
Какими источниками информации пользовались люди до появления компьютеров и интернета
Итоговое собеседование по русскому языку состоит из четырёх заданий. Задания 1 и 2 выполняются с использованием одного текста. Задание 1 — чтение вслух небольшого текста. Время на подготовку — 2 минуты. В задании 2 предлагается пересказать прочитанный текст, дополнив его высказыванием. Время на подготовку — 2 минуты. Задания 3 и 4 не связаны с текстом, который Вы читали и пересказывали, выполняя задания 1 и 2. Вам предстоит выбрать одну тему для монолога и диалога. В задании 3 предлагается выбрать один из трёх предложенных вариантов беседы: описание фотографии, повествование на основе жизненного опыта, рассуждение по одной из сформулированных проблем. Время на подготовку — 1 минута. В задании 4 Вам предстоит поучаствовать в беседе по теме предыдущего задания.
Общее время Вашего ответа (включая время на подготовку) — 15 минут. Постарайтесь полностью выполнить поставленные задачи, говорить ясно и чётко, не отходить от темы и следовать предложенному плану ответа. Так Вы сможете набрать наибольшее количество баллов.
Если вариант задан учителем, вы можете вписать или загрузить в систему ответы к заданиям с развернутым ответом. Учитель увидит результаты выполнения заданий с кратким ответом и сможет оценить загруженные ответы к заданиям с развернутым ответом. Выставленные учителем баллы отобразятся в вашей статистике.
Выразительно прочитайте текст вслух.
В ожерелье народных ремесел современная Хохлома — наш драгоценный бриллиант. Вы приходите на выставку, и первое, что бросается в глаза, — бочонок, чашка и поставец, ярко украшенные золотом и киноварью. Вы берете бочонок, такой массивный и тяжелый с виду, и рука вдруг чувствует, что он совсем легок. Ну, конечно, не как пух — ведь бочонок сделан из дерева, но тяжести ожидаешь потому, что он похож на металлический. На нем незатейливые золотистые узоры «травкой», «ягодкой», «листочками».
Знаменитое хохломское «золото» и орнамент «травка» возникли на основе уже существовавших многовековых художественных традиций.
Золото всегда было олицетворением счастливой, богатой жизни, довольства, красоты и чистоты. В народе говорили: «золото не горит, а чудеса творит»…
Крестьянин собирал свадебный пир. Бедна была домашняя деревенская обстановка! Подумайте, как приятно было в семье хлебопашца поставить на стол отливающую золотом посуду, украшенную гроздьями рябины, травным орнаментом.
(по Е.И. Осетрову)
Решения заданий с развернутым ответом не проверяются автоматически.
На следующей странице вам будет предложено проверить их самостоятельно.
Перескажите прочитанный Вами текст, включив в пересказ слова из русской пословицы:
«С мастерством люди не родятся, но добытым мастерством гордятся».
В ожерелье народных ремесел современная Хохлома — наш драгоценный бриллиант. Вы приходите на выставку, и первое, что бросается в глаза, — бочонок, чашка и поставец, ярко украшенные золотом и киноварью. Вы берете бочонок, такой массивный и тяжелый с виду, и рука вдруг чувствует, что он совсем легок. Ну, конечно, не как пух — ведь бочонок сделан из дерева, но тяжести ожидаешь потому, что он похож на металлический. На нем незатейливые золотистые узоры «травкой», «ягодкой», «листочками».
Знаменитое хохломское «золото» и орнамент «травка» возникли на основе уже существовавших многовековых художественных традиций.
Золото всегда было олицетворением счастливой, богатой жизни, довольства, красоты и чистоты. В народе говорили: «золото не горит, а чудеса творит»…
Крестьянин собирал свадебный пир. Бедна была домашняя деревенская обстановка! Подумайте, как приятно было в семье хлебопашца поставить на стол отливающую золотом посуду, украшенную гроздьями рябины, травным орнаментом.

В это уже сложно поверить, но раньше люди не могли гуглить по вполне понятной причине — Google ещё не было. Рассказываем, как появились поисковые системы, что значит песня группы «Сплин» и при чём тут сериал «Ривердэйл».
Представьте себе, что вы переместились назад во времени, попали в девяностые и вам срочно нужно найти что-то очень важное в интернете. Сможете ли вы это сделать? Зависит от года, в котором вы оказались.

В начале девяностых у пользователей интернета ещё не было привычки задавать вопросы поисковым системам. Ссылки на полезные сайты буквально передавали из рук в руки: ими делились со знакомыми, сохраняли их в отдельных текстовых файлах.
Но в 1990 году уже появилась первая в мире компьютерная программа для поиска в интернете. Её зовут Арчи (Archie), но это не столько имя, сколько сокращение от слова archive («архив»).
Создатели Арчи — Алан Эмтег, Билл Хилан и Питер Дойч, студенты, изучавшие информатику в университете Макгилла в Монреале (Канада). Сами того не зная, они положили начало многомиллиардной индустрии. Сам Эмтег вспоминал об этом так:
Я написал кусок кода, который заложил основу для многомиллиардной индустрии. В то время интернет не был бизнесом, и мы не стали патентовать Archie. На этом можно было заработать, но я не стал так делать, и совершенно об этом не жалею.
Арчи был ещё не поисковой системой, а просто программой, которая скачивает списки файлов со всех доступных серверов и строит базу данных с поиском по именам этих файлов. Эта программа не умела индексировать содержимое файлов, но для 1990 года это не было страшно. Объём данных пока был настолько мал, что всё можно было найти и вручную.
Первые «дата-центры»
Отдельно скажем несколько слов о первом «дата-центре» в мире. Если пойти на некоторые допущения, первым дата-центром можно считать компьютер ENIAC (электронный числовой интегратор и вычислитель, Electronic Numerical Integrator and Computer) 1945 года, использовавшийся для хранения боевых кодов ядерного оружия, расчетов траекторий полета бомб, прогнозирования погоды на территории СССР.

По правде говоря, история компьютера началась существенно раньше, в 1942-1943 гг., но ввиду новизны проекта и сложностей с получением одобрения от консервативных военных, строительство завершилось лишь в 1945 году. Разумеется, использовался он также в военных целях для произведения расчетов при разработке термоядерного оружия и таблиц стрельбы (а также для предсказания выпадения ядерных осадков на территории СССР на основании прогнозов погоды). Проект был продемонстрирован публике лишь спустя несколько месяцев после окончания войны и проработал в сумме ровно 10 лет, с осени 1945 по 2 октября 1955, когда состоялось его окончательное отключение. Примечательно, что первыми программистами ENIAC стали девушки:
- Мэрлин Мельцер
- Рут Лихтерман
- Кэтлин Рита Макналти
- Бетти Джин Дженнингс
- Франсис Элизабет Снайдер
- Франсис Билас
В чем-то ENIAC действительно был похож на современные дата-центры: отдельное помещение, оборудованное несколькими степенями защиты, ряды стеллажей с лампами, системы питания с резервированием, большой штат обслуживающего персонала и огромная ответственность перед «заказчиком».
Весил ENIAC приблизительно 27 тонн, потреблял 174 кВт энергии и имел тактовую частоту в 100 кГц. Первая компьютерная комната в СССР площадью 60м2 появилась в 1951 году, но это, как говорится, уже совершенно другая история, которую мы затронем в одной из следующих статей.
Кстати, в 1995 году была создана кремниевая интегральная микросхема ENIAC-on-A-Chip размерами 7,44 мм × 5,29 мм, в которой с помощью 250 000 (по другим данным — 174 569) транзисторов была реализована логика, аналогичная ламповому ЭНИАКу.
Однако этот компьютер был лишь похож на дата-центры, ни о какой виртуализации в данном случае речи не шло, хотя эпоха уже позволяла о ней говорить.
Почерк
Учителя обучали красиво писать от руки, потому что это было необходимым требованием для учеников.

Не ARPANETом единым
Уже в 1983 ARPANET состояла из 4000 хостов. Несмотря на изначальную сугубо военную направленность проекта, многие другие организации посчитали его крайне удобным. Среди них были университеты, предприятия, городские службы и многие, многие другие. Таким образом, ARPANET был разделен на две части: одноименную для гражданских нужд и военную MILNET. Несмотря на произошедшее разделение, Министерство обороны США продолжало поддерживать ARPANET, пусть даже военные организации более не использовали эту сеть для своих нужд.
Ранее мы не упоминали о еще одном «брате-близнеце» ARPANET – сети, созданной Национальным научным фондом для проведения научных исследований. Это позволило многим учреждениям, которые ранее не имели возможности подключиться к ARPANET, общаться по «собственным» каналам. CSNET начала работу в 1981 году и стала предшественницей высокоскоростной NSFNET, объединившей национальные научные фонды и ставшей основой современного интернета.
К слову о скорости. Прежних 50-56 кбит/с было крайне мало для эффективной коммуникации внутри постоянно растущей сети компьютеров. Благодаря компании MCI Corporation, сеть была существенно модернизирована путем внедрения новых линий T-1. Они позволяли передавать данные на скорости до 1,5 Мбит/с. В свою очередь, IBM разработали более совершенные маршрутизаторы, а компания Merit взяла под свой контроль все вопросы по управлению сетью. Уже к концу 1980-х в разработке находилась линия T-3, которая позволяла разогнать сети до 45 Мбит/с.
О существенной части дальнейшей истории интернета мы уже рассказывали ранее. 6 августа 1991 года свет увидела Всемирная паутина, знаменитая World Wide Web, и интернет официально «встал на крыло», а к 1993 году, появился первый графический браузер Mosaic.

/ Браузер Mosaic, сыгравший важную роль в популяризации интернета
Через океан

Первый телеграфный кабель был проложен по дну Атлантического океана более чем за 100 лет до описываемых событий, в 1857 году. Тем не менее, по ряду причин (отсутствие опыта у участников экспедиции, несовершенная изоляция и пр.) уже через несколько недель этот кабель приказал долго жить. Спустя 10 лет по дну Атлантики было проложено уже несколько телеграфных кабелей с куда лучшей изоляцией, а к 1919 году их общее число увеличилось до 13.

/ Фрагмент первого телеграфного трансатлантического кабеля
К середине ХХ века возникла объективная надобность в прокладке уже телефонных кабелей. Первый телефонный кабель, ТАТ-1, был проложен в 1956 году и прослужил чуть более 20 лет.

/ Фрагмент TAT-1

/ Первые маршруты пролегания трансатлантических кабелей
До прокладки кабелей из Европы было вполне возможно позвонить в США путем длинноволновой радиосвязи. Тем не менее, эти услуги стоили весьма немало, а качество связи все равно оставляло желать лучшего.
Именно с помощью телефонного кабеля была впервые налажена связь США и Норвегии со скоростью 2,4 Кбит/с по ARPANET.
Таким образом, проект, разработанный военными для военных, стал чем-то большим и постепенно обрел независимость. Спутники, с помощью которых уже в конце 1970-х было налажено трансатлантическое соединение (SATNET), принадлежали уже не ВС США, а консорциуму стран, подключенных к сети.
Еще одним изобретением 70-х стал стандарт Ethernet, разработанный для более удобной организации локальной сети и передачи данных между компьютерами на высокой скорости. Этот стандарт в практически неизменном виде используется и сегодня.
Помимо Ethernet, еще одним важным нововведением 1970-х стал протокол UUCP (Unix to Unix Copy). Он позволял быстро обмениваться файлами между компьютерами под управлением Unix и со временем «превратился» в Usenet, сеть, с помощью которой миллионы людей до сих пор обмениваются новостями, отправляют электронную почту и файлы.
Переломный момент случился уже в следующем десятилетии и фактически создал тот интернет, которым мы сейчас пользуемся. Достаточно будет сказать, что в 1977 году к сети было подключено около 111 компьютеров, а в 1989 их число превысило 100 000.
70-е: взрывной рост интернета

/ Логическая схема ARPANET, март 1977
К 1971 году количество компьютеров, подключенных к ARPANET, выросло почти в 6 раз: теперь основу сети составляли 23 хоста. Люди ступали на новые, еще неизведанные земли, и каждый новый шаг был инновацией. Так, в первые же дни работы ARPANET был придуман и внедрен протокол NCP, Network Control Protocol. Однако еще одно изобретение стало, как сейчас это принято называть, киллер-фичей интернета: электронная почта.
Тем не менее, энтузиастам из США со временем стало тесно в пределах родной страны. Требовалось расширить горизонты коммуникации и установить связь со странами по ту сторону Атлантики. Здесь стоит сделать небольшое отступление и поговорить о том, каким образом была впервые налажена прямая «кабельная» связь между Америкой и Европой.
Школьные проекты
В то время не было WhatsApp или GoogleDocs, чтобы обсудить материал и сбросить документы. Студенты должны были встретиться лично, чтобы участвовать в обсуждении и выполнять свои школьные задания.
Телевидение
С появлением YouTube и других интернет-сервисов в наши дни трудно представить, что нужно с нетерпением ждать выхода своего любимого телешоу у экрана телевизора.
80-е: BIND и DNS
Практически все технологии, которыми мы пользуемся сегодня, проходят сходный путь от хаоса раннего применения до жесткой стандартизации и упорядочивания.
Одним из важнейших «упорядочивающих» моментов стало создание системы доменных имен, DNS. Коснемся её истории, чтобы доказать важность этого нововведения.
Ранее для хранения числовых адресов компьютеров, подключенных к ARPANET и сопоставления их с именами узлов, использовался текстовый файл HOSTS.TXT на компьютере Стэнфордского исследовательского института. Все адреса назначались сугубо вручную, и для того, чтобы запросить имя хоста и адрес, а также добавить компьютер в файл HOSTS, требовалось позвонить по телефону в сетевой информационный центр.
К началу 80-х стало понятно, что ввиду роста числа подключенных компьютеров такой способ поддержания централизованной таблицы хостов становится чрезвычайно медленным и громоздким. Требовалось автоматизировать систему именования.
Первая версия сервера имен BIND была написана студентами Беркли Дугласом Терри, Марком Пейнтером, Дэвидом Ригглом и Сонгниан Чжоу в 1984 году. В середине-конце 1980-х активно создавались и утверждались новые спецификации DNS, а к 90-м годам BIND был перенесен на платформу Windows NT. BIND до сих пор широко распространен в Unix-системах (и не только) и по-прежнему является одним из самых широко используемых ПО DNS в интернете. Внедрение DNS принесло массу других нововведений, например – принудительное использование протокола TCP/IP для подключения.
До изобретения письменности
До того, как появилось то, что можно без сомнения назвать письменностью, основным способом сохранить важные факты была устная традиция. В такой форме передавались социальные обычаи, важные исторические события, личный опыт или творчество рассказчика. Эту форму сложно переоценить, она продолжала процветать вплоть до средних веков, далеко после появления письменности. Несмотря на неоспоримую культурную ценность, устная форма — эталон неточности и искажений. Представьте себе игру в «испорченный телефон», в которую люди играют на протяжении нескольких столетий. Ящерицы превращаются в драконов, люди обретают песьи головы, а достоверную информацию о быте и нравах целых народностей невозможно отличить от мифов и легенд.

Боян
Газеты
Каждое утро людям доставляли новые газеты, и это был основной источник свежей информации и новостей.

От клинописи до печатного станка
Для большинства историков рождении цивилизации с большой буквы неотрывно связано с появлением письменности. Согласно распространенным теориям, цивилизация в современном ее понимании появляется в результате создания излишков пищи, разделения труда и появления торговли. В долине Тигра и Евфрата произошло именно это: плодородные поля дали почву торговле, а коммерция, в отличии от эпоса, требует точности. Было это примерно в 2700 г. до нашей эры, то есть 4700 лет назад. Львиная доля шумерских табличек с клинописью заполнены бесконечным рядом торговых транзакций. Не все, конечно, так банально, например, расшифровка шумерской клинописи сохранила для нас старейшую на данный момент литературную работу — «Эпос о Гильгамеше».

Глиняная табличка с клинописью
Клинопись, определенно, была отличным изобретением. Глиняные таблички неплохо сохранились, что уж говорить о клинописи, выбитой на камне. Но у клинописи есть однозначный минус — скорость, и физический (не в мегабайтах) вес итоговых «документов». Представьте, что вам нужно срочно написать и доставить несколько счетов в соседний город. С глиняными табличками такая работа может стать в буквальном смысле неподъемной.
Во многих странах, от Египта до Греции, человечество искало способы быстро, удобно и надежно фиксировать информацию. Все больше люди приходили к той или иной вариации тонких листов органического происхождения и контрастных «чернил». Это решало проблему с со скоростью и, так сказать, «емкостью» на килограмм веса. Благодаря пергаменту, папирусу и, в конечном счете, бумаге человечество получило свою первую информационную сеть: почту.
Однако, с новыми преимуществами пришли новые проблемы: все, что написано на материалах органического происхождения имеет свойство разлагаться, выцветать, да и просто гореть. В эпоху от темных веков вплоть до изобретения печатного пресса большим и важным делом было копирование книг: буквальное переписывание набело, буква за буквой. Если представить сложность и трудоемкость этого процесса, легко понять, почему чтение и письмо оставались привилегией очень узкой прослойки монашества и знатных людей. Однако в середине пятнадцатого века произошло то, что можно назвать Первой Информационной Революцией.
Зарождение виртуализации
Путь к виртуализации проложили такие устройства, как IBM 7044, Compatible Time Sharing System (CTSS), разработанный MIT на базе IBM 704, и суперкомпьютер Atlas.
IBM признала важную роль виртуализации еще в прорывных 60-х вместе с развитием мейнфреймов. Актуальная тогда System/360 Model 67 виртуализировала все интерфейсы оборудования через Virtual Machine Monitor (VMM). Кстати, на рассвете компьютерной эпохи операционную систему называли супервизором, а возможность запуска одной операционной системы на другой операционной системе положило начало термину «гипервизор». Первая ВМ появилась в супервизоре Atlas'a — суперкомпьютера, созданного в Великобритании совместно Манчестерским университетом Виктории и компаниями Ferranti и Plessey по заказу Правительства Великобритании для использования (а как иначе!) в военных целях.

/ Cуперкомпьютер Atlas
Виртуализация x86 и облака
Впервые аппаратная виртуализация была реализована в 386-х процессорах и называлась V86 mode. Режим позволял запускать параллельно несколько DOS-приложений.
В 2005-2006 году компании Intel и AMD представили решения аппаратной поддержки виртуализации — INTEL VT и AMD-V. Были введены дополнительные инструкции для предоставления прямого доступа к ресурсам процессора из гостевых систем, набор которых назывался Virtual Machine Extensions (VMX).
Уже в 2008 году в нашей стране стали появляться облачные провайдеры. Именно тогда была основана компания ИТ-ГРАД, а также запущено корпоративное облако IaaS. В 2020-ом ИТ-ГРАД — это 12 площадок в России и СНГ, а также более 2000 успешно реализованных проектов миграции в облако.
История интернета поистине необъятна, поэтому мы искренне будем рады вашим дополнениям и комментариям. В следующей статье мы расскажем о становлении сетей в СССР и проектах, которые так и не увидели свет.

Появление интернета действительно принесло нам много преимуществ и облегчило жизнь, но было время, когда люди обходились без него. Так как же они выполняли такие задачи, как исследование информации или оплата счетов? Как общались и обменивались материалом?
Мы расскажем вам, как люди жили в эпоху без интернета, до появления Всемирной паутины.
Письма
Хотя к моменту изобретения Интернета у большинства людей уже были стационарные телефоны, во многих ситуациях все равно приходилось писать письма от руки, чтобы связаться с людьми, которые живут далеко.
60-е: предпосылки появления интернета и ARPANET
Как и многие другие передовые технологии, интернет в его первичной форме зародился в военных штабах Америки. Холодная война грозила США множеством бед, в том числе, и запуском межконтинентальных ядерных ракет. Советские технологии внушали страх и трепет, а запуск первого автономного летательного аппарата в 1957 году не только подарил всему англоязычному миру неологизм «sputnik», но и заставил оборонную промышленность работать на опережение.
Одним из следствий этой работы стало создание ARPA, агентства перспективных исследовательских проектов. В компетенции агентства была разработка технологий, которые могли бы дать США весомое преимущество в Холодной войне и возглавить гонку вооружений, а в случае открытой конфронтации — помочь в защите страны.

К 1962 году агентством были сформированы первые тезисы о некой взаимосвязанной сетевой системе, которую Дж.К.Р. Ликлайдер из Массачусетского технологического института назвал «галактической сетью». Вкратце, галактическая сеть предполагала мгновенное получение доступа к любой информации в электронном виде, находящейся на множестве взаимоудаленных компьютеров. Теперь требовалось понять, как именно эти компьютеры будут связаны.

/ Дж.К.Р. Ликлайдер, гений, инноватор и крестный отец интернета
В то же самое время, благодаря исследованиям ВВС США, заказанным с целью определить, каким образом вооруженные силы смогут сохранять командование в случае ядерного удара, к «галактической сети» прибавился еще один кирпичик будущего интернета: технология коммутации пакетов (packet switching).
Поскольку США требовалось построить децентрализованную модель командования, при которой, независимо от степени нанесенного врагом ущерба, ВС не теряли бы контроль над собственным оружием, самолетами и бомбардировщиками и могли продолжать оборону, внедрение технологии коммутации пакетов решало эту задачу.
В 1968 году в США началось строительство ARPANET, сети-предшественника современного интернета, которой было суждено стать плацдармом для обкатки множества технологий, которые мы используем и по сей день.
В 1969 году, 29 октября, состоялся первый успешный сеанс связи между двумя компьютерами. Первый находился в Массачусетсе, второй – в Калифорнии, оба принадлежали местным техническим университетам. Расстояние между компьютерами составляло порядка 640 км.
В 21:00 по местному времени Чарли Клайн попытался подключиться к компьютеру Стэнфорда и передать 5 символов, слово ”LOGIN”, однако сеть оборвалась, и удалось ввести только два первых символа. В 22:30 соединение было восстановлено, и вторая попытка увенчалась успехом. Кстати, успешность передачи фиксировалась в ходе прямого телефонного разговора с Биллом Дюваллем. С третьей попытки все символы слова были получены, и интернет, можно сказать, наконец «родился».
Эксперимент показал, что компьютеры не только могут быть физически соединены друг с другом, но и способны обмениваться данными и программами. Тем не менее, способ связи с помощью низкоскоростной телефонной сети уже тогда не мог считаться надежным и приемлемым.
ARPANET был построен на базе четырех миникопьютеров Honeywell DP-516, оснащенных 24 кбайт оперативной памяти и расположенных в университетах Санта-Барбары, Лос-Анджелеса, Стэнфорда и Юты. Данные передавались со скоростью до 56 Кбит/с.

/ DDP-516

/ Один из первых IMP, выполнявших функцию маршрутизаторов и использовавшихся в ARPANET с конца 60-х по 1989 год
Команда, работающая над IMP, назвала себя «IMP Guys».
/ Команда IMP (слева направо): Трутт Тэтч, Билл Бартелл, Дейв Уолден, Джим Гейсман, Роберт Кан, Фрэнк Харт, Бен Баркер, Марти Торп, Уилл Кроутер и Северо Орнштейн. Берни Козелла на фото нет.
Фан-почта
Много лет назад, когда социальных сетей еще не существовало, единственный способ связаться с вашей любимой знаменитостью - это послать им фан-письма и надеяться, что они потрудятся открыть конверт и прочитать содержимое.
Хождение в библиотеку
Еще до того, как появился Google, люди ходили в библиотеки, чтобы читать интересные книги и собирать информацию для эссе и сочинений.

Покупка музыкальных альбомов
Люди ходили в магазины, чтобы заполучить самые горячие новинки альбомов в виде компакт-дисков или кассет.
Карты
Прежде чем получить легкий доступ к GPS, люди использовали карты или спрашивали, как проехать из точки А в точку Б.
1991-1992

В 1991 году Марк Маккэхил из университета Миннесоты создал новый сетевой протокол — Gopher. Сетевые протоколы — наборы правил и действий, позволяющие устройствам в сети обмениваться информацией. Протокол Gopher позволял быстро искать информацию, потому что состоял из вложенных друг в друга каталогов — как папки в компьютере.
Вскоре на его базе появились две новые поисковые программы — Вероника (Veronica — Very Easy Rodent-Oriented Net-wide Index to Computerized Archives ) и Джагхед (Jughead — J onzy’s Universal Gopher Hierarchy Excavation And Display ). Раз уж первую программу назвали Арчи, этим двум дали имена в честь персонажей из одноимённых комиксов. Кстати, именно на этих комиксах основан современный сериал «Ривердэйл».

Вероника (в центре), Арчи (слева), Джагхед (крайний справа)
Вероника позволяла выполнять поиск по ключевым словам почти всех заголовков в списках Gopher. А Джагхед извлекал информацию о меню от определённых Gopher-серверов. Но ни одной полноценной системы для поиска в вебе пока так и не появилось.

В начале 1990-х годов появились целые сайты-каталоги для хранения ссылок — рубрикаторы на них заполнялись вручную. В их числе, например, Yahoo! и Virtual Library (VLib), который вёл на сервере CERN изобретатель современного интернета Тим Бернерс-Ли.
В 1993 году Оскар Нирштрасс из Женевского университета написал cценарии на языке программирования Perl, которые копировали эти страницы и переписывали в стандартный формат. На их основе он и создал первую примитивную поисковую систему W3catalog.
Эта система ещё не умела сканировать все сайты подряд, она использовала составленные вручную списки веб-ресурсов.
В том же году появился первый поисковый робот, написанный на языке Perl, — World Wide Web Wanderer. Этот бот от Мэтью Грэя из Массачусетского технологического института создавал Wandex — первую систему с поиском прямо по веб-сайтам (в интернете их тогда было чуть больше 600).
В 1993 году появилась и вторая поисковая система — Aliweb. Она не использовала поискового робота, а вместо этого ждала уведомлений от администраторов веб-сайтов о наличии на их сайтах индексного файла в определённом формате.
Фотографии
Создание фотографий было целым процессом. Люди должны были сначала пойти в специальный магазин, ждать, пока пленка будет проявлена, и только тогда они могли увидеть фотографии, которыми впоследствии делились с родственниками и друзьями.

1994-1996

Первая полнотекстовая поисковая система, индексирующая ресурсы при помощи робота, — WebCrawler (1994 год). Он первым в мире позволил искать по любым словам, расположенным на любых сайтах. Кстати, WebCrawler работает до сих пор.
Этот поисковик стал весьма популярным, а вскоре по его подобию были созданы и другие новые системы. Поначалу они конкурировали с сайтами-каталогами вроде Yahoo!, но вскоре всем стало ясно: поиск по текстам победил. Большинство каталогов объединилось с поисковыми роботами и тоже стало поисковыми системами.
Одним из самых известных поисковиков стала появившаяся в 1995 году AltaVista («взгляд сверху», «другая точка зрения»). До неё системы не работали с естественным языком: запрос надо было формулировать так, чтобы его «понял робот». А тут достаточно было напечатать любую фразу или вопрос, чтобы получить ответ.
В одноимённой песне группы «Сплин» 1999 года Александр Васильев обыграл и название поисковика, и изначальный смысл слова «альтависта».
На глубине прорвётся сквозь сеть твоя Альтависта. И ты сыграешь азбуку Морзе, симфонию Глюка на клавиатуре. Так, что навсегда уходящее солнце замрёт в этом жарком июле.
А в 1996 году появилась российская поисковая система «Рамблер» (rambler — странник, бродяга). В России она была весьма популярна вплоть до 2011 года, а потом превратилась в медиапортал персонализированных новостей.

Возможно, вы не знали, но «Яндекс» появился на свет раньше, чем Google. Система была анонсирована 23 сентября 1997 года , хотя разработки велись ещё до этого. Название поисковика можно расшифровать двумя способами: yet another indexer («ещё один индексатор») или как «Языковой Индекс».
В 1990-е годы «Яндекс» действительно был «ещё одним поисковиком», ведь в России и в мире уже было множество подобных систем. Но к 2001 году он обогнал «Рамблер» в рунете, научился понимать вопросы на естественном языке, распознавать ошибки и опечатки и начал свой путь к настоящему триумфу.

Если машина времени перенесла вас в 1998 год, вам повезло, и вы сможете гуглить по-настоящему. Ещё в 1996 году студенты Стэнфорда Ларри Пейдж и Сергей Брин начали работать над поисковой системой BackRub, а потом на её основе создали Google.
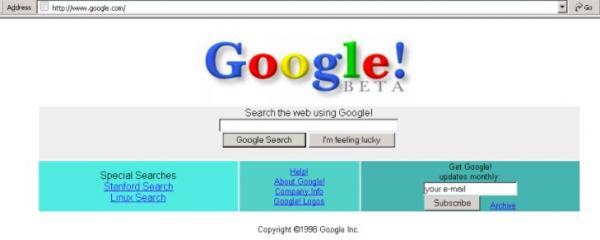
Благодаря лучшим алгоритмам Google и «Яндекс» стали международным и региональным лидерами. Создатели же первых поисковиков либо бросили это занятие, либо перешли на работу в крупные интернет-компании, выкупившие их системы целиком.
Сейчас Google — первая по популярности в мире система, которая обрабатывает больше 41 миллиарда запросов в месяц и индексирует больше 25 миллиардов веб-страниц.
А «Яндекс» называют национальным достоянием — и это неудивительно. Почти нигде в мире нет такого, чтобы местная поисковая система была не менее популярна, чем американская (другие исключения — Китай и Южная Корея). К тому же, Россия — единственная в мире страна, где без помощи США было создано больше одной успешной поисковой технологии.
Впрочем, некоторые пользователи интернета отказываются от поиска в Google и «Яндекс» из-за так называемого пузыря фильтров. Эти системы угадывают, что пользователь хотел бы увидеть, основываясь на его прошлых действиях в системе. В результате человек каждый раз получает выдачу, которая соответствует его интересам, перестаёт видеть информацию, которая противоречит его взглядам и остаётся в изоляции в собственном «информационном пузыре».
На волне борьбы с пузырём фильтров популярность потихоньку набирают другие системы, отказавшиеся от слежки и подтасовки результатов выдачи. Например, созданная в 2008 году DuckDuckGo позиционирует себя в качестве поисковика, который сохраняет конфиденциальность и показывает всё по запросу пользователя.
Вопросы кибербезопасности и ухода от слежки в последнее время волнуют многих людей. Так, владельцам айфонов стоит пристально изучить свои настройки, чтобы удостовериться, что их разговоры с Siri не прослушают другие люди.
А тем, у кого смартфон на Android, нужно беспокоиться о вездесущем Google. Компания получает данные о ваших перемещениях, даже если их отслеживание отключено. И проверить это можно в своём личном гугл-аккаунте.
Наше время часто называют информационным веком. Однако информация была критически важна для рода человеческого на протяжении всего его существования. Человек никогда не был самым быстрым, самым сильным и выносливым животным. Своим положением в пищевой цепи мы обязаны двум вещам: социальности и способности передавать информацию более чем через одно поколение.

То, как информация хранилась и распространялась сквозь века, продолжает оставаться буквально вопросом жизни и смерти: от выживания племени и сохранения рецептов традиционной медицины до выживания вида и обработки сложных климатических моделей.
Посмотрите на инфографику (кликабельна для просмотра в полной версии). Она отображает эволюцию устройств хранения данных, и масштабы действительно впечатляют. Однако эта картинка далека от совершенства — она охватывает каких-то несколько десятилетий истории человечества, уже живущего в информационном обществе. А между тем данные накапливались, транслировались и хранились с того момента, откуда нам известна история человечества. Сперва это была обычная человеческая память, а в недалёком будущем мы уже ждём хранения данных в голографических слоях и квантовых системах. На Хабре уже неоднократно писали про историю магнитных накопителей, перфокарты и диски размером с дом. Но ещё ни разу не было проделано путешествие в самое начало, когда не было железных технологий и понятия данных, но были биологические и социальные системы, которые научились накапливать, сохранять, транслировать информацию. Попробуем сегодня прокрутить всю историю в рамках одного поста.

Источник изображения: Flickr
От Гутенберга до лампы
Попытки упростить и ускорить набор текста с помощью комплектов заранее отлитых словоформ или букв и ручного пресса предпринимали еще в Китае в 11 веке. Почему же мы мало знаем об этом и привыкли считать родиной печати Европу? Распространению наборной печати в Китае помешала их собственная сложная письменность. Производство литер для полноценной печати на китайском было слишком трудоемким.
Благодаря Гутенбергу же, у книг появилось понятие экземпляра. Библия Гутенберга была отпечатана 180 раз. 180 копий текста, и каждая копия повышает вероятность, что пожары, наводнения, ленивые переписчики, голодные грызуны не будут помехой для будущих поколений читателей.

Печатный станок Гутенберга
Ручной пресс и ручной подбор литер, однако, не являются, конечно, оптимальным по скорости и трудозатратам процессом. С каждым столетием человеческое общество стремилось не только найти способ сохранить информацию, но и распространить ее как можно более широкому кругу лиц. С развитием технологий, эволюционировала как печать, так и производство копий.
Ротационная печатная машина была изобретена в конце девятнадцатого века, и ее вариации используются вплоть до сегодняшнего дня. Эти махины, с непрерывно вращающимися валами, на которых закреплены печатные формы, были квинтэссенцией индустриального подхода и символизировали очень важный этап в информационном развитии человечества: информация стала массовой, благодаря газетам, листовкам и подешевевшим книгам.
Массовость, однако, не всегда идет на пользу конкретному кусочку информации. Основной носитель, бумага и чернила, все так же подвержены износу, ветхости, утере. Библиотеки, полные книг по всем возможным областям человеческих знаний, становились все более объемны, занимая огромные пространства и требуя все больше ресурсов для своего обслуживания, каталогизации и поиска.
Очередной сдвиг парадигмы в сфере хранения информации произошел после изобретения фотопроцесса. Нескольким инженерам пришла в голову светлая мысль, что миниатюрные фотокопии технических документов, статей и даже книг могут продлить исходникам жизнь и сократить необходимое для их хранения место. Получившиеся в результате подобного мыслительного процесса микрофильмы (миниатюрные фотографии и оборудование для их просмотра) вошли в обиход в финансовых, технических и научных кругах в 20-х годах двадцатого века. У микрофильма много плюсов — этот процесс сочетает в себе легкость копирования и долговечность. Казалось, что развитие способов хранения информации достигло своего апогея.

Микроплёнка, используется до сих пор
От перфокарт и магнитных лент к современным ЦОДам
Инженерные умы пытались придумать универсальный метод обработки и хранения информации еще с 17-го века. Блез Паскаль, в частности, заметил, что если вести вычисления в двоичной системе счисления, то математические закономерности позволяют привести решения задач в такой вид, который делает возможным создание универсальной вычислительной машины. Его мечта о такой машине осталась лишь красивой теорией, однако, спустя века, в середине 20-го века, идеи Паскаля воплотились в железе и породили новую информационную революцию. Некоторые считают, что она все еще продолжается.
То, что сейчас принято называть «аналоговыми» методами хранения информации, подразумевает, что для звука, текста, изображений и видео использовались свои технологии фиксации и воспроизведения. Компьютерная память же универсальна — все, что может быть записано, выражается с помощью нулей и единиц и воспроизводится с помощью специализированных алгоритмов. Самый первый способ хранения цифровой информации не отличался ни удобством, ни компактностью, ни надежностью. Это были перфокарты, простые картонки с дырками в специально отведенных местах. Гигабайт такой «памяти» мог весить до 20 тонн. В такой ситуации сложно было говорить о грамотной систематизации или резервном копировании.

Перфокарта
Компьютерная индустрия развивалась стремительно и быстро проникала во все возможные области человеческой деятельности. В 50-х годах инженеры «позаимствовали» запись данных на магнитную ленту у аналоговой аудио и видеозаписи. Стримеры с кассетами объемом до 80 Мб использовались для хранения и резервного копирования данных вплоть до 90-х годов. Это был неплохой способ с относительно продолжительным сроком хранения (до 50 лет) и небольшим размером носителя? Кроме того, удобство их использования и стандартизация форматов хранения данных ввела понятие резервного копирования в бытовой обиход.

Один из первых жёстких дисков IBM, 5 МБ
У магнитных лент и систем, связанных с ними, есть один серьезный недостаток — это последовательный доступ к данным. То есть, чем дальше запись находится от начала ленты, тем больше времени потребуется для того, чтобы ее прочитать.
В 70-х годах 20-го века был произведен первый «жесткий диск» (HDD) в том формате, в котором он знаком нам сегодня — комплект из нескольких дисков с намагничивающимся материалом и головками для чтения/записи. Вариации этой технологии используются и сегодня, постепенно уступая в популярности твердотельным накопителям (SSD). Начиная с этого момента, в течении всего компьютерного бума 80-х формируются основные парадигмы хранения, защиты и резервного копирования информации. Благодаря массовому распространению бытовых и офисных компьютеров, не обладающих большим объемом памяти и вычислительной мощности, укрепилась модель «клиент-сервер». По началу «сервера» были по большей части локальными, своими для каждой организации, института или фирмы. Не было какой-то системы, правил, информация дублировалась в основном на дискеты или магнитные ленты.
Появление интернета, однако, подстегнуло развитие систем хранения и обработки данных. В 90-х годах, на заре «пузыря доткомов» начали появляться первые дата-центры, или ЦОД-ы (центры обработки данных). Требования к надежности и доступности цифровых ресурсов росли, вместе с ними росла сложность их обеспечения. Из специальных комнат в глубине предприятия или института дата-центры превратились в отдельные здания со своей хитрой инфраструктурой. В то же время, у ЦОД-ов кристаллизовалась своего рода анатомия: сами компьютеры (серверы), системы связи с интернет-провайдерами и все, что касается инженерных коммуникаций (охлаждение, системы пожаротушения и физического доступа в помещения).
Чем ближе к сегодняшнему дню, тем больше мы зависим от данных, хранящихся где-то в «облаках» ЦОД-ов. Банковские системы, электронная почта, онлайн-энциклопедии и поисковые движки — все это стало новым стандартом жизни, можно сказать, физическим продолжением нашей собственной памяти. То, как мы работаем, отдыхаем и даже лечимся, всему этому можно навредить простой утерей или даже временным отключением от сети. В двухтысячных годах были разработаны стандарты надежности дата центров, от 1-го до 4-го уровня.
Тогда же из космической и медицинской отраслей начали активно проникать технологии резервирования. Конечно, копировать и размножать информацию с тем, чтобы защитить ее в случае уничтожения оригинала люди умели давно, но именно дублирование не только носителей данных, но и различных инженерных систем, а также необходимость предусматривать точки отказала и возможных человеческих ошибок отличает серьезные ЦОДы. Например, ЦОД, принадлежащий к Tier I будет лишь ограниченную избыточность хранения данных. В требования к Tier II уже прописано резервирование источников питания и наличие защиты от элементарных человеческих ошибок, а Tier III предусматривает резервирование всех инженерных систем и защиту от несанкционированного проникновения. Наконец, высший уровень надежности ЦОДа, четвертый, требует дополнительное дублирование всех резервных систем и полное отсутствие точек отказа. Кратность резервирования (сколько именно резервных элементов приходится на каждый основной) обычно обозначается буквой M. Со временем требования к кратности резервирования только росли.
Построить ЦОД уровня надежности TIER-III, — это проект, с которым справится только исключительно квалифицированная компания. Такой уровень надежности и доступности означает, что, как инженерные коммуникации, так и системы связи дублированы, и дата-центр имеет право на простой только в количестве около 90 минут в год.
У нас в Safedata такой опыт есть: в январе 2014 года в рамках сотрудничества с Российским Научным Центром «Курчатовский Институт» нами был введен в эксплуатацию второй дата-центр SAFEDATA — Москва-II, который также отвечает требованиям уровня TIER 3 стандарта TIA-942, ранее же (2007-2010) мы построили дата-центр Москва-I, который отвечает требованиям уровня TIER 3 стандарта TIA-942 и относится к категории центров хранения и обработки данных с защищенной сетевой инфраструктурой.
Мы видим, что в IT происходит еще одна смена парадигмы, и связана она с data science. Обработка и хранение больших объемов данных становятся актуальны как никогда. В каком-то смысле, любой бизнес должен быть готов стать немного учеными: вы собираете огромное количество данных о ваших клиентах, обрабатываете их и получаете для себя новую перспективу. Для реализации таких проектов потребуется аренда большого количества мощных серверных машин и эксплуатация будет не самой дешевой. Либо, возможно, ваша внутренняя ИТ-система настолько сложна, что на поддержание ее уходит слишком много ресурсов компании.
В любом случае, для каких бы целей вам не понадобились значительные вычислительные мощности, у нас есть услуга «Виртуального ЦОДа». Инфраструктура как сервис — не новое направление, однако мы выгодно отличаемся целостным подходом, начиная от специфически ИТ-шных проблем, вроде переноса корпоративных ресурсов в «Виртуальный ЦОД», до юридических, таких как консультация по актуальному законодательству РФ в сфере защиты данных.
Развитие информационных технологий похоже на беспощадно несущийся вперед поезд, не все успевают запрыгнуть в вагон когда им предоставляется возможность. Где-то до сих пор используют бумажные документы, в старых архивах хранятся сотни не оцифрованных микрофильмов, государственные органы могут до сих пор использовать дискеты. Прогресс никогда не бывает линейно-равномерным. Никто не знает, сколько важных вещей мы в результате навсегда потеряли и какое количество часов было потрачено из-за до сих пор не вполне оптимальных процессов. Зато мы в Safedata знаем, как не допустить пустых трат и невосполнимых потерь конкретно в вашем случае.
Сейчас в обжитой части планеты практически не осталось точек, где не найдется ни одного, даже самого завалящего способа подключиться к интернету. И речь идет вовсе не о конечных устройствах пользователей, а о том, что практически весь земной шар опутан коммуникационными линиями, а там, где возможности проложить кабель нет, приходят на помощь спутники.
Но Москва не сразу строилась, и язык не всегда до Киева доводил. История становления всемирной паутины, начавшаяся более полувека назад, многогранна и интересна. Мы решили продолжить наш рассказ о развитии интернета, и сегодня хотим разобраться, пробежавшись по десятилетиям, как именно происходило становление инфраструктуры, как одни технологии сменялись другими, и мир телекоммуникаций становился таким, каким мы знаем его сегодня.

Двадцатый век с точки зрения информации вполне можно определить как эпоху, когда люди научились транслировать данные из одного источника миллионам удаленных устройств. В качестве источника выступали радио- и телевещательные станции, а получателями были все, кто имел доступ к радио или телевизору.
В то же самое время активно развивались и телефонные сети. К середине XX века практически любой человек мог запросто позвонить в любую точку родного города или страны, а компании могли собирать телефонные конференции для нескольких абонентов одновременно.
Читайте также: