретическое предположение алгоритма BF состоит в том, что если определенный бит не удовлетворяет максимальному количеству проверочных уравнений, то этот бит, скорее всего, ошибочен, поэтому этот бит выбирается для инверсии. Алгоритм BF отбрасывает информацию о надежности каждого бита и просто принимает жесткое решение по кодовому слову.Теория самая простая и самая легкая для реализации, но производительность также наихудшая. Когда две последовательные итерации функции переворота определяют, что один и тот же бит является наиболее подверженным ошибкам битом, алгоритм BF попадет в бесконечный цикл, что значительно снижает производительность декодирования.
Прежде чем вводить алгоритм декодирования BP, нам необходимо понять концепцию графа Таннера.
Независимая битовая последовательность длиной m, предполагающая, что вероятность того, что i-й бит равен 1, равна p i p_i p i , Тогда вероятность выпадения четного числа единиц во всей последовательности равна
)
Вероятность нечетного числа единиц равна
Эта теорема часто используется в области кодирования каналов, поэтому используйте ее напрямую.

Теорема Галлагера: для ( n , j , k ) (n, j, k) ( n , j , k ) Обычные коды LDPC, P i l P_ P i l Первый i i i В уравнениях калибровки l l l Вероятность того, что специальная школа равна 1, тогда
где:
P r ( x i = 0 ∣ < y >, S ) P_r(x_i=0|\,S) P r ( x i = 0 ∣ < y >, S ) Указывает, что группа в процессе S S S , Последовательность приема y y y Определите вероятность того, что i-й бит в переданном кадре равен 0 при условии
P r ( x i = 1 ∣ < y >, S ) P_r(x_i=1|\,S) P r ( x i = 1 ∣ < y >, S ) Указывает, что группа в процессе S S S , Последовательность приема y y y Определите вероятность того, что i-й бит в переданном кадре равен 0 при условии
p i p_i p i Указывает априорную вероятность того, что i-й бит последовательности передачи равен 1;
M ( i ) M(i) M ( i ) Представляет набор проверочных узлов, все узлы в наборе такие же, как узлы переменных i i i Соседний
N ( j ) N( j) N ( j ) Представляет набор переменных узлов, все узлы в наборе такие же, как и проверочные узлы. j j j Соседний.
Согласно принципу алгоритма BP, представленному в предыдущем разделе, и описанию в теореме Галлагера, узел переменной i i i Перейти к проверке узла j j j Информация о надежности q i j ( 1 ) q_ (1) q i j ( 1 ) Только P r ( X j = 1 ∣ < y >, S ) Pr(X_j=1|\,S) P r ( X j = 1 ∣ < y >, S ) , Так что определите
означает узел переменной i i i Перейти к проверке узла j j j Информация о внешней вероятности, то есть после получения контрольного узла j j j После всех остальных контрольных битов и внешней информации канала оценивается переменный узел. c i = 1 c_i=1 c i = 1 Вероятность.
Переопределить
означает узел переменной i i i Перейти к проверке узла j j j Информация о внешней вероятности j j j После всех остальных контрольных битов и внешней информации канала оценивается переменный узел. c i = 0 c_i=0 c i = 0 Вероятность.
С другой стороны, контрольный узел j j j Перейти к узлу переменной i i i Информация о надежности должна быть уравнением проверки при условии, что заданные информационные биты и другие информационные биты имеют независимые распределения вероятностей. j j j Вероятность удовлетворения. Запишите эту информацию о надежности как r j i r_ r j i ,тогда
Замените приведенную выше формулу
Согласно приведенному выше описанию и определению символа, процесс вероятностного алгоритма декодирования BP можно свести к следующим этапам:
(1) Инициализация
Вычислить начальную вероятность каждого узла переменной после передачи по каналу. p i ( 1 ) p_i(1) p i ( 1 ) с p i ( 0 ) p_i(0) p i ( 0 ) . Затем для каждого узла переменной найдите информацию о надежности, передаваемую соседнему контрольному узлу.
, где верхний индекс (0) указывает количество итераций.
2) Проверьте процесс обработки узла. ( r i j (r_ ( r i j Расчет)
Найдите l l l Во время второй итерации проверочный узел i передается соседнему узлу переменной j j j Информация о надежности
, где верхний индекс ( l ) (l) ( l ) с ( l − 1 ) (l −1) ( l − 1 ) Оба представляют количество итераций.
(3) Процесс обработки узла переменной ( q i j q_ q i j Расчет)
Найдите l l l Узел переменной во второй итерации j j j Передано соседнему контрольному узлу i i i Информация о надежности
где K i j K_ K i j Это поправочный коэффициент, чтобы каждый рассчитал q i j ( l ) ( 1 ) + q i j ( l ) ( 0 ) = 1 q^_(1)+q^_(0)=1 q i j ( l ) ( 1 ) + q i j ( l ) ( 0 ) = 1
(4) Оценка декодирования
В конце этого итерационного процесса пересчитайте информацию о надежности каждого узла переменной.
где K j K_j K j Это также поправочный коэффициент, цель которого - сделать q j ( l ) ( 1 ) + q j ( l ) ( 0 ) = 1 q^_(1)+q^_(0)=1 q j ( l ) ( 1 ) + q j ( l ) ( 0 ) = 1
если q j ( l ) ( 1 ) > q j ( l ) ) ( 0 ) q^_j (1)>q^_j)(0) q j ( l ) ( 1 ) > q j ( l ) ) ( 0 ) , Тогда оценочная стоимость этой точки равна c i = 1 c_i=1 c i = 1 , В противном случае оценочное значение c i = 0 c_i=0 c i = 0 . Если оценочное значение удовлетворяет уравнению проверки четности, алгоритм завершается, в противном случае алгоритм продолжает работать до тех пор, пока не будет достигнуто заданное максимальное количество итераций.

Описание моделирования выглядит следующим образом:
На рисунке ниже представлено сравнение результатов декодирования кодовых слов LDPC и некодированных кодовых слов в гауссовском канале. Чтобы гарантировать эффективность сравнения, код LDPC и некодированные кодовые слова при моделировании Такой же длины, как 1440, код LDPC декодируется алгоритмом декодирования BP, а некодированное кодовое слово декодируется жестким решением демодуляции.
Анализ результатов моделирования: из рисунка видно, что способность кодового слова противостоять шуму значительно улучшается после кодирования и декодирования LDPC. По сравнению с некодированным кодовым словом, частота ошибок по битам составляет всего At 1e-4, его производительность улучшена примерно на 9,5 дБ, таким образом подтверждая, что код LDPC является кодом исправления ошибок канала с отличной производительностью.
В настоящее время основная работа в области исследования кода LDPC сосредоточена на анализе производительности алгоритмов декодирования, методов кодирования, алгоритмов оптимизации кода и т. Д. Благодаря усилиям исследователей исследования кодов LDPC достигли большого прогресса, но все еще есть много вопросов, требующих дальнейшего изучения:
(1) Построение матрицы проверки кода LDPC. Хотя в построении оптимального кода LDPC был достигнут некоторый прогресс, до сих пор не существует систематического метода построения необходимого хорошего кода, особенно когда длина кода ограничена. определенной скорости кода, очень сложно создать хороший код с отличной производительностью.
(2) Совместная оптимизация системы кодирования LDPC, сочетающая технологию кодирования с технологией модуляции, технологию выравнивания, технологию пространственно-временного кодирования и технологию OFDM для оптимизации производительности, является одним из текущих и будущих направлений развития.
(3) Методы анализа характеристик и критерии оптимизации кодов LDPC в беспроводном канале с замираниями и технологии MIMO. В настоящее время оптимальная конструкция кодовых слов LDPC в основном достигается при использовании каналов аддитивного белого гауссовского шума, а также при беспроводных каналах с замираниями, особенно в нелинейной среде изменяющихся во времени каналов, также используются метод анализа производительности кодового слова, критерии проектирования оптимизации и оценка канала. затронуты. Очень важный вопрос, требующий дальнейшего исследования и изучения.
Кроме того, на основе технологии адаптации канала LDPC-кода, применения LDPC-кода на физическом уровне интегрированной сети связи и системы совместной оптимизации прикладного уровня, применения LDPC-кода в беспроводной локальной сети и космической авиации дальнего космоса, передача изображения на основе кода LDPC, применение в системе цифровых водяных знаков изображений и поиск методов кодирования и декодирования кода LDPC, более подходящих для аппаратной реализации, - все это темы, заслуживающие изучения.

где RP0 ~ RP15 - шестнадцать битов, что означает четность строк,
RP0 - это полярность 0-го, 2, 4, 6,…, 252, 254 байтов
RP1-----1、3、5、7……253、255
RP2 ---- 0, 1, 4, 5, 8, 9 . 252, 253 (обработка 2 байтов, пропуск 2 байтов)
RP3 ---- 2, 3, 6, 7, 10, 11 . 254, 255 (пропустить 2 байта, обработать 2 байта)
RP4 ---- обработка 4 байта, пропуск 4 байта;
RP5 ---- пропустить 4 байта и обработать 4 байта;
RP6 ---- Обработка 8 байтов, пропуск 8 байтов
RP7 ---- пропустить 8 байтов и обработать 8 байтов;
RP8 ---- обработка 16 байтов, пропуск 16 байтов
RP9 ---- пропустить 16 байтов и обработать 16 байтов;
RP10 ---- обработать 32 байта, пропустить 32 байта
RP11 ---- пропустить 32 байта и обработать 32 байта;
RP12 ---- обработать 64 байта, пропустить 64 байта
RP13 ---- пропустить 64 байта и обработать 64 байта;
RP14 ---- обработать 128 байтов, пропустить 128 байтов
RP15 ---- пропустить 128 байтов и обработать 128 байтов;
Можно видеть, что каждый бит RP0 ~ RP15 составляет 128 байтов (то есть 128 строк), то есть результат XOR 128 * 8 = 1024 бит.
В итоге, результаты проверки 6-битного столбца и 16-битные результаты проверки строки генерируются в общей сложности для 22 битов для 256 байтов данных. В Nand для хранения результата проверки используются 3 байта, а для двух дополнительных битов установлено значение 1. Порядок хранения показан в следующей таблице:

Взяв K9F1208 в качестве примера, каждая страница страницы содержит 512-байтовую область данных и 16-байтовую область OOB. Первые 256 байтов данных генерируют 3-байтовый контрольный код ECC, а последние 256 байтов данных генерируют 3-байтовый контрольный код ECC. Всего в области OOB хранится 6 байтов контрольных кодов ECC, и позиция хранения является 0, 1, 2 и 3, 6, 7 байтов.
Реализация алгоритма генерации чекового языка на языке Си
В ядре Linux файл, в котором находится алгоритм проверки ECC, называется drivers / mtd / nand / nand_ecc.c. На самом деле существует два вида новых и старых.Программа, используемая в 2.6.27 и более ранних ядрах, начинается с 2.6.28. Он больше не используется и заменен более эффективной программой. Подробное введение в новую программу можно найти в файле Documentation / mtd / nand_ecc.txt.
0x00, 0x55, 0x56, 0x03, 0x59, 0x0c, 0x0f, 0x5a, 0x5a, 0x0f, 0x0c, 0x59, 0x03, 0x56, 0x55, 0x00
63>;

Значение этой таблицы: для 256 чисел от 0 до 255 вычислите и сохраните значение проверки столбца и значение проверки строки каждого числа и используйте число в качестве индекса массива. Например, nand_ecc_precalc_table [13] хранит значение проверки столбца и значение проверки строки 13, двоичное представление 13 равно 00001101, а его CP0 = Bit0 ^ Bit2 ^ Bit4 ^ Bit6 = 0;
CP1 = Bit1^Bit3^Bit5^Bit7 = 1;
CP2 = Bit0^Bit1^Bit4^Bit5 = 1;
CP3 = Bit2^Bit3^Bit6^Bit7 = 0;
CP4 = Bit0^Bit1^Bit2^Bit3 = 1;
CP5 = Bit4^Bit5^Bit6^Bit7 = 0;
Полярность линии RP = бит0 ^ бит1 ^ бит2 ^ бит3 ^ бит4 ^ бит5 ^ бит6 ^ бит7 = 1;
Тогда значение, хранящееся в nand_ecc_precalc_table [13], должно быть 0101 0110, что составляет 0x56.
Обратите внимание, что индекс массива nand_ecc_precalc_table на самом деле является байтом данных, которые мы хотим проверить.
Понимая значение этой таблицы, легко написать программу для генерации этой таблицы. Описание процедуры см. В файле MakeEccTable.c во вложении.
С помощью этой таблицы для однобайтовых данных вы можете напрямую проверить таблицу nand_ecc_precalc_table [dat], чтобы получить значение проверки строки и значение проверки столбца dat. Но фактическим ECC является проверка 256 байтов данных, необходимо выполнить 256 операций поиска в таблице, поразрядно XOR полученных 256 результатов поиска в таблице, окончательный результат Bit0 ~ Bit5 - это данные CP0 ~ 256 байтов. CP5.
/* Build up column parity */
81 for(i = 0; i < 256; i++) 82
/* Get CP0 - CP5 from table */
83
idx = nand_ecc_precalc_table[*dat++];
84
reg1 ^= (idx & 0x3f);
85
86/// Некоторые здесь опущены и будут представлены позже
91 >

Reg1
Здесь процесс вычисления полярности столбца состоит в том, чтобы фактически вычислить CP0 ~ CP5 в байте данных, после вычисления каждого байта, а затем вычислить результат с другими байтами. Ищу XOR. В Таблице 1 сначала выполняется XOR для столбца Бита 0, а затем для столбца Бита 2 выполняется XOR. Два отличаются в порядке расчета, и результаты являются согласованными. Потому что порядок операций XOR коммутативный.
Расчет полярности линии более сложен.
Бит6 в таблице nand_ecc_precalc_table [] сохранил значение полярности строки каждого однобайтового числа. Чтобы проверить 256 байтов данных, посмотрите таблицу отдельно. Если полярность строки равна 1, запишите индекс строки, в которой расположены данные (то есть значение i цикла for). Индекс строки здесь очень важен, потому что Вычисление RP0 ~ RP15 тесно связано с индексом строки, например, RP0 рассчитывает только четные строки, RP1 рассчитывает только нечетные строки и т. Д.
Здесь ключ к пониманию строк 88 и 89. Reg3 и reg2 являются переменными типа unsigned char и инициализируются нулем.
Индекс строки (то есть i в цикле for) имеет диапазон значений от 0 до 255. В соответствии с таблицей 2 можно нарисовать следующие правила:
RP0 рассчитывает только строки с индексом строки Бит0, равным 0, RP1 рассчитывает только строки с индексом строки Бит0, равным 1;
RP2 рассчитывает только те строки, у которых индекс строки Бит1 равен 0, RP3 рассчитывает только те строки, у которых индекс строки Бит1 равен 1;
RP4 рассчитывает только строки с индексом строки Бит2, равным 0, RP5 рассчитывает только строки с индексом строки Бит2, равным 1;
RP6 рассчитывает только строки с индексом строки Бит3, равным 0, RP7 рассчитывает только строки с индексом строки Бит3, равным 1;
RP8 рассчитывает только строки с индексом строки Бит4, равным 0, RP9 рассчитывает только строки с индексом строки Бит4, равным 1;
RP10 рассчитывает только строки с индексом строки Бит 5, равным 0, RP11 рассчитывает только строки с индексом строки Бит5, равным 1;
RP12 только вычисляет строку, индекс строки которой Бит 6 равен 0, RP13 только вычисляет индекс строки Бит 6 равен 1 строке;
RP14 вычисляет только строку, индекс строки которой Бит7 равен 0, RP15 рассчитывает только индекс строки Бит7 равен 1 строке;
Считается, что все строки, чья контрольная сумма строки равна 1,
Сколько строк принадлежит диапазону вычисления RP1 -------- Обозначается битом 0 в reg3, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP3 -------- Обозначается битом 1 в reg3, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP5 -------- Обозначается битом 2 в reg3, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP7 ------, указанному битом 3 в reg3, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP9 -------- Обозначается битом 4 в reg3, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP11 -------- Обозначается битом 5 из reg3, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP13 -------- Обозначается битом 6 регистра 3, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP15 -------- Обозначается битом 7 в reg3, 0 означает четное число, 1 означает нечетное число;

Следовательно, роль каждого бита reg3 показана в следующей таблице:
Reg3
Строка 89, после побитового инвертирования индекса строки всех строк с контрольной суммой 1, а затем побитовой XOR, функция должна определить количество битов 0 Например, если бит 0 для reg2 равен 0, это означает, что среди всех строк, чья контрольная сумма строк равна 1, имеется четное количество строк, чей индекс строки Бит 0 равен 0, то есть есть четное количество строк, попадающих в диапазон вычисления RP0. Итак, можно сделать вывод:
Среди всех строк, чья контрольная сумма равна 1,
Сколько строк принадлежит диапазону вычисления RP0 -------- Обозначается битом 0 в reg2, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP2 -------- Обозначается битом 1 в reg2, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP4 ------, указанному битом 2 в reg2, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP6 -------- Обозначается битом 3 в reg2, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP8 -------- Обозначается битом 4 в reg2, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP10 -------- Обозначается битом 5 в reg2, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP12 -------- Обозначается битом 6 в reg2, 0 означает четное число, 1 означает нечетное число;
Сколько строк принадлежит диапазону вычисления RP14 ------, указанному битом 7 в reg2, 0 означает четное число, 1 означает нечетное число;

Следовательно, роль каждого бита reg2 показана в следующей таблице:
Reg2
Пока что для расчета всех контрольных цифр CP0 ~ CP5 и RP0 ~ RP15 используется только одна справочная таблица и одна для цикла. Следующая задача просто переставляет эти биты в порядке, указанном в таблице 3.
Извлеките RP8 ~ RP15 из reg2 и reg3 и поместите их в tmp1, извлеките RP0 ~ RP7 и поместите их в tmp2,
Reg1 перемещается на два места влево, а два нижних на 1,
Затем поместите tmp2, tmp1, reg1 в три байта кода ECC.
Также есть в программеCONFIG_MTD_NAND_ECC_SMCИ провел еще одну операцию отрицания, пока не знаю почему.
Алгоритм исправления ошибок ECC
При записи данных на страницу NAND Flash мы генерируем контрольную сумму ECC каждые 256 байтов, называемую исходной контрольной суммой ECC, и сохраняем ее в OOB (PAGE внеполосный) в области данных. При чтении данных из NAND Flash мы генерируем контрольную сумму ECC каждые 256 байтов, называемую новой контрольной суммой ECC.
Предположим, что ecc_code_raw [3] сохраняет исходный контрольный код ECC, ecc_code_new [3] сохраняет вновь рассчитанный контрольный код ECC, формат которого показан в следующей таблице:

Способ определения адреса строки состоит в том, чтобы установить для адреса строки значения беззнаковых байтов, извлечь бит 7, бит 5, бит 3, бит 1 в s1, в качестве старших четырех бит байтов, извлечь бит 7 в s 0, Бит5, Бит3, Бит1 - это младшие четыре бита байтовых импульсов, тогда значение байтовых байтов указывает адрес строки байта ошибки (диапазон 0 ~ 255).
Метод определения адреса столбца: извлечь бит 7, бит 5, бит 3 в s2 в качестве младших трех битов битовой цифры, а оставшуюся часть битовой цифры 0, затем битная цифра указывает адрес столбца ошибочного битового бита (диапазон 0 ~ 7).
Давайте рассмотрим тайну этого на простом примере.
Если предположить, что данные для проверки составляют два байта, 0x45 (двоичный код 0100 0101) и 0x38 (двоичный код 0011 1000), коды проверки строки и столбца показаны в следующей таблице:

Значения CP5 ~ CP0 могут быть рассчитаны из таблицы и перечислены в первой строке таблицы ниже (исходные данные). Предположим теперь, что бит данных изменился, 0x38 становится 0x3A, что является байтом
Бит 1 из 1 изменился с 0 на 1, и новые значения CP5 ~ CP0 были вычислены и помещены во второй ряд таблицы ниже (измененные данные). Результат XORing старого и нового контрольных кодов помещается в третью строку таблицы ниже.
Видимо, когда бит
Когда изменяется 1, изменились только CP1, CP2 и CP4 в контрольном значении столбца, в то время как CP0, CP3 и CP5 не изменились, что означает половину 6-битных контрольных кодов Если есть изменение, половина результатов XOR равна 1. Таким же образом, половина результатов XOR для проверки строки также равна 1. Вот почему, когда один битовый бит в 256-байтовых данных изменяется, результат исключающего ИЛИ старых и новых 22-битных проверочных кодов будет иметь 11 битовых битов, равных 1.


Давайте посмотрим, как найти неправильный бит. Принимая адрес столбца в качестве примера, если CP5 изменяется (CP5 после XOR = 1), ошибка должна быть в Бите 4 ~ Бит 7, если CP5 не изменяется (CP5 после XOR = 0), ошибка В Бите 0 ~ Бит 3 половина битов отфильтровывается. Среди оставшихся 4 битов посмотрите, изменился ли CP3, и выберите 2 бита. В оставшихся 2-битных битах, если есть изменение в CP1, вы, наконец, можете найти бит ошибки. Следующая древовидная структура более четко демонстрирует этот процесс принятия решений:
Диаграмма 1 Дерево решений для определения местоположения битового адреса
Примечание. CP на рисунке относится к CP в результате поиска разницы или после
Зачем использовать только CP4, CP2, CP0? Фактически, это содержит избыточную информацию, потому что CP5 = 1 должен иметь CP4 = 0, CP5 = 0 должен иметь CP4 = 1, то есть CP5 должен быть противоположен CP4 по той же причине, CP3 должен быть противоположен CP2, CP1 должен быть противоположен CP0 по сравнению. Так что нужно использовать только половину.
Таким образом, мы извлекаем биты CP5, CP3 и CP1 из результата XOR для определения адреса столбца ошибочного бита. Например, в приведенном выше примере CP5 / CP3 / CP1 = 001, что означает, что бит 1 имеет ошибку.
Аналогично, проверка строки RP1 изменяется, извлекаем RP1, мы видим, что байт 1 изменился. Это находит ошибку Байт 1 Бит 0.
Когда бит данных равен 256 байтам, при проверке строки используются RP0 ~ RP15 и могут быть найдены биты RP15, RP13, RP11, RP9, RP7, RP5, RP3 и RP1 результата XOR. Узнайте, какой байт неверен, а затем используйте CP5, CP3, CP1, чтобы определить, какой бит неправильный.
Читайте также: