
Из чего состоит индекс файла
Физическая организация выделяет способ размещения файлов на диске и учет соответствия блоков диска файлам. Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.
Наиболее часто используются следующие схемы размещения файлов:
- непрерывное размещение (непрерывные файлы);
- сводный список блоков (кластеров) файла;
- сводный список индексов блоков (кластеров) файла;
- перечень номеров блоков (кластеров) файла в структурах, называемых i-узлами (index-node – индекс-узел).
Простейший вариант физической организации – непрерывное размещение в наборе соседних кластеров (рис. 7.15a). Достоинство этой схемы – высокая скорость доступа и минимальный объем адресной информации, поскольку достаточно хранить номер первого кластера и объем файла. Размер файла при такой организации не ограничивается.
Однако у этой схемы имеется серьезный недостаток – фрагментация, возрастающая по мере удаления и записи файлов. Кроме того, возникает вопрос, какого размера область нужно выделить файлу, если при каждой модификации он может увеличить свой размер.
И все-таки есть ситуации, в которых непрерывные файлы могут эффективно использоваться и действительно широко применяются – на компакт-дисках. Здесь все размеры файлов заранее известны и не могут меняться.
Второй метод размещения файлов состоит в представлении файла в виде связного списка кластеров дисковой памяти (рис. 7.15б). Первое слово каждого кластера используется как указатель на следующий кластер. В этом случае адресная информация минимальна, поскольку расположение файла задается номером его первого кластера.
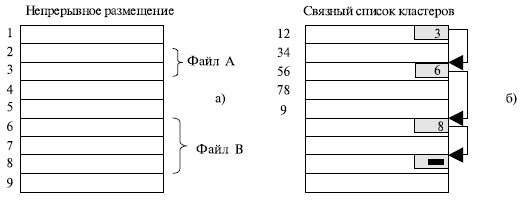
Рис. 7.15. Варианты физической организации файлов
Кроме того, отсутствует фрагментация на уровне кластеров, а файл легко может изменять размер наращиванием или удалением цепочки кластеров. Однако доступ к такому файлу может оказаться медленным, так как для получения доступа к кластеру n операционная система должна прочитать первые n-1 кластеры. Кроме того, размер кластера уменьшается на несколько байтов, требуемых для хранения. Указателю это не очень важно, но многие программы читают и пишут блоками, кратными степени двойки.
Оба недостатка предыдущей схемы организации файлов могут быть устранены, если указатели на следующие кластеры хранить в отдельной таблице, загружаемой в память. Таким образом, образуется связный список не самих блоков (кластеров) файла, а индексов, указывающих на эти блоки (рис. 7.16).
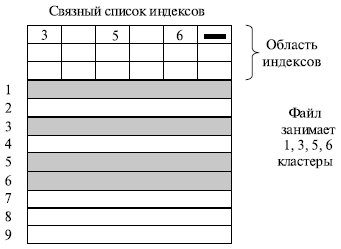
Рис. 7.16. Вариант физической организации файлов
Такая таблица, называемая FAT-таблицей (File Allocation Table), используется в файловых системах MS-DOS и Windows (FAT 16 и FAT 32). Файлу выделяется память на диске в виде связного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. С каждым кластером диска связывается индекс. Индексы располагаются в FAT-таблице в отдельной области диска. Когда память свободна, все индексы равны нулю. Если некоторый кластер N назначен файлу, то индекс этого кластера либо становится равным номеру M следующего кластера файла, либо принимает специальное значение, являющееся признаком того, что кластер является последним для файла. Вообще индексы могут содержать следующую информацию о кластере диска (для FAT 32):
- не используется (Unused) – 0000.0000;
- используется файлом (Cluster in us by a file) – значение, отличное от 000.000, FFFF.FFFF и FFFF.FFF7;
- плохой кластер (Bad cluster) – FFFF.FFF7;
- последний кластер файла (Last cluster in a file) – FFFF.FFFF.
При такой организации сохраняются все достоинства второго метода организации файлов: отсутствие фрагментации, отсутствие проблем при изменении размера. Кроме того, данный способ обладает дополнительными преимуществами: для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать FAT-таблицу, отсчитать нужное количество кластеров файла по цепочке и определить номера нужного кластера. Во-вторых, данные файла заполняют кластер целиком в объеме, кратном степени двойки.
Еще один способ заключается в простом перечислении номеров кластеров, занимаемых файлом (рис. 7.17). Этот перечень и служит адресом файла. Недостаток такого подхода – длина адреса зависит от размера файла. Достоинства – высокая скорость доступа к произвольному кластеру благодаря прямой адресации, отсутствие внешней фрагментации.

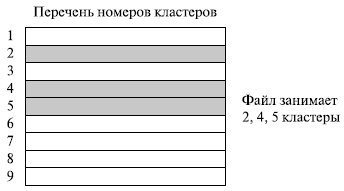
Рис. 7.17. Вариант физической организации файлов
Эффективный метод организации файлов, используемый в Unix-подобных операционных системах, состоит в связывании с каждым файлом структуры данных, называемой i-узлами. Такой узел содержит атрибуты файла и адреса кластеров файла (рис. 7.18). Преимущество такой схемы перед FAT-таблицей заключается в том, что каждый конкретный i-узел должен находиться в памяти только тогда, когда открыт соответствующий ему файл. Если каждый узел занимает n байт, а одновременно может быть открыто k фалов, то массив i-узлов займет в памяти k * n байт, что значительно меньше, чем FAT-таблица.
Это объясняется тем, что размер FAT-таблицы растет линейно с размером диска и даже быстрее, чем линейно, так как с увеличением количества кластеров на диске может потребоваться увеличить разрядность числа для хранения их номеров.
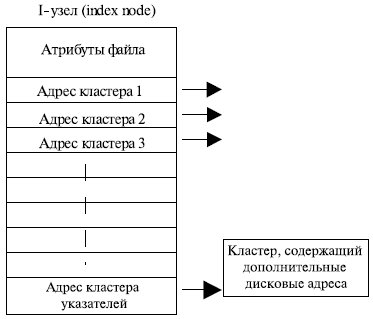
Рис. 7.18. Вариант физической организации файлов
Достоинством i-узлов является также высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация. Фрагментация на уровне кластеров также отсутствует.
Однако с такой схемой связана проблема, заключающаяся в том, что при выделении каждому файлу фиксированного количества адресов кластеров этого количества может не хватить. Выход из этой ситуации может быть в сочетании прямой и косвенной адресации. Такой поход реализован в файловой системе ufs, используемой в ОС UNIX, схема адресации в которой приведена на рис. 7.19.
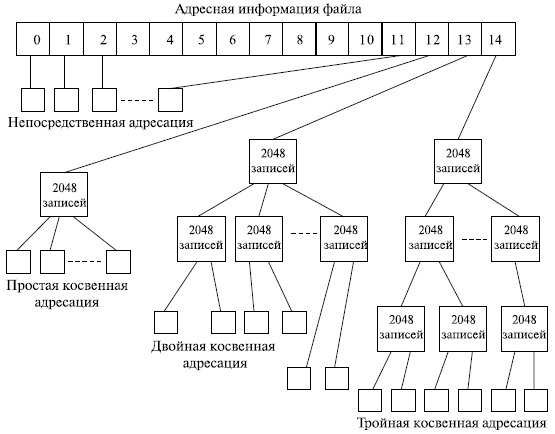
Рис. 7.19. Файловая система ufs
Для хранения адреса файла выделено 15 полей, каждое из которых состоит из 4 байт. Если размер файлов меньше или равен 12 кластерам, то номера этих кластеров непосредственно перечисляются в первых двенадцати полях адреса. Если кластер имеет размер 8 Кбайт, то можно адресовать файл размеров до 8 Кбайт * 12 = 98304 байт. Если размер кластера превышает 12 кластеров, то следующее 13 поле содержит адрес кластера, в котором могут быть расположены номера следующих кластеров, и размер файла может возрасти до 8192 * (12 + 2048) = 16.875.520 байт.
Следующий уровень адресации, обеспечиваемый 14-м полем, позволяет адресовать до 8192 * (12 + 2048 + 20482) = 3,43766*1020 байт. Если и этого недостаточно, используется следующее 15-е поле. В этом случае максимальный размер файла может составить 8192 * (12 + 2048 + 20482 + 20483) = 7,0403*1013 байт.
При этом объеме самой адресной информации составит всего 0,05% от объема адресуемых данных (задачи. ).
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS, применяемой в Windows NT/2000/2003. Для сокращения объема адресной информации в NTFS адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область называется экстентом (extent) и описывается двумя числами: номером начального кластера и количеством кластеров.
Каждому файлу на диске соответствует один и только один индексный дескриптор файла, который идентифицируется своим порядковым номером - индексом файла. Это означает, что число файлов, которые могут быть созданы в файловой системе, ограничено числом индексных дескрипторов, которое либо явно задается при создании файловой системы, либо вычисляется исходя из физического объема дискового раздела.
Индексный дескриптор файла имеет следующее строение.
| Название поля | Тип | Описание |
| 1.2em i_mode | USHORT | Тип и права доступа к данному файлу |
| i_uid | USHORT | Идентификатор владельца файла (Owner UID) |
| i_size | ULONG | Размер файла в байтах |
| i_atime | ULONG | Время последнего обращения к файлу (Access time) |
| i_ctime | ULONG | Время создания файла |
| i_mtime | ULONG | Время последней модификации файла |
| i_dtime | ULONG | Время удаления файла |
| i_gid | USHORT | Идентификатор группы (GID) |
| i_links_count | USHORT | Счетчик числа связей (Links count) |
| i_blocks | ULONG | Число блоков, занимаемых файлом |
| i_flags | ULONG | Флаги файла (File flags) |
| i_reserved1 | ULONG | Зарезервировано для ОС |
| i_block | ULONG[15] | Указатели на блоки, в которых записаны данные файла |
| i_version | ULONG | Версия файла (для NFS) |
| i_file_acl | ULONG | ACL файла |
| i_dir_acl | ULONG | ACL каталога |
| i_faddr | ULONG | Адрес фрагмента (Fragment address) |
| i_frag | UCHAR | Номер фрагмента (Fragment number) |
| i_fsize | UCHAR | Размер фрагмента (Fragment size) |
| i_pad1 | USHORT | Заполнение |
| i_reserved2 | ULONG[2] | Зарезервировано |
Поле типа и прав доступа к файлу представляет собой двух- байтовое слово, каждый бит которого служит флагом, индицирующим отношение файла к определенному типу или установку одного конкретного права на файл.
| Идентификатор | Значение | Назначение флага (поля) |
| 1.2em S_IFMT | F000 | Маска для типа файла |
| S_IFSOCK | A000 | Доменное гнездо (socket) |
| S_IFLNK | C000 | Символическая ссылка |
| S_IFREG | 8000 | Обычный (regular) файл |
| S_IFBLK | 6000 | Блок-ориентированное устройство |
| S_IFDIR | 4000 | Каталог |
| S_IFCHR | 2000 | Байт-ориентированное (символьное) устройство |
| S_IFIFO | 1000 | Именованный канал (fifo) |
| S_ISUID | 0800 | SUID - бит смены владельца S_ISGID 0400 SGID - бит смены группы |
| S_ISVTX | 0200 | Бит сохранения задачи (sticky bit) |
| S_IRWXU | 01C0 | Маска прав владельца файла |
| S_IRUSR | 0100 | Право на чтение |
| S_IWUSR | 0080 | Право на запись |
| S_IXUSR | 0040 | Право на выполнение |
| S_IRWXG | 0038 | Маска прав группы |
| S_IRGRP | 0020 | Право на чтение |
| S_IWGRP | 0010 | Право на запись |
| S_IXGRP | 0008 | Право на выполнение |
| S_IRWXO | 0007 | Маска прав остальных пользователей |
| S_IROTH | 0004 | Право на чтение |
| S_IWOTH | 0002 | Право на запись |
| S_IXOTH | 0001 | Право на выполнение |
Среди индексных дескрипторов имеется несколько дескрипторов, которые зарезервированы для специальных целей и играют особую роль в файловой системе. Это следующие дескрипторы
| Идентификатор | Значение | Описание |
| 1.2em EXT2_BAD_INO | 1 | Индексный дескриптор, в котором перечислены адреса дефектных блоков на диске (Bad blocks inode) |
| EXT2_ROOT_INO | 2 | Индексный дескриптор корневого каталога файловой системы (Root inode) |
| EXT2_ACL_IDX_INO | 3 | ACL inode |
| EXT2_ACL_DATA_INO | 4 | ACL inode |
| EXT2_BOOT_LOADER_INO | 5 | Индексный дескриптор загрузчика (Boot loader inode) |
| EXT2_UNDEL_DIR_INO | 6 | Undelete directory inode |
| EXT2_FIRST_INO | 11 | Первый незарезервированный индексный дескриптор |
Самый важный дескриптор в этом списке - дескриптор корневого каталога. Этот дескриптор указывает на корневой каталог, который, подобно всем каталогам, состоит из записей следущей структуры:
| Название поля | Тип | Описание |
| 1.2em inode | ULONG | номер индексного дескриптора (индекс) файла |
| rec_len | USHORT | Длина этой записи |
| name_len | USHORT | Длина имени файла |
| name | CHAR[0] | Имя файла |
Отдельная запись в каталоге не может пересекать границу блока (то есть должна быть расположена целиком внутри одного блока). Поэтому, если очередная запись не помещается целиком в данном блоке, она переносится в следующий блок, а предыдущая запись продолжается таким образом, чтобы она заполнила блок до конца.
Next: Система адресации данных Up: Файловая система Previous: Область блоков данных Contents Index Alex Otwagin 2002-12-16
Как уже говорилось, индекс включает в себя таблицу адресов расположения информации файла на диске. Так как каждый блок на диске адресуется по своему номеру, в этой таблице хранится совокупность номеров дисковых блоков. Если бы данные файла занимали непрерывный участок на диске (то есть файл занимал бы линейную последовательность дисковых блоков), то для обращения к данным в файле было бы достаточно хранить в индексе адрес начального блока и размер файла. Однако, такая стратегия размещения данных не позволяет осуществлять простое расширение и сжатие файлов в файловой системе без риска фрагментации свободного пространства памяти на диске. Более того, ядру пришлось бы выделять и резервировать непрерывное пространство в файловой системе перед выполнением операций, могущих привести к увеличению размера файла.
Рисунок 4.5. Размещение непрерывных файлов и фрагментация свободного пространства
Предположим, например, что пользователь создает три файла, A, B и C, каждый из которых занимает 10 дисковых блоков, а также что система выделила для размещения этих трех файлов непрерывное место. Если потом пользователь захочет добавить 5 блоков с информацией к среднему файлу, B, ядру придется скопировать файл B в то место в файловой системе, где найдется окно размером 15 блоков. В дополнение к затратам ресурсов на проведение этой операции дисковые блоки, занимаемые информацией файла B, станут неиспользуемыми, если только они не понадобятся файлам размером не более 10 блоков (Рисунок 4.5). Ядро могло бы минимизировать фрагментацию пространства памяти, периодически запуская процедуры чистки памяти, уплотняющие имеющуюся память, но это потребовало бы дополнительного расхода временных и системных ресурсов.
В целях повышения гибкости ядро присоединяет к файлу по одному блоку, позволяя информации файла быть разбросанной по всей файловой системе. Но такая схема размещения усложняет задачу поиска данных. Таблица адресов содержит список номеров блоков, содержащих принадлежащую файлу информацию, однако простые вычисления показывают, что линейным списком блоков файла в индексе трудно управлять. Если логический блок занимает 1 Кбайт, то файлу, состоящему из 10 Кбайт, потребовался бы индекс на 10 номеров блоков, а файлу, состоящему из 100 Кбайт, понадобился бы индекс на 100 номеров блоков. Либо пусть размер индекса будет варьироваться в зависимости от размера файла, либо пришлось бы установить относительно жесткое ограничение на размер файла.
Для того, чтобы небольшая структура индекса позволяла работать с большими файлами, таблица адресов дисковых блоков приводится в соответствие со структурой, представленной на Рисунке 4.6. Версия V системы UNIX работает с 13 точками входа в таблицу адресов индекса, но принципиальные моменты не зависят от количества точек входа. Блок, имеющий пометку "прямая адресация" на рисунке, содержит номера дисковых блоков, в которых хранятся реальные данные. Блок, имеющий пометку "одинарная косвенная адресация", указывает на блок, содержащий список номеров блоков прямой адресации. Чтобы обратиться к данным с помощью блока косвенной адресации, ядро должно считать этот блок, найти соответствующий вход в блок прямой адресации и, считав блок прямой адресации, обнаружить данные. Блок, имеющий пометку "двойная косвенная адресация", содержит список номеров блоков одинарной косвенной адресации, а блок, имеющий пометку "тройная косвенная адресация", содержит список номеров блоков двойной косвенной адресации.
В принципе, этот метод можно было бы распространить и на поддержку блоков четверной косвенной адресации, блоков пятерной косвенной адресации и так далее, но на практике оказывается достаточно имеющейся структуры. Предположим, что размер логического блока в файловой системе 1 Кбайт и что номер блока занимает 32 бита (4 байта). Тогда в блоке может храниться до 256 номеров блоков. Расчеты показывают (Рисунок 4.7), что максимальный размер файла превышает 16 Гбайт, если использовать в индексе 10 блоков прямой адресации и 1 одинарной косвенной адресации, 1 двойной косвенной адресации и 1 тройной косвенной адресации. Если же учесть, что длина поля "размер файла" в индексе - 32 бита, то размер файла в действительности ограничен 4 Гбайтами (2 в степени 32).
Процессы обращаются к информации в файле, задавая смещение в байтах. Они рассматривают файл как поток байтов и ведут подсчет байтов, начиная с нулевого адреса и заканчивая адресом, равным размеру файла. Ядро переходит от байтов к блокам: файл начинается с нулевого логического блока и заканчивается блоком, номер которого определяется исходя из размера файла. Ядро обращается к индексу и превращает логический блок, принадлежащий файлу, в соответствующий дисковый блок. На Рисунке 4.8 представлен алгоритм bmap пересчета смещения в байтах от начала файла в номер физического блока на диске.
Рисунок 4.6. Блоки прямой и косвенной адресации в индексе
Рисунок 4.7. Объем файла в байтах при размере блока 1 Кбайт
Рисунок 4.8. Преобразование адреса смещения в номер блока в файловой системе
Рисунок 4.9. Размещение блоков в файле и его индексе
При ближайшем рассмотрении Рисунка 4.9 обнаруживается, что несколько входов для блока в индексе имеют значение 0 и это значит, что в данных записях информация о логических блоках отсутствует. Такое имеет место, если в соответствующие блоки файла никогда не записывалась информация и по этой причине у номеров блоков остались их первоначальные нулевые значения. Для таких блоков пространство на диске не выделяется. Подобное расположение блоков в файле вызывается процессами, запускающими системные операции lseek и write (см. следующую главу). В следующей главе также объясняется, каким образом ядро обрабатывает системные вызовы операции read, с помощью которой производится обращение к блокам.
Преобразование адресов с большими смещениями, в частности с использованием блоков тройной косвенной адресации, является сложной процедурой, требующей от ядра обращения уже к трем дисковым блокам в дополнение к индексу и информационному блоку. Даже если ядро обнаружит блоки в буферном кеше, операция останется дорогостоящей, так как ядру придется многократно обращаться к буферному кешу и приостанавливать свою работу в ожидании снятия блокировки с буферов. Насколько эффективен этот алгоритм на практике? Это зависит от того, как используется система, а также от того, кто является пользователем и каков состав задач, вызывающий потребность в более частом обращении к большим или, наоборот, маленьким файлам. Однако, как уже было замечено [Mullender 84], большинство файлов в системе UNIX имеет размер, не превышающий 10 Кбайт и даже 1 Кбайта ! (*) Поскольку 10 Кбайт файла располагаются в блоках прямой адресации, к большей части данных, хранящихся в файлах, доступ может производиться за одно обращение к диску. Поэтому в отличие от обращения к большим файлам, работа с файлами стандартного размера протекает быстро.
В двух модификациях только что описанной структуры индекса предпринимается попытка использовать размерные характеристики файла. Основной принцип в реализации файловой системы BSD 4.2 [McKusick 84] состоит в том, что чем больше объем данных, к которым ядро может получить доступ за одно обращение к диску, тем быстрее протекает работа с файлом. Это свидетельствует в пользу увеличения размера логического блока на диске, поэтому в системе BSD разрешается иметь логические блоки размером 4 или 8 Кбайт. Однако, увеличение размера блоков на диске приводит к увеличению фрагментации блоков, при которой значительные участки дискового пространства остаются неиспользуемыми. Например, если размер логического блока 8 Кбайт, тогда файл размером 12 Кбайт занимает 1 полный блок и половину второго блока. Другая половина второго блока (4 Кбайта) фактически теряется; другие файлы не могут использовать ее для хранения данных. Если размеры файлов таковы, что число байт, попавших в последний блок, является равномерно распределенной величиной, то средние потери дискового пространства составляют полблока на каждый файл; объем теряемого дискового пространства достигает в файловой системе с логическими блоками размером 4 Кбайта 45% [McKusick 84]. Выход из этой ситуации в системе BSD состоит в выделении только части блока (фрагмента) для размещения оставшейся информации файла. Один дисковый блок может включать в себя фрагменты, принадлежащие нескольким файлам. Некоторые подробности этой реализации исследуются на примере упражнения в главе 5.
Второй модификацией рассмотренной классической структуры индекса является идея хранения в индексе информации файла (см. [Mullender 84]). Если увеличить размер индекса так, чтобы индекс занимал весь дисковый блок, небольшая часть блока может быть использована для собственно индексных структур, а оставшаяся часть - для хранения конца файла и даже во многих случаях для хранения файла целиком. Основное преимущество такого подхода заключается в том, что необходимо только одно обращение к диску для считывания индекса и всей информации, если файл помещается в индексном блоке.
(*) На примере 19978 файлов Маллендер и Танненбаум говорят, что приблизительно 85% файлов имеют размер менее 8 Кбайт и 48% - менее 1 Кбайта. Несмотря на то, что эти данные варьируются от одной реализации системы к другой, для многих реализаций системы UNIX они показательны.
Обращаем Ваше внимание, что в соответствии с Федеральным законом N 273-ФЗ «Об образовании в Российской Федерации» в организациях, осуществляющих образовательную деятельность, организовывается обучение и воспитание обучающихся с ОВЗ как совместно с другими обучающимися, так и в отдельных классах или группах.
Рабочие листы и материалы для учителей и воспитателей
Более 2 500 дидактических материалов для школьного и домашнего обучения
Столичный центр образовательных технологий г. Москва
Получите квалификацию учитель математики за 2 месяца
от 3 170 руб. 1900 руб.
Количество часов 300 ч. / 600 ч.
Успеть записаться со скидкой
Форма обучения дистанционная
- Онлайн
формат - Диплом
гособразца - Помощь в трудоустройстве
311 лекций для учителей,
воспитателей и психологов
Получите свидетельство
о просмотре прямо сейчас!
Индексированные файлы. _
Хотя технология хеширования и может дать высокую эффективность, но для её реализации не всегда удается найти соответствующую функцию, поэтому при организации доступа к данным широко используются индексные файлы.
Основное назначение индексов состоит в обеспечении эффективного прямого доступа к записи таблицы по ключу. Различают индексированный файл и индексный файл (рис. 7). Индексированный файл — это основной файл, содержащий данные отношения, для которого создан индексный файл.

Рис. 7. Индексированный и индексный файлы
Индексный файл — это файл особого типа, в котором каждая запись состоит из двух значений: данных и указателя. Данные представляют поле, по которому производится индексирование, а указатель осуществляет связывание с соответствующим кортежем индексированного файла. Если индексирование осуществляется по ключевому полю, то индекс называется первичным. Такой индекс к тому же обладает свойством уникальности, т. е. не содержит дубликатов ключа.
Обычно индекс определяется для одного отношения, и ключом является значение простого или составного атрибута.
Основное преимущество использования индексов заключается в значительном ускорении процесса выборки данных, а основной недостаток — в замедлении процесса обновления данных- Действительно, при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс (а это дополнительное время) в индексный файл. Поэтому при выборе поля индексирования всегда важно уточнить, который из двух показателей важнее: скорость выборки или скорость обновления.
осуществлять последовательный доступ к индексированному файлу в соответствии со значениями индексного поля для составления запросов на поиск наборов записей;
осуществлять прямой доступ к отдельным записям индексированного файла на основе заданного значения индексного поля для составления запросов для заданных значений индекса;
организовать запросы, не требующие обращения к индексированному файлу, а лишь приводящие к проверке наличия данного значения в индексном файле.
Поскольку при выполнении многих операций языкового уровня требуется сортировка отношений в соответствии со значениями некоторых атрибутов, полезным свойством индекса является обеспечение последовательного просмотра кортежей отношения в диапазоне значений ключа в порядке возрастания или убывания значений ключа.
В зависимости от организации индексной и основной областей различают два типа файлов: индексно-прямые файлы и индексно-последовательные файлы. При рассмотрении определенной технологии будем, прежде всего обращать внимание на ее достоинства и слабые места, а также на поддерживаемые ею способы поиска информации, вставки и удаления записи.
Индекс в базе данных аналогичен предметному указателю в книге. Индекс – это вспомогательная структура, связанная с файлом и предназначенная для поиска информации по тому же принципу, что и в книге предметным указателем. Индекс позволяет избежать проведения последовательного или пошагового просмотра файла в поисках необходимых данных.
Индекс – структура данных, которая помогает СУБД быстрее обнаружить отдельные записи в файле и сократить время выполнения запросов пользователей. Структура индекса связана с определенным ключом поиска и содержит записи, состоящие из ключевого значения и адреса логической записи в файле, содержащей это ключевое значение. Файл, содержащий логические записи, называется файлом данных, а файл, содержащий индексные записи, - индексным файлом. Значения в индексном файле упорядочены по полю индексирования, которое обычно строится на базе одного атрибута.
Для ускорения доступа к данным применяют несколько типов индексов:
· Первичный индекс. Файл данных последовательно упорядочивается по полю ключа упорядочения, а на основе ключа упорядочения создается поле индексации, которое гарантированно имеет уникальное значение в каждой записи.
· Индекс кластеризации. Файл данных последовательно упорядочивается по неключевому полю, а на основе этого неключевого поля формируется поле индексации, поэтому в файле может быть несколько записей, соответствующих значению этого поля индексации. Неключевое поле называется атрибутом кластеризации.
· Вторичный индекс, который определен на поле данных, отличном от поля, по которому выполняется упорядочение.
Файл может иметь не больше одного первичного индекса или одного индекса кластеризации, но дополнительно к ним может иметь несколько вторичных индексов.
Индекс может быть:
· Разреженным то есть содержать индексные записи только для некоторых значений ключа поиска.
· Плотным то есть содержать индексные записи для всех значений ключа поиска.
Файлы на основе индексов можно разделить на следующие группы: индексно-последовательные файлы, файлы с использованием вторичного индекса, файлы с использованием многоуровневых индексов и файлы с использованием индекса кластеризации.
Индексно-последовательные файлы – отсортированные файлы с первичным индексом. В таком файле записи могут обрабатываться как последовательно, так и выборочно с произвольным доступом, осуществляемым на основе поиска по заданному значению ключа с использованием индекса.
Файлы с использованием вторичного индекса являются упорядоченными файлами. Файл данных, связанный с вторичным индексом, не всегда отсортирован по ключу индексации. Ключ вторичного индекса может содержать повторяющиеся значения. При запросах, в которых для поиска используются атрибуты, отличные от атрибутов первичного ключа, вторичные индексы повышают производительность обработки запросов.
Файлы с использованием многоуровневых индексов. Поиск в такого рода файлах начинается с поиска индекса самого низкого уровня, при нахождении нужной страницы (с атрибутом, равным условию или большим) идет ссылка на следующий уровень индекса с более подробной индексацией записей и т.д.
Во многих СУБД используется структура данных, называемая деревом. Дерево состоит из иерархии узлов, в котором каждый узел, за исключением корня, имеет родительский узел, а также один, несколько или ни одного дочернего узла. Если узел не имеет дочернего, его называют листом. Глубина дерева – минимальное количество уровней между корнем и листом. Глубина дерева может быть различной для разных путей доступа к листам. Если глубина одинакова для всех листов, то дерево называют сбалансированным или В-деревом. Степенью или порядком дерева называют максимально допустимое количество дочерних узлов для каждого родительского узла. Бинарным деревом называют дерево порядка 2.
Усовершенствованные сбалансированные древовидные индексы (В+-деревом) определяются по следующим правилам:
· если корень не является лист-узлом, то он должен иметь хотя бы два дочерних узла;
· в дереве порядка n каждый узел (за исключением корня и листов) должны иметь от n/2 до n указателей и дочерних узлов. Если число n/2 не является целым, то оно округляется до ближайшего большего целого;
· в дереве порядка n количество значений ключа в листе должно находиться в пределах от (n-1)/2 до (n-1). Если число (n-1)/2 не является целым, то оно округляется до ближайшего большего целого;
· количество значений ключа в нелистовом узле на единицу меньше количества указателей;
· дерево всегда должно быть сбалансированным;
· листы дерева связаны в порядке возрастания значений ключа.
Файлы с использованием индекса кластеризации.
Кластерами называют группы из одной или нескольких таблиц, которые физически хранятся вместе, поскольку в них совместно используются общие столбцы и доступ к ним часто осуществляется одновременно. Пример кластеризованного хранения данных приведен на рисунке 21.
Рисунок 21 - Таблицы Сотрудники и Должность, кластеризованные по значению Код должности
Использование кластеров позволяет повысить производительность выборки данных, но степень такого повышения зависит от распределения данных и типовых запросов.
В кластеризованных таблицах используют индексированные и хешированные кластеры. В индексированном кластере хранятся вместе записи, имеющие одинаковый ключ кластера. В хешированный кластер запись вносится с учетом применения хеш-функции к значению ключа кластера этой записи.
Читайте также: