
Какой файл называется непрерывным
Аннотация: В лекции рассмотрены следующие темы: зачем нужна архивация данных, создание архива, извлечение из архива, работа в программе WinRAR.
Смотреть на ИНТУИТ в качестве: низком | среднем | высоком
Процесс архивации файлов
Архивация информации производится посредством упаковки файлов, т.е. сжатия хранимой в них информации. При сжатии информации уменьшается ее избыточность и, соответственно, требуется меньший объем памяти для хранения. Методы сжатия различны, например, повтор символов заменяется коэффициентом их повторения. Поясним сказанное на примере. Рассмотрим следующую строчку: АAAAABBBCCCCCDD. Если стоит задача: "Запомнить строку", то, скорее всего, вы запомните ее как: "пять А, три B, пять С, две D", т. е. 5A3B5C2D. Здесь цифра обозначает, сколько раз повторяется в строке следующая за ней буква. Такая запись и есть аналог архива, а операция ее создания — упаковка. Соответственно, восстановление первоначального вида строки — это распаковка.
Архивация (упаковка) — помещение исходных файлов в архивный файл в сжатом виде. Разархивация (распаковка) — процесс восстановления файлов из архива точно в таком виде, какой они имели до загрузки в архив. Программы, осуществляющие упаковку и распаковку файлов, называются архиваторами .
При сжатии один или несколько файлов в сжатом виде помещаются в архивный файл (архив). Таким образом, цель упаковки файлов — обеспечение более компактного размещения информации. Кроме того, упаковка упрощает перенос данных с одного компьютера на другой, сокращает время копирования файлов на диски, позволяет защитить информацию от несанкционированного доступа, способствует защите от заражения компьютерными вирусами. Степень сжатия файлов зависит от используемой программы, метода сжатия и типа исходного файла. Наиболее хорошо сжимаются текстовые файлы, существенно меньше сжимаются файлы исполняемых программ. Большие по объему архивные файлы могут быть размещены в нескольких частях (томах). Такие архивы называются многотомными.
Наиболее популярные форматы архивов:
- ZIP — архивный формат, основанный на алгоритмах сжатия, предложенных израильскими математиками Лемпелем и Зивом. Он отличается приемлемой степенью сжатия информации и достаточно высоким быстродействием.
- RAR — разработан российским программистом Евгением Рошалем и позволяет получить размер сжатого файла гораздо меньший, чем ZIP, но ценой этого является более продолжительный процесс обработки архива.
- CAB — применяется в продуктах Microsoft как стандартный для упаковки файлов, причем его алгоритм является коммерческой тайной.
- TAR — получил наибольшее распространение в системах на базе Linux.
Архиватор WinRAR
WinRAR — один из самых популярных на сегодня архиваторов. Название программы образовано от слов Win (Windows) и RAR (Roshal ARchive). Автором программы является Евгений Рошал (Roshal). При запуске программы вы увидите ее главное окно (рис. 8.1 ).

Основные пиктограммы интерфейса таковы:
Поясним также некоторые пункты строки меню.
- Пункт меню Избранное создает список архивов для ускоренного перехода в любой из них. Добавить архивы в список можно командой Добавить к избранному.
- При помощи команды Параметры → Установки → Архивация можно указать папки для архивации и разархивации по умолчанию (рис. 8.2).

Возможности WinRAR
Упаковка информации в архив
Выберите файл или группу файлов и вызовите команду Добавить (рис. 8.3).
Все что до "Загрузочного блока" и включая его одинаково у всех ОС. Дальше начинаются различия.
Суперблок - содержит ключевые параметры файловой системы.
2.2 Реализация файлов
Основная проблема - сколько, и какие блоки диска принадлежат тому или иному файлу.
2.2.1 Непрерывные файлы
Выделяется каждому файлу последовательность соседних блоков.
5 непрерывных файлов на диске и состояние после удаления двух файлов
Преимущества такой системы:
Простота - нужно знать всего два числа, это номер первого блока и число блоков.
Высокая производительность - требуется только одна операция поиска, и файл может быть прочитан за одну операцию
Диск сильно фрагментируется
Сейчас такая запись почти не используется, только на CD-дисках и магнитных лентах.
2.2.2 Связные списки
Файлы хранятся в разных не последовательных блоках, и с помощью связных списков можно собрать последовательно файл.
Размещение файла в виде связного списка блоков диска
Номер следующего блока хранится в текущем блоке.
Нет потерь дискового пространства на фрагментацию
Нужно хранить информацию только о первом блоке
Уменьшение быстродействия - для того чтобы получить информацию о всех блоках надо перебрать все блоки.
Уменьшается размер блока из-за хранения служебной информации
2.2.3 Связные списки при помощи таблиц в памяти
Чтобы избежать два предыдущих недостатка, стали хранить всю информацию о блоках в специальной таблице загружаемой в память.
FAT (File Allocation Table) - таблица размещения файлов загружаемая в память.
Рассмотри предыдущий пример, но в виде таблицы.
Таблица размещения файлов
Здесь тоже надо собирать блоки по указателям, но работает быстрее, т.к. таблица загружена в память.
Основной не достаток этого метода - всю таблицу надо хранить в памяти. Например, для 20Гбайт диска, с блоком 1Кбайт (20 млн. блоков), потребовалась бы таблица в 80 Мбайт (при записи в таблице в 4 байта).
Такие таблицы используются в MS-DOS и Windows.
2.2.4 i - узлы
С каждым файлом связывается структура данных, называемая i-узлом (index-node- индекс узел), содержащие атрибуты файла и адреса всех блоков файла.
Быстродействие - имея i-узел можно получить информацию о всех блоках файла, не надо собирать указатели.
Меньший объем, занимаемый в памяти. В память нужно загружать только те узлы, файлы которых используются.
Если каждому файлу выделять фиксированное количество адресов на диске, то со временем этого может не хватить, поэтому последняя запись в узле является указателем на дополнительный блок адресов и т.д..
Такие узлы используются в UNIX.
2. 3 Реализация каталогов
При открытии файла используется имя пути, чтобы найти запись в каталоге. Запись в каталоге указывает на адреса блоков диска.
В зависимости от системы это может быть:
дисковый адрес всего файла (для непрерывных файлов)
номер первого блока (связные списки)
Одна из основных задач каталоговой системы преобразование ASCII-имени в информацию, необходимую для нахождения данных.
Также она хранит атрибуты файлов.
Варианты хранения атрибутов:
В каталоговой записи (MS-DOS)
Варианты реализации каталогов
2. 3.1 Реализация длинных имен файлов
Раньше операционные системы использовали короткие имена файлов, MS-DOS до 8 символов, в UNIX Version 7 до 14 символов. Теперь используются более длинные имена файлов (до 255 символов и больше).
Методы реализации длинных имен файлов:
Просто выделить место под длинные имена, увеличив записи каталога. Но это займет много места, большинство имен все же меньше 255.
Применить записи с фиксированной частью (атрибуты) и динамической записью (имя файла).
Второй метод можно реализовать двумя методами:
Имена записываются сразу после заголовка (длина записи и атрибутов)
Имена записываются в конце каталога после всех заголовков (указателя на файл и атрибутов)
Реализация длинных имен файлов
2. 3.2 Ускорение поиска файлов
Если каталог очень большой (несколько тысяч файлов), последовательное чтение каталога мало эффективно.
2. 3.2.1 Использование хэш-таблицы для ускорения поиска файла.
Алгоритм записи файла:
Создается хэш-таблица в начале каталога, с размером n (n записей).
Для каждого имени файла применяется хэш-функция, такая, чтобы при хэшировании получалось число от 0 до n-1.
Исследуется элемент таблицы соответствующий хэш-коду.
Если элемент не используется, туда помещается указатель на описатель файла (описатели размещены вслед за хэш-таблицей).
Если используется, то создается связный список, объединяющие все описатели файлов с одинаковым хэш-кодом.
Алгоритм поиска файла:
Имя файла хэшируется
По хэш-коду определяется элемент таблицы
Затем проверяются все описатели файла из связного списка и сравниваются с искомым именем файла
Если имени файла в связном списке нет, это значит, что файла нет в каталоге.
Такой метод очень сложен в реализации, поэтому используется в тех системах, в которых ожидается, что каталоги будут содержать тысячи файлов.
2. 3.2.2 Использование кэширования результатов поиска файлов для ускорения поиска файла.
Алгоритм поиска файла:
Проверяется, нет ли имени файла в кэше
Если нет, то ищется в каталоге, если есть, то берется из кэша
Такой способ дает ускорение только при частом использовании одних и тех же файлов.
2.4 Совместно используемые файлы
Иногда нужно чтобы файл присутствовал в разных каталогах.
Link (связь, ссылка) - с ее помощью обеспечивается присутствие файла в разных каталогах.
А - совместно используемый файл.
Такая файловая система называется ориентированный ациклический граф (DAG, Directed Acyclic Graph).
Возникает проблема, если дисковые адреса содержатся в самих каталоговых записях, тогда при добавлении новых данных к совместно используемому файлу новые блоки будут числится только в каталоге того пользователя, который производил эти изменения в файле.
Есть два решения этой проблемы:
Использование i-узлов, в каталогах хранится только указатель на i-узел. Такие ссылки называются жесткими ссылками.
При создании ссылки, в каталоге создавать реальный Link-файл, новый файл содержит имя пути к файлу, с которым он связан. Такие ссылки называются символьными ссылками.
2.4.1 Жесткие ссылки
Может возникнуть проблема, если владелец файла удалит его (и i-узел тоже), то указатель, каталога содержащего ссылку, будет указывать на не существующий i-узел. Потом может появиться i-узел с тем же номером, а значит, ссылка будет указывать на не существующий файл.
Поэтому в этом случае при удалении файла i-узел лучше не удалять.
Файл будет удален только после того, как счетчик будет равен 0.
Иллюстрация проблемы, которая может возникнуть
2.4.2 Символьные ссылки
Удаление файла не влияет на ссылку, просто по ссылке будет не возможно найти файл (путь будет не верен).
Удаление ссылки тоже никак не скажется на файле.
Но возникают накладные расходы, чтобы получить доступ к i-узлу, должны быть проделаны следующие шаги:
Прочитать файл-ссылку (содержащий путь)
Пройти по всему этому путь, открывая каталог за каталогом
2.5 Организация дискового пространства
2.5.1 Размер блока
Если принято решение хранить файл в блоках, то возникает вопрос о размере этих блоков.
Есть две крайности:
Большие блоки - например, 1Мбайт, то файл даже 1 байт займет целый блок в 1Мбайт.
Маленькие блоки - чтение файла состоящего из большого числа блоков будет медленным.
Скорости чтения/записи и эффективность использования диска,
в системе с файла одинакового размера 2 Кбайта.
В UNIX системах размер блока фиксирован, и, как правило, равен от 1Кбайта до 4Кбайт.
В MS-DOS размер блока может быть от 512 до 32 Кбайт в зависимости от размера диска, поэтому FAT16 использовать на дисках больше 500 Мбайт не эффективно.
В NTFS размер блока фиксирован (от 512байт до 64 Кбайт), как правило, равен примерно 2Кбайтам (от 512байт до 64 Кбайт).
2.5.2 Учет свободных блоков
Основные два способа учета свободных блоков :
Связной список блоков диска, в каждом блоке содержится номеров свободных блоков столько, сколько вмешается в блок. Часто для списка резервируется нужное число блоков в начале диска.
Недостатки:
- Требует больше места на диске, если номер блока 32-разрядный, требуется 32бита для номера
- Излишние операции ввода/вывода, т.к. в памяти не хранятся все блоки, а, например, только один блок
Битовый массив (бит-карта) - для каждого блока требуется один бит.
Основные два способа учета свободных блоков
2.5.3 Дисковые квоты
Чтобы ограничить пользователя, существует механизм квот.
Два вида лимитов:
Жесткие - превышены быть не могут
Гибкие - могут быть превышены, но при выходе пользователь должен удалить лишние файлы. Если он не удалил, то при следующем входе получит предупреждение, после получения нескольких предупреждений он блокируется.
Наиболее распространенные квоты:
Объем использования диска
Количество открытых файлов
2.6 Надежность файловой системы
2.6.1 Резервное копирование
Случаи, для которых необходимо резервное копирование:
Аварийные ситуации, приводящие к потере данных на диске
Случайное удаление или программная порча файлов
Основные принципы создания резервных копий:
Создавать несколько копий - ежедневные, еженедельные, ежемесячные, ежеквартальные.
Как правило, необходимо сохранять не весь диск, а только выборочные каталоги.
Применять инкрементные резервные копии - сохраняются только измененные файлы
Сжимать резервные копии для экономии места
Фиксировать систему при создании резервной копии, чтобы вовремя резервирования система не менялась.
Хранить резервные копии в защищенном месте, не доступном для посторонних.
Существует две стратегии:
Физическая архивация - поблочное копирование диска (копируются блоки, а не файлы)
Недостатки:
- копирование пустых блоков
- проблемы с дефектными блоками
- не возможно применять инкрементное копирование
- не возможно копировать отдельные каталоги и файлы
Преимущества:
- высокая скорость копирования
- простота реализации
Логическая архивация - работает с файлами и каталогами. Применяется чаще физической.
2.6.2 Непротиворечивость файловой системы
Если в системе произойдет сбой, прежде чем модифицированный блок будет записан, файловая система может попасть в противоречивое состояние. Особенно если это блок i-узла, каталога или списка свободных блоков.
В большинстве файловых систем есть специальная программа, проверяющая непротиворечивость системы.
В Windows - scandisk.
Если произошел сбой, то во время загрузки они проверяют файловую систему (если файловая система журналируемая, такая проверка не требуется).
Журналируемая файловая система - операции выполняются в виде транзакций, если транзакция не завершена, то во время загрузки происходит откат в системе назад.
Два типа проверки на непротиворечивость системы:
проверка блоков - проверяется дублирование блоков в файле или в списке свободных блоков. Потом проверяется, нет ли блока файла, который еще присутствует в списке свободных блоков. Если блока нет в занятых и в незанятых, то блок считается не достающем (уменьшается место на диске), такие блоки добавляются к свободным. Также блок может оказаться в двух файлах.
проверка файлов - в первую очередь проверяется каталоговая структура. Файл может оказаться; либо в нескольких каталогах, либо не в одном каталоге (уменьшается место на диске).
2.7 Производительность файловой системы
Так как дисковая память достаточно медленная. Приходится использовать методы повышающие производительность.
2.7.1 Кэширование
Блочный кэш (буферный кэш) - набор блоков хранящиеся в памяти, но логически принадлежащие диску.
Перехватываются все запросы чтения к диску, и проверяется наличие требуемых блоков в кэше.
Ситуация схожа со страничной организацией памяти, можно применять те же алгоритмы.
Нужно чтобы измененные блоки периодически записывались на диск.
В UNIX это выполняет демон update (вызывая системный вызов sync).
В MS-DOS модифицированные блоки сразу записываются на диск (сквозное кэширование).
2.7.2 Опережающее чтение блока
Если файлы считываются последовательно, и когда получен к-блок, можно считать блок к+1 (если его нет в памяти). Что увеличивает быстродействие.
2.7.3 Снижение времени перемещения блока головок
Если записывать, наиболее часто запрашиваемые файлы, рядом (соседние сектора или дорожки), то перемещение головок будет меньше
В случае использования i-узлов если они расположены в начале диска, то быстродействие будет уменьшено, т.к. сначала головка считает i-узел (в начале диска), а потом будет считывать данные (где-то на диске). Если располагать i-узлы поближе к данным, то можно увеличить скорость доступа.
Передача информации производится с помощью сигналов, а самим сигналом является изменение некоторой характеристики носителя с течением времени. При этом в зависимости от особенностей изменения этой характеристики (т.е. параметра сигнала) с течением времени выделяют два типа сигналов: непрерывные и дискретные .
Сигнал называется непрерывным (или аналоговым), если его параметр может принимать любое значение в пределах некоторого интервала
Если обозначить Z- значение параметра сигнала, at- время, то зависимость Z(t) будет непрерывной функцией (рис.1.2,а).
Рис. 1.2. Непрерывные (а) и дискретные (б) сигналы
Примерами непрерывных сигналов являются речь и музыка, изображение, показание термометра (параметр сигнала - высота столба спирта или ртути - имеет непрерывный ряд значений) и пр.
Сигнал называется дискретным, если его параметр может принимать конечное число значений в пределах некоторого интервала.
Пример дискретных сигналов представлен на рис. 1.2,б. Как следует из определения, дискретные сигналы могут быть описаны дискретным и конечным множеством значений параметров . Примерами устройств, использующих дискретные сигналы, являются часы (электронные и механические), цифровые измерительные приборы, книги, табло и пр.
Принципиальным и важнейшим различием непрерывных и дискретных сигналов является то, что дискретные сигналы можно обозначить, т.е. приписать каждому из конечного чисел возможные значения сигнала знак, который будет отличать данный сигнал от другого.
Знак - это элемент некоторого конечного множества отличных друг от друга сущностей.
Вся совокупность знаков, используемых для представления дискретной информации, называется набором знаков.
Таким образом, набор есть дискретное множество знаков.
Набор знаков, в котором установлен порядок их следования, называется алфавитом.
Следовательно, алфавит - это упорядоченная совокупность знаков. Порядок следования знаков в алфавите называется лексикографическим. Благодаря этому порядку между знаками устанавливаются отношения «больше-меньше»: для двух знаков ξ и ψ принимается, что ξ < ψ, если порядковый номер у ξ, в алфавите меньше, чем у ψ.
Примером алфавита может служить совокупность арабских цифр 0,1. 9 - с его помощью можно записать любое целое число в системах счисления от двоичной до десятичной. Если к этому алфавиту добавить знаки «+» и «-», то сформируется набор знаков, применимый для записи любого целого числа, как положительного, так и отрицательного; правда, этот набор нельзя считать алфавитом, поскольку в нем не определен порядок следования знаков. Наконец, если добавить знак разделителя разрядов («.» или «,»), то такой алфавит позволит записать любое вещественное число.
Знаки, используемые для обозначения фонем человеческого языка, называются буквами, а их совокупность - алфавитом языка.
Сами по себе знак или буква не несут никакого смыслового содержания. Однако такое содержание им может быть приписано - в этом случае знак будет называться символом. (Например, массу в физике принято обозначать буквой m - следовательно, m является символом физической величины «масса» в формулах. Другим примером символов могут служить пиктограммы, обозначающие в компьютерных программах объекты или действия).
Таким образом, понятия «знак», «буква» и «символ» нельзя считать тождественными, (хотя весьма часто различия между ними не проводят, поэтому в информатике существуют понятия «символьная переменная», «кодировка символов алфавита», «символьная информация» - во всех приведенных примерах вместо термина «символьный» корректнее было бы использовать «знаковый» или «буквенный».)
Рис. 1.3. Варианты преобразований
Рассмотрим общий подход к преобразованию типа N → D. С математической точки зрения перевод сигнала из аналоговой формы в дискретную означает замену описывающей его непрерывной функции времени Z(t) на некотором отрезке [t1, t2] конечным множеством (массивом) i, ti> (i = 0. n, где n - количество точек разбиения временного интервала). Подобное преобразование называется дискретизацией непрерывного сигнала и осуществляется посредством двух операций: развертки по времени и квантования по величине сигнала.
Развертка по времени состоит в том, что наблюдение за значением величины Z производится не непрерывно, а лишь в определенные моменты времени с интервалом Δt:
Квантование по величине - это отображение вещественных значений параметра сигнала в конечное множество чисел, кратных некоторой постоянной величине - шагу квантования (ΔZ).
Рис. 1.4. Дискретизация аналогового сигнала за счет операций развертки по времени и квантования по величине
При такой замене довольно очевидно, что чем меньше n (больше Δt, тем меньше число узлов, но и точность замены Z(t) значениями Zi, будет меньшей. Другими словами, при дискретизации может происходить потеря части информации, связанной с особенностями функции Z(t). На первый взгляд кажется, что увеличением количества точек n можно улучшить соответствие между получаемым массивом и исходной функцией, однако полностью избежать потерь информации все равно не удастся, поскольку n - величина конечная.
Ответом на эти сомнения служит так называемая теорема отсчетов, доказанная в 1933г. В. А. Котельниковым (по этой причине ее иногда называют его именем), значение которой для решения проблем передачи информации было осознано лишь в 1948г. после работ К. Шеннона. Теорема, которую примем без доказательства, но результаты будем в дальнейшем использовать, гласит:
Непрерывный сигнал можно полностью отобразить и точно воссоздать по последовательности измерений или отсчетов величины этого сигнала через одинаковые интервалы времени, меньшие или равные половине периода максимальной частоты, имеющейся в сигнале.
Комментарии к теореме:
Теорема касается только тех линий связи, в которых для передачи используются колебательные или волновые процессы.
Любое подобное устройство использует не весь спектр частот колебаний, а лишь какую-то его часть; например, в телефонных линиях используются колебания с частотами от 300 Гц до 3400 Гц. Согласно теореме отсчетов определяющим является значение верхней границы частоты - обозначим его Vm.
Смысл теоремы в том, что дискретизация не приведет к потере информации и по дискретным сигналам можно будет полностью восстановить исходный аналоговый сигнал, если развертка по времени выполнена в соответствии со следующим соотношением:
Можно перефразировать теорему отсчетов:
Развертка по времени может быть осуществлена без потери информации, связанной с особенностями непрерывного (аналогового) сигнала, если шаг развертки не будет превышать Δt, определяемый в соответствии с (1.2).
Например, для точной передачи речевого сигнала с частотой до Vm = 4000 Гц при дискретной записи должно производиться не менее 8000 отсчетов в секунду; в телевизионном сигнале Vm ≈ 4 МГц, следовательно, для его точной передачи потребуется около 8000000 отсчетов в секунду.
Однако, помимо временной развертки, дискретизация имеет и другую составляющую - квантование. Выясним, как определяется шаг квантования ΔZ?
Выбор шага развертки по времени и квантования по величине сигнала лежат в основе оцифровки звука и изображения. Примерами устройств, в которых происходят такие преобразования, являются сканер, модем, устройства для цифровой записи звука и изображения, лазерный проигрыватель, графопостроитель. Термины «цифровая запись», «цифровой сигнал» следует понимать как дискретное представление с применением двоичного цифрового алфавита.
Таким образом, преобразование сигналов типа N → D, как и обратное D → N, может осуществляться без потери, содержащейся в них информации.
Преобразование типа D1 → D2 состоит в переходе при представлении сигналов от одного алфавита к другому - такая операция носит название перекодировка и может осуществляться без потерь. Примерами ситуаций, в которых осуществляются подобные преобразования, могут быть: запись-считывание с компьютерных носителей информации; шифровка и дешифровка текста; вычисления на калькуляторе.
• простоту и, как следствие, надежность и относительную дешевизну устройств по обработке информации;
• точность обработки информации, которая определяется количеством обрабатывающих элементов и не зависит от точности их изготовления;
Информация, порождаемая и существующая в природе, связана с материальным миром - это размеры, форма, цвет и другие физические, химические и прочие характеристики и свойства объектов. Данная информация передается посредством физических и иных взаимодействий и процессов. Эту природную информацию можно считать хаотической и неупорядоченной, поскольку никем и ничем не регулируется ее появление, существование, использование. Чаще всего она непрерывна по форме представления. Напротив, дискретная информация - это информация, прошедшая обработку - отбор, упорядочение, преобразование; она предназначена для дальнейшего применения человеком или техническим устройством. Другими словами, дискретная - это уже частично осмысленная информация, т.е. имеющая для кого-то смысл и значение и, как следствие, более высокий (с точки зрения пользы) статус, нежели непрерывная.
По стандарту диски могут быть разбиты на логические разделы, но мы будем рассматривать диски с одним разделом.
Как вы знаете из предыдущих лекций: блоки записываются последовательно; по спирали; сектора по 2352 байта.
Порядок записи информации:
Каждый CD-ROM начинается с 16 блоков (неопределенных ISO 9660), эта область может быть использована для размещения загрузчика ОС или для других целей.
Дальше один блок основного описателя тома - хранит общую информацию о CD-ROM, в нее входит:
- идентификатор системы (32байта)
- идентификатор тома (32байта)
- идентификатор издателя (128байт)
- идентификатор лица, подготовившего данные (128байт)
- имена трех файлов, которые могут содержать краткий обзор, авторские права и библиографическая информация.
- ключевые слова: размер логического блока (как правило 2048, но могут быть 4096, 8192 и т.д.); количество блоков; дата создания; дата окончания срока службы диска.
- описатель корневого каталога (номер блока содержащего каталог).
Могут быть дополнительные описатели тома, подобные основному.
Каталоговая запись стандарта ISO 9660.
Каталоговая запись стандарта ISO 9660.
Расположение файла - номер начального блока, т.к. блоки располагаются последовательно.
L - длина имени файла в байтах
Имя файла - 8 символов, 3 символа расширения (из-за совместимости с MS-DOS). Имя файла может встречаться несколько раз, но с разными номерами версий.
Sys - поле System use (используется различными ОС для своих расширений )
Порядок каталоговых записей:
Описатель самого каталога (аналог ".")
Ссылка на родительский каталог (аналог "..")
Остальные записи (записи файлов) в алфавитном порядке
Количество каталоговых записей не ограничено, но ограничено количество вложенности каталогов - 8.
В стандарте ISO 9660 определены три уровня ограничений:
имена файлов и каталогов до 31 символа
- имена файлов и каталогов до 31 символа
- файлы могут быть не непрерывными, состоять из разделов
3.1.2 Рок-ридж расширения для UNIX
Это расширение было создано, чтобы файловая система UNIX была представлена на CD-ROM.
Для этого используется поле System use.
Расширения содержат следующие поля:
PX - атрибуты POSIX (стандартные биты rwxrwxrwx, (чтение, запись, запуск) (владелец, группа, все) )
PN - старший и младший номер устройств (чтобы можно было записать каталог /dev, который содержит устройства)
SL - символьная связь
NM - альтернативное имя, позволяет использовать произвольные имена, без ограничений
CL - расположение дочернего узла (чтобы обойти ограничение на вложенность каталогов)
PL - расположение дочернего узла (чтобы обойти ограничение на вложенность каталогов)
RE - перераспределение (чтобы обойти ограничение на вложенность каталогов)
TF - временные штампы (время создания, последнее изменение , последний доступ)
3.1.3 Joliet расширения для Windows
Это расширение было создано, чтобы файловая система ОС Windows 95 была представлена на CD-ROM.
Для этого используется поле System use.
Расширения содержат следующие поля:
Длинные имена файлов (до 64 символов)
Набор символов Unicode (поддержка различных языков)
Преодоление ограничений на вложенность каталогов
Имена каталогов с расширениями
3.1.4 Romeo расширения для Windows
Стандарт Romeo предоставляет другую возможность записи файлов с длинными именами на компакт-диск. Длина имени может составлять 128 символов, однако использование кодировки Unicode не предусмотрено. Альтернативные имена в этом стандарте не создаются, поэтому программы MS-DOS не смогут прочитать файлы с такого диска.
Вы можете выбрать стандарт Romeo только в том случае, если диск предназначен для чтения приложениями Windows 95 и Windows NT.
3.1.5 HFS расширения для Macintosh
Иерархическая файловая система компьютеров Macintosh, не совместима ни с какими другими файловыми системами и называется Hierarchical File System (HFS).
3.1.6 Файловая система UDF (Universal Disk Format)
Изначально созданная для DVD, с версии 1.50 добавили поддержку CD-RW и CD-R.
Эта файловая система позволяет дописывать диски, а также поддерживает большие размеры файлов и длинные имена файлов.
3.2 Файловая система CP/M
CP/M (Control Program for Microcomputers) - операционная система, предшественник MS-DOS.
В ее файловой системе только один каталог, с фиксированными записями по 32 байта.
Имена файлов - 8+3 символов верхнего регистра.
После каждой перезагрузки рассчитывается битовый массив занятых и свободных блоков. Массив находится постоянно в памяти (для 180Кбайтного диска 23 байта массива). После завершения работы, он не записывается на диск.
Каталоговая запись CP/M
Видно, что максимальный размер файла 16Кбайт (16*1Кбайт).
Для файлов размером от 16 до 32 Кбайт можно использовать две записи. Для до 48 Кбайт три записи и т.д.
Порядковый номер записи хранится в поле экстент.
Код пользователя - каждый пользователь мог работать только со своими файлами.
Порядок чтения файлов:
Файл открывается системным вызовом open
Читается каталоговая запись, из которой получает информацию о всех блоках.
Вызывается системный вызов read
3.2 Файловая система MS-DOS (FAT-12,16,32)
В первых версиях был только один каталог (MS-DOS 1.0).
С версии MS-DOS 2.0 применили иерархическую структуру.
Каталоговые записи, фиксированны по 32 байта.
Имена файлов - 8+3 символов верхнего регистра.
Порядок чтения файлов:
Файл открывается системным вызовом open, которому указывается путь к файлу (может быть абсолютным и относительным).
Файловая система открывает каталоги (согласно пути), считывает последний каталог в память.
Ищет описатель файла.
Читается дескриптор файла, из которого получает информацию о всех блоках.
Вызывается системный вызов read
Каталоговая запись MS-DOS, обратите внимание на пустые 10 байт, они будут задействованы в Windows 98
Атрибут архивный нужен для программ резервного копирования, по нему они определяют надо копировать файл или нет.
Поле время (16 разрядов) разбивается на три подполя:
секунды - 5бит (2^5=32 поэтому хранятся с точностью до 2-х секунд)
Поле даты (16 разрядов) разбивается на три подполя:
год - 7бит (начинается с 1980г, т.е. максимальный 2107г.)
Теоретически размер файлов может быть до 4Гбайт (32 разряда).
Все блоки файла в записи не хранятся, а только первый блок. Этот номер используется в качестве индекса для 64К (для FAT-16) элементов FAT-таблицы, хранящейся в оперативной памяти.
В зависимости от количества блоков на диске в системе MS-DOS применяется три версии файловой системы FAT:
FAT-32 - для адреса используются только 28 бит, поэтому правильнее назвать FAT-28
Размер блока (кластера) должен быть кратным 512 байт.
В первой версии MS-DOS использовалась FAT-12 с 512 байтовыми блоками, поэтому максимальный размер раздела мог достигать 2Мбайта (2^12*512байта).
С увеличением дисков, этого стало не хватать, стали увеличивать размер блоков 1,2 и 4 Кбайта (2^12) (при этом эффективность использования диска падает).
FAT-12 до сих пор применяется для гибких дисков.
16-разрядные дисковые указатели
Размеры кластеров 512, 1, 2, 4, 8, 16 и 32Кбайт (2^15)
Таблица постоянно занимала в памяти 128 Кбайт.
Максимальный размер раздела диска мог достигать 2Гбайта (2^16*32Кбайта).
Причем кластер в 32 Кбайта для файлов со средним размером в 1Кбайт, не эффективен.
Размеры кластеров 512, 1, 2, 4, 8, 16 и 32Кбайт
Максимальный размер раздела диска мог бы достигать 2^28*2^15, но здесь уже вступает другое ограничение - 512 байтные сектора адресуются 32-разрядным числом, а это 2^32*2^9, т.е. 2 Тбайта.
Максимальный размер раздела для различных размеров кластеров
Размер кластера, Кбайт
Из таблицы видно, что FAT-16 использовать не эффективно уже при разделах в 256 Мбайт, учитывая, что средний размер файла 1Кбайт.
3.2.4 Расширение Windows 98 для FAT-32
Для расширения были задействованы 10 свободных бит.
Формат каталоговой записи в системе FAT-32 с расширениями для Windows 98
Пять добавленных полей:
NT - предназначено для совместимости с Windows.
Sec - дополнение к старому полю время, позволяет хранить время с точностью до секунды (было 2 секунды)
Дата и время создания файла (Creation time)
Дата (но не время) последнего доступа (Last access)
Для хранения номера блока выделено еще 2 байта (16 бит), т.к. номера блоков стали 32-разрядные.
Основная надстройка над FAT-32, это длинные имена файлов.
Для каждого файла стали присваивать два имени:
Короткое 8+3 для совместимости с MS-DOS
Длинное имя файла, в формате Unicode
Доступ к файлу может быть получен по любому имени.
Если файлу дано длинное имя (или используются пробелы), то система делает следующие шаги:
берет первые шесть символов
преобразуются в верхний регистр ASCII, удаляются пробелы, лишние точки, некоторые символы преобразуются в "_"
добавляется суффикс ~1
если такое имя есть, то используется суффикс ~2 и т.д.
Короткие имена хранятся в в обычном дескрипторе файла.
Длинные имена хранятся в дополнительных каталоговых записях, идущих перед основным описателем файла. Каждая такая запись содержит 13 символов формата Unicode (для символа Unicode нужно два байта).
Формат каталогов записи с фрагментом длинного имени файла в Windows 98
Поле "Атрибуты" позволяет отличить фрагмент длинного имени (значение 0х0F) от дескриптора файла. Старые программы MS-DOS каталоговые записи со значением поля атрибутов 0х0F, просто игнорируют.
Последовательность - порядковый номер в последовательности фрагментов.
Длина имени файла ограничена 260 символами не из-за порядкового номера (1 байт), для номера используются только 6 бит 6х13=819 символов.
Контрольная сумма нужна для выявления ошибок, т.к. файл с длинным именем может удалить MS-DOS и создать новый, и тогда останутся не удаленные записи, которые "прилипнут" к новому файлу. Т.к. это поле один байт, есть вероятность 1/256 что Windows 98 не заметит подмены.
3.3 Файловая система NTFS
Файловая система NTFS была разработана для Windows NT.
64-разрядные адреса, т.е. теоретически может поддерживать 2^64*2^16 байт (1 208 925 819 Пбайт~1Йбайт(2 80 )).
Размеры блока (кластера) от 512байт до 64 Кбайт, для большинства используется 4Кбайта.
Поддержка больших файлов.
Имена файлов ограничены 255 символами Unicode.
Длина пути ограничивается 32 767 (2^15) символами Unicode.
Имена чувствительны к регистру, my.txt и MY.TXT это разные файлы (но из-за Win32 API использовать нельзя), это заложено на будущее.
Журналируемая файловая система, т.е. не попадет в противоречивое состояние после сбоев.
Контроль доступа к файлам и каталогам.
Поддержка жестких и символических ссылок.
Поддержка сжатия и шифрования файлов.
Поддержка дисковых квот.
Главная файловая таблица MFT (Master File Table) - главная структура данных в каждом томе, записи фиксированные по 1Кбайту. Каждая запись описывает один каталог или файл. Для больших файлов могут использоваться несколько записей, первая запись называется - базовой записью.
MFT представляет собой обычный файл (размером до 2^48 записей), который может располагаться в любом месте на диске.
Главная файловая таблица MFT, каждая запись ссылается на файл или каталог.
Первые 16 записей MFT зарезервированы для файлов метаданных. Каждая запись описывает нормальный файл, имена этих файлов начинаются с символа "$".
Каждая запись представляет собой последовательность пар (заголовок атрибута, значение).
Некоторые записи метаданных в MFT:
0) Первая запись описывает сам файл MFT, и содержит все блоки файла MFT. Номер первого блока файла MFT содержится в загрузочном блоке.
1) Дубликат файла MFT, резервная копия.
2) Журнал для восстановления, например, перед созданием, удалением каталога делается запись в журнал. Система не попадет в противоречивое состояние после сбоев.
3) Информация о томе (размер, метка и версия)
4) Определяются атрибуты для MFT записей.
6) Битовый массив использованных блоков - для учета свободного места на диске
7) Указывает на файл начальной загрузки
Атрибуты, используемые в записях MFT:
Стандартная информация - флаговые биты (только чтение, архивный), временные штампы и т.д.
Имя файла - имя файла в кодировке Unicode, файлы могут повторятся в формате MS-DOS 8+3.
Список атрибутов - расположение дополнительных записей MFT
Идентификатор объекта - 64-разрядный идентификатор файла, уникальный для данного тома.
Точка повторного анализа - используется для символьных ссылок и монтирования устройств.
Корневой индекс - используется для каталогов
Размещение индекса - используется для очень больших каталогов
Битовый массив - используется для очень больших каталогов
Поток данных утилиты регистрации - используется для шифрования
Данные - поточные данные, может повторяться, используется для хранения самого файла. За заголовком следует список дисковых адресов, определяющий положение файла на диске, если файл очень маленький (несколько сотен байт), то следует сам файл (такой файл называется - непосредственный файл).
Как привило, все данные файла не помещаются в запись MFT.
Дисковые блоки файлам назначаются по возможности в виде серий последовательных блоков (сегментов файлов). В идеале файл должен быть записан в одну серию (не фрагментированный файл), файл, состоящий из n блоков, может быть записан от 1 до n серий.
Запись MFT для 9-блочного файла, состоящего из трех сегментов (серий).
Вся запись помещается в одну запись MFT (файл не сильно фрагментирован).
Заголовок содержит количество блоков (9 блоков).
Каждая серия записывается в виде пары, дисковый адрес - количество блоков (20-4, 64-2, 80-3).
Каждая пара, при отсутствие сжатия, это два 64-разрядные числа (16 байт на пару).
Многие адреса содержат большое количество нулей, сжатие делается за счет убирания нулей в старших байтах. В результате для пары требуется чаще всего 4байта.
Если файл сильно фрагментирован, требуется несколько записей MFT.
Три записи MFT для сильно фрагментированного файла.
В первой записи указывается индексы на дополнительные записи.
Может потребоваться очень много индексов MFT, так что индексы не поместятся в запись. В этом случае список хранится не в MFT, а в файле.
Запись MFT для небольшого каталога
Поиск файла в каталоге по имени состоит в последовательном переборе имен файлов.
Для больших каталогов используется другой формат. Используется дерево В+, обеспечивающее поиск в алфавитном порядке.
3.3.1 Поиск файла по имени
При создании файла, программа обращается к библиотечной процедуре
Этот вызов попадает в совместно используемую библиотеку уровня пользователя kernel32.dll, где \??\ помещается перед именем файла, и получается строка:
Это имя пути передается системному вызову NtFileCreate в качестве параметра.
Этапы поиска файла C:\windows\readmy.txt
3.3.2 Сжатие файлов
Если файл помечен как сжатый, то система автоматически сжимает при записи, а при чтении происходит декомпрессия.
Берутся для изучения первые 16 блоков файла (не зависимо от сегментов файла).
При меняется к ним алгоритм сжатия.
Если полученные данные можно записать хотя бы в 15 блоков, они записываются в сжатом виде.
Если их можно записать только в 16 блоков, то они записываются в несжатом виде.
Алгоритм повторяется для следующих 16 блоков.
Запись MFT для предыдущего файла.
Как видно из рисунка, сжатие приводит к сильной фрагментации.
Чтобы прочитать сжатый блок системе придется распаковать весь сегмент. Поэтому сжатие применяют к 16 блокам, если увеличить количество блоков, уменьшится производительность (но возрастет эффективность сжатия).
3.3.3 Шифрование файлов
Любую информацию, если она не зашифрована, можно прочитать, получив доступ. Поэтому самая надежная защита информации от несанкционированного доступа - шифрование.
Даже если у вас украдут винчестер, прочесть данные не смогут (большинство не сможет).
Если файл помечен как шифрованный, то система автоматически шифрует при записи, а при чтении происходит дешифрация.
Шифрование и дешифрование выполняет не сама NTFS, а специальный драйвер EFS (Encrypting File System).
Каждый блок шифруется отдельно.
Физическая организация выделяет способ размещения файлов на диске и учет соответствия блоков диска файлам. Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.
Наиболее часто используются следующие схемы размещения файлов:
- непрерывное размещение (непрерывные файлы);
- сводный список блоков (кластеров) файла;
- сводный список индексов блоков (кластеров) файла;
- перечень номеров блоков (кластеров) файла в структурах, называемых i-узлами (index-node – индекс-узел).
Простейший вариант физической организации – непрерывное размещение в наборе соседних кластеров (рис. 7.15a). Достоинство этой схемы – высокая скорость доступа и минимальный объем адресной информации, поскольку достаточно хранить номер первого кластера и объем файла. Размер файла при такой организации не ограничивается.
Однако у этой схемы имеется серьезный недостаток – фрагментация, возрастающая по мере удаления и записи файлов. Кроме того, возникает вопрос, какого размера область нужно выделить файлу, если при каждой модификации он может увеличить свой размер.
И все-таки есть ситуации, в которых непрерывные файлы могут эффективно использоваться и действительно широко применяются – на компакт-дисках. Здесь все размеры файлов заранее известны и не могут меняться.
Второй метод размещения файлов состоит в представлении файла в виде связного списка кластеров дисковой памяти (рис. 7.15б). Первое слово каждого кластера используется как указатель на следующий кластер . В этом случае адресная информация минимальна, поскольку расположение файла задается номером его первого кластера.
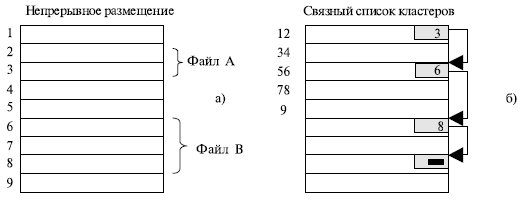
Кроме того, отсутствует фрагментация на уровне кластеров, а файл легко может изменять размер наращиванием или удалением цепочки кластеров. Однако доступ к такому файлу может оказаться медленным, так как для получения доступа к кластеру n операционная система должна прочитать первые n-1 кластеры. Кроме того, размер кластера уменьшается на несколько байтов, требуемых для хранения. Указателю это не очень важно, но многие программы читают и пишут блоками, кратными степени двойки.
Оба недостатка предыдущей схемы организации файлов могут быть устранены, если указатели на следующие кластеры хранить в отдельной таблице, загружаемой в память . Таким образом, образуется связный список не самих блоков (кластеров) файла, а индексов, указывающих на эти блоки (рис. 7.16).
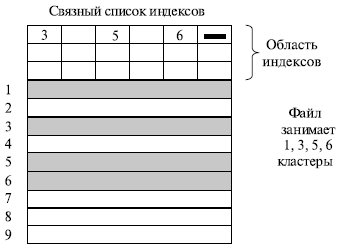
Такая таблица , называемая FAT -таблицей (File Allocation Table ), используется в файловых системах MS- DOS и Windows ( FAT 16 и FAT 32). Файлу выделяется память на диске в виде связного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. С каждым кластером диска связывается индекс . Индексы располагаются в FAT -таблице в отдельной области диска. Когда память свободна, все индексы равны нулю. Если некоторый кластер N назначен файлу, то индекс этого кластера либо становится равным номеру M следующего кластера файла, либо принимает специальное значение , являющееся признаком того, что кластер является последним для файла. Вообще индексы могут содержать следующую информацию о кластере диска (для FAT 32):
- не используется (Unused) – 0000.0000;
- используется файлом (Cluster in use by a file) – значение, отличное от 000.000, FFFF.FFFF и FFFF.FFF7;
- плохой кластер ( Bad cluster ) – FFFF.FFF7;
- последний кластер файла (Last cluster in a file) – FFFF.FFFF.
При такой организации сохраняются все достоинства второго метода организации файлов: отсутствие фрагментации, отсутствие проблем при изменении размера. Кроме того, данный способ обладает дополнительными преимуществами: для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать FAT -таблицу, отсчитать нужное количество кластеров файла по цепочке и определить номера нужного кластера. Во-вторых, данные файла заполняют кластер целиком в объеме, кратном степени двойки.
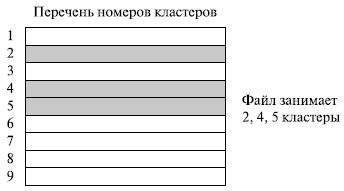
Еще один способ заключается в простом перечислении номеров кластеров, занимаемых файлом (рис. 7.17). Этот перечень и служит адресом файла. Недостаток такого подхода – длина адреса зависит от размера файла. Достоинства – высокая скорость доступа к произвольному кластеру благодаря прямой адресации, отсутствие внешней фрагментации.
Эффективный метод организации файлов, используемый в Unix -подобных операционных системах, состоит в связывании с каждым файлом структуры данных, называемой i-узлами. Такой узел содержит атрибуты файла и адреса кластеров файла (рис. 7.18). Преимущество такой схемы перед FAT -таблицей заключается в том, что каждый конкретный i-узел должен находиться в памяти только тогда, когда открыт соответствующий ему файл . Если каждый узел занимает n байт , а одновременно может быть открыто k файлов, то массив i-узлов займет в памяти k * n байт , что значительно меньше, чем FAT - таблица .
Это объясняется тем, что размер FAT -таблицы растет линейно с размером диска и даже быстрее, чем линейно, так как с увеличением количества кластеров на диске может потребоваться увеличить разрядность числа для хранения их номеров.
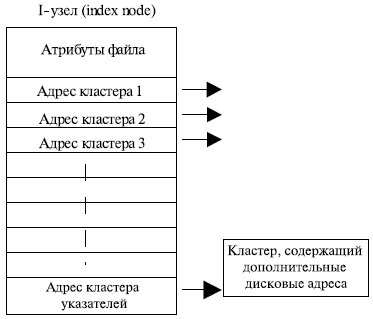
Достоинством i-узлов является также высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация . Фрагментация на уровне кластеров также отсутствует.
Однако с такой схемой связана проблема, заключающаяся в том, что при выделении каждому файлу фиксированного количества адресов кластеров этого количества может не хватить. Выход из этой ситуации может быть в сочетании прямой и косвенной адресации. Такой поход реализован в файловой системе ufs , используемой в ОС UNIX , схема адресации в которой приведена на рис. 7.19.
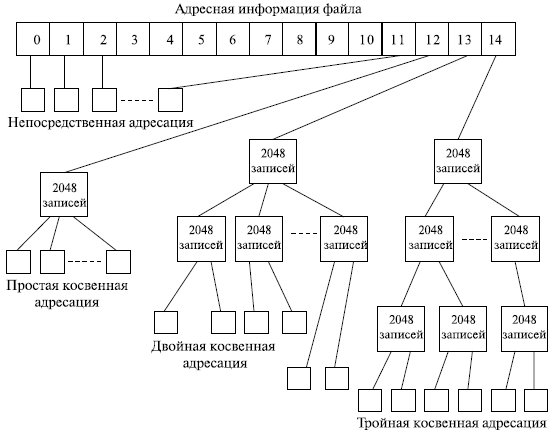
Для хранения адреса файла выделено 15 полей, каждое из которых состоит из 4 байт . Если размер файлов меньше или равен 12 кластерам, то номера этих кластеров непосредственно перечисляются в первых двенадцати полях адреса. Если кластер имеет размер 8 Кбайт, то можно адресовать файл размеров до 8 Кбайт * 12 = 98304 байт . Если размер кластера превышает 12 кластеров, то следующее 13 поле содержит адрес кластера, в котором могут быть расположены номера следующих кластеров, и размер файла может возрасти до 8192 * (12 + 2048) = 16.875.520 байт .
Следующий уровень адресации, обеспечиваемый 14-м полем, позволяет адресовать до 8192 * (12 + 2048 + 20482) = 3,43766*1020 байт . Если и этого недостаточно, используется следующее 15-е поле . В этом случае максимальный размер файла может составить 8192 * (12 + 2048 + 20482 + 20483) = 7,0403*1013 байт .
При этом объеме самой адресной информации составит всего 0,05% от объема адресуемых данных (задачи. ).
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS , применяемой в Windows NT/2000/2003. Для сокращения объема адресной информации в NTFS адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область называется экстентом ( extent ) и описывается двумя числами: номером начального кластера и количеством кластеров.
Читайте также: