
Kvm vepa что это
Я перевожу виртуальную машину kvm со старого хоста (как аппаратного, так и операционного) на новый.
Для работы в сети virt-manager предложил мне новую опцию: macvtap . Это выглядело хорошей альтернативой настройке моста на eth0.
Так что теперь гость загружается просто отлично, получает IP-адрес от моего локального сетевого DHCP-сервера, может выйти в Интернет. Гость также видит другие машины в локальной сети, я могу ssh их и т. Д.
Вот route -n команда с хоста:
(тот же вывод от гостя).
Я мог бы, вероятно, настроить новый интерфейс tun / tap, предназначенный для связи между хостом и гостем, но это выглядит немного излишним. Есть ли способ заставить хозяина и гостя общаться?
Macvtap не является допустимой заменой мостов. Если вы хотите переключение, а не мостовое соединение, посмотрите на openvswitch.
Я задал этот вопрос на IRC, и кажется, что Macvtap
вводит гостевой трафик в сетевой стек, слишком низкий для этого
Решение состоит в том, чтобы добавить сетевой интерфейс для связи между гостем и хостом или остаться со старым мостовым решением .
virt-manager прямо говорит, что при настройке macvtap не работает связь между хостом и гостевой сетью. Я просто добавил второй интерфейс на основе nat, настроил его в гостевой системе и использовал его для связи с моим хостом.
Решение состоит в том, чтобы настроить интерфейс macvlan на гипервизоре с тем же IP-адресом, что и реальный аппаратный интерфейс (очень важно), и настроить маршрутизацию на хосте для его использования. В Qemu / KVM используйте интерфейс macvtap на аппаратном интерфейсе как обычно.
Для моей конфигурации (сеть 192.168.1.0/24, аппаратный интерфейс p10p1 и шлюз 192.168.1.1) это дает (на гипервизоре):
Как уже упоминалось в предыдущих ответах, решение этой проблемы заключается в добавлении сетевого адаптера macvlan на хост. Тем не менее, я чувствовал, что ручная переподключение маршрутов к адаптеру macvlan было довольно хакерским, тем более что я хотел, чтобы поддержка IPv6 и ручная настройка маршрутов могли стать проблемой при изменении префикса. Итак, вот моя конфигурация, которая оставляет ядро под контролем таблицы маршрутизации:
(Конкретная конфигурация здесь специфична для Debian и Upstart, но основные шаги должны работать на любом GNU / Linux.)
9. Настройка сети (MACvTAP-bridge to LAN)
После request system power-off (машина VRR20 выключается) появляется файл vrr20.xml, в котором мы будем редактировать настройку сети – сделаем bridge в LAN с помощью MACVTAP.
Выясняем имя сетевой карты Centos/Ubuntu, смотрящей в LAN:

Выяснив, что (в данном примере) имя нашей сетевой карты, смотрящей в LAN = “eno16777736”, идём в следующий пункт.
Создание адаптера macvlan при загрузке
Сначала вам нужно выбрать MAC-адрес для вашего адаптера. Вы можете использовать случайный, но я предлагаю вам вручную создать адаптер macvlan и использовать его MAC. Таким образом, MAC обязуется любые соглашения, которые могут быть там.
Рекомендуется установить фиксированный MAC-адрес, поскольку в противном случае, например, DHCP-сервер не сможет распознать ваш компьютер после перезагрузки и назначить ему тот же IP-адрес, что и раньше.
Итак, создайте адаптер и найдите MAC:
Выделенное шестнадцатеричное число - ваш MAC-адрес.
Теперь вы создаете сценарий инициализации - который должен быть запущен до инициализации сети - для создания адаптера macvlan при каждом запуске. Команда для этого:
Пример сценария инициализации Upstart для этой цели:
Просто вставьте это, например /etc/init/macvlan.conf .
Отключение IPv6 для физического адаптера
Наконец, вы не хотите, чтобы физический адаптер получал IP-адрес. Для IPv4 установка адаптера на ручной режим не позволяет ему получить адрес. Однако я не нашел конфигурацию, которая мешает ядру получить / назначить IPv6-адрес для / адаптеру. Когда это происходит, он также добавляет маршруты для них, что может вызвать проблемы. Таким образом, лучший способ - отключить IPv6 для физического адаптера. Вы можете сделать это, добавив строку
чтобы /etc/sysctl.conf , создав файл /etc/sysctl.d/ с этой строкой, или добавив
на ваш сценарий инициализации.
Когда вы сейчас перезагружаете свою машину, связь между хостом и гостем должна работать как с IPv4, так и с IPv6.
Имейте в виду, что если вы допустите ошибку при настройке, ваш хост может стать недоступным через сеть даже после перезагрузки. Делайте это только в том случае, если у вас есть физический доступ к машине или другие меры безопасности, чтобы вы могли устранить потенциальные проблемы.
Проанализировав в двух предыдущих номерах «Журнала сетевых решений/LAN» концепции централизованно программируемых сетей SDN и коммутирующих «фабрик», переходим к третьей составляющей «революции» в области сетевых инфраструктур, источником которой стала потребность в поддержке виртуализации ИТ-ресурсов. В этом номере мы поговорим о различных способах коммутации трафика виртуальных машин, а в следующем — об организации наложенных виртуальных сетей.
Проанализировав в двух предыдущих номерах «Журнала сетевых решений/LAN» концепции централизованно программируемых сетей SDN и коммутирующих «фабрик», переходим к третьей составляющей «революции» в области сетевых инфраструктур, источником которой стала потребность в поддержке виртуализации ИТ-ресурсов. В этом номере мы поговорим о различных способах коммутации трафика виртуальных машин, а в следующем — об организации наложенных виртуальных сетей. Помимо рассмотрения соответствующих технологий, обсудим их связь с SDN и «фабриками».
С внедрением технологий виртуализации и появлением виртуальных машин возникла очевидная потребность в коммутации трафика между ними. С этой целью были разработаны виртуальные коммутаторы, такие как VMware vSwitch или Cisco Nexus 1000V — в англоязычной литературе их обычно называют Virtual Embedded (или Ethernet) Bridge (VEB). По своему функционалу они соответствуют обычным коммутаторам Ethernet, только выполнены программно на уровне гипервизора. Трафик между виртуальными машинами в рамках «своего» сервера коммутируется локально, не выходя за его пределы (см. Рисунок 1). А прочий трафик (с внешними МАС-адресами) — направляется во внешнюю сеть.
_500.jpg) |
| Рисунок 1. Коммутация трафика виртуальных машин внутри сервера (VEB) и вынос этого процесса во внешний коммутатор (VEPA). |
Виртуальные коммутаторы могут быть модульными, как, например, уже упомянутый Cisco Nexus 1000V. Он состоит из двух основных компонент: модуль Virtual Ethernet Module (VEM) функционирует на базе гипервизора и отвечает за коммутацию трафика виртуальных машин, а модуль управления Virtual Supervisor Module (VSM) может быть установлен на внешнем сервере. Один коммутатор Nexus 1000V способен поддерживать множество модулей VEM на физических серверах. А для управления всем этим хозяйством (решения задач конфигурирования, мониторинга, диагностики и пр.) достаточно одного модуля VSM. По сути, все как в обычном модульном устройстве: VEM — это аналог линейной карты, а VSM — платы управления.
У виртуальных коммутаторов VEB есть свои преимущества: локальная коммутация трафика внутри сервера не приводит к какой-либо дополнительной нагрузке на сеть, к тому же для реализации такой коммутации не требуется внешнее оборудование. Данное решение отличается невысокой стоимостью и обеспечивает малое значение задержки. Но у него есть и серьезные минусы: к виртуальным коммутаторам далеко не всегда применимы традиционные приемы конфигурирования и управления, а курсирующий через них трафик невозможно отследить обычными средствами мониторинга. Такие коммутаторы часто находятся в ведении специалистов, отвечающих за серверы, тогда как за все остальные (аппаратные) коммутаторы отвечают сетевые администраторы, что создает проблемы для целостного управления всей сетью. Кроме того, поддержка работы виртуальных коммутаторов означает дополнительную загрузку процессоров сервера.
Другой подход к коммутации трафика виртуальных машин состоит в выносе этого процесса во внешние коммутаторы. Для его реализации были разработаны несколько технологий, две основные описаны в документах IEEE 802.1Qbg (Edge Virtual Bridging) и 802.1BR (Bridge Port Extension), которые на данный момент находятся в финальной стадии утверждения. Разработка первой из указанных технологий, в основу которой положен механизм Virtual Ethernet Port Aggregator (VEPA), была инициирована компанией HP. Технология 802.1BR родилась в Cisco Systems. Изначально ее стандартизацией занималась группа 802.1Qbh, но потом было решено выделить эту технологию в отдельный стандарт 802.1BR, дабы дистанцировать ее от стандартов серии 802.1Q, «отвечающих» за тегирование трафика Ethernet.
Настройка конфигурации сети
В /etc/network/interfaces настройте физический сетевой адаптер на ручной (но оставьте его автоматическим) и перенесите его предыдущую конфигурацию (обычно DHCP или статический IP-адрес) на ваш адаптер macvlan. Например:
5. На всякий случай (этого (почти) не может быть, но на всякий и чтобы знать как оно устроено) проверяем, - есть ли default network - она должна быть ("таков путь" ):

Default-network - есть
Если, вдруг, её нет - создаем default network в режиме NAT:
Копипастим туда вот это:
Теперь используем наш default.xml для создания default-network:
virsh net-define /tmp/default.xml
virsh net-start default
virsh net-autostart default
6. Создаём STORAGE POOL с именем “images”:
Теперь KVM настроен, можно начинать установку Juniper VRR, например вот этого:
vrr-bundle-kvm-20.4R1-S1.2.tgz
В распакованном виде, Juniper VRR версии 20 состоит из двух файлов:
ТЕХНОЛОГИЯ VEPA: ВОЗМОЖНЫ ВАРИАНТЫ
Базовый вариант технологии VEPA (Standard Mode) прост в реализации. При небольшой модернизации гипервизора весь трафик будет направляться наружу вне зависимости от MAC-адреса назначения. А от внешнего коммутатора требуется направлять обратно (немыслимая операция для традиционного моста/коммутатора Ethernet!) кадры с МАС-адресом назначения, принадлежащим виртуальной машине, которая находится на том же физическом сервере, что и отправитель. Реализация этой функции обеспечивается простым обновлением микропрограммного кода коммутатора. При этом весь трафик — даже если его отправитель и получатель находятся на одном сервере — будет проходить через внешний коммутатор (см. Рисунок 1).
Этот вариант позволяет использовать отработанные годами методики и инструменты для мониторинга трафика и управления им. Он также дает возможность задействовать весь развитый функционал современных коммутаторов для обработки трафика — например, применять к нему заданные политики обеспечения безопасности, правила гарантированного качества обслуживания (QoS) и пр. Но трафик приходится «гонять порожняком» через сеть, даже если исходная и конечная точки его маршрута находятся на одном сервере. Это повышает временную задержку и увеличивает требования к пропускной способности каналов связи. С одной стороны, вычислительные ресурсы сервера освобождаются от задач по мониторингу трафика и его обработке, но с другой — серверу приходится дважды пропускать трафик через гипервизор.
Наряду с базовым вариантом в документах IEEE 802.1Qbg описан и другой вариант — многоканальный (Multichannel VEPA), который предоставляет ряд дополнительных возможностей. В этом случае один физический канал Ethernet делится на несколько виртуальных каналов, или туннелей. Они обеспечивают независимое подключение к сети различных объектов внутри сервера: это может быть виртуальный коммутатор VEB, VEPA или непосредственно виртуальная машина. Для формирования туннелей используется хорошо известный механизм Q-in-Q (стандарт IEEE 802.1ad), который предусматривает добавление к кадру сервисного тега (S-Tag). При этом сохраняется тег, определяющий принадлежность кадра к той или иной сети VLAN (802.1q). Для реализации многоканального режима VEPA, очевидно, необходимо, чтобы внешний коммутатор поддерживал механизм Q-in-Q.
Благодаря многоканальному режиму, архитекторы сетей получают большую гибкость для выбора оптимального механизма. Скажем, для снижения задержки при взаимодействии между виртуальными машинами, находящимися на одном сервере, можно использовать виртуальный коммутатор VEB, а для повышения уровня управляемости — режим VEPA. И все в рамках одного физического соединения (см. Рисунок 2).
_500.jpg) |
| Рисунок 2. Многоканальный режим работы VEPA. |
Ставим CentOS-7-x86_64-Minimal-1511.iso - например, в VMWARE.
После установки в Centos необходимо сначала сделать DISABLE SELINUX:
Проверяем, должно ответить, что SELinux status: disabled:

SELinux status: disabled:
Удаляем NetworkManager:
yum remove NetworkManager
В случае лабы можно сделать:
*Либо не выключаем, но тогда разрешаем всё, что нужно.
Cтавим KVM + необходимое остальное:
В ДЕЛО ВСТУПАЮТ АДАПТЕРЫ
В качестве примера реализации технологии VN-Tag рассмотрим так называемые виртуальные интерфейсные карты (Virtual Interface Card, VIC) компании Cisco.
_500.jpg) |
| Рисунок 3. Пример реализации технологии VN-Tag с использованием виртуальных интерфейсных карт (Virtual Interface Card, VIC) компании Cisco. |
_300.jpg) |
| Рисунок 4. Различные режимы взаимодействия между виртуальными интерфейсами vNIC и виртуальными машинами при использовании виртуальных интерфейсных карт (Virtual Interface Card, VIC) компании Cisco. |
Пусть вас не смущает название: на самом деле это вполне реальный сетевой адаптер с портами 10 GbE и поддержкой технологии FCoE, но специально подготовленный к работе в виртуализированных средах. На его базе могут быть сформированы до 256 виртуальных интерфейсов vNIC, которые, согласно концепции выносов, становятся логическим продолжением внешнего коммутатора Ethernet. В результате каждой виртуальной машине выделяется виртуальный порт на физическом коммутаторе (см. Рисунок 3), который берет на себя заботу не только о коммутации трафика, но и о соблюдении установленных правил безопасности, качества обслуживания и пр.
Поддержка продуктами VIC технологии VMware VMDirectPath позволяет существенно повысить производительность и снизить задержку сетевого взаимодействия виртуальных машин. Она делает возможным прямое взаимодействие между виртуальными интерфейсами vNIC и виртуальными машинами в обход гипервизора (см. Рисунок 4). При необходимости можно использовать механизм VMware VMotion, например, для динамического распределения нагрузки.
_300.jpg) |
| Рисунок 5. Различные варианты коммутации трафика виртуальных машин при использовании адаптера Brocade Fabric Adapter (FA) 1860. |
Сетевые адаптеры нового поколения, оптимизированные для работы в виртуализированных средах, могут не только направлять трафик виртуальных машин во внешнюю сеть, но и самостоятельно его коммутировать. Примером такого продукта служит адаптер Brocade Fabric Adapter (FA) 1860, который содержит один или два физических порта: 10 Гбит/с (Ethernet, FCoE) или 16 Гбит/с (Fibre Channel). При использовании этого адаптера возможны три варианта коммутации трафика виртуальных машин (см. Рисунок 5). Первые два — это уже рассмотренные нами локальная коммутация силами виртуального коммутатора (адаптер FA 1860 в данном случае вообще не задействуется) и вынос коммутации во внешнюю сеть с применением технологии VEPA. Третий вариант в Brocade называют аппаратным виртуальным коммутатором (Hardware Based VEB).
При использовании этого варианта весь трафик от виртуальных машин направляется на локальный сетевой адаптер для коммутации: если трафик предназначен для виртуальной машины, находящейся на том же сервере, он направляется обратно гипервизору, если нет — уходит в сеть. Данный вариант коммутации использует стандартный формат кадра Ethernet. К преимуществам технологии Hardware Based VEB специалисты Brocade относят низкую загрузку процессора сервера, а также возможность (правда, лишь частичную) для настройки политик безопасности и использования механизма качества обслуживания (QoS), к недостаткам — ограничения по управлению трафиком.
_300.jpg) |
| Рисунок 6. Технология виртуализации PCI-устройств Single-Root I/O Virtualization (SR-IOV). |
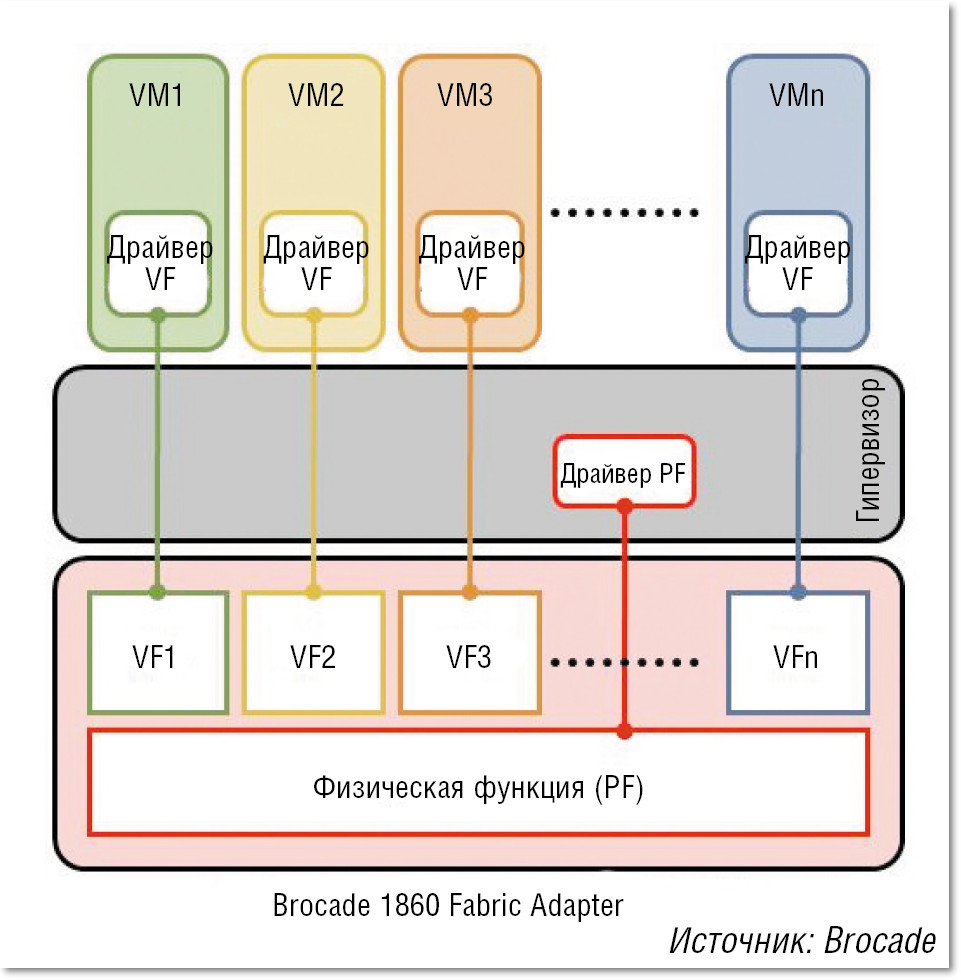
Второй и третий варианты в решении Brocade основаны на использовании технологии виртуализации PCI-устройств Single-Root I/O Virtualization (SR-IOV), разработанной группой специалистов PCI Special Interest Group. Эта технология вводит понятие «виртуальной функции» — Virtual Function (VF) и позволяет разделять сетевое устройство PCI на несколько виртуальных экземпляров, которые будут работать непосредственно с виртуальными машинами (см. Рисунок 6). Например, при использовании метода разделения ресурсов SR-IOV в рамках одного физического адаптера FA 1860 может быть создано 255 виртуальных экземпляров. К сожалению, как отмечают специалисты Brocade, технология SR-IOV имеет свои ограничения: в текущей спецификации предусматривается только передача входящего/ исходящего трафика виртуальных машин, а локальная коммутация осуществляется программным коммутатором гипервизора. Кроме того, виртуальный экземпляр адаптера VF не может вести себя как полноценный физический PCI-адаптер и поэтому требуется дополнительная инсталляция драйверов для гипервизора операционной системы VMware ESX и Microsoft HyperV, а также для BIOS серверов. Такая поддержка только планируется производителями этих операционных систем, что затрудняет применение методов Hardware Based VEB и VEPA.
Компания Brocade предлагает и свою фирменную технологию логического разделения ресурсов адаптера FA 1860 (пропускной способности порта и внутренней шины PCI) — vFLink, причем она не требует дополнительной установки драйверов для операционной системы VMware ESX и Microsoft Hyper-V. В режиме работы CNA на одном порту 10 GbE можно организовать до 8 независимых логических сетевых адаптеров и до 16 при использовании двух портов — в любой комбинации vNIC и vHBA. Общая пропускная способность (10 Гбит/с для портов Ethernet и 16 Гбит/с для портов Fibre Channel) может быть распределена между виртуальными адаптерами с шагом 100 Мбит/с.
12. Мультикаст на MACVTAP-интерфейсах по-умолчанию выключен и его необходимо на них включить.
Здесь необходимо учесть, что KVM создает macvtap-интерфейсы только после старта машины! Поэтому нельзя просто так взять и сказать, например, crontab -e и положить туда что-то вроде @rebootipconfig macvtap0 allmulti
Решением будет создать скрипт с именем "qemu", включающий мультикаст на создающихся при старте машины macvtap-интерфейсах, и положить его в папку /etc/libvirt/hooks
Cначала выключим машину. Из самого VRR: request system power-off
Или из Линупса: virsh shutdown vrr20
Создаём папку и затем скрипт в ней:
Добавляем следующий текст:
Сохраняем и выходим: CTRL+O + CTRL+X
Делаем скрипт исполняемым:
chmod +x /etc/libvirt/hooks/qemu
KVM при старте машины автоматически проверяет существование файла в директории /etc/libvirt/hooks/ и запускает его при старте виртуальных машин.
Включаем машину:
Смотрим, активировался ли мультикаст на macvtap-интерфейсах:
ip address | egrep 'macvtap.*ALLMULTI'

Здесь видно, что появились два macvtap-интерфейса:
macvtap0=ens33=em0 в VRR,
macvtap1 = ens34 = em1 в VRR
Проверяем show ospf neighbor:

Ура!
Полезные команды VIRSH:
cd /etc/libvirt/qemu/ - перейти в папку qemu
virsh list –all --inactive - вывести список всех машин, даже выключенных
virsh net-list –all --inactive - список настроенных сетей KVM
virsh pool-list - показать какие настроены ПУЛЫ хранения вирт-машин
virsh pool-info images - информация о хранилище образов "images"
virsh pool-dumpxml images - вывести инфо о папке images в XML
virsh autostart vrr20 - сделать автостарт машины при запуске Линукса
Найти файл нашего VRR:
find / -name *.xml | grep vrr20
Большое спасибо Михаилу Шишкову за ценные консультации и помощь в подготовке скрипта "qemu"!
Я только что нашел много разных способов создания сетей KVM. Но я застрял о том, как правильно это сделать. Я обнаружил, что openstack использует macvtap для создания нейтронных сетей. И это выглядит хорошо.
Но какая разница и зачем использовать каждый способ.
Способ 1 [СТАРЫЙ? TUN / TAP]
В основном вы создаете мостовой интерфейс с вашим физическим интерфейсом внутри и
И когда вы запускаете виртуальную машину из virt-manager, интерфейс vnet создается и добавляется к мосту. По крайней мере, до тех пор, пока я не знаю. Интерфейс TUN / TAP не требуется.
Долгое время это работало довольно хорошо, но теперь с дерзостью я обнаружил проблемы.
Почему вы можете добавить новый интерфейс vnet на мост без интерфейса TAP?
Способ 3 [MACVTAP]
Последний интерфейс Macvtap.
Он копирует программный интерфейс TUN / TAP, но делает это лучше. Не знаю, каким образом, но, кажется, лучше.
В чем преимущество macvtap перед вторым способом?
Любая помощь в этом?
Это действительно зависит от того, чего именно вы хотите достичь
Неважно, виртуальная машина или физическая машина. TUN приносит вам туннелированную сеть и TAP устройство. Короче говоря, вы проходите через туннельную сеть, чтобы связаться с другой сетью.
Например, при настройке сети OpenVPN вы получите 10.8.0.6 на своем клиенте. Сервер VPN 10.8.0.1 направляет ваш запрос в другую сеть (например, 192.168.xx) позади. При использовании TAP вы получите IP-адрес (192.168.10.10/24) непосредственно из вашей целевой сети (192.168.10.x / 24). Просто.
«Linux Bridge» соединяет VNET (от ВМ) до физического Ethernet. Если вам нужна виртуальная машина (на основе KVM), мост должен быть между vnet и ethernet на хосте
Ммммм. Спасибо за ответ, но это не решает мои сомнения. Если вы увидите ссылки, вы обнаружите, что есть больше причин использовать ту или иную. Фактически мост теперь не работает хорошо на текущем стеке Linux для VM. Поэтому мне пришлось использовать MACVTAP.
Я бы сказал, что это зависит от вашего варианта использования.
Автоматизированные добавления / удаления виртуальных хостов?
Попробуйте Macvtap. Он также должен быть более производительным, чем macvlan (что примерно соответствует добавлению другого MAC к физическому устройству, информация о котором поступает туда, обрабатывается сетевым стеком) или дополнительным мостом, поскольку macvtap каким-то образом обходит сетевой стек и напрямую экспортирует символьное устройство. Но не приставай ко мне. Помимо того, что оба (macvlan / macvtap) используют одни и те же доступные режимы (VEPA / шпилька, мостовой, приватный), шпилька работает только в том случае, если ваш коммутатор поддерживает режим отражательного реле. (Пакеты, поступающие на физический коммутатор через порт x, должны иметь возможность снова покинуть коммутатор через тот же порт x.)
Поскольку eth0 (или тот, который вы используете) переводится в смешанный режим при использовании моста, говорят, что режимы macvXXX имеют более высокую пропускную способность.
Режимы также определяют «количество» изоляции (могут ли vhosts видеть трафик друг друга? Как насчет hv?). Как это работает под капотом я пока не знаю.
veth (виртуальные пары Ethernet) несколько похожи для изоляции: вы определяете два виртуальных интерфейса: один подключается к мосту, другой - к вашей виртуальной машине. Там изоляция осуществляется путем помещения vm-интерфейса в собственное пространство имен, чтобы устройства были несколько изолированы. Весь трафик собирается на мосту, но один vhost не может видеть vNIC другого.
Если вы работаете с мостом, у вас есть дополнительные настройки, и когда мост не работает, все ваши подключения. При восстановлении моста вам, возможно, придется снова подключить все виртуальные интерфейсы к мосту (или просто перезагрузить полную версию hv . ).
Итог: если вы не часто меняете свою топологию, просто переходите к мостовому соединению, поскольку вы найдете в нем наибольшую информацию, что лучше, чем чтение кода ядра. Черт возьми, даже самому пакету iproute2-doc не хватает большей части информации, которую действительно имеет iproute2, даже когда вы запускаете новейшие версии. Попробуйте узнать об этом man ip-tcp_metrics из доступных manpages или ip-crefs.ps .
Эти методы делают принципиально разные вещи. Чтобы понять почему, вам нужно понять многоуровневую модель сетевого взаимодействия. Для наших целей здесь важны слои 1, 2 и 3:
- Уровень 1 является физическим уровнем - он определяет такие вещи, как то, какие кабели вы можете использовать, какие схемы напряжения / тока представляют 1 и 0 на этом кабеле, как устройства на каждом конце кабеля согласовывают, с какой скоростью передачи данных они работают, и так далее.
- Уровень 2 является канальным уровнем - он определяет, какие языковые объекты на каждом конце кабеля общаются друг с другом. Устройства Ethernet на этом уровне имеют такие вещи, как кадры и MAC-адреса.
- Уровень 3 - это сетевой уровень - он определяет, как устройства используют прямую связь уровня 2 с другим устройством для доступа к третьему устройству, к которому они не могут подключиться напрямую на уровне 2. Устройства на этом уровне имеют IP-адреса и таблицы маршрутизации.
MACVLAN / MACVTAP
MACVLAN создает виртуальный уровень 2 или устройство канального уровня со своим собственным MAC-адресом, который совместно использует уровень 1 или физический уровень с существующим устройством. Наиболее очевидно понятный случай, когда у вас есть устройство Ethernet, подключенное к сети, и вы создаете устройство MACVLAN на основе этого устройства Ethernet; Теперь у вас есть два Ethernet-устройства с разными MAC-адресами, но оба они передают свои кадры по одному и тому же кабелю. Я буду говорить о MACVTAP немного дальше.
Интерфейсы MACVLAN могут взаимодействовать несколькими различными способами с существующим интерфейсом Ethernet, в частности, когда на одном из интерфейсов появляется кадр, который адресован другому:
Обратите внимание, что интерфейсы MACVLAN имеют важное ограничение: они не способны к изучению адресов. Таким образом, вы не можете соединить интерфейс MACVLAN со вторым физическим устройством и ожидать, что сможете подключиться к этому второму физическому устройству через первое. Это работает с исходным интерфейсом Ethernet, но не с подключенным к нему интерфейсом MACVLAN.
TUN / TAP
Интерфейс TAP также является новым виртуальным устройством уровня 2, но к нему не подключен уровень 1. Вместо этого программа может получить дескриптор файла, представляющий физический уровень. Затем он может записать необработанные данные кадра Ethernet в этот файловый дескриптор, и ядро будет обрабатывать его как любой другой пакет Ethernet, полученный на реальном физическом интерфейсе.
Главное в интерфейсах TAP то, что физический уровень находится в режиме пользователя; любое программное обеспечение с соответствующими разрешениями может генерировать кадры Ethernet любым удобным для них способом и превращать их во что-то, что ядро рассматривает так же, как реальный физический интерфейс. Это делает их очень полезными для таких вещей, как VPN и туннелирование; Вы можете написать любое программное обеспечение для туннелирования, которое вам нравится, в пространстве пользователя, и вам не нужно вмешиваться в пространство ядра, чтобы поместить кадры в сетевой стек, вы просто создаете устройство TAP и записываете кадры в его файловый дескриптор.
Устройства TUN аналогичны устройствам TAP, за исключением того, что они работают на уровне 3 вместо уровня 2, и программное обеспечение пользовательского режима должно записывать необработанные IP-пакеты в файловый дескриптор вместо необработанных кадров Ethernet.
Возвращаясь к устройствам MACVTAP , это своего рода смешение между интерфейсами MACVLAN и TAP. Как и интерфейсы TAP, программа пользовательского режима может получить дескриптор файла и записать в него необработанные кадры Ethernet. Подобно интерфейсу MACVLAN, эти кадры затем отправляются через физический уровень реального устройства Ethernet. Это позволяет вам легко адаптировать программное обеспечение, написанное для использования устройств TAP, вместо устройства MACVLAN.
VNET
Это концептуально аналогично сетям TUN / TAP, но имеет более развитую плоскость управления (поэтому программное обеспечение пользовательского режима, использующее его, может более гибко настраивать интерфейс) и более оптимизированную плоскость данных (так что вы можете перемещать данные через виртуальное сетевое устройство более подробно). эффективно).
Все они делают подобные вещи, но имеют немного разные возможности. Все они могут быть использованы для подключения виртуальной машины к сети Ethernet:
Необходимо чтобы kvm-хост использовал один ip адрес в качестве шлюза интернет, первая виртуальная машина использовала другой адрес и вторая виртуальная машина соответственно третий адрес.
Как это сделать?


отдать интерфейс гостевой системе
на хосте создаёшь бридж. гостю указываешь этот бридж интерфейс.
и что? в виртуалке же тогда инет kvm-хоста будет, а мне надо в виртуалку отдельный интернет кабель завести. Скорее всего это через секцию interface type='direct' делается:
только непонятно какой mode указывать: vepa, bridge, private или passthrough? Чем они отличаются вообще? И надо ли поднимать предназначенный для виртуальной машины интерфейс на kvm-хосте?
да ничего. ты спросил, я ответил.
или ты имел ввиду сделать по отдельному бриджу для каждого кабеля и уже к ним виртуалки подключать? тогда на хосте придется три интерфейса поднять, как они уживаться будут?

Нормально уживаться. А что такого? Тебе все правильно сказали, делаешь 3 бриджа и готово.
а сетевой интерфейс прокинуть в виртуалку некашерно будет? )

вряд ли у тебя есть свич поддерживающий 802.1Qbg
Mode=bridge?? А почему не Vepa? И зачем вообще свич нужен?
потому что vepa требует поддержки на стороне свича, и таких свичей очень мало.
А можно подробней насчет этого, или ссылкой может поделитесь
сколько интерфейсов нужно для гостей, столько и бриджов создаёшь.
как два еврея. мирно и без проблем.
Немного не по теме конечно, но можете, если не трудно, небольшой ликбез дать, как настроить правильно сеть, если два или более различных кабеля интернет воткнуты. Я вот пробовал, потери пакетов появляются, если два интерфейса подняты. Шлюз прописан разумеется на один из интернетов. Без шаманства с iptables никак не обойтись в этом случае? сорри за оффтопик.
как настроить правильно сеть, если два или более различных кабеля интернет воткнуты.
имеется ввиду что нужно их надо пробросить гостям ?
см. 3-ий коммент этой темы.
на хостевой системе создаётся бридж интерфейс. говоря другими словами, переводишь eth0 в режим моста.
А гостевой системе указываешь именно этот, созданный тобой интерфейс.
Обычно их называют br0/br1 и т.д.
так же как и с обычным хостом, воткнутым в два аплинка, только сетевые хоста прицеплены к мостам, к которым цепляются виртуалки.
пример который я указывал наверху, для простого использования macvtap и отдачи доступа к сетевой хоста виртуалке, без проброса PCI. можно обойтись и без этих извратов, с обычным мостом, который в данном случае выступает как виртуальный хаб
3. Активируем сервис LIBVIRTD:

Libvertd started OK
11. Запускаем VRR20
Машина запускается, смотрим ещё раз сеть командой ip address.
Должен появиться хотя бы один MACVTAP-интерфейс, выполняющий бриджинг виртуального сетевого интерфейса VRR “e1000” в интерфейс Centos – “eno16777736” – и далее в LAN:

После окончания загрузки - заходим на консоль vrr20:
Должен быть виден (хотя бы) em0.
Назначаем на em0 адрес в нашей LAN, у меня это 172.24.224.26:
Должен запинговаться default GW в LAN:

Отл.
Казалось-бы - ура, можно поднимать с RR OSPF и BGP, но, не всё так просто ----------> см. пункт 12
ТРЕТИЙ ТОРЖЕСТВЕННЫЙ МОМЕНТ
2. Добавляем своего пользователя (здесь пользователь - “avk”) в группы libvirt и kvm:
ВИРТУАЛЬНЫЕ И (ИЛИ) ФИЗИЧЕСКИЕ
Многие эксперты считают наиболее перспективными технологии наподобие VEPA, когда сетевое взаимодействие между виртуальными машинами выводится в физическую сеть. Однако ряд причин, в том числе уже упомянутая задержка с выходом необходимых для механизма SR-IOV драйверов для популярных гипервизоров, осложняют реализацию этих технологий. Собственно, с точки зрения разработчиков сред виртуализации вполне логично выглядит отсутствие у них большого энтузиазма по созданию инструментов, которые позволят вывести из-под их контроля такой важный процесс, как взаимодействие виртуальных машин.
В этой связи показательна позиция Cisco. Продвигая технологию 802.1BR с целью обеспечить «проникновение» сети вглубь сервера, она не менее активно развивает и свой виртуальный коммутатор Nexus 1000V, который выполняет локальную коммутацию трафика виртуальных машин внутри сервера. Правда, при этом функции управления этим процессом — модуль Virtual Supervisor Module (VSM) — выносятся вовне. Это вам ничего не напоминает? Конечно, это не что иное, как реализация идей SDN: обработка трафика отделяется от управления этим процессом (подробнее см. статью «SDN: кому и зачем это надо?» в декабрьском номере «Журнала сетевых решений/LAN» за 2012 год). В полном соответствии с этим принципом построено и решение по виртуализации сети компании Nicira, причем оно ориентировано на использование программных коммутаторов (Open vSwitch). Именно ради этого решения, а не каких-то агентов OpenFlow, на мой взгляд, эта компания и была приобретена VMware.
И программные (виртуальные), и физические коммутаторы станут играть важную роль в процессе построения сетей нового поколения, где требуется обеспечить эффективную поддержку виртуальных машин. Причем преимущество получат те продукты, которые позволят включить сетевые объекты обоих типов в единую коммутационную среду. И совсем будет замечательно, если эта среда окажется построена по принципам «фабрики», то есть с минимумом иерархических уровней (в идеале — связь по принципу «каждый с каждым»), поддержкой всех линий связи в активном состоянии с обеспечением низкой задержки и отсутствием точек общесистемного отказа.
В определенный момент домашняя лаба (бесшумная - ищите по запросу "Totally silent (fanless) LAB") доросла до потребности в RR (route-reflector) - чтобы не поднимать сессии между всеми устройствами, - не разводить в квартире full-mesh , а поднять c каждого устройства лишь одну сессию - с RR.
Было решено использовать Juniper VRR - крутиться он может на чём угодно, подойдет (относительно) старый комп или ноут, где есть хотя бы 6GB RAM.

Данная статья является пошаговым руководством по установке Juniper VRR на KVM в Linux Centos или Ubuntu. VRR будет смотреть в локальную сеть, поэтому с ним можно будет поднять соседство с железных (или других виртуальных) сетевых устройств.
Сеть будет настроена с помощью macvtap-бриджа в LAN. Будет также создан скрипт qemu, включающий мультикаст на macVtap-интерфейсах, возникающих при старте виртуальной машины, благодаря чему с ней можно будет поднять OSPF, чтобы затем поднять BGP (чтобы в лабе было как в жизни: у BGP был маршрут до соседей не статикой, - а динамически от OSPF).
Centos или Ubuntu могут быть реальными или виртуальными.
В данном примере:
subnet = 172.24.224.0/27
GW = 172.24.224.10
Linux with KVM ip = 172.24.224.18/27
VRR 20 ipv4 = 172.24.224.26/27
Linux user = “avk”
Далее - ОДИНАКОВО для Centos/Ubuntu > > >
Б). Вариант с Ubuntu
8. Запускаем инсталляцию VRR в KVM - одной строкой - с помощью утилиты virt-install импортом двух дисков с именами junos-x86-64-20.4R1-S1.2.img и metadata.img. RAM = 4192 mb:
В том окне, где мы запустили инсталляцию будет “Waiting for the installation to complete":

Чтобы попасть в саму установку JUNOS - в отдельном терминале до этой машины говорим:
Дожидаемся окончания установки, логинимся root, ставим пароль на root и выключаем машину:
"Request system power-off" нужен, чтобы установка завершилась. После чего можно переходить к настройке сети.
ВТОРОЙ ТОРЖЕСТВЕННЫЙ МОМЕНТ
10. Редактируем выключенную машину vrr20:
Попадаем в редактирование (vi либо nano) xml-документа. Скроллим вниз до – это сетевой интерфейс, который создается автоматически при инсталляции VRR:

Заменяем весь этот блок - на новый. В нём “type network”, заменяется на ‘direct’, а source network заменяем на source dev=eno1677736 (выясненное в пункте 9):
Обратите внимание на "slot='0x03'" – делаем в нашем новом блоке таким же, как в том который было до этого, либо любое другое значение, но не повторяющееся больше ни разу в файле!

Проверить можно заранее сделав cat + grep по xml-файлу нашего vrr20.xml (ну или grep -i "slot full-width ">
Здесь видно, что для второго интерфейса можно взять, например, слот 0x08, т.к. как он ни разу в файле не встречается. Второй интерфейс может понадобиться для mgmt или резервирования доступности VRR. В VMWARE можно сделать, например, один сетевой интерфейс нашего Centos/Ubuntu в режиме NAT, второй - bridge.
Заканчиваем редактирование vrr20. Если редактор VI это будет Escape, shift + :, wq! + enter. В случае с nano - ctrl+O + Enter + Ctrl+X.
802.1BR И ВЫНОСЫ ПОРТОВ
Предложенная Cisco технология VN-Tag, которая положена в основу стандарта IEEE 802.1BR, предполагает вынос (extender) портов коммутатора. Они (выносы) могут быть реализованы на базе отдельных сетевых элементов (например, устройств Nexus 2000 или сетевых модулей для блейд-серверов Cisco UCS), в сетевых адаптерах серверов и даже на уровне подключений виртуальных машин (технология VM-FEX).
Это означает проникновение сети «внутрь» сервера и включение в единую плоскость коммутации не только портов коммутаторов, но также серверных адаптеров и виртуальных машин. Управление коммутаторами вместе с выносами осуществляется как одним устройством, а добавление выносов, по сути, аналогично установке линейных карт в обычный модульный коммутатор.
Технология VN-Tag предусматривает добавление в кадры тега с одноименным названием. Главными компонентами этого тега являются поля с идентификаторами виртуальных интерфейсов (VIF) отправителя и получателя. Такие интерфейсы могут идентифицировать разные объекты, например виртуальные сетевые адаптеры (vNIC) виртуальных машин. На одном физическом порту может быть сформировано несколько виртуальных интерфейсов. Они становятся частью распределенного коммутатора, а потому трафик между такими интерфейсами (значит, и между виртуальными машинами) пойдет через его основной блок.
Технологию VN-Tag можно использовать как для выноса портов (по сути, для формирования распределенной коммутационной фабрики, в состав которой включаются виртуальные машины), так и для вывода трафика виртуальных машин в сеть. Важный плюс этой технологии — возможность конфигурировать каждый индивидуальный виртуальный интерфейс так, как будто это обычный физический порт. Главный недостаток — необходимость введения дополнительных полей в кадр Ethernet, что может потребовать аппаратной модернизации продуктов.
Ставим Ubuntu, например 21 server.
Устанавливаем в нём KVM + необходимое:
sudo apt install qemu-kvm libvirt-daemon-system libvirt-clients bridge-utils net-tools virtinst virt-manager
7. Копируем архив .tgz (либо эти два образа) в /var/lib/libvirt/images/vrr20/ - с помощью MC либо WinSCP:

Проверяем MD5:
После распаковки появится подпапка с именем, например, 20.4R1-S1.2 – из которой (лично мне так удобнее) файлы перемещаем в папку vrr20:
4. Делаем нашему Centos/Ubuntu - перезагрузку:
1. Устанавливаем Сentos или Ubuntu.
А) Вариант с Centos.
Читайте также: