
Каким образом текстовая информация представлена в памяти компьютера
Обращаем Ваше внимание, что в соответствии с Федеральным законом N 273-ФЗ «Об образовании в Российской Федерации» в организациях, осуществляющих образовательную деятельность, организовывается обучение и воспитание обучающихся с ОВЗ как совместно с другими обучающимися, так и в отдельных классах или группах.
Рабочие листы и материалы для учителей и воспитателей
Более 2 500 дидактических материалов для школьного и домашнего обучения
Столичный центр образовательных технологий г. Москва
Получите квалификацию учитель математики за 2 месяца
от 3 170 руб. 1900 руб.
Количество часов 300 ч. / 600 ч.
Успеть записаться со скидкой
Форма обучения дистанционная
- Онлайн
формат - Диплом
гособразца - Помощь в трудоустройстве
311 лекций для учителей,
воспитателей и психологов
Получите свидетельство
о просмотре прямо сейчас!
Дискретное представление информации
Кодирование – преобразование входной информации в форму, воспринимаемую компьютером, то есть двоичный код.
Декодирование – преобразование данных из двоичного кода в форму, понятную человеку.
С точки зрения технической реализации использование двоичной системы счисления для кодирования информации оказалось намного более простым, чем применение других способов. действительно, удобно кодировать информацию в виде последовательности нулей и единиц, если представить эти значения как два возможных устойчивых состояния электронного элемента:
0 – отсутствие электрического сигнала;
1 – наличие электрического сигнала.
Эти состояния легко различать. Недостаток двоичного кодирования – длинные коды. но в технике легче иметь дело с большим количеством простых элементов, чем с небольшим числом сложных.
Способы кодирования и декодирования информации в компьютере, в первую очередь, зависит от вида информации, а именно, что должно кодироваться: числа, текст, графические изображения или звук.
Аналоговый и дискретный способ кодирования
Человек способен воспринимать и хранить информацию в форме образов (зрительных, звуковых, осязательных, вкусовых и обонятельных). Зрительные образы могут быть сохранены в виде изображений (рисунков, фотографий и так далее), а звуковые – зафиксированы на пластинках, магнитных лентах, лазерных дисках и так далее.
Информация, в том числе графическая и звуковая, может быть представлена в аналоговой или дискретной форме. При аналоговом представлении физическая величина принимает бесконечное множество значений, причем ее значения изменяются непрерывно. При дискретном представлении физическая величина принимает конечное множество значений, причем ее величина изменяется скачкообразно.
Примером аналогового представления графической информации может служить, например, живописное полотно, цвет которого изменяется непрерывно, а дискретного – изображение, напечатанное с помощью струйного принтера и состоящее из отдельных точек разного цвета. Примером аналогового хранения звуковой информации является виниловая пластинка (звуковая дорожка изменяет свою форму непрерывно), а дискретного – аудиокомпакт-диск (звуковая дорожка которого содержит участки с различной отражающей способностью).
Преобразование графической и звуковой информации из аналоговой формы в дискретную производится путем дискретизации, то есть разбиения непрерывного графического изображения и непрерывного (аналогового) звукового сигнала на отдельные Элементы. В процессе дискретизаЦии производится кодирование, то есть присвоение каждому элементу конкретного значения в форме кода.
Дискретизация – это преобразование непрерывных изображений и звука в набор дискретных значений в форме кодов.
Кодирование текстовой информации
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вспомним некоторые известные нам факты:
Множество символов, с помощью которых записывается текст, называется алфавитом .
Число символов в алфавите – это его мощность .
Формула определения количества информации: N = 2 b ,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
От начала 90-х годов, времени господства операционной системы MS DOS , остается кодировка CP 866 (" CP " означает " Code Page ", "кодовая страница").
Компьютеры фирмы Apple , работающие под управлением операционной системы Mac OS , используют свою собственную кодировку Mac .
Кроме того, Международная организация по стандартизации ( International Standards Organization , ISO ) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows , обозначаемая сокращением CP 1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode . Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов
Использование компьютера для обработки звука началось позднее, нежели чисел, текстов и графики.
Звук – волна с непрерывно изменяющейся амплитудой и частотой. чем больше амплитуда, тем он громче для человека, чем больше частота, тем выше тон.
Звуковые сигналы в окружающем нас мире необычайно разнообразны. Сложные непрерывные сигналы можно с достаточной точностью представлять в виде суммы некоторого числа простейших синусоидальных колебаний. Причем каждое слагаемое, то есть каждая синусоида, может быть точно задана некоторым набором числовых параметров – амплитуды, фазы и частоты, которые можно рассматривать как код звука в некоторый момент времени.
В процессе кодирования звукового сигнала производится его временная дискретизация – непрерывная волна разбивается на отдельные маленькие временные участки и для каждого такого участка устанавливается определенная величина амплитуды.
Таким образом, непрерывная зависимость амплитуды сигнала от времени заменяется на дискретную последовательность уровней громкости.
Каждому уровню громкости присваивается его код. Чем большее количество уровней громкости будет выделено в процессе кодирования, тем большее количество информации будет нести значение каждого уровня и тем более качественным будет звучание.
Качество двоичного кодирования звука определяется глубиной кодирования и частотой дискретизации.
Частота дискретизации – количество измерений уровня сигнала в единицу времени.
Количество уровней громкости определяет глубину кодирования . Современные звуковые карты обеспечивают 16-битную глубину кодирования звука. При этом количество уровней громкости равно N = 2^16 = 65536.
Для компьютера любой текст – это линейная последовательность символов. Причем это не только обычные символы, но и пробелы между словами, а также другие специальные символы: переход на следующую строчку, переход на следующую страницу и т.п. Каждому символу из этой последовательности соответствует конкретный двоичный код.
Для перевода информации из машинного представления в человеческий необходимы таблицы кодировки символов – таблицы соответствия между символами определенного языка и кодами символов. Их еще называют кодовыми страницами (code page, или сокр. CP), известен также английский термин character set (который иногда сокращают до charset).
Самой известной таблицей кодировки является код ASCII - американский стандартный код для обмена информацией. Первоначально он был разработан для передачи текстов по телеграфу, причем в то время он был 7-битовым, т. е. для кодирования символов английского языка, служебных и управляющих символов использовались только 128 семибитовых комбинаций. При разработке первых компьютеров фирмы IBM этот код был использован для представления символов в компьютере. Поскольку в исходном коде ASCII было всего 128 символов, для их кодирования хватило значений байта (восьмой бит равен нулю). Список этих символов и соответствующие им восьмиразрядные (т. е. состоящие из восьми двоичных разрядов) двоичные коды образуют основную (базовую) кодовую таблицу ASCII.
Когда стали приспосабливать компьютеры для других стран и языков, места для новых символов уже не стало хватать. Для того чтобы полноценно поддерживать помимо английского и другие языки, фирма IBM ввела в употребление несколько кодовых таблиц, ориентированных на конкретные страны. Так, для скандинавских стран была предложена таблица 865 (Nordic), для арабских стран – таблица 864 (Arabic), для Израиля – таблица 862 (Israel) и т. д. В этих таблицах часть кодов из второй половины кодовой таблицы (т.е. те, для которых восьмой бит равен единице) использовалась для представления символов национальных алфавитов (за счет исключения некоторых символов псевдографики). Вариант кодовой страницы, используемый в США и большинстве европейских стран, называется code page 437 (CP437).
Альтернативная кодировка — основанная на CP437 кодовая страница, где все специфические европейские символы во второй половине заменили на кириллицу, оставляя псевдографические символы нетронутыми. Следовательно, это не портит вид программ, использующих для работы текстовые окна, а также обеспечивает использование в них символов кириллицы. Альтернативной кодовой таблицей называют кодировку IBM CP866, поддержка которой была добавлена в MS-DOS версии 6.22. Эта кодировка используется в консоли русифицированных систем семейства Windows NT.
Вне среды MS-DOS в Microsoft Windows кодировка IBM CP866 заменена стандартной кодировкой CP1251, а в операционных системах Windows NT и следующих за ней (Windows 2000, Windows XP, Windows Server 2003, Windows Vista, Windows Server 2008) – кодировкой Юникод.
В табл. 4.4 и 4.5 под каждым символом указан его десятичный код, номер строки и столбца дает шестнадцатеричный код. Пример: символ «Я» имеет код 15910 и 9F16
Таблица 4.4. Альтернативная кодовая таблица (CP866)
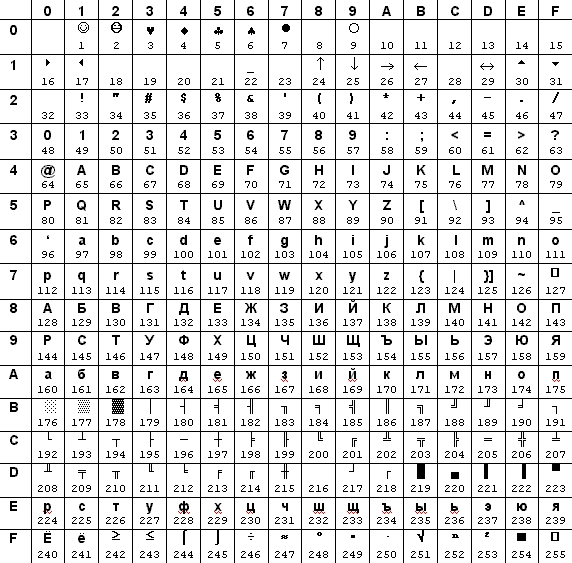
Таблица 4.5. Кодовая таблица Windows (CP1251)
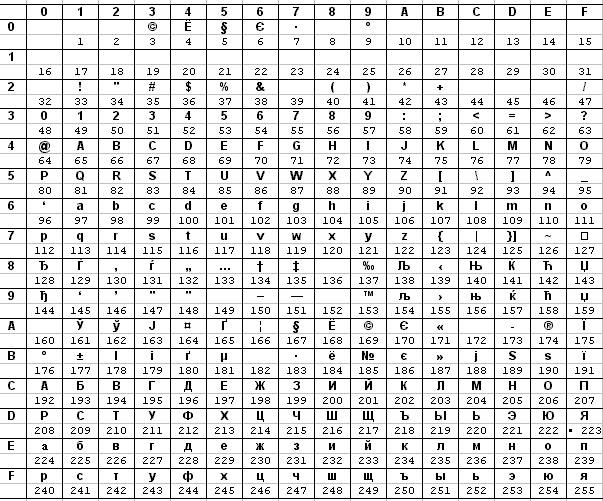
Пример 4.6. Так будет выглядеть слово «Информатика» в различных кодировках в шестнадцатеричной системе счисления:
| Слово | И | н | ф | о | р | м | а | т | и | к | а |
| В альтернативной кодировке | AD | E4 | AE | E0 | AC | A0 | E2 | A8 | AA | A0 | |
| В CP1251 | C8 | ED | F4 | EE | F0 | EC | E0 | F2 | E8 | EA | E0 |
Юникод. Для таких языков, как китайский или японский, 256 символов недостаточно. Кроме того, всегда существует проблема вывода или сохранения в одном файле одновременно текстов на разных языках. Поэтому была разработана универсальная кодовая таблица Юникод (UNICODE), содержащая символы, применяемые в языках всех народов мира, а также различные служебные и вспомогательные символы (знаки препинания, математические и технические символы, стрелки, диакритические знаки и т.д.). Очевидно, что байта недостаточно для кодирования такого большого множества символов. Поэтому в Юникоде используются 16-битовые (2-байтовые) коды, что позволяет представить 65 536 символов. К настоящему времени задействовано около 49 000 кодов. Последнее значительное изменение произошло в сентябре 1998 года в связи с введением символа валюты EURO.
ЭТО СВЯЗАНО С ТЕМ, ЧТО ИНФОРМАЦИЮ, ПРЕДСТАВЛЕННУЮ В ТАКОМ ВИДЕ, ЛЕГКО ТЕХНИЧЕСКИ СМОДЕЛИРОВАТЬ, НАПРИМЕР В ВИДЕ ЭЛЕКТРИЧЕСКИХ СИГНАЛОВ. Если в какой-то момент времени по проводнику идет ток, то по нему передается единица, если тока нет- ноль. Аналогично, если направление магнитного поля на каком-то участке поверхности магнитного диска одно- на этом участке записан ноль, другое- единица. Если определенный участок поверхности оптического диска отражает лазерный луч- на нем записан ноль, не отражает- единица. Оперативная память состоит из очень большого числа триггеров- электронных схем, состоящих из двух транзисторов. Триггер может сколь угодно долго находиться в одном из двух состояний- когда один транзистор открыт, а другой закрыт, или наоборот. Одно состояние обозначается нулем, а другое единицей.
ОБЪЕМ ИНФОРМАЦИИ, НЕОБХОДИМЫЙ ДЛЯ ЗАПОМИНАНИЯ ОДНОГО ИЗ ДВУХ СИМВОЛОВ-0 ИЛИ 1, НАЗЫВАЕТСЯ 1 БИТ (англ. binary digit- двоичная единица). 1 бит- минимально возможный объем информации. Он соответствует промежутку времени, в течение которого по проводнику передается или не передается электрический сигнал, участку поверхности магнитного диска, частицы которого намагничены в том или другом направлении, участку поверхности оптического диска, который отражает или не отражает лазерный луч, одному триггеру, находящемуся в одном из двух возможных состояний.
Итак, если у нас есть один бит, то с его помощью мы можем закодировать один из двух символов- либо 0, либо 1.
Если же есть 2 бита, то из них можно составить один из четырех вариантов кодов: 00 , 01 , 10 , 11 .
Если есть 3 бита- один из восьми: 000 , 001 , 010 , 100 , 110 , 101 , 011 , 111 .
1 бит- 2 варианта,
2 бита- 4 варианта,
3 бита- 8 вариантов;
Продолжая дальше, получим:
4 бита- 16 вариантов,
5 бит- 32 варианта,
6 бит- 64 варианта,
7 бит- 128 вариантов,
8 бит- 256 вариантов,
9 бит- 512 вариантов,
10 бит- 1024 варианта,
N бит - 2 в степени N вариантов.
В обычной жизни нам достаточно 150-160 стандартных символов (больших и маленьких русских и латинских букв, цифр, знаков препинания, арифметических действий и т.п.). Если каждому из них будет соответствовать свой код из нулей и единиц, то 7 бит для этого будет недостаточно (7 бит позволят закодировать только 128 различных символов), поэтому используют 8 бит.
ДЛЯ КОДИРОВАНИЯ ОДНОГО ПРИВЫЧНОГО ЧЕЛОВЕКУ СИМВОЛА В ЭВМ ИСПОЛЬЗУЕТСЯ 8 БИТ, ЧТО ПОЗВОЛЯЕТ ЗАКОДИРОВАТЬ 256 РАЗЛИЧНЫХ СИМВОЛОВ.
СТАНДАРТНЫЙ НАБОР ИЗ 256 СИМВОЛОВ НАЗЫВАЕТСЯ ASCII ( произносится "аски", означает "Американский Стандартный Код для Обмена Информацией"- англ. American Standart Code for Information Interchange).
ОН ВКЛЮЧАЕТ В СЕБЯ БОЛЬШИЕ И МАЛЕНЬКИЕ РУССКИЕ И ЛАТИНСКИЕ БУКВЫ, ЦИФРЫ, ЗНАКИ ПРЕПИНАНИЯ И АРИФМЕТИЧЕСКИХ ДЕЙСТВИЙ И Т.П.
Таким образом, если человек создает текстовый файл и записывает его на диск, то на самом деле каждый введенный человеком символ хранится в памяти компьютера в виде набора из восьми нулей и единиц. При выводе этого текста на экран или на бумагу специальные схемы - знакогенераторы видеоадаптера (устройства, управляющего работой дисплея) или принтера образуют в соответствии с этими кодами изображения соответствующих символов.
Набор ASCII был разработан в США Американским Национальным Институтом Стандартов (ANSI), но может быть использован и в других странах, поскольку вторая половина из 256 стандартных символов, т.е. 128 символов, могут быть с помощью специальных программ заменены на другие, в частности на символы национального алфавита, в нашем случае - буквы кириллицы. Поэтому например, передавть по электронной почте за границу тексты, содержащие русские буквы, бессмысленно. В англоязычных странах на экране дисплея вместо русской буквы Ь будет высвечиваться символ английского фунта стерлинга, вместо буквы р - греческая буква альфа, вместо буквы л - одна вторая и т.д.

ОБЪЕМ ИНФОРМАЦИИ, НЕОБХОДИМЫЙ ДЛЯ ЗАПОМИНАНИЯ ОДНОГО СИМВОЛА ASCII НАЗЫВАЕТСЯ 1 БАЙТ.
Очевидно что, поскольку под один стандартный ASCII-символ отводится 8 бит,
Остальные единицы объема информации являются производными от байта:
1 КИЛОБАЙТ = 1024 БАЙТА И СООТВЕТСТВУЕТ ПРИМЕРНО ПОЛОВИНЕ СТРАНИЦЫ ТЕКСТА,
1 МЕГАБАЙТ = 1024 КИЛОБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 500 СТРАНИЦАМ ТЕКСТА,
1 ГИГАБАЙТ = 1024 МЕГАБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 2 КОМПЛЕКТАМ ЭНЦИКЛОПЕДИИ,
1 ТЕРАБАЙТ = 1024 ГИГАБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 2000 КОМПЛЕКТАМ ЭНЦИКЛОПЕДИИ.
Обратите внимание, что в информатике смысл приставок кило- , мега- и других в общепринятом смысле выполняется не точно, а приближенно, поскольку соответствует увеличению не в 1000, а в 1024 раза.
СКОРОСТЬ ПЕРЕДАЧИ ИНФОРМАЦИИ ПО ЛИНИЯМ СВЯЗИ ИЗМЕРЯЕТСЯ В БОДАХ.
1 БОД = 1 БИТ/СЕК.
В частности, если говорят, что пропускная способность какого-то устройства составляет 28 Килобод, то это значит, что с его помощью можно передать по линии связи около 28 тысяч нулей и единиц за одну секунду.
А теперь от обсуждения вопроса о том, что представляет собой компьютер, перейдем к ответу на вопрос, что умеет делать компьютер. Начиная с этой главы, мы будем знакомиться с применением ЭВМ.
Первая область применения, которую мы рассмотрим — работа с текстами .
Тѐкст - связанная и полная последовательность символов.
При ручной записи часто приходиться исправлять ошибки или вносить какие-то изменения в текст. При этом нужно зачеркивать, стирать, заклеивать, что портит вид текста, а переписывать текст ведет к потере времени и лишнему расходу бумаги.
Имея компьютер, можно создавать тексты, не тратя на это лишнее время и бумагу.

Носителем текста становится память ЭВМ. Конечно, для длительного его сохранения это должна быть внешняя память — магнитные или оптические диски.
Текст на внешних носителях сохраняется в виде файла.
Есть ряд преимуществ сохранения текстов в файловой форме на компьютерных носителях по сравнению с бумагой:
- v Компактное размещение.
- v Если данный текст становится ненужным, то текст можно просто стереть.
- v С помощью компьютера легко скопировать файлы в любом количестве на другие носители.
- v Файл с текстом можно быстро переслать другому человеку по электронной почте.
Главное неудобство хранения текстов в файлах состоит в том, что прочитать их можно только с помощью компьютера. Человек может просмотреть текст на экране дисплея или напечатать на бумаге, используя принтер.
Представьте себе, что вся ваша личная библиотека разместится в коробке с дисками. Причем по объему информации она будет не меньше, чем сотни книг, собранных родителями. А экономя бумагу, мы сохраняем леса на нашей планете.
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других.
Алфавѝт - множество всех символов, с помощью которых записывается текст.
Число символов в алфавите — его м̀ощность.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов.
Один символ такого алфавита несет 8 битов информации: 2 8 = 256. 8 битов = 1 байт, следовательно:
один символ в компьютерном тексте занимает 1 байт памяти.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода .
Двоѝчный код - это способ представления данных в виде комбинации двух знаков, обычно обозначаемых цифрами 0 и 1.

Из памяти компьютера текст может быть выведен на экран или на печать в символьной форме.
Наиболее существенное отличие компьютерного текста от бумажного вы почувствуете, если встретитесь с текстом, информация в котором организована по принципу гипертекста.
Гипертѐкст — это текст, содержащий указатели на другие документы.
Гиперсс̀ылка - часть гипертекстового документа, ссылка на другой элемент.
Чаще всего по принципу гипертекста организованы компьютерные справочники, энциклопедии, учебники. Такую «книгу» можно читать не только в обычном порядке, "листая страницы" на экране, но и перемещаясь по смысловым связям в произвольном порядке.
Для представления целых чисел в компьютере существуют два представления: беззнаковое (для неотрицательных чисел) и знаковое.
В беззнаковом целом все разряды используются для двоичной записи числа. Соответственно, в n-разрядной сетке можно представить числа от 0 до 2 n -1. (Для 1-байтного беззнакового целого диапазон значений будет от 0 до 255; для 2-байтного — от 0 до 65535).
Если нужно представлять не только положительные, но и отрицательные значения, обычно используют дополнительный код. Он имеет следующие особенности:
- старший («знаковый») разряд отрицательного числа имеет значение 1, а положительного — 0;
- число 0 (ноль) имеет единственное представление, в котором все разряды равны нулю;
- сложение чисел со знаком в дополнительном коде выполняется так же, как сложение чисел без знака, включая знаковый разряд, который при сложении ничем не отличается от других разрядов.
Для положительных чисел дополнительный код совпадает с прямым (т.е. фактически его двоичной записью).
Для отрицательных — 2 n -|m|, где m — кодируемое число, n — количество разрядов в сетке.
Фактически, дополнительный код — это число, которое нужно добавить к модулю исходного, чтобы достичь переполнения разрядной сетки. От этого и происходит название «дополнительный».
Для получения дополнительного кода отрицательного числа следует сделать следующее:
- Записать модуль числа в прямом коде.
- Инвертировать каждый разряд получившейся записи (заменить нули на единицы, а единицы — на нули). Получится так называемый «обратный код».
- Прибавить к результату единицу.
Пример работы с числами в дополнительном коде
7210 = 10010002. Запись в восьмиразрядной сетке: 01001000.
Таким образом получаем запись в дополнительном коде: 11010010.
Сложим полученные числа:
Перенос из старшего разряда выходит за разрядную сетку и просто отбрасывается: 00011010.
Полученное число переведем в десятичную систему счисления:
Действительно, 72 - 46 = 26.
Числа с плавающей точкой
Для представления вещественных (действительных) чисел в современных компьютерах принят способ представления с плавающей точкой (запятой). Этот способ представления опирается на нормализованную (ее еще называют экспоненциальной) запись действительных чисел.
Нормализованная запись отличного от нуля действительного числа — это запись вида a = m * P q , где q — целое число, а m — правильная P-ичная дробь, у которой первая цифра после запятой не равна нулю, то есть
При этом m называют мантиссой, а q — порядком числа.
3,1415926 = 0, 31415926 ⋅ 10 1 ;
1250000=0,125 ⋅ 10 7 ;
0,123456789 = 0,123456789 ⋅ 10 0 ;
0,000076 = 0,76 ⋅ 10 -4 ;
1000,00012 = 0,100000012 ⋅ 2 4 . (порядок записан в десятичной системе)
Для хранения чисел с плавающей точкой в компьютерах обычно отводится 4, 8 или 10 байт.
Чем больше разрядов отводится под запись мантиссы, тем выше точность представления числа.
Чем больше разрядов занимает порядок, тем шире диапазон от наименьшего до наибольшего представимого числа.
Найти в Интернет более подробную информацию о кодировании чисел
Текст — это последовательность символов (букв, цифр, знаков препинания, математических знаков и т.д.). Как и любая другая информация, в компьютере текст представляется двоичным кодом. Для этого каждому символу ставится в соответствие некоторое положительное число, двоичная запись которого и будет записана в память компьютера. Соответствие между символом и его кодом определяется кодовой таблицей.
Современные кодовые таблицы ведут начало от американского стандартного кода обмена информацией ASCII (American Standard Code for Information Interchange). Он был семибитным и, соответственно, позволял представить 2 7 =128 различных символов. Таблица включала буквы латинского алфавита, цифры, основные знаки и управляющие символы (перевод строки, возврат каретки, табуляция и др.).
В дальнейшем широкое распространение получили восьмибитные кодировки, в которых каждый символ текста был представлен полным байтом. В большинстве из них первые 128 кодов повторяли таблицу ASCII, а следующие («верхняя половина кодовой таблицы») использовались для представления символов национальных алфавитов и полиграфических знаков.
Во многих случаях для одного и того же языка было создано несколько кодировок. Например, для кодирования русскоязычных текстов достаточно широко использовалось (и до сих пор в некоторых случаях используются) пять кодировок:
Основные недостатки восьмибитных кодировок:
- Множественные варианты кодировок для одного и того же языка и, как следствие, проблемы с переносом текстов между компьютерами, использующими разные варианты.
- Невозможность использования в одном тексте (без дополнительных программных ухищрений) разных систем письма (за исключением сочетаний базового латинского алфавита с каким-либо иным алфавитным письмом).
- Невозможность использования для языков с иероглифической системой письма.
Для устранения этих недостатков в 1991 году был предложен стандарт Unicode («Юникод»). Он включает универсальный набор символов (UCS, Universal Character Set) и форматы машинного представления их кодов (UTF, Unicode Transformation Format).
Первая версия Юникода представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 2 16 (65 536). Отсюда происходит практика обозначения символов четырьмя шестнадцатеричными цифрами (например, U+0410). При этом в Юникоде планировалось кодировать не все существующие символы, а только те, которые необходимы в повседневном обиходе.
В дальнейшем было принято решение расширить набор символов за счет различных способов кодирования. Поскольку в ряде систем уже началось использование 16-битной версии Unicode, за основными символами сохранили принятые в ней коды (образовавшие «основную многоязычную плоскость»), а для более редко применяемых назначили «суррогатные пары» — четырехбайтные коды. Эта система кодирования получила обозначение UTF-16. В UTF-16 можно отобразить только 2 20 +2 16 −2048 (1112064) символов, это число и было выбрано в качестве окончательной величины кодового пространства Юникода. Но и этого более чем достаточно — сейчас используется немногим более 100000 кодовых позиций. Unicode включает символы практически всех современных, а также многих древних систем письма.
Существует также UTF-32, в которой для записи любого символа используется 4 байта. Из-за очень неэкономного расхода памяти (в 2-4 раза больше, чем UTF-8, и почти вдвое больше, чем UTF-16) на практике она используется достаточно редко.
В Интернет наибольшее распространение получила система кодирования UTF-8, в MS Windows преимущественно используют UTF-16, в Unix-подобных ОС (включая Linux и Mac OS X) — в основном UTF-8.
В отличие от чисел и текста, графическая и звуковая информация по своей природе — аналоговая (т.е. представляется непрерывным изменением некоторой величины). Компьютер же может работать только с дискретной («разрывной», представляемой скачкообразными изменениями). Поэтому непосредственно закодировать изображение или звук невозможно.
И для одного, и для другого вида информации существуют два способа представления: либо искусственно разбить на малые элементы, либо описать правила формирования.
Читайте также: