
Из чего состоит файл doc
О сложности и жуткости вордовских файлов давно ходили легенды. Известно было, что формат этот крайне запутанный, а к тому же еще и полностью засекреченный, так что о половине тамошних полей можно было только догадываться.
Не скрою, что и меня эти файлы интересовали, но дальше первой страницы описания я так продвинуться и не смог. Однако незакрытый гештальт остался.
А теперь вот жизнь заставила (или подкинула возможность) все-таки разобраться во внутренностях всем хорошо известных документов, тем более, что в Штирлица теперь играть не обязательно, достаточно скачать с сайта «Майкрософта» официальные спецификации.
Что тут можно сказать? Невольно вспоминается старый пошлый анекдот: ну ужас. Ну просто ужас, но ведь не ужас-ужас-ужас.
Слава богу, что я разбирал эти файлы на Перле, а не на каком-нибудь автокоде Си. Высокий уровень языка и куча готовых библиотек (например, для чтения разных кодовых страниц) — это дар божий.
Так что работа в совокупности заняла неделю, и самым сложным было понять внутренний формат. Конечно, понимание это не совсем полное, потому что моей задачей было вытащить из документа одни тексты без всякого форматирования, но уж это я сделал тщательно.
Итак, как же устроены вордовские файлы?
Контейнер
Начнем с того, что это совсем не вордовские файлы, а некий универсальный контейнер, в который упакованы собственно документы. В такой контейнер засунуты все файлы Офиса, а, может быть, и еще что-нибудь.
Формат контейнера называется по-разному — docfile, ole storage, compound document file. Уже сам разнобой в названиях намекает на то, что он не сильно-то и нужен, поскольку действительно полезная вещь обычно имеет одно и четкое название. Основная его идея — иметь возможность запихать в один файл несколько других. Самым разумным было бы (как и сделали в OpenOffice) упаковать все в архив ZIP (можно без архивации, если она не нужна). Формат известен огромному множеству программ, компактен, легко разбирается. Но в «Майкрософте», очевидно, процветает синдром «Not invented here». Главное — изобрести велосипед, пусть и трехколесный, но собственный.
В принципе, формат OLE Storage достаточно разумен и не производит впечатление чего-то совсем идиотского. Но… он совершенно не нужен. Фактически, это что-то типа файловой системы FAT16, засунутой внутрь отдельного файла. Это не то что стрельба из пушки по воробьям, а истребление этих самых воробьев ядерными торпедами. В документе, внутри которого лежит несколько файлов, не нужна файловая система, находящаяся не менее чем на уровне ФС времен ДОС.
Итак, файлы CDF (как их называет юниксовская утилитка file) начинаются с заголовка. В заголовке отведено место под первую сотню записей ТРФ (таблицы размещения файлов, в просторечии — ФАТ). ФАТ там самый натуральный, очень похож на то, что можно найти на досовских дискетках. Остальные записи ТРФ лежат в отдельных секторах, соединенных связанным списком. Дополнительные сектора бывают только в больших (>7мб) файлах.
По табличке ФАТ/ТРФ можно собрать содержимое любого внутреннего файла (в терминологии МС он называется потоком, но это только запутывает дело), если знать, с какого блока он начинается. Начальные блоки разных структур написаны, естественно, в заголовке. Дальше из таблицы можно вытянуть всю цепочку секторов, в котором записано содержимое этого псевдофайла.
В частности, у CDF есть корневой каталог, физически размазанный по куче секторов. Это самый настоящий каталог, опять-таки, очень напоминающий старый досовский. Правда, для эффективности (или для выпендрежа) он выполнен не просто линейным списком, а сбалансированным двоичным деревом. Это значит, что в него без потери эффективности поиска можно записывать десятки тысяч отдельных записей. Зачем это нужно в файле, в котором записей бывает обычно штук пять, ну иногда, двадцать, ну максимум сто штук (презентация с огромным количество картинок) — знают только в Редмонде. Кстати, имена файлов в каталоге хранятся в UTF16 — тоже на всякий случай.
По каталогу можно определить начальный сектор любого файла и с помощью ТРФ вытянуть всю его цепочку размещения.
Но это еще не все.
Поскольку размер блока немаленький (обычно 512 байт, по спецификации возможно также 4096), то при хранении мелких псевдофайлов, теоретически можно потерять много свободного места. Поэтому существует отдельное хранилище, поделенное на блочки по 64 байта. Хранилище опять-таки вытягивается по цепочке ФАТ.
Чтобы указать, какие блочки какому файлу принадлежат, существует отдельная табличка ФАТ или, вернее сказать, миниФАТ.
Итак, чтобы добраться до вордовского документа, надо сделать следующее:
1. Прочитать заголовок CDF
2. Загрузить в память ФАТ — таблицу размещения файлов, собрав ее по цепочке секторов.
3. Загрузить табличку МиниФАТ, собрав ее по цепочке ТРФ
4. Загрузить хранилище блочков, собрав ее по цепочке ТРФ
5. Загрузить корневой каталог, собрав ее по цепочке ТРФ
6. Разобрать каталог и преобразовать его во что-то читаемое
7. Найти в каталоге запись WordDocument
8. Если это маленький файл, то собрать его с помощью миниТРФ из хранилища для блочков.
9. Если большой, то вытянуть с диска сектора по цепочке ТРФ.
Каждый шаг сам по себе не особенно сложен, но в совокупности они вызывают исключительно недоумение. Зачем такие сложности? Почему нельзя было разместить после заголовка обыкновенный линейный каталог, а после него непрерывно, друг за другом записывать внутренние файлы?
Единственное, что можно предположить — все это сделано для того, чтобы была возможность дописывать подфайлы, не трогая начало основного файла. Надо заметить, что, во-первых, это не сильно востребованная операция, поскольку все программы обычно записывают документы от начала до конца в один проход. Исключение составляет только MS Word и то только в пресловутом режиме быстрого сохранения, проклятом пользователями. А во-вторых, даже в этих условиях все равно не получится не трогать начало основного файла, поскольку надо обновлять каталоги, ТРФ и заголовки.
В общем, «Майкрософт» в своем амплуа. Зачем делать просто, если можно сложно и запутанно?
WordDocument
Формат CDF при всей своей монструозности хотя бы логичен и не очень сложен (если сравнивать с остальным содержимым вордовского документа). Его описание занимает всего каких-то двадцать страниц — тьфу по сравнению с 300 страницами формата Ворда.
Формат документа сложно даже назвать форматом, гораздо больше к нему подойдет определение каменной летописи. Представьте себе такой каменный обрыв, на котором отпечаталось пятьдесят миллионов лет истории планеты. Вот мезозойский слой, вот кайнозойский, вот отпечаток крыла птеродактиля, а сверху уже третичные отложения. Примерно так же выглядит и документ изнутри.
Достаточно посмотреть на заголовок, который занимает чуть ли не треть файла. Заголовков целых три. Сначала идет один небольшой, в котором половина записей зияет дырами «Reserved» или «Not used». Раньше, в мезозое, там явно что-то лежало, но потом было выкинуто на свалку истории. Здесь же имеется версия записавшей программы, по которой в коде, похоже, выполняется огромный switch/case.
Затем идет второй заголовок, состоящий из шестнадцатибитовых слов. В нем нет вообще ничего полезного. В его начале прописан размер явно с таким расчетом, что здесь будут в будущем откладываться панцири простейших.
После этого идет третий заголовок, на этот раз современный, из длинных слов (32 бита). Он немерянной длины, в начале тоже указывает количество записей с прицелом на дальнейшее расширение, и в основном представляет собой список, где искать различные таблицы и куски файла — пары начало/размер. Сами таблицы, кстати, лежат не здесь, а в отдельном псевдофайле CDF под названием 0Table или 1Table (возможны варианты).
В первом заголовке написана длина самого текста и его начало. Очевидно, что во времена царя Гороха именно так его и можно было прочитать. Текст лежал одним большим куском. Забавно, что можно читать его так и сейчас, но… не всегда! На десять читаемых файлов найдется такой, у которого в середине окажутся невразумительные куски, в конце — сноски, которых там быть не должно, а в самом начале — большой кусок текста, который стерли в прошлом году. Кроме того, половина файла окажется написана китайскими иероглифами. Прискорбно заметить, что известная утилита catdoc Витуса Вагнера в некоторых случаях именно такие результаты и дает, из чего можно сделать вывод, что формат она разбирает недокорректно.
Жизнь на самом деле гораздо сложнее. Когда-то в файлах действительно был только текст, однако со временем под давлением пользователей и маркетинга накапливались различные «фичи». Под них отвели отдельные потоки — под простые сноски, под сноски концевые, под колонтитулы, под какие-то textbox (то еще извращение — на вид текст, но не текст. Назначение толком не ясно).
Начала этих потоков указаны в специальных местах заголовка, но самый первый заголовок почему-то показывает общую длину — не самого текста, а текста плюс все этих извращений. Вот и первая причина, почему в вывод многих утилит попадают надписи типа Page 1.
Где-то в архее в редактор добавили быстрое сохранение. Смысл его в том, что файл целиком не переписывается, а добавления и изменения просто дописываются в его конец, что теоретически должно быть быстрее. Предполагалось радовать этим пользователей, но фактически они остались недовольны. Особой разницы в скорости записи при этом не получается, но в файле образуется много мусора, причем из кусков, которые теоретически уже стерты. Если там была какая-нибудь секретная информация, то простым просмотром дампа файла ее можно легко обнаружить.
Для поддержки быстрого сохранения была заведена особая таблица огрызков (piece table), в которую записывается начало каждого куска и его адрес в файле. Длины нет, но ее можно высчитать, вычтя начало текущего куска из начала следующего. Однако тут тоже надо быть осторожным, поскольку огрызки перечисляются из всех потоков. Слава богу, что они идут в определенном порядке, поэтому, зная общую длину текста, легко вовремя остановиться.
Теоретически, этот сложный формат задействован только, если в заголовке установлен специальный флажок fComplex. Но… Вот на этом очередном «но» тоже прокалываются многие конверторы.
Уже в наше время в документы добавили возможность записи в Юникоде. При этом встала проблема (как по мне, надуманная): а ведь файлы получаются ровно в два раза длиннее. Поскольку ПО разрабатывают американцы, которые в душе вообще не верят в существование других азбук, и тайно считают, что всякие странные буквы бывают только в диссертациях про Древнюю Грецию, да и там встречаются только иногда, первое, что пришло им на ум — отделить чистые символы ASCII от грязных юникодовских. Первые писать по байту на символ, вторые — как получится.
Из этой идеи возникла, например, элегантная кодировка UTF-8, где двухбайтовые символы кодируются хитрыми последовательностями в духе кодирования Хаффмана. В «Майкрософте» сделали то же самое, только не так красиво. Раз уж у нас есть таблица огрызков, то запишем туда заодно и какие куски текста написаны в чистом ASCII (на самом деле сp1252), а какие — на всякого рода невразумительных алфавитах, требующих Юникода и, соответственно два байта на символ. Поэтому нынешние файлы всегда нужно разбирать с помощью таблицы кусков, невзирая на всякие там флажки. Юникодовские фрагменты там берутся как есть, только надо учитывать, что количество читаемых байтов должно быть в два раза больше количества читаемых символов. Однобайтовые фрагменты отмечаются в адресе установленным вторым слева старшим битом (почему не первым?). Чтобы узнать настоящий адрес, нужно этот бит сбросить, а адрес разделить на два (!).
Если учесть, что сама эта таблица огрызков тоже занимает место, а еще больше места в файле занимают разные двоичные деревья и таблички цепочек секторов от формата CDF, то размеры экономии текста на символах Юникода не поразят воображения даже в древнегреческих диссертациях. О файлах на великом и могучем языке и говорить нечего. Положили бы все в UTF-16 и не страдали. Ну заархивировали бы поток, раз уж так жаба давит.
После героических усилий по чтению текста, в нем самом, как ни странно, нет ничего сложного. Обычный текст (с поправкой на кодировку), кое-какие коды ниже пробела играют служебную роль. Например, 0х9 обозначает, как и положено, табуляцию, 0хА — конец страницы, 0х7 — конец ячейки таблицы и т.д. Единственная тонкость связана с полями. Начало содержимого поля обозначается как 0х13, конец поля — 0х15, имя и параметры поля отделяются символом 0х14 от того, что, собственно, видно в тексте пользователю. Но… Вторая часть может иметь в себе вложенное поле, чего многие программы не учитывают. В результате в тексте остаются огрызки вроде INCLUDEPICTURE или PAGEREF *.
Впрочем, есть еще одна мелкая пакость. Некоторые символы могут означать что-нибудь совсем другое, вроде текущей даты. Чтобы понять, простой это символ или нет, надо разбирать таблицы свойств символов, о которых ниже. Каюсь, я просто вырезал все символы с кодом ниже пробела, что не совсем достаточно, но дешево, быстро и практично.
Выдрав текст, дальше в формат я углубляться не стал. Это уже занятие для молодых и сильных духом — разобрать все эти таблицы с такими многообещающими названиями как CHP, PAPX, SHST, PLCF и все в том же духе. Занятие совсем уже для титанов — вопроизвести форматирование в точности, как это делает сам Ворд.
Кратко изложу только, что все хранится в специальных таблицах, входом в которые служит адрес символа с начала потока. Стили лежат в длинных списках, изменения в стилях — в специальных списках исключений. Локальные изменения стиля, например, при редактировании абзаца или символа хранятся в таблицах как специальные команды по изменению родительских таблиц стилей. Сами команды очень напоминают команды виртуальной машины от типичной игры-квеста.
Осталось только подвести мораль, а она банальна: что один человек придумал, то другой завсегда поломать может. Что не делает формат Ворда менее позорным, уродливым и совершенно неприспособленным для задач массового обмена информацией в гетерогенных системах.
Думаю, что «Майкрософт» столько лет его не открывала не потому, что боялась конкуренции, а просто потому что было… стыдно.
Несколько позже, чем хотелось, но продолжаем наш разговор о получении текста из разных форматов данных. Мы с вами уже познакомились с тем, как работать с изначально XML-base файлами (docx и odt), прочитали текст из pdf, преобразовали содержимое rtf в plain-text. Теперь перейдём в вкусненькому да сладенькому — формату DOC.
Прежде, чем внимательный читатель задастся вопросом о странной аббревиатуре в заголовке, я всё же попрошу взглянуть на содержимое какого-нибудь doc-файла:
Я думаю, что многие из нас на заре своей компьютерной грамотности пытались открыть doc-файлы блокнотом и видели похожие крякозябрики. Но давайте зададимся вопросом, что мы можем вынести из этого месива байтов, которое есть ничто иное, как всё тот же «Парус»? Самое интересное для нас здесь, это первые восемь байт, которые будут попадаться нам от файла к файлу, а именно "D0 CF 11 E0 A1 B1 1A E1" в hex'ах, или если угодно "РПаЎ±б" в блокноте.
Вот теперь-то и стоит расшифровать второе сокращение в заголовке. WCBFF есть ничто иное, как Windows Compound Binary File Format, что по-русски звучит как «Windows Подворье двоичных файлов формата». Оставим перевод на совести корпорации и подумаем, чем нам поможет этот формат со страшным названием.
Так вот, CFB является прародителем, или, даже правильней сказать, скелетом для всех форматов Microsoft Office от 97 ой версии до 2007 (при сохранении в формате совместимости). Этот CFB используется не только для хранения Word'овского текста, но и для сохранения листов Excel'а или презентаций PowerPoint'а. Как следствие, нам придётся прочитать костяк, что «зашифрован» в CFB, а уж потом найти в прочитанных данных текст с учётом формата DOC.
CFB или маленькая файловая система
Первым этапом, как я уже сказал, будет чтение CFB. CFB представляет файловую структуру в миниатюре: с секторами, корневой директориями и некоторым подобием файлов. Даже проблемы у этого файла такие же, как у обычных ФС — фрагментрованность секторов, например. Поэтому без знания структуры формата этот файл прочесть будет делом не лёгким — благо Microsoft пару лет открыл документацию как по CFB, так и по всем остальным «надстроечным» форматам.
Давайте попробуем понять, как упакована информация в CFB-файлах. Весь файл поделён на сектора — в 512 байт каждый (в новой, четвёртой, версии размер сектора может быть 4096 байт). В первом секторе находится заголовок файла, кусочек которого мы лицезрели на скриншоте выше. В нём (заголовке) содержится вся информация о том, как, что и в какой последовательности читать из файла.
Данные в файле хранятся сегментами (FAT) в те самые 512 байт. При нехватке места в секторе-сегменте остаток данных переносится в следующий по цепочке. Секторы цепочки могут быть разбросаны по файлу (т.е. файл может быть фрагментирован, как отмечалось выше). Для поддержания целостности цепочки секторов существуют специальные сектора, которые содержат, в какой сектор переходить из текущего, если все данные не прочитаны. Конец цепочки характеризуется специальным словом ENDOFCHAIN = 0xFFFFFFFE .
В связи с тем, что для некоторых данных 512 байт может быть очень много, существуют «миниатюрные» сектора, называемые mini FAT. Мини FAT-сектор имеет длину 64 байта, поэтому в один FAT-сектор может влезть 8 (или 64) таких маленьких сегмента. Выбор в сторону FAT или mini FAT осуществляется, исходя из полной длины текущих данных. Если она меньше 4096 байт (один из параметров заголовка файла), тогда стоит использовать mini FAT, в противном случае — FAT.
Данные в CFB-файле не навалены просто так — они структурированы в некоторую древовидную структуру, с корнем в специальном «файловом вхождении» Root Entry . Каждое такое entry имеет длину в 128 байт (в один сегмет FAT влезает 4 или 32 вхождения) и характеризуется названием, типом (хранилище — storage, поток — stream, корневое хранилище — root storage, пустое пространство — unused), дочерним и «братскими» элементами, цветом в красно-чёрном дереве. Помимо этого для потоков и корневого элемента имеют место такие параметры как смещение и длина содержимого.
Таким образом, каждое вхождение в ФС может характеризоваться «прикреплённым к нему содержимым». Для потоков это будут хранимые в них данные, для корневого элемента — mini FAT файла.
Кроме того, в файле есть структура, называемая DIFAT, которая хранит ссылки на сектора с цепочками FAT-последовательностей. Первые 109 DIFAT-ссылок лежат в конце заголовка файла и могут «обслужить» файлы длиной до 8,5 Мб, если этого недостаточно, то в заголовке могут быть ссылки на дополнительный DIFAT-сектор, который может заканчивать ссылкой на следующий DIFAT и так далее.
Эта информация вкратце характеризует весь тот разброд и шатания, что творится в CFB-файлах. Формат, в принципе, достаточно неплохо документирован (ссылки по обыкновению в конце топика), достаточно только вдумчиво и скрупулёзно читать мануалы. Целью этой статьи я не ставил полное объяснение работы CFB-файлов, поэтому перейдём к главному — как читать doc из этого всего…
DOC или они украли мои смещения
Для начала скажу, что я написал парсинг doc (вместе с cfb) лишь с третьей попытки. До этого что-то где-то как-то не так читалось. А причина тому, что всё нужно было делать по документации, но… если с CFB это не составляет больших проблем (разве что английский, как язык мануала), то с DOC проблемы обеспечены.
Начнём с того, что мы прочитали файловую систему нашего DOC'а и жаждем найти в нём текстовые данные. Что ж, Microsoft открывший спецификацию сделал нам подарок и дал возможность это сделать. Для этого мы будем работать всего с двумя вхождениями в древовидную структуру элементов CFB-файла: это поток под названием « WordDocument » и поток с названием « 0Table » или « 1Table » в зависимости от ситуации.
В первом потоке находится текст документа Word, но просто так его не достать. Всё ужасно бинарно, да и ко всему прочему в Unicode кодировке с обратным порядком байтов (как и во всех CFB-файлах, стоит отметить). В связи с этим для начала прочитаем несколько полей из FIB — File Information Block — что лежит в начале потока WordDocument и наполняется от версии к версии (в 97 ом Word'е этот заголовок занимал около 700 байт, в 2007 ом — уже больше 2000).
В первую очередь прочитаем слово по смещению 0x000A , в котором найдём 0x0200 бит, единичка которого скажет нам, что мы будем иметь дело с таблицей 1Table , а ноль — с 0Table . Стоит отметить, что мне попадались файлы с обеими таблицами, поэтому бит придётся читать в любом случае.
Дальше, нам нужно найти CLX — самую жоп важную часть одной из выбранных ранее табличек. В этой структуре CompLeX хранятся смещения и длины последовательностей текстовых данных в потоке WordDocument. Длина и offset к CLX находятся в 0x01A2 и 0x01A6 DWORD'ах FIB'а «документарного потока». Получив эту информацию, мы считываем CLX из табличного потока и натыкаемся на затык…
Дело в том, что CLX содержит две абсолютно разные структуры данных переменного размера — ненужную нам RgPrc и важную PlcPcd. Дело в том, что длина PgPrc может быть как нулевой, так любой. К счастью, документация не говорит, как именно отсекать первые данные от вторых, поэтому в конечном коде пришлось писать некоторого рода костыль, который, как ни странно, работает.
После получения PlcPcd или, если быть более адекватным в названиях, Piece Table, мы можем разбить этот массив на два: массив cp — длины текстовых кусков ( lcbi = cpi+1 - cpi ) и pcd (piece descriptors). В каждом из последних содержится информация о смещении в WordDocument-потоке и характеристика fCompress — является ли этот кусок сжатым в Unicode, или это ANSI (Windows-1252).
В полученных кусочках могут встречаться некоторые управляющие символы, например, вставка объекта или изображения. В моём коде часть из них удалено, парсинг остальных спецсимволов я оставляю читателю.
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Выводы
Используя только XSLT и ZIP можно успешно работать с документами docx, таблицами xlsx и презентациями pptx.
Наша статья расскажет о текстовом формате DOCX: особенностях создания и редактирования, чем открыть.
Наша статья расскажет о текстовом формате DOCX: особенностях создания и редактирования, чем открыть DOCX, и какие платформы поддерживают такой формат.

Алгоритм
Алгоритм выглядит следующим образом:
- Распаковываем документ.
- Добавляем наш нижний колонтитул.
- Прописываем ссылку на него в [Content_Types].xml и word/_rels/document.xml.rels .
- В word/document.xml в тег добавляем тег или заменяем в нём ссылку на наш нижний колонтитул.
- Запаковываем документ.
Распаковка
В Caché ObjectScript есть возможность выполнять команды ОС с помощью функции $zf(-1, oscommand). Вызовем unzip для распаковки документа с помощью обёртки над $zf(-1):
Создаём файл нижнего колонтитула
На вход поступает текст нижнего колонтитула, запишем его в файл in.xml:
В XSLT (файл — footer.xsl) будем создавать нижний колонтитул с текстом из тега xml (часть пространств имён опущена, вот полный список):
В результате получится файл нижнего колонтитула footer0.xml :
Добавляем ссылку на колонтитул в список связей основного документа
Сссылки с идентификатором rId0 как правило не существует. Впрочем можно использовать XPath для получения идентификатора которого точно не существует.
Добавляем ссылку на footer0.xml c идентификатором rId0 в word/_rels/document.xml.rels :
Прописываем ссылки в документе
Далее надо в каждый тег добавить тег или заменить в нём ссылку на наш нижний колонтитул. Оказалось, что у каждого тега может быть 3 тега — для первой страницы, четных страниц и всего остального:
Добавляем колонтитул в [Content_Types].xml
Добавляем в [Content_Types].xml информацию о том, что /word/footer0.xml имеет тип application/vnd.openxmlformats-officedocument.wordprocessingml.footer+xml :
В результате
Весь код опубликован. Работает он так:
- in.docx — исходный документ
- out.docx — выходящий документ
- TEST — текст, который добавляется в нижний колонтитул
Практика
Найдя интересующее нас изменение, логично перейти к следующему этапу, это может быть что-либо из:
- Создания docx
- Парсинг docx
- Преобразования docx
Тут нам потребуются знания XSLT и XPath.
Давайте напишем достаточно простое преобразование — замену или добавление нижнего колонтитула в существующий документ. Писать я буду на языке Caché ObjectScript, но даже если вы его не знаете — не беда. В основном будем вызовать XSLT и архиватор. Ничего более. Итак, приступим.
Открыть DOCX в Word 2003

Чем открыть файл DOCX онлайн
Открыть DOCX онлайн в Microsoft Word Online. Чтобы работать с документами в этом сервисе, требуется авторизация в OneDrive. Интерфейс схож с Google: слева находится список последних файлов, справа – шаблоны.
Третий способ открыть файл DOCX онлайн – сервис Zoho Writer.
- Нажимаете «Start Writing». Создайте учетную запись на сайте или используйте авторизацию через соцсети Вконтакте, Facebook, Одноклассники.
- Откроется поле редактора.
- Вверху слева нажмите кнопку «Файл», далее «Импортировать документ». После загрузки нажмите «Открыть».
- Документ открыт для работы.
- После внесения изменений выберите вверху «Файл» и «Загрузить как».
Если нужно открыть документ ворд офис онлайн только для просмотра, выбирайте конвертер DocsPal.
Зачем?
docx — самый популярный формат документов, поэтому задача отдавать информацию пользователю в этом формате всегда может возникнуть. Один из вариантов решения этой проблемы — использование готовой библиотеки, может не подходить по ряду причин:
- библиотеки может просто не существовать
- в проекте не нужен ещё один чёрный ящик
- ограничения библиотеки по платформам и т.п.
- проблемы с лицензированием
- скорость работы
Поэтому в этой статье будем использовать только самые базовые инструменты для работы с docx документом.
Как и чем открыть файл DOCX расширения
Помимо общего описания формата мы подготовили список совместимых программ, которые открывают формат DOCX. Выбирайте, чем открыть файл DOCX на компьютере, смартфоне, онлайн или оффлайн:
Как и чем открыть
Представляем список программ и приложений, которые позволяют открыть DOC онлайн, а также на ревизиях операционки Windows 7 и 10.
История возникновения
Файловый формат DOC – интеллектуальная собственность корпорации Microsoft и принадлежит к категории проприетарного (частного, несвободного) ПО.
Первая сборка Word выпущена в 1985 году как 16-битное приложение PC-DOS / MS-DOS. Разработчики компании постоянно модернизировали программу и формат просуществовал вплоть до 2007 года. Тогда появилась Microsoft Word 2007 и новый формат текстовых документов – DOCX на основе двоичного кода XML.

На компьютере
Расскажем о программах, которые помогут открыть DOC без доступа к интернету и подойдут для разных выпусков Windows.
Общее описание
Формат применяется в системе Microsoft Word, которая включает Excel, Outlook, Photo Draw, PowerPoint и Publisher. В редактор встроены функции форматирования текста, работа с таблицами и иллюстрациями, настройка формата печати и другие.
docx и Microsoft Word
docx созданный с помощью Microsoft Word, да в принципе и с помощью любого другого редактора имеет несколько дополнительных файлов.
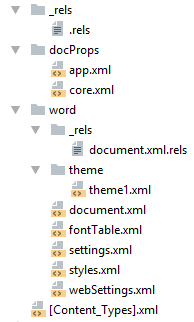
Вот что в них содержится:
- docProps/core.xml — основные метаданные документа согласно Open Packaging Conventions и Dublin Core [1], [2].
- docProps/app.xml — общая информация о документе: количество страниц, слов, символов, название приложения в котором был создан документ и т.п.
- word/settings.xml — настройки относящиеся к текущему документу.
- word/styles.xml — стили применимые к документу. Отделяют данные от представления.
- word/webSettings.xml — настройки отображения HTML частей документа и настройки того, как конвертировать документ в HTML.
- word/fontTable.xml — список шрифтов используемых в документе.
- word/theme1.xml — тема (состоит из цветовой схемы, шрифтов и форматирования).
В сложных документах частей может быть гораздо больше.
На андроиде
Расскажем, чем открыть файл DOC на платформе Android. Эти утилиты можно скачать у нас на сайте.
Чем открыть DOCX на андроиде
Официальное приложение Google - Quickoffice можно также скачать на нашем сайте. Открывает и конвертирует текстовые файлы, таблицы Excel и презентации. Синхронизируется с облаком и File Commander для быстрого доступа к файлам на смартфоне. По сравнению с другими приложениями оснащено расширенным инструментарием.
Реверс-инжиниринг docx
Итак, первоначальная задача — узнать как какой-либо фрагмент документа хранится в xml, чтобы потом создавать (или парсить) подобные документы самостоятельно. Для этого нам понадобятся:
- Архиватор zip
- Библиотека для форматирования XML (Word выдаёт XML без отступов, одной строкой)
- Средство для просмотра diff между файлами, я буду использовать git и TortoiseGit
Инструменты
- Под Windows: zip, unzip, libxml2, git, TortoiseGit
- Под Linux: apt-get install zip unzip libxml2 libxml2-utils git
Также понадобятся скрипты для автоматического (раз)архивирования и форматирования XML.
Использование под Windows:
- unpack file dir — распаковывает документ file в папку dir и форматирует xml
- pack dir file — запаковывает папку dir в документ file
Использование под Linux аналогично, только ./unpack.sh вместо unpack , а pack становится ./pack.sh .
Использование
Поиск изменений происходит следующим образом:
- Создаём пустой docx файл в редакторе.
- Распаковываем его с помощью unpack в новую папку.
- Коммитим новую папку.
- Добавляем в файл из п. 1. изучаемый элемент (гиперссылку, таблицу и т.д.).
- Распаковываем изменённый файл в уже существующую папку.
- Изучаем diff, убирая ненужные изменения (перестановки связей, порядок пространств имён и т.п.).
- Запаковываем папку и проверяем что получившийся файл открывается.
- Коммитим изменённую папку.
Пример 1. Выделение текста жирным
Посмотрим на практике, как найти тег который определяет форматирование текста жирным шрифтом.
- Создаём документ bold.docx с обычным (не жирным) текстом Test.
- Распаковываем его: unpack bold.docx bold . .
- Выделяем текст Test жирным.
- Распаковываем unpack bold.docx bold .
- Изначально diff выглядел следующим образом:
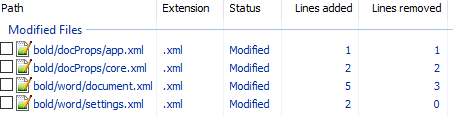
Рассмотрим его подробно:
docProps/app.xml
Изменение времени нам не нужно.
docProps/core.xml
Изменение версии документа и даты модификации нас также не интересует.
word/document.xml
Изменения в w:rsidR не интересны — это внутренняя информация для Microsoft Word. Ключевое изменение тут
в параграфе с Test. Видимо элемент и делает текст жирным. Оставляем это изменение и отменяем остальные.
word/settings.xml
Также не содержит ничего относящегося к жирному тексту. Отменяем.
7 Запаковываем папку с 1м изменением (добавлением ) и проверяем что документ открывается и показывает то, что ожидалось.
8 Коммитим изменение.
Пример 2. Нижний колонтитул
Теперь разберём пример посложнее — добавление нижнего колонтитула.
Вот первоначальный коммит. Добавляем нижний колонтитул с текстом 123 и распаковываем документ. Такой diff получается первоначально:
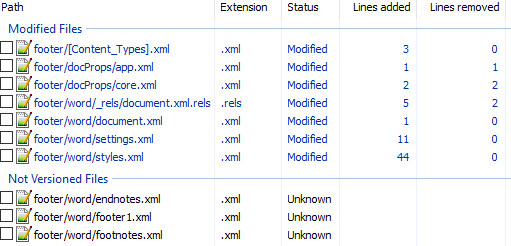
Сразу же исключаем изменения в docProps/app.xml и docProps/core.xml — там тоже самое, что и в первом примере.
[Content_Types].xml
footer явно выглядит как то, что нам нужно, но что делать с footnotes и endnotes? Являются ли они обязательными при добавлении нижнего колонтитула или их создали заодно? Ответить на этот вопрос не всегда просто, вот основные пути:
- Посмотреть, связаны ли изменения друг с другом
- Экспериментировать
- Ну а если совсем не понятно что происходит:

Идём пока что дальше.
word/_rels/document.xml.rels
Изначально diff выглядит вот так:
Видно, что часть изменений связана с тем, что Word изменил порядок связей, уберём их:
Опять появляются footer, footnotes, endnotes. Все они связаны с основным документом, перейдём к нему:
word/document.xml
Редкий случай когда есть только нужные изменения. Видна явная ссылка на footer из sectPr. А так как ссылок в документе на footnotes и endnotes нет, то можно предположить что они нам не понадобятся.
word/settings.xml
А вот и появились ссылки на footnotes, endnotes добавляющие их в документ.
word/styles.xml
Изменения в стилях нас интересуют только если мы ищем как поменять стиль. В данном случае это изменение можно убрать.
word/footer1.xml
Посмотрим теперь собственно на сам нижний колонтитул (часть пространств имён опущена для читабельности, но в документе они должны быть):
В результате анализа всех изменений делаем следующие предположения:
- footnotes и endnotes не нужны
- В [Content_Types].xml надо добавить footer
- В word/_rels/document.xml.rels надо добавить ссылку на footer
- В word/document.xml в тег надо добавить
Уменьшаем diff до этого набора изменений:

Затем запаковываем документ и открываем его.
Если всё сделано правильно, то документ откроется и в нём будет нижний колонтитул с текстом 123. А вот и итоговый коммит.
Таким образом процесс поиска изменений сводится к поиску минимального набора изменений, достаточного для достижения заданного результата.
Чем открыть DOCX на компьютере
Расскажем, как открыть расширение DOCX на компьютере, если не установлен редактор Microsoft Word.

В Windows 7
В Windows “зашит” один секрет - программа WordPad. Через меню Пуск найдите раздел «Все программы», затем «Стандартные». Вот так выглядит “родной” редактор:

В программе создается новый текст или редактируется существующий. По инструментарию этот редактор не уступает Word.
Общее описание формата DOCX
Формат DOCX – это обновленное расширение doc, которое появилось в первом редакторе Microsoft Word. В программе доступны инструменты форматирования текста, стили и работа с изображениями. Информация о документе хранится в сжатом архиве XML. Папки docProps, Word и _rels определяют свойства источника и соотношение файлов.
Открыть онлайн
Можно открыть файл DOC онлайн на сервисе Word Online. Доступны все функции текстового процессора:
- управление стилями с различными размерами и цветами шрифта, цветами фона;
- работа с таблицами и изображениями;
- поиск и замена функций с помощью специальных символов.
Второй способ открыть файл DOC онлайн - Google Docs. Редактируйте файл вместе с коллегами, общайтесь через встроенный чат, контролируйте доступ к файлу. Документ конвертируется, при этом исходный файл останется без изменений.

История возникновения
Первое издание Microsoft Word в составе блока Microsoft Office появилось в 1983 году. Разработчиком выступил Ричард Броди, который до этого работал в компании «Xerox PARC» над графическим редактором Bravo.
Признание пользователей программа получила в 1985 году в пакете «Word 3.01 для Macintosh». Тогда компании постепенно отказались от конкурентов WordPerfect и WordStar, которые работали с комбинациями “горячих клавиш”.
С 1990 по 1995 год Microsoft Word заняла лидерскую позицию, добавляя новые “фишки”: введение дополнительных объектов, графические инструменты, разнообразие стилей и шрифтов.

Последнее обновление редактора вышло в 2018 году.
Какие еще могут быть проблемы с DOCX файлом
Если DOCX файл некорректно отображает части текста или символы, причина в повреждении документа.
Сегодня документооборот компаний и предприятий в основном ведется в электронном виде. Для этого испо.
Сегодня документооборот компаний и предприятий в основном ведется в электронном виде. Для этого используется текстовый процессор Microsoft Word. В статье мы рассмотрим главные признаки текстового формата, узнаем, как открыть файл DOC и где скачать программу для открытия файлов DOC.

В Windows 7
Посмотрим, чем открыть формат DOC на 7-й Виндовс.
Программа Doc Viewer 2.0 подходит только для просмотра текстового документа, режим редактирования недоступен. Включена опция передачи файлов по электронке.
Структура docx
Для начала разоберёмся с тем, что собой представляет docx документ. docx это zip архив который физически содержит 2 типа файлов:
- xml файлы с расширениями xml и rels
- медиа файлы (изображения и т.п.)
А логически — 3 вида элементов:
- Типы (Content Types) — список типов медиа файлов (например png) встречающихся в документе и типов частей документов (например документ, верхний колонтитул).
- Части (Parts) — отдельные части документа, для нашего документа это document.xml, сюда входят как xml документы так и медиа файлы.
- Связи (Relationships) идентифицируют части документа для ссылок (например связь между разделом документа и колонтитулом), а также тут определены внешние части (например гиперссылки).
Они подробно описаны в стандарте ECMA-376: Office Open XML File Formats, основная часть которого — PDF документ на 5000 страниц, и ещё 2000 страниц бонусного контента.
Минимальный docx
Простейший docx после распаковки выглядит следующим образом
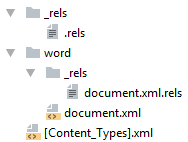
Давайте посмотрим из чего он состоит.
[Content_Types].xml
Находится в корне документа и перечисляет MIME типы содержимого документа:
_rels/.rels
Главный список связей документа. В данном случае определена всего одна связь — сопоставление с идентификатором rId1 и файлом word/document.xml — основным телом документа.
word/document.xml
Если открыть этот документ в текстовом редакторе, то увидим документ из одного слова Test .
word/_rels/document.xml.rels
Здесь содержится список связей части word/document.xml . Название файла связей создаётся из названия части документа к которой он относится и добавления к нему расширения rels . Папка с файлом связей называется _rels и находится на том же уровне, что и часть к которой он относится. Так как связей в word/document.xml никаких нет то и в файле пусто:
Даже если связей нет, этот файл должен существовать.
В Windows 10
- Бесплатный русскоязычный редактор Apache Open Office – альтернатива пакету Microsoft Word. Работает с таблицами, рисунками, формулами, презентациями.
- Следующий инструмент, чем открыть DOC на Виндоус 10 – портативная программа Doc Reader. Функционала недостаточно для полноценной работы с текстом, однако хватит для срочных задач: просмотреть или распечатать документ, скопировать часть текста.
Читайте также: