
Htaccess закрыть файл от индексации
Facebook Если у вас не работает этот способ авторизации, сконвертируйте свой аккаунт по ссылке ВКонтакте Google RAMBLER&Co ID
Авторизуясь в LiveJournal с помощью стороннего сервиса вы принимаете условия Пользовательского соглашения LiveJournal
Закрыть сайт от индексации в файле .htaccess
Как закрыть от индексации страницу на сайте
- 1 Вариант - в robots.txt
- 2 Вариант - закрыть страницу в метегах - это наиболее правильный вариант
- 3 Вариант - запретить индексацию через ответ сервера
Задача, чтобы ответ сервера для поисковых систем был
404 - ошибка страницы
410 - страница удаленна
Добавить в файл .htaccess:
это серый метод, использовать в крайних мерах
Закрытие сайта от бота Google
Принцип построения команды тот же. Только меняется название бота:
Usеr-аgеnt: GооgІеbоt
При проверке используется тот же прием, что и для «Яндекса». На панели инструментов Google Search Console должны появиться надпись «Заблокировано по строке» напротив соответствующей ссылки и команда, запрещающая ботам индексацию сайта. Но велика вероятность получить ответ «Разрешено», который говорит о вашей ошибке или о том, что поисковик разрешил индексацию страниц, для которых в robots прописан запрет. Как уже упоминалось выше, поисковые роботы воспринимают содержимое этого файла не как руководство к действию, а как набор рекомендаций, поэтому они оставляют за собой право решать, индексировать сайт или нет.
Пять вариантов закрыть дубли на сайте от индексации Яндекс и Google
1 Вариант - и самый правильный, чтобы их не было - нужно физически от них избавиться т.е при любой ситуации кроме оригинальной страницы - должна показываться 404 ответ сервера
2 Вариант - использовать Атрибут rel="canonical" - он и является самым верным. Так как помимо того, что не позволяет индексироваться дублям, так еще и передает вес с дублей на оригиналы
Ну странице дубля к коде необходимо указать
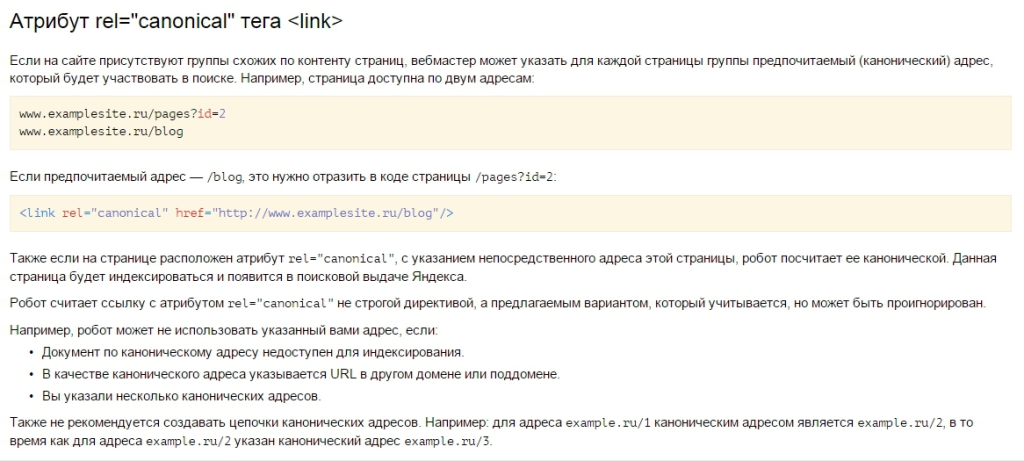
3 Вариант избавиться от индексации дублей - это все дублирующие страницы склеить с оригиналами 301 редиректом через файл .htaccess
4 Вариант - метатеги на каждой странице дублей
5 Вариант - все тот же robots
Если что то упустили, будем рады любым дополнениям в комментариях.
Здравствуй, %habrauser%.
Сегодня я покажу как не надо закрывать от индексации зеркало сайта, и как закрыть его правильно.
Предыстория
Началась «оптимизация»
Всё началось с того, что они не разобрались в движке сайта PHPShop.
Отправили нам письмо, мы им сообщили где что редактируется, в каком файле находятся нужные им теги, а так же в довесок дали немного ссылок на официальную документацию.
Сам сайт устроен так, что скелет вёрстки главной страницы находится в файле index.tpl, а html-скелет остальных внутренних страниц находится в файле shop.tpl. Сам же контент находится в базе данных и редактируется через админку с помощью визуального редактора, либо в виде source html.
Сеошники поправили верстку как им было необходимо, но на главной странице они захотели воткнуть свой копирайт-рекламу.
В договоре, кстати, указано что убирать эту индексируемую ссылку на их сайт нельзя.
Горе-оптимизаторы так и не разобравшись в элементарной админке, напичкали сайт своими скриптами костылями, которые мешали нормальной работе фреймворка и шли в разрез со здравым смыслом. Самое безобидное — сделали статичную версию главной, и положили этот статичный index.html рядом с index.php.
Далее, через свои скрипты, сделали переадресацию с index.php на index.html
Зачем? Закрывая глаза на то, что всё редактируется через админку, можно же через htaccess и mod_rewrite сделать такую переадресацию на уровне веб-сервера написав несколько строк, и не подключать mod_php для вывода 301 заголовка.
Выяснился этот сюрприз оставленный сеошниками через месяц, когда клиент захотел поменять на главной информацию, и обратился к нам.
Я всё делаю по т.з., сохраняю, и начинаю медленно сходить с ума.
Полез в базу — информация новая. Полез ковыряться в движке, и дебаг показывает что информация выдаётся правильно. Захожу по ftp, и нахожу 4 незнакомых скрипта в корне сайта, в названии которых есть наименование seo-компании.
Поправляю за ними косяк, переношу проделанную ими работу из статичного index.html в базу данных движка.
«Нам сюрпризов не жалко»
Еще через пару недель выясняется новый косяк. Именно тот, о котором данный тред.
Клиент звонит и злостно говорит что мы опять что-то натворили на сайте, и ничего не работает. Мы в недоумении начинаем опять разбираться в проблеме.
Заходим на главную страницу зеркала в зоне РФ, и видим ошибку 404.
Снова начинаем немного удивляться умению добавить людям работы на ровном месте, и задаваться вопросом «как?».
Заходим на основной домен в зоне.ру (они его и продвигают) — всё нормально.
Опять лезу ковыряться в коде горе-оптимизаторов.
И… Нахожу следующий код:
Доменные имена специально не раскрываю, а так же умолчу какая именно seo компания так извращается
Как мы видим, они не захотели что бы зеркало попадало в индекс Яндекса, и сделали зверский костыль.
Сношу их индусский код, и делаю следующее:
Создаю файл robots.php, и пишу туда следующее:
Пол дела сделано, теперь удаляем robots.txt, и в файл .htaccess добавляем такие строки (обязательное условие apache+mod_rewrite):
UPD: конвертированное правило для nginx Лично не проверял, но должно работать.
Если что напишите в коммент — поправлю
Всё! Когда роботы запрашивает robots.txt, сервер отдаёт им файл robots.php
P.S. Надеюсь если кто-то использует подобные кривые способы закрытия зеркала, добавит это к себе в «копилку» скриптов для оптимизации.
P.P.S. Так уж сложилось, что в настоящее время профессиональных seo компаний очень мало, и получается вечное противостояние «сеошники VS разработчики», одни делают сайт, другие ломают его функциональность за счёт кривых рук и непонимания.
P.P.P.S. Если кому то интересно, всё таки могу указать ссылочку на ту seo-конторку
Спасибо за внимание!
UPD: Очередной случай. Полезли что-то делать, поехала вёрстка. Уже надоело за свой счёт и время поправлять их косяки
Задача: закрыть от индексации поддомен
Поддомен для поисковых систем является отдельным сайтом, из чего следует, что для него подходят все варианты того, как закрыть от индексации сайт.
Что именно мы прописали в .htaccess для запрета?
Попробую расшифровать написанное на примере Google
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase – это мы задаем условия для переменной env
User-Agent – означает какая именно переменная, в данном случае это имя агента или бота поисковой машины
"^Googlebot" собственно это имя этого агента
А search_bot – это значение переменной
Другими словами (по русски) строчка
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
Значит: если на сайт придет бот у которого в имени будет содержаться слово Googlebot, то такому боту задать значение переменной env= search_bot (пометить его как search_bot)
Запрет других ботов в .htaccess
Вот список других ботов которые могут вас навестить:
SetEnvIfNoCase User-Agent "^Aport" search_bot
SetEnvIfNoCase User-Agent "^msnbot" search_bot
SetEnvIfNoCase User-Agent "^spider" search_bot
SetEnvIfNoCase User-Agent "^Robot" search_bot
SetEnvIfNoCase User-Agent "^php" search_bot
SetEnvIfNoCase User-Agent "^Mail" search_bot
SetEnvIfNoCase User-Agent "^bot" search_bot
SetEnvIfNoCase User-Agent "^igdeSpyder" search_bot
SetEnvIfNoCase User-Agent "^Snapbot" search_bot
SetEnvIfNoCase User-Agent "^WordPress" search_bot
SetEnvIfNoCase User-Agent "^BlogPulseLive" search_bot
SetEnvIfNoCase User-Agent "^Parser" search_bot
Задаем правило для запрета в .htaccess
Вот само правило:
Deny from env=search_bot
в строке Order Allow,Deny
Мы указываем порядок доступа, у нас сказано сначала разрешить, а потом запретить
Allow from all – разрешить всем
Deny from env=search_bot – запретить доступ тем, кто помечен флажком search_bot, в данном случае это боты, которые мы перечисляли выше
Нужно заметить что такое правило запрещает доступ этим ботам на весь сайт, если мы хотим запретить в .htaccess только определенный файл или группу файлов нужно их уточнить, делается это так:
Deny from env=search_bot
То есть все тоже самое, но мы ограничиваем область запрета в FilesMatch
"^.*$" эта комбинация также значит любой файл (^ - начало строки, точка – это любой символ, звезда – любое количество этого символа, то есть сочетание (.*) значит любая комбинация любых символов, а $ - это конец строки). Поэтому такой комбинацией мы запрещаем в .htaccess доступ к любому файлу.
-тут мы запрещаем доступ только к файлу primer.html
- запрет к любому файлу, содержащему слово primer
2-й способ – Изменение файла robots.txt
Примеры запрета в .htaccess для ботов
Запрет на любой файл для ботов:
SetEnvIfNoCase User-Agent "^Yandex" search_bot
SetEnvIfNoCase User-Agent "^Yahoo" search_bot
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase User-Agent "^Aport" search_bot
SetEnvIfNoCase User-Agent "^msnbot" search_bot
SetEnvIfNoCase User-Agent "^spider" search_bot
SetEnvIfNoCase User-Agent "^Robot" search_bot
SetEnvIfNoCase User-Agent "^php" search_bot
SetEnvIfNoCase User-Agent "^Mail" search_bot
SetEnvIfNoCase User-Agent "^bot" search_bot
SetEnvIfNoCase User-Agent "^igdeSpyder" search_bot
SetEnvIfNoCase User-Agent "^Snapbot" search_bot
SetEnvIfNoCase User-Agent "^WordPress" search_bot
SetEnvIfNoCase User-Agent "^BlogPulseLive" search_bot
SetEnvIfNoCase User-Agent "^Parser" search_bot
Deny from env=search_bot
Запрет на файл primer.html для трех основных поисковиков Google, Yandex и Yahoo
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase User-Agent "^Yandex" search_bot
SetEnvIfNoCase User-Agent "^Yahoo" search_bot
Deny from env=search_bot
Надеюсь вам пригодиться данная информация, у меня ушло очень много времени, чтобы разобрать как запрещать доступ к файлам через переменную в .htaccess

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

- Нужно скрыть от общего доступа какую то секретную информацию.
- В целях создания релевантного контента: бывают случаи, когда хочется донести до пользователей больше информации, но она размывает текстовую релевантность.
- Закрыть дублированный контент.
- Скрыть мусорную информацию: поисковые системы очень не любят контент, который не несет или имеет устаревший смысл, например, календарь в афише.
Вся статья будет неким хелпом по закрытию от индексации для различных ситуаций:
Блокировка картинок
Для запрета индексации изображений в зависимости от их формата прописываются такие команды:
DіsаІІоw: *.jрg (*.gіf или *.рng)
Решение: запрет на индексацию сайта с помощью robots.txt
Создаем текстовый файл с названием robots, получаем robots.txt.
Копируем туда этот код
Полученный файл с помощью FTP заливаем в корень сайта.
Если нужно закрыть индексацию сайта только от Яндекс:
Если же скрываем сайт только от Google, то код такой:
4-й способ – Прописывание кода в настройках сервера
Веб-мастера выбирают этот вариант запрета индексации, когда боты не реагируют на другие действия. Если такое происходит, для решения проблемы можно прописать в файле .htaccess на сервере такую команду:
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
Она заблокирует доступ для бота Google. Дальше нужно повторить операцию и прописать такие же строки для других поисковиков, но с названиями их ботов: Yаndех, msnbоt, MаіІ, Yаhоо, Rоbоt, Snарbоt, Раrsеr, WоrdРrеss, рhр, ВІоgPuІsеLіvе, bоt, Ароrt, іgdеSрydеr и sріdеr. Всего должно получиться 15 команд.
Запрет с помощью .htaccess
Для осуществления данного действия нужно чтобы у вас в корневой папке домена находился файл .htaccess.
Если у вас такой файл есть - а его особенность – отсутсвие имени и наличние только расширения, то есть (точка)htaccess, то можно просто внести в него изменения. Если такого файла нет, то его очень просто сделать: нужно в блокноте создать файлик htaccess.txt , и переименовать в .htaccess.
Кстати в проводнике windows с этим могут быть проблемы.
Когда вы убедились, что файлик .htaccess есть, в него просто нужно дописать следующие строки:
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase User-Agent "^Yandex" search_bot
SetEnvIfNoCase User-Agent "^Yahoo" search_bot
Вышеописанные строки для трех основных поисковиков Google, Yandex и Yahoo.
Способ второй и третий
- Ответ сервера - 403 Доступ к ресурсу запрещен -код 403 Forbidden
- Ответ сервера - 410 Ресурс недоступен - окончательно удален
3-й способ – Использование специального мета-тега name=”robots”
Этот способ закрытия сайта или его отдельных элементов от поисковых роботов считается одним из лучших. Он заключается в прописывании с тегами
и такого кода:Место размещения кода значения не имеет.
Полное закрытие для всех поисковиков
С этой целью прописываем в роботс такие строки:
Как закрыть от индексации страницу сайта с помощью Meta тегов
Проверка индексирования сайта и отдельных страниц
Чтобы определить, индексируется сайт (страница, отдельный материал) в поисковике или нет, можно использовать один из таких четырех способов.
- Через панель инструментов «Вебмастера». Это самый популярный вариант. Находим в меню раздел индексирования сайта и проверяем, какие страницы попали в поиск.
- С использованием операторов поисковиков. Если указать команду «site: url сайта» в строке поиска Google или «Яндекса», можно определить, какое примерное количество страниц попало в индекс.
- При помощи расширений и плагинов. Можно провести автоматическую проверку индексирования через специальные приложения. Лидер по популярности среди таких плагинов – RDS bar.
- Посредством специальных сторонних сервисов. Они наглядно демонстрируют, что попало в индекс, а каких страниц там нет. Есть и платные, и бесплатные варианты таких инструментов.
Закрыть сайт или часть кода от индексации htaccess robots.txt

Закрыть сайт или часть кода от индексации htaccess robots.txt
Иногда, по тем или иным причинам нужно скрыть от поисковых систем часть кода, блок или целый сайт (к примеру, старый).
Файл robots.txt - специальный файл, содержащий инструкции для поисковых систем. Обычно, файл robots.txt уже присутствует в корневой папке сайта на хостинге. Однако, если его нет, нужно создать обычный текстовый документ с именем robots.txt, внести в него необходимые инструкции и загрузить в корневую папку сайта.
Файл .htaccess - специальный файл конфигурации веб-сервера Apache, управляет настройками сайта и работой веб-сервера. Файл .htaccess также должен присутствовать в корневой папке сайта по умолчанию.
Как закрыть от индексации с помощью файла robots.txt
Полностью запретить индексацию всего сайта:
User-agent: *
Disallow: /
Запретить индексацию всего сайта только Гуглу:
User-agent: Googlebot
Disallow: /
Запретить индексацию всего сайта только Яндексу:
User-agent: Yandex
Disallow: /
Запретить индексацию всего раздела:
User-agent: *
Disallow: /administrator
Disallow: /plugins
*В этом варианте запрет коснется всех файлов и папок в разделе.
Запретить индексацию отдельной папки:
User-agent: *
Disallow: /administrator/
Disallow: /images/
*В этом варианте запрет коснется только файлов и документов, но не будет распространяться на имеющиеся папки.
Запретить индексацию отдельным страницам:
User-agent: *
Disallow: /reklama.html
Disallow: /sis-pisi.html
Как закрыть от индексации ссылку
К ссылке нужно добавить rel="nofollow" и получится:
Запрещают индексацию ссылки обычно для того, чтобы не передавать вес своего сайта
Довольно часто возникает необходимость в запрете на включение ресурса в индекс поисковиков, например, когда он разрабатывается и есть риск индексирования информации, которую не хотелось бы разглашать, а также во многих других случаях. Рассмотрим, как закрыть свой сайт от индексации всеми доступными способами.

Как закрыть сайт от индексации
Задача: закрыть внешние или внутренние ссылки от индексации
Обычно это делают для того, чтобы не передавать вес другим сайтам или при перелинковке уменьшить уходящий вес текущей страницы.
Создаем файл transfers.js
Эту часть кода вставляем в transfers.js
Этот файл, размещаем в соответствующей папке (как в примере "js") и на странице в head вставляем код:
А это и есть сама ссылка, которую нужно скрыть от индексации:
Способ четвертый
Запретить индексацию с помощью доступа к сайту только по паролю
В файл .htaccess, добавляем такой код:
Авторизацию уже увидите, но она пока еще не работает
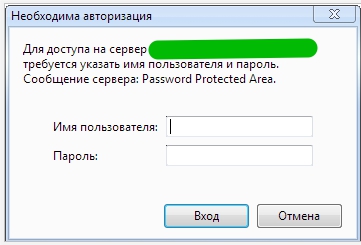
Теперь необходимо добавить пользователя в файл паролей:
USERNAME это имя пользователя для авторизации. Укажите свой вариант.
Подведем итоги
Независимо от причины, по которой поисковым роботам закрывается доступ к ресурсу в целом, определенным страницам или материалам, можно использовать любой из описанных выше способов блокировки. Их несложно реализовать, и для этого не требуется большое количество времени. Вам вполне под силу самостоятельно скрыть от поисковых ботов определенную информацию, но следует помнить, что не каждый из методов дает 100-процентный результат.
Блокировка индексирования «Яндексом»
В первой строке меняем «*» на название бота поисковика:
Usеr-аgеnt: Yаndех
Запрет индексации другими поисковыми системами
У каждого поисковика свои боты с оригинальными именами, что позволяет веб-мастерам прописывать для них персональные команды в robots.txt. О «Яндексе» и Google мы уже писали. Вот еще три робота популярных поисковиков:
Причины для запрета индексирования
Интернет-ресурсы скрывают от поисковых роботов в разных ситуациях, но чаще всего эта процедура проводится по одной из таких причин.
- При создании сайта. Допустим, вы на начальном этапе разработки и наполнения своей площадки контентом, меняете навигацию, интерфейс и других параметры. Как только начинается работа над сайтом, он и его наполнение еще не соответствуют всем вашим ожиданиям. Поэтому до окончательной доработки стоит скрыть свой ресурс от просмотра Google и «Яндексом», чтобы не индексировать неполноценные страницы. Не стоит рассчитывать на то, что ваш новый сайт, по которому еще не отправлены ссылки для индексирования, не обнаружат поисковики. Их роботы не только учитывают ссылки, но и смотрят на посещения сайта в браузере.
- Когда веб-ресурс копируется. В некоторых случаях у разработчиков возникает необходимость в дублировании сайта, например, для тестирования на втором экземпляре доработок. И стоит сделать так, чтобы этот дубликат не индексировался. Иначе может пострадать оригинальный проект, и поисковики будут введены в заблуждение.
5-й способ – Использование X-Robots-Tag
В этом случае также настраивается блокировка через .htaccess, но при этом меняется заголовок НТТР X-Robots-Tag, который дает поисковикам указания, для понимания которых не нужно загружать сам документ. Такие инструкции авторитетнее, так как не нужно тратить ресурсы на изучение содержимого. Кроме того, этот метод подходит для любых видов контента.
Он используется с такими же директивами, как и Meta Robots: nоnе, nоіndех, nоаrсhіvе, nоfоІІоw и т. д. Есть два способа применения X-Robots-Tag. Первый – при помощи РНР, а второй – через настройку файла .htaccess.
Запрет индексации с помощью .htaccess
Главной особенностью было то, что запрет на индексацию нужно было сделать не через прописывание запрета в robots.txt, а с помощью файла .htaccess.
Нужно это было для того, чтобы никто кроме меня не знал, что я запретил.
Как закрыть от индексации сразу весь раздел на проекте
1 Вариант реализовать это с помощь robots.txt
Также подойдут варианты, которые используются при скрытии страницы от индекса, только в данном случае это должно распространятся на все страницы раздела - конечно же если это позволяет сделать автоматически
- Ответ сервера для всех страниц раздела
- Вариант с метатегами к каждой странице
Это все можно реализовать программно, а не в ручную прописывать к каждой странице - трудозатраты - одинаковые.
Конечно же проще всего это прописать запрет в robots, но наша практика показывает, что это не 100% вариант и поисковые системы бывает игнорируют запреты.
Способы закрытия индексации
Для решения этой задачи используются такие основные технологии:
Закрытие поддомена
В этом случае нужно учитывать один важный нюанс. У каждого поддомена свой файл robots.txt, находящийся, как правило, в его корневой папке. В нем нужно прописать стандартную команду блокировки:
При отсутствии такого документа его необходимо создать.
Как закрыть от индексации с помощью файла .htaccess
Полностью запретить индексацию всего сайта:
SetEnvIfNoCase User-Agent "^Googlebot" search_bot
SetEnvIfNoCase User-Agent "^Yandex" search_bot
SetEnvIfNoCase User-Agent "^Yahoo" search_bot
SetEnvIfNoCase User-Agent "^Aport" search_bot
SetEnvIfNoCase User-Agent "^msnbot" search_bot
SetEnvIfNoCase User-Agent "^spider" search_bot
SetEnvIfNoCase User-Agent "^Robot" search_bot
SetEnvIfNoCase User-Agent "^php" search_bot
SetEnvIfNoCase User-Agent "^Mail" search_bot
SetEnvIfNoCase User-Agent "^bot" search_bot
SetEnvIfNoCase User-Agent "^igdeSpyder" search_bot
SetEnvIfNoCase User-Agent "^Snapbot" search_bot
SetEnvIfNoCase User-Agent "^WordPress" search_bot
SetEnvIfNoCase User-Agent "^BlogPulseLive" search_bot
SetEnvIfNoCase User-Agent "^Parser" search_bot
*Для каждой поисковой системы отдельная строчка кода.
Универсальный вариант скрытия картинок от индексации
К примеру, вы используете на сайте картинки, но они не являются оригинальными. Есть страх, что поисковые системы воспримут их негативно.
Код элемента, в данном случае ссылки, на странице, будет такой:
Скрипт, который будет обрабатывать элемент:
Отключение индексации одной папки
В команде дополнительно указываем ее название:
DіsаІІоw: /fоІdеr/
Этот способ позволяет полностью скрыть файлы, размещенные в определенной папке.
Способ первый
В файл .htaccess вписываем следующий код:
Каждая строчка для отдельной поисковой системы
1-й способ – Запрет на индексирование через WordPress
Для сайтов, созданных на базе этой системы, есть такой быстрый и несложный алгоритм действий для закрытия от роботов.
- В «Панели управления» находим пункт меню «Настройки».
- Заходим в раздел «Чтение».
- Здесь в пункте «Видимость для поисковых систем» ставим галочку возле надписи о рекомендации роботам не проводить индексацию.
- Сохраняем изменения.
В ответ на эти действия происходит автоматическое изменение файла robots.txt, корректируются правила, и таким образом отключается индексирование. При этом поисковая система оставляет за собой право решить, отключить робота или нет, даже несмотря на решение разработчика сайта. Опыт показывает, что от «Яндекса» можно не ждать таких решений, а Google иногда продолжает индексацию.
Закрываем блок на сайте от индекса
Довольно часто требуется закрыть от индексации определенный блок: меню, счетчик, текст или какой-нибудь код.
Когда был популярен в основном Яндекс, а Google все само как то в топ выходило, все использовали вариант Тег "noindex"
Но потом Яндекс все чаще и чаще стал не обращать внимания на такой технический прием, а Google вообще не понимает такой комбинации и все стали использовать другую схему для скрытия от индексации части текста на странице - с помощью javascript:
Текст или любой блок - кодируется в javascript , а потом сам скрипт закрывается от индексации в robots.txt
Как это реализовать?
- Файл BASE64.js для декодирования того, что нужно скрыть.
- Алгоритм SEOhide.js.
- Jquery.
- Robots.txt (чтобы скрыть от индексации сам файл SEOhide.js)
- HTML код
BASE64.js. Здесь я его приводить не буду, в данном контексте он нам не так интересен.
Переменные seoContent и seoHrefs. В одну записываем html код, в другую ссылки.
- de96dd3df7c0a4db1f8d5612546acdbb — это идентификатор, по которому будет осуществляться замена.
- 0JHQu9C+0LMgU0VPINC80LDRgNC60LXRgtC+0LvQvtCz0LAgLSDQn9Cw0LLQu9CwINCc0LDQu9GM0YbQtdCy0LAu— html, который будет отображаться для объявленного идентификатора.
И сам HTML файл:
В robots.txt обязательно скрываем от индексации файл SEOhide.js.
Закрываем папку от индексации
В данном случае под папкой имеется ввиду не раздел,а именно папка в которой находят файлы, которые стоит скрыть от поисковых систем - это или картинки или документы
Единственный вариант для отдельной папки это реализация через robots.txt
Читайте также: