
Коллизия в хешировании это
Коллизией хеш-функции H называется два различных входных блока данных x и y таких, что H(x) = H(y).
Разрешение коллизий в хеш-таблицах
Коллизии осложняют использование хеш-таблиц, так как нарушают однозначность соответствия между хеш-кодами и данными. Тем не менее, существуют специальные методики для преодоления возникающих сложностей:
Коллизией хеш-функции называется два различных входных блока данных и таких, что
Коллизии существуют для большинства хеш-функций, но для «хороших» хеш-функций частота их возникновения близка к теоретическому минимуму. В некоторых частных случаях, когда множество различных входных данных конечно, можно задать инъективную хеш-функцию, по определению не имеющую коллизий. Однако для хеш-функций, принимающих вход переменной длины и возвращающих хеш постоянной длины (таких как MD5), коллизии обязаны существовать, поскольку хотя бы для одного значения хеш-функции соответствующее ему множество входных данных (полный прообраз) будет бесконечно — и любые два набора данных из этого множества образуют коллизию.
Коллизии хеш-функции SHA-1
В феврале 2005 года Ван Сяоюнь, Лиза Инь Ицюнь и Юй Хунбо представили атаку на полноценный SHA-1, которая требует менее 2 69 операций.
В августе 2005 года на CRYPTO 2005 эти же специалисты представили улучшенную версию атаки на полноценный SHA-1, с вычислительной сложностью в 2 63 операций. В декабре 2007 года детали этого улучшения были проверены Мартином Кохраном.
Кристоф де Каньер и Кристиан Рехберг позже представили усовершенствованную версию атаки на SHA-1, за что были удостоены награды за лучшую статью на конференции ASIACRYPT 2006. Ими была представлена двух-блоковая коллизия на 64-раундовый алгоритм с вычислительной сложностью около 2 35 операций.
Ввиду того, что теоретические атаки на SHA-1 оказались успешными, NIST планирует полностью отказаться от использования SHA-1 в цифровых подписях.
Разрешение коллизий в хеш-таблицах
Коллизии осложняют использование хеш-таблиц, так как нарушают однозначность соответствия между хеш-кодами и данными. Тем не менее, существуют специальные методики для преодоления возникающих сложностей:
Разрешение коллизий (англ. collision resolution) в хеш-таблице, задача, решаемая несколькими способами: метод цепочек, открытая адресация и т.д. Очень важно сводить количество коллизий к минимуму, так как это увеличивает время работы с хеш-таблицами.
Коллизии криптографических хеш-функций
Мерой криптостойкости хеш-функции является вычислительная сложность нахождения коллизии. Так как криптографические хеш-функции используются для подтверждения неизменности исходной информации (например, для создания цифровой подписи), то найти коллизию для них должно быть сложно (не проще чем полным перебором).
Для криптографических хеш-функций различают два типа стойкости к нахождению коллизий:
Пожалуй, самой простой атакой на нахождение коллизий является атака «дней рождения». С помощью этой атаки отыскание коллизии для хеш-функции разрядности n бит потребует в среднем около 2 n / 2 операций. Поэтому n-битная хеш-функция считается криптостойкой, если вычислительная сложность нахождения коллизий для нее близка к 2 n / 2 .
Также ключевым свойством хеш-функций является их необратимость:
- Под необратимостью понимается вычислительная невозможность нахождения исходного блока данных X по известному значению хеш-функции от этого блока H(X) .
На этом свойстве основано большинство методов применения хеш-функций в криптографии. В качестве примера можно рассмотреть простую процедуру аутентификации пользователя: при регистрации в системе пользователь вводит свой пароль, к которому применяется хеш-функция и результат записывается в базу данных; далее при каждом вводе пароля, он хешируется и результат сравнивается с тем, который записан в БД. При таком подходе даже если злоумышленник получит доступ к базе данных, он не сможет восстановить исходные пароли пользователей (при условии того, что обеспечено свойство необратимости хеш-функции). Однако, если злоумышленник умеет находить коллизии для этой хеш-функции, ему не составит труда найти поддельный пароль, который будет иметь хеш одинаковый с паролем пользователя.
Большая часть современных хеш-функций имеют одинаковую структуру, основанную на разбиении входного текста на блоки и последующем итерационном процессе, в котором на каждой итерации используется некоторая функция G(x,y) , где x — очередной блок входного текста, а y — результат предыдущй операции. Однако такая схема несовершенна, так как, зная функцию G , мы можем проводить анализ данных в промежутках между итерациями, что облегчает поиск коллизий.
Решение задания collision
Нажимаем на вторую иконку с подписью collision, и нам говорят, что нужно подключиться по SSH с паролем guest.

При подключении мы видим соотвтствующий баннер.

Давайте узнаем какие файлы есть на сервере, а также какие мы имеем права.

Таким образом мы можем можем прочитать исходный код программы, так как есть право читать для всех, и выполнить с правами владельца программу col (установлен sticky-бит). Давайте просмотрим исход код.
Из кода следует, что программа принимает в качестве параметра строку из 20 символов, передает в функцию, которая вычисляет хеш и сравнивает его с эталонным значением.


Внутри функции наша строка разбивается на 5 блоков по 4 байта, которые преобрауются в числа, после чего эти числа суммируются. Таким образом нам нужно 5 чисел, которые в сумме дадут 0x21dd09ec. Удовлеворяют условию: 0xd1d905e8 и 0x01010101.

Теперь нужно передать непечатуемые символы в командную строку в качестве параметра для программы. Для этого используем синтаксис bash и интерпретатор python. Важно отметить, что при в памяти компьютера эти числа будут хранится в обратном порядке, потому перевернем их.

Как результат, получаем три очка.

Сейчас мы рассмотрели очень простой пример коллизии, а в следующей статье решим третье задание и разберем такую уязвимость, как переполнение буфера в стеке. До встречи в следующих статьях.
Свойства криптографических хеш-функций
Для того, чтобы хеш-функция H считалась криптографически стойкой, она должна удовлетворять трём основным требованиям, на которых основано большинство применений хеш-функций в криптографии:
Содержание
Коллизии других хеш-функций
Хеш функции RIPEMD и HAVAL также являются уязвимыми к алгоритму поиска коллизий MD5, опубликованному Ван Сяоюнь (Wang Xiaoyun), Фен Дэнгуо (Feng Dengguo), Лай Сюэцзя (Lai Xuejia) и Юй Хунбо (Yu Hongbo) в 2004 году.
Для второй модификации хеш-функции WHIRLPOOL, называемой Whirlpool-T, на 2009 год не предложено алгоритмов поиска коллизий или псевдоколлизий; существенным ограничением для их нахождения является сложность самой функции и большая длина (512 бит) выходного ключа.

операций.
Защита от использования коллизий
Существует ряд методов защиты от взлома, защиты от подделки паролей, подписей и сертификатов, даже если злоумышленнику известны методы построения коллизий для какой-либо хеш-функции.
Одним из методов является метод «salt», применяемый при хранении UNIX-паролей — добавление некоторой последовательности символов перед хешированием. Иногда, эта же последовательность добавляется и к полученному хешу. После такой процедуры итоговые хеш-таблицы значительно сложнее анализировать, а так как эта последовательность секретна, существенно повышается сложность построения коллизий — злоумышленнику должна быть также известна последовательность «salt».
Другим методом является конкатенация хешей, получаемых от двух различных хеш-функций. При этом, чтобы подобрать коллизии к хеш-функции , являющейся конкатенацией хеш-функций и , необходимо знать методы построения коллизий и для , и . Недостатком конкатенации является увеличение размера хеша, что не всегда приемлемо в практических приложениях.
Содержание
Пример

Рассмотрим в качестве примера хеш-функцию , определённую на множестве целых чисел. Её область значений состоит из 19 элементов (кольца вычетов по модулю 19), а область определения — бесконечна. Так как множество прообразов заведомо больше множества значений, коллизии обязаны существовать.
Построим коллизию для этой хеш-функции для входного значения 38, хеш-сумма которого равна нулю. Так как функция — периодическая с периодом 19, то для любого входного значения y, значение y + 19 будет иметь ту же хеш-сумму, что и y. В частности, для входного значения 38 той же хеш-суммой будут обладать входные значения 57, 76, и т. д. Таким образом, пары входных значений (38,57), (38,76) образуют коллизии хеш-функции .
Коллизии в хеш функциях
Коллизия хеш-функции — это такая пара блоков x и y, результат хеш-функции hash() от которых дает в результате одинаковый блок z.
hash(x) = hash(y) = z
Коллизии возможны абсолютно у любой хеш-функции, так как множество входов на много превышает множетсво выходов хеш-функции.

Поэтому стойкость хеш-функции определяется тремя характеристиками:
Коллизии криптографических хеш-функций
Мерой криптостойкости хеш-функции является вычислительная сложность нахождения коллизии. Так как криптографические хеш-функции используются для подтверждения неизменности исходной информации (например, для создания цифровой подписи), то найти коллизию для них должно быть сложно (не проще чем полным перебором).
Для криптографических хеш-функций различают два типа стойкости к нахождению коллизий:
Пожалуй, самой простой атакой на нахождение коллизий является атака «дней рождения». С помощью этой атаки отыскание коллизии для хеш-функции разрядности n бит потребует в среднем около 2 n / 2 операций. Поэтому n-битная хеш-функция считается криптостойкой, если вычислительная сложность нахождения коллизий для нее близка к 2 n / 2 .
Также ключевым свойством хеш-функций является их необратимость:
- Под необратимостью понимается вычислительная невозможность нахождения исходного блока данных X по известному значению хеш-функции от этого блока H(X) .
На этом свойстве основано большинство методов применения хеш-функций в криптографии. В качестве примера можно рассмотреть простую процедуру аутентификации пользователя: при регистрации в системе пользователь вводит свой пароль, к которому применяется хеш-функция и результат записывается в базу данных; далее при каждом вводе пароля, он хешируется и результат сравнивается с тем, который записан в БД. При таком подходе даже если злоумышленник получит доступ к базе данных, он не сможет восстановить исходные пароли пользователей (при условии того, что обеспечено свойство необратимости хеш-функции). Однако, если злоумышленник умеет находить коллизии для этой хеш-функции, ему не составит труда найти поддельный пароль, который будет иметь хеш одинаковый с паролем пользователя.
Большая часть современных хеш-функций имеют одинаковую структуру, основанную на разбиении входного текста на блоки и последующем итерационном процессе, в котором на каждой итерации используется некоторая функция G(x,y) , где x — очередной блок входного текста, а y — результат предыдущй операции. Однако такая схема несовершенна, так как, зная функцию G , мы можем проводить анализ данных в промежутках между итерациями, что облегчает поиск коллизий.
Коллизии криптографических хеш-функций
Так как криптографические хеш-функции используются для подтверждения неизменности исходной информации, то возможность быстрого отыскания коллизии для них обычно равносильна дискредитации. Например, если хеш-функция используется для создания цифровой подписи, то умение находить для неё коллизии фактически равносильно умению подделывать цифровую подпись. Поэтому мерой криптостойкости хеш-функции считается вычислительная сложность нахождения коллизии. В идеале не должно существовать способа отыскания коллизий более быстрого, чем полный перебор. Если для некоторой хеш-функции находится способ получения коллизий существенно более быстрый, чем полный перебор, то эта хеш-функция перестаёт считаться криптостойкой и использоваться для передачи и хранения секретной информации. Теоретические и практические вопросы отыскания и использования коллизий ежегодно обсуждаются в рамках международных конференций (таких как CRYPTO или ASIACRYPT), на большом количестве ресурсов Интернета, а также во множестве публикаций.
Разрешение коллизий в хеш-таблицах
Коллизии осложняют использование хеш-таблиц, так как нарушают однозначность соответствия между хеш-кодами и данными. Тем не менее, существуют специальные методики для преодоления возникающих сложностей:

В данной статье вспомним про колизии в хеш-функциях, и решим второе задание с сайта pwnable.kr.
Специально для тех, кто хочет узнавать что-то новое и развиваться в любой из сфер информационной и компьютерной безопасности, я буду писать и рассказывать о следующих категориях:
- PWN;
- криптография (Crypto);
- cетевые технологии (Network);
- реверс (Reverse Engineering);
- стеганография (Stegano);
- поиск и эксплуатация WEB-уязвимостей.
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Использование коллизий для взлома
В качестве примера можно рассмотреть простую процедуру аутентификации пользователя:
- при регистрации в системе пользователь вводит свой пароль, к которому применяется некоторая хеш-функция, значение которой записывается в базу данных;
- при каждом вводе пароля, к нему применяется та же хеш-функция, а результат сравнивается с тем, который записан в БД.
При таком подходе, даже если злоумышленник получит доступ к базе данных, он не сможет восстановить исходные пароли пользователей (при условии необратимости используемой хеш-функции). Однако, если злоумышленник умеет находить коллизии для используемой хеш-функции, ему не составит труда найти поддельный пароль, который будет иметь ту же хеш-сумму, что и пароль пользователя.
Схожим образом можно использовать коллизии для подделки цифровых подписей и сертификатов.
Содержание
Коллизии хеш-функций MD4 и MD5
В 2004 году китайские исследователи Ван Сяоюнь (Wang Xiaoyun), Фэн Дэнго (Feng Dengguo), Лай Сюэцзя (Lai Xuejia) и Юй Хунбо (Yu Hongbo) объявили об обнаруженной ими уязвимости в алгоритме, позволяющей за небольшое время (1 час на сервере IBM p690 (англ.) русск. ) находить коллизии.
В 2005 году исследователи Ван Сяоюнь и Юй Хунбо из университета Шаньдуна в Китае, опубликовали алгоритм для поиска коллизий в хеш-функции MD5, причём их метод работает для любого инициализирующего вектора, а не только для вектора, используемого по стандарту. Применение этого метода к MD4 позволяет найти коллизию меньше чем за секунду. Он также применим и к другим хеш-функциям, таким как RIPEMD и HAVAL.
В 2008 году Сотиров Александр, Марк Стивенс (Marc Stevens), Якоб Аппельбаум (Jacob Appelbaum) опубликовали на конференции 25th Chaos Communication Congress статью, в которой показали возможность генерирования поддельных цифровых сертификатов, на основе использования коллизий MD5.
Содержание

Каждая ячейка [math]i[/math] массива [math]H[/math] содержит указатель на начало списка всех элементов, хеш-код которых равен [math]i[/math] , либо указывает на их отсутствие. Коллизии приводят к тому, что появляются списки размером больше одного элемента.
В зависимости от того нужна ли нам уникальность значений операции вставки у нас будет работать за разное время. Если не важна, то мы используем список, время вставки в который будет в худшем случае равна [math]O(1)[/math] . Иначе мы проверяем есть ли в списке данный элемент, а потом в случае его отсутствия мы его добавляем. В таком случае вставка элемента в худшем случае будет выполнена за [math]O(n)[/math]
Время работы поиска в наихудшем случае пропорционально длине списка, а если все [math]n[/math] ключей захешировались в одну и ту же ячейку (создав список длиной [math]n[/math] ) время поиска будет равно [math]\Theta(n)[/math] плюс время вычисления хеш-функции, что ничуть не лучше, чем использование связного списка для хранения всех [math]n[/math] элементов.
Удаления элемента может быть выполнено за [math]O(1)[/math] , как и вставка, при использовании двухсвязного списка.

Все элементы хранятся непосредственно в хеш-таблице, без использования связных списков. В отличие от хеширования с цепочками, при использовании этого метода может возникнуть ситуация, когда хеш-таблица окажется полностью заполненной, следовательно, будет невозможно добавлять в неё новые элементы. Так что при возникновении такой ситуации решением может быть динамическое увеличение размера хеш-таблицы, с одновременной её перестройкой.
Последовательный поиск
При попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math]i+1, i+2, i+3[/math] и так далее, пока не найдём свободную ячейку. В неё и запишем элемент.

Линейный поиск
Выбираем шаг [math]q[/math] . При попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math]i+(1 \cdot q), i+(2 \cdot q), i+(3 \cdot q)[/math] и так далее, пока не найдём свободную ячейку. В неё и запишем элемент. По сути последовательный поиск - частный случай линейного, где [math]q=1[/math] .
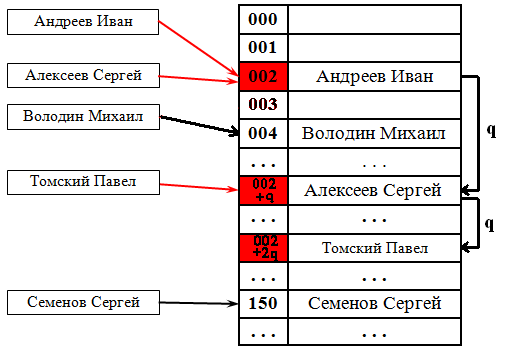
Квадратичный поиск
Шаг [math]q[/math] не фиксирован, а изменяется квадратично: [math]q = 1,4,9,16. [/math] . Соответственно при попытке добавить элемент в занятую ячейку [math]i[/math] начинаем последовательно просматривать ячейки [math] i+1, i+4, i+9[/math] и так далее, пока не найдём свободную ячейку.

Проверка осуществляется аналогично добавлению: мы проверяем ячейку [math]i[/math] и другие, в соответствии с выбранной стратегией, пока не найдём искомый элемент или свободную ячейку.
При поиске элемента может получится так, что мы дойдём до конца таблицы. Обычно поиск продолжается, начиная с другого конца, пока мы не придём в ту ячейку, откуда начинался поиск.
Проблем две — крайне нетривиальное удаление элемента из таблицы и образование кластеров — последовательностей занятых ячеек.
Кластеризация замедляет все операции с хеш-таблицей: при добавлении требуется перебирать всё больше элементов, при проверке тоже. Чем больше в таблице элементов, тем больше в ней кластеры и тем выше вероятность того, что добавляемый элемент попадёт в кластер. Для защиты от кластеризации используется двойное хеширование и хеширование кукушки.
Рассуждение будет описывать случай с линейным поиском хеша. Будем при удалении элемента сдвигать всё последующие на [math]q[/math] позиций назад. При этом:
- если в цепочке встречается элемент с другим хешем, то он должен остаться на своём месте (такая ситуация может возникнуть если оставшаяся часть цепочки была добавлена позже этого элемента)
- в цепочке не должно оставаться "дырок", тогда любой элемент с данным хешем будет доступен из начала цепи
Учитывая это будем действовать следующим образом: при поиске следующего элемента цепочки будем пропускать все ячейки с другим значением хеша, первый найденный элемент копировать в текущую ячейку, и затем рекурсивно его удалять. Если такой следующей ячейки нет, то текущий элемент можно просто удалить, сторонние цепочки при этом не разрушатся (чего нельзя сказать про случай квадратичного поиска).
Хеш-таблицу считаем зацикленной
Вариант с зацикливанием мы не рассматриваем, поскольку если [math]q[/math] взаимнопросто с размером хеш-таблицы, то для зацикливания в ней вообще не должно быть свободных позиций
Теперь докажем почему этот алгоритм работает. Собственно нам требуется сохранение трёх условий.
Докажем по индукции. Если на данной итерации мы просто удаляем элемент (база), то после него ничего нет, всё верно. Если же нет, то вызванный в конце [math]\mathrm[/math] (см. псевдокод) заметёт созданную дыру (скопированный элемент), и сам, по предположению, новых не создаст.
- Элементы, которые уже на своих местах, не должны быть сдвинуты.
Противное возможно только в том случае, если какой-то элемент был действительно удалён. Удаляем мы только последнюю ячейку в цепи, и если бы на её месте возникла дыра для сторонней цепочки, это бы означало что элемент, стоящий на [math]q[/math] позиций назад, одновременно принадлежал нашей и другой цепочкам, что невозможно.
Двойное хеширование (англ. double hashing) — метод борьбы с коллизиями, возникающими при открытой адресации, основанный на использовании двух хеш-функций для построения различных последовательностей исследования хеш-таблицы.
При двойном хешировании используются две независимые хеш-функции [math] h_1(k) [/math] и [math] h_2(k) [/math] . Пусть [math] k [/math] — это наш ключ, [math] m [/math] — размер нашей таблицы, [math]n \bmod m [/math] — остаток от деления [math] n [/math] на [math] m [/math] , тогда сначала исследуется ячейка с адресом [math] h_1(k) [/math] , если она уже занята, то рассматривается [math] (h_1(k) + h_2(k)) \bmod m [/math] , затем [math] (h_1(k) + 2 \cdot h_2(k)) \bmod m [/math] и так далее. В общем случае идёт проверка последовательности ячеек [math] (h_1(k) + i \cdot h_2(k)) \bmod m [/math] где [math] i = (0, 1, \; . \;, m - 1) [/math]
Таким образом, операции вставки, удаления и поиска в лучшем случае выполняются за [math]O(1)[/math] , в худшем — за [math]O(m)[/math] , что не отличается от обычного линейного разрешения коллизий. Однако в среднем, при грамотном выборе хеш-функций, двойное хеширование будет выдавать лучшие результаты, за счёт того, что вероятность совпадения значений сразу двух независимых хеш-функций ниже, чем одной.
[math]\forall x \neq y \; \exists h_1,h_2 : p(h_1(x)=h_1(y))\gt p((h_1(x)=h_1(y)) \land (h_2(x)=h_2(y)))[/math]
[math] h_1 [/math] может быть обычной хеш-функцией. Однако чтобы последовательность исследования могла охватить всю таблицу, [math] h_2 [/math] должна возвращать значения:
- не равные [math] 0 [/math]
- независимые от [math] h_1 [/math]
- взаимно простые с величиной хеш-таблицы
Есть два удобных способа это сделать. Первый состоит в том, что в качестве размера таблицы используется простое число, а [math] h_2 [/math] возвращает натуральные числа, меньшие [math] m [/math] . Второй — размер таблицы является степенью двойки, а [math] h_2 [/math] возвращает нечетные значения.
Например, если размер таблицы равен [math] m [/math] , то в качестве [math] h_2 [/math] можно использовать функцию вида [math] h_2(k) = k \bmod (m-1) + 1 [/math]
Показана хеш-таблица размером 13 ячеек, в которой используются вспомогательные функции:
[math] h(k,i) = (h_1(k) + i \cdot h_2(k)) \bmod 13 [/math]
[math] h_1(k) = k \bmod 13 [/math]
[math] h_2(k) = 1 + k \bmod 11 [/math]
Мы хотим вставить ключ 14. Изначально [math] i = 0 [/math] . Тогда [math] h(14,0) = (h_1(14) + 0\cdot h_2(14)) \bmod 13 = 1 [/math] . Но ячейка с индексом 1 занята, поэтому увеличиваем [math] i [/math] на 1 и пересчитываем значение хеш-функции. Делаем так, пока не дойдем до пустой ячейки. При [math] i = 2 [/math] получаем [math] h(14,2) = (h_1(14) + 2\cdot h_2(14)) \bmod 13 = 9 [/math] . Ячейка с номером 9 свободна, значит записываем туда наш ключ.
Таким образом, основная особенность двойного хеширования состоит в том, что при различных [math] k [/math] пара [math] (h_1(k),h_2(k)) [/math] дает различные последовательности ячеек для исследования.
Пусть у нас есть некоторый объект [math] item [/math] , в котором определено поле [math] key [/math] , от которого можно вычислить хеш-функции [math] h_1(key)[/math] и [math] h_2(key) [/math]
Так же у нас есть таблица [math] table [/math] величиной [math] m [/math] , состоящая из объектов типа [math] item [/math] .
Чтобы наша хеш-таблица поддерживала удаление, требуется добавить массив [math]deleted[/math] типов [math]bool[/math] , равный по величине массиву [math]table[/math] . Теперь при удалении мы просто будем помечать наш объект как удалённый, а при добавлении как не удалённый и замещать новым добавляемым объектом. При поиске, помимо равенства ключей, мы смотрим, удалён ли элемент, если да, то идём дальше.
В Java 8 для разрешения коллизий используется модифицированный метод цепочек. Суть его заключается в том, что когда количество элементов в корзине превышает определенное значение, данная корзина переходит от использования связного списка к использованию сбалансированного дерева. Но данный метод имеет смысл лишь тогда, когда на элементах хеш-таблицы задан линейный порядок. То есть при использовании данныx типа [math]\mathbf[/math] или [math]\mathbf[/math] имеет смысл переходить к дереву поиска, а при использовании каких-нибудь ссылок на объекты не имеет, так как они не реализуют нужный интерфейс. Такой подход позволяет улучшить производительность с [math]O(n)[/math] до [math]O(\log(n))[/math] . Данный способ используется в таких коллекциях как HashMap, LinkedHashMap и ConcurrentHashMap.
Коллизией хеш-функции H называется два различных входных блока данных x и y таких, что H(x) = H(y).
Методы поиска коллизий
Одним из самых простых и универсальных методов поиска коллизий является атака «дней рождения». С помощью этой атаки отыскание коллизии для хеш-функции разрядности битов потребует в среднем около " width="" height="" />
операций. Поэтому n-битная хеш-функция считается криптостойкой, если вычислительная сложность нахождения коллизий для неё близка к " width="" height="" />
.
Большая часть современных хеш-функций имеют одинаковую структуру, основанную на разбиении входного текста на блоки и последующем итерационном процессе, в котором на каждой итерации используется некоторая функция , где x — очередной блок входного текста, а y — результат предыдущей операции. Однако такая схема несовершенна, так как, зная функцию , можно проводить анализ данных в промежутках между итерациями, что облегчает поиск коллизий.
Читайте также: