Java что такое нативная память
Это глубокое погружение в управление памятью Java позволит расширить ваши знания о том, как работает куча, ссылочные типы и сборка мусора.
Вероятно, вы могли подумать, что если вы программируете на Java, то вам незачем знать о том, как работает память. В Java есть автоматическое управление памятью, красивый и тихий сборщик мусора, который работает в фоновом режиме для очистки неиспользуемых объектов и освобождения некоторой памяти.
Поэтому вам, как программисту на Java, не нужно беспокоиться о таких проблемах, как уничтожение объектов, поскольку они больше не используются. Однако, даже если в Java этот процесс выполняется автоматически, он ничего не гарантирует. Не зная, как устроен сборщик мусора и память Java, вы можете создать объекты, которые не подходят для сбора мусора, даже если вы их больше не используете.
Поэтому важно знать, как на самом деле работает память в Java, поскольку это дает вам преимущество в написании высокопроизводительных и оптимизированных приложений, которые никогда не будут аварийно завершены с ошибкой OutOfMemoryError . С другой стороны, когда вы окажетесь в плохой ситуации, вы сможете быстро найти утечку памяти.
Для начала давайте посмотрим, как обычно организована память в Java:

Структура памяти
Обычно память делится на две большие части: стек и куча. Имейте в виду, что размер типов памяти на этом рисунке не пропорционален реальному размеру памяти. Куча - это огромный объем памяти по сравнению со стеком.
Сборщик мусора Mark & Sweep
JVM использует отдельный поток демона, который работает в фоне для сборки мусора. Этот процесс запускается при выполнении определённых условий. Сборщик Mark & Sweep обычно работает в два этапа, иногда добавляют третий, в зависимости от используемого алгоритма.
- Разметка: сначала сборщик определяет, какие объекты используются, а какие нет. Те, что используются или доступны для стековых указателей, рекурсивно помечаются как живые.
- Удаление: сборщик проходит по куче и убирает все объекты, которые не помечены как живые. Эти места в памяти помечаются как свободные.
- Сжатие: после удаления неиспользуемых объектов все выжившие объекты перемещают, чтобы они были вместе. Это уменьшает фрагментацию и повышает скорость выделения памяти для новых объектов.
JVM предлагает на выбор несколько разных алгоритмов сборки мусора, и в зависимости от вашего JDK может быть ещё больше вариантов (например, сборщик Shenandoah в OpenJDK). Авторы разных реализаций стремятся к разным целям:
- Пропускная способность: время, затраченное на сборку мусора, а не работу приложения. В идеале, пропускная способность должна быть высокой, то есть паузы на сборку мусора короткие.
- Длительность пауз: насколько долго сборщик мусора мешает исполнению приложения. В идеале, паузы должны быть очень короткими.
- Размер кучи: в идеале, должен быть маленьким.
Сборка мусора: флаги
В этом разделе приведены некоторые важные флаги, которые можно использовать для настройки процесса сборки мусора.
Флаг
Описание
Первоначальный размер кучи
Максимальный размер куча
Отношение размера Old Generation к Young Generation
Отношение размера Eden к Survivor
Возраст объекта, когда объект перемещается из области Survivor в область Old Generation
Типы сборщиков мусора
Сборщик мусора
Описание
Преимущества
Когда использовать
Флаги для включения
Использует один поток.
Эффективный, т.к. нет накладных расходов на взаимодействие потоков.
Работа с небольшими наборами данных.
Использует несколько потоков.
Многопоточность ускоряет сборку мусора.
В приоритете пиковая производительность.
Допустимы паузы при GC в одну секунду и более.
Работа со средними и большими наборами данных.
Для приложений, работающих на многопроцессорном или многопоточном оборудовании.
Выполняет некоторую тяжелую работу параллельно с работой приложения.
Может использоваться как на небольших системах, так и на больших с большим количеством процессоров и большим количеством памяти.
Когда время отклика важнее пропускной способности.
Паузы GC должны быть меньше одной секунды.
Выполняет всю тяжелую работу параллельно с работой приложения.
В приоритете время отклика.
Сборщики мусора в Java
Ссылки на String
Ссылки на тип String в Java обрабатываются немного по- другому. Строки неизменяемы, что означает, что каждый раз, когда вы делаете что-то со строкой, в куче фактически создается другой объект. Для строк Java управляет пулом строк в памяти. Это означает, что Java сохраняет и повторно использует строки, когда это возможно. В основном это верно для строковых литералов. Например:
При запуске этот код распечатывает следующее:
Strings are equal
Следовательно, оказывается, что две ссылки типа String на одинаковые строковые литералы фактически указывают на одни и те же объекты в куче. Однако это не действует для вычисляемых строк. Предположим, что у нас есть следующее изменение в строке // 1 приведенного выше кода.
Strings are different
В этом случае мы фактически видим, что у нас есть два разных объекта в куче. Если учесть, что вычисляемая строка будет использоваться довольно часто, мы можем заставить JVM добавить ее в пул строк, добавив .intern() метод в конец вычисляемой строки:
При добавлении вышеуказанного изменения создается следующий результат:
Общие библиотеки
Здесь хранится нативный код для любых общих библиотек. Эта область памяти загружается операционной системой лишь один раз для каждого процесса.
Теперь давайте посмотрим, как исполняемая программа использует самые важные части памяти. Воспользуемся нижеприведённым кодом. Он не оптимизирован с точки зрения корректности, так что игнорируйте проблемы вроде ненужных промежуточных переменных, некорректных модификаторов и прочего. Его задача — визуализировать использование стека и кучи.
Здесь вы можете увидеть, как исполняется вышеприведённая программа и как используются стек и куча:
- Каждый вызов функции добавляется в стек потока исполнения в качестве фреймового блока.
- Все локальные переменные, включая аргументы и возвращаемые значения, сохраняются в стеке внутри фреймовых блоков функций.
- Все примитивные типы вроде int хранятся прямо в стеке.
- Все типы объектов вроде Employee, Integer или String создаются в куче, а затем на них ссылаются с помощью стековых указателей. Это верно и для статичных данных.
- Функции, которые вызываются из текущей функции, попадают наверх стека.
- Когда функция возвращает данные, её фрейм удаляется из стека.
- После завершения основного процесса объекты в куче больше не имеют стековых указателей и становятся потерянными (сиротами).
- Пока вы явно не сделаете копию, все ссылки на объекты внутри других объектов делаются с помощью указателей.
Давайте разберёмся с автоматическим управлением кучей, которое играет очень важную роль с точки зрения производительности приложения. Когда программа пытается выделить в куче больше памяти, чем доступно (в зависимости от значения Xmx ), мы получаем ошибки нехватки памяти.
JVM управляет куче с помощью сборки мусора. Чтобы освободить место для создания нового объекта, JVM очищает память, занятую потерянными объектами, то есть объектами, на которые больше нет прямых или опосредованных ссылок из стека.

Сборщик мусора в JVM отвечает за:
- Получение памяти от ОС и возвращение её ОС.
- Передачу выделенной памяти приложению по его запросу.
- Определение, какие части выделенной памяти ещё используются приложением.
- Затребование неиспользованной памяти для использования приложением.
Заключение
Знание того, как организована память, дает вам преимущество в написании хорошего и оптимизированного кода с точки зрения ресурсов памяти. Преимущество заключается в том, что вы можете настроить свою работающую JVM, предоставив различные конфигурации, наиболее подходящие для запуска вашего приложения. Выявление и устранение утечек памяти - это очень просто, если использовать правильные инструменты.
Всем привет! Перевод сегодняшнего материала мы хотим приурочить к запуску нового потока по курсу «Разработчик Java», который стартует уже завтра. Что ж начнём.
JVM может быть сложным зверем. К счастью, большая часть этой сложности скрыта под капотом, и мы, как разработчики приложений и ответственные за деплой, часто не должны об этом сильно беспокоиться. Хотя из-за роста популярности технологий развертывания приложений в контейнерах, стоит обратить внимание на распределение памяти в JVM.

Два вида памяти
JVM разделяет память на две основные категории: «кучу» (heap) и «не кучу» (non-heap). Куча — это часть памяти JVM, с которой разработчики наиболее знакомы. Здесь хранятся объекты, созданные приложением. Они остаются там до тех пор, пока не будут убраны сборщиком мусора. Как правило, размер кучи, которую использует приложение, изменяется в зависимости от текущей нагрузки.
Память вне кучи делится на несколько областей. В HotSpot для изучения областей этой памяти можно использовать механизм Native memory tracking (NMT). Обратите внимание, что, хотя NMT не отслеживает использование всей нативной памяти (например, не отслеживается выделение нативной памяти сторонним кодом), его возможностей достаточно для большинства типичных приложений на Spring. Для использования NMT запустите приложение с параметром -XX:NativeMemoryTracking=summary и с помощью jcmd VM.native_memory summary посмотрите информацию об используемой памяти.
Давайте посмотрим использование NMT на примере нашего старого друга Petclinic. Диаграмма ниже показывает использование памяти JVM по данным NMT (за вычетом собственного оверхеда NMT) при запуске Petclinic с максимальным размером кучи 48 МБ ( -Xmx48M ):

Как вы видите, на память вне кучи приходится большая часть используемой памяти JVM, причем память кучи составляет только одну шестую часть от общего объёма. В этом случае это примерно 44 МБ (из которых 33 МБ использовалось сразу после сборки мусора). Использование памяти вне кучи составило в сумме 223 МБ.
Области нативной памяти
Compressed class space (область сжатых указателей): используется для хранения информации о загруженных классах. Ограничивается параметром MaxMetaspaceSize . Функция количества классов, которые были загружены.
Примечание переводчика
Почему-то автор пишет про «Compressed class space», а не про всю область «Class». Область «Compressed class space» входит в состав области «Сlass», а параметр MaxMetaspaceSize ограничивает размер всей области «Class», а не только «Compressed class space». Для ограничения «Compressed class space» используется параметр CompressedClassSpaceSize .
Отсюда:
If UseCompressedOops is turned on and UseCompressedClassesPointers is used, then two logically different areas of native memory are used for class metadata…
A region is allocated for these compressed class pointers (the 32-bit offsets). The size of the region can be set with CompressedClassSpaceSize and is 1 gigabyte (GB) by default…
The MaxMetaspaceSize applies to the sum of the committed compressed class space and the space for the other class metadata
Если включен параметр UseCompressedOops и используется UseCompressedClassesPointers , тогда для метаданных классов используется две логически разные области нативной памяти…
Для сжатых указателей выделяется область памяти (32-битные смещения). Размер этой области может быть установлен CompressedClassSpaceSize и по умолчанию он 1 ГБ…
Параметр MaxMetaspaceSize относится к сумме области сжатых указателей и области для других метаданных класса.
- Thread (потоки): память, используемая потоками в JVM. Функция количества запущенных потоков.
- Code cache (кэш кода): память, используемая JIT для его работы. Функция количества классов, которые были загружены. Ограничивается параметром ReservedCodeCacheSize . Можно уменьшить настройкой JIT, например, отключив многоуровневую компиляцию (tiered compilation).
- GC (сборщик мусора): хранит данные, используемые сборщиком мусора. Зависит от используемого сборщика мусора.
- Symbol (символы): хранит такие символы, как имена полей, сигнатуры методов и интернированные строки. Чрезмерное использование памяти символов может указывать на то, что строки слишком интернированы.
- Internal (внутренние данные): хранит прочие внутренние данные, которые не входят ни в одну из других областей.
По сравнению с кучей, память вне кучи меньше изменяется под нагрузкой. Как только приложение загрузит все классы, которые будут использоваться и JIT полностью прогреется, всё перейдет в устойчивое состояние. Чтобы увидеть уменьшение использования области Compressed class space, загрузчик классов, который загрузил классы, должен быть удален сборщиком мусора. Это было распространено в прошлом, когда приложения развертывались в контейнерах сервлетов или серверах приложений (загрузчик классов приложения удалялся сборщиком мусора, когда приложение удалялось с сервера приложений), но с современными подходами к развертыванию приложений это случается редко.
Настройка JVM
Настроить JVM для эффективного использования доступной оперативной памяти непросто. Если вы запустите JVM с параметром -Xmx16M и ожидаете, что будет использоваться не более 16 МБ памяти, то вас ждёт неприятный сюрприз.
Интересной областью памяти JVM является кэш кода JIT. По умолчанию HotSpot JVM будет использовать до 240 МБ. Если кэш кода слишком мал, в JIT может не хватить места для хранения своих данных, и в результате будет снижена производительность. Если кэш слишком велик, то память может быть потрачена впустую. При определении размера кэша важно учитывать его влияние как на использование памяти, так и на производительность.
К счастью, команда CloudFoundry обладает обширными знаниями о распределении памяти в JVM. Если вы загружаете приложения в CloudFoundry, то сборщик (build pack) автоматически применит эти знания для вас. Если вы не используете CloudFoudry или хотели бы больше понять о том, как настроить JVM, то рекомендуется прочитать описание третьей версии Java buildpack’s memory calculator.
Что это значит для Spring
Команда Spring проводит много времени, думая о производительности и использовании памяти, рассматривая возможность использования памяти как в куче, так и вне кучи. Один из способов ограничить использование памяти вне кучи — это делать части фреймворка максимально универсальными. Примером этого является использование Reflection для создания и внедрения зависимостей в бины вашего приложения. Благодаря использованию Reflection количество кода фреймворка, который вы используете, остается постоянным, независимо от количества бинов в вашем приложении. Для оптимизации времени запуска мы используем кэш в куче, очищая этот кэш после завершения запуска. Память кучи может быть легко очищена сборщиком мусора, чтобы предоставить больше доступной памяти вашему приложению.

Для работы любого приложения требуется память. Однако память компьютера ограничена. Поэтому важно ее очищать от старых неиспользуемых данных, чтобы освободить место для новых.
Кто занимается этой очисткой? Как и когда очищается память? Как выглядит структура памяти? Давайте разберем с этим подробнее.
Стек (Stack)
Стековая память отвечает за хранение ссылок на объекты кучи и за хранение типов значений (также известных в Java как примитивные типы), которые содержат само значение, а не ссылку на объект из кучи.
Кроме того, переменные в стеке имеют определенную видимость, также называемую областью видимости. Используются только объекты из активной области. Например, предполагая, что у нас нет никаких глобальных переменных (полей) области видимости, а только локальные переменные, если компилятор выполняет тело метода, он может получить доступ только к объектам из стека, которые находятся внутри тела метода. Он не может получить доступ к другим локальным переменным, так как они не выходят в область видимости. Когда метод завершается и возвращается, верхняя часть стека выталкивается, и активная область видимости изменяется.
Возможно, вы заметили, что на картинке выше отображено несколько стеков памяти. Это связано с тем, что стековая память в Java выделяется для каждого потока. Следовательно, каждый раз, когда поток создается и запускается, он имеет свою собственную стековую память и не может получить доступ к стековой памяти другого потока.
Метапространство
Это часть нативной памяти, по умолчанию у неё нет верхней границы. В более ранних версиях JVM эта память называлась пространством постоянного поколения (Permanent Generation (PermGen) Space). Загрузчики классов хранили в нём определения классов. Если это пространство растёт, то ОС может переместить хранящиеся здесь данные из оперативной в виртуальную память, что может замедлить работу приложения. Избежать этого можно, задав размер метапространства с помощью флагов XX:MetaspaceSize и -XX:MaxMetaspaceSize , в этом случае приложение может выдавать ошибки памяти.
Типы ссылок
Если вы внимательно посмотрите на изображение структуры памяти, вы, вероятно, заметите, что стрелки, представляющие ссылки на объекты из кучи, на самом деле относятся к разным типам. Это потому, что в языке программирования Java используются разные типы ссылок: сильные, слабые, мягкие и фантомные ссылки. Разница между типами ссылок заключается в том, что объекты в куче, на которые они ссылаются, имеют право на сборку мусора по различным критериям. Рассмотрим подробнее каждую из них.
1. Сильная ссылка
Это самые популярные ссылочные типы, к которым мы все привыкли. В приведенном выше примере со StringBuilder мы фактически храним сильную ссылку на объект из кучи. Объект в куче не удаляется сборщиком мусора, пока на него указывает сильная ссылка или если он явно доступен через цепочку сильных ссылок.
2. Слабая ссылка
Попросту говоря, слабая ссылка на объект из кучи, скорее всего, не сохранится после следующего процесса сборки мусора. Слабая ссылка создается следующим образом:
Хорошим вариантом использования слабых ссылок являются сценарии кеширования. Представьте, что вы извлекаете некоторые данные и хотите, чтобы они также были сохранены в памяти - те же данные могут быть запрошены снова. С другой стороны, вы не уверены, когда и будут ли эти данные запрашиваться снова. Таким образом, вы можете сохранить слабую ссылку на него, и в случае запуска сборщика мусора, возможно, он уничтожит ваш объект в куче. Следовательно, через некоторое время, если вы захотите получить объект, на который вы ссылаетесь, вы можете внезапно получить null значение. Хорошей реализацией сценариев кеширования является коллекция WeakHashMap . Если мы откроем WeakHashMap класс в Java API, мы увидим, что его записи фактически расширяют WeakReference класс и используют его поле ref в качестве ключа отображения ( Map) :
После сбора мусора ключа из WeakHashMap вся запись удаляется из карты.
3. Мягкая ссылка
Эти типы ссылок используются для более чувствительных к памяти сценариев, поскольку они будут собираться сборщиком мусора только тогда, когда вашему приложению не хватает памяти. Следовательно, пока нет критической необходимости в освобождении некоторого места, сборщик мусора не будет касаться легко доступных объектов. Java гарантирует, что все объекты, на которые имеются мягкие ссылки, будут очищены до того, как будет выдано исключение OutOfMemoryError . В документации Javadocs говорится, что «все мягкие ссылки на мягко достижимые объекты гарантированно очищены до того, как виртуальная машина выдаст OutOfMemoryError».
Подобно слабым ссылкам, мягкая ссылка создается следующим образом:
4. Фантомная ссылка
Используется для планирования посмертных действий по очистке, поскольку мы точно знаем, что объекты больше не живы. Используется только с очередью ссылок, поскольку .get() метод таких ссылок всегда будет возвращаться null . Эти типы ссылок считаются предпочтительными для финализаторов.
Процесс сборки мусора
Как обсуждалось ранее, в зависимости от типа ссылки, которую переменная из стека содержит на объект из кучи, в определенный момент времени этот объект становится подходящим для сборщика мусора.

Объекты, подходящие для сборки мусора
Например, все объекты, отмеченные красным цветом, могут быть собраны сборщиком мусора. Вы можете заметить, что в куче есть объект, который имеет строгие ссылки на другие объекты, которые также находятся в куче (например, это может быть список, который имеет ссылки на его элементы, или объект, имеющий два поля типа, на которые есть ссылки). Однако, поскольку ссылка из стека потеряна, к ней больше нельзя получить доступ, так что это тоже мусор.
Чтобы углубиться в детали, давайте сначала упомянем несколько вещей:
Этот процесс запускается автоматически Java, и Java решает, запускать или нет этот процесс.
На самом деле это дорогостоящий процесс. При запуске сборщика мусора все потоки в вашем приложении приостанавливаются (в зависимости от типа GC, который будет обсуждаться позже).
На самом деле это более сложный процесс, чем просто сбор мусора и освобождение памяти.
Несмотря на то, что Java решает, когда запускать сборщик мусора, вы можете явно вызвать System.gc() и ожидать, что сборщик мусора будет запускаться при выполнении этой строки кода, верно?
Это ошибочное предположение.
Вы только как бы просите Java запустить сборщик мусора, но, опять же, Java решать, делать это или нет. В любом случае явно вызывать System.gc() не рекомендуется.
Поскольку это довольно сложный процесс и может повлиять на вашу производительность, он реализован разумно. Для этого используется так называемый процесс «Mark and Sweep». Java анализирует переменные из стека и «отмечает» все объекты, которые необходимо поддерживать в рабочем состоянии. Затем все неиспользуемые объекты очищаются.
Так что на самом деле Java не собирает мусор. Фактически, чем больше мусора и чем меньше объектов помечены как живые, тем быстрее идет процесс. Чтобы сделать это еще более оптимизированным, память кучи на самом деле состоит из нескольких частей. Мы можем визуализировать использование памяти и другие полезные вещи с помощью JVisualVM, инструмента, поставляемого с Java JDK. Единственное, что вам нужно сделать, это установить плагин с именем Visual GC, который позволяет увидеть, как на самом деле структурирована память. Давайте немного увеличим масштаб и разберем общую картину:

Поколения памяти кучи
Когда объект создается, он размещается в пространстве Eden (1). Поскольку пространство Eden не такое уж большое, оно заполняется довольно быстро. Сборщик мусора работает в пространстве Eden и помечает объекты как живые.
Если объект выживает в процессе сборки мусора, он перемещается в так называемое пространство выжившего S0(2). Во второй раз, когда сборщик мусора запускается в пространстве Eden, он перемещает все уцелевшие объекты в пространство S1(3). Кроме того, все, что в настоящее время находится на S0(2), перемещается в пространство S1(3).
Если объект выживает в течение X раундов сборки мусора (X зависит от реализации JVM, в моем случае это 8), скорее всего, он выживет вечно и перемещается в пространство Old(4).
Принимая все сказанное выше, если вы посмотрите на график сборщика мусора (6), каждый раз, когда он запускается, вы можете увидеть, что объекты переключаются на пространство выживших и что пространство Эдема увеличивалось. И так далее. Старое поколение также может быть обработано сборщиком мусора, но, поскольку это большая часть памяти по сравнению с пространством Eden, это происходит не так часто. Метапространство (5) используется для хранения метаданных о ваших загруженных классах в JVM.
Представленное изображение на самом деле является приложением Java 8. До Java 8 структура памяти была немного другой. Метапространство на самом деле называется PermGen область. Например, в Java 6 это пространство также хранит память для пула строк. Поэтому, если в вашем приложении Java 6 слишком много строк, оно может аварийно завершить работу.
Типы сборщиков мусора
Фактически, JVM имеет три типа сборщиков мусора, и программист может выбрать, какой из них следует использовать. По умолчанию Java выбирает используемый тип сборщика мусора в зависимости от базового оборудования.
1. Serial GC (Последовательный сборщик мусора) - однониточный коллектор. В основном относится к небольшим приложениям с небольшим использованием данных. Можно включить, указав параметр командной строки: -XX:+UseSerialGC.
2. Parallel GC (Параллельный сборщик мусора) - даже по названию, разница между последовательным и параллельным будет заключаться в том, что параллельный сборщик мусора использует несколько потоков для выполнения процесса сбора мусора. Этот тип GC также известен как сборщик производительности. Его можно включить, явно указав параметр: -XX:+UseParallelGC.
3. Mostly concurrent GC (В основном параллельный сборщик мусора). Если вы помните, ранее в этой статье упоминалось, что процесс сбора мусора на самом деле довольно дорогостоящий, и когда он выполняется, все потоки приостанавливаются. Однако у нас есть в основном параллельный тип GC, который утверждает, что он работает одновременно с приложением. Однако есть причина, по которой он «в основном» параллелен. Он не работает на 100% одновременно с приложением. Есть период времени, на который цепочки приостанавливаются. Тем не менее, пауза делается как можно короче для достижения наилучшей производительности сборщика мусора. На самом деле существует 2 типа в основном параллельных сборщиков мусора:
3.1 Garbage First - высокая производительность с разумным временем паузы приложения. Включено с опцией: -XX:+UseG1GC.
3.2 Concurrent Mark Sweep (Параллельное сканирование отметок) - время паузы приложения сведено к минимуму. Он может быть использован с помощью опции: -XX:+UseConcMarkSweepGC . Начиная с JDK 9, этот тип GC объявлен устаревшим.
Кеш кода
Здесь компилятор Just In Time (JIT) хранит скомпилированные блоки кода, к которым приходится часто обращаться. Обычно JVM интерпретирует байткод в нативный машинный код, однако код, скомпилированный JIT-компилятором, не нужно интерпретировать, он уже представлен в нативном формате и закеширован в этой области памяти.
Инструменты мониторинга GC
Что мониторить?
Частота запуска сборки мусора. Так как GC вызывает "stop the world", поэтому чем время сборки мусора меньше, тем лучше.
Длительность одного цикла сборки мусора.
Как мониторить сборщик мусора?
Для мониторинга можно использовать следующие инструменты:
Для включения логирования событий сборщика мусора добавьте следующие параметры JVM:

В серии статей я хочу опровергнуть заблуждения, связанные с управлением памятью, и глубже рассмотреть её устройство в некоторых современных языках программирования — Java, Kotlin, Scala, Groovy и Clojure. Надеюсь, эта статья поможет вам разобраться, что происходит под капотом этих языков. Сначала мы рассмотрим управление памятью в виртуальной машине Java (JVM), которая используется в Java, Kotlin, Scala, Clojure, Groovy и других языках. В первой статье я рассказал и разнице между стеком и кучей, что полезно для понимания этой статьи.
Сначала давайте посмотрим на структуру памяти JVM. Эта структура применяется начиная с JDK 11. Вот какая память доступна процессу JVM, она выделяется операционной системой:

Это нативная память, выделяемая ОС, и её размер зависит от системы, процессор и JRE. Какие области и для чего предназначены?
Поколения объектов
Что такое поколения объектов?
Для оптимизации сборки мусора память кучи дополнительно разделена на четыре области. В эти области объекты помещаются в зависимости от их возраста (как долго они используются в приложении).
Young Generation (молодое поколение). Здесь создаются новые объекты. Область young generation разделена на три части раздела: Eden (Эдем), S0 и S1 (Survivor Space — область для выживших).
Old Generation (старое поколение). Здесь хранятся давно живущие объекты.
Что такое Stop the World?
Когда запускается этап mark, работа приложения останавливается. После завершения mark приложение возобновляет свою работу. Любая сборка мусора — это "Stop the World".
Что такое гипотеза о поколениях?
Как уже упоминалось ранее, для оптимизации этапов mark и sweep используются поколения. Гипотеза о поколениях говорит о следующем:
Большинство объектов живут недолго.
Если объект выживает, то он, скорее всего, будет жить вечно.
Этапы mark и sweep занимают меньше времени при большом количестве мусора. То есть маркировка будет происходить быстрее, если анализируемая область небольшая и в ней много мертвых объектов.
Таким образом, алгоритм сборки мусора, использующий поколения, выглядит следующим образом:
Новые объекты создаются в области Eden. Области Survivor (S0, S1) на данный момент пустые.
Когда область Eden заполняется, происходит минорная сборка мусора (Minor GC). Minor GC — это процесс, при котором операции mark и sweep выполняются для young generation (молодого поколения).
После Minor GC живые объекты перемещаются в одну из областей Survivor (например, S0). Мертвые объекты полностью удаляются.
По мере работы приложения пространство Eden заполняется новыми объектами. При очередном Minor GC области young generation и S0 очищаются. На этот раз выжившие объекты перемещаются в область S1, и их возраст увеличивается (отметка о том, что они пережили сборку мусора).
При следующем Minor GC процесс повторяется. Однако на этот раз области Survivor меняются местами. Живые объекты перемещаются в S0 и у них увеличивается возраст. Области Eden и S1 очищаются.
Объекты между областями Survivor копируются определенное количество раз (пока не переживут определенное количество Minor GC) или пока там достаточно места. Затем эти объекты копируются в область Old.
Major GC. При Major GC этапы mark и sweep выполняются для Old Generation. Major GC работает медленнее по сравнению с Minor GC, поскольку старое поколение в основном состоит из живых объектов.
Преимущества использования поколений
Minor GC происходит в меньшей части кучи (~ 2/3 от кучи). Этап маркировки эффективен, потому что область небольшая и состоит в основном из мертвых объектов.
Недостатки использования поколений
В каждый момент времени одно из пространств Survivor (S0 или S1) пустое и не используется.
Младший сборщик
Он поддерживает чистоту и компактность пространства молодого поколения. Запускается тогда, когда JVM не может получить в раю необходимую память для размещения нового объекта. Изначально все области кучи пусты. Рай заполняется первым, за ним область выживших, и в конце хранилище.
Здесь вы можете увидеть процесс работы этого сборщика:
- Допустим, в раю уже есть объекты (блоки с 01 по 06 помечены как используемые).
- Приложение создаёт новый объект (07).
- JVM пытается получить необходимую память в раю, но там уже нет места для размещения нового объекта, поэтому JVM запускает младший сборщик.
- Он рекурсивно проходит по графу объектов начиная со стековых указателей и помечает используемые объекты как (используемая память), остальные — как мусор (потерянные).
- JVM случайно выбирает один блок из S0 и S1 в качестве «целевого» пространства (To Space), пусть это будет S0. Теперь сборщик перемещает все живые объекты в «целевое» пространство, которое было пустым, когда мы начали работу, и повышает их возраст на единицу.
- Затем сборщик очищает рай, и в нём выделяется память для нового объекта.
- Допустим, прошло какое-то время, и в раю стало больше объектов (блоки с 07 по 13 помечены как используемые).
- Приложение создаёт новый объект (14).
- JVM пытается получить в раю нужную память, но там нет свободного места для нового объекта, поэтому JVM снова запускает младший сборщик.
- Повторяется этап разметки, который охватывает и те объекты, что находятся в пространстве выживших в «целевом пространстве».
- Теперь JVM выбирает в качестве «целевого» свободный блок S1, а S0 становится «исходным». Сборщик перемещает все живые объекты из рая и «исходного» в «целевое» (S1), которое было пустым, и повысил возраст объектов на единицу. Поскольку некоторые объекты сюда не поместились, сборщик переносит их в «хранилище», ведь область выживших не может увеличиваться, и этот процесс называют преждевременным продвижением (premature promotion). Такое может происходить, даже если свободна одна из областей выживших.
- Теперь сборщик очищает рай и «исходное» пространство (S0), а новый объект размещается в раю.
- Так повторяется при каждой сессии младшего сборщика, выжившие перемещаются между S0 и S1, а их возраст увеличивается. Когда он достигает заданного «максимального порога», по умолчанию это 15, объект перемещается в «хранилище».
Стеки потоков исполнения
Это стековая область, в которой на один поток выделяется один стек. Здесь хранятся специфические для потоков статичные данные, в том числе фреймы методов и функций, указатели на объекты. Размер стековой памяти можно задать с помощью флага Xss .
Куча (heap)
Здесь JVM хранит объекты и динамические данные. Это самая крупная область памяти, в ней работает сборщик мусора. Размером кучи можно управлять с помощью флагов Xms (начальный размер) и Xmx (максимальный размер). Куча не передаётся виртуальной машине целиком, какая-то часть резервируется в качестве виртуального пространства, за счёт которого куча может в будущем расти. Куча делится на пространства «молодого» и «старого» поколения.
- Молодое поколение, или «новое пространство»: область, в которой живут новые объекты. Она делится на «рай» (Eden Space) и «область выживших» (Survivor Space). Областью молодого поколения управляет «младший сборщик мусора» (Minor GC), который также называют «молодым» (Young GC).
- Рай: здесь выделяется память, когда мы создаём новые объекты.
- Область выживших: здесь хранятся объекты, которые остались после работы младшего сборщика мусора. Область делится на две половины, S0 и S1.
Советы и приемы
Чтобы минимизировать объем памяти, максимально ограничьте область видимости переменных. Помните, что каждый раз, когда выскакивает верхняя область видимости из стека, ссылки из этой области теряются, и это может сделать объекты пригодными для сбора мусора.
Явно устанавливайте в null устаревшие ссылки. Это сделает объекты, на которые ссылаются, подходящими для сбора мусора.
Избегайте финализаторов (finalizer). Они замедляют процесс и ничего не гарантируют. Фантомные ссылки предпочтительны для работы по очистке памяти.
Не используйте сильные ссылки там, где можно применить слабые или мягкие ссылки. Наиболее распространенные ошибки памяти - это сценарии кэширования, когда данные хранятся в памяти, даже если они могут не понадобиться.
JVisualVM также имеет функцию создания дампа кучи в определенный момент, чтобы вы могли анализировать для каждого класса, сколько памяти он занимает.
Настройте JVM в соответствии с требованиями вашего приложения. Явно укажите размер кучи для JVM при запуске приложения. Процесс выделения памяти также является дорогостоящим, поэтому выделите разумный начальный и максимальный объем памяти для кучи. Если вы знаете его, то не имеет смысла начинать с небольшого начального размера кучи с самого начала, JVM расширит это пространство памяти. Указание параметров памяти выполняется с помощью следующих параметров:
Начальный размер кучи -Xms512m - установите начальный размер кучи на 512 мегабайт.
Максимальный размер кучи -Xmx1024m - установите максимальный размер кучи 1024 мегабайта.
Размер стека потоков -Xss1m - установите размер стека потоков равным 1 мегабайту.
Размер поколения -Xmn256m - установите размер поколения 256 мегабайт.
Если приложение Java выдает ошибку OutOfMemoryError и вам нужна дополнительная информация для обнаружения утечки, запустите процесс с –XX:HeapDumpOnOutOfMemory параметром, который создаст файл дампа кучи, когда эта ошибка произойдет в следующий раз.
Используйте опцию -verbose:gc , чтобы получить вывод процесса сборки мусора. Каждый раз, когда происходит сборка мусора, будет генерироваться вывод.
Структура памяти Java
Память в Java состоит из следующих областей:
![Структура памяти Java]()
Структура памяти Java
Native Memory — вся доступная системная память.
Heap (куча) — часть native memory, выделенная для кучи. Здесь JVM хранит объекты. Это общее пространство для всех потоков приложения. Размер этой области памяти настраивается с помощью параметра -Xms (минимальный размер) и -Xmx (максимальный размер).
Stack (стек) — используется для хранения локальных переменных и стека вызовов метода. Для каждого потока выделяется свой стек.
Metaspace (метаданные) — в этой памяти хранятся метаданные классов и статические переменные. Это пространство также является общими для всех. Так как metaspace является частью native memory, то его размер зависит от платформы. Верхний предел объема памяти, используемой для metaspace, можно настроить с помощью флага MaxMetaspaceSize.
PermGen (Permanent Generation, постоянное поколение) присутствовало до Java 7. Начиная с Java 8 ему на смену пришла область Metaspace.
CodeCache (кэш кода) — JIT-компилятор компилирует часто исполняемый код, преобразует его в нативный машинный код и кеширует для более быстрого выполнения. Это тоже часть native memory.
Сборщики в JDK 11
JDK 11 — это текущая версия LTE. Ниже приведён список доступных в ней сборщиков мусора, и JVM выбирает по умолчанию один из них в зависимости от текущего оборудования и операционной системы. Мы всегда можем принудительно выбрать какой-либо сборщик с помощью переключателя -XX .
- Серийный сборщик: использует один поток, эффективен для приложений с небольшим количеством данных, наиболее удобен для однопроцессорных машин. Его можно выбрать с помощью -XX:+UseSerialGC .
- Параллельный сборщик: нацелен на высокую пропускную способность и использует несколько потоков, чтобы ускорить процесс сборки. Предназначен для приложений со средним или большим количеством данных, исполняемых на многопоточном/многопроцессорном оборудовании. Его можно выбрать с помощью -XX:+UseParallelGC .
- Сборщик Garbage-First (G1): работает по большей части многопоточно (то есть многопоточно выполняются только объёмные задачи). Предназначен для многопроцессорных машин с большим объёмом памяти, по умолчанию используется на большинстве современных компьютеров и ОС. Нацелен на короткие паузы и высокую пропускную способность. Его можно выбрать с помощью -XX:+UseG1GC .
- Сборщик Z: новый, экспериментальный, появился в JDK11. Это масштабируемый сборщик с низкой задержкой. Многопоточный и не останавливает исполнение потоков приложения, то есть не относится к stop-the-world. Предназначен для приложений, которым необходима низкая задержка и/или очень большая куча (на несколько терабайтов). Его можно выбрать с помощью -XX:+UseZGC .
Сборка мусора: процесс
Для сборки мусора используется алгоритм пометок (Mark & Sweep). Этот алгоритм состоит из трех этапов:
Mark (маркировка). На первом этапе GC сканирует все объекты и помечает живые (объекты, которые все еще используются). На этом шаге выполнение программы приостанавливается. Поэтому этот шаг также называется "Stop the World" .
Sweep (очистка). На этом шаге освобождается память, занятая объектами, не отмеченными на предыдущем шаге.
Compact (уплотнение). Объекты, пережившие очистку, перемещаются в единый непрерывный блок памяти. Это уменьшает фрагментацию кучи и позволяет проще и быстрее размещать новые объекты.
Стек (Stack)
Стековая память отвечает за хранение ссылок на объекты кучи и за хранение типов значений (также известных в Java как примитивные типы), которые содержат само значение, а не ссылку на объект из кучи.
Кроме того, переменные в стеке имеют определенную видимость, также называемую областью видимости. Используются только объекты из активной области. Например, предполагая, что у нас нет никаких глобальных переменных (полей) области видимости, а только локальные переменные, если компилятор выполняет тело метода, он может получить доступ только к объектам из стека, которые находятся внутри тела метода. Он не может получить доступ к другим локальным переменным, так как они не выходят в область видимости. Когда метод завершается и возвращается, верхняя часть стека выталкивается, и активная область видимости изменяется.
Возможно, вы заметили, что на картинке выше отображено несколько стеков памяти. Это связано с тем, что стековая память в Java выделяется для каждого потока. Следовательно, каждый раз, когда поток создается и запускается, он имеет свою собственную стековую память и не может получить доступ к стековой памяти другого потока.
Сборка мусора: введение
Что такое "мусор"? Мусором считается объект, который больше не может быть достигнут по ссылке из какого-либо объекта. Поскольку такие объекты больше не используются в приложении, то их можно удалить из памяти.
Например, на диаграмме ниже объект fruit2 может быть удален из памяти, поскольку на него нет ссылок.
![Мусор]()
Мусор
Что такое сборка мусора? Сборка мусора — это процесс автоматического управления памятью. Освобождение памяти (путем очистки мусора) выполняется автоматически специальным компонентом JVM — сборщиком мусора (Garbage Collector, GC). Нам, как программистам, нет необходимости вмешиваться в процесс сборки мусора.
Процесс сборки мусора
Вне зависимости от того, какой выбран сборщик, в JVM используется два вида сборки — младший и старший сборщик.
Куча (Heap)
Эта часть памяти хранит в памяти фактические объекты, на которые ссылаются переменные из стека. Например, давайте проанализируем, что происходит в следующей строке кода:
Ключевое слово new несет ответственность за обеспечение того, достаточно ли свободного места на куче, создавая объект типа StringBuilder в памяти и обращаясь к нему через «Builder» ссылки, которая попадает в стек.
Для каждого запущенного процесса JVM существует только одна область памяти в куче. Следовательно, это общая часть памяти независимо от того, сколько потоков выполняется. На самом деле структура кучи немного отличается от того, что показано на картинке выше. Сама куча разделена на несколько частей, что облегчает процесс сборки мусора.
Максимальные размеры стека и кучи не определены заранее - это зависит от работающей JVM машины. Позже в этой статье мы рассмотрим некоторые конфигурации JVM, которые позволят нам явно указать их размер для запускаемого приложения.
Старший сборщик
Следит за чистотой и компактностью пространства старого поколения (хранилищем). Запускается при одном из таких условий:
- Разработчик вызывает в программе System . gc() или Runtime.getRunTime().gc() .
- JVM решает, что в хранилище недостаточно памяти, потому что оно заполнено в результате прошлых сессий младшего сборщика.
- Если во время работы младшего сборщика JVM не может получить достаточно памяти в раю или области выживших.
- Если мы задали в JVM параметр MaxMetaspaceSize и для загрузки новых классов не хватает памяти.
- Допустим, прошло уже много сессий младшего сборщика и хранилище почти заполнено. JVM решает запустить старший сборщик.
- В хранилище он рекурсивно проходит по графу объектов начиная со стековых указателей и помечает используемые объекты как (используемая память), остальные — как мусор (потерянные). Если старший сборщик запустили в ходе работы младшего сборщика, то его работа охватывает пространство молодого поколения (рай и область выживших) и хранилище.
- Сборщик убирает все потерянные объекты и возвращает память.
- Если в ходе работы старшего сборщика в куче не осталось объектов, JVM также возвращает память из метапространства, убирая из него загруженные классы, если это относится к полной сборке мусора.
Мы рассмотрели структуру и управление памятью JVM. Это не исчерпывающая статья, мы не говорили о многих более сложных концепциях и способах настройки под особые сценарии использования. Подробнее вы можете почитать здесь.
Но для большинства JVM-разработчиков (Java, Kotlin, Scala, Clojure, JRuby, Jython) этого объёма информации будет достаточно. Надеюсь, теперь вы сможете писать более качественный код, создавать более производительные приложения, избегая различных проблем с утечкой памяти.
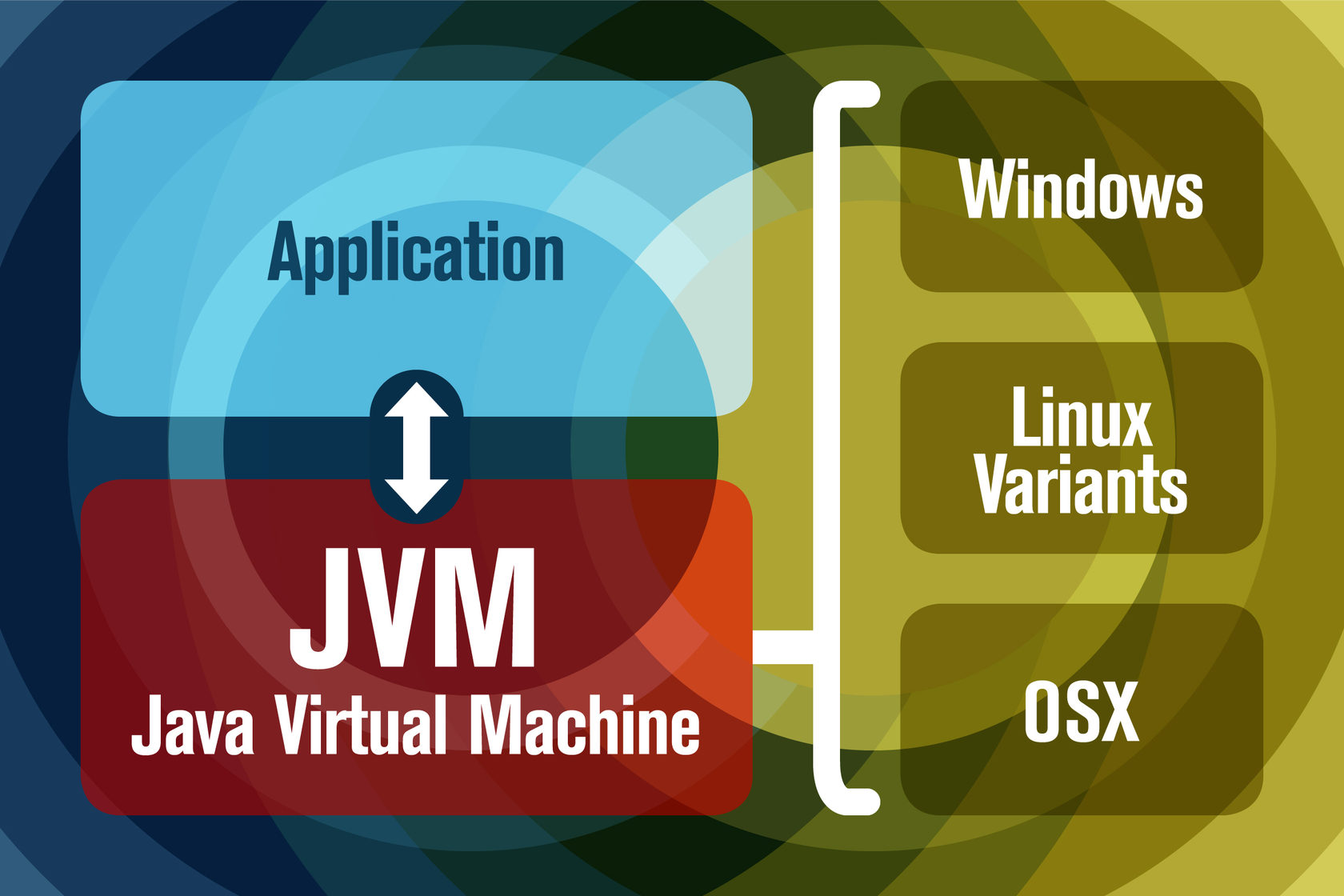
Java virtual machine (JVM) — это программа, предназначенная для выполнения других программ. В ее основу заложена простая идея, которая всегда будет одним из величайших примеров кодирования в стиле «kung fu».
- Позволяет запускать Java-приложения на любых устройствах или операционных системах (принцип — «Написал один раз, запускай везде»)
- Управляет и оптимизирует память, используемую приложением
В 1995 году, когда Java появилась, все компьютерные программы были написаны под определенные операционные системы, и управлять памятью приходилось разработчику программного обеспечения. Так что появление JVM было революцией.
![]()
- Техническое определение: JVM — это спецификация программного обеспечения, которое выполняет код и предоставляет среду выполнения для этого кода
- Повседневная формулировка: JVM — это способ запуска наших Java-приложений. Мы настраиваем параметры JVM, а затем полагаемся на ее автоматическое управление ресурсами программы во время выполнения
Когда разработчики говорят о JVM, обычно имеют в виду процесс, запущенный на устройстве, который предоставляет и контролирует использование ресурсов Java-приложения. Спецификация JVM описывает требования для разработки программы, которая выполняет эти задачи.
JVM активно используется и разрабатывается очень сильными программистами как корпоративное ПО, а так же как ПО с открытым кодом. Проект OpenJDK является потомком решений компании Sun Microsystems для open-source версии Java. Компания Oracle и другие продолжают развитие OpenJDK.
До Java память программы контролировалась программистом. В Java же памятью управляет виртуальная машина через процесс, называемый сборкой мусора, который непрерывно определяет и устраняет неиспользуемую память в программах. Сборка мусора происходит внутри работающей JVM.
В ранний период Java подвергалась критике, так как не была «Close to the metal» как C++ и поэтому не была такой быстрой. Особенно спорным был процесс сборки мусора. С тех пор были предложены и использованы различные алгоритмы и подходы, которые значительно улучшили сборку мусора.
Выражение означает ручное управление (из кода) памятью операционной системы. В теории, программисты могут выжать больше производительности из своих программ, выделяя и освобождать память самостоятельно. Но в большинстве случаев делегирование управления памятью высокоточному процессу, такому как JVM, дает лучшую производительность и защищает от ошибок, нежели ручное управление.
Глобально JVM состоит из трех частей: спецификация, реализация и экземпляр. Рассмотрим каждую из них.
Первая часть JVM — спецификация в которой не определены детали реализации JVM, что обеспечивает максимальную свободу творчества при ее создании:
«Для правильной реализации виртуальной машины Java, вам лишь необходимо уметь читать class-файлы и правильно выполнять указанные в нем операции»
Таким образом, все что JVM должна делать — это корректно запускать Java-программы. Звучит просто, но это колоссальная задача, особенно, если учитывать мощь и гибкость языка Java.
JVM – это виртуальная машина, которая запускает Java-программы в портативном режиме. Термин "Виртуальная машина" означает, что JVM является абстракцией фактической машины, такой как сервер, на которой работают программы. Независимо от операционной системы или технического обеспечения, JVM создает предсказуемую среду для запускаемых внутри нее программ.
Существует множество различных реализаций спецификации JVM как коммерческих, так и с открытым исходным кодом. JVM HotSpot от проекта OpenJDK является эталонной реализацией и содержит одну из наиболее тщательно проверенных в мире кодовых баз. HotSpot также является самой широко используемой JVM.
Почти все лицензированные JVM созданы, как ответвление от OpenJDK и HotSpot JVM, включая лицензионный JDK от Oracle. Разработчики, создающие лицензированные продукты на основе OpenJDK, зачастую мотивируются желанием увеличить производительность для определенных операционных систем. Обычно пользователи загружают и устанавливают JVM, как часть среды выполнения Java (JRE).
После того как спецификация JVM реализована и выпущена, вы можете загрузить ее как приложение. Загруженная программа является экземпляром виртуальной машины.
В большинстве случаев, говоря о JVM, имеют в виду экземпляр JVM, который работает в среде разработки. Вы можете сказать: «Привет Макс, сколько памяти использует JVM на этом сервере?» или «Я не могу поверить, я сделал зацикленный вызов, и переполнение стека сломало мою JVM. Ошибка новичка!»
Спецификация программного обеспечения – это читаемый человеком проектный документ, описывающий, как должна работать программная система. Цель спецификации – создать четкое описание и требования к коду для разработчиков.
Мы говорили о роли JVM в запуске Java-приложений, но как она выполняет свою функцию? При выполнении Java-приложений JVM зависит от загрузчика классов и механизма выполнения.
Все в Java является классом, и все Java-приложения состоят из классов. Приложение может состоять из одного или тысячи классов. Для запуска приложения JVM должна загрузить скомпилированные .class-файлы в контекст, такой как сервер, где они будут доступны. JVM зависит от своего загрузчика класса во время выполнения этой функции.
Загрузчик классов Java является частью JVM, которая загружает классы в память и делает их доступными для выполнения. Загрузчики классов используют технику ленивой загрузки (lazy-loading) и кэширования, чтобы сделать загрузку классов максимально эффективной.
Любая виртуальная машина Java включает в себя загрузчик классов. Спецификация JVM описывает стандартные методы для запросов и управления загрузчиком во время работы, но за выполнение этих возможностей отвечает конкретная реализация JVM.
Выполнение кода включает управление доступом к системным ресурсам. Механизм выполнения JVM стоит между работой программы, с ее запросами на файловые, сетевые ресурсы и ресурсы памяти, и операционной системой, которая обеспечивает эти ресурсы.
Вспомните, что JVM отвечает за очистку неиспользуемой памяти, а сборщик мусора — это механизм, который эту очистку осуществляет. JVM также отвечает за распределение и поддержание ссылочной структуры, которую разработчик принимает как должное. Например, при использовании ключевого слова new, механизм выполнения JVM осуществляет запрос к операционной системе на выделение памяти.
Помимо памяти, механизм выполнения управляет ресурсами файловой системы и сети. Так как JVM может взаимодействовать с разными операционными системами, это задача не из легких. В дополнение к потребностям каждого приложения в ресурсах, механизм выполнения должен корректно работать с каждой операционной системой.
В 1995 году JVM представила две революционных концепции, которые с тех пор стали стандартом в современной разработке: «Написал один раз, запускай везде» и автоматическое управление памятью. В то время совместимость ПО была смелой концепцией, но сейчас это незаменимое удобство. Точно так же, в то время разработчики должны были сами управлять программной памятью, нынешнее поколение живет с автоматической сборкой мусора.
Изначально виртуальная машина Java предназначалась только для Java, но сегодня она может поддерживать разные скриптовые и другие языки программирования, включая Scala, Groovy и Kotlin. Глядя вперед, трудно увидеть будущее, в котором JVM не является заметной частью развития разработки программного обеспечения.
Читайте также: