
Какие элементы находятся на уровне микроархитектуры современных компьютеров
Микроархитектура - описание аппаратной реализации процессора, определяющее его работу, используемое в компьютерной инженерии .
В научном сообществе чаще используется термин процессорная организация . Вместе с программной моделью процессора он формирует понятие архитектуры процессора .
Микроархитектура, хоть и связана с концептуальной моделью программного обеспечения процессора (называемой. Instruction Set Architecture - ISA), - это нечто совершенно иное. Хотя ISA не зависит от организации процессора, микроархитектура должна соответствовать требованиям, предъявляемым моделью программного обеспечения, например, обеспечивать адекватный ресурс регистров.
Микроархитектура обычно представляет собой набор диаграмм, определяющих выбранные элементы процессора (функциональные блоки, исполнительные блоки) и связи между ними. Однако он не определяет фактическую реализацию логических схем.
Следует отметить, что:
- Два процессора могут иметь одинаковую микроархитектуру (организацию) и в то же время иметь совершенно разную физическую реализацию. [1]
- Процессоры разных организаций могут иметь одинаковую модель программного обеспечения (ISA). Это позволяет разрабатывать более быстрые процессоры одного и того же семейства (выполняющие один и тот же код).
Из-за необходимости ускорения обработки и ограничений, связанных с существованием самого длинного критического пути в каждой системе, конвейерная обработка в настоящее время используется в процессорах. Это позволяет одновременно выполнять несколько инструкций, каждая из которых в данный момент находится на разных стадиях. Обычно длина конвейера выполнения составляет от 6 до 20 шагов. Проектирование трубопроводов - один из основных вопросов микроархитектуры.
Точно так же исполнительные блоки также являются важной частью микроархитектуры. К ним относятся арифметические и логические блоки (ALU), блоки с плавающей запятой (FPU), блоки загрузки / сохранения , система прогнозирования ветвлений (BTB) и блоки SIMD . Они выполняют основные операции каждого заказа. Выбор исполнительных блоков, выбор их параметров ( латентность , энергопотребление, возможность конвейерной обработки) является важной задачей проектирования микроархитектуры, как и выбор организации памяти.
Помимо производительности, для микроархитектуры есть еще много других вопросов. Среди прочего, это:
- Размер / стоимость ИС
- Потребление энергии
- сложность логики
- возможность производства
- простота отладки
- проверяемость
Вообще говоря, все процессоры выполняют программы инструкция за инструкцией со следующими шагами:
- скачать руководство
- декодирование инструкций
- поиск данных, необходимых для выполнения инструкции
- выполнение инструкций
- запись результатов
Ниже описывается выбор методов уровня микроархитектуры, используемых в современных процессорах.
Многоуровневая структура компьютера: языки, уровни и виртуальные машины
Существует огромная разница между тем, что удобно людям, и тем, что могут компьютеры. Люди хотят сделать X, но компьютеры могут сделать только Y. Из-за этого возникает проблема.
Вышеупомянутую проблему можно решить двумя способами. Оба способа подразумевают разработку новых команд, более удобных для человека, чем встроенные команды. Эти новые команды в совокупности формируют язык, который мы будем называть Я 1. Встроенные машинные команды тоже формируют язык, и мы будем называть его Я 0. Компьютер может выполнять только программы, написанные на его машинном языке Я 0. Два способа решения проблемы различаются тем, каким образом компьютер будет выполнять программы, написанные на языке Я 1, — ведь в конечном итоге компьютеру доступен только машинный язык Я 0.
Первый способ выполнения программы, написанной на языке Я 1, подразумевает замену каждой команды эквивалентным набором команд на языке Я 0. В этом случае компьютер выполняет новую программу, написанную на языке Я 0, вместо старой программы, написанной на Я 1. Эта технология называется трансляцией.
Второй способ означает создание программы на языке Я 0, получающей в качестве входных данных программы, написанные на языке Я 1. При этом каждая команда языка Я 1 обрабатывается поочередно, после чего сразу выполняется эквивалентный ей набор команд языка Я 0. Эта технология не требует составления новой программы на Я 0. Она называется интерпретацией, а программа, которая осуществляет интерпретацию, называется интерпретатором.
Между трансляцией и интерпретацией много общего. В обоих подходах компьютер в конечном итоге выполняет набор команд на языке Я 0, эквивалентных командам Я 1. Различие лишь в том, что при трансляции вся программа Я 1 переделывается в программу Я 0, программа Я 1 отбрасывается, а новая программа на Я 0 загружается в память компьютера и затем выполняется.
При интерпретации каждая команда программы на Я 1 перекодируется в Я 0 и сразу же выполняется. В отличие от трансляции, здесь не создается новая программа на Я 0, а происходит последовательная перекодировка и выполнение команд. С точки зрения интерпретатора, программа на Я 1 есть не что иное, как «сырые» входные данные. Оба подхода широко используются как вместе, так и по отдельности.
Впрочем, чем мыслить категориями трансляции и интерпретации, гораздо проще представить себе существование гипотетического компьютера или виртуальной машины, для которой машинным языком является язык Я 1. Назовем такую виртуальную машину М 1, а виртуальную машину для работы с языком Я 0 — М 0. Если бы такую машину М 1 можно было бы сконструировать без больших денежных затрат, язык Я 0, да и машина, которая выполняет программы на языке Я 0, были бы не нужны. Можно было бы просто писать программы на языке Я 1, а компьютер сразу бы их выполнял. Даже с учетом того, что создать виртуальную машину, возможно, не удастся (из-за чрезмерной дороговизны или трудностей разработки), люди вполне могут писать ориентированные на нее программы. Эти программы будут транслироваться или интерпретироваться программой, написанной на языке Я 0, а сама она могла бы выполняться существующим компьютером. Другими словами, можно писать программы для виртуальных машин так, как будто эти машины реально существуют.
Трансляцию и интерпретацию возможно выполнить только в том случае, когда Я 0 и Я 1 не сильно отличаются друг от друга. Но ведь цель создания Я 1 заключалась в создании языка более удобного для человека. Очевидно что она не может быть достигнута. Чтобы решить эту проблему можно создать еще одну виртуальную машину М 2 и язык Я 2, который будет более понятен для человека, чем Я 1. При этом, программы написанные на языке Я 2 могут транслироваться на язык Я 1 или выполняться интерпретатором, написанным на языке Я 1.
Изобретение целого ряда языков, каждый из которых более удобен для человека, чем предыдущий, может продолжаться до тех пор, пока мы не дойдем до подходящего нам языка. Каждый такой язык использует своего предшественника как основу, поэтому мы можем рассматривать компьютер в виде ряда уровней, такая структура изображена на рисунке ниже. Язык, находящийся в самом низу иерархической структуры компьютера, — самый примитивный, а тот, что расположен на ее вершине — самый сложный.

Многоуровневая структура компьютера
Компьютер с п уровнями можно рассматривать как п разных виртуальных машин, у каждой из которых есть свой машинный язык. Термины «уровень» и «виртуальная машина» мы будем использовать как синонимы. Только программы, написанные на Я 0, могут выполняться компьютером без трансляции или интерпретации. Программы, написанные на Я 1, Я 2, …, Я п, должны проходить через интерпретатор более низкого уровня или транслироваться на язык, соответствующий более низкому уровню.
Уровень 0: Цифровой логический уровень
Объекты цифрового логического уровня — вентили. Хотя вентили состоят из аналоговых компонентов, таких как транзисторы, они могут быть точно смоделированы как цифровые устройства. У каждого вентиля есть один или несколько цифровых входов (сигналов, представляющих 0 или 1). Вентиль вычисляет простые функции этих сигналов, такие как И или ИЛИ. Каждый вентиль формируется из нескольких транзисторов. Несколько вентилей формируют 1 бит памяти, который может содержать 0 или 1. Биты памяти, объединенные в группы, например, по 16, 32 или 64, формируют регистры. Каждый регистр может содержать одно двоичное число до определенного предела. Из вентилей также может состоять сам компьютер.
Уровень 5: уровень языка прикладных программистов
Уровень 5 обычно состоит из языков, разработанных для прикладных программистов. Такие языки называются языками высокого уровня. Существуют сотни языков высокого уровня. Наиболее известные среди них — С, C++, Java, LISP и Prolog. Программы, написанные на этих языках, обычно транслируются на уровень 3 или 4. Трансляторы, которые обрабатывают эти программы, называются компиляторами. Отметим, что иногда также имеет место интерпретация. Например, программы на языке Java сначала транслируются на язык, напоминающий ISA и называемый байт-кодом Java, который затем интерпретируется.
В некоторых случаях уровень 5 состоит из интерпретатора для конкретной прикладной области, например символической логики. Он предусматривает данные и операции для решения задач в этой области, выраженные при помощи специальной терминологии.
Таким образом, компьютер проектируется как иерархическая структура уровней, которые надстраиваются друг над другом. Каждый уровень представляет собой определенную абстракцию различных объектов и операций. Рассматривая компьютер подобным образом, мы можем не принимать во внимание ненужные нам детали и, таким образом, сделать сложный предмет более простым для понимания.
Набор типов данных, операций и характеристик каждого отдельно взятого уровня называется архитектурой. Архитектура связана с программными аспектами. Например, сведения о том, сколько памяти можно использовать при написании программы, — часть архитектуры. Аспекты реализации (например, технология, применяемая при реализации памяти) не являются частью архитектуры. Изучая методы проектирования программных элементов компьютерной системы, мы изучаем компьютерную архитектуру. На практике термины «компьютерная архитектура» и «компьютерная организация» употребляются как синонимы.
По материалам книги «Архитектура компьютера» Э. Таненбаума. Советую прочитать оригинал.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Выбор списка заказов
Выбор типа архитектуры списка инструкций между CISC , RISC , VLIW , EPIC в значительной степени подразумевает микроархитектуру. Выбор архитектуры списка инструкций между RISC и CISC со временем перестает быть важным из-за того, что реализация логики декодирования инструкций имеет фиксированную сложность и не представляет большой нагрузки для всего процессора.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Уровень 3: уровень операционной системы
Этот уровень обычно является гибридным. Большинство команд в его языке есть также и на уровне архитектуры набора команд (команды, имеющиеся на одном из уровней, вполне могут быть представлены и на других уровнях). У этого уровня есть некоторые дополнительные особенности: новый набор команд, другая организация памяти, способность выполнять две и более программы одновременно и некоторые другие. При построении уровня 3 возможно больше вариантов, чем при построении уровней 1 и 2.
Новые средства, появившиеся на уровне 3, выполняются интерпретатором, который работает на втором уровне. Этот интерпретатор был когда-то назван операционной системой. Команды уровня 3, идентичные командам уровня 2, выполняются микропрограммой или аппаратным обеспечением, но не операционной системой. Другими словами, одна часть команд уровня 3 интерпретируется операционной системой, а другая часть — микропрограммой. Вот почему этот уровень считается гибридным. Мы будем называть этот уровень уровнем операционной системы.
Между уровнями уровнем архитектуры набора команд и уровнем операционной системы есть существенная разница. Нижние три уровня задуманы не для того, чтобы с ними работал обычный программист. Они изначально ориентированы на интерпретаторы и трансляторы, поддерживающие более высокие уровни. Эти трансляторы и интерпретаторы составляются так называемыми системными программистами, которые специализируются на разработке новых виртуальных машин. Уровни с четвертого и выше предназначены для прикладных программистов, решающих конкретные задачи.
Еще одно изменение, появившееся на уровне операционной системы, — механизм поддержки более высоких уровней. Уровни 2 и 3 обычно интерпретируются, а уровни 4, 5 и выше
обычно, хотя и не всегда, транслируются.
Другое отличие между уровнями 1, 2, 3 и уровнями 4, 5 и выше — особенность языка. Машинные языки уровней 1, 2 и 3 — цифровые. Программы, написанные на этих языках, состоят из длинных рядов цифр, которые воспринимаются компьютерами, но малопонятны для людей. Начиная с уровня 4, языки содержат слова и сокращения, понятные человеку.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Уровень 2: уровень архитектуры набора команд
Уровень 2 мы будем называть уровнем архитектуры набора команд. Каждый производитель публикует руководство для компьютеров, которые он продает, под названием «Руководство по машинному языку X», «Принципы работы компьютера У» и т. п. Подобное руководство содержит информацию именно об этом уровне. Описываемый в нем набор машинных команд в действительности выполняется микропрограммой-интерпретатором или аппаратным обеспечением. Если производитель поставляет два интерпретатора для одной машины, он должен издать два руководства по машинному языку, отдельно для каждого интерпретатора.
Уровень 4: уровень Ассемблера
Уровень 4 представляет собой символическую форму одного из языков более низкого уровня. На этом уровне можно писать программы в приемлемой для человека форме. Эти программы сначала транслируются на язык уровня 1, 2 или 3, а затем интерпретируются соответствующей виртуальной или фактически существующей машиной. Программа, которая выполняет трансляцию, называется ассемблером.
Выбор списка заказов
Выбор типа архитектуры списка инструкций между CISC , RISC , VLIW , EPIC в значительной степени подразумевает микроархитектуру. Выбор архитектуры списка инструкций между RISC и CISC со временем перестает быть важным из-за того, что реализация логики декодирования инструкций имеет фиксированную сложность и не представляет большой нагрузки для всего процессора.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Логические элементы
Логические элементы, это как кубики лего, из которых мы собираем микроархитектуру. У нас есть некий ограниченный набор элементов, но мы можем использовать их для создания систем любой сложности.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Суперскалярный торрент
Использование возможности параллельного выполнения нескольких инструкций приводит к концепции суперскалярного конвейера, в котором исполнительные единицы дублируются или умножаются.
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Микроархитектура
Если продолжить аналогию с автомобилем, то микроархитектура компьютера это уже детали его внутреннего строения. На этом уровне работают инженеры, которые проектируют процессоры.
Уровень 1: уровень Микроархитектуры
Следующий уровень называется уровнем микроархитектуры. На этом уровне находятся совокупности 8 или 32 регистров, которые формируют локальную память и схему, называемую АЛУ (арифметико-логическое устройство). АЛУ выполняет простые арифметические операции. Регистры вместе с АЛУ формируют тракт данных, по которому поступают данные. Тракт данных работает следующим образом. Выбирается один или два регистра, АЛУ производит над ними какую-либо операцию, например сложения, после чего результат вновь помещается в один из этих регистров.
На некоторых машинах работа тракта данных контролируется особой программой, которая называется микропрограммой. На других машинах тракт данных контролируется аппаратными средствами.
На машинах, где тракт данных контролируется программным обеспечением, микропрограмма — это интерпретатор для команд на уровне 2. Микропрограмма вызывает команды из памяти и выполняет их одну за другой, используя при этом тракт данных. Например, при выполнении команды ADD она вызывается из памяти, ее операнды помещаются в регистры, АЛУ вычисляет сумму, а затем результат переправляется обратно. На компьютере с аппаратным контролем тракта данных происходит такая же процедура, но при этом нет программы, интерпретирующей команды уровня 2.
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Современные многоуровневые компьютеры
Современные компьютеры можно представить как структуру, состоящую из 6 уровней:

Структура шестиуровневого компьютера
Ради полноты нужно упомянуть о существовании еще одного уровня, который расположен ниже нулевого. Этот уровень не показан на рис. выше, так как он попадает в сферу электронной техники и, следовательно, не рассматривается из-за сложности материала. Он называется уровнем физических устройств. На этом уровне находятся транзисторы, которые для разработчиков компьютеров являются примитивами. Объяснить, как работают транзисторы, — задача физики.
Конвейерная обработка
Основным методом ускорения обработки на уровне микроархитектуры является использование конвейера выполнения. Разделив выполнение отдельной инструкции на этапы, вы можете увеличить тактовую частоту процессора и повысить эффективность использования логики процессора.
Использование сложной иерархии кешей процессора позволяет снизить среднее время доступа к памяти и значительно ускорить обработку.
Непоследовательное выполнение инструкций
Непоследовательное выполнение инструкций (так называемое исполнение вне очереди ) дает еще большую возможность воспользоваться преимуществами инструкций параллельной обработки в базовом блоке .
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Абстракция как инструмент работы с сложными системами
Для понимания устройства компьютерных систем очень важным является такое понятие как абстракция. На самом деле оно имеет очень широкое применение, выходящее далеко за рамки компьютерной техники. Если говорить просто, то абстракция – это способность разума сконцентрироваться на главном, игнорируя детали. Когда мы используем пульт от телевизора, мы как правило не задумываемся о его внутреннем устройстве, как он посылает радиоволны телевизору, как телевизор считывает эти волны и т.д. Для нас эти детали не важны. Пульт для нас это что-то вроде черного ящика. Мы жмем на кнопку, он выполняет необходимые действия. Или, например, водитель может управлять автомобилем, абсолютно не зная, что у него “под капотом”. Он просто жмет на педали, крутит руль и машина реагирует соответствующим образом. Абстракция разгружает наш разум и позволяет строить и использовать сложные системы. С другой стороны, в случае когда автомобиль, допустим, не заводится, нам необходимо “сорвать одеяло абстракций”. Если в системе что-то идет не так, то для исправления дефектов нам необходимо обратное действие – деконструкция, способность перейти от абстракции к более детальному рассмотрению устройства системы.
Многопоточность и использование нескольких процессоров
Конструкция многоядерных ( Chip Multiprocessing - CMP) и многопоточных процессоров увеличивает общую производительность системы, обеспечивая одновременную обработку более чем одной программы или потока. Это влечет за собой значительное усложнение всей системы и не увеличивает эффективность однопоточных приложений.
Мы уже проделали немалый путь к пониманию работы процессора. Начинали мы с самого нижнего уровня абстракции, говорили о транзисторах и логических схемах. После этого переходили к более сложным функциональным блокам. Если вы проделали весь этот путь вместе с каналом, то не забудьте поставить палец вверх, чтобы поддержать эту рубрику!
Сегодня мы будем говорить о микроархитектуре процессора. Для начала определим, что это такое.
Микроархитектура является связующим звеном между логическими схемами и архитектурой. В рамках нашего повествования микроархитектура - это следующий уровень сложности. Она описывает, как именно в процессоре расположены и соединены друг с другом регистры, АЛУ, схемы конечных состояний, блоки памяти и многое другое, необходимое для реализации архитектуры.
У каждой архитектуры, в том числе у многим известной x86 , может быть много различных микроархитектур, обеспечивающих разное соотношение производительности, цены и сложности. Все они смогут выполнять одни и те же программы, но их внутреннее устройство может очень сильно отличаться.
В частном случае состав микроархитектуры определяется тем, какой список команд предусмотрен для данного процессора. Но в общем, в любой микроархитектуре существует разделение на два блока .
Тракт данных - это часть микроархитектуры, которая включает в себя компоненты, которые работают над обработкой данных. Тракт данных получает из памяти все необходимые данные, осуществляет над ними все нужные операции и сохраняет это обратно в память.
Сам тракт данных не знает, что именно нужно совершить с данными, да и вообще, он может не знать можно ему перезаписывать данные в памяти. Определением типа операций, разрешением записи данных и так далее, занимается устройство управления - это второй блок микроархитектуры.
Любая микроархитектура обязана обладать блоками хранения. В самом простом случае мы будем иметь: счетчик команд, регистровый файл и память . Так как мы будем рассматривать Гарвардскую (?) микроархитектуру, память данных и память команд у нас будут разделены. Сейчас обговорим, что и для чего нужно.
Счетчик команд является так называемым хранителем архитектурного состояния системы. То есть благодаря ему мы можем на каждом этапе работы микропроцессора знать, чем он занят. Сам счетчик команд постоянно указывает на какое-либо место в памяти команд. Та команда, на которую указывает счетчик, извлекается процессором и выполняется в тракте данных. После ее завершения значение счетчика изменяется в зависимости от того, как завершилась предыдущая команда. И так повторяется каждый раз. По своему устройству он представляет собой обычный регистр.
Память команд нужна для того, чтобы хранить команды необходимые для выполнения программ на данном процессоре. Вообще под командой мы понимаем в буквальном смысле инструкцию действий для процессора. Например: мы можем сказать процессору, чтобы он взял какие-нибудь два числа, которые хранятся в каком-либо месте в памяти и сложил их, а результат записал в третье место в памяти.
Память данных необходима для того, чтобы хранить данные с которыми будет работать программа по мере ее выполнения. Это как раз те самые два числа, о которых мы с вами говорили.
Ну и регистровый файл - это просто набор регистров, которые хранят в себе данные, с которыми работает процессор непосредственно в момент выполнения команды. В нашем примере, когда мы сказали процессору, какие два числа мы хотим сложить, он извлекет их из памяти и запишет в этот регистровый файл. Из него он сможет максимально быстро поработать с ними. Но основное удобство этого блока состоит в том, что если следующей команде будет необходим результат этого сложения, то процессор сможет не тратить время на обратную запись результата и повторное его извлечение, а просто оставить его в регистровом файле и дать доступ к этому регистру следующей команде.
И вот мы разобрали все блоки, которые необходимы микроархитектуре для хранения. В качестве исполняющего устройства используются АЛУ. Если вы не знаете что это такое, то переходите по ссылке на статью. Все эти компоненты соединяются массой различных способов при помощи промежуточных регистров, мультиплексоров и другого.
Глобально существует всего несколько типов микроархитектур, которые мы с вами разберем в следующих статьях. Сегодня мы лишь поверхностно ознакомились с таким понятием как микроахритектура. В следующих статьях я расскажу об основных ее типах и мы с вами попробуем самостоятельно разработать какую-нибудь микроархитектуру. А чтобы не пропустить новых статей, подписывайтесь на канал и поддерживайте выпуски лайками, так я буду видеть вашу заинтересованность! Всего вам доброго и до скорых встреч!
Какие ассоциации возникают у вас при слове “компьютер”? Возможно вам придет в голову ваш собственный настольный компьютер, который включает в себя системный блок, монитор, клавиатуру, мышь, колонки. У кого-то другого компьютер ассоциируется с ноутбуком.
Но на самом деле это понятие гораздо шире. Ваш смартфон также является компьютером. Компьютеры, выполняющие самые разные функции, можно встретить и в автомобилях.
Такой компьютер может, например, обрабатывать информацию, которую ему передают какие-либо датчики (например, температуру двигателя, закрыты ли двери и т.д.) и выводить на некий дисплей предупреждающий сигнал, если что-то не в порядке. Существую также так называемые суперкомпьютеры, которые могут занимать целые комнаты. Они используются для задач, требующих огромных вычислительных мощностей. Как видно, понятие компьютера намного более широкое, чем может показаться на первый взгляд. Поэтому я также буду использовать термин “компьютерная система”.
Все компьютеры имеют между собой набор общих черт. Они представляют собой системы обработки информации, которые имеют программную часть (софт) – набор команд которые указывают о том, какие операции над информацией необходимо произвести, а также аппаратную часть (железо), которое собственно и выполняет эти команды. Устройство которое выполняет команды называется процессором, а которое хранит команды, а также результаты операций – компьютерной памятью. Память и процессор ключевые элементы любой компьютерной системы.
Помимо этого, компьютерная система обычно включает в себя устройства для ввода и вывода информации. Примеры устройств ввода: клавиатура, мышь, сенсорный экран. Примеры устройств вывода: монитор, колонки. Важным также является тот факт, что хотя все компьютеры и различаются вычислительной мощностью (скоростью выполнения программ) и объемом памяти, но программа, которую способен выполнить один компьютер, способен выполнить любой другой. То есть, например, ваш телефон способен производить те же операции, что и какой-нибудь Гугловский суперкомпьютер, просто у него это займет гораздо больше времени (то что суперкомпьютер выполнит за секунду ваш смартфон выполнит лишь за месяц).
Уровни абстракции компьютера
Рассмотрим теперь устройство компьютера с точки зрения уровней абстракции.
- Софт (програмное обеспечение)
- Архитектура набора команд
- Микроархитектура
- Логические элементы
- Девайсы
На этом уровне мы имеем программу, написанную на языке программирования предназначенную для выполнения компьютером. Существует множество языков программирования. Поскольку процессор понимает только двоичный код, любой код, написанный на языке программирования должен по итогу быть преобразован в двоичный код, понятный процессору. За это отвечает компилятор.
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Прерывания
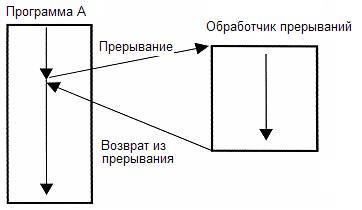
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Девайсы
Каждый логический элемент сам должен быть из чего-то построен и это что-то мы будем называть девайсами. Современных компьютеры работают на основе электричества, поэтому девайсы представляют собой устройства, направляющие и реагирующие на движение электронов. Но, возможно, в будущем появятся компьютеры, которые функционируют за счет других физических принципов, например, оптические компьютеры, которые работают на основе фотонов.
В последнее время я много писал о компьютерных сетях. Но и строении и структуре современных компьютеров тоже не стоит забывать. Также как и в компьютерных сетях существует эталонная модель OSI, компьютер тоже делится на уровни. Однако функции да и само деление на уровни созданы по иным причинам, чем в компьютерных сетях. Далее все это излагается в довольно простой и понятной форме.
Прогноз ветвления
Команды перехода вызывают конфликты управления, что приводит к остановке обработки и замедлению выполнения программы. Способ смягчить этот эффект - использовать прогнозирование переходов, которое позволяет спекулятивное выполнение кода после инструкции перехода. К сожалению, в случае неверного прогноза стоимость опустошения конвейера и возобновления обработки в нужной точке может быть значительной (от нескольких до нескольких циклов процессора).
Архитектура набора команд
На этом уровне мы имеем тот самый двоичный код. У нас есть процессор, который считывает некий набор битов (команду) и выполняет соответствующие действия. Затем он считывает следующий набор битов и выполняет их. И так до бесконечности, пока работу компьютера что-то не остановит. На этом уровне процессор для нас как черный ящик. Мы не знаем детали его внутреннего устройства, мы просто знаем какие команды он способен выполнять. Если проводить аналогию с современными автомобилями, то архитектура набора команд это руль, педали и коробка передач. Два автомобиля могут иметь абсолютно разное внутреннее строение, но если они одинаково реагируют на повороты руля, нажатие педалей и переключение скоростей, то умея управлять одним из них, мы также успешно можем управлять другим. Также и два процессора могут понимать одни и те же команды, но при этом иметь различное устройство.
Читайте также: