
Какое расширение имеет файл блокировки баз данных
Доброе время суток! Администрирование и сопровождение реляционных баз данных чаще всего является нетривиальной задачей. Иногда запросы, работавшие быстро, внезапно начинают «тормозить» по непонятным причинам, размер таблиц растет и в целом производительность базы данных снижается.
Часто причиной такого поведения являются возникающие в базе блокировки различных ресурсов, и соответственно — вырастающее время ожидания этих ресурсов. Например, сложности начинаются в ситуациях, когда два или более запроса в разных сеансах пытаются одновременно изменить одни и те же данные в таблицах или саму структуру таблицы.
Чтобы разобраться в сложившейся ситуации, администратору БД необходимо понять, какой процесс блокирует и какой процесс является блокируемым, а также иметь возможность отменить или «убить» блокирующий процесс и в конце проверить результат.
В этой статье я хочу коснуться темы блокировок в PostgreSQL и рассказать об инструментах для работы с ними. Но сначала попробуем разобраться в самой теме.
Непредвиденные ситуации
Например, если запустить долго обрабатываемый запрос к таблице c 1000 записей, к которой в секунду происходит 100 UPDATE запросов, то за 5-6 часов размер таблицы увеличится до 1.8 миллионов записей, соответственно, физический размер таблицы тоже увеличивается (так как БД хранит все версии строк, пока длинная транзакция не завершит свою работу.
Рассмотрим такую ситуацию подробнее.
Файловая группа файлового потока
Дополнительные сведения о файловых группах файлового потока см. в статьях FILESTREAM и Создание базы данных с поддержкой FILESTREAM.
Автоматическое создание и удаление файлов блокировки
Для каждой базы данных, открытой для совместного использования, создается файл ".laccdb" или ".ldb" для хранения имен компьютеров и безопасности, а также для размещения блокировок расширенного диапазона байтов. Файл блокировки всегда имеет то же имя и находится в той же папке, что и открытая база данных. Например, при открытии (для совместного использования) образца базы данных Northwind.accdb в C:\users\\documents\ , автоматически создается файл с именем Northwind.laccdb в той же папке документов.
Каждый раз, когда последний пользователь закрывает общую базу данных, файл блокировки удаляется. За единственным исключением: если у пользователя нет прав на удаление или если база данных помечена как поврежденная. Затем файл блокировки не удаляется, так как содержит сведения о том, кто использовал базу данных в момент, когда она была помечена как поврежденная.
Запросы в БД
В сети есть много разных реализаций запросов для просмотра заблокированных и блокирующих запросов в БД.
Первый же результат в поисковике по запросу “pg_locks monitoring” выдает ссылку с вариантом запроса:

Открываем редактор и вводим запрос, чтобы получить информацию о блокировках:

Итак, видим кто и кого блокирует. Есть ещё варианты подобных запросов, где можно вывести информацию и о том, как долго уже процесс ждет своей очереди, и тд.
Вторая ссылка (из официальной, между прочим, документации) предлагает совсем уж простой запрос:
Смысл всех этих вариаций по сути одного и того же запроса: вывод информации о блокировках. Нужную информацию мы получили, но ответ не лежит прямо на поверхности. Особенно если к БД осуществляется много запросов. Сиди и разбирайся сам, кто кого и почему блокирует! Построить граф заблокированных ресурсов у себя в голове может далеко не каждый!

К тому же, нам надо уничтожить или остановить блокирующий процесс. И да, это придется вручную, через другой запрос с указанием pid процесса —
Чтобы проверить результат, снова запускаем Запрос 1 или SELECT * FROM pg_catalog.pg_stat_activity WHERE pid=16728; .
Файловая группа по умолчанию (первичная)
Если в базе данных создаются объекты без указания файловой группы, к которой они относятся, они назначаются файловой группе по умолчанию. В любом случае только одна файловая группа создается как файловая группа по умолчанию. Файлы в файловой группе по умолчанию должны быть достаточно большими, чтобы вмещать новые объекты, не назначенные другим файловым группам.
Файловая группа PRIMARY является группой по умолчанию, если только она не была изменена инструкцией ALTER DATABASE. Системные объекты и таблицы распределяются внутри первичной файловой группы, а не новой файловой группой по умолчанию.
Стратегия заполнения файлов и файловых групп
В файловых группах для каждого файла используется стратегия пропорционального заполнения. При записи данных в файловую группу компонент Компонент SQL Server Database Engine записывает в каждый файл количество данных, пропорциональное свободному пространству этого файла, вместо записи всех данных в первый файл до его заполнения. Затем запись производится в следующий файл. Например, если в файле f1 свободно 100 МБ, а в файле f2 — 200 МБ, то в файл f1 записывается одна часть данных, а в файл f2 — две части, и так далее. Таким образом, оба файла будут заполнены примерно в одно и то же время, и достигается простейшее распределение данных между хранилищами.
Например, файловая группа состоит из трех файлов, для всех разрешено автоматическое увеличение. Когда свободное пространство во всех файлах группы закончится, будет расширен только первый файл. Когда заполнится первый файл и в файловую группу снова нельзя будет записывать новые данные, будет расширен второй файл. Когда заполнится второй файл и в файловую группу опять нельзя будет записывать новые данные, будет расширен третий файл. Когда заполнится третий файл и в файловую группу нельзя будет записывать новые данные, будет снова расширен первый файл и т. д.
Содержимое файла блокировки
Для каждого пользователя, который открывает общую базу данных, ядро базы данных Access вносит запись в файл ".laccdb" или ".ldb" базы данных. Размер каждой записи составляет 64 байта. Первые 32 байта содержат имя компьютера (например, JohnDoe). Следующие 32 байта содержат имя безопасности (например, администратор). Максимальное число одновременных пользователей, поддерживаемых ядром базы данных Access, — 255. Поэтому размер файла блокировки никогда не превышает 16 КБ.
Решение файлового сервера может поддерживать до 255 одновременных пользователей, однако если пользователи вашего решения будут часто добавлять и обновлять данные, рекомендуется поддерживать не более 25–50 пользователей в решении файлового сервера Access. Дополнительные сведения см. в разделе Глава 1. Общие сведения о клиенте Microsoft Access 2000/разработке сервера.
Когда пользователь закрывает общую базу данных, запись пользователя не удаляется из файла блокировки. Однако запись пользователя может быть перезаписана при открытии базы данных другим пользователем. Это означает, что вы не можете использовать файл блокировки только для определения того, кто в настоящее время использует базу данных.
Использование файла блокировки
Ядро базы данных Access использует сведения о файлах блокировки, чтобы запретить пользователям записывать данные на страницы или вносить записи, заблокированные другими пользователями, а также определять, кто заблокировал другие страницы или записи. Если ядро базы данных Access обнаруживает конфликт блокировки с другим пользователем, он считывает файл блокировки, чтобы получить имя компьютера и безопасности пользователя с заблокированным файлом или записью.
Не удалось заблокировать таблицу ; в настоящее время используется пользователем на компьютере .
С помощью Microsoft Visual Basic для приложений можно вывести список пользователей, которые выполнили вход в определенную базу данных. Дополнительные сведения о том, как это сделать, и пример кода см. в разделе Определение входа в базу данных с помощью Microsoft Jet UserRoster в Access.
В данном посте база SQLite будет рассмотрена в разрезе, вы можете найти информацию о строении файла базы данных, о представлении данных в памяти, а также информацию о структуре и файловом представлении В – дерева.
Формат файла базы данных
Вся база данных хранится в одном файле на диске под названием «main database file». Во время транзакций, SQLite хранит дополнительную информацию во втором файле: журнал отката (rollback journal), либо, если база работает в режиме WAL, лог-файл с информацией о записях. Если приложение или компьютер отключился до окончания транзакции, то данные файлы называются «hot journal» или «hot WAL file» и содержат необходимую информацию для восстановления базы в согласованное состояние.
Основной файл базы состоит из одной или нескольких страниц. Все страницы в одной базе имеют одинаковый размер, который может быть от 512 до 65536 байт. Размер страницы для файла базы определяется целым 2-ух байтовым числом со смещением 16 байт от начала файла базы данных.
Все страницы пронумерованы от 1 до 2147483646 (2^31 – 2). Минимальный размер базы: одна страница размеров 512 байт, максимальный размер базы: 2147483646 страниц по 65536 байт (~140 Тбайт).
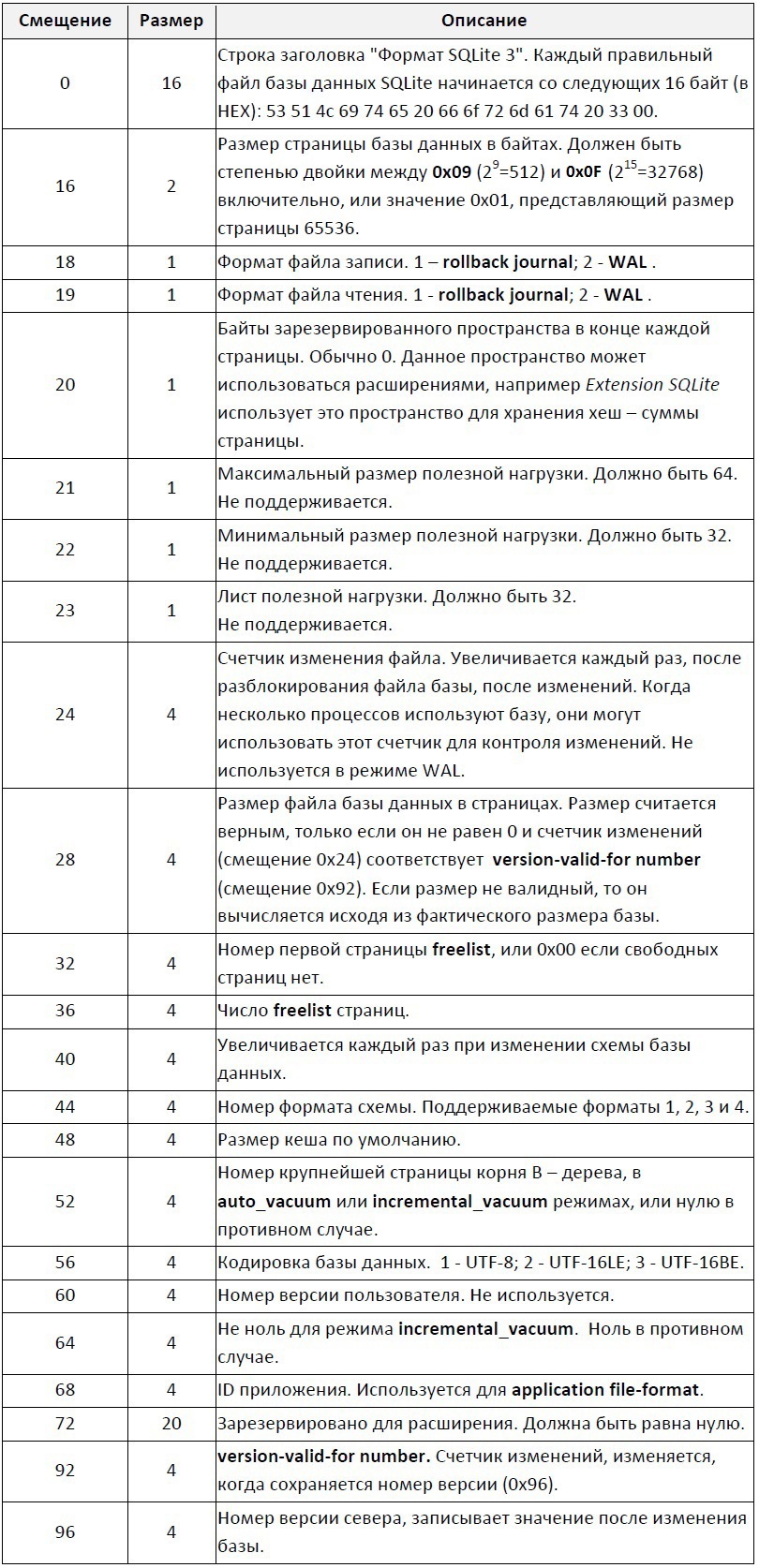
Заголовок
Первый 100 байт файла базы данных содержат заголовок базы, в таблице 1 представлена схема заголовка.
Lock-byte страница
Freelist
Список пустых страниц организован как связный список. Каждый элемент списка состоит из двух чисел по 4 байта. Первое число определяет номер следующего элемента freelist (trunk pointer), либо равняется нулю, если список кончился. Второе число, это указатель на страницу данных (Leaf page numbers). На рисунке ниже показана схема данной структуры.

B — tree
SQLite использует две вида деревьев: «table B – tree» (на листьях хранятся данные) и «index B – tree» (на листьях хранятся ключи).
Каждая запись в «table B – tree» состоит из 64-битового целое ключа и до 2147483647 байт произвольных данных. Ключ «table B – tree» соответствует ROWID таблицы SQL.
Каждая запись в «index B – tree» состоит из произвольного ключа до 2147483647 байт в длину.
- Заголовок файла базы данных (100 байт)
- Заголовок страницы B-дерева (8 или 12 байт)
- Массив указателей ячеек
- Незанятое пространство
- Содержимое ячейки
- Зарезервированное место
Заголовок файла базы данных встречается только на первой странице, которая всегда является старицей «table B – tree». Все остальные страницы B-дерева в базе не имеют этого заголовка.
Заголовок страницы B-дерева имеет размер 8 байт для страниц листьев и 12 байт для внутренних страниц. В таблице 2 представлена структура заголовка страницы.

Freeblock — это структура, используемая для определения незанятого пространства внутри страницы B-дерева. Freeblock организованы в виде цепочки. Первые 2 байта в freeblock (от старшего к младшему), это смещением до следующего freeblock, или ноль, если freeblock является последним в цепочке. Третий и четвертый байты – целое число, размер freeblock в байтах, включая заголовок в 4 байта. Freeblocks всегда связаны в порядке возрастания смещения.
Число фрагментированных байт – это общее число неиспользуемых байт в области содержимого ячейки.
Массив указателей ячеек состоит из K 2-байтовых целочисленных смещений содержимого ячеек (при K ячейках в B-дереве). Массив отсортирован по возрастанию (от наименьших ключей к наибольшим).
Незанятое пространство — это область между последней ячейкой массива указателей и началом первой ячейки.
Зарезервированное место в конце каждой страницы используется расширениями для хранения информации о странице. Размер зарезервированной области определяется в заголовке базы (по умолчанию равен нулю).
Representation
TABLE
TABLEWITHOUT ROWID
Каждая таблица (без ROWID) представляется в базе в виде index b — tree. Отличие от таблиц с rowid, заключается в том, что ключ каждой записи SQL таблицы хранится в виде record format, при чем столбцы ключа хранятся как указаны в PRIMARY KEY, а остальные в порядке указанном в объявлении таблицы.
Таким образом записи в index b — tree представляются также как и в table b — tree, кроме порядка столбцов и того, что содержание строки хранится в ключе дерева, а не в качестве данных на листьях как в table b — tree.
INDEX
Каждый индекс (объявленный CREATE INDEX, PRIMARY KEY или UNIQUE) представляется в базе в виду index b — tree. Каждая запись в таком дереве соответствует строки в SQL таблице. Ключ индексного дерева представляет собой последовательность значений столбцов указанных в индексе и завершается значением ключа строки (rowid или primary key) в record format.
UPD 13:44: переработан раздел Representation, спасибо за критику mayorovp (можно было конечно и пошевелиться, ну да ладно).
Каждая база данных SQL Server имеет как минимум два рабочих системных файла: файл данных и файл журнала. Файлы данных содержат данные и объекты, такие как таблицы, индексы, хранимые процедуры и представления. Файлы журнала содержат сведения, необходимые для восстановления всех транзакций в базе данных. Файлы данных могут быть объединены в файловые группы для удобства распределения и администрирования.
Пример с возникающей блокировкой
Пусть в некоторой БД у нас есть таблица pgsqlblocks_testing и у неё есть правило rule_pgsqlblocks_testing. Эмулируем к нему “долгий” запрос на 10 минут, к примеру, с помощью SQL редактора pgAdmin:
Pid процесса 16728
Открываем ещё один редактор и выполняем другой запрос на удаление правила:
Pid процесса 16726
И вот DROP RULE блокируется SELECT запросом. MVCC в данном случае не смог обойтись без явной блокировки таблицы pgsqlblocks_testing.
Рекомендации
Рекомендации при работе с файлами и файловыми группами:
- Для большинства баз данных достаточно использовать один файл данных и один файл журнала транзакций.
- При использовании множества файлов данных создайте вторую файловую группу с дополнительным файлом и сделайте ее файловой группой по умолчанию. Тогда в первичном файле будут храниться только системные таблицы и объекты.
- Чтобы увеличить производительность, по возможности разнесите файлы и файловые группы по нескольким доступным дискам. Объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы.
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках.
- Помещайте разные таблицы, использующиеся в одних и тех же запросах с соединениями, в разные файловые группы. Этот этап увеличит производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод.
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, помещайте в разные файловые группы. Использование разных групп файлов увеличит производительность, так как можно будет использовать параллельный ввод и вывод, если файлы находятся на разных жестких дисках.
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы.
- Если необходимо расширить том или раздел, в котором находятся файлы базы данных, с помощью таких средств, как Diskpart, следует сначала выполнить резервное копирование всех системных и пользовательских баз данных и остановить службы SQL Server. Кроме того, после успешного расширения томов дисков рекомендуется выполнить команду DBCC CHECKDB , чтобы обеспечить физическую целостность всех баз данных в томе.
Дополнительные рекомендации по управлению файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.

ИНСТРУКЦИЯ 1С 8 → перейти в меню [СТАТЬИ И ИНСТРУКЦИИ]

*.cf - файл содержит только конфигурацию(код и структура) без пользовательских данных. Создаётся из конфигуратора 1С 8.х: «Конфигурация -> Сохранить конфигурацию в файл» или «Конфигурация -> Поставка конфигурации -> Создать файл поставки и обновление конфигурации -> признак «Создать файл поставки»».
*.cfu - файл содержит только обновление конфигурации. Например файл 1cv8.cfu. Создать конфигурацию из этого файла невозможно, так как он содержит в себе только отличия новой конфигурации от предыдущей. Создаётся из конфигуратора 1С 8.х: «Конфигурация -> Поставка конфигурации -> Создать файл поставки и обновление конфигурации -> признак «Создать файл обновления конфигурации»».
*.cfe - файл-расширение, предназначенный для доработки конфигурации без её изменения. При использовании расширений 1С (*.cfe) - доработанная конфигурация может полноценно обновляться и с поддержки не снимается.
*.dt - файл содержит конфигурацию вместе с пользовательской базой данных. Это специализированный формат архива 1С 8. Создаётся из конфигуратора 1С 8.х: «Администрирование -> Выгрузить информационную базу».
*.epf (*.erf) – файл внешней обработки (отчёта). Любую обработку (отчёт) из конфигурации можно сохранить внешней. Создаётся из конфигуратора 1С 8.х: «Конфигурация -> Открыть конфигурацию -> становимся на нужную обработку (отчёт) -> выделяем правой кнопкой мыши -> Сохранить как внешнюю обработку, отчёт…». Открыть эти файлы в режиме 1С Предприятия 8.3 можно по инструкции .
*.1cd – файл полноценной базы данных. Представление имени по умолчанию: 1Cv8.1CD. Включает в себя конфигурацию, базу данных, пользовательские настройки. Открывается платформой 1С 8.x. Создаётся для разработки новой конфигурации автоматически по кнопке «Добавить» при выборе пункта «Создание новой информационной базы».
*.log, *.lgf, *.lgp, *.elf - лог файлы, которые собирают информацию (регистрируют данные) в 1С 8.0 8.1, 8.2, 8.3. Например, файл 1Cv8.lgf (в каталоге 1Cv8Log ) содержит информацию журнала регистрации.
*. cdn - файл с таким расширением ( 1Cv8.cdn) служит для ручной или автоматической блокировки базы данных 1С Предприятия восьмой версии .
*.mxl - файлы печатных форм используются, в том числе и в 1С. Являются как печатными формами документов, справочников, отчётов, так и различными накопителями данных для различных классификаторов. Открывается через Конфигуратор или в режиме 1С:Предприятии через «файл -> открыть». Создаётся точно так же: в режиме Конфигуратор или в 1С:Предприятии через «файл -> новый». Так же файлы с такими расширениями могут служить правилами переноса, например, из 1С 7.7 в 8.2 ( acc77_82.xml и вспомогательная обработка exp77_82.ert) - находятся они обычно в папке ExtForms.
*.efd - это архивный файл 1С, используется для установки конфигурации. Содержит или конфигурацию 1с или обновление к ней. Запускается с помощью вспомогательного исполняющего файла setup.exe (должен находиться в одной папке).
*.mft – вспомогательный файл для создания конфигурации из шаблона. Содержит информацию о конфигурации, описание, пути, название. Используется непосредственно самой платформой при создании информационной базы 1С из шаблона.
*.grs - файлы графических схем в специализированном формате 1С. Открывается через Конфигуратор или в режиме 1С:Предприятии через «файл -> открыть». Создаётся точно так же: в режиме Конфигуратор или в 1С:Предприятии через «файл -> новый».
*.geo - файлы географических схем в специализированном формате 1С. Открывается через Конфигуратор или в режиме 1С:Предприятии через «файл -> открыть». Создаётся точно так же: в режиме Конфигуратор или в 1С:Предприятии через «файл -> новый».
*.st - файлы шаблонов текстов. Используются в основном 1С разработчиками. Рекомендую для автозамены эти шаблоны кода .
*.pff - файл с сохраненными замерами производительности. Используются системными администраторами и специалистами 1С.
. 1Cv8.pfl - параметры для компьютера/информационной базы/пользователя (в т.ч. пароли пользователей, настройки текстового редактора, настройки глобального поиска по текстам конфигурации, список переменных для быстрого просмотра в отладчике ). Настройки модулей в конфигураторе хранятся в файле 1Cv8.pfl . Этот файл обычно находится в каталоге настроек пользователя C:\Users\<ИмяПользователя>\AppData\Roaming\1C\1cv8.
. 1Cv8cmn.pfl - общие параметры для компьютера, используемые в 1С:Предприятии/Конфигураторе (в т.ч. цвета редактора модулей в конфигураторе )
*.ini - стандартное расширение файла настроек в разных программах. В 1С 8 используется файл nethasp.ini для хранения настроек аппаратного ключа.
Файловые группы
- Эта файловая группа содержит первичный файл данных и все вторичные файлы, не входящие в другие файловые группы.
- Пользовательские файловые группы могут создаваться для удобства администрирования, распределения и размещения данных.
Например, Data1.ndf , Data2.ndf и Data3.ndf могут быть созданы на трех дисках соответственно и отнесены к файловой группе fgroup1 . В этом случае можно создать таблицу на основе файловой группы fgroup1 . Запросы данных из таблицы будут распределены по трем дискам, и это улучшит производительность. Подобного улучшения производительности можно достичь и с помощью одного файла, созданного на чередующемся наборе дискового массива RAID. Тем не менее файлы и файловые группы позволяют без труда добавлять новые файлы на новые диски.
Все файлы данных хранятся в файловых группах, перечисленных в следующей таблице.
| Файловая группа | Описание |
|---|---|
| Первичная | Файловая группа, содержащая первичный файл. Все системные таблицы являются частью первичной файловой группы. |
| Данные, оптимизированные для памяти | В основе оптимизированной для памяти файловой группы лежит файловая группа файлового потока. |
| Файловый поток | |
| Определяемые пользователем маршруты | Любая файловая группа, созданная пользователем при создании или изменении базы данных. |
Логические и физические имена файлов
Файлы SQL Server имеют два типа имен файлов.
logical_file_name: имя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файла должно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.
os_file_name: имя физического файла, включающее путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Дополнительные сведения об аргументах NAME и FILENAME см. в статье Параметры ALTER DATABASE ((Transact-SQL)) для файлов и файловых групп.
Файлы данных и файлы журналов SQL Server могут использоваться как в файловой системе FAT, так и в системе NTFS. В системах Windows рекомендуется использовать файловую систему NTFS по причинам ее большей безопасности.
Файловые группы, доступные как для чтения, так и для записи, а также файлы журналов не поддерживаются со сжатой файловой системой NTFS. В сжатую файловую систему NTFS разрешено помещать лишь доступные только для чтения базы данных и доступные только для чтения вторичные файловые группы. Для экономии места настоятельно рекомендуется использовать сжатие данных вместо сжатия файловой системы.
Если на одном компьютере запущено несколько экземпляров SQL Server, каждый экземпляр получает отдельный каталог по умолчанию для хранения файлов баз данных, созданных в этом экземпляре. Дополнительные сведения см. в разделе Расположение файлов для экземпляра по умолчанию и именованных экземпляров SQL Server.
Правила проектирования файлов и файловых групп
Для файлов и файловых групп действуют следующие правила:
- файл или файловая группа не могут использоваться несколькими базами данных. Например, файлы sales.mdf и sales.ndf, содержащие данные и объекты базы данных sales, не могут использоваться никакой другой базой данных.
- файл может быть элементом только одной файловой группы;
- файлы журнала транзакций не могут входить ни в какие файловые группы.
Размер файла
Файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели. При определении файла пользователь может указывать требуемый шаг роста. Каждый раз при заполнении файла его размер увеличивается на указанный шаг роста. Если в файловой группе имеется несколько файлов, их автоматический рост начинается лишь по заполнении всех файлов.
Дополнительные сведения о страницах и их типах см. в разделе Руководство по архитектуре страниц и экстентов.
Кроме того, можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файл может продолжать увеличиваться в размерах, пока не займет все доступное место на диске. Эта функция особенно полезна в случаях, когда SQL Server используется в качестве базы данных, внедренной в приложение, где пользователь не имеет удобного доступа к системному администратору. По мере необходимости пользователь может предоставить файлам возможность увеличиваться в размерах автоматически, тем самым снимая с администратора часть забот по наблюдению за свободным пространством базы данных и по распределению дополнительного пространства вручную.
Дополнительные сведения об управлении файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
Введение
Файл ".laccdb" или ".ldb" играет важную роль в многопользовательской архитектуре ядра базы данных Microsoft Access. Файл ".laccdb" или ".ldb" используется для определения того, какие записи заблокированы в общей базе данных и кем. Файл ".laccdb" используется в базах данных .accdb, а файл ".ldb" используется в базах данных ".mdb". Файлы ".laccdb" и ".ldb" обычно называются файлами блокировки.
Установка и настройка
В системе должна быть предустановлена JRE 8.
Это всё, что нужно для запуска приложения. Всё работает “из коробки”.
Для начала работы с приложением стоит заполнить список с базами данных. Для добавления новой БД нажмите иконку БД со значком "+" над списком БД и заполните необходимые данные в появившемся диалоге. Пароль лучше хранить в pgpass файле.

Протестировано на версиях 9.2-9.6 PostgreSQL.
Дополнительно можно настроить частоту обновления информации из БД, необходимость показывать idle процессы, список отображаемых колонок.
Файлы базы данных
SQL Server имеют три типа файлов.
| Файл | Описание |
|---|---|
| Первичная | Содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется расширение MDF. |
| Вторичная | Необязательные определяемые пользователем файлы данных. Данные могут быть распределены на несколько дисков, в этом случае каждый файл записывается на отдельный диск. Для имени вторичного файла данных рекомендуется расширение NDF. |
| Журнал транзакций | Журнал содержит информацию для восстановления базы данных. Для каждой базы данных должен существовать хотя бы один файл журнала. Для файлов журнала транзакций рекомендуется расширение LDF. |
Например, простая база данных с именем Sales включает один первичный файл, содержащий все данные и объекты, и один файл журнала, содержащий сведения журнала транзакций. Более сложная база данных с именем Orders может содержать один первичный файл и пять вторичных файлов. Данные и объекты внутри базы данных распределяются по всем шести файлам, а четыре файла журнала содержат сведения журнала транзакций.
По умолчанию и данные, и журналы транзакций помещаются на один и тот же диск и имеют один и тот же путь для обработки однодисковых систем. Для производственных сред это может быть неоптимальным решением. Рекомендуется помещать данные и файлы журнала на разные диски.
Файловая группа данных, оптимизированных для памяти
Дополнительные сведения об оптимизированных для памяти файловых группах см. в разделе Оптимизированные для памяти файловые группы.
Состояние сервера в pgAdmin
pgAdmin представляет собой достаточно удобное и простое ПО для работы с БД PostgreSQL. На данный момент актуальными версиями являются pgAdmin III и вышедший только в конце сентября pgAdmin IV.
pgAdmin III
Отображение информации о блокировках и активных процессах в pgAdmin III требует наличия расширения adminpack в базе данных. После установки этого расширения нужное нам окно открывается через меню Инструменты — Состояние сервера.
В этом окне мы видим таблицу с процессами и таблицу с имеющимися блокировками в БД. Чтобы не растеряться среди большого количества процессов, мы можем настроить цвета процессов в зависимости от их статуса: активный, заблокированный, бездействующий или «медленный».

В таблице каждый блокирующий и блокируемый процесс представлены отдельными строками, и нет возможности быстро определить, кто кого блокирует. Для решения этой задачи нам придется сопоставлять разные строки между собой в попытке найти строки, объединенные общим значением колонки relation и отличными значениями колонки granted.
Для отмены или терминирования выбранного процесса в окне имеются две кнопки. После терминирования какого-либо из процессов нужно обновить окно и снова сопоставить строки, чтобы оценить результат.
Итак, pgAdmin III может быть использован как инструмент для работы с блокировками, но обладает парой минусов: требует предварительной настройки БД и показывает блокировки в плоском виде (без древовидного отображения блокирующих-блокируемых процессов), что осложняет поиск проблемных процессов и оценку их терминирования. Это делает его не самым удобным инструментом для наших задач.
pgAdmin IV
После установки и запуска pgAdmin IV мы сможем посмотреть существующие блокировки в том же виде, как это было в pgAdmin III.

Но… это все, что мы сможем сделать здесь. В pgAdmin IV пропала панель инструментов для действий над процессами, и мы уже не можем отменить или терминировать процессы из этого вида, что делает pgAdmin IV неудобным инструментом работы с блокировками.
Файлы моментального снимка базы данных
Вид файла, используемый для хранения копируемых во время записи данных моментального снимка базы данных, зависит от того, создается ли моментальный снимок пользователем или используется внутренними механизмами.
- Данные моментального снимка базы данных, созданного пользователем, хранятся в одном или нескольких разреженных файлах. Технология разреженных файлов является свойством файловой системы NTFS. Изначально разреженный файл не содержит данных пользователя, и место на диске под него не выделяется. Общие сведения об использовании разреженных файлов в моментальных снимках базы данных и о том, как растут моментальные снимки базы данных, см. в разделе Просмотр размера разреженного файла моментального снимка базы данных.
- Моментальные снимки базы данных могут использоваться внутренними механизмами при выполнении определенных команд DBCC. Эти команды включают DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC и DBCC CHECKFILEGROUP. Внутренним моментальным снимком базы данных используются разреженные дополнительные потоки данных исходных файлов базы данных. Подобно разреженным файлам, дополнительные потоки данных являются свойством файловой системы NTFS. Использование разреженных дополнительных потоков данных позволяет связать несколько расположений данных с одним файлом или папкой, не затрагивая при этом размер файла или статистику тома.
Заключение
Проблема появления блокирующих запросов в БД может быть очень серьезной и приводить к заметному замедлению работы БД и исчерпанию дискового пространства. Поэтому важно иметь удобный и быстрый инструмент для детектирования блокировок и принятия (иногда) оперативных действий.
Таким инструментом для нас является pgSqlBlocks — это приложение, которое позволяет легко ориентироваться среди процессов и получать информацию о блокирующих и ожидающих запросах.
К преимуществам его можно отнести наглядность предоставленной информации, а также удобство выполнения типичных задач — просмотра информации о процессах, поиска проблем среди списка процессов, отмены или терминирования процесса и оценки результата. Кроме того, приятной возможностью является сохранение истории блокировок в файл для дальнейшего разбора сложившейся ситуации. Всё это делает вашу работу с блокировками в БД PostgreSQL быстрой и удобной.
P.S.: вдохновением для создания этого приложения стала утилита MSSQL Blocks. Но она предназначена именно для работы с БД MSSQL. Для PostgreSQL его аналогов не оказалось.
Office 365 ProPlus переименован в Майкрософт 365 корпоративные приложения. Для получения дополнительной информации об этом изменении прочитайте этот блог.
Немного теории: ликбез о блокировках
Что же такое блокировки в БД? Википедия предлагает следующее определение:“Блокировка (англ. lock) в СУБД — отметка о захвате объекта транзакцией в ограниченный или исключительный доступ с целью предотвращения коллизий и поддержания целостности данных.”
PostgeSQL поддерживает целостность данных, реализуя модель MVCC. MVCC (MultiVersion Concurrency Control) — один из механизмов обеспечения параллельного доступа к БД, заключающийся в предоставлении каждому пользователю так называемого «снимка» БД. Особое «свойство» такого снимка в том, что вносимые пользователем изменения в БД невидимы для других пользователей до момента фиксации транзакции.
PostgreSQL гарантирует целостность даже для самого строгого уровня изоляции транзакций, используя инновационный уровень изоляции SSI (Serializable Snapshot Isolation, Сериализуемая изоляция снимков).
Для большего понимания темы можно почитать статью на Хабре и статью в блоге Александра Журавлёва о блокировках, их работе и конкурентном доступе вообще.
Привилегии, необходимые для папки
Если вы планируете совместное использование базы данных, файл базы данных должен располагаться в папке, в которой пользователи имеют привилегии на чтение, запись, создание и удаление. Даже если вы хотите, чтобы у пользователей были различные привилегии для файлов (например, некоторые только для чтения и некоторые для чтения и записи), все пользователи, предоставляющие общий доступ к базе данных, должны иметь разрешения на чтение, запись и создание для папки. Однако отдельным пользователям можно назначить разрешения только на чтение для файла .accdb или .mdb, но при этом разрешить полные разрешения для папки.
Если пользователь открывает базу данных с монопольным доступом (щелкнув стрелку справа от кнопки Открытие, а затем щелкнув Монопольный доступ), блокировка записи не используется. Поэтому Microsoft Access не пытается открыть или создать файл блокировки. Если база данных всегда открыта для монопольного использования, пользователю необходимо иметь только привилегии на чтение и запись для папки.
Всё просто и удобно с pgSqlBlocks!
Хочу показать вам ещё один инструмент и поделиться, чем он так удобен, — pgSqlBlocks. Инструмент pgSqlBlocks написан нами для себя, и создан именно для того, чтобы облегчить решение проблем с блокировками в PostgreSQL, которым мы пользуемся уже больше года.
Вот так выглядит окно pgSqlBlocks в случае нашего примера с двумя процессами (здесь они имеют pid 29981 (SELECT) и 28710 (DROP RULE)).

В левой части окна имеется список баз данных, в котором отображается информация о состоянии подключения к БД (соединен, отключен, обновление информации, ошибка соединения, имеются блокировки в БД).
Основную часть приложения занимает дерево процессов, которые на данный момент есть в выбранной БД. Блокированные процессы имеют иконку закрытого серого замка и являются потомками блокирующих процессов, чья иконка — красный замок. Иконка обычных процессов — зеленая точка.
Такое представление процессов позволяет нам легко ориентироваться в них, получать информацию о блокирующих и ожидающих процессах, а также об их отношении друг к другу. Можно для большей наглядности скрыть обычные (не заблокированные и не блокирующие) процессы.

Наглядно видим, что процесс с pid 29981 с долгим SELECT-запросом блокирует процесс с pid 28710.
При необходимости можно послать сигнал отмены или уничтожении любого процесса. Например, если уничтожить блокируемый процесс 28710, то информация в дереве процессов тут же обновится и мы увидим результат — процесс 29981 с долгим SELECT-запросом больше никого не блокирует. Быстро и удобно.
Еще из мелких и приятных фич приложения можно отметить:
— Сохранение истории блокировок в файл и загрузка обратно в приложение. Этакий snapshot всех блокировок на момент сохранения, который позволяет в любой удобный момент просмотреть и проанализировать, какие были блокировки в БД;
— Иконка в трее меняется, если хотя бы в одной из подключенных БД появилась блокировка;
— Нотификации в трее при появлении блокировок;
— Настраиваемое автообновление списка процессов.
Как установить pgSqlBlocks и чем он удобен по сравнению с описанными выше вариантами?
Пример файлов и файловых групп
В следующем примере создается база данных на основе экземпляра SQL Server. База данных содержит первичный файл данных, пользовательскую файловую группу и файл журнала. Первичный файл данных входит в состав первичной файловой группы, а пользовательская файловая группа состоит из двух вторичных файлов данных. Инструкция ALTER DATABASE придает пользовательской файловой группе статус файловой группы по умолчанию. Затем создается таблица, определяющая пользовательскую файловую группу. (В этом примере используется универсальный путь к c:\Program Files\Microsoft SQL Server\MSSQL.1 , чтобы не указывать версию SQL Server.)
Данная иллюстрация обобщает все вышесказанное (кроме данных файлового потока).
Инструменты для работы с блокировками
Как же нам просмотреть имеющиеся блокировки? Можно самому писать запрос для таблицы блокировок pg_locks и представления pg_stat_activity или использовать встроенный в pgAdmin инструмент.
Читайте также: