
Какая память хранит правки в файле
Файлы… что вообще может быть проще? Мы все привыкли создавать, удалять, редактировать, перекидываться файлами.
Но можем ли мы заглянуть внутрь каждого файла и понять как он устроен? Конечно можем, поэтому сегодня мы немного покопаемся в бинарном коде и пощупаем метаданные.
Заодно узнаем, почему iPhone зависает от SMS и распотрошим PowerPoint.
Почему форматов файлов так много?
Если бы мы просто могли взглянуть на сырые данные, которые хранятся внутри жесткого диска или SSD, то мы бы не увидели никаких файлов: мы бы увидели только нолики и единички. Потому как, в любом случае, в памяти компьютера всё хранится в виде сплошного потока двоичного кода.
Но как же тогда понять, где заканчивается один файл и начинается другой?
Поначалу эту проблему человечество решало брутально. Люди записывали один файл на один жесткий диск, чтобы уж точно не ошибиться. Поэтому раньше словом файл называли не отдельную область на жестком диске, а прям целое устройство. К примеру IBM 305.

CTSS (Compatible Time-Sharing System)
Но потом, люди придумали файловые системы. Если очень упростить, это такое оглавление в котором указано имя файла, где он начинается и его длина. А также всякие метаданные, типа время создания, изменения, и можно ли его перезаписывать.

Но для того чтобы прочитать файл, знать его местоположение и границы на жестком диске недостаточно, ведь нам нужно как-то расшифровать бинарный код.
Для этого и существуют различные форматы файлов. В большинстве операционных систем форматы файлов указываются в виде расширения, которое отделяется точкой от имени файла. А если вы не видите расширения, это нормально. Потому что, по умолчанию, современные ОС их скрывают, но можно поставить галочку в настройках.
Расширение даёт подсказку операционной системе и программам, о том какой тип данных он содержит и как это всё структурировано. Например, увидев файл droider.jpg операционная система и мы, люди, сразу понимаем, что это картинка в формате JPEG.
Естественно, для типов данных и разных задач оптимальной будет разная структура файла. Поэтому и форматов файлов существует огромная масса.
Поэтому давайте разберем, как устроены наиболее популярные форматы файлов от более простых к более сложным.
Один из самый простых форматов — это TXT. Это текстовый формат. Знаменитое приложение «Блокнот» в Windows работает как раз с этим форматом.
TXT — формат незамысловатый. Он может хранить в себе только простой неформатированный текст, то есть в нем нет никаких выделений, подчеркиваний, курсивов, отступов, разных шрифтов. Только голый текст, а точнее просто символы.
Каждый символ в TXT-формате хранится в виде бинарного кода.
То что мы с вами видим как осмысленный текст, операционная система видит вот так:
01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001
Каждые 8 цифр, то есть 8 бит этого кода — это отдельный символ.
Например, 01001000 — это “H”, 01100101 — это “e”, и так далее.
Подобрав правильную кодировку остается дело техники. Система сопоставляет бинарный код с таблицей кодировки UTF-8 и готово! Но что будет если система подберет кодировку неправильно? Вариантов не много, скорее всего мы увидим крякозябры:
И такое часто случается, так как TXT-файл не содержит никакой дополнительной информации о кодировке. И это большой недостаток формата.
И вдобавок, эту таблицу нужно было загрузить в оперативную память при загрузке компьютера, а у типового ПК в начале 80-х годов редко было больше 640 килобайт оперативки. А использовать 16-битные таблицы (65536 вариантов) было просто невозможно, такая таблица просто не влезла бы в память.
Но мощность компьютеров росла и проблема ушла. К таблицам с латинскими символами добавились кириллические, которые занимали уже не по 8 бит, а по 16 бит каждый. Поэтому текст на русском занимает в два раза больше памяти, при том же количестве символов.
11010000 10011111 11010001 10000000 11010000 10111000 11010000 10110010 11010000 10110101 11010001 10000010 00101100 00100000 11010000 10111100 11010000 10111000 11010001 10000000 00100001
11010000 10011111 — П
11010001 10000000 — р
10111000 11010000 — и
11010000 10110010 — в
Старики помнят лайфхак, если писать SMS на латинице, то влезет в два раза больше текста. Всё это как раз из-за кодировки.
Так вот, чтобы у операционной системы не было проблем с пониманием как прочитать файл. Помимо самих данных, в разные форматы стали добавлять данные о данных. То есть метаданные, которые хранятся прямо внутри файла и содержат дополнительную информацию о том, как этот файл прочитать.
Это простой аудиоформат, который содержит несжатый. Всё CD диски записаны в формате WAV.

Первые 44 байта классического WAV-файла содержат заголовок, к котором указывается полезнейшая информация:
- количество аудио каналов;
- частота дискретизации;
- битовая глубина;
- и многое другое.
Открытые и проприетарные форматы
Структура WAV хорошо известна и наверное такой файл сможет прочитать практически любой плеер. Всё потому, что WAV-файл — это пример открытого формата.
Есть и другие открытые форматы, которыми вы ежедневно пользуетесь. Например:
- язык разметки web-страниц — HTML;
- картинки — PNG;
- аудио в формате — OGG;
- архива — ZIP;
- видео — MKV;
- электронной книги — EPUB;
- и другие.
Проприетарные форматы всем прекрасны, но в отдельных случаях они препятствуют конкуренции в сфере программного обеспечения, так как приводят к замыканию на поставщике. Есть даже такой термин Vendor lock-in.
Старый офис
Например, раньше такая ситуация была с форматами Microsoft Office: DOC, XLS, PPT.
Мало того, что это были проприетарные форматы компании Microsoft и работали только с фирменным ПО. Так еще Microsoft постоянно меняли свою структуру файлов от одной версии MS Office к другой. И в результате? при выходе новой версии офисного пакета? файлы из старого редактора уже не читались новым, а наоборот — и подавно.
Такая ситуация не очень нравилась Европейскому Союзу. Поэтому, ЕС взъелся на тему ограничения конкуренции. В итоге, форматы файлов опубличили, и все научились хотя бы их читать, но для записи в старые форматы, по-прежнему, нужна лицензия Microsoft. И параллельно этому начали разрабатываться открытые форматы.
ODF и OOXML
1 мая 2006 года на свет появился формат формат ODF, что буквально расшифровывается как открытый формат документов для офисных приложений. Он был разработан консорциумом OASIS и Sun Microsystems.
- ODF — Open Document Format for Office Application.
- OASIS — Organization for the Advancement of Structured Information Standards.

Microsoft тоже не спал. Под давлением Европейского суда они объединились с рядом компаний в ассоциацию ECMA и разработали свой открытый формат Office Open XML, который появился на свет чуть позже в 2006 году.
OOXML стандартизирован European Computer Manufacturers Association. Standard ECMA-376
К привычным форматом конце добавилась буква X и мы получили: DOCX, XLSX, PPTX.
OOXML — Office Open XML (DOCX, XLSX, PPTX)
OOXML, в целом, очень похож на ODF. Он также основан на XML-разметке и также представляет из себя ZIP-архив. Поэтому вы также можете заглянуть внутрь офисных файлов при помощи любого архиватора. Можно даже вытащить картинки и даже подменить их, что бывает особенно удобно при работе с презентациями или когда вам присылают текстовый документ с картинками внутри файла.

Несмотря на кажущуюся простоту, формат реально сложный. Только основная документация — это 5 тысяч страниц. И это практически без картинок.
Тем не менее, кто-то всё таки смог прочитать всю эту документацию и поэтому на свет появились классные офисные пакеты, например МойОфис, которые умеют работать и ODF форматом, и с Office Open XML, и даже с устаревшими форматами типа DOC.
Но есть важная ремарка про старые форматы. Как правило, современный софт умеет их только читать, но не записывать, потому как это действие требует приобретение лицензии Microsoft. Впрочем, в наше время это действие, мягко говоря, бессмысленно.
Итого

Что мы в итоге узнали? Файлы бывают нескольких типов:
Самые базовые — бинарные. Такие форматы любят придумывать компании, чтобы никто не понял, как их программы хранят данные.
Более открытый вариант — xml-контейнеры. К счастью, большинство популярных офисных форматов сейчас такие. Если хотите работать со всеми этими файлами хоть дома, хоть на бегу, скачивайте программы МойОфис! На этом у нас сегодня всё.
Управление памятью – одна из главных задач ОС. Она критична как для программирования, так и для системного администрирования. Я постараюсь объяснить, как ОС работает с памятью. Концепции будут общего характера, а примеры я возьму из Linux и Windows на 32-bit x86. Сначала я опишу, как программы располагаются в памяти.
Каждый процесс в многозадачной ОС работает в своей «песочнице» в памяти. Это виртуальное адресное пространство, которое в 32-битном режиме представляет собою 4Гб блок адресов. Эти виртуальные адреса ставятся в соответствие (mapping) физической памяти таблицами страниц, которые поддерживает ядро ОС. У каждого процесса есть свой набор таблиц. Но если мы начинаем использовать виртуальную адресацию, приходится использовать её для всех программ, работающих на компьютере – включая и само ядро. Поэтому часть пространства виртуальных адресов необходимо резервировать под ядро.


Это не значит, что ядро использует так много физической памяти – просто у него в распоряжении находится часть адресного пространства, которое можно поставить в соответствие необходимому количеству физической памяти. Пространство памяти для ядра отмечено в таблицах страниц как эксклюзивно используемое привилегированным кодом, поэтому если какая-то программа пытается получить в него доступ, случается page fault. В Linux пространство памяти для ядра присутствует постоянно, и ставит в соответствие одну и ту же часть физической памяти у всех процессов. Код ядра и данные всегда имеют адреса, и готовы обрабатывать прерывания и системные вызовы в любой момент. Для пользовательских программ, напротив, соответствие виртуальных адресов реальной памяти меняется, когда происходит переключение процессов:
Голубым отмечены виртуальные адреса, соответствующие физической памяти. Белым – пространство, которому не назначены адреса. В нашем примере Firefox использует гораздо больше места в виртуальной памяти из-за своей легендарной прожорливости. Полоски в адресном пространстве соответствуют сегментам памяти таким, как куча, стек и проч. Эти сегменты – всего лишь интервалы адресов памяти, и не имеют ничего общего с сегментами от Intel. Вот стандартная схема сегментов у процесса под Linux:

Когда программирование было белым и пушистым, начальные виртуальные адреса сегментов были одинаковыми для всех процессов. Это позволяло легко удалённо эксплуатировать уязвимости в безопасности. Зловредной программе часто необходимо обращаться к памяти по абсолютным адресам – адресу стека, адресу библиотечной функции, и т.п. Удаленные атаки приходилось делать вслепую, рассчитывая на то, что все адресные пространства остаются на постоянных адресах. В связи с этим получила популярность система выбора случайных адресов. Linux делает случайными стек, сегмент отображения в память и кучу, добавляя смещения к их начальным адресам. К сожалению, в 32-битном адресном пространстве особо не развернёшься, и для назначения случайных адресов остаётся мало места, что делает эту систему не слишком эффективной.
Самый верхний сегмент в адресном пространстве процесса – это стек, в большинстве языков хранящий локальные переменные и аргументы функций. Вызов метода или функции добавляет новый кадр стека (stack frame) к существующему стеку. После возврата из функции кадр уничтожается. Эта простая схема приводит к тому, что для отслеживания содержимого стека не требуется никакой сложной структуры – достаточно всего лишь указателя на начало стека. Добавление и удаление данных становится простым и однозначным процессом. Постоянное повторное использование районов памяти для стека приводит к кэшированию этих частей в CPU, что добавляет скорости. Каждый поток выполнения (thread) в процессе получает свой собственный стек.
Можно прийти к такой ситуации, в которой память, отведённая под стек, заканчивается. Это приводит к ошибке page fault, которая в Linux обрабатывается функцией expand_stack(), которая, в свою очередь, вызывает acct_stack_growth(), чтобы проверить, можно ли ещё нарастить стек. Если его размер не превышает RLIMIT_STACK (обычно это 8 Мб), то стек увеличивается и программа продолжает исполнение, как ни в чём не бывало. Но если максимальный размер стека достигнут, мы получаем переполнение стека (stack overflow) и программе приходит ошибка Segmentation Fault (ошибка сегментации). При этом стек умеет только увеличиваться – подобно государственному бюджету, он не уменьшается обратно.
Динамический рост стека – единственная ситуация, в которой может осуществляться доступ к свободной памяти, которая показана белым на схеме. Все другие попытки доступа к этой памяти вызывают ошибку page fault, приводящую к Segmentation Fault. А некоторые занятые области памяти служат только для чтения, поэтому попытки записи в эти области также приводят к Segmentation Fault.
После стека идёт сегмент отображения в память. Тут ядро размещает содержимое файлов напрямую в памяти. Любое приложение может запросить сделать это через системный вызов mmap() в Linux или CreateFileMapping() / MapViewOfFile() в Windows. Это удобный и быстрый способ организации операций ввода и вывода в файлы, поэтому он используется для подгрузки динамических библиотек. Также возможно создать анонимное место в памяти, не связанное с файлами, которое будет использоваться для данных программы. Если вы сделаете в Linux запрос на большой объём памяти через malloc(), библиотека C создаст такую анонимное отображение вместо использования памяти из кучи. Под «большим» подразумевается объём больший, чем MMAP_THRESHOLD (128 kB по умолчанию, он настраивается через mallopt().)
Если в куче оказывается недостаточно места для выполнения запроса, эту проблему может обработать сама программа без вмешательства ядра. В ином случае куча увеличивается системным вызовом brk(). Управление кучей – дело сложное, оно требует хитроумных алгоритмов, которые стремятся работать быстро и эффективно, чтобы угодить хаотичному методу размещению данных, которым пользуется программа. Время на обработку запроса к куче может варьироваться в широких пределах. В системах реального времени есть специальные инструменты для работы с ней. Кучи тоже бывают фрагментированными:

И вот мы добрались до самой нижней части схемы – BSS, данные и текст программы. BSS и данные хранят статичные (глобальные) переменные в С. Разница в том, что BSS хранит содержимое непроинициализированных статичных переменных, чьи значения не были заданы программистом. Кроме этого, область BSS анонимна, она не соответствует никакому файлу. Если вы пишете static int cntActiveUsers , то содержимое cntActiveUsers живёт в BSS.
Сегмент данных, наоборот, содержит те переменные, которые были проинициализированы в коде. Эта часть памяти соответствует бинарному образу программы, содержащему начальные статические значения, заданные в коде. Если вы пишете static int cntWorkerBees = 10 , то содержимое cntWorkerBees живёт в сегменте данных, и начинает свою жизнь как 10. Но, хотя сегмент данных соответствует файлу программы, это приватное отображение в память (private memory mapping) – а это значит, что обновления памяти не отражаются в соответствующем файле. Иначе изменения значения переменных отражались бы в файле, хранящемся на диске.
Пример данных на диаграмме будет немного сложнее, поскольку он использует указатель. В этом случае содержимое указателя, 4-байтный адрес памяти, живёт в сегменте данных. А строка, на которую он показывает, живёт в сегменте текста, который предназначен только для чтения. Там хранится весь код и разные другие детали, включая строковые литералы. Также он хранит ваш бинарник в памяти. Попытки записи в этот сегмент оканчиваются ошибкой Segmentation Fault. Это предотвращает ошибки, связанные с указателями (хотя не так эффективно, как если бы вы вообще не использовали язык С). На диаграмме показаны эти сегменты и примеры переменных:

Изучить области памяти Linux-процесса можно, прочитав файл /proc/pid_of_process/maps. Учтите, что один сегмент может содержать много областей. К примеру, у каждого файла, сдублированного в память, есть своя область в сегменте mmap, а у динамических библиотек – дополнительные области, напоминающие BSS и данные. Кстати, иногда, когда люди говорят «сегмент данных», они имеют в виду данные + bss + кучу.
Бинарные образы можно изучать при помощи команд nm и objdump – вы увидите символы, их адреса, сегменты, и т.п. Схема виртуальных адресов, описанная в этой статье – это т.н. «гибкая» схема, которая по умолчанию используется уже несколько лет. Она подразумевает, что переменной RLIMIT_STACK присвоено какое-то значение. В противном случае Linux использует «классическую» схему:
Встречаются гибридные решения, когда текст хранится в наборе массивов, которые, в свою очередь, объединены в список. Казалось бы, такой подход позволяет объединить преимущества массивов и списков (быстрая вставка/удаление при низких накладных расходах по памяти). Однако такое решение сложно в реализации. Также оно приводит к фрагментации памяти.
Предлагаю вашему вниманию эффективную структуру данных для хранения редактируемого текста, которая проста в реализации, имеет константные накладные расходы по памяти и быструю вставку/удаление в произвольном месте. Также она позволяет эффективно редактировать файлы, которые целиком не умещаются в оперативную память.
Описание
Такая структура данных называется в английской терминологии Gap Buffer. Русское название мне неизвестно, встречается только термин «буферное окно» в русской Википедии. Не знаю, правда, доверять такому переводу термина или нет.
Анализ
- Операции вставки и удаления — дешевые: O(1) как при вставке отдельного символа, так и их группы (например, вставка из буфера обмена).
- Накладные расходы по памяти — низкие: O(1). Нужно хранить только положение курсора и общий размер буфера.
- Операция поиска элемента по индексу — дешевая: O(1).
- Операция копирования участка содержимого (например, для копирования в буфер обмена или сохранения текста на диск) — O(n), где n — размер копируемого участка. Сложность такая же, как для массива.
Таким образом, Gap Buffer эксплуатирует то свойство процесса редактирования текста, что операции вставки и удаления всегда происходят в том месте, где находится курсор; в свою очередь, перемещения курсора обычно бывают невелики.
Вариации
1. Теневой курсор записи
В своей базовой реализации Gap Buffer все же может вызывать нежелательные задержки. Например, при поиске текста или использовании закладок могут происходить значительные перемещения курсора. Также не всякое перемещение курсора по тексту сопровождается редактированием. Отсюда решение: ввести невидимый пользователю «курсор записи», который соответствует разрыву в Gap Buffer. Этот курсор перемещается только тогда, когда пользователь начинает вставку или удаление текста. При простых же перемещениях видимого курсора по тексту или замене (то есть когда общий размер текста не меняется) курсор записи не перемещать. Тем самым устраняются задержки при любых случайных перемещениях видимого курсора при просмотре текста, использовании закладок, поиска и т.д.
2. Редактирование файлов, которые не умещаются в оперативную память
В нашу эпоху оперативной памяти гигабайтного размера мало кто реализует редакторы, которые обходятся без полной загрузки текста в память. Большинство созданных людьми документов умещаются в нее, поэтому просто нет смысла усложнять редактор. Однако иногда возникает необходимость редактировать большие файлы, которые не умещаются даже в память сегодняшних компьютеров. Это могут быть машинно-генерированные данные, такие как лог-файлы или текстовое представление записи с каких-нибудь датчиков или приборов.
С помощью Gap Buffer можно эффективно реализовать редактирование файлов, размер которых превышает размер оперативной памяти компьютера. Можно заметить, что Gap Buffer фактически представляет собой два стека, один из которых хранит данные до курсора, а второй — после курсора. Первый из стеков растет вверх, а второй — вниз. Отсюда идея: реализовать оба стека в виде файлов, при этом храня в оперативной памяти только те их участки, которые находятся ближе к вершине.
Стек в памяти может расти вверх или вниз, а стек, реализованный в виде файла, может расти только вверх. Только к концу файла мы можем дописывать данные или наоборот, удалять их оттуда. Если вернуться теперь к операциям с памятью и рассмотреть стеки, растущие в разные стороны — то видно, что в стеке, растущем вверх, данные располагаются в прямом порядке по отношению к последовательности помещения их на стек, а в стеке, растущем вниз — в обратном порядке. Так что, если мы хотим реализовать Gap Buffer в виде двух стеков, растущих вверх — нам придется поменять порядок элементов во втором стеке, который хранит текст после курсора. Поэтому тот временный файл, который содержит данные после курсора, должен их содержать в обратном порядке, задом наперед.
Во временных файлах мы будем хранить не все содержимое стеков, а только их нижнюю часть. Верхняя часть будет располагаться в оперативной памяти, образуя как бы «локальный» Gap Buffer и позволяя пользователю, как и прежде, быстро редактировать текст и перемещаться по нему в некоторых пределах. При перемещениях курсора по тексту за пределы загруженного в память участка, его часть, наиболее далекая от курсора, будет сохраняться в один из временных файлов, а из другого будет подгружаться недостающая часть.
По окончании редактирования текста мы просто перемещаем курсор в его конец. Весь текст попадает в первый стек, растущий вверх, то есть первый временный файл. В оперативной памяти, возможно, остается еще кусок текста — его просто дописываем к файлу. После этого первый временный файл содержит сохраненный текст.
Можно реализовать еще несколько оптимизаций. При открытии файла, например, курсор обычно находится в его начале. Весь текст поэтому должен располагаться во втором стеке, то есть мы должны практически всё исходное содержимое редактируемого файла скопировать во второй временный файл задом наперед. Это длительная операция. Ее можно избежать, если отложить создание второго временного файла до тех пор, пока в этом не возникнет необходимость. То есть до тех пор, пока содержимое хвоста исходного файла полностью совпадает с содержимым второго стека. В этот период, вместо использования второго временного файла, мы можем подгружать информацию из исходного файла. Для создания второго временного файла, таким образом, придется сначала переместить курсор по тексту на расстояние, превышающее размер свободной оперативной памяти, потом что-нибудь там отредактировать, а потом вернуться назад, к началу текста.
Такую же оптимизацию можно реализовать и для первого временного файла. Не создавать его до тех пор, пока в нем не возникнет необходимость. А возникнет она не ранее, чем содержимое находящейся на диске части первого стека перестанет совпадать с начальным участком исходного файла. Также можно использовать «теневой курсор записи» и тем самым избежать ненужных операций копирования при перемещениях курсора по тексту без редактирования. Тогда, если пользователь далеко перемещает курсор по тексту без редактирования, скорость работы будет не хуже, чем у программы простого просмотра текста без полной его загрузки в память.
Реализованное описанным способом редактирование текста без полной его загрузки в память имеет, таким образом, умеренные накладные расходы по дисковому пространству: для временных файлов требуется место, равное размеру текста.
Интересно, что даже если текст большого объема в принципе влезает в оперативную память, при использовании редактора, который не загружает его целиком, такой документ будет быстрее открываться. Снова-таки повышение удобства для пользователя.
Заключение
Я уже не первый раз сталкиваюсь с тем, что некоторые технологии, разработанные для старых компьютеров с ограниченными возможностями, оказываются в наше время забытыми, что приводит к распространению неэффективных решений. Надеюсь, что описанное в этой статье «тайное знание предков» поможет появлению на свет хороших текстовых редакторов.
Благодарности
Итак, мы познакомились с разными видами внутренней и внешней памяти. Осталось разобраться, как они взаимодействуют между собой.

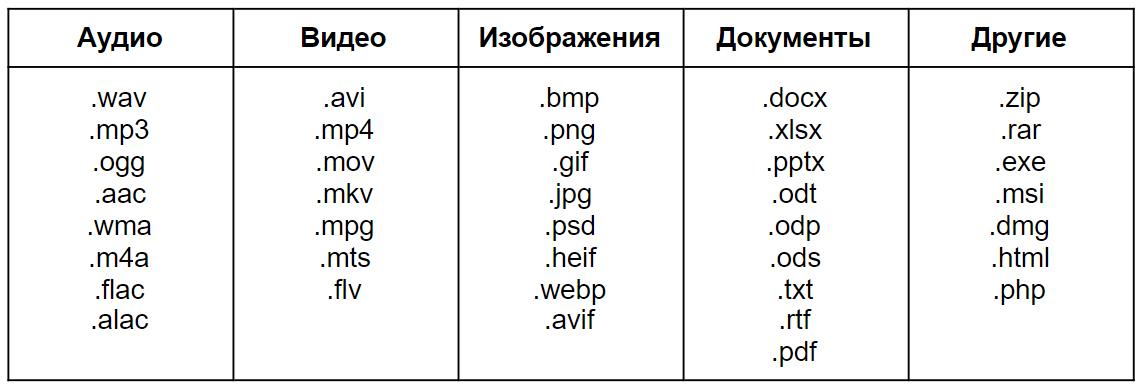
Иерархия памяти. Кэширование. Как следует из обсуждения в § 32, невозможно создать память, которая имела бы одновременно большой объём и высокое быстродействие. Поэтому используют многоуровневую (иерархическую) систему из нескольких типов памяти. Как правило, чем больший объём имеет память, тем медленнее она работает.
Самая быстрая (и очень небольшая) память — это регистры процессора. Гораздо больше по объёму, но заметно медленнее внутренняя память (ОЗУ и ПЗУ). Далее следует огромная, но ещё более медленная внешняя память. Наконец, последний уровень — это данные, которые можно получить из компьютерных сетей (рис. 5.19).
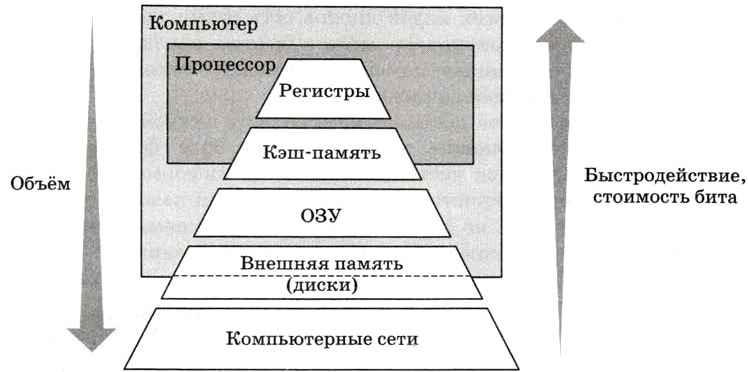
Рис. 5.19
Для редактирования файла, расположенного на диске (внешняя память), программа обработки загружает его в ОЗУ (внутренняя память), а конкретные символы, с которыми в данные доли секунды работает процессор, «поднимаются» по иерархии выше — в регистры процессора.
Производительность компьютера в первую очередь зависит от «верхних» уровней памяти — процессорной памяти и ОЗУ. Быстродействие процессоров значительно выше, чем скорость работы ОЗУ, поэтому процессору приходится ждать, пока до него дойдут данные из оперативной памяти. Чтобы улучшить ситуацию, между процессором и ОЗУ добавляют ещё один слой памяти, который называют кэш-памятью, или кэшем (от англ, cache — тайник, прятать).

Кэш-память — это память, ускоряющая работу другого (более медленного) типа памяти, за счёт сохранения прочитанных данных на случай повторного обращения к ним.
Кэш-память — это статическая память, которая работает значительно быстрее динамического ОЗУ. В ней нет собственных адресов, она работает не по фон-неймановскому принципу адресности.
При чтении из ОЗУ процессор обращается к контроллеру кэш-памяти, который хранит список всех ячеек ОЗУ, копии которых находятся в кэше. Если требуемый адрес уже есть в этом списке, то запрашивать ОЗУ не нужно и контроллер передаёт процессору значение, связанное (ассоциированное) с этим адресом (рис. 5.20) 1 . Такой принцип организации памяти называется ассоциативным.
1 Это напоминает поиск в Интернете содержимого документа по его названию.
Если нужных данных нет в кэш-памяти, они читаются из ОЗУ, но одновременно попадают и в кэш — при следующем обращении их уже не нужно читать из ОЗУ.
Рис. 5.20
Обычно в кэш-память заносится содержимое не только запрошенной ячейки, но и ближайших к ней (эта стрелка на рис. 5.20 показана более толстой). Таким образом, в кэше хранятся копии часто используемых ячеек ОЗУ, и передача этих данных в процессор происходит быстрее.
В работе кэш-памяти есть две основные трудности. Во-первых, объём кэша намного меньше объёма ОЗУ, и он быстро заполняется — приходится заменять наиболее «ненужные» (например, редко используемые) данные. Во-вторых, если считанные из кэш-памяти данные обрабатываются процессором и сохраняются в ОЗУ, нужно обновлять и содержимое кэша. Обе эти задачи решает контроллер кэш-памяти. Несмотря на трудности, кэширование во многих случаях повышает скорость выполнения программы в несколько раз.
Сама кэш-память также строится по многоуровневой схеме: в современных процессорах есть, по крайней мере, 2-3 уровня. Некоторые из них входят в состав процессора, а остальные выполнены в виде отдельных микросхем (поэтому на схеме многоуровневой памяти на рис. 5.19 кэш только частично расположен внутри процессора). Кэш для программ и для данных изготовляется раздельно. Это удобно потому, что считываемую программу, в отличие от данных, не принято изменять, поэтому кэш команд можно делать проще.
Подчеркнём, что термин «кэширование» в вычислительной технике имеет довольно широкий смысл: речь идёт о сохранении информации в более быстродействующей памяти с целью повторного использования. Например, браузер кэширует файлы, полученные из Интернета, сохраняя их на жёстком диске в специальной папке. В накопителе на жёстком диске также используется кэширование. Таким образом, кэш может быть организован как с помощью аппаратных средств (кэш процессора), так и программно (кэш браузера).
Виртуальная память. Пользователям хочется, чтобы программное обеспечение было интеллектуальным и дружественным и чтобы в нём были предусмотрены все самые мелкие детали, которые им могут потребоваться. Программистам хочется написать программу с наименьшими затратами сил и времени, поэтому они широко используют среды быстрой разработки программ (англ. RAD — Rapid. Application Development). В результате программы всё больше увеличиваются в размере. Кроме того, объём обрабатываемых данных постоянно растёт. Поэтому компьютерам требуется все больше и больше памяти, особенно в многозадачном режиме, когда одновременно запускаются сразу несколько программ.
Как же согласовать эти требования с ограниченным объёмом ОЗУ? Современные операционные системы используют для этого идею виртуальной памяти. Предполагается, что компьютер обладает максимально допустимым объёмом памяти, с которым может работать процессор, а реально установленное ОЗУ — лишь некоторая часть этого пространства. Оставшаяся часть размещается в специальном системном файле или отдельном разделе жёсткого диска. Если ёмкости ОЗУ не хватает для очередной задачи, система копирует «наименее нужную» (дольше всего не использовавшуюся) часть ОЗУ на диск, освобождая необходимый объём памяти. Когда, наоборот, потребуются данные с диска, они будут возвращены в освобожденное таким же образом место ОЗУ (и это совсем не обязательно будет то самое первоначальное место!).
При использовании виртуальной памяти выполнение программ замедляется, но зато они могут выполняться на компьютере с недостаточным объёмом ОЗУ. В этом случае установка дополнительного ОЗУ может повысить быстродействие во много раз.
Использование виртуальной памяти ещё раз подтверждает, что деление памяти на внутреннюю и внешнюю память — это искусственная мера. Она вызвана тем, что невозможно создать идеальную память, удовлетворяющую всем требованиям сразу.

Следующая страница Основные характеристики памяти

Cкачать материалы урока
- Использование знаков препинания при наборе текста.
- Использование режимов вставки и замены при наборе текста.
- Вставка символов.
- Удаление символов.
- Объединение строк.
- Разделение строк.
- Загрузка файла.
- Сохранение файла на диске.
Режим ввода-редактирования текста
Ввод-редактирование — это основной режим работы текстового редактора.
При записи текста на бумаге мы пользуемся ручкой или карандашом. Ввод (запись) текста в память компьютера производится с помощью клавиатуры. Если в прежние времена, до массового распространения ПК, быстро набирать текст на клавишах пишущих машинок умели только профессиональные машинистки, то сейчас этот навык становится необходимым для большинства людей. На занятиях в компьютерном классе вам поможет овладеть этим навыком учитель. Кроме того, существуют специальные учебные программы-тренажеры, развивающие умение быстро работать на клавиатуре.
При работе с текстовым редактором в режиме ввода-редактирования по экрану монитора перемещается курсор, который указывает текущую позицию для ввода. Символ, соответствующий нажатой клавише, помещается в позицию курсора, который после этого перемещается на один шаг вправо или, если достигнут конец строки, в начало следующей строки.
Под редактированием понимается внесение любых изменений в набранный текст. Чаще всего приходится стирать ошибочный символ, слово, строку; заменять один символ на другой; вставлять пропущенные символы, слова, строки. В процессе редактирования текста пользователь может изменять шрифты, форматировать текст, выделять фрагменты и манипулировать ими (переносить, удалять, копировать). В многооконных редакторах можно «разложить» сразу несколько документов в разных окнах и быстро переходить от одного к другому.
Поиск и замена фрагмента
Представьте, что в большом по объему тексте вам нужно найти определенное слово или фразу. В «бумажном» тексте, например в книге, такой поиск может занять довольно много времени. В компьютерном тексте текстовый редактор сделает это за вас достаточно быстро. В большинстве текстовых редакторов реализован режим поиска. Указав искомое слово (или фразу) и отдав команду «Поиск», вы можете быть уверены, что текстовый редактор не пропустит ни одного места в тексте, где слово встречается.
Часто поиск фрагмента текста совмещается с заменой одних слов на другие. Например, в некотором тексте вам требуется заменить слово «дисплей» на слово «монитор». Для этого достаточно отдать команду: «Заменить» «дисплей» на «монитор». И текстовый редактор произведет такую замену во всем документе.
Печать документа
Тексты, созданные с помощью текстового редактора, можно распечатать на бумаге. Для этого предусмотрен режим печати. Он включается командой «Печать».
Компьютер для этого, во-первых, должен быть оснащен устройством печати — принтером. Во-вторых, поскольку существует очень много разных типов принтеров, постольку компьютер должен быть настроен на работу именно с тем принтером, который имеется в наличии. Настройка на тип принтера происходит путем установки специальной системной программы управления принтером, называемой драйвером. Поэтому имейте в виду, что если на вашей машине не выполняется печать, то это еще не значит, что неисправен принтер. Вполне возможно, что с принтером работает «чужой» драйвер.
Обычно текстовые редакторы позволяют настроить работу принтера на определенный режим. Можно, например, выполнить черновую печать, которая производится быстрее, чем обычная, но с низким качеством, можно установить режим высококачественной печати, если требуется получить «красивый» документ.
Работа с окнами
Часто человеку, работающему с деловыми бумагами, документами, приходится держать на столе открытыми одновременно несколько документов. Новый документ может составляться из фрагментов уже имеющихся документов. То же самое можно делать на компьютере, если ваш текстовый редактор поддерживает многооконный режим работы. Причем на компьютере это делать гораздо удобнее, поскольку части текста не нужно переписывать заново, а путем копирования фрагментов просто переносить из одного документа в другой.
В многооконном режиме текстовый редактор выделяет для каждого обрабатываемого документа отдельную область памяти, а на экране — отдельное окно. Окна на экране могут располагаться каскадом (друг за другом) или мозаикой (параллельно в плоскости экрана) (рис. 3.2). Активным окном является то, в котором в данный момент находится курсор.
С помощью специальных команд (нажимая определенные клавиши или используя мышь) производится переход от одного активного окна к другому. При этом можно переносить или копировать фрагменты текстов между разными документами, используя буфер, как об этом говорилось выше.
Коротко о главном
Основные режимы работы текстового редактора:
• ввод-редактирование;
• поиск и замена;
• проверка правописания;
• работа с файлами;
• печать;
• помощь.
Шрифты и начертания
В текстовом документе, созданном на компьютере с помощью текстового редактора, могут использоваться разнообразные шрифты. Современные текстовые редакторы имеют много наборов шрифтов. У каждого шрифта есть свое название. Например: Arial, Times New Roman и др. Буквы одного шрифта могут иметь разные начертания. Различаются обычное (прямое) начертание, курсив, полужирное начертание. Кроме того, предоставляется возможность подчеркивания текста. Вот несколько примеров:

Это обычное начертание шрифта Times New Roman.
Это курсив шрифта Times New Roman.
Это полужирное начертание шрифта Times New Roman.
Это полужирный курсив шрифта Times New Roman.
Это пример подчеркнутого текста.
Все текстовые редакторы позволяют управлять размером символов.
Следует иметь в виду, что если текстовый редактор позволяет менять шрифты, начертания и размеры, то в памяти приходится хранить не только коды символов, но и указания на способ их изображения. Это увеличивает размер файла с текстом. Информацию о шрифтах воспринимают программы, управляющие выводом текста на экран или на печать. Именно они и создают изображение символов в нужной форме.
Практически все редакторы, распространенные в нашей стране, позволяют использовать как русский, так и английский алфавит.
This is an example of English text.
Режим помощи пользователю
Одно из главных условий «дружественности» программного обеспечения — наличие помощи пользователю. Это делается в форме подсказки, справочника, учебника, хранимых во внешней памяти компьютера. Обычно обращение к режиму помощи происходит по команде «Справка», или «Помощь», или «?». Получив справку, пользователь выходит из режима помощи и возвращается к тому этапу работы, который был прерван.
Режим ввода-редактирования текста
Ввод-редактирование — это основной режим работы текстового редактора.
При записи текста на бумаге мы пользуемся ручкой или карандашом. Ввод (запись) текста в память компьютера производится с помощью клавиатуры. Если в прежние времена, до массового распространения ПК, быстро набирать текст на клавишах пишущих машинок умели только профессиональные машинистки, то сейчас этот навык становится необходимым для большинства людей. На занятиях в компьютерном классе вам поможет овладеть этим навыком учитель. Кроме того, существуют специальные учебные программы-тренажеры, развивающие умение быстро работать на клавиатуре.
При работе с текстовым редактором в режиме ввода-редактирования по экрану монитора перемещается курсор, который указывает текущую позицию для ввода. Символ, соответствующий нажатой клавише, помещается в позицию курсора, который после этого перемещается на один шаг вправо или, если достигнут конец строки, в начало следующей строки.
Под редактированием понимается внесение любых изменений в набранный текст. Чаще всего приходится стирать ошибочный символ, слово, строку; заменять один символ на другой; вставлять пропущенные символы, слова, строки. В процессе редактирования текста пользователь может изменять шрифты, форматировать текст, выделять фрагменты и манипулировать ими (переносить, удалять, копировать). В многооконных редакторах можно «разложить» сразу несколько документов в разных окнах и быстро переходить от одного к другому.
Вопросы и задания
1. Перечислите основные режимы работы текстового редактора.
2. Какие основные начертания шрифтов используются в текстовом редакторе?
3. Что понимается под форматированием текста?
4. Что такое фрагмент текста? Какие действия с ним можно выполнять?
5. Какие возможности предоставляет многооконный редактор?
6. Как осуществляется в текстовом редакторе поиск и замена?
8. Какие файловые операции можно выполнять, работая в текстовом редакторе?
9. Как распечатать текст на бумаге? Какие технические и программные средства для этого необходимы?
10. Как воспользоваться режимом помощи?
Сохранение и загрузка файлов
Основные приемы ввода и редактирования текста
Выполнение практического задания №4.
Практическое задание №4
Тема: Набор и редактирование текста

1. Запустить текстовый редактор Word и набрать следующий текст:
Процессор - это электронная схема, выполняющая обработку информации и управляющая всеми остальными устройствами компьютера. Современные процессоры называются микропроцессорами, так как они имеют очень маленький размер.
Основные характеристики процессора:
1) Тактовая частота - скорость обработки данных, измеряемая в МГц. 1 МГц=1 млн.тактов. Тактовые импульсы задаются генератором тактовой частоты. На каждую операцию требуется определённое количество тактов. Современные процессоры имеют тактовую частоту от 1,5 до 3,8 ГГц (15003800 МГц).
2) Разрядность - это количество бит, которые процессор способен принять и обработать за одну операцию. Современные процессоры бывают 32 или 64-разрядными.
Марки современных процессоров фирмы AMD: Athlon XP, Sempron, Athlon 64, Duron, Athlon 64 X2.
3. Сохранить набранный текст в файле с именем Процессоры.
1. Запустить текстовый редактор Word и набрать следующий текст:
Оптические диски (компакт-диски) - это устройства для долговременного хранения информации, а также её переноса с одного компьютера на другой.
Привод чтения/записи компакт-дисков - это устройство для работы с компакт-дисками.
Информация на компакт-диски записывается с помощью лазерного луча, под воздействием которого меняется прозрачность отражающего слоя, которым покрыт диск.
Для чтения информации с компакт дисков используются специальные приводы (CD-ROM, CD-RW, DVD-ROM, DVD-RW), некоторые из которых (RW) способны не только читать, но и записывать информацию на диск.
Объём стандартных компакт-дисков (CD) от 650 до 800 Мбайт.
Объём DVD-дисков - 4,7 Гбайт, 8,5 Гбайт, 17 Гбайт.
Обозначения компакт дисков:
CD-ROM (DVD-ROM) - диск только для чтения (однократная запись информации производится в заводских условиях).
CD-R (DVD-R, DVD+R) - диск для однократной записи.
CD-RW (DVD-RW) - диск для многократной записи.
3. Сохранить набранный текст в файле с именем Диски.
Электронное приложение к уроку
| Вернуться к материалам урока | |
| Презентации, плакаты, текстовые файлы | Ресурсы ЕК ЦОР |
| Видео к уроку |
Cкачать материалы урока
Автоматическая проверка правописания
Люди часто делают при письме ошибки. Когда возникают сомнения в написании какого-нибудь слова, мы заглядываем в орфографический словарь. Современный текстовый редактор может помочь пользователю и в такой ситуации. В тех ТР, в которых реализован режим орфографического контроля, во внешней памяти хранится достаточно большой словарь. Благодаря этому становится возможным автоматический поиск ошибок в тексте.
Работа с фрагментами текста
Большинство текстовых редакторов позволяют выделять в тексте куски, которые называют фрагментами (блоками).
Чаще всего выделение фрагмента отмечается на экране изменением цвета фона и символов.
С выделенным фрагментом могут быть выполнены следующие действия:
• переформатирование;
• изменение шрифта;
• удаление;
• перенос;
• копирование.
Три последние операции связаны с использованием специальной области памяти, которую называют буфером обмена. Для примера рассмотрим, как происходит перенос фрагмента текста из одного места в другое.
Вот последовательность действий для такой операции:
1. Выделить фрагмент в тексте.
2. Выбрать команду «Вырезать».
3. Установить курсор в позицию вставки.
4. Выбрать команду «Вставить».
Удаленный из текста по команде «Вырезать» фрагмент не исчезает совсем, а только перемещается в буферную область. Затем из буферной области он копируется в указанное курсором место. Копирование из буфера можно производить многократно.
Если в пункте 2 вместо команды «Вырезать» выполнить команду «Копировать», то выделенный блок не только скопируется в буфер, но и останется в тексте на прежнем месте.
Форматирование текста
Под форматом печатного текста понимается расположение строк (длина строки, междустрочное расстояние, выравнивание текста по краю или по центру строки), размеры полей, страниц.
Параметры формата (длина строки, междустрочное расстояние) устанавливаются пользователем перед вводом текста и в дальнейшем автоматически выдерживаются текстовым редактором. Пользователю остается только набирать текст.
Как, например, текстовый редактор управляет размером строки? После установки размера строки текстовый редактор сам следит за окончанием строк: как только длина набираемой строки достигает предела, происходит переход к новой строке (в память записывается символ конца строки).
При переходе к новой строке может происходить автоматическое выравнивание набранной строки по краям или по центру текста, если режим выравнивания установлен в текстовом редакторе.
Вот два примера текста: в первом был установлен режим выравнивания по центру текста, во втором — по левому краю.
У лукоморья дуб зеленый, Златая цепь на дубе том: И днем и ночью кот ученый Все ходит по цепи кругом. | У лукоморья дуб зеленый, Златая цепь на дубе том: И днем и ночью кот ученый Все ходит по цепи кругом. |
Некоторые текстовые редакторы производят автоматический перенос слов, соблюдая правила переноса.
Если вы ввели текст в определенном формате, а потом решили изменить формат, то с помощью текстового редактора это легко сделать.
Достаточно установить новые параметры формата и отдать команду «Переформатировать текст» (весь текст или абзац, или выделенный фрагмент текста).
Файловые операции
Документы, создаваемые с помощью текстового редактора, сохраняются в файлах на внешних носителях. Значит, работая с текстовым редактором, пользователь должен иметь возможность выполнять основные файловые операции:
• создать новый файл;
• сохранить текст в файле;
• открыть файл (загрузить текст из файла в оперативную память).
В системе команд текстового редактора имеется команда включения режима работы с файлами. Обычно она так и называется: «Файл». Затем пользователь отдает одну из команд: «Создать», «Сохранить», «Открыть». Обращение к конкретному файлу происходит путем указания его имени.
Читайте также: