
Когда появился термин компьютерное зрение
Этот фрагмент взят из недавней публикации, которую составила наша научно-исследовательская группа в области компьютерного зрения. В ближайшие месяцы мы опубликуем работы на разные темы исследований в области Искусственного Интеллекта — о его экономических, технологических и социальных приложениях — с целью предоставить образовательные ресурсы для тех, кто желает больше узнать об этой удивительной технологии и её текущем состоянии. Наш проект надеется внести свой вклад в растущую массу работ, которые обеспечивают всех исследователей информацией о самых современных разработках ИИ.
Компьютерным зрением обычно называют научную дисциплину, которая даёт машинам способность видеть, или более красочно, позволяя машинам визуально анализировать своё окружение и стимулы в нём. Этот процесс обычно включает в себя оценку одного или нескольких изображений или видео. Британская ассоциация машинного зрения (BMVA) определяет компьютерное зрение как «автоматическое извлечение, анализ и понимание полезной информации из изображения или их последовательности».
Термин понимание интересно выделяется на фоне механического определения зрения — и демонстрирует одновременно и значимость, и сложность области компьютерного зрения. Истинное понимание нашего окружения достигается не только через визуальное представление. На самом деле визуальные сигналы проходят через оптический нерв в первичную зрительную кору и осмысливаются мозгом в сильно стилизованном смысле. Интерпретация этой сенсорной информации охватывает почти всю совокупность наших естественных встроенных программ и субъективного опыта, то есть как эволюция запрограммировала нас на выживание и что мы узнали о мире в течение жизни.
В этом отношении зрение относится только к передаче изображений для интерпретации; а компьютинг указывает на то, что изображения больше походят на мысли или сознание, опираясь на множество способностей мозга. Поэтому многие верят, что компьютерное зрение, истинное понимание визуального окружения и его контекста, прокладывает путь к будущим вариациям Сильного Искусственного Интеллекта благодаря совершенному освоению работы в междоменных областях.
Но не хватайтесь за оружие, потому что мы ещё практически не вышли из зачаточной стадии развития этой потрясающей области. Эта статья должна просто пролить немного света на самые значительные достижения компьютерного зрения в 2016 году. И возможно попытаться вписать некоторые из этих достижений в здравую смесь ожидаемых краткосрочных общественных взаимодействий и, где это применимо, гипотетических прогнозов завершения нашей жизни в том виде, какой мы её знаем.
Хотя наши работы всегда написаны максимально доступным образом, разделы в этой конкретной статье могут показаться немного неясными из-за предмета обсуждения. Мы везде предлагаем определения на примитивном уровне, но они дают только поверхностное понимание ключевых концепций. Концентрируясь на работах 2016 года, мы часто делаем пропуски ради краткости изложения.
Одно из таких очевидных упущений относится к функциональности свёрточных нейронных сетей (CNN), которые повсеместно применяются в области компьютерного зрения. Успех AlexNet в 2012 году, архитектуры CNN, которая ошеломила конкурентов в конкурсе ImageNet, стала свидетельством революции, которая де-факто произошла в этой области. Впоследствии многочисленные исследователи начали использовать системы на основе CNN, а свёрточные нейросети стали традиционной технологией в компьютерном зрении.
Прошло более четырёх лет, а варианты CNN по-прежнему составляют основную массу новых нейросетевых архитектур для задач компьютерного зрения. Исследователи переделывают их как кубики конструктора. Это реальное доказательство мощи как open source научных публикаций, так и глубинного обучения. Однако объяснение свёрточных нейросетей легко растянется на несколько статей, так что лучше оставить его для тех, кто более глубоко разбирается в предмете и имеет желание объяснить сложные вещи понятным языком.
Для обычных читателей, которые желают быстро вникнуть в тему перед продолжением этой статьи, рекомендуем первые два источника из перечисленных ниже. Если вы желаете ещё более погрузиться в предмет, то для этого мы приводим ещё и другие источники:
- «Что глубокая нейронная сеть думает о твоём селфи» от Андрея Карпаты — одна из лучших статей, которая помогает людям понять применение и функциональность свёрточных нейросетей. — здесь полно отличных ссылок и объяснений. Особенно подходит для тех, у кого не было предварительного понимания в этой области. — отличный ресурс для более глубокого изучения темы.
- «Глубокое обучение» (Goodfellow, Bengio & Courville, 2016) даёт подробное объяснение функций свёрточных нейросетей и функциональности в главе 9. Авторы любезно опубликовали этот учебник бесплатно в формате HTML.
- «Нейросети и глубокое обучение» (Nielsen, 2017) — бесплатный онлайновый учебник, который обеспечивает действительно интуитивное понимание всех сложностей нейросетей и глубокого обучения. Даже чтение первой части должно во многом осветить для новичков тему предмета этой статьи.
От лица всех участников,
The M Tank

Задача классификации по отношению к изображениям обычно заключается в присвоении метки целому изображению, например, «кот». С учётом этого локализация может означать определение, где находится объект на этом изображении. Обычно тот обозначается неким ограничивающим прямоугольником вокруг объекта. Нынешние методы классификации на ImageNet уже превосходят группы специально обученных людей по точности классификации объектов.
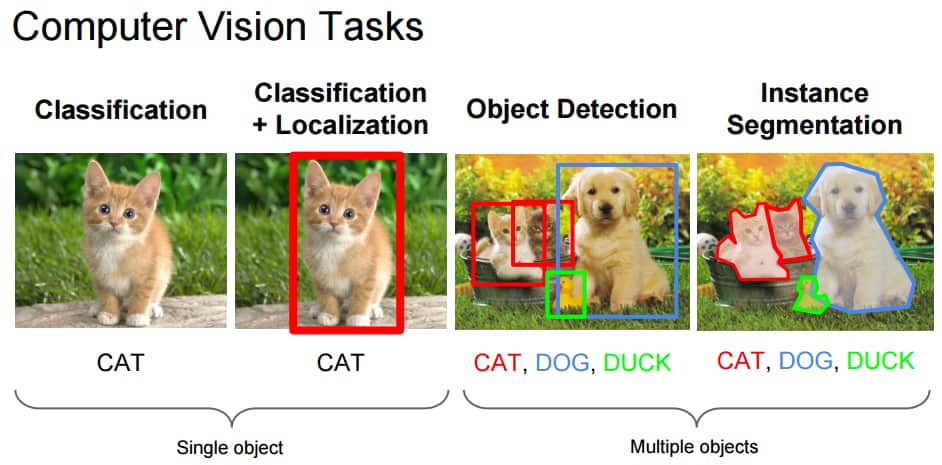
Рис. 1: Задачи компьютерного зрения
Источник: Fei-Fei Li, Andrej Karpathy & Justin Johnson (2016) cs231n, лекция 8 — слайд 8, пространственная локализация и обнаружение (01/02/2016), pdf
Однако увеличение количества классов, вероятно, обеспечит новые метрики для измерения прогресса в ближайшем будущем. В частности, Франсуа Шолле, создатель Keras, применил новые методы, в том числе популярную архитектуру Xception, к внутреннему набору данных Google с более чем 350 млн изображений с множественными метками, содержащими 17 000 классов.

Рис. 2: Результаты классификации/локализации с конкурса ILSVRC (2010–2016)
Примечание: Конкурс ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Улучшение результатов после 2011–2012 гг связано с появлением AlexNet. См. обзор требований конкурса в отношении классификации и локализации
Источник: Jia Deng (2016). Локализация объектов ILSVRC2016: введение, результаты. Слайд 2, pdf
Интересные выдержки с ImageNet LSVRC (2016):
-
Классификация сцены обозначает задачу присвоения меток изображению с определённым классом сцены, таким как «оранжерея», «стадион», «собор» и т.д. В рамках ImageNet в прошлом году прошёл конкурс по классификации сцен на выборке из набора данных Places2: 8 млн изображений для обучения с 365 категориями сцен.
Как можно догадаться, процесс обнаружения объектов делает именно то, что должен делать — обнаруживает объекты на изображениях. Определение обнаружения объектов от ILSVRC 2016 включает в себя выдачу ограничивающих рамок и меток для отдельных объектов. Это отличается от задачи классификации/локализации, поскольку здесь классификация и локализация применяются ко многим объектам, а не к одному доминирующему объекту.

Рис. 3: Обнаружение объектов, где лицо является единственным классом
Примечание: Картинка представляет собой пример обнаружения лиц как обнаружения объектов одного класса. Авторы называют одной из неизменных проблем в этой области обнаружение маленьких объектов. Используя маленькие лица как тестовый класс, они исследовали роль инвариантности размеров, разрешений изображения и контекстуальных обоснований.
Источник: Hu, Ramanan (2016, p. 1)
Одной из главных тенденций 2016 года в области обнаружения объектов стал переход к более быстрым и эффективным системам обнаружения. Это видно по таким подходам как YOLO, SSD и R-FCN в качестве шага к совместным вычислениям на всём изображении целиком. Этим они отличаются от ресурсоёмких подсетей, связанных с техниками Fast/Faster R-CNN. Такую методику обычно называют «тренировкой/обучением от начала до конца» (end-to-end training/learning).
По сути идея состоит в том, чтобы избежать применения отдельных алгоритмов для каждой из подпроблем в изоляции друг от друга, поскольку обычно это повышает время обучения и снижает точность нейросети. Говорится, что такая адаптация нейросетей для работы от начала до конца обычно происходит после работы первоначальных подсетей и, таким образом, представляет собой ретроспективную оптимизацию. Однако техники Fast/Faster R-CNN остаются высокоэффективными и по-прежнему широко используются для обнаружения объектов.
- SSD: Single Shot MultiBox Detector использует единую нейронную сеть, которая выполняет все необходимые вычисления и устраняет необходимость в ресурсоёмких методах предыдущего поколения. Он демонстрирует «75,1% mAP, превосходя сравнимую самую современную модель Faster R-CNN».
- Одной из самых впечатляющих разработок 2016 года можно назвать систему, метко названную YOLO9000: Better, Faster, Stronger, в которой используются системы обнаружения YOLOv2 и YOLO9000 (YOLO означает You Only Look Once). YOLOv2 — это сильно улучшенная модель YOLO от середины 2015 года, и она способна показать лучшие результаты на видео с очень высокой частотой кадров (до 90 FPS на изображениях низкого разрешения при использовании обычного GTX Titan X). Вдобавок к повышению скорости, система превосходит Faster RCNN с ResNet и SSD на определённых наборах данных для определения объектов.
YOLO9000 реализует совмещённый метод обучения для обнаружения и классификации объектов, расширяющий его возможности предсказания за пределы доступных размеченных данных обнаружения. Другими словами, он способен обнаруживать объекты, которые никогда не встречались в размеченных данных. Модель YOLO9000 обеспечивает обнаружение объектов в реальном времени среди более 9000 категорий, что нивелирует разницу в размере наборов данных для классификации и обнаружения. Дополнительные подробности, предобученные модели и видеодемонстрацию см. здесь.
Обнаружение объектов YOLOv2 работает на кадрах фильма с Джеймсом Бондом

Рис. 4: Компромисс между точностью и размером объектов при обнаружении объектов на разных архитектурах
Примечание: По вертикальной оси отложен показатель mAP (mean Average Precision), а по горизонтальной оси — разнообразие мета-архитектур для каждого блока извлечения признаков (VGG, MobileNet… Inception ResNet V2). Вдобавок, малый, средний и большой mAP показывают среднюю точность для малых, средних и крупных объектов, соответственно. По существу, точность зависит от размера объекта, мета-архитектуры и блока извлечения признаков. При этом «размер изображения зафиксирован на 300 пикселях». Хотя модель Faster R-CNN относительно неплохо показала себя в данном примере, важно отметить, что эта мета-архитектура значительно медленнее, чем более современные подходы, такие как R-FCN.
Источник: Huang et al. (2016, p. 9)
В вышеупомянутой научной статье представлено подробное сравнение производительности R-FCN, SSD и Faster R-CNN. Из-за сложностей точного сравнения техник машинного обучения мы хотели бы указать на достоинства создания стандартизированного подхода, описанного авторами. Они рассматривают эти архитектуры как «мета-архитектуры», потому что их можно сочетать с разными блоками извлечения признаков, такими как ResNet или Inception.
Авторы изучают компромиссы между точностью и скоростью работы в разных мета-архитектурах, блоках извлечения признаков и разрешениях. Например, выбор блока извлечения признаков сильно изменяет результаты работы на различных мета-архитектурах.
В научных статьях с описанием SqueezeDet и PVANet ещё раз подчёркивается необходимость компромисса между тенденцией повышения скорости работы приложением со снижением потребляемых вычислительных ресурсов — и сохранением точности, которая требуется для коммерческих приложений реального времени, особенно в приложениях беспилотного автотранспорта. Хотя китайская компания DeepGlint показывала хороший пример обнаружения объектов в реальном времени в потоке с камеры видеонаблюдения.
Определение объектов, отслеживание объектов и распознавание лиц в системе DeepGlint
Результаты ILSVRC и COCO Detection Challenge
COCO (Common Objects in Context) — ещё один популярный набор данных изображений. Однако он относительно меньше по размеру и тщательнее курируется, чем альтернативы вроде ImageNet. Он нацелен на распознавание объектов с более широким контекстом понимания сцены. Организаторы проводят ежегодный конкурс на обнаружение объектов, сегментацию и ключевые точки. Вот результаты с конкурсов ILSVRC и COCO на обнаружение объектов:
- ImageNet LSVRC, обнаружение объектов на изображениях (DET): Система CUImage показала 66% meanAP. Выиграла в 109 из 200 категорий объектов.
- ImageNet LSVRC, обнаружение объектов на видео (VID): NUIST 80,8% meanAP
- ImageNet LSVRC, обнаружение объектов на видео с отслеживанием: CUvideo 55,8% meanAP
- COCO 2016, обнаружение объектов (ограничивающие рамки): G-RMI (Google) 41,5% AP (абсолютный прирост в 4,2 п.п. по сравнению с победителем 2015 года — MSRAVC)

Рис. 5: Результаты систем обнаружения на изображениях в конкурсе ILSVRC (2013–2016)
Примечание: Результаты систем обнаружения на изображениях в конкурсе ILSVRC (2013–2016). Источник: ImageNet 2016, онлайновая презентация, слайд 2, pdf
Относится к процессу отслеживания конкретного интересующего объекта или нескольких объектов, на заданной сцене. Традиционно этот процесс применяется в видеоприложениях и системах взаимодействия с реальным миром, где наблюдения производятся после обнаружения исходного объекта. Например, процесс критически важен для систем беспилотного транспорта.
- «Полностью свёрточные сиамские сети для отслеживания объектов» сочетает базовый алгоритм отслеживания с сиамской сетью, обученной от начала до конца, которая достигает рекордных показателей в своей области и работает покадрово со скоростью, превышающей необходимую для работы приложений реального времени. Эта научная статья пытается преодолеть недостаток функциональной насыщенности, доступный моделям отслеживания из традиционных методов онлайнового обучения.
- «Обучение глубоких регрессионных сетей отслеживанию объектов на 100 FPS» — ещё одна статья, авторы которой пытается преодолеть существующие проблемы с помощью онлайновых методов обучения. Авторы разработали трекер, который применяет сеть с механизмом прогнозирования событий (feed-forward network) для усвоения общих взаимоотношений в связи с движением объекта, его внешним видом и ориентацией. Это позволяет эффективно отслеживать новые объекты без онлайнового обучения. Показывает рекордный результат в стандартном бенчмарке отслеживания, в то же время позволяя «отслеживать общие объекты на 100 FPS».
Видео работы GOTURN (Generic Object Tracking Using Regression Networks)
Компьютерное зрение - область искусственного интеллекта , обучающая компьютеры интерпретировать и понимать визуальный мир. Используя цифровые изображения с камер, видео и модели глубокого обучения, компьютеры точно идентифицируют и классифицируют объекты , а затем реагируют, когда "видят" их снова.
Развитие компьютерного зрения
Как и машинное обучение, компьютерное зрение появилось в 1950-х годах. Тогда вычислительные мощности и доступ к данным были ограничены, поэтому требовалось проводить много операций вручную, а технология действовала с ошибками. Но это уже напоминало известное нам компьютерное зрение.
Еще в 1959 году было обнаружено, как эффективно первичная обработка учитывает основные свойства изображения, например линии или края. В том же году также была изобретена технология , которая позволила преобразовывать картинки в сетки чисел. Этот двоичный язык был понятен машинам, и они могли воспринимать записанные им изображения.
В течение следующих нескольких десятилетий новые технические достижения сделали компьютерное зрение возможным.
- Появилась технология компьютерного сканирования, которая впервые позволила машинам оцифровывать изображения, а затем — превращать двумерные изображения в трехмерные формы.
- В 1974 году создан алгоритм распознавания объектов, который мог воспринимать текст
- К 1982 году уже начало формироваться компьютерное зрение. В том же году один исследователь усовершенствовал иерархию обработки, а другой разработал раннюю версию нейросети.
К началу 2000-х гг. распознавание объектов вызывало особенно большой интерес. В 2010 году был опубликован ImageNet, набор с миллионами размеченных изображений, который дал толчок к развитию компьютерного зрения. Внезапно любой желающий мог получить доступ к огромному количеству готовых к использованию данных.
Большинство существующих систем компьютерного зрения были созданы на базе ImageNet. Но они по-прежнему содержали много ошибок. Все изменилось в 2012 году, когда модель AlexNet, которая использовала ImageNet, значительно снизила частоту ошибок при распознавании изображений, открыв современную область компьютерного зрения.
Розничная торговля
Ритейл может использовать компьютерное зрение, чтобы улучшить процесс совершения покупок, повысить уровень защиты от потерь и обнаружить пустые полки. Компьютерное зрение уже помогает клиентам быстрее оформлять заказы: с помощью автоматов для самостоятельной проверки или в сочетании с машинным обучением полностью облегчает процесс оформления заказа.
Ларри Робертс в 1963 году
Он является автором первой кандидатской диссертации по компьютерному зрению. В его диссертации мир сводится к простым геометрическим фигурам, Цель исследования - идентифицировать эти геометрические фигуры и реконструировать их. (the world is simplified into simple geometric shapes and the goal is to able to recognize them and reconstruct what these shapes are)。

Развитие компьютерного зрения
Дэвид Марр в 1970 году
Дэвид Марр предложил когнитивный процесс зрительной нервной системы. Первый этап - это первичный набросок, включающий края, линии, полосы, границы и линии и т. Д., Второй этап - 2 + 1 / 2D, а второй этап можно разделить на блоки. (Соберите вместе поверхности, информацию о глубине, слои или неоднородности визуальной сцены), третий этап - это трехмерная абстракция, иерархическая информация об элементах поверхности и объема (иерархически организованная с точки зрения поверхностные и объемные примитивы)
Написал эту книгу, и он сделал предложение Концепция наслоения: край-> эскиз-> 3D модель


Дэвид Лоу в 1999 году
Предлагаемое распознавание изображений на основе признаков, а именно SIFT (масштабно-инвариантное преобразование признаков), масштабно-инвариантное преобразование признаков.Смысл распознавания изображений на основе признаков заключается в том, что изображение предмета будет иметь некоторые особенности, которые, как правило, остаются диагностическими и инвариантными под влиянием таких переменных, как угол, свет, деформация и окклюзия. к изменениям), сравнение характеристик путем извлечения этих типичных особенностей изображения лучше, чем сравнение шаблонов всего изображения (сравнение шаблонов)
Распознавание человеческого тела: гистограмма градиентов / модель деформируемой детали

Компьютерное зрение напоминает мозаику
Компьютеры собирают визуальные образы так же, как вы можете составить пазл.
Подумайте, каким методом вы собираете пазл. У вас есть все части, вам нужно собрать их в единую картинку. Так работают нейронные сети для компьютерного зрения. Они различают много разных частей изображения, идентифицируют края и затем моделируют подкомпоненты. Используя фильтрацию и ряд действий через глубокие сетевые слои, они могут объединить все части изображения, также, как вы делаете с пазлом.
Компьютер не получает окончательного изображения пазла, но часто видит сотни или тысячи связанных изображений, чтобы научиться распознавать конкретные объекты.
Вместо того, чтобы учить компьютер искать усы, хвосты и острые уши, чтобы распознать кошку, программисты загружают миллионы фотографий кошек, а затем модель самостоятельно изучает различные характеристики кошки.
Развитие биологического зрения
Около 543 миллионов лет назад древние существа на Земле не имели глаз и бродили по морю с открытыми ртами. В то время на Земле могло быть только несколько видов существ. Андерв Паркер, австралийский биолог, обнаружил первое существо с глазами в окаменелостях. Это существо появилось около 540 миллионов лет назад. В следующие 10 миллионов лет количество существ на Земле экспоненциально увеличилось. Биологи называют это Большим взрывом революции (Big Bang of Revolution). Было много предположений о Большом взрыве. Обнаружив это существо с глазами, биолог предложил Теория: поскольку у существ эволюционировали глаза, действия между хищниками и добычей в существах стали более активными (преактивными), что привело к ускорению биологической эволюции, и количество существ увеличилось с нескольких до миллионов. Сегодня у людей зрение превратилось в самую крупную сенсорную систему, а зрительная кора занимает около половины коры головного мозга. Это показывает важность зрительной системы для биологического развития.

Государственные организации
Государственные учреждения используют компьютерное зрение, чтобы лучше понять физическое состояние активов, находящихся под их контролем, включая оборудование и инфраструктуру. Компьютерное зрение помогает выполнять профилактическое обслуживание, анализируя изображения оборудования и инфраструктуры, чтобы принимать более обоснованные решения о том, какие из них требуют ремонта. Кроме того, гос. учреждения используют компьютерное зрение для контроля за соблюдением правил и норм. Например, компьютерное зрение может использоваться для обнаружения контрабанды в грузе, выявления потенциальных нарушений безопасности в зданиях, проверки этикеток на предмет соответствия нормам хранения. Наконец, по мере того, как беспилотники становятся все более востребованными в сфере обороны и безопасности страны, использование аналитики для выявления и анализа критических элементов выходит на передний план в случаях использования компьютерного зрения в государственном секторе.
Как самостоятельная дисциплина компьютерное зрение зародилось в начале 50-х годов прошлого века. В 1951 году Джон фон Нейман предложил анализировать микроснимки при помощи компьютеров путём сравнения яркости соседних частей изображения. В 60-е годы начались исследования в области распознавания машинного и рукописного текста. Тогда же были сделаны первые попытки моделирования нейронной сети. Первым устройством, способным распознавать буквы, стала разработка Фрэнка Розенблатта — персептроном. А в 70-х годах ученые стали изучать зрительную систему человека с целью её формализации и реализации в виде алгоритмов. Такой подход был призван позволить распознавать объекты на изображениях. Как же работает современное компьютерное зрение – об этом в сегодняшнем выпуске.

Итак, компьютерное зрение — это набор методов, позволяющих обучить машину извлекать информацию из изображения или видео. Чтобы компьютер находил на изображениях определенные объекты, его необходимо научить. Для этого составляется огромная обучающая выборка, например, из фотографий, часть из которых содержат искомый объект, а другая часть — напротив, не содержит. Далее в дело вступает машинное обучение. Компьютер анализирует изображения из выборки, определяет, какие признаки и их комбинации указывают на наличие искомых объектов, и просчитывает их значимость.

После завершения обучения компьютерное зрение можно применять в деле. Для компьютера изображение — это набор пикселей, у каждого из которых есть своё значение яркости или цвета. Чтобы машина смогла получить представление о содержимом картинки, ее обрабатывают с помощью специальных алгоритмов. Сначала выявляют потенциально значимые места. Это можно делать несколькими способами. Например, исходное изображение несколько раз подвергают размытию по Гауссу, используя разный радиус размытия. Затем результаты сравнивают друг с другом. Это позволяет выявить наиболее контрастные фрагменты — яркие пятна и изломы линий.

После того как значимые места найдены, компьютер описывает их в числах. Запись фрагмента картинки в числовом виде называется дескриптором. С помощью дескрипторов можно достаточно точно сравнивать фрагменты изображения без использования самих фрагментов. Чтобы ускорить вычисления, компьютер проводит кластеризацию или распределение дескрипторов по группам. В один и тот же кластер попадают похожие дескрипторы с разных изображений. После кластеризации важным становится лишь номер кластера с дескрипторами, наиболее похожими на данный. Переход от дескриптора к номеру кластера называется квантованием, а сам номер кластера — квантованным дескриптором. Квантование существенно сокращает объём данных, которые необходимо обработать компьютеру.

Опираясь на квантованные дескрипторы, компьютер может сравнивать изображения и распознавать на них объекты. Он сопоставляет наборы квантованных дескрипторов с разных изображений и делает вывод о том, насколько они или их отдельные фрагменты похожи. Такое сравнение в том числе используется поисковыми системами для поиска по загруженной картинке.
Не секрет, что ИИ проник во многие сферы жизни. Однако мы до сих пор не всегда понимаем, когда взаимодействуем с ним, и какие методы он использует. Как правило, в инструментах, связанных с фото или видео, применяется компьютерное зрение.
Компьютерное зрение — это область ИИ, в частности, машинного обучения. Если ИИ позволяет машинам «думать», то компьютерное зрение помогает им «видеть». В техническом плане это позволяет распознавать, понимать и реагировать на визуальную информацию, например, фото или видео.
За последние годы компьютерное зрение стало основным драйвером ИИ. Технология широко используется во многих сферах, в том числе производстве, онлайн-торговле, сельском хозяйстве, автомобилестроении и медицине.
По оценкам, к 2022 году мировой рынок компьютерного зрения вырастет до $48,6 млрд. Еще в 2015 году он составлял всего $6,6 млрд.
История компьютерного зрения в целом повторяет историю ИИ: медленный старт, полный технических препятствий, за ним — взрывной рост, подкрепленный огромными объемами данных, после — быстрое распространение, и, наконец, озабоченность по поводу предвзятости и использования технологии. Разберемся, как оно работает, как используется, с какими проблемами справляется и какие ему еще предстоит решить.
Дэвид Лоу в 1980-е годы
Дэвид Лоу пытался использовать комбинацию линий и линий, чтобы реорганизовать графику, которую он видел, 80 лет Дэвид Лоу определил набор изображений бритв и указал, что объекты могут быть представлены комбинацией линий и линий.
С 60-х по 80-е годы развитие компьютерного зрения в основном отражалось в теоретических предположениях. Оно по-прежнему основано на человеческом восприятии для анализа обработки нервной системы, а не на анализе данных изображения, снятого камерой (конечно, в то время не было числа Информация об изображении). Позже кто-то предложил теорию сегментации изображения, пытаясь сначала сегментировать изображение, а затем распознать его с помощью цветовой информации, которая в основном оставалась на стадии предположений.
Компьютерное зрение в современном мире
От распознавания лиц до обработки движений на футбольном матче, компьютерное зрение превосходит визуальные способности человека во многих областях.
Другие вопросы
- 3D реконструкция
- Activity Recognition
- Зрение робота и др.
[1]: Receptive fields of single neurons in the cat’s striate cortex
[2]: Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex
Хубле и Визель в 1959 году

Исследование принципа формирования зрения людьми должно было начаться очень рано. Самый ранний знаменательный эксперимент был проведен в 1959 году [1] [2]. Биологи Хабле и Визель имплантировали электроды в зрительную кору головного мозга кошек. Проецируя различные линии и формы перед глазами кошки, они обнаружили, что некоторые клетки плоского зрительного слоя кошки чувствительны к определенным линиям, формам или углам. Они называют эти клетки «маленькими клетками», а есть некоторые «комплексы». «Cell» может обнаруживать определенный край (независимо от положения) или определенное направление движения. Позднее вывод этого эксперимента постоянно резюмировался следующим образом: Сложное представление вещей зрительной нервной системой происходит из простых функций, что является методом многоуровневого абстрактного представления. Изображение ниже - это скриншот двух выводов в исходном тексте. Чтобы

Анализ изображений и ИИ
Ознакомьтесь с введением в анализ изображений и изучите аналитические методы, которые можно применять к данным изображений.
Лазебник и др. 2006 г.
Предложите сопоставление пространственной пирамиды, чтобы идентифицировать всю сцену изображения. Они обнаружили, что на реальном изображении, независимо от того, что это за сцена, ее можно классифицировать по признакам, а затем по SVM.
Весенняя загрузка + Vue Все развитие стека делает что-то внешнее знание?
Разработка набора данных
Чтобы оценить развитие компьютерного зрения и извлечь выгоду из развития Интернета, стали появляться наборы данных в качестве стимулов для тестирования алгоритмов компьютерного зрения. Самым влиятельным в 2007–2012 годах был вызов визуальных объектов PASCAL, а затем набор данных ImageNet, созданный командой под руководством профессора Ли Фейфея. В ходе курса профессор Ли Фейфей говорил о цели создания этого набора данных. Одна из них - проверить, может ли алгоритм машинного обучения распознавать все в мире; вторая - вернуть алгоритм машинного обучения к проблеме переобучения.
PASCAL Visual Object Challenge: 20 видов изображений объектов

IMAGENET: 14 миллионов изображений, 22 000 категорий
Конкурс распознавания изображений ImageNet:



С 2010 по 2015 год уровень ошибок при распознавании изображений постепенно снижался, но в 2010 и 2011 годах уровень ошибок по-прежнему составлял около 25%.
В 2012 году произошло значительное падение почти на 10%. Победителем стал 7-слойный CNN, предложенный Хинтоном, которому также посвящен этот курс.
Благодаря CNN точность распознавания и скорость компьютерного зрения в некоторых случаях уже могут быть сопоставимы с человеческим, но компьютерное зрение все еще находится в зачаточном состоянии, а компьютерное зрение лучше понимает информацию об изображении, чем люди. Существует пробел. Люди могут выдавать множество предположений, которые соответствуют ситуации, когда они видят изображение, но компьютеры пока не могут. По сравнению с людьми, компьютерное зрение гораздо более жесткое. Кроме того, потребляемая мощность компьютерного зрения для распознавания и необходимые вычислительные ресурсы также являются проблемой.

Брук и Бинфорд в 1979 году и Фишлер и Эльшлагер в 1973 году.
Предлагаются теории абстрактного описания сложных объектов соответственно: обобщенного цилиндра и изобразительной структуры. Они указали Каждый объект состоит из простых геометрических фигур.

Развитие машинного обучения
В 1997 году Ши и Малик предложили Нормализованное вырезание, сказав нам, что если слишком сложно напрямую идентифицировать объект, мы должны сначала сегментировать изображение и разделить его на значимые части.

Развитие алгоритмов машинного обучения с 1990-х по 2010-е годы, особенно статистического машинного обучения (статистического машинного обучения), таких как поддержка векторных машинных SVM, бустинговых и графических моделей и т. Д., Успешным примером машинного обучения в области компьютерного зрения является распознавание лиц. Пол Виола и Майкл Джонс предложили в 2001 году использовать алгоритм Adaboost для распознавания лиц в реальном времени. , И FujiFilm использовала этот алгоритм для создания камеры, которая может распознавать лица в реальном времени в 2006 году, достигая быстрого преобразования результатов. Следует также отметить, что в то время была предложена сверточная нейронная сеть. В 1998 году Ян Лекун и другие предложили ее для распознавания символов на марках. В то время нейронная сеть не была функционально сопоставима с традиционными машинами. Алгоритм обучения сопротивляется и почти умирает. После неустанной настойчивости Яна Лекуна и других, алгоритм нейронной сети, наконец, открыл богатые и быстрые вычислительные ресурсы и большое количество наборов данных. В 2012 году AlexNet (другое название - надзор) боролся с коренным успехом. С тех пор Открыл эру бурного развития.

Демонстрация распознавания лиц
Изучите основные методы и этапы обработки данных, необходимые для распознавания лиц и компьютерного зрения. Эта демо показывает, как модель SAS ® Viya ® обнаруживает, выравнивает, представляет и классифицирует изображения лица.
Как работает компьютерное зрение
Технология позволяет компьютерам выполнять разнообразные задачи.
- Сегментация изображений (разделяет картинку на части и изучает каждую) и распознавание образов (находит повторы визуальных стимулов между изображениями).
- Классификация объектов (сортирует объекты, обнаруженные на изображении), отслеживание объектов (находит и отслеживает движущиеся объекты на видео) и обнаружение объектов (ищет и идентифицирует конкретные объекты на изображении).
- Распознавание лиц — усовершенствованная форма обнаружения объектов, которая может находить и идентифицировать человеческие лица.
Как упоминалось выше, компьютерное зрение — подраздел машинного обучения, и оно аналогичным образом использует нейросети, чтобы сортировать огромные объемы данных, пока не поймет, на что смотрит.
Конкретный пример использования компьютерного зрения — задача на разделение изображений мороженого и пиццы с пепперони. Система искусственного интеллекта получает множество фотографий с этими продуктами. Затем компьютер пропускает изображения через несколько уровней обработки, из которых состоит нейросеть, чтобы шаг за шагом отличить мороженое от пиццы.
Первые уровни оценивают базовые свойства, например линии или края между светлыми и темными частями изображений. Последующие уровни изучают более сложные детали — формы или даже грани.
Это работает, поскольку системы компьютерного зрения интерпретирует изображения или видео как группы пикселей, каждому из которых присвоено цветовое значение. Эти метки используются как входные данные, которые перерабатывает система при перемещении изображения по уровням нейросети.
Массачусетский технологический институт в 1966 году
Летний проект MIT (Массачусский технологический институт), Создать лабораторию искусственного интеллекта, Задача - изучить механизм зрительного восприятия в течение нескольких месяцев. Конечно, это очень радикальная цель. Пока мы не изучили этот вопрос досконально.

CS231n_Lecture1_ Обзор компьютерного зрения, История компьютерного зрения
Основное содержание курса CS231n в Стэнфордском университете - компьютерное зрение или распознавание изображений, а алгоритм в основном ориентирован на CNN (сверточную нейронную сеть) или глубокое обучение в целом. Компьютерное зрение - это сильный междисциплинарный предмет, включая биологию, психологию, физику, инженерию, математику и так далее.
Первый класс состоит из двух основных частей: одно - это изучение важности компьютерного зрения, а второе - краткая история развития компьютерного зрения.
Важность изучения компьютерного зрения проистекает из повсеместного распространения камер и общественного мнения о визуальной информации.Информация о видео и изображениях составляет большую часть интернет-трафика, а информация о видео и изображениях быстро растет. Спикер сравнил видеоинформацию в Интернете с черной дырой, а это значит, что объем большой, но содержащийся в нем контент сложно наблюдать и анализировать. Кроме того, компьютерное зрение также способствует повышению производительности машин и популяризации искусственного интеллекта.
Ubuntu16.04 установка записи процесса OpenCV
1. Установите зависимости и инструменты OpenCV. 2. Загрузите исходный код OpenCV и функции библиотеки и разархивируйте 3. Настройте среду Python. 4. Создайте виртуальную среду. 5. Включите виртуальную.
Глубокое обучение и компьютерное зрение
Как глубокое обучение учит компьютер видеть? Узнайте, как работают различные типы нейронных сетей, и как они используются для компьютерного зрения.
Предвзятость и проблемы компьютерного зрения
Доступность ImageNet одновременно помогла и нанесла ущерб столь влиятельной сегодня технологии. Это иллюстрирует популярную фразу в области дата-сайенс и ИИ: «мусор на входе, мусор на выходе».
Стремясь быстрее воспользоваться набором данных, исследователи не задумывались, откуда появились изображения, кто их разметил, почему они размечены таким образом, каких изображений или меток не хватает, и как это отразится на работе, не говоря уже о влиянии на сообщество и жизни людей. Лишь в 2019 году было выявлено, как много предвзятости и некорректных меток присутствует в датасете.
Исследователь ИИ Кейт Кроуфорд в своей книге «Атлас ИИ» отмечает, что внутри ImageNet встречались довольно оскорбительные и вредные категории, содержащие дискриминацию по полу, расе, возрасту или физическим возможностям. Сейчас уже ведется работа над тем, чтобы исключить предвзятость из датасета. Его критикуют и за нарушение приватности, поскольку люди, чьи снимки были включены, не давали согласие на использование и разметку фото.

Фото в тексте: marvent / Shutterstock
Предвзятость данных и алгоритмов — одна из ключевых проблем для ИИ в целом, но ее влияние особенно легко увидеть в некоторых приложениях, использующих компьютерное зрение.
Например, известно, что технология распознавания лиц позволяет неверно идентифицировать темнокожих, но ритейлеры все чаще используют ее в магазинах. Полиция США также широко ее применяет, что стало поводов для протестов и законодательного регулирования в нескольких городах и штатах.
Правила в целом являются новой проблемой для компьютерного зрения (и ИИ в целом). Ясно, что их будет больше (особенно если большая часть мира последует по пути Европейского союза), но пока точно неизвестно, как будут выглядеть такие правила. Поэтому исследователям и компаниям пока неясно, на что ориентироваться в данный момент.
Компьютерное зрение также сталкивается с некоторыми техническими проблемами. Его ограничивает оборудование, в том числе камеры и датчики. Кроме того, системы компьютерного зрения очень сложно масштабировать. И, как и все типы ИИ, они требуют огромных вычислительных мощностей (что дорого) и данных.
Как показывает вся история компьютерного зрения, хорошие данные, которые являются репрезентативными, беспристрастными и этично собранными, трудно найти — и невероятно утомительно размечать.
Кто использует компьютерное зрение?
Компьютерное зрение используется во всех отраслях промышленности для улучшения качества обслуживания потребителей, снижения затрат и повышения безопасности.
- Выберите отрасль
- Розничная торговля
- Производство
- Государственные организации
- Здравоохранение
- Защита и безопасность
- Страхование
Развитие механического зрения
Камера-обскура: в эпоху Возрождения в 1960-х годах появились некоторые камеры, использующие теорию камеры-обскуры.
Самой ранней попыткой людей в области машинного зрения должно быть создание изображений с помощью темного ящика.Принцип получения изображений - это визуализация точечных отверстий, аналогичная принципу визуализации биологических глаз. Позже этот тип камеры получил дальнейшее развитие, добавив линзовидные линзы, диафрагмы, светочувствительные материалы и т. Д., После нескольких поколений технологических инноваций он превратился в сегодняшние камеры.

Курс фокус
cs231n focuses on one of the most important problems of visual recognition – image classification
There is a number of visual recognition problemsthat are related to image classification:
Обнаружение объекта: используйте рамку изображения, чтобы отметить положение объекта на изображении и идентифицировать объект в рамке изображения
подписи к изображениям: используйте естественный язык для описания изображений
Convolutional Neural Networks (CNN) have become an important tool for object recognition
Маленькое Мин яблоко

Производство
На производстве компании используют компьютерное зрение для выявления дефектов продукта в режиме реального времени. По мере того, как продукты поступают с производственной линии, компьютер обрабатывает изображения или видео и отмечает десятки различных типов дефектов, даже на маленьких продуктах.
История CNN
В упомянутом выше соревновании ImageNetd с 2012 года выигрышными алгоритмами были глубокие нейронные сети. До этого все они основывались на выявлении признаков с последующим использованием SVM для классификации. В 2015 году команда Microsoft MSRA использовала даже 152 уровня nn.
Но CNN не был изобретен в 2012 году. Еще в 1998 году ЛеКун использовал эту нейронную сеть в Bell Labs для распознавания чисел на рукописных банкнотах.

Почему CNN и глубокие нейронные сети до сих пор не популярны? Есть две основные причины:
Во-первых, вычислительные возможности ЦП и ГП продолжают расти, особенно параллельные возможности ГП очень полезны для вычислений в нейронных сетях.
Второй - большие данные, независимо от того, какой это алгоритм машинного обучения, без достаточного количества данных его легко переобучить, и теперь существует достаточно большая база данных с метками.
Интеллектуальная рекомендация
Запрос разбивки на базы данных Oracle
Например, есть такая таблица Я хочу узнать данные 3-6 Также может быть так.

История компьютерного зрения
Первые эксперименты в области компьютерного зрения проводились в 1950-х годах. В них использовались некоторые из первых нейронных сетей для обнаружения краев объекта и для объединения простых объектов в категории – круги и квадраты. В 1970-х годах первое коммерческое использование компьютерного зрения заключалось в интерпретации печатного или рукописного текста с использованием оптического распознавания символов. Это продвижение было использовано для интерпретации письменного текста для невидящих людей.
По мере того, как в 1990-х годах Интернет развивался, делая множество изображений доступными онлайн для анализа, программы распознавания лиц процветали. Эти растущие объемы данных помогли машинам идентифицировать конкретных людей на фотографиях и видео.
Сегодня несколько факторов объединились, чтобы возродить компьютерное зрение:
Мобильные технологии со встроенными камерами наполнили мир фотографиями и видео.
Вычислительная мощность стала более доступной.
Оборудование для компьютерного зрения и анализа стало широко доступно.
Новые алгоритмы, такие как сверточные нейронные сети, могут использовать аппаратные и программные возможности.
Влияние этих достижений на область компьютерного зрения поразительно. Точность определения и классификации объектов менее чем за десятилетие возросла с 50 до 99%. Современные системы быстрее и корректнее, чем люди обнаруживают и реагируют на визуальные сигналы.
Функция-член swap в контейнере
Функция-член swap в контейнере В векторе контейнера пространство, занимаемое его памятью, только увеличивается, например, сначала выделяется 10 000 байт, а затем стираются следующие 9 999. Хотя сущест.

Читайте также: