
Hibernate framework что это
Ни за что бы не сделал, если бы не комментарии. Спасибо всем. Мало того, что в самой статье иногда сразу через 2 шага прыжки плюс многое не объяснено, так пришлось и код подправлять, чтобы некоторые запросы работали. Это я как новичок пишу, для которого и написана эта статья. Основное, что мне помогло, собрал из комментов, еще раз спасибо. - чтобы создать таблицу в Idea, нужно развернуть сначала базу в окне справа до схемы, далее по ней пкм -. dependencies in pom.xml: и hibernate.cfg.xml взял у bulkin ниже, меняем пароль, и, при необходимости, название БД - Во всех методах класса UserDao закрывайте сессию - @OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.EAGER) так должна выглядеть соответствующая аннотация. Что там такое в конце, не знаю, но помогло при определенных запросах Многое осталось непонятно, подробных объяснений, как что работает, повторюсь, нет Удачи!
dependencies in pom.xml: hibernate.cfg.xml надо создавать в папке 'src/main/resources' вот его configuration:
У меня у одного возник вопрос по работе mappedBy? Если кто-то не понял что это за аннотация. Кратко: Эта аннотация связывает сущности (Entity) между собой по BI-directional (двунаправленной) связи. Подробно: У нас есть уровень БД, где находятся таблицы, например, User и Auto, которые соединены например OneToMany, т.е. внешний ключ находится в Auto, а User ничего не знает об Auto. Также у нас есть уровень JPA/Hibernate со своими Entity, это более абстрактный уровень, в нем больше возможностей. Обычно сразу между Entity User и Auto образуется такое же отношение, как и в БД между таблицами User и Auto, т.е. UNI-directional (однонаправленная связь). И вот мы хотим, чтобы сущности эти знали друг о друге, в отличие от таблиц в БД. Именно в этом случае в сущности User нужно создать доп. поле List. (Напомню, при однонаправленной связи данного поля быть не должно.) Но на основании чего? По каким правилам Hibernate поймет что сюда нужно положить всех Auto данного User. Отвечает за это аннотация @mappedBy, она говорит хиберу, где нужно взять эту информацию, где прописано это отношение между таблицами, чтобы его использовать для выгрузки всех Auto. Очевидно, что это отношение прописано в поле user в сущности Auto, это отношение пришло с уровня БД. Вот мы на него и указали. Теперь, при обращении к List хибернейт поймет где находится эти правила (где находится владелец отношения) и вытащит все Auto.
А на какой строке кода класса Main добавляются записи в autos? Я в точности скопировал код, в users все добавилось, а вот autos так и осталось пустая, хотя физически эти 2 объекта создаются (проверял выводом в консоль).
А я ваще в шоке. Для эксперимента занялся копи-пастем и в шоке. Идея отказывется верить в то, что User в классе Models может существовать без импорта класса. @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "user_id") private User user; public Auto() < >Вот тут и ругается, где выделил.
Вопрос автору, если он еще читает комменты :) Вы используете Session. В доке в Hibernate + JPA примеры даются с EntityManager. В реальных проектах что используют? Session или EntityManager?
нах писать "для новичков которые ничего не знают" если тут даже банально не написано ни как правильно установить постгрес, ни как настроить, ни как таблицы создавать, ничего вообще. Для новичков которые хорошо знают SQL видимо, откуда то Hibernate.cfg.xml пришлось писать вручную, зависимости пришлось искать в репозитории, как че половина работает непонятно, в общем информативности мало
При создании таблиц users и autos в графе default что писать? Я так понял показано не всё, у меня идея горит красным
Я сталкивался (да и не только я) с проблемой развертывания Hibernate и решил попробовать осветить данную тему. Hibernate — это популярный framework, цель которого связать ООП и реляционную базу данных. Работа с Hibernate сократит время разработки проекта в сравнении с обычным jdbc.
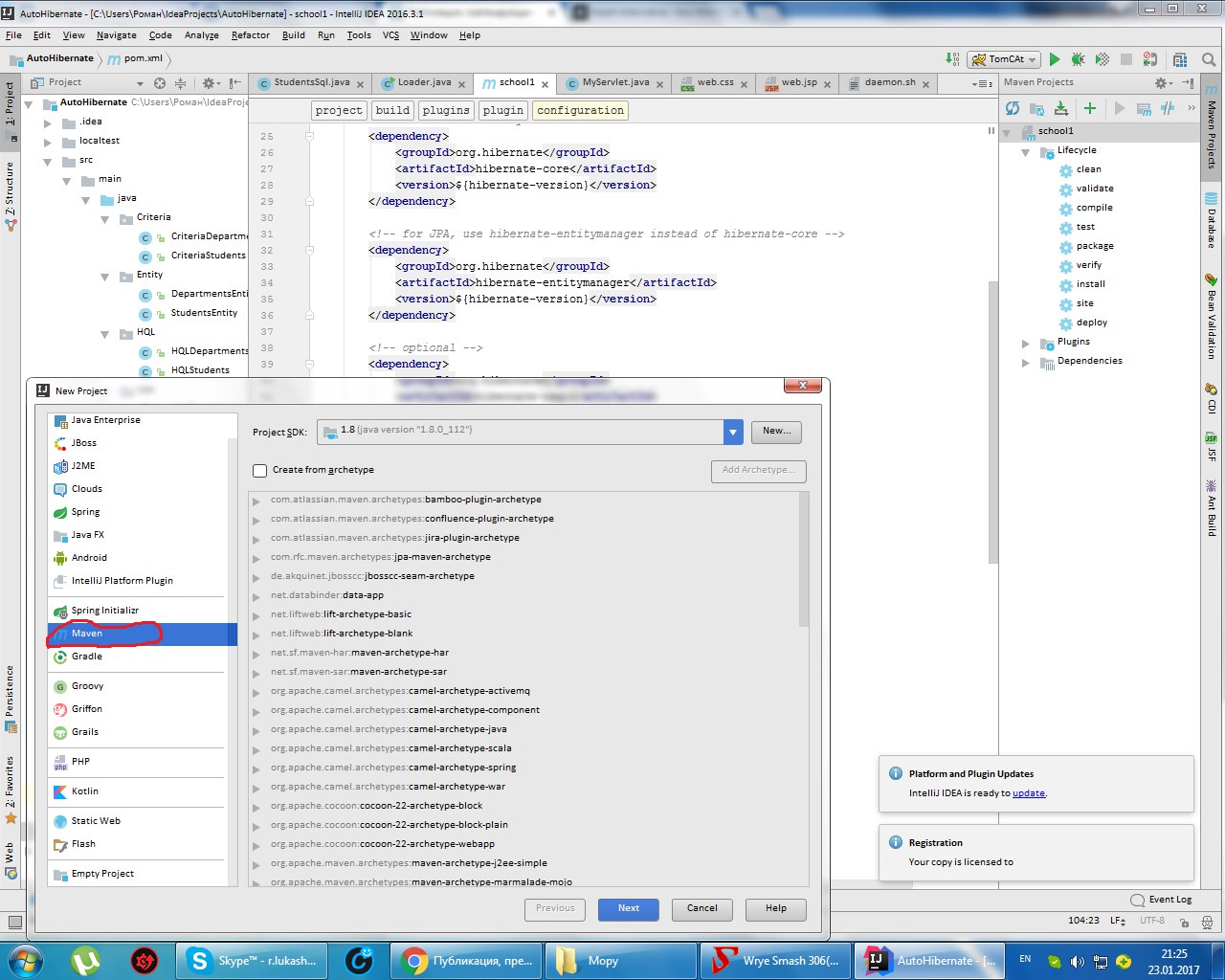
Потом в pom.xml вставляем. Нам понадобятся две зависимости: hibernate-core и mysql-connector, но если вы хотите больше функционала — вы должны подключить больше зависимостей.
Существуют стандартные рекомендации подключать зависимости по отдельности, но я так не делаю.
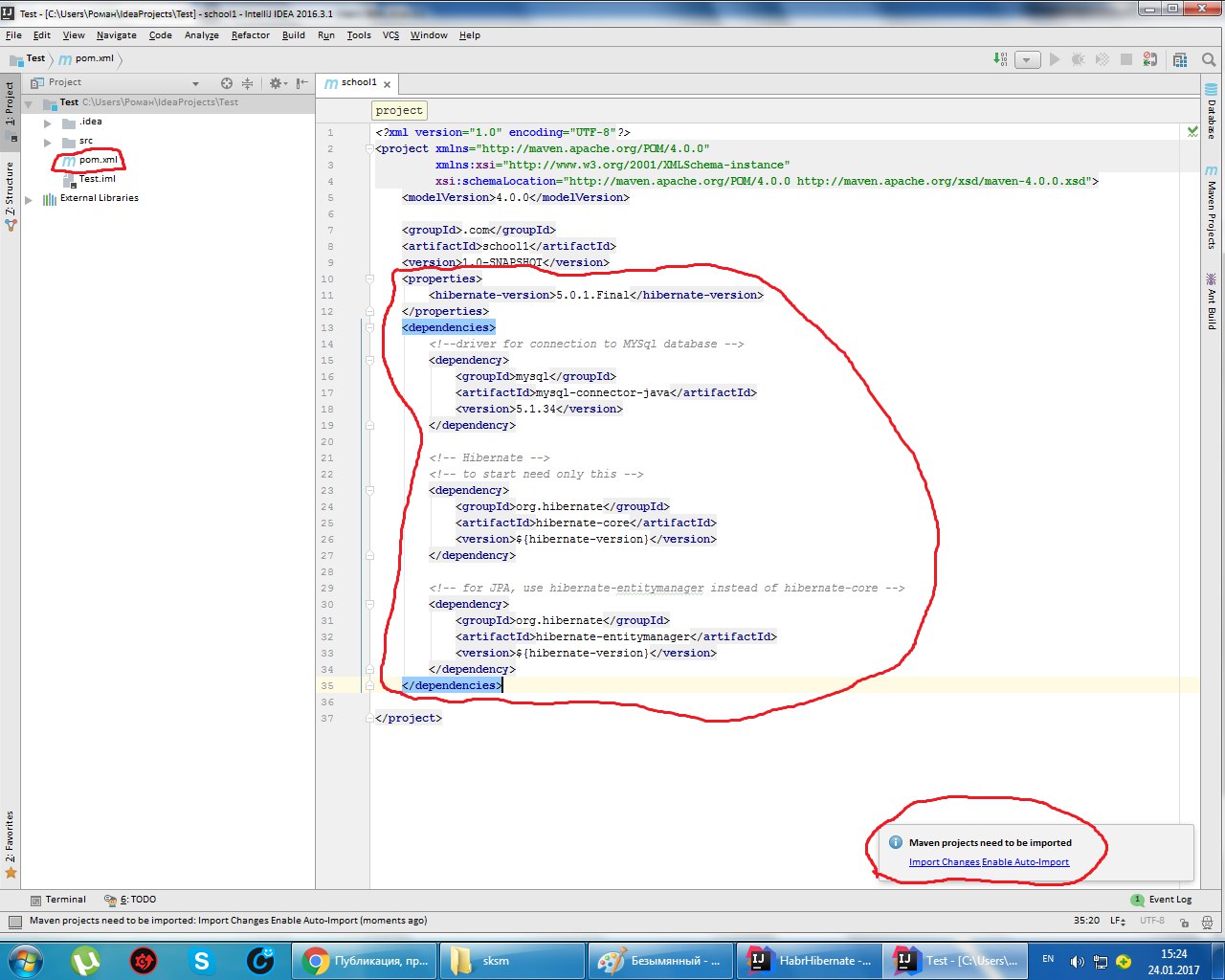
И щелкаем на Import Changes Enable Auto-Import, автоматически импортируя изменения.
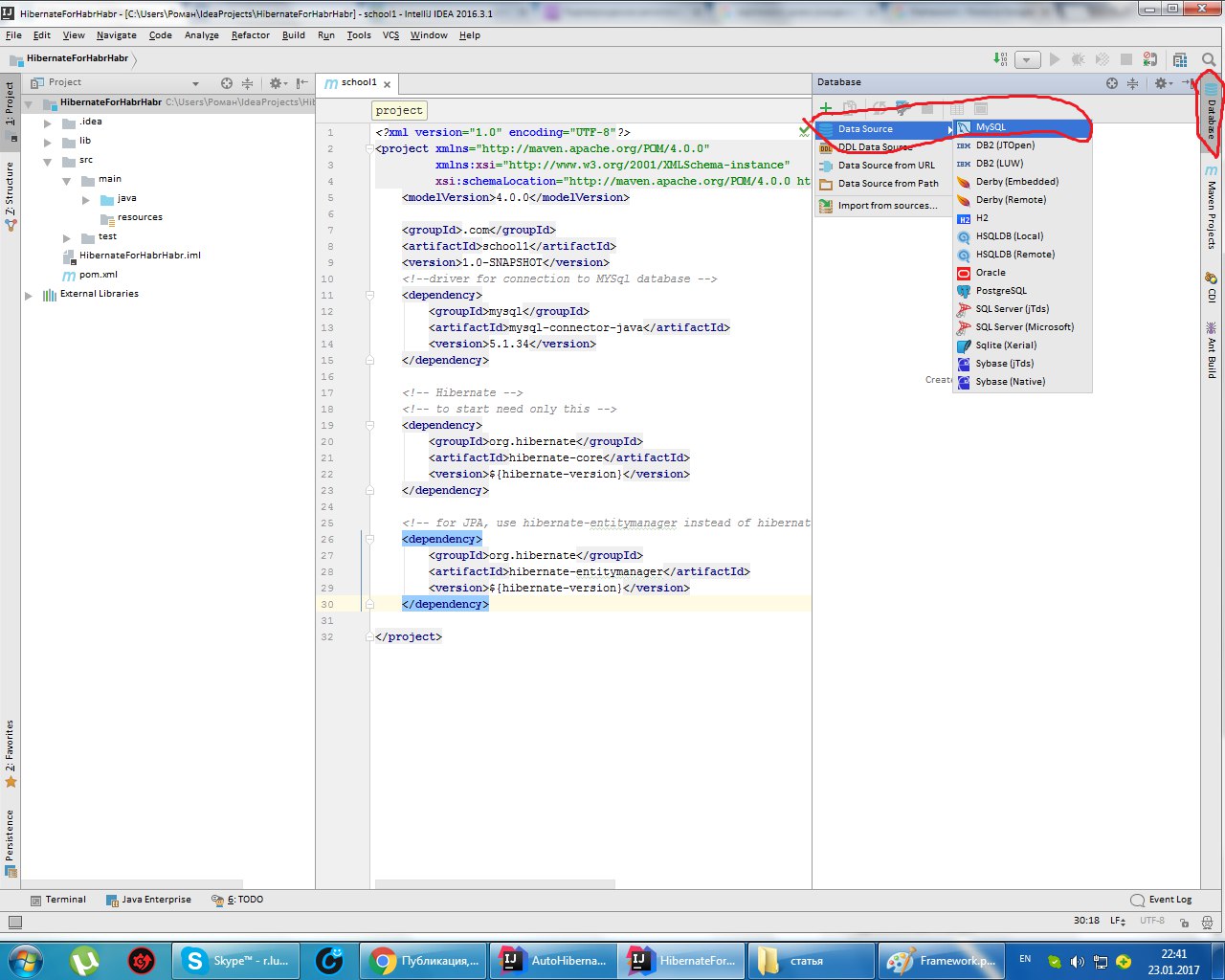
Подключаемся к базе данных, которая развернута на локальном компьютере, выбираем поставщика баз данных MySQL.
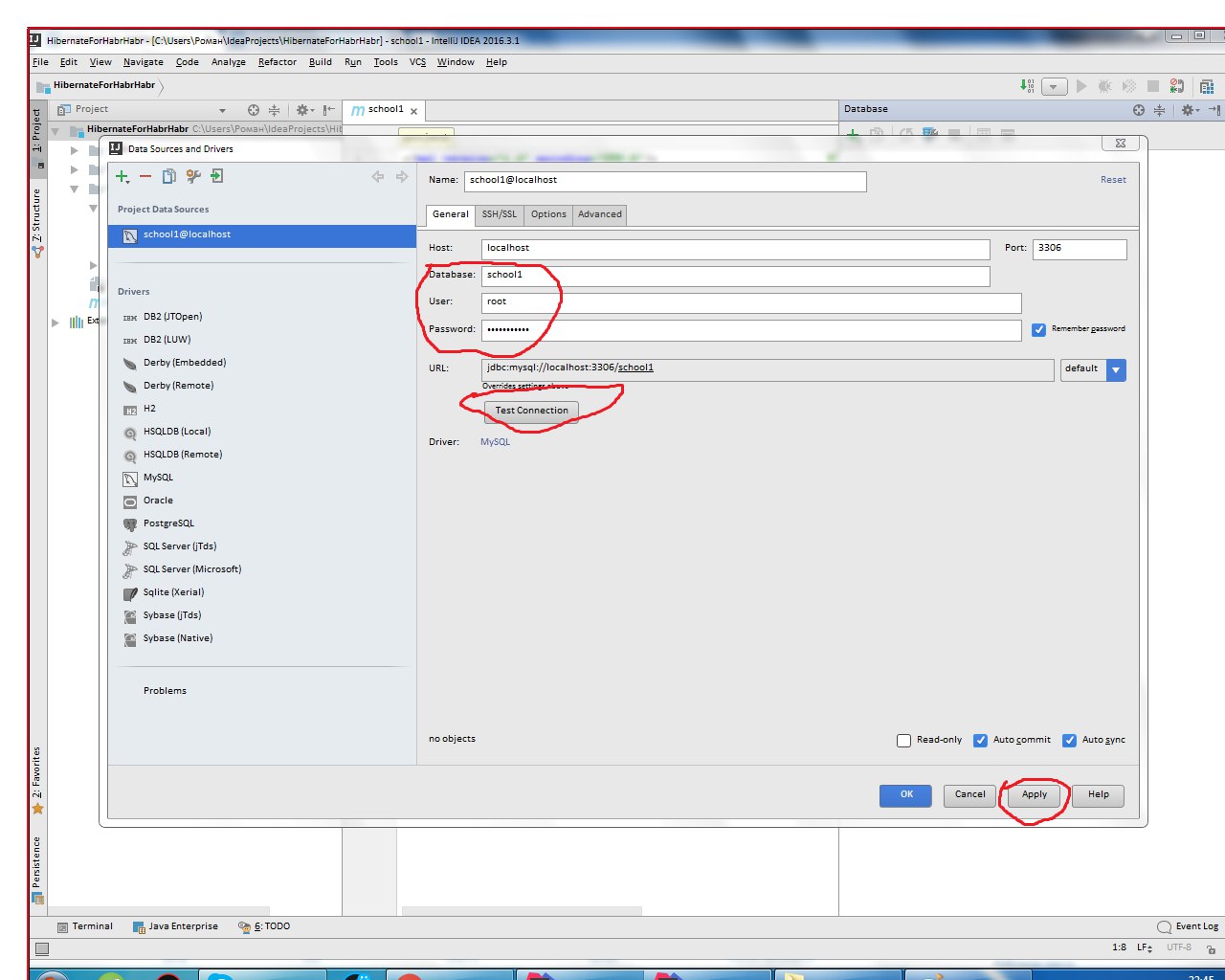
Вводим имя базы данных, имя пользователя и пароль. Протестируйте соединение.
Выбираем проект и через framework support просим у хибернейта создать за нас Entity файлы и классы с Getter и Setter.
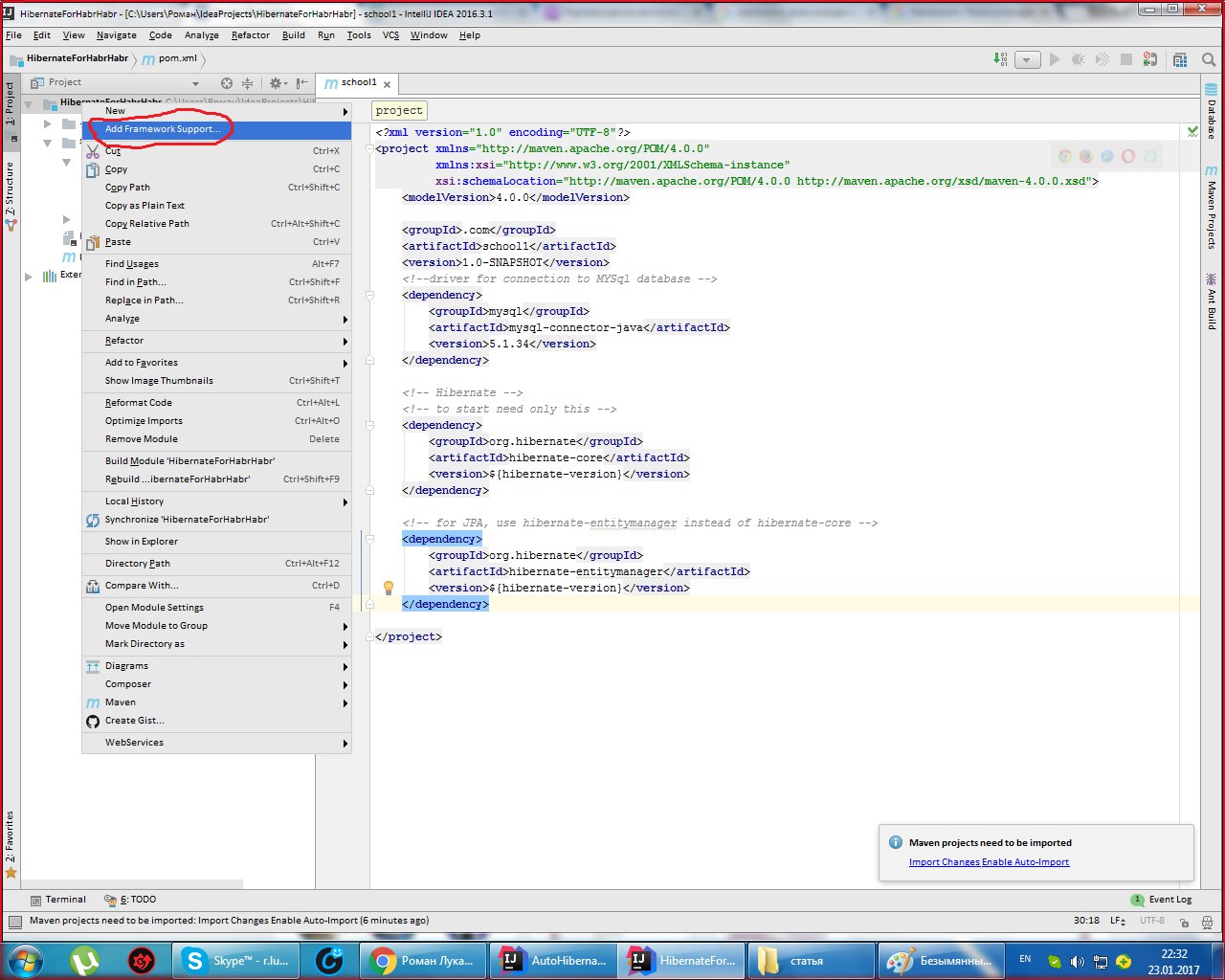
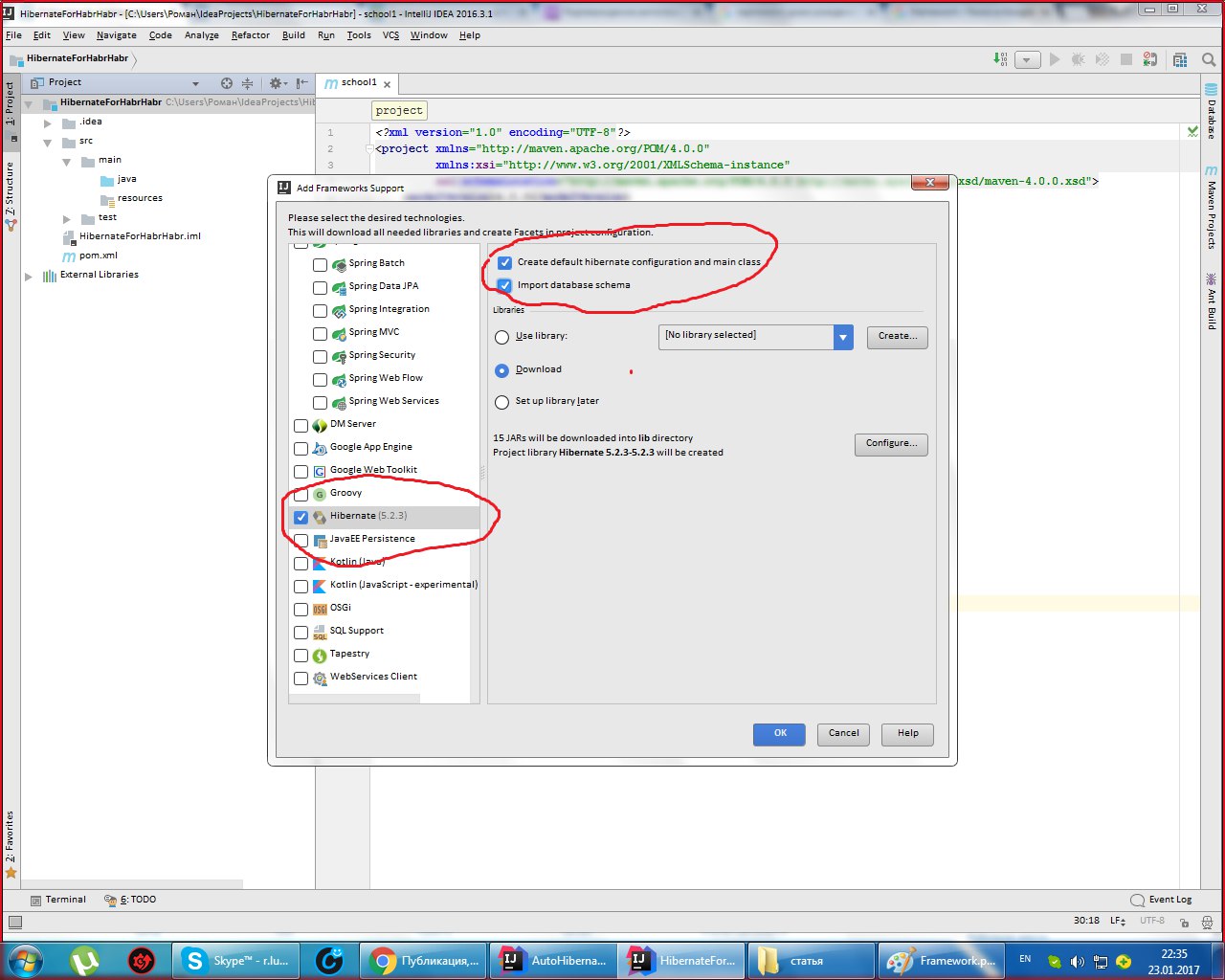
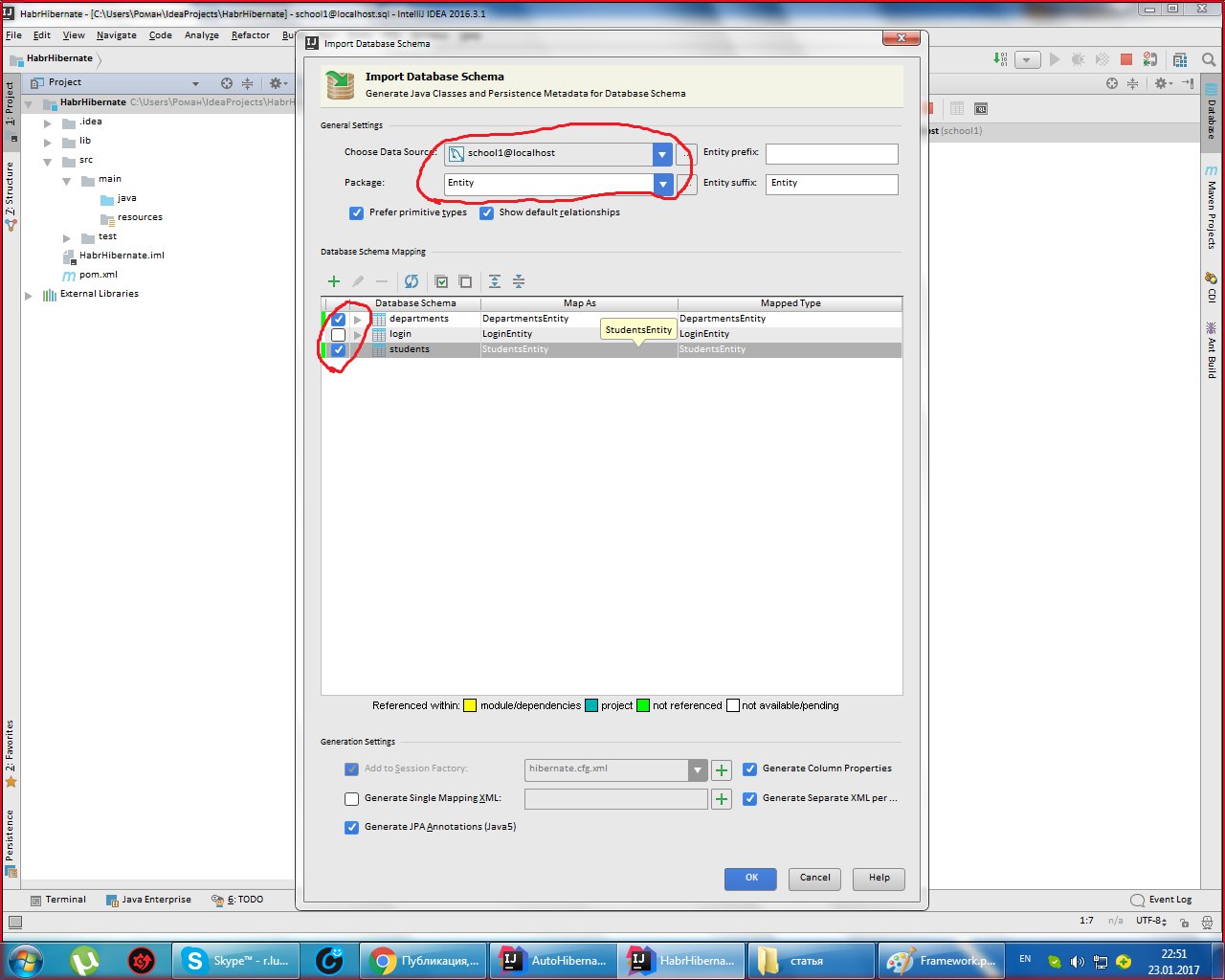
Выбираем Generate Persistence Mapping через кладку Persistence, выбираем jenerate Persistance Mapping, а в появившемся окне прописываем схему базы данных, выбираем prefix и
sufix к автоматически сгенерированным названиям. Будут сгенерированы названия xml файлов и классов с аннотациями:
Раскидайте файлы в таком порядке: .xml-файлы должны находится в папке с ресурсами, а сущности в папке java.
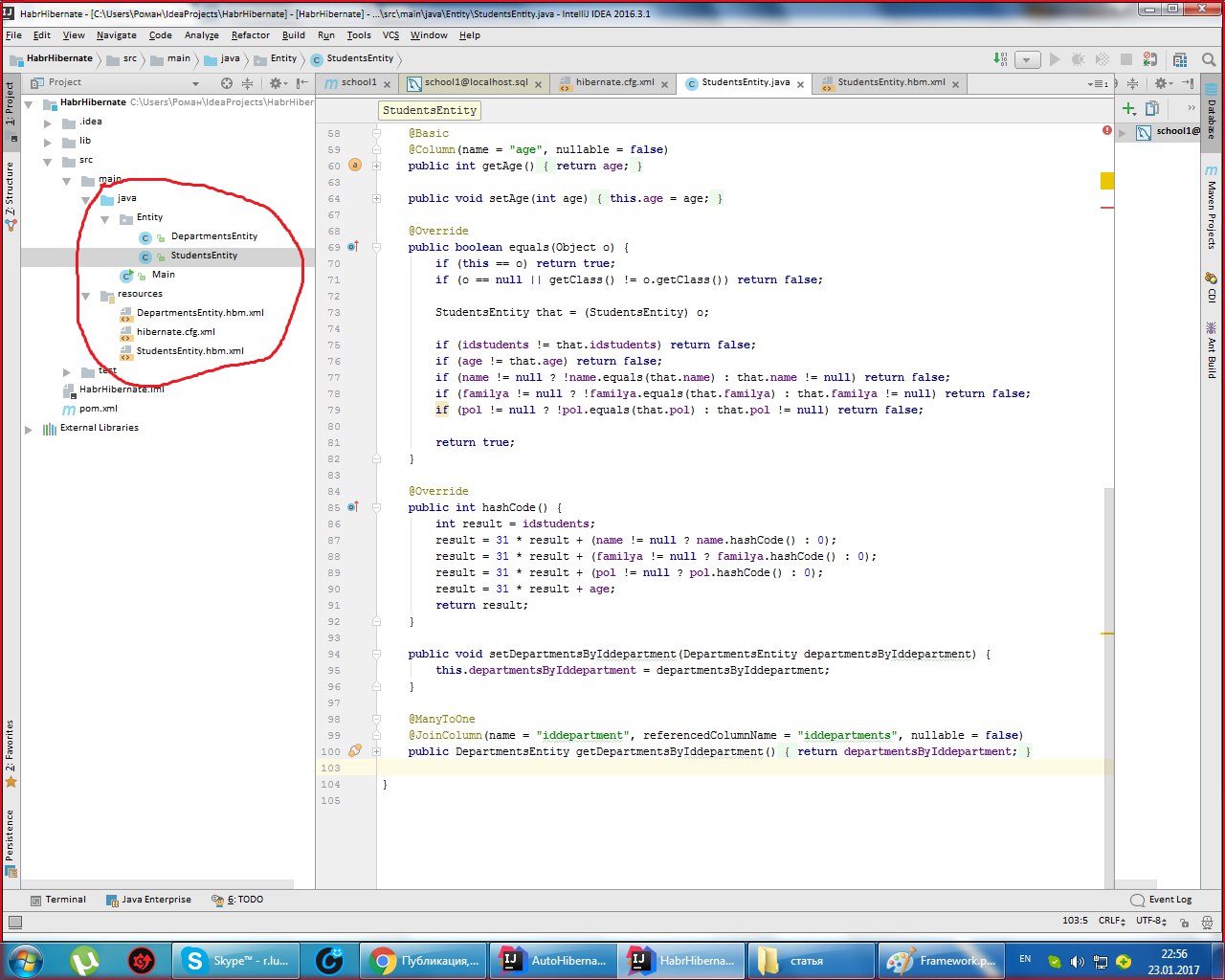
Дописываем в hibernate.cfg username и password (звёзды поставил я, а так пишите обычным шрифтом).
Хочу начать со слов благодарности тому человеку, который мне вчера накинул кармы, позволив этим писать мне в персональный блог.
Долго думал, о чем же написать свой «первый» топик… Слово первый не зря взял в кавычки, так как первый топик на самом деле уже был, опыт был к сожалению неудачный — дело закончилось баном. Решил больше не копипастить. Уверенности тому, что надо написать что-то свое, придал вот этот топик. Решил твердо — пусть это будет и редко, но буду писать сам.
Совсем недавно, по роду свой деятельности, мне пришлось столкнуться с таким понятием как ORM — (англ. Object-relational mapping). В двух словах ORM — это отображение объектов какого-либо объектно-ориентированного языка в структуры реляционных баз данных. Именно объектов, таких, какие они есть, со всеми полями, значениями, отношениями м/у друг другом.
ORM-решением для языка Java, является технология Hibernate, которая не только заботится о связи Java классов с таблицами базы данных (и типов данных Java в типы данных SQL), но также предоставляет средства для автоматического построения запросов и извлечения данных и может значительно уменьшить время разработки, которое обычно тратится на ручное написание SQL и JDBC кода. Hibernate генерирует SQL вызовы и освобождает разработчика от ручной обработки результирующего набора данных и конвертации объектов, сохраняя приложение портируемым во все SQL базы данных.
Итак, перед нами стоит задача написать небольшое приложение, которое бы осуществляло простое взаимодействие с базой данных, посредством технологии Hibernate.
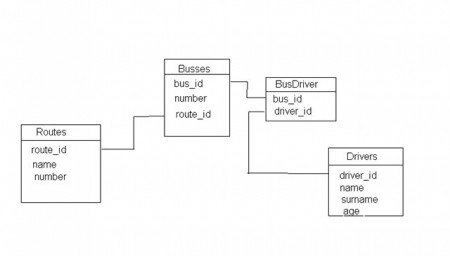
Немного подумав, решил написать так называемый «Виртуальный автопарк». Суть парка такова: есть автобусы, есть маршруты и есть водители. Автобусы и маршруты связаны отношением один ко многим, т.е. на одном маршруте может кататься сразу несколько автобусов. Водители и автобусы связаны отношением многие ко многим, т.е. один водитель может водить разные автобусы и один автобус могут водить разные водители. Вроде ничего сложного.
Вот схема базы данных.
За качество не ругайте — под рукой не оказалось нормального инструмента таблички рисовать…
Вот ссылка на дамп, снятый с базы, вдруг кто-то решит все это дело поднять :)
Приступаем к коду. Во первых нам необходимо описать классы наших сущностей, т.е. класс автобуса, водителя и маршрута.
Класс автобус.
import java.util.Set;
import java.util.HashSet;
public class Bus private Long id;
private String number;
private Set drivers = new HashSet();
private Long route_id;
public Bus() >
public void setId(Long id) this .id = id;
>
public void setNumber( String number) this .number = number;
>
public void setDrivers(Set drivers) this .drivers = drivers;
>
public void setRoute_id(Long route_id) this .route_id = route_id;
>
public Long getId() return id;
>
public String getNumber() return number;
>
public Set getDrivers() return drivers;
>
public Long getRoute_id() return route_id;
>
> * This source code was highlighted with Source Code Highlighter .
import java.util.Set;
import java.util.HashSet;
public class Driver private Long id;
private String name;
private String surname;
private int age;
private Set busses = new HashSet();
public Driver() >
public void setBusses(Set busses) this .busses = busses;
>
public Set getBusses() return busses;
>
public void setId(Long id) this .id = id;
>
public void setName( String name) this .name = name;
>
public void setSurname( String surname) this .surname = surname;
>
public void setAge( int age) this .age = age;
>
public Long getId() return id;
>
public String getName() return name;
>
public String getSurname() return surname;
>
public int getAge() return age;
>
> * This source code was highlighted with Source Code Highlighter .
import java.util.Set;
import java.util.HashSet;
public class Route private Long id;
private String name;
private int number;
private Set busses = new HashSet();
public Route() >
public void setId(Long id) this .id = id;
>
public void setName( String name) this .name = name;
>
public void setNumber( int number) this .number = number;
>
public void setBusses(Set busses) this .busses = busses;
>
public Long getId() return id;
>
public String getName() return name;
>
public int getNumber() return number;
>
public Set getBusses() return busses;
>
> * This source code was highlighted with Source Code Highlighter .
Заметьте, что все классы сущностей должны соответствовать Java naming conventions, т.е. у них должны быть обязательно геттеры, сеттеры и конструктор по умолчанию. Ничего сложного :)
Теперь для наших классов необходимо описать маппинг в виде xml-файлов, эти файлы как раз и будут отвечать за взаимодействие наших объектов с Hibernate и с базой данных.
Bus.hbm.xml
Driver.hbm.xml
- Тег hibernate-mapping я думаю понятен, тут ничего говорить не стоит.
- Тег class имеет два параметра: параметр name — Имя класса (необходимо указывать полный путь с учетом структуры пакетов) и параметр table — имя таблицы в базе данных, на которую будет маппиться наш класс.
- Тег id описывает идентификатор. Параметр column указывает на какую колонку в таблице будет ссылаться поле id нашего объекта, так же указываем класс и указываем generator, который отвечает за генерацию id.
- Тег property описывает простое поле нашего объекта, в качестве параметров указываем имя поля, его класс и имя колонки в таблице.
- Тег set описывает поле в котором содержится некий набор(коллекция) объектов. Тег содержит параметр name — имя поля нашего объекта, параметр table — имя таблицы связи(в случае отношения многие ко многим) и параметр lazy. Lazy, если меня не подводит моя память, с английского — ленивый. Так называемые ленивые коллекци, сейчас постараюсь объяснить понятнее. Когда мы в параметре lazy указываем значечение false, то у нас при получении объекта Route из базы вместе с объектом достается и коллекция объектов Bus, так как busses это поле объекта Route. А если в качестве параметра мы указываем значение true, то коллекция объектов Bus не вытаскивается, для ее получения надо явно вызывать метод route.getBusses(). Вот предположим такой очень хороший пример. Есть объект город, в него входит массив районов, в каждый район — массив улиц, в каждую улицу — массив домов и так далее до людей, живущих в квартирах. Предположим мы хотим вытянуть из базы названия районов. Если укажем lazy = false, то помимо районом у нас вытянется еще огромный объем «ненужных» данных, если же lazy = true, то мы получим то что надо и ничего лигнего.
- Тег key имеет параметр column, который говорит, на какую колонку в таблице связи будет ссылаться поле нашего объекта.
- Тег many-to-many описывает связь типа многие ко многим, в качестве параметров тег использует column — имя колонки второй колонки в таблице связи и параметр class, указывающий какого класса будут объеты на той стороне.
Теперь создадим главный конфигурационный файл hibernate.cfg.xml, файл, откуда он будет дергать всю необходимую ему информацию.
Тут я не буду особо вдаваться в объяснение, думаю многим и так все понятно :) Скажу, что надо только в конце не забыть добавить тег mapping и указать в качестве параметра resources файлы конфигурации ваших бинов.
Теперь создадим класс, который будет хавать наш конфиг-файл и возвращать нам объект типа SessionFactory, который отвечает за создание hibernate-сессии.
import org.hibernate.cfg.Configuration;
import org.hibernate.SessionFactory;
public class HibernateUtil private static final SessionFactory sessionFactory;
static try sessionFactory = new Configuration().configure().buildSessionFactory();
> catch (Throwable ex) System.err.println( «Initial SessionFactory creation failed.» + ex);
throw new ExceptionInInitializerError(ex);
>
>
public static SessionFactory getSessionFactory() return sessionFactory;
>
> * This source code was highlighted with Source Code Highlighter .
Теперь нам осталось разобраться со взаимодействием нашего приложения с базой данных. Для этого для каждого класса-сущности, определим интерфейс, содержащий набор необходимых методов (Я приведу только один интерфейс и одну его реализацию, интерфейсы и реализации для др. классов подобны этим.)
import logic.Bus;
import logic.Driver;
import logic.Route;
import java.util.Collection;
import java.sql.SQLException;
public interface BusDAO public void addBus(Bus bus) throws SQLException;
public void updateBus(Long bus_id, Bus bus) throws SQLException;
public Bus getBusById(Long bus_id) throws SQLException;
public Collection getAllBusses() throws SQLException;
public void deleteBus(Bus bus) throws SQLException;
public Collection getBussesByDriver(Driver driver) throws SQLException;
public Collection getBussesByRoute(Route route) throws SQLException;
Теперь определим реализацию этого интерфейса в классе BusDAOImpl
import DAO.BusDAO;
import logic.Bus;
import logic.Driver;
import logic.Route;
import java.sql.SQLException;
import java.util.Collection;
import java.util. ArrayList ;
import java.util. List ;
import util.HibernateUtil;
import javax.swing.*;
import org.hibernate.Session;
import org.hibernate.Query;
public class BusDAOImpl implements BusDAO
public Bus getBusById(Long bus_id) throws SQLException Session session = null ;
Bus bus = null ;
try session = HibernateUtil.getSessionFactory().openSession();
bus = (Bus) session.load(Bus. class , bus_id);
> catch (Exception e) JOptionPane.showMessageDialog( null , e.getMessage(), «Ошибка 'findById'» , JOptionPane.OK_OPTION);
> finally if (session != null && session.isOpen()) session.close();
>
>
return bus;
>
public Collection getAllBusses() throws SQLException Session session = null ;
List busses = new ArrayList ();
try session = HibernateUtil.getSessionFactory().openSession();
busses = session.createCriteria(Bus. class ).list();
> catch (Exception e) JOptionPane.showMessageDialog( null , e.getMessage(), «Ошибка 'getAll'» , JOptionPane.OK_OPTION);
> finally if (session != null && session.isOpen()) session.close();
>
>
return busses;
>
Еще рас скажу, что реализации DriverDAOImpl и RouteDAOImpl будут аналогичны этой.
Наибольший интерес для нас представляют два последних метода, взгляните на них повнимательнее. Как происходит общение с базой? От объекта SessionFactory создается новая или получается текущая сессия, зачем начинается транзакция, выполняются необходимые действия, коммит транзакции и закрытие сессии. Вроде ничего сложного :) Обратите внимание, на то, каким синтаксисом описан запрос к базе. Это так называемый HQL (Hibernate Query Language) HQL представляет собой объектно-ориентированный язык запросов, возможности его широки, но мной настолько широко еще не осилены :) Помимо save, load, update, delete и HQL, можно пользоваться и обычным SQL. Например:
String query = "SELECT driver_id, name, surname, age FROM drivers";
List drivers = new ArrayList();
drivers = (List) session.createSQLQuery(query).list();
Теперь создадим класс фабрики, к которой будем обращаться за нашими реализациями DAO, от которых и будем вызывать необходимые нам методы.
public class Factory
private static BusDAO busDAO = null ;
private static DriverDAO driverDAO = null ;
private static RouteDAO routeDAO = null ;
private static Factory instance = null ;
public static synchronized Factory getInstance() if (instance == null ) instance = new Factory();
>
return instance;
>
public BusDAO getBusDAO() if (busDAO == null ) busDAO = new BusDAOImpl();
>
return busDAO;
>
public DriverDAO getDriverDAO() if (driverDAO == null ) driverDAO = new DriverDAOImpl();
>
return driverDAO;
>
public RouteDAO getRouteDAO() if (routeDAO == null ) routeDAO = new RouteDAOImpl();
>
return routeDAO;
>
> * This source code was highlighted with Source Code Highlighter .
Теперь нам осталось создать какой-либо демонстрационный класс, для того, чтобы посмотреть и опробовать все то, что мы написали. Ну, не будем тянуть, вот этот класс, возможно не самый удачный, но все же :)
public class Main public static void main( String [] args) throws SQLException
>
> * This source code was highlighted with Source Code Highlighter .
Еще раз скажу, что может не самый удачный вариант использования всего нами написанного, но для этого уже лучше GUI писать или Web-интерфейс, а это уже другая песня :)
P.S.. Скажу, что на 100%-ую правильность я не претендую, это мое личное имхо, однако очень надеюсь, что это станет для кого-то полезным материалом.

Представьте, что вы закончили обучение на JavaRush и начали искать первую работу. В описаниях вакансий вам встречаются фреймворки и инструменты, которые вы не проходили. Мы запускаем цикл статей, чтобы помочь вам понять, какие инструменты Java в каких проектах используют, и на каком этапе карьеры разработчика их следует учить. В четвертом материале поговорим о фреймворке Hibernate.
Насколько Hibernate востребован?
Хотя есть и другие инструменты для работы с базами данных, сейчас Hibernate считается одной из основных технологий для работы с Java. В 87 из 300 вакансий для Java-разработчиков с таких сайтов, как AngelList, StackOverflow, LinkedIn указано, что ищут разработчика со знанием Hibernate — об этом говорится в исследовании ресурса CV Compiler. В рейтинге исследования этот фреймворк занимает 9-е место по популярности среди всех инструментов Java. Средняя зарплата девелоперов, которые владеют Hibernate, — около 52,5 тысяч фунтов в год, по данным ресурса ITJobsWatch. В рейтинг сопутствующих навыков, которые чаще всего работодатель просит знать наряду с Hibernate, входят Spring, Agile Software Development, TDD, AngularJS.
Операция обновления
Теперь продвинемся вперед и попробуем обновить уже существующие в таблице данные.

Мы создали метод updateFlightNumber , в котором сначала извлекаем объект Flight с заданным идентификатором, а затем обновляем номер рейса методом-сеттером. После этого вызываем update -метод, чтобы обновить существующую сущность.
Примечание: если вам хочется вывести объекты, извлеченные из базы данных, на консоль, добавьте метод toString() в класс POJO, иначе выведется хэш-код.
Операция сохранения
Метод сохранения в объекте сеанса выполняет задачу вставки объекта.

Hibernate: что это?
Ни одна программа не может обойтись без подключения к базе данных. Для хранения данных используют различные базы — Oracle, MS SQL Server, MySQL, Postgres. Для подключения к базам данных в Java придумали стандарт JDBC. Он позволяет работать по единым правилам с различными базами данных одинаковыми методами. Для этого нужно лишь установить драйвер для определенной базы данных (например, для баз данных Oracle или Postgres) по стандарту JDBC. До определенного момента эта схема хорошо работала. Но приложения становились тяжелее и больше и, соответственно, количество кода в приложении тоже: в том числе и того, который отвечал за запросы к базам данных. Появилось много так называемого спагетти-кода (повторяющегося) и рутинной работы. Hibernate — это фреймворк, который придумали для того, чтобы облегчить жизнь программистам. Он устраняет повторяющийся код и скрывает код, необходимый для управления ресурсами, уменьшает количество ошибок. Работая с Hibernate, разработчик может сосредоточиться на бизнес-логике приложения. По сути Hibernate при связи приложения с базой данных выступает адаптером.
Операция удаления
В базе данных есть только один объект с id=1 . Попытаемся удалить этот объект.

После выполнения метода deleteFlight таблица становится пустой. В приведенном выше коде мы сначала извлекли объект по его идентификатору и передали его методу удаления. Если все пойдет хорошо, транзакция окажется зафиксирована, в противном случае выполнится откат.
И еще одно: хотим ли мы обновить объект в базе данных или удалить его, нам понадобится значение его первичного ключа. Однако у нас не всегда есть возможность его получить. Кроме того, для этого необходимо выполнять сложные операции с данными. Цели можно достичь с помощью HQL, аналогичного SQL, но он удаляет шаблонный код. Это означает, что теперь не нужно использовать операторы select с запросами.
На каких проектах понадобится?
Можно сказать, что Hibernate востребован так же широко, как и базы данных. То есть, практически в любом проекте.
Когда и как учить?
Изучить работу с Hibernate на практике можно на онлайн-стажировке JavaRush.
Наборы проводятся раз в сезон среди пользователей, которые достигли 35 уровня.

В сегодняшней IT-индустрии хранение и извлечение данных приложений базируется на объектно-ориентированных языках программирования и реляционных базах данных. Базы данных хранят большой объем информации в одном месте. Наряду с этим, они предоставляют эффективный способ поиска записей, чтобы легко и быстро добраться до нужных данных.
Но при работе с объектами есть одна функция, которую база данных не поддерживает, — это хранение самих объектов, поскольку в ней хранятся только реляционные данные. Данные в виде объектов обеспечивают абстракцию и переносимость.
Существует ли метод, с помощью которого возможно напрямую хранить и извлекать объекты в реляционной базе данных? Ответ — да, такая возможность есть. Название этой техники — ORM.
ORM устраняет несоответствие между объектной моделью и реляционной базой данных. Само название предполагает отображение объектов в реляционные таблицы. Технология ORM преобразует объекты в реляционные данные и обратно. Возникает вопрос: как это делается?
По сути, имя переменной экземпляра присваивается имени столбца, а его значение формирует строку в реляционной базе данных. Теперь вопрос в том, нужно ли объявлять таблицу в базе данных для хранения объектов. Ответ — нет, ORM сделает это за нас, объявив типы данных для столбцов такими же, как и для переменных экземпляра.
Однако для этого нужно выполнить небольшую настройку и сообщить ORM, как будут отображаться объекты. В Java ORM работает с обычными старыми классами объектов Java (POJO), объекты которых необходимо сопоставить. Эти классы по сути состоят из частных переменных экземпляра, параметризованного конструктора с общедоступными геттерами и сеттерами.
Наряду с параметризованным конструктором класс POJO должен иметь открытый конструктор без аргументов, поскольку он необходим ORM для сериализации. Поскольку параметризованный конструктор присутствует, compile не будет добавлять конструктор аргументов самостоятельно, поэтому придется делать это вручную.
Hibernate — это высокопроизводительный инструмент объектно-реляционного сопоставления с открытым исходным кодом для языка программирования Java. Он был выпущен в 2001 году Гэвином Кингом и его коллегами из Cirrus Technologies в качестве альтернативы Entity Beans (объектным бинам) в стиле EJB2.
Этот фреймворк отвечает за решение проблем несоответствия объектно-реляционного импеданса. В Java есть спецификация под названием Java Persistence API (JPA), которая описывает управление объектами в реляционной базе данных. Hibernate — это всего лишь реализация JPA.
Обсудим компоненты, из которых состоит Hibernate. Hibernate имеет многоуровневую архитектуру и позволяет работать, даже не зная базовых API, реализующих объектно-реляционное сопоставление. Hibernate находится между Java-приложением и базой данных. Архитектура Hibernate подразделяется на четыре уровня:

- уровень Java-приложения;
- уровень фреймворка;
- уровень API;
- уровень базы данных.
На приведенной выше диаграмме показаны все четыре слоя. Поток данных между Java-приложением и базой данных выполняется с использованием постоянного объекта, определенного Hibernate. Уровень инфраструктуры Hibernate состоит из различных объектов, таких как конфигурация, фабрика сеансов, сеанс, транзакция, запрос и критерии. Эти объекты создаются вручную, по мере необходимости.
Объект конфигурации. Первый объект Hibernate, который должен присутствовать в любом Hibernate-приложении. Он активирует платформу Hibernate. Объект конфигурации создается только один раз во время инициализации приложения. Это родительский объект — именно из него создаются все остальные. Он проверяет, является ли файл конфигурации синтаксически правильным или нет. Он предоставляет свойства конфигурации и сопоставления, необходимые Hibernate.
Объект фабрики сеансов. Фабрика сеансов — это массивный потокобезопасный объект, используемый несколькими потоками одновременно. Таким образом, в приложении он должен быть создан только один раз и сохранен для последующего использования. Для каждой базы данных необходим отдельный объект фабрики сеансов. Фабрика сеансов отвечает за настройку Hibernate посредством свойств конфигурации, предоставляемых объектом конфигурации.
Объект сеанса. Облегченный объект, который создается каждый раз, когда нужно взаимодействовать с базой данных. Постоянные объекты сохраняются и извлекаются с помощью объекта сеанса. Это не потокобезопасный объект, поэтому его следует уничтожить после завершения взаимодействия.
Объект транзакции. Представляет собой единицу работы с базой данных. Это необязательный объект, но его следует использовать для обеспечения целостности данных и в случае возникновения какой-либо ошибки — выполнять откат.
Объект запроса. Объект запроса нужен для записи запросов и выполнения операций CRUD в базе данных. Можно написать запрос на SQL или воспользоваться языком запросов Hibernate (HQL). В процессе реализации вам станет известно о HQL больше.
Объект критериев. С его помощью выполняются объектно-ориентированные запросы для извлечения объектов из базы данных.
Во-первых, нужно установить Hibernate у себя в проекте. Можно загрузить jar-файл или воспользоваться более удобным способом, например, применить maven. Так и поступим. Загрузим зависимость hibernate, определенную в POM.xml.

Фреймворк Hibernate должен знать, как сопоставлять объекты, учетные данные сервера базы данных, где будут храниться и откуда будут извлекаться объекты, и еще несколько свойств. Вопрос в том, как передать всю эту информацию в Hibernate.
Эта настройка выполняется с помощью двух XML-файлов.
- hibernate.cfg.xml содержит свойства гибернации, такие как диалект, класс драйвера, URL-адрес сервера базы данных, имя пользователя и пароль.
- Файл сопоставления содержит взаимосвязь сопоставления между Java-объектами и таблицами базы данных. Имя файла должно соответствовать шаблону .hbm.XML. Например, если мы хотим работать с объектом типа “Employee”, имя файла будет Employee.hbm.xml.
XML-файлы необходимо поместить в папку META-INF внутри src/main/resources . Третий компонент, который понадобится в настройке, — это класс POJO, который мы обсуждали ранее.
Рассмотрим пример работы с объектом Flight. В качестве переменных экземпляра он содержит идентификатор (ID), номер рейса, место отправления, место прибытия, дату рейса и тариф. Идентификатор будет первичным ключом таблицы.

Приведенное выше изображение — это hbm.cfg.xml. Как видите, все свойства определены внутри тега hibernate-configuration . Внутри тега session-factory указываются свойства базы данных, к которой необходимо подключиться.
Свойство hbm2ddl.auto проверяет или экспортирует язык определения данных схемы при создании объекта фабрики сеансов. Здесь мы прописали операцию обновления, которая обновит базу данных, не затрагивая ранее записанные данные. Недостает еще нескольких, таких как проверка, создание и создание-удаление.

Приведенный выше XML-код относится к файлу сопоставления. Все свойства определены внутри тега hibernate-mapping . Тег class предназначен для определения имени класса POJO и имени таблицы, которые будут созданы внутри базы данных в качестве атрибутов, а отношения сопоставления — в качестве значений.
Первичный ключ определяется внутри тега id . Мы определяем имя переменной экземпляра внутри атрибута name . Имя столбца и тип данных указаны в атрибутах column и type соответственно. Теги generator предоставляют стратегию, с помощью которой необходимо выполнить автоинкремент. Все остальные сопоставления переменных экземпляра предоставляются внутри тегов свойств property .
Настало время, когда нужно создать класс POJO для рейсов ( Flights ), объекты которого будут сохраняться в таблице FLIGHTS. Здесь есть также пустой конструктор по умолчанию, необходимость которого мы обосновали ранее.

Один вопрос, который наверняка приходит вам в голову: если мы, Java-разработчики, пользуемся инструментарием Java, зачем выполнять настройку с использованием XML? Есть ли какой-нибудь другой способ? Ответ таков: да, но только частично.
От файла сопоставления можно избавиться с помощью аннотаций, но конфигурационный XML-файл все еще необходим. Аннотации — мощный способ определения взаимосвязи между объектом и реляционной моделью. Они начинаются с @ .
Нужно просто добавить аннотации внутри класса POJO. Отдельного файла не требуется:

Аннотацию необходимо указывать непосредственно над объявлением поля.
- @Entity сообщает Hibernate, что этот класс — компонент сущности, и его объекты должны быть постоянными.
- @Table применяется для указания имени создаваемой таблицы в базе данных.
- @Id используется для определения первичного ключа. Можно также добавить совместно несколько полей, чтобы создать составной ключ.
- @GeneratedValue определяет стратегию инкремента в поле. Это необязательный параметр — если он не определен с помощью @Id , применяется стратегия по умолчанию.
- @Column определяет, как поле сопоставляется со столбцом в таблице. Аннотация принимает такие атрибуты, как имя столбца, определение столбца, возможность принимать null-значение, уникальность и т. д. В отличие от XML-файлов, здесь не нужно указывать тип, поскольку он берется непосредственно из поля.
Попробуем, наконец, выполнить CRUD-операции с помощью Hibernate. Для этого создадим класс с именем DAO . Но еще до этого нам понадобится объект фабрики сеансов. Есть два способа его создания. Если мы работаем без аннотации, то поступим вот так:

Другой способ будет определен в приведенном ниже примере. Процедура создания всех остальных объектов одинакова для обоих вариантов.
Первый пример — добавление объектов рейса Flight в базу данных. Создаем метод addFlight , который сохраняет объект в базе данных. Далее выполняется транзакция в режиме try-catch , чтобы в случае возникновения какой-либо проблемы удалось выполнить откат, а в противоположном случае — транзакция была зафиксирована в таблице.
Читайте также: