
Какие данные записываются в логические переменные сколько места в памяти они занимают
Аннотация: Изучение механизмов формирования физического адреса при различной организации логического адресного пространства. Организация памяти микропроцессорной системы один из важнейших компонентов, влияющий на многие параметры ее работы: защиту данных, мультипрограммирование, работу кэш-памяти и т. д. Поэтому изучение принципов построения памяти как на логическом, так и на физическом уровне является одним из ключевых моментов данного курса, и данному вопросу будет уделено достаточно много внимания.
Структура
Ранее были рассмотрены встроенные типы данных. Теперь мы переходим к пользовательским типам данных. Структура - конструкция, позволяющая содержать в себе набор переменных различных типов.
Структуры реализованы в языке программирования, чтобы собрать некие близки по смыслу вещи воедино.
Например, есть колесо автомобиля. У колеса есть диаметр, толщина, шина. Шина в свою очередь является структурой, у которой есть свои параметры: материал, марка, чем заполнена. Естественно, для каждого параметра можно создать свою переменную или константу, у нас появится большое количество переменных, которые, чтобы понять к чему они относятся, нужно в именах общую часть выделять. Имена будут нести лишнюю смысловую нагрузку. Получается запутанная история. А так мы определяем две структуры, а затем параметры в них.
Логический тип данных
Перечислимый тип данных
Во внутреннем представлении, это целочисленный тип данных, только здесь пользователь вместо числе использует заранее определенные строковые значения.
Теперь переменные перечислимого типа Forms могут принимать лишь значения, определенные в примере кода. Это очень удобно, ведь мы уже оперируем не с числами, а с некими смысловыми значениями, замечу лишь, что для компьютера эти значения всё-равно являются целыми числами.
Классификация типов данных

Изначально, типы данных делятся на простые и составные. Простой - это тип данных, объекты (переменные или постоянные) которого не имеют доступной программисту внутренней структуры. Для объектов составного типа данных, в противовес простому, программист может работать с элементами внутренней его структуры.
Числовой тип данных разработан для хранения естественно чисел. Символьный - для хранения одного символа. Логический тип имеет два значения: истина и ложь. Перечислимый тип может хранить только те значения, которые прямо указаны в его описании.
Для простых типов данных определяются границы диапазона и количество байт, занимаемых ими в памяти компьютера.
В большинстве языков программирования, простые типы жестко связаны с их представлением в памяти компьютера. Компьютер хранит данные в виде последовательности битов, каждый из которых может иметь значение 0 и 1. Фрагмент данных в памяти может выглядеть следующим образом
Данные на битовом уровне (в памяти) не имеют ни структуры, ни смысла. Как интерпретировать данные, как целочисленное число, или вещественное, или символ, зависит от того, какой тип имеют данные, представленные в этой и последующих ячейках памяти.
Целочисленные типы данных
Выделяют знаковые и беззнаковые. Как видно из названия, знаковые предназначены для хранения как положительных, так и отрицательных значений, нуль, а беззнаковые - чисел, не меньше нуля.
Беззнаковые типы данных, в отличии от соответствующих знаковых, имеют в два раза больший диапазон. Это из-за их машинного представления. В знаковых типах первый бит указывает на знак числа: 1 - отрицательное, 0 - положительное.
Исходя из машинного представления целого числа, в ячейке памяти из n бит может хранится 2 n для беззнаковых, и 2 n-1 для знаковых типов.
Рассмотрим теперь конкретные целочисленные типы в трёх языках.
| Тип | Разрядность в битах | Диапазон чисел |
|---|---|---|
| byte | 8 | 0 - 255 |
| sbyte | 8 | -128 - 127 |
| short | 16 | -32 768 - 32 767 |
| ushort | 16 | 0 - 65 535 |
| int | 32 | -2 147 483 648 - 2 147 483 647 |
| uint | 32 | 0 - 4 294 967 295 |
| long | 64 | -9 223 372 036 854 775 808 - 9 223 372 036 854 775 807 |
| ulong | 64 | 0 - 18 446 744 073 709 551 615 |
| Тип | Разрядность в битах | Диапазон чисел |
|---|---|---|
| unsigned short int / unsigned short | 16 | 0 - 65 535 |
| short int | 16 | -32 768 - 32 767 |
| unsigned long int / unsigned long | 32 | 0 - 4 294 967 295 |
| long int / long | 32 | -2 147 483 648 - 2 147 483 647 |
| int (16 разрядов) | 16 | -32 768 - 32 767 |
| int (32 разряда) | 32 | -2 147 483 648 - 2 147 483 647 |
| unsigned int (16 разрядов) | 16 | 0 - 65 535 |
| unsigned int (32 разряда) | 32 | 0 - 4 294 967 295 |
У некоторых типов есть приписка "16 разрядов" или "32 разряда". Это означает, что в зависимости от разрядности операционной системы и компилятора данный тип будет находится в соответствующем диапазоне. По-этому, рекомендуется не использовать int, unsigned int, а использовать их аналоги, но уже жестко определенные, short, long, unsigned short, unsigned long.
| Тип | Разрядность в битах | Диапазон чисел |
|---|---|---|
| byte | 8 | -128 - 127 |
| short | 16 | -32 768 - 32 767 |
| int | 32 | -2 147 483 648 - 2 147 483 647 |
| long | 64 | -9 223 372 036 854 775 808 - 9 223 372 036 854 775 807 |
В Java нет беззнаковых целочисленных типов данных.
Формирование физического адреса в универсальном микропроцессоре при различных режимах работы
Микропроцессор способен работать в двух режимах: реальном и защищенном.
При работе в реальном режиме возможности процессора ограничены: емкость адресуемой памяти составляет 1 Мбайт, отсутствует страничная организация памяти, сегменты имеют фиксированную длину 2 16 байт .
Этот режим обычно используется на начальном этапе загрузки компьютера для перехода в защищенный режим.
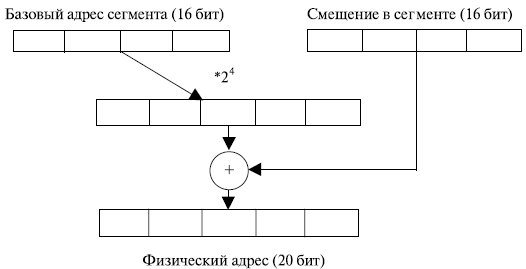
В реальном режиме сегментные регистры процессора содержат старшие 16 бит физического адреса начала сегмента. Сдвинутый на 4 разряда влево селектор дает 20-разрядный базовый адрес сегмента. Физический адрес получается путем сложения этого адреса с 16-разрядным значением смещения в сегменте, формируемого по заданному режиму адресации для операнда или извлекаемому из регистра EIP для команды (рис. 3.1). По полученному адресу происходит выборка информации из памяти.
Наиболее полно возможности микропроцессора по адресации памяти реализуются при работе в защищенном режиме. Объем адресуемой памяти увеличивается до 4 Гбайт, появляется возможность страничного режима адресации. Сегменты могут иметь переменную длину от 1 байта до 4 Гбайт.
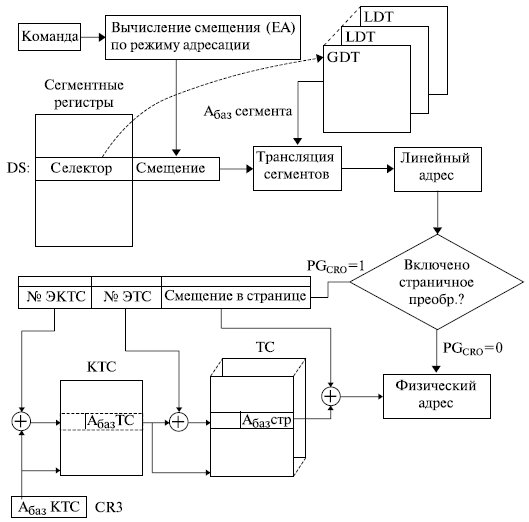
Общая схема формирования физического адреса микропроцессором , работающим в защищенном режиме, представлена на рис. 3.2.
Как уже отмечалось, основой формирования физического адреса служит логический адрес . Он состоит из двух частей: селектора и смещения в сегменте.
Селектор содержится в сегментном регистре микропроцессора и позволяет найти описание сегмента (дескриптор) в специальной таблице дескрипторов. Дескрипторы сегментов хранятся в специальных системных объектах глобальной ( GDT ) и локальных ( LDT ) таблицах дескрипторов. Дескриптор играет очень важную роль в функционировании микропроцессора , от формирования физического адреса при различной организации адресного пространства и до организации мультипрограммного режима работы. Поэтому рассмотрим его структуру более подробно.
Сегменты микропроцессора , работающего в защищенном режиме, характеризуются большим количеством параметров. Поэтому в универсальных 32-разрядных микропроцессорах информация о сегменте хранится в
Структура дескриптора сегмента представлена на рис. 3.3.
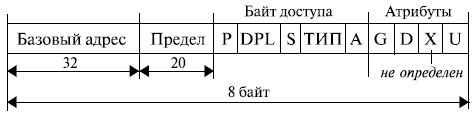
Мы будем рассматривать именно структуру, а не формат дескриптора, так как при переходе от микропроцессора i286 к 32-разрядному МП расположение отдельных полей дескриптора потеряло свою стройность и частично стало иметь вид "заплаток", поставленных с целью механического увеличения разрядности этих полей.
32-разрядное поле базового адреса позволяет определить начальный адрес сегмента в любой точке адресного пространства в 2 32 байт (4 Гбайт).
Поле предела (limit) указывает длину сегмента (точнее, длину сегмента минус 1: если в этом поле записан 0, то это означает, что сегмент имеет длину 1) в адресуемых единицах, то есть максимальный размер сегмента равен 2 20 элементов.
Величина элемента определяется одним из атрибутов дескриптора битом G ( Granularity - гранулярность , или дробность):

Таким образом, сегмент может иметь размер с точностью до 1 байта в диапазоне от 1 байта до 1 Мбайт (при G = 0 ). При объеме страницы в 2 12 = 4 Кбайт можно задать объем сегмента до 4 Гбайт (при G = l ):

Так как в архитектуре IA-32 сегмент может начинаться в произвольной точке адресного пространства и иметь произвольную длину, сегменты в памяти могут частично или полностью перекрываться.
Бит размерности ( Default size ) определяет длину адресов и операндов, используемых в команде по умолчанию:

Конечно, этот бит предназначен не для обычного пользователя, а для системного программиста, применяющего его, например, для отметки сегментов для сбора"мусора" или сегментов, базовые адреса которых нельзя модифицировать. Этот бит доступен только программам, работающим на высшем уровне привилегий. Микропроцессор в своей работе его не меняет и не использует.
Байт доступа определяет основные правила обращения с сегментом.
Бит присутствия P (Present) показывает возможность доступа к сегменту. Операционная система (ОС) отмечает сегмент, передаваемый из оперативной во внешнюю память , как временно отсутствующий, устанавливая в его дескрипторе P = 0 . При P = 1 сегмент находится в физической памяти. Когда выбирается дескриптор с P = 0 (сегмент отсутствует в ОЗУ ), поля базового адреса и предела игнорируются. Это естественно: например, как может идти речь о базовом адресе сегмента, если самого сегмента вообще нет в оперативной памяти? В этой ситуации процессор отвергает все последующие попытки использовать дескриптор в командах, и определяемое дескриптором адресное пространство как бы"пропадает".
Возникает особый случай неприсутствия сегмента. При этом операционная система копирует запрошенный сегмент с диска в память (при этом, возможно, удаляя другой сегмент), загружает в дескриптор базовый адрес сегмента, устанавливает P = 1 и осуществляет рестарт той команды, которая обратилась к отсутствовавшему в ОЗУ сегменту.
Двухразрядное поле DPL ( Descriptor Privilege Level ) указывает один из четырех возможных (от 0 до 3) уровней привилегий дескриптора, определяющий возможность доступа к сегменту со стороны тех или иных программ (уровень 0 соответствует самому высокому уровню привилегий).
Бит обращения A (Accessed) устанавливается в"1" при любом обращении к сегменту. Используется операционной системой для того, чтобы отслеживать сегменты , к которым дольше всего не было обращений.
Пусть, например, 1 раз в секунду операционная система в дескрипторах всех сегментов сбрасывает бит А. Если по прошествии некоторого времени необходимо загрузить в оперативную память новый сегмент, места для которого недостаточно, операционная система определяет"кандидатов" на то, чтобы очистить часть оперативной памяти, среди тех сегментов, в дескрипторах которых бит А до этого момента не был установлен в"1", то есть к которым не было обращения за последнее время.
Поле типа в байте доступа определяет назначение и особенности использования сегмента. Если бит S ( System - бит 4 байта доступа) равен 1, то данный дескриптор описывает реальный сегмент памяти. Если S = 0 , то этот дескриптор описывает специальный системный объект , который может и не быть сегментом памяти, например, шлюз вызова, используемый при переключении задач, или дескриптор локальной таблицы дескрипторов LDT . Назначение битов байта доступа определяется типом сегмента (рис. 3.4).
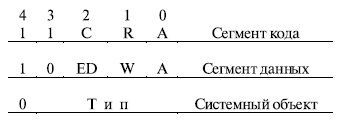
В сегменте кода: бит подчинения, или согласования, C ( Conforming ) определяет дополнительные правила обращения, которые обеспечивают защиту сегментов программ. При C = 1 данный сегмент является подчиненным сегментом кода. В этом случае он намеренно лишается защиты по привилегиям. Такое средство удобно для организации, например, подпрограмм, которые должны быть доступны всем выполняющимся в системе задачам. При C = 0 - это обычный сегмент кода; бит считывания R ( Readable ) устанавливает, можно ли обращаться к сегменту только на исполнение или на исполнение и считывание, например, констант как данных с помощью префикса замены сегмента. При R = 0 допускается только выборка из сегмента команд для их выполнения. При R = 1 разрешено также чтение данных из сегмента.
Запись в сегмент кода запрещена. При любой попытке записи возникает программное прерывание .
В сегменте данных:
- ED ( Expand Down) - бит направления расширения. При ED = 1 этот сегмент является сегментом стека и смещение в сегменте должно быть больше размера сегмента. При ED = 0 - это сегмент собственно данных (смещение должно быть меньше или равно размеру сегмента);
- бит разрешения записи W(Writeable) . При W = 1 разрешено изменение сегмента. При W = 0 запись в сегмент запрещена, при попытке записи в сегмент возникает программное прерывание .
В случае обращения за операндом смещение в сегменте формируется микропроцессором по режиму адресации операнда, заданному в команде. Смещение в сегменте кода извлекается из регистра - указателя команд EIP .
Сумма извлеченного из дескриптора начального адреса сегмента и сформированного смещения в сегменте дает линейный адрес (ЛА).
Если в микропроцессоре используется только сегментное представление адресного пространства, то полученный линейный адрес является также и физическим.
Если помимо сегментного используется и страничный механизм организации памяти , то линейный адрес представляется в виде двух полей: старшие разряды содержат номер виртуальной страницы , а младшие смещение в странице. Преобразование номера виртуальной страницы в номер физической проводится с помощью специальных системных таблиц: каталога таблиц страниц (КТС) и таблиц страниц (ТС). Положение каталога таблиц страниц в памяти определяется системным регистром CR3. Физический адрес вычисляется как сумма полученного из таблицы страниц адреса физической страницы и смещения в странице, полученного из линейного адреса.
Рассмотрим теперь все этапы преобразования логического адреса в физический более подробно.
Да́нные (калька от лат. data) — это представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе.
Изначально — данные величины, т. е. величины, заданные заранее, вместе с условием задачи. Противоположность — переменные величины.
Если данные ориентированы на их понимание человеком непосредственно при их восприятии или после их некоторго преобразования, то они содержат в себе информацию. Возможна ситуация, когда данные не содержат информацию, на настоящее время доступную человеку. Человек способен извлекать информацию не из всех доступных для него данных. Шифрование информации делает ее недоступной для всех, кто не имеет ключа расшифровывания. Шифротекст содержит информацию, но она недоступна.
---------------
В информатике
Основная статья: Данные (вычислительная техника)
С точки зрения программиста данные — это часть программы, совокупность значений определённых ячеек памяти, преобразование которых осуществляет код. С точки зрения компилятора, процессора, операционной системы, это совокупность ячеек памяти, обладающих определёнными свойствами (возможность чтения и записи (необяз.) , невозможность исполнения) .
Контроль за доступом к данным в современных компьютерах осуществляется аппаратно.
Традиционно выделяют два типа данных — двоичные (бинарные) и текстовые.
Двоичные данные обрабатываются только специализированным программным обеспечением, знающим их структуру, все остальные программы передают данные без изменений.
Текстовые данные воспринимаются передающими системами как текст, записанный на каком-либо языке. Для них может осуществляться перекодировка (из кодировки отправляющей системы в кодировку принимающей) , заменяться символы переноса строки, изменяться максимальная длина строки, изменяться количество пробелов в тексте.
Передача текстовых данных как бинарных приводит к необходимости изменять кодировку в прикладном программном обеспечении (это умеет большинство прикладного ПО, отображающего текст, получаемый из разных источников) , передача бинарных данных как текстовых может привести к их необратимому повреждению.
INTEGER - целочисленные данные, во внутреннем представлении занимают 2 байта; диапазон возможных значений - от -32768 до +32767; данные представляются точно;
REAL - вещественные данные, занимают 6 байт; диапазон возможных значений модуля - от 2.9Е-39 до 1.7Е+38; точность представления данных - 11. 12 значащих цифр;
CHAR - символ, занимает 1 байт;
STRING - строка символов, занимает МАХ+1 байт, где МАХ - максимальное число символов в строке;
BOOLEAN - логический тип, занимает 1 байт и имеет два значения: FALSE(ложь) и TRUE (истина) .
это если программирование .
Данные это информация, представленная в форме пригодной для хранения, передачи и обработки компьютером. Виды данных по другому информация это текстовая, числовая, графическая, звуковая и видео информация.
Это часть программы, совокупность значений определенных ячеек памяти, преобразование которых осуществляет код
данные - информация, которая обрабатывается компьютером в двоичном коде в форме последовательности электрических импульсов
4. Переменные: тип, имя, значение.
В объектно-ориентированном языке программирования Visual Basic переменные используются для хранения и обработки данных в программах.
Переменные задаются именами, которые определяют области оперативной памяти компьютера, в которых хранятся значения переменных. Значениями переменных могут быть данные различных типов (целые или вещественные числа, последовательности символов, логические значения и т. д.).
Переменная в программе представлена именем и служит для обращения к данным определенного типа, конкретные значения которых хранятся в ячейках оперативной памяти.
Тип переменной . Тип переменных определяется диапазоном значений, которые могут принимать переменные, и допустимыми операциями над этими значениями. Значениями переменных числовых типов Byte , Short , Integer , Long , Single , Double являются числа, логического типа Boolean — значения True («истина») или False («ложь»), строкового типа String — последовательности символов.
Различные типы данных требуют для своего хранения в оперативной памяти компьютера различное количество ячеек (байтов) (табл. 2.2).
Таблица 2.2. Некоторые типы переменных в языке Visual Basic 2 010
Возможные значения
Объем занимаемой памяти
Целые неотрицательные числа от 0 до 255
Целые числа от –32 768 до 32 767
Целые числа от –2 147 483 648 до 2 147 483 647
Целые числа от –9 223 372 036 854 до
9 223 372 036 853
Десятичные числа одинарной точности (7-8 значащих цифр) от –1,4·10 –45 до 3,4·10 38
Десятичные числа двойной точности (15-16 значащих цифр) от -5,0·10 –324 до 1,7·10 308
Логическое значение True или False
Строка символов в кодировке Unicode
Даты от 1 января 0001 года до 31 декабря 9999 года и время от 0:00:00 до 23:59:59
Имя переменной. Имена переменных определяют области оперативной памяти компьютера, в которых хранятся значения переменных. Имя каждой переменной (идентификатор) уникально и не может меняться в процессе выполнения программы. Имя переменной может состоять из различных символов (латинские и русские буквы, цифры и т. д.), но должно обязательно начинаться с буквы и не должно включать знак точка «.». Количество символов в имени не может быть более 1023, однако для удобства обычно ограничиваются несколькими символами.
Объявление переменных. Необходимо объявлять переменные, для того чтобы исполнитель программы (компьютер) «понимал», переменные какого типа используются в программе.
Для объявления переменной используется оператор Dim . С помощью одного оператора можно объявить сразу несколько переменных, например:
Dim A As Byte, В As Short, С As Single, D As String, G As Boolean
Присваивание переменным значений. Переменная может получить или изменить значение с помощью оператора присваивания. При выполнении оператора присваивания переменная, имя которой указано слева от знака равенства, получает значение, которое находится справа от знака равенства. Например:
Значение переменной может быть задано числом, строкой или логическим значением, а также может быть представлено с помощью арифметического, строкового или логического выражения.
Проект «Переменные». Создать проект, в котором объявить переменные различных типов, присвоить им значения и вывести значения в поле списка, размещенное на форме.
Создадим графический интерфейс (рис. 2.8).
1. Поместить на форму:
• поле списка ListBox 1 для вывода значений переменных;
• кнопку Button 1 для запуска событийной процедуры.
Создадим событийную процедуру, реализующую присваивание значений переменным различных типов. Вывод значений переменных в поле списка произведем с использованием метода Items . Add () , аргументами которого будут переменные.
2. Dim A As Byte, В As Short, С As Single, D As String, G As Boolean
Private Sub Button1_Click (. )
End Sub
3. Запустить проект на выполнение. После щелчка по кнопке начнет выполняться событийная процедура, в которой будут выполнены операции присваивания (в отведенные переменным области оперативной памяти будут записаны их значения).
Затем с помощью метода Items . Add () будет произведен вывод значений переменных в поле списка. В этом процессе значения переменных считываются из оперативной памяти и печатаются в столбик в поле списка (см. рис. 2.8).

Рис. 2.8. Проект «Переменные»
Проанализируем процесс выполнения программы компьютером. После запуска проекта оператор объявления переменных Dim отведет в оперативной памяти для их хранения необходимое количество ячеек (табл. 2.3):
Данные, с которыми работает программа, хранятся в оперативной памяти. Компилятору необходимо точно знать, сколько места они занимают, как именно закодированы и какие действия с ними можно выполнять. Все это задается при описании данных с помощью типа. Тип данных однозначно определяет:
- внутреннее представление данных, а следовательно и множество их возможных значений;
- допустимые действия над данными (операции и функции).
Например, целые и вещественные числа, даже если они занимают одинаковый объем памяти, имеют совершенно разные диапазоны возможных значений; целые числа можно умножать друг на друга, а, например, символы — нельзя. Каждое выражение в программе имеет определенный тип. Компилятор использует информацию о типе при проверке допустимости описанных в программе действий.
Классификация типов
Рассмотрим классификацию типов в таблица 1.2.
Стандартные типы не требуют предварительного определения. Для каждого типа существует ключевое слово, которое используется при описании переменных, констант и т. д. Если же тип данных определяет сам программист, он описывает его характеристики и дает ему имя, которое затем применяется точно так же, как имена стандартных типов. Описание собственного типа данных должно задавать всю информацию, необходимую для его использования: внутреннее представление и допустимые действия.
ПРИМЕЧАНИЕ Типы, выделенные в таблица 1.2 полужирным шрифтом, объединяются термином 'порядковые'. Этот термин рассмотрен далее в этой лекции.
Стандартные типы данных
Логические типы
Внутреннее представление. Основной логический тип данных Паскаля называется boolean . Величины этого типа занимают в памяти 1 байт и могут принимать всего два значения: true (истина) или false (ложь). Внутреннее представление значения false — 0 (нуль), значения true — 1.
Операции. К величинам логического типа применяются логические операции and , or , xor и not ( таблица 1.3). Для наглядности вместо значения false в таблице используется 0, а вместо true — 1.
Операция and называется ' логическое И ', или логическое умножение. Ее результат имеет значение true , только если оба операнда имеют значение true .
Результат операции or ( логическое ИЛИ, логическое сложение) имеет значение true , если хотя бы один из операндов имеет значение true . Например, false or true true , true or true true .
Операция xor — так называемое исключающее ИЛИ, или операция неравнозначности. Ее результат истинен, когда значения операндов не совпадают.
Логическое отрицание not является унарной операцией, то есть имеет один операнд, который и инвертирует. Например, not true даст в результате false .
Величины логического типа можно сравнивать между собой с помощью операций отношения, перечисленных в таблица 1.4. Результат этих операций имеет логический тип.
Целые типы
Внутреннее представление. Целые числа представляются в компьютере в двоичной системе счисления. В Паскале определены несколько целых типов данных, отличающиеся длиной и наличием знака: старший двоичный разряд либо воспринимается как знаковый, либо является обычным разрядом числа ( таблица 1.5). Внутреннее представление определяет диапазоны допустимых значений величин (от нулей до единиц во всех двоичных разрядах).
Операции.С целыми величинами можно выполнять арифметические операции ( таблица 1.6). Результат их выполнения всегда целый (при делении дробная часть отбрасывается).
К целым величинам можно также применять операции отношения, а также поразрядные операции and , or , xor и not . При выполнении этих операций каждая величина представляется как совокупность двоичных разрядов. Действие выполняется над каждой парой соответствующих разрядов операндов: первый разряд с первым, второй — со вторым, и т. д. Например, результатом операции 3 and 2 будет 2, поскольку двоичное представление числа 3 — 11, числа 2 — 10.
Для работы с целыми величинами предназначены также операции сдвига влево shl и вправо shr . Слева от знака операции указывается, с какой величиной будет выполняться операция, а справа — на какое число двоичных разрядов требуется сдвинуть величину. Например, результатом операции 12 shr 2 будет значение 3, а выполнив операцию 12 shl 1 , то есть сдвинув это число влево на 1 разряд, получим 24. Освободившиеся при сдвиге влево разряды заполняются нулями, а при сдвиге вправо — знаковым разрядом.
Стандартные функции и процедуры.К целым величинам можно применять стандартные функции и процедуры, перечисленные в таблица 1.7 (в тригонометрических функциях угол задается в радианах).
Тип данных - фундаментальное понятие языка программирования. Тип данных определяет, что именно представляют собой данные, как они хранятся в памяти, какие операции с ними можно выполнять.
Класс
Еще одним пользовательским типом данных является класс. Класс умеет всё, что и структура, но кроме параметров, у него есть и методы, и поддерживает большое количество вещей, связанных с объектно-ориентированным программированием.
Числовые типы данных
Логическое адресное пространство
Для адресации операндов в физическом адресном пространстве программы используют логическую адресацию. Процессор автоматически транслирует логические адреса в физические, выдаваемые затем на системную шину.
Архитектура компьютера различает физическое адресное пространство (ФАП) и логическое адресное пространство (ЛАП). Физическое адресное пространство представляет собой простой одномерный массив байтов, доступ к которому реализуется аппаратурой памяти по адресу, присутствующему на шине адреса микропроцессорной системы . Логическое адресное пространство организуется самим программистом исходя из конкретных потребностей. Трансляцию логических адресов в физические осуществляет блок управления памятью MMU .
В архитектуре современных микропроцессоров ЛАП представляется в виде набора элементарных структур: байтов, сегментов и страниц. В микропроцессорах используются следующие варианты организации логического адресного пространства:
- плоское (линейное) ЛАП: состоит из массива байтов, не имеющего определенной структуры; трансляция адреса не требуется, так как логический адрес совпадает с физическим;
- сегментированное ЛАП: состоит из сегментов - непрерывных областей памяти, содержащих в общем случае переменное число байтов; логический адрес содержит 2 части: идентификатор сегмента и смещение внутри сегмента; трансляцию адреса проводит блок сегментации MMU ;
- страничное ЛАП: состоит из страниц - непрерывных областей памяти, каждая из которых содержит фиксированное число байтов. Логический адрес состоит из номера (идентификатора) страницы и смещения внутри страницы; трансляция логического адреса в физический проводится блоком страничного преобразования MMU ;
- сегментно-страничное ЛАП: состоит из сегментов, которые, в свою очередь, состоят из страниц; логический адрес состоит из идентификатора сегмента и смещения внутри сегмента. Блок сегментного преобразования MMU проводит трансляцию логического адреса в номер страницы и смещение в ней, которые затем транслируются в физический адрес блоком страничного преобразования MMU .
Таким образом, основой получения физического адреса памяти служит логический адрес . В какой-то степени логическое адресное пространство , с которым имеет дело программист, можно сравнить со структурой книги, где аналогом сегмента выступает рассказ, страница книги соответствует странице ЛАП, а искомая информация - это некоторое слово . При этом если память организована как линейная, то номер искомого слова задается в явном виде и просто отсчитывается от начала книги. При сегментном представлении памяти искомое слово определяется его номером в заданном рассказе. Страничное представление памяти предполагает задание информации о слове в виде номера страницы в книге и номера слова на указанной странице. При сегментно-страничном представлении логический адрес слова задается номером слова в определенном рассказе. В этом случае по оглавлению книги определяется номер страницы, с которой начинается указанный рассказ. Затем, зная количество слов на странице и положение слова в рассказе, можно вычислить страницу книги и положение искомого слова на этой странице.
Символьный тип данных
Значение переменной этого типа данных представляет собой один символ. В действительности, это есть целое число. В зависимости от кодировки, это число превращается в некий символ. Данные типы данных характеризуются лишь размером выделяемой под них памяти.
Массив
Далее перейдем к сложным типам данных. Первый из них - это массив. Массив - это набор однотипных переменных, расположенных в памяти непосредственно друг за другом, доступ к которым осуществляется по индексу. Индекс массива — целое число, указывающее на конкретный элемент массива.
Каждый массив характеризуется типом данных его элементов, который может быть как простым, так и сложным, то есть любым.
В языках программирования нельзя оперировать всем массивом, работают с конкретным элементом. Чтобы доступиться до него в трёх рассматриваемых нами языках используют оператор "[]".
Логическое адресное пространство
Для адресации операндов в физическом адресном пространстве программы используют логическую адресацию. Процессор автоматически транслирует логические адреса в физические, выдаваемые затем на системную шину.
Архитектура компьютера различает физическое адресное пространство (ФАП) и логическое адресное пространство (ЛАП). Физическое адресное пространство представляет собой простой одномерный массив байтов, доступ к которому реализуется аппаратурой памяти по адресу, присутствующему на шине адреса микропроцессорной системы . Логическое адресное пространство организуется самим программистом исходя из конкретных потребностей. Трансляцию логических адресов в физические осуществляет блок управления памятью MMU .
В архитектуре современных микропроцессоров ЛАП представляется в виде набора элементарных структур: байтов, сегментов и страниц. В микропроцессорах используются следующие варианты организации логического адресного пространства:
- плоское (линейное) ЛАП: состоит из массива байтов, не имеющего определенной структуры; трансляция адреса не требуется, так как логический адрес совпадает с физическим;
- сегментированное ЛАП: состоит из сегментов - непрерывных областей памяти, содержащих в общем случае переменное число байтов; логический адрес содержит 2 части: идентификатор сегмента и смещение внутри сегмента; трансляцию адреса проводит блок сегментации MMU ;
- страничное ЛАП: состоит из страниц - непрерывных областей памяти, каждая из которых содержит фиксированное число байтов. Логический адрес состоит из номера (идентификатора) страницы и смещения внутри страницы; трансляция логического адреса в физический проводится блоком страничного преобразования MMU ;
- сегментно-страничное ЛАП: состоит из сегментов, которые, в свою очередь, состоят из страниц; логический адрес состоит из идентификатора сегмента и смещения внутри сегмента. Блок сегментного преобразования MMU проводит трансляцию логического адреса в номер страницы и смещение в ней, которые затем транслируются в физический адрес блоком страничного преобразования MMU .
Таким образом, основой получения физического адреса памяти служит логический адрес . В какой-то степени логическое адресное пространство , с которым имеет дело программист, можно сравнить со структурой книги, где аналогом сегмента выступает рассказ, страница книги соответствует странице ЛАП, а искомая информация - это некоторое слово . При этом если память организована как линейная, то номер искомого слова задается в явном виде и просто отсчитывается от начала книги. При сегментном представлении памяти искомое слово определяется его номером в заданном рассказе. Страничное представление памяти предполагает задание информации о слове в виде номера страницы в книге и номера слова на указанной странице. При сегментно-страничном представлении логический адрес слова задается номером слова в определенном рассказе. В этом случае по оглавлению книги определяется номер страницы, с которой начинается указанный рассказ. Затем, зная количество слов на странице и положение слова в рассказе, можно вычислить страницу книги и положение искомого слова на этой странице.
Вещественные типы данных
Числа вещественного типа данных задаются в форме чисел с плавающей запятой.
Плавающая запятая — форма представления действительных чисел, в которой число хранится в форме мантиссы и показателя степени. В случае языков программирования, любое число может быть представлено в следующем виде
где N — записываемое число;
M — мантисса;
p (целое) — порядок.
Например: 14441544=1,4441544*10 7 ; 0,0004785=4,785*10 -4 . Компьютер же на экран выведет следующие числа:
Следовательно, в отведенной памяти хранится мантисса и порядок записываемого числа. Рассмотрим на примера типа данных, который хранится в 8 байтах или 64 битах. В данном случае, мантисса составляет 53 бита: 1 для знака числа и 52 для её значения; порядок 10 битов: 1 бит для знака и 10 для значения. Мы можем в данном случае говорить о диапазоне точности, то есть насколько малое и насколько большое число может хранить данный тип данных: 4,94×10 −324 до 1.79×10 308 . Но, поскольку, память компьютера не безразмерна, да и далеко не всегда нужно, храниться несколько первых разрядов мантиссы, которые называются значащими.
Вывод: вещественные типы данных, в отличии от целочисленных, характеризуются диапазоном точности и количеством значащих разрядов.
Рассмотрим конкретные типы данных в наших трёх языках.
| Тип | Разрядность в битах | Количество значащих цифр | Диапазон точности |
|---|---|---|---|
| float | 32 | 7 | от 1,5*10 -45 до 3,4*10 38 |
| double | 64 | 15 | от 4,9*10 -324 до 1,7*10 308 |
| decimal | 128 | 28 | от 1,0*10 -28 до 7,9*10 28 |
Тип decimal создан специально для операций высокой точности, в частности финансовых операций. Он не реализован как примитивный тип, по-этому его частое использование может повлиять на производительность вычислений.
| Тип | Разрядность в битах | Количество значащих цифр | Диапазон точности |
|---|---|---|---|
| float | 32 | 7 | от 1,5*10 -45 до 3,4*10 38 |
| double | 64 | 15 | от 4,9*10 -324 до 1,7*10 308 |
| Тип | Разрядность в битах | Количество значащих цифр | Диапазон точности |
|---|---|---|---|
| float | 32 | 7 | от 1,5*10 -45 до 3,4*10 38 |
| double | 64 | 15 | от 4,9*10 -324 до 1,7*10 308 |
Читайте также: