
Etl фреймворк что это
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
- Как случайные ошибки, возникшие на уровне ввода, переноса данных, или из-за багов;
- Как различия в справочниках и детализации данных между смежными ИТ-системами.
- Привести все данные к единой системе значений и детализации, попутно обеспечив их качество и надежность;
- Обеспечить аудиторский след при преобразовании (Transform) данных, чтобы после преобразования можно было понять, из каких именно исходных данных и сумм собралась каждая строчка преобразованных данных.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
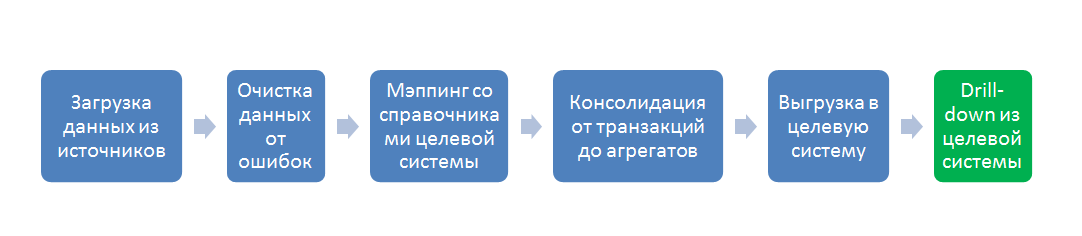
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
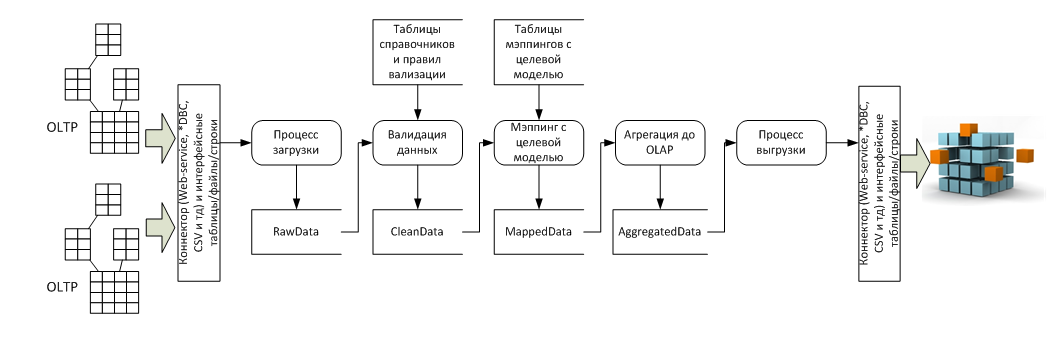
- Процесс загрузки – Его задача затянуть в ETL данные произвольного качества для дальнейшей обработки, на этом этапе важно сверить суммы пришедших строк, если в исходной системе больше строк, чем в RawData то значит — загрузка прошла с ошибкой;
- Процесс валидации данных – на этом этапе данные последовательно проверяются на корректность и полноту, составляется отчет об ошибках для исправления;
- Процесс мэппинга данных с целевой моделью – на этом этапе к валидированной таблице пристраивается еще n-столбцов по количеству справочников целевой модели данных, а потом по таблицам мэппингов в каждой пристроенной ячейке, в каждой строке проставляются значения целевых справочников. Значения могут проставляться как 1:1, так и *:1, так и 1:* и *:*, для настройки последних двух вариантов используют формулы и скрипты мэппинга, реализованные в ETL-инструменте;
- Процесс агрегации данных – этот процесс нужен из-за разности детализации данных в OLTP и OLAP системах. OLAP-системы — это, по сути, полностью денормализованная таблица фактов и окружающие ее таблицы справочников (звездочка/снежинка), максимальная детализация сумм OLAP – это количество перестановок всех элементов всех справочников. А OLTP система может содержать несколько сумм для одного и того же набора элементов справочников. Можно было-бы убивать OLTP-детализацию еще на входе в ETL, но тогда мы потеряли бы «аудиторский след». Этот след нужен для построения Drill-down отчета, который показывает — из каких строк OLTP, сформировалась сумма в ячейке OLAP-системы. Поэтому сначала делается мэппинг на детализации OLTP, а потом в отдельной таблице данные «схлопывают» для загрузки в OLAP;
- Выгрузка в целевую систему — это технический процесс использования коннектора и передачи данных в целевую систему.
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
- Надо учитывать требования бизнеса по длительности всего процесса. Например: Если данные должны быть загружены в течение недели с момента готовности в исходных системах, и происходит 40 итераций загрузки до получения нормального качества, то длительность загрузки пакета не может быть больше 1-го часа. (При этом если в среднем происходит не более 40 загрузок, то процесс загрузки не может быть больше 30 минут, потому что в половине случаев будет больше 40 итераций, ну или точнее надо считать вероятности:) ) Главное если вы не укладываетесь в свой расчет, то не надейтесь на чудо — сносите и все, делать заново т.к. вы не впишитесь;
- Данные могут загружаться набегающей волной – с последовательным обновлением данных одного и того-же периода в будущем в течение нескольких последовательных периодов. (например: обновление прогноза окончания года каждый месяц). Поэтому кроме справочника «Период», должен быть предусмотрен технический справочник «Период загрузки», который позволит изолировать процессы загрузки данных в разных периодах и не потерять историю изменения цифр;
- Данные имеют обыкновение быть перегружаемыми много раз, и хорошо если будет технический справочник «Версия» как минимум с двумя элементами «Рабочая» и «Финальная», для отделения вычищенных данных. Кроме-того создание персональных версий, одной суммарной и одной финальной позволяет хорошо контролировать загрузку в несколько потоков;
- Данные всегда содержат ошибки: Перезагружать весь пакет в [50GB -> +8] это очень не экономно по ресурсам и вы, скорее всего, не впишитесь в регламент, следовательно, надо грамотно делить загружаемый пакет файлов и так проектировать систему, чтобы она позволяла обновлять пакет по маленьким частям. По моему опыту лучший способ – техническая аналитика «файл-источник», и интерфейс, который позволяет снести все данные только из одного файла, и вставить вместо него обновленные. А сам пакет разумно делить на файлы по количеству исполнителей, ответственных за их заполнение (либо админы систем готовящие выгрузки, либо пользователи заполняющие вручную);
- При проектировании разделения пакета на части надо еще учитывать возможность так-называемого «обогащения» данных (например: Когда 12 января считают налоги прошлого года по правилам управленческого учета, а в марте-апреле перегружают суммы на посчитанные по бухгалтерскому), это решается с одной стороны правильным проектированием деления пакета данных на части так, чтобы для обогащения надо было перегрузить целое количество файлов (не 2,345 файла), а с другой стороны введением еще одного технического справочника с периодами обогащения, чтобы не потерять историю изменений по этим причинам).
Процесс валидации
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
- Не из списка разрешенных значений
- Отсутствие обязательных значений
- Не соответствие формату (Все договора должны нумероваться «ДГВxxxx..»)
- Не из списка разрешенных значений для связанного элемента
- Отсутствие обязательных элементов для связанного элемента
- Не соответствие формату для связанного элемента(например: для продукта «АИС» все договора должны нумероваться «АИСxxxx..»)
- Символы допустимые в одном формате, недопустимы в другом
- Кодировка
- Обратная совместимость (Элемент справочника был изменен в целевой системе без добавления мэппинга)
- Новые значения (нет мэппинга)
- Устаревшие значения (не из списка разрешенных в целевой системе)
- Не число
- Не в границах разрешенного интервала значений
- Пропущено порядковое значение (например: данные не дошли)
- Не выполняется отношение y=ax+b (например: НДС и Выручка, или Встречные суммы равны)
- Элементу «А» присвоен неправильный порядковый номер
- Разницы за счет разных правил округления значений (например: в 1С и SAP никогда не сходится рассчитанный НДС)
- Переполнение
- Потеря точности и знаков
- Несовместимость форматов при конвертации в не число
- День недели не соответствует дате
- Сумма единиц времени не соответствует из-за разницы рабочие/не рабочие/праздничные/сокращенные дни
- Несовместимость формата даты при передаче текстом (например: ISO 8601 в UnixTime, или разные форматы в ISO 8601)
- Ошибка точки отсчета и точности при передаче числом (например: TimeStamp в DateTime)
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
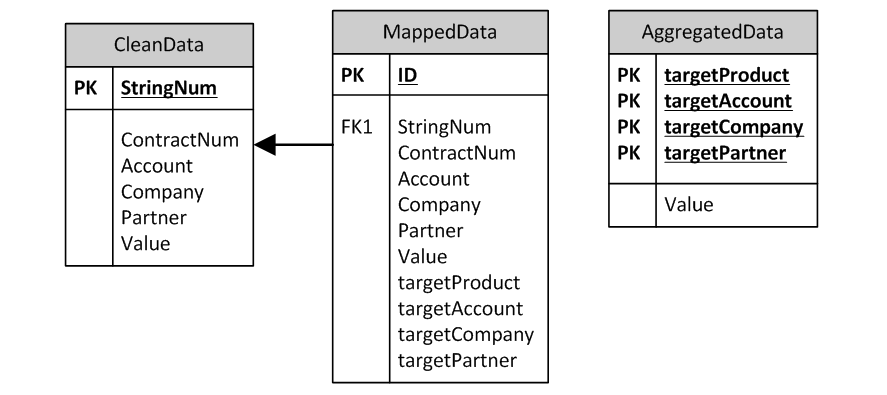
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
-
Таблица замэпленных данных должна включать одновременно два набора полей – старых и новых аналитик, чтобы можно был сделать select по исходным аналитикам и посмотреть, какие целевые аналитики им присвоены, и наоборот:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
Способность data scientist-а извлекать ценность из данных тесно связана с тем, насколько развита инфраструктура хранения и обработки данных в компании. Это значит, что аналитик должен не только уметь строить модели, но и обладать достаточными навыками в области data engineering, чтобы соответствовать потребностям компании и браться за все более амбициозные проекты.
При этом, несмотря на всю важность, образование в сфере data engineering продолжает оставаться весьма ограниченным. Мне повезло, поскольку я успел поработать со многими инженерами, которые терпеливо объясняли мне каждый аспект работы с данными, но не все обладают такой возможностью. Именно поэтому я решил написать эту статью — введение в data engineering, в которой я расскажу о том, что такое ETL, разнице между SQL- и JVM-ориентированными ETL, нормализации и партиционировании данных и, наконец, рассмотрим пример запроса в Airflow.

Системы управления рабочим процессом — Workflow management systems (WMS)
Сначала мы рассмотрим инструменты Python meta-ETL. Системы управления рабочим процессом (WMS) позволяют планировать, организовывать и отслеживать любые повторяющиеся задачи в вашем бизнесе. Таким образом, вы можете использовать WMS для настройки и запуска рабочих процессов ETL.
Carry
Carry — это пакет Python, который объединяет SQLAlchemy и Pandas. Это полезно для перехода между CSV и общими типами реляционных баз данных, включая Microsoft SQL Server, PostgreSQL, SQLite, Oracle и другие. Используя Carry,несколько таблиц могут быть перенесены параллельно, и в процессе могут выполняться сложные преобразования данных. Carry может автоматически создавать и сохранять представления на основе перенесенных данных SQL для использования в будущем.
ВременнАя метка. Немного трюков
Начнем с временной метки. Временные показатели исполнения, естественно, будут зависеть от мощности машины. Поэтому приводимые показатели важны для сопоставительного анализа.
Воспользуемся базовыми функциями R, на сгенерированном датасете получаем примерно 130 секунд. Большинство аналитиков (неважно, на каком языке пишут) скажут, что это вполне нормальная ситуация, нет смысла хотеть бОльшего.
Но не будем на этом останавливаться. Вдруг данных будет немного больше (это же IoT по постановке задачи). 50М или 500М? Поменяем библиотеку с пониманием того, как она устроена внутри и как устроен POSIXct.
Получаем 3.5 секунды на нашем датасете.
Останавливаемся? А почему, собственно, да? Можно попробовать другие библиотеки. Но мы пойдем другим способом. Так уже получается, что у нас есть весь загруженный датасет в память. Давайте пользоваться спецификой предметной области и спецификой преобразуемых данных. Преобразование строки в дату — очень трудозатратная операция. Зачем прикидываться, что мы ничего не знаем о данных и делать эту операцию для каждой строки? Можно же сделать преобразование только для уникальных значений временных меток. Таковых оказывается на порядки меньше, сказывается специфика задачи.
Используем этот подход + меняем библиотеку.
Вариант через групповую обработку — получаем 2.9 сек.
Для потоковых преобразований ограниченных подмножеств наилучшим подходом является предварительное создание словаря "входное значение — преобразованное значение". Тогда вся трансформация будет сводится выборке из этого словаря. Вариант через слияние по ссылкам со словарем дает чуть лучший результат 1.3 сек:
Это все? Потенциально, если расщепить словари даты и времени, то можно сократить объем преобразований еще примерно в 10 раз (1113 + 48 против 53K). Таймзоны в исходных данных не наблюдаются, городов тоже, значит все условно можно считать в UTC.
В таком варианте получаем примерно 0.7 сек.
Итого, путем краткого исследования исходной задачи и незначительных манипуляций получаем ускорение со 130 сек (которые многие аналитики сочли приемлемым) до 0.7 сек. (~ 180 раз) в базовом варианте, или с 3.5 сек до 0.7 сек (~ 5 раз) в варианте с lubridate . Можно, конечно, разбрасываться ресурсами, но если это делать на каждом шагу, то ресурсов и времени может легко не хватить.
Более простая альтернатива
Использование инструментов Python ETL — один из способов настроить вашу инфраструктуру ETL. Однако, как и в случае со всеми проектами кодирования, это может быть дорогостоящим, трудоемким и полным неожиданных проблем.
Если вы просто хотите синхронизировать, хранить и легко получать доступ к своим данным, Panoply для вас. Вместо того, чтобы тратить недели на кодирование конвейера ETL на Python, сделать это за несколько минут и щелкнуть мышью с Panoply. Это единственный инструмент конвейера данных, который легко помещает все ваши бизнес-данные в одно место, предоставляет всем сотрудникам неограниченный доступ, который им нужен, и не требует обслуживания. Кроме того, у Panoply есть встроенное хранилище, поэтому вам не нужно манипулировать несколькими поставщиками, чтобы обеспечить поток данных.
ETL‑фреймворки
Мы обсудили некоторые инструменты, которые можно комбинировать для создания собственного решения Python ETL (например, Airflow и Spark). Но теперь давайте посмотрим на инструменты Python, которые могут обрабатывать каждый шаг процесса извлечения-преобразования-загрузки.
Bubbles
Bubbles — это популярная среда Python ETL, упрощающая создание конвейеров ETL. Bubbles написан на Python, но не зависит от технологий. Он настроен для работы с объектами данных — представлениями наборов данных, являющихся ETL, — чтобы максимизировать гибкость в конвейере ETL пользователя. Если ваш конвейер ETL имеет много узлов с форматом -зависимое поведение, Пузыри могут быть решением для вас. Репозиторий Github не подвергался активной разработке с 2015 года, поэтому некоторые функции могут быть устаревшими.
mETL — это инструмент Python ETL, который автоматически создает файл YAML для извлечения данных из заданного файла и загрузки их в базу данных SQL. Это немного больше рук-по сравнению с некоторыми другими описанными здесь пакетами, но может работать с широким спектром источников данных и целевых объектов, включая стандартные плоские файлы, таблицы Google и полный набор диалектов SQL (включая Microsoft SQL Server). Недавние обновления предоставили некоторые настройки для обхода замедления, вызванного некоторыми драйверами Python SQL,так что это может быть пакет для вас, если вам нравится, что ваш процесс ETL похож на Python, но быстрее.
Обратное заполнение (backfilling) исторических данных
Еще одно важное преимущество использования временной метки в качестве ключа партиционирования — легкость обратного заполнения данных. Если ETL-пайплайн уже построен, то он рассчитывает метрики и измерения наперед, а не ретроспективно. Часто нам бы хотелось посмотреть на сложившиеся тренды путем расчета измерений в прошлом — этот процесс и называется backfilling.
Backfilling настолько распространен, что в Hive есть встроенная возможность динамического партиционирования, чтобы выполнять одни и те же SQL запросы по нескольким партициям сразу. Проиллюстрируем эту идею на примере: пусть требуется заполнить количество бронирований по каждому рынку для дашборда, начиная с earliest_ds и заканчивая latest_ds. Одно из возможных решений выглядит примерно так:
Такой запрос возможен, однако он слишком громоздкий, поскольку мы выполняем одну и ту же операцию, только над разными партициями. Используя динамическое партиционирование мы можем все упростить до одного запроса:
Отметим, что мы добавили ds в SELECT и GROUP BY выражения, расширили диапазон в операции WHERE и изменили синтаксис с PARTITION (ds= '>') на PARTITION (ds). Вся прелесть динамического партиционирования в том, что мы обернули GROUP BY ds вокруг необходимых операций, чтобы вставить результаты запроса во все партиции в один заход. Такой подход очень эффективен и используется во многих пайплайнах в Airbnb.
Теперь, рассмотрим все изученные концепции на примере ETL джобы в Airflow.
pandas
Pandas , пожалуй, наиболее широко используемый набор инструментов для обработки и анализа данных во вселенной Python. Благодаря постоянному развитию и удивительно интуитивно понятному API, в pandas можно делать все, что угодно.
Вот пример, в котором мы извлекаем данные из файла CSV, применяем некоторые преобразования данных и загружаем их в базу данных PostgreSQL:
Однако есть загвоздка. Pandas разработан в первую очередь как инструмент анализа данных. Таким образом, он делает все в памяти и может работать довольно медленно, если вы работаете с большими данными. Это был бы хороший выбор для создания экспериментального конвейера ETL, но если вы хотите запустить в производство большой конвейер ETL, этот инструмент, вероятно, не для вас.
Моделирование данных, нормализация и схема «звезды»
В процессе построения качественной аналитической платформы, главная цель дизайнера системы — сделать так, чтобы аналитические запросы было легко писать, а различные статистики считались эффективно. Для этого в первую очередь нужно определить модель данных.
В качестве одного из первых этапов моделирования данных необходимо понять, в какой степени таблицы должны быть нормализованы. В общем случае нормализованные таблицы отличаются более простыми схемами, более стандартизированными данными, а также исключают некоторые типы избыточности. В то же время использование таких таблиц приводит к тому, что для установления взаимоотношений между таблицами требуется больше аккуратности и усердия, запросы становятся сложнее (больше JOIN-ов), а также требуется поддерживать больше ETL джобов.
С другой стороны, гораздо легче писать запросы к денормализованным таблицам, поскольку все измерения и метрики уже соединены. Однако, учитывая больший размер таблиц, обработка данных становится медленнее (“Тут можно поспорить, ведь все зависит от того, как хранятся данные и какие запросы бывают. Можно, к примеру, хранить большие таблицы в Hbase и обращаться к отдельным колонкам, тогда запросы будут быстрыми” — прим. пер.).
Среди всех моделей данных, которые пытаются найти идеальный баланс между двумя подходами, одной из наиболее популярных (мы используем ее в Airbnb) является схема «звезды». Данная схема основана на построении нормализованных таблиц (таблиц фактов и таблиц измерений), из которых, в случае чего, могут быть получены денормализованные таблицы. В результате такой дизайн пытается найти баланс между легкостью аналитики и сложностью поддержки ETL.

Bonobo
Если вам нравится работать с Python, вы не хотите изучать новый API и хотите создавать полусложные масштабируемые конвейеры ETL, Bonobo может быть именно тем, что вам нужно.
Bonobo имеет инструменты ETL для создания конвейеров данных, которые могут обрабатывать несколько источников данных параллельно, и имеет расширение SQLAlchemy (в настоящее время в альфа-версии), которое позволяет подключать конвейер напрямую к базам данных SQL.
Эта структура должна быть доступна для всех, кто имеет базовый уровень владения Python, и включает в себя визуализатор графа процесса ETL, который упрощает отслеживание вашего процесса. Кроме того, вы можете начать работу в течение 10 минут благодаря превосходно написанному руководству.
Вот базовый конвейер Bonobo ETL, адаптированный из учебника. Обратите внимание, что все это просто функция или генератор Python.
Вы можете связать эти функции вместе в виде графика (исключенного здесь для краткости) и запустить его в командной строке как простой файл Python, например, $ python my_etl_job.py .
Одна из проблем заключается в том, что Bonobo еще не до версии 1.0, и их Github не обновлялся с июля 2019 года. Кроме того, документация утверждает, что Bonobo находится в стадии интенсивной разработки и может быть не полностью стабильной. Таким образом, Bonobo может быть хорошей основой для быстрого создания небольших конвейеров, но может быть не лучшим долгосрочным решением, по крайней мере, до выпуска версии 1.0.
Если вы взглянули на Airflow и считаете, что он слишком сложен для того, что вам нужно, и вам не нравится идея писать всю логику ETL самостоятельно, Mara может быть для вас хорошим вариантом. Mara характеризуется, как «легковесная самодостаточная среда ETL, находящуюся на полпути между простыми скриптами и Apache Airflow».
Mara снижает сложность вашего конвейера ETL, делая некоторые предположения. Вот некоторые из них: 1) у вас должен быть PostgreSQL в качестве механизма обработки данных, 2) вы используете декларативный код Python для определения ваших конвейеров интеграции данных, 3) вы используете командную строку в качестве основного инструмента для взаимодействия с вашими базами данных, и 4) вы используете их красиво оформленный веб-интерфейс (который можно вставить в любое приложение Flask) в качестве основного инструмента для проверки, запуска и отладки ваших конвейеров.
Вот демонстрационный Mara-конвейер, который трижды проверяет локальный хост:
Обратите внимание, что документация все еще находится в стадии разработки, и что Mara изначально не работает в Windows. Однако он все еще находится в активной разработке, поэтому, если вы хотите что-то среднее между двумя крайностями, упомянутыми выше, попробуйте Mara.
Как помогает ETL в работе дата-аналитика
В ERP-системах обычно творится бардак, который годами никто не может разобрать. Именно для структурирования этого бардака и была создана ETL.
Функции фреймворка заключаются в следующих действиях для разгребания ненужного мусора и поиска стоящих крупиц информации:
- найти случайные ошибки, появившиеся при вводе или переносе данных, а может быть, возникшие из-за багов;
- находить отличия в справочниках и детализациях между смежными IT-системами.
ETL автоматически приводит всю информацию к единой системе значений. Она дает надежность и обеспечивает качество данных для конечного пользователя. С помощью фреймворка можно проследить, из каких исходных данных сформировалось получившееся значение.
Следующий список дает знания начинающему аналитику о том, как работает ETL-система:
- подгружается информация из выбранных источников. Эта процедура нужна для затягивания в фреймворк информации произвольного качества. Главное на этом шаге — сверить суммы пришедших строк. Если получится, что в исходной системе строк больше, чем в Raw Data, то это значит, что где-то есть ошибки;
- она очищается от ошибок. Этот шаг дает возможность упорядочить полученные данные и исключить из них не валидную информацию;
- определяется соответствие данных и справочников. К утвержденной таблице пристраивается еще один тип столбцов, количество которых равно количеству справочников ЦС;
- происходит консолидация от транзакций до агрегатов;
- готовая информация выгружается в ЦС;
- происходит детализация.
Таким образом работает ETL-фреймворк.

Pygrametl
Pygrametl описывает себя как «среду Python, которая предлагает часто используемые функции для разработки процессов извлечения-преобразования-загрузки (ETL)». Впервые он был создан еще в 2009 году и с тех пор постоянно обновляется.
Pygrametl предоставляет объектно-ориентированные абстракции для часто используемых операций, таких как взаимодействие между различными источниками данных, запуск параллельной обработки данных или создание схем снежинок. Поскольку это фреймворк, вы можете легко интегрировать его с другим кодом Python. Действительно, в документации говорится, что он используется в производственных системах в секторах транспорта, финансов и здравоохранения.
Учебное пособие для начинающих невероятно всеобъемлющее и проведет вас через создание собственного мини-курса хранилищ данных с таблицами, содержащими стандартные размеры, SlowlyChangingDimensions и SnowflakedDimensions.
В приведенном ниже примере мы создаем FactTable для книжного магазина с подробным описанием того, какие книги были проданы и в какое время:
Одним из потенциальных недостатков является то, что эта библиотека существует уже более десяти лет, но еще не приобрела широкой популярности. Это может указывать на то, что на практике это не так удобно. Однако pygrametl работает как в CPython, так и в Jython, поэтому он может быть хорошим выбором, если у вас есть существующий код Java и/или драйверы JDBC в конвейере обработки ETL.
Таблицы фактов и таблицы измерений
Чтобы лучше понять, как строить денормализованные таблицы из таблиц фактов и таблиц измерений, обсудим роли каждой из них:
Таблицы фактов чаще всего содержат транзакционные данные в определенные моменты времени. Каждая строка в таблице может быть чрезвычайно простой и чаще всего является одной транзакцией. У нас в Airbnb есть множество таблиц фактов, которые хранят данные по типу транзакций: бронирования, оформления заказов, отмены и т.д.
Таблицы измерений содержат медленно меняющиеся атрибуты определенных ключей из таблицы фактов, и их можно соединить с ней по этим ключам. Сами атрибуты могут быть организованы в рамках иерархической структуры. В Airbnb, к примеру, есть таблицы измерений с пользователями, заказами и рынками, которые помогают нам детально анализировать данные.
Ниже представлен простой пример того, как таблицы фактов и таблицы измерений (нормализованные) могут быть соединены, чтобы ответить на простой вопрос: сколько бронирований было сделано за последнюю неделю по каждому из рынков?
Еще быстрее. GNU parallel
В качестве дополнительной вишенки на торте — параллелизация исполнения скриптов в shell. Все инструменты есть в ОС, просто пишите скрипт и бейте задачу. Все остальное — удел операционной системы. Можно начинать читать с разных мест, например с «Get more done at the Linux command line with GNU Parallel»
Экспериментальные наблюдения показали, что сочетание различных методов, упомянутых в публикации, может привести к двум результатам:
Многие начинающие аналитики не могут полностью разобраться, зачем нужно изучать ETL. Многим известны общие принципы работы с системой, так как они включают в себя действия: извлечение, преобразование, загрузку. Эти принципы понятны многим, кто изучает мир Big Data аналитики. А вот концепцию не всегда учащиеся, да и некоторые специалисты, схватывают сразу. Сегодня поговорим об этой системе более подробно.
ETLAlchemy
Этот легкий инструмент Python ETL позволяет выполнять миграцию между любыми двумя типами СУБД всего за 4 строки кода. ETLAlchemy может перенести вас от MySQL к SQLite, от SQL Server к Postgres или любой другой разновидности комбинаций.
Вот код в действии:
Довольно просто, да?
Последний раз Github обновлялся в январе 2019 года, но сообщает, что они все еще находятся в активной разработке. Если вы хотите быстро переходить между разными вариантами SQL, этот инструмент ETL может быть для вас.
(Результаты будут отличаться от приведенных выше, поскольку фид обновляется несколько раз в день).
Riko все еще находится в стадии разработки, поэтому, если вы ищете движок потоковой обработки, это может быть вашим ответом.
ETL: Extract, Transform, Load
Extract, Transform и Load — это 3 концептуально важных шага, определяющих, каким образом устроены большинство современных пайплайнов данных. На сегодняшний день это базовая модель того, как сырые данные сделать готовыми для анализа.

Extract. Это шаг, на котором датчики принимают на вход данные из различных источников (логов пользователей, копии реляционной БД, внешнего набора данных и т.д.), а затем передают их дальше для последующих преобразований.
Transform. Это «сердце» любого ETL, этап, когда мы применяем бизнес-логику и делаем фильтрацию, группировку и агрегирование, чтобы преобразовать сырые данные в готовый к анализу датасет. Эта процедура требует понимания бизнес задач и наличия базовых знаний в области.
Load. Наконец, мы загружаем обработанные данные и отправляем их в место конечного использования. Полученный набор данных может быть использован конечными пользователями, а может являться входным потоком к еще одному ETL.
Направленный ациклический граф (DAG)
Казалось бы, с точки зрения идеи ETL джобы очень просты, однако на деле они часто очень запутаны и состоят из множества комбинаций Extract, Transform и Load операций. В этом случае очень полезно бывает визуализировать весь поток данных, используя граф, в котором узел отображает операцию, а стрелка — взаимосвязь между операциями. Учитывая, что каждая операция выполняется единожды, а данные идут дальше по графу, то он является направленным и ациклическим, отсюда и название.

Одна из особенностей интерфейса Airflow — это наличие механизма, который позволяет визуализировать пайплайн данных через DAG. Автор пайплайна должен задать взаимосвязи между операциями, чтобы Airflow записал спецификацию ETL джоба в отдельный файл.
При этом помимо DAG-ов, которые определяют порядок запуска операций, в Airflow есть операторы, которые задают, что необходимо выполнить в рамках пайплайна. Обычно есть 3 вида операторов, каждый из которых имитирует один из этапов ETL-процесса:
- Сенсоры: открывают поток данных по истечении определенного времени, либо когда данные из входного источника становятся доступны (по аналогии с Extract).
- Операторы: запускают определенные команды (выполни Python-файл, запрос в Hive и т.д.). По аналогии с Transform, операторы занимаются преобразованием данных.
- Трансферы: переносят данные из одного места в другое (как и на стадии Load).
Etlpy
Etlpy — это библиотека Python, предназначенная для оптимизации конвейера ETL, который включает в себя парсинг веб-страниц и очистку данных.Однако большая часть документации на китайском языке, поэтому он может не подойти вам, если вы не говорите по-китайски или не привыкли полагаться на Google Translate. Etlpy предоставляет графический интерфейс для разработки поисковых роботов / парсеров и инструментов для очистки данных. Создав инструмент, вы можете сохранить его как файл XML и передать его в механизм etlpy., который, по-видимому, предоставляет словарь Python в качестве вывода. Это может быть ваш выбор, если вы хотите извлечь большой объем данных, использовать для этого графический интерфейс и говорить по-китайски.
Locopy
Capital One создал мощный инструмент Python ETL с Locopy, который позволяет легко (раз) загружать и копировать данные в Redshift или Snowflake. API прост, понятен и выполняет свою работу.
Например, вот как вы можете загрузить данные из Redshift в CSV:
Он все еще активно поддерживается, поэтому, если вы ищете специально инструмент, который упрощает ETL с Redshift и Snowflake, обратите внимание на locopy.
Бинарный Excel ( .xslb )
Файлы в таком формате далеко не редкость. В чем причина его появления — сложно сказать. Объем не меньше, чем в xslx . Макросы и пр. для анализа не особо нужны. Формат формально проприетарный и закрытый.
Типовой сценарий — начинается поиск библиотек для работы с этим форматом. Даже если они и находятся, у этих библиотек возникает куча ограничение и сложностей.
Решение тривиальное. Ничто не работает с бинарным файлом лучше чем сам Excel. Так и преобразуйте на Windows машине с установленным офисом с помощью командной строки все xlsb в xlsx . Это можно делать руками или автоматически, как через COM на любом удобном языке, так и с помощью PowerShell. Примеры скрипта на PowerShell можно найти поиском, взять хотя бы этот.
Проблемы больше не существует.
PDF формат слабо пригоден для анализа. Формально — это контейнер, содержащий атомарные данные и инструкции для типографской машины по их размещению на листе. В нем сборище графических примитивов. Можно почитать спецификацию «Document management — Portable document format — Part 1: PDF 1.7». Однако PDF весьма популярен при публикации открытых данных различными компаниями, особенно гос.службами.
Какие прагматичные варианты есть? Не очень много.
- поиск утилит по стыковке DS инструмента с pdf напрямую, например, rOpenSci: The pdftools package;
- попытка ручной выгрузки из Adobe Reader содержания pdf файлов в текст с последующим парсингом этого текста;
- распознавание через OCR, выгрузка в форматы Word/Excel с последующей перегрузкой в текстовые форматы (если потребуется).
При немного набитой руке и поставленном процессе можно вытаскивать даже табличные данные сложные из сканов практически без ручной правки.
Проблема может и осталась, но объезжена и почти не брыкается.
Когда-то, в конце 90-х, этому формату прочили большое будущее. Даже БД на нем хотели строить. По факту все свалилось куда-то на обочину. Избыточно, крайне сложно, если все делать по-настоящему (c dtd). Но формат стал во многих областях де-факто средством кросс-обмена между программными компонентами или предоставления данных для публикации.
Штатный подход DS — загрузим все в память и распарсим дерево, а так делают «не задумываясь» большинство начинающих и некоторое количество слегка продолжающих, не приводит к успеху на данных чуть больше мизерных. Либо времени требует очень много, либо памяти не хватает. Ситуация усугубляется еще тем, что для анализа достаточно всего некоторого количества полей. Но даже если и удалось весь документ разобрать — обход многоуровневой вложенности циклами по распарсенному дереву на языке высокого уровня — типичный антипаттерн для ETL задач. Так делать совершенно не стоит.
Полагаете тема надумана? Для примера берем открытый «Единый реестр субъектов малого и среднего предпринимательства», ~6.5K XML файлов, ~46Гб сырых данных.
Какие есть альтернативы?
-
. Все круто, но писать обработчики событий для простого импорта данных — это как-то не совсем для аналитика данных задача.
- регулярки. Да-да, опять регулярки. Если нужно выдрать некоторые поля, которые легко идентифицируются, то регулярки могут дать прекрасный результат, особенно на этапе предварительного препроцессинга. ! Практика показывает, что почти никто из DS специалистов не знаком с этой технологией и даже о ней не слышал.
На самом деле XSLT / XPath из командной строки является единственным серьезным ответом в случае больших объемов и сложной разветвленной структуры. Все было в XML технологии продумано и структурировано до мелочей, а потом и стандартизировано. Но что-то где-то пошло не так.
За компактной сводкой по синтаксису и примерами кода можно обратиться, например, на
W3School.
Проблемы больше не существует, осталось только неудобство.
Json успешно заменяет формат xml, особенно в части обмена данными между отдельными модулями посредством REST API. В большинстве случаев эти структуры данных предназначены для разработчиков и их сложная нефиксированная древовидная структура доставляет много мучений аналитикам данных. Ведь для большинства алгоритмов и функций требуются либо матрицы либо прямоугольные таблицы ( data.frame ).
Типичный способ решения задачи преобразования иерархического json в data.frame — многоуровневые циклы. Такое решение плохо по множеству различных моментов:
- очень много кода и непонятных манипуляций;
- логика работы с данными перемешана с физическими манипуляциями;
- понять логику и отследить отработку всех веток порой очень сложно;
- включение проверок на возможные ошибки и некорректность входных данных кратно «раздувает» код и приводит почти к его полной нечитаемости;
- работает медленно и потребляем много оперативной памяти.
Типовой пример из окружающего нас информационного мира. Аналитика помарочного учета.
Собрать данные ветки childs в таблицу штатными функциями парсинга не удастся. Тут и иерархические вложенные массивы и дублирование имен параметров. Ничего удивительного — это же протокол M2M обмена, там цели совсем другие ставились.
Что делаем? Правильно, циклы. На выходе получается примерно такой код.
Можно было бы успокоиться, но мы сделаем еще пару шагов.
Шаг 1. json parser
Альтернативное решение, которое ни на каких курсах не рассказывают.
Смотрим на структуру. Похоже, что down по структуре дублирует up, проверяем гипотезу. Все верно, поэтому достанем только ветку down. Достаем специализированный парсер jq о котором знают и который используют многие системные администраторы, но с которым аналитики данных практически не знакомы. jq можно использовать где угодно, включая командную строку. Про jqr писал ранее в публикации «Швейцарский нож для обработки json»

И сам код трансформации в R
Все, в одну строчку получили чистое прямоугольное представление. Компактно, стабильно и очень быстро. Вот ссылки на базисные ресурсы по jq :
Шаг 2. Смотрим по сторонам
С упомянутыми инструментами почти никакой json вам не будет страшен, а стиль работы может измениться неузнаваемым образом.
Ну тут то многие вздохнут и скажут, что с этим нет проблем. И могут легко ошибиться.
Возьмем, для примера, практическую задачку. Миллионы «IoT» устройств (электросчетчики, например) фиксируют по расписанию показания своих регистров. И вот эта все сводка приходит вам в виде кучи файлов в весьма странном формате. А что, разработчики счетчиков тоже люди. Они хотели сделать как лучше. Но работаем мы с тем что есть.
Итак, вот пример входного файла:
Тут у нас есть все радости — и время представлено не в ISO формате и числа с разделителем десятичной части, отличающимся от системных настроек (обычно это точка). В довершение всего и знак стоит не там, где надо, почти как в SAP выгрузках. Штатные парсеры загрузчиков csv не помогут. Надо делать все самостоятельно. Итого, у стоит задача парсинга временнЫх и числовых показателей. Понятно, что это не проблема. Вопрос скорее в том, как сделать трансформацию со скоростями не меньше (или даже больше) штатной библиотеки импорта.
Построим генератор входных данных
Имеем ~5.8M записей — в целом, для теста сущие пустяки.
Типовой сценарий — воспроизвести логику загрузчика. Загрузить все как текст и потом построчно провести преобразование. Насколько эффективен этот способ? На это нельзя дать однозначный ответ. Сильно зависит от языка, навыков аналитики, используемых библиотек и особенности структуры данных и специфики предметной области.
Проводим загрузку данных, смотрим тайминги. Чтобы все везде было хорошо, именуйте файлы с использованием только цифр и латинского алфавита.
Инструменты, проверенные временем
Вот список инструментов, которые мы рекомендовали в прошлом, но сейчас они не находятся в активной разработке. Возможно, вам удастся их использовать в краткосрочной перспективе, но мы не советуем вам создавать что-либо большого размера из-за присущей им нестабильности из-за отсутствия разработки.
Data Engineering
Maxime Beauchemin, один из разработчиков Airflow, так охарактеризовал data engineering: «Это область, которую можно рассматривать как смесь бизнес-аналитики и баз данных, которая привносит больше элементов программирования. Эта сфера включает в себя специализацию по работе с распределенными системами больших данных, расширенной экосистемой Hadoop и масштабируемыми вычислениями».
Среди множества навыков инженера данных можно выделить один, который является наиболее важным — способность разрабатывать, строить и поддерживать хранилища данных. Отсутствие качественной инфраструктуры хранения данных приводит к тому, что любая активность, связанная с анализом данных, либо слишком дорога, либо немасштабируема.
Apache Airflow
Apache Airflow (или просто Airflow) — один из самых популярных инструментов Python для оркестровки рабочих процессов ETL. Сам он не обрабатывает данные, но вы можете использовать его для планирования, организации и мониторинга процессов ETL с помощью Python. Airflow был создан в Airbnb એ и используется многими компаниями по всему миру для выполнения сотен тысяч заданий в день.
С помощью Airflow вы строите рабочие процессы как направленные ациклические графы (DAG). Затем для максимальной эффективности планировщик распределяет задачи между множества процессоров. Для управления и редактирования ваших DAG есть удобный веб-интерфейс, а также хороший набор инструментов, которые упрощают выполнение «операции из командной строки .
Вот простой DAG, адаптированный из учебника для начинающих, который запускает пару простых команд bash каждый день:
Airflow — это Ferrari инструментов Python ETL. Он действительно может все. Но за такую расширяемость приходится платить. Это может быть немного сложно для начинающих пользователей (несмотря на их отличную документацию и учебные пособия) и может быть больше, чем вам нужно прямо сейчас. Если вы хотите немедленно запустить процесс ETL, может быть лучше выбрать что-нибудь попроще. Но если у вас есть время и деньги, ваш единственный предел — ваше воображение, если вы работаете с Airflow.
Из чего состоит фреймворк ETL и с чем его «едят»
ETL — важнейший компонент бизнес-аналитики. Фреймворк ETL эксплуатируют для внедрения большого количества информационных систем. Это делается для их уникализации и анализа хранения данных.
Опытные аналитики знают, что есть много готовых ETL. Они выполняют функции загрузки данных в корпоративные хранилища. Ниже перечислены только некоторые из этих ETL:
- Informatica PowerCenter;
- Oracle Data Integrator;
- SAP Data Services;
- Talend Open Studio.
На практике эти коробочные решения не приносят эффективных результатов. Поэтому Data-аналитики стараются изобрести свой конвейер доставки и обработки информации.
Давайте посмотрим, почему так происходит. Возьмем обычный комплекс задач для аналитика:
- Сделать выборку данных из реляционных СУБД.
- Обработать полученные данные и сохранить в таблицу Apache Hive.
Чтобы выполнить эту задачу, дата-аналитики применяют ETL-фреймворк.
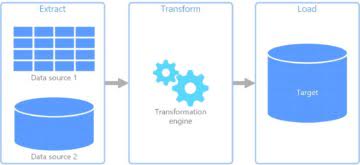
Luigi
Luigi — это WMS, созданная Spotify. Он позволяет создавать длительные и сложные конвейеры для пакетных заданий и обрабатывать всю сантехнику, обычно связанную с ними (следовательно, он назван в честь второго по величине сантехника в мире).
Luigi поставляется с веб-интерфейсом, который позволяет пользователю визуализировать задачи и обрабатывать зависимости. Концептуально он похож на GNU Make, но предназначен не только для Hadoop (хотя и упрощает работу с Hadoop). Кроме того, создавать рабочие процессы довольно просто, поскольку все они являются просто классами Python.
Вот схема того, как выглядит типичная задача (адаптировано из документации ). Ваш конвейер ETL состоит из множества таких задач, связанных вместе.
Хотя пакет регулярно обновляется, он не так активно развивается, как Airflow, а документация устарела, так как она завалена кодом Python 2. Если вы справитесь с этим, Luigi может стать вашим инструментом ETL, если у вас есть большие, длительные задания с данными, которые просто нужно выполнить.
Какой ETL-фреймворк выбрать?
В мире batch-обработки данных есть несколько платформ с открытым исходным кодом, с которыми можно попробовать поиграть. Некоторые из них: Azkaban — open-source воркфлоу менеджер от Linkedin, особенностью которого является облегченное управление зависимостями в Hadoop, Luigi — фреймворк от Spotify, базирующийся на Python и Airflow, который также основан на Python, от Airbnb.
У каждой платформы есть свои плюсы и минусы, многие эксперты пытаются их сравнивать (смотрите тут и тут). Выбирая тот или иной фреймворк, важно учитывать следующие характеристики:

Конфигурация. ETL-ы по своей природе довольно сложны, поэтому важно, как именно пользователь фреймворка будет их конструировать. Основан ли он на пользовательском интерфейсе или же запросы создаются на каком-либо языке программирования? Сегодня все большую популярность набирает именно второй способ, поскольку программирование пайплайнов делает их более гибкими, позволяя изменять любую деталь.
Мониторинг ошибок и оповещения. Объемные и долгие batch запросы рано или поздно падают с ошибкой, даже если в самой джобе багов нет. Как следствие, мониторинг и оповещения об ошибках выходят на первый план. Насколько хорошо фреймворк визуализирует прогресс запроса? Приходят ли оповещения вовремя?
Обратное заполнение данных (backfilling). Часто после построения готового пайплайна нам требуется вернуться назад и заново обработать исторические данных. В идеале нам бы не хотелось строить две независимые джобы: одну для обратного а исторических данных, а вторую для текущей деятельности. Насколько легко осуществлять backfilling c помощью данного фреймворка? Масштабируемо и эффективно ли полученное решение?
Как используется ETL дата-аналитиками
Для работы с описанной выше задачей используется два типа решений посредством фреймворка ETL. Первый из них — это потоковая обработка информации. Ее еще называют Stream. Для работы с потоковой обработкой информации используют инструмент Apache Ni Fi.
А вот для работы с пакетной обработкой подходит Apache Airflow. Это open-source-набор библиотек планирования и мониторинга процессов работы. Разработанный на Python, Apache Airflow помогает формировать и устанавливать цепочки задач как визуально, так и в программном виде, с помощью прописывания кода.
Обработка данных
Ядром ETL является обработка данных. Хотя с этим справляется множество инструментов Python, некоторые из них специально разработаны для этой задачи. Давайте посмотрим на возможные варианты:
Заключение
Теперь вы знаете, что такое ETL-система и как она работает. Если вам понравилась тема Data-аналитики и вы желаете поглубже изучить ее, реализовать мечту помогут курсы от DevEducation.

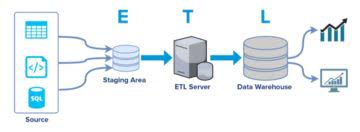
При создании хранилища данных, для их перемещения в это хранилище обязательно встанет вопрос об ETL એ (от англ. Extract, Transform, Load — дословно «извлечение, преобразование, загрузка»). Первоначально данные извлекаются из массивов различных источников. Затем необходимо сделать преобразования в формат, который нужен для использования данных в дальнейшем, и, наконец, происходит загрузка в свое хранилище данных.
Есть масса способов организовать это процесс, и один из них — использование языка программирования Python. Сообщество Python создало ряд инструментов для контроля над процессом и облегчения вашей жизни с ETL. Если есть время, деньги и терпение, использование Python обеспечит оптимизацию конвейера ETL в точном соответствии с потребностями вашего бизнеса.
Исходя из этих соображений, вот вам лучшие инструменты Python ETL на 2021 год. Некоторые из них позволяют управлять каждым этапом процесса ETL, в то время как другие превосходны только на отдельных этапах. Для того, что бы было легче сравнивать они разделены на группы.
Для анализа и машинного обучения данных много требуется. Можно было бы собрать их самостоятельно, но это крайне утомительно. Тут на помощь приходят готовые датасеты в самых разных категориях:
Маленький, но мощный
Следующие ниже инструменты Python ETL не являются полноценными решениями ETL, но предназначены для выполнения тяжелой работы на определенной части процесса. Если вы смешиваете много инструментов, подумайте о добавлении одного из следующих.
Это может быть наградой за лучшую маленькую библиотеку ETL на свете. Odo имеет одну функцию — odo, и одну цель: легко переносить данные между разными контейнерами. Он также работает с небольшими контейнерами в памяти и большими контейнерами вне ядра.
Функция принимает два аргумента odo (источник, цель) и преобразует источник в цель. Итак, чтобы преобразовать кортеж (1, 2, 3) в список, выполните:
Или для перехода между HDF5 и PostgreSQL выполните:
Odo работает под капотом, соединяя разные типы данных через путь/сеть преобразований (hodos означает «путь» по-гречески), поэтому, если один путь не работает, может быть другой способ выполнить преобразование.
Более того, odo использует собственные возможности загрузки CSV баз данных на основе SQL, которые значительно быстрее, чем при использовании чистого Python. Документация показывает, что Odo в 11 раз быстрее, чем чтение вашего CSV-файла в pandas, а затем его отправка в базу данных. Если вы обнаружите, что загружаете много данных из CSV в базы данных SQL, odo может стать для вас инструментом ETL.
Обратите внимание, что Github не обновлялся несколько лет, поэтому odo может быть не полностью стабильным. Но многие файловые системы обратно совместимы, так что это не может быть проблемой.
Числовые показатели. Немного трюков
Формат, конечно, не очень удобный. Штатный парсер такую подачу не берет. Задача нормализации строки тривиальная, легко решается заменами или регулярками. Фактически, надо
- знак - перенести вперед (или вообще исключить, по технической сути задачи все данные только на убыль);
- привести десятичный разделить к виду, требуемому для работы функций преобразования.
Насчет десятичного разделителя, увы, нет четкого стандарта. Рекомендуемые символы — . или , , встретить можно и то и другое. В R точка является штатным разделителем, поэтому приводим к нему. Пропускаем базовые методы, берем пакет stringr и преобразуем подобным образом:
На этом можно было бы остановится и большинство делают именно так. Но попробуем сделать еще пару шагов.
Шаг 1. Использование форматного сканера.
Большинство функций форматного ввода данных в различных языках берут начало от C-шной функции printf() , либо просто являются интерфейсом к ее реализации. Однако, в C существует и обратная функция scanf() — форматный ввод. Т.е. можно не заниматься модификацией исходной строки, а модифицировать настройки парсера. В R есть различные функции парсинга, настройка decimal separator может различаться: настройка локали ОС, настройка опций R, передача параметром в функцию. Рассмотрим далее readr::parse_number .
Шаг 2. Смотрим по сторонам.
Итого, подводим итоги. Оценим временной вклад, который дает предварительное преобразование строки на векторе в 100k значений.
Теперь прогоним различные тесты с учетом базового сценария и шагов 1 и 2.
Видно, что подход настройки параметров парсера лидирует на таком объеме, если числа действительно приходят в кривоватом формате (нет менеджмента памяти!). Базовый же подход самый неудачный. Но на правильных данных, когда не будет накладных на преобразование строк, использование современной библиотеки SIMD парсинга может дать выигрыш, особенно на больших датасетах, на порядок и больше. Тут уже будет все зависеть от числа доступных ядер процессора, объема данных и т.д. Чем всего больше, тем существеннее разница.
Отметим, что отдельные группы разработки ПО оперативно «перескочили» на парсер fast_float , в частности в ПО Apache Arrow, Yandex ClickHouse and by Google Jsonnet, Microsoft LightGBM framework и получили значительное повышение скорости работы.
Вот так вот. Вы на какой стороне? Черной, белой или зеленой?
Как только мы договорились, что фаза предварительной подготовки данных и фаза аналитики разведены, можно ни в чем себе не отказывать. Большое количество задач по предварительному процессингу может быть выполнено утилитами командной строки. Зачастую это будет даже быстрее, чем поднимать DS инструменты. Тут и построчный анализ и работа с фиксированным буфером без пула операций менеджмента памяти и оптимизированные *nix библиотеки и устранение всяких байндингов и механизм передачи результатов посредством пайпов, без обращения к диску.
Там, конечно, тоже все нетривиально и есть масса подводных камней. Вот интересный список ссылок, которые высвечивают фонариком разные аспекты в формате попурри. И книги и «полудетективные истории».
Партиционирование данных по временной метке
Сейчас, когда стоимость хранения данных очень мала, компании могут себе позволить хранить исторические данные в своих хранилищах, вместо того, чтобы выбрасывать. Обратная сторона такого тренда в том, что с накоплением количества данных аналитические запросы становятся неэффективными и медленными. Наряду с такими принципами SQL как «фильтровать данные чаще и раньше» и «использовать только те поля, которые нужны», можно выделить еще один, позволяющий увеличить эффективность запросов: партиционирование данных.
Основная идея партиционирования весьма проста — вместо того, чтобы хранить данные одним куском, разделим их на несколько независимых частей. Все части сохраняют первичный ключ из исходного куска, поэтому получить доступ к любым данным можно достаточно быстро.
В частности, использование временной метки в качестве ключа, по которому проходит партиционирование, имеет ряд преимуществ. Во-первых, в хранилищах типа S3 сырые данные часто сортированы по временной метке и хранятся в директориях, также отмеченных метками. Во-вторых, обычно batch-ETL джоб проходит примерно за один день, то есть новые партиции данных создаются каждый день для каждого джоба. Наконец, многие аналитические запросы включают в себя подсчет количества событий, произошедших за определенный временной промежуток, поэтому партиционирование по времени здесь очень кстати.
Простой пример
Ниже представлен простой пример того, как объявить DAG-файл и определить структуру графа, используя операторы в Airflow, которые мы обсудили выше:
Когда граф будет построен, можно увидеть следующую картинку:

Итак, надеюсь, что в данной статье мне удалось максимально быстро и эффективно погрузить вас в интересную и многообразную сферу — Data Engineering. Мы изучили, что такое ETL, преимущества и недостатки различных ETL-платформ. Затем обсудили моделирование данных и схему «звезды», в частности, а также рассмотрели отличия таблиц фактов от таблиц измерений. Наконец, рассмотрев такие концепции как партиционирование данных и backfilling, мы перешли к примеру небольшого ETL джоба в Airflow. Теперь вы можете самостоятельно изучать работу с данными, наращивая багаж своих знаний. Еще увидимся!
Роберт отмечает недостаточное количество программ по data engineering в мире, однако мы таковую проводим, и уже не в первый раз. В октябре у нас стартует Data Engineer 3.0, регистрируйтесь и расширяйте свои профессиональные возможности!

Кадр из фильма «Индиана Джонс: В поисках утраченного ковчега» (1981)
Наблюдаемая все чаще и чаще картина в задаче анализа данных вызывает удручающее впечатление. Intel, AMD и другие производители непрерывно наращивают вычислительную мощность. Гениальные математики-программисты пишут суперэффективные библиотеки и алгоритмы. И вся эта мощь гасится и распыляется рядовыми аналитиками и разработчиками. Причем начинается это все с нулевого этапа — этап подготовки и загрузки данных для анализа. Многочисленные вопросы и диалоги показывают, что в нынешних программах обучения зияют огромные дыры. Людям просто незнакомы многие концепции и инструменты, уже давно придуманные для этих задач. Для тех, кто хочет увеличить свою продуктивность, далее тезисно будут рассмотрены ряд таких подходов и инструментов в частичной привязке к реальным задачам.
В первую очередь, материал ориентирован на аналитиков, которые манипулируют разумными объемами данных, необходимых для решения практических задач. ETL из Бигдаты в котором перекачиваются сотни Тб ежесуточно живет своей отдельной жизнью.
Разграничим задачи анализа данных на два больших класса:
- периодический информационный обмен между ИТ системами и DS контуром;
- эпизодический обмен или ad-hoc аналитика.
Технологически сильно больших различий между этими классами нет за исключением того, что при периодическом обмене вы можете дополнительно настоять на получении в аналитический контур машиночитаемых форматов в валидированном виде. При эпизодическом обмене вы можете получать на вход совершенно любые носители и представления и форматы. Бумажные носители или их скан также не являются исключением.
Ключевые ошибки в работе с такими грязными данным можно свести к следующим:
- попытка автоматизировать неформализуемый хаос и смешать все в одной кастрюле;
- попытка решать все одним инструментом на котором, к тому же, говорят «со словарем»;
- использование циклов N-ой степени вложенности на языках высокого уровня.
С точки зрения бизнеса задача предварительной обработки данных не несет никакой ценности. Задача преобразования данных в удобочитаемый формат и задача аналитики должны быть физически разнесены. Преобразование входных файлов в пригодный формат проводится однократно, аналитика же на этих данных может проводиться многократно. Типичная ошибка — когда в один пайп смешиваются задачи загрузки исходников из непригодных форматов (сложные скрипты, огромное время) и аналитика.
В зависимости от задач и объемов, преобразованные данные могут размещаться в локальные файлы, в БД, в облако — да куда угодно. Ключевое требование — минимальное время загрузки в RAM и возможность выборочной загрузки для больших объемов.
Важным эффектом от такого разделения — выполнение аналитики в совершенно чистом пространстве. Все проблемы, утечки памяти, резервы ресурсов и пр., случившиеся на этапе преобразования забыты после завершения этого процесса. У вас на руках только чистые входные данные — можно решать основную задачу.
Работать с текстовыми данными в R достаточно удобно. Однако, утечка памяти, на которую могут жаловаться в случае процессинга текстовых данных, скорее всего бывает связана со спецификой архитектуры R — наличие global string pool . Судя по анализу памяти, даже после удаления текстовой переменной и вызова gc() , сама строка остается в пуле — для внешнего наблюдателя «память течет». Это ни хорошо и ни плохо. Это архитектура среды, которую в задаче ETL можно обойти просто выполнения независимых блоков препроцессинга в отдельных процессах ОС, например, используя пакет callr . Терминируя процесс после выполнения возложенных задач, ОС получает всю использованную оперативную память обратно до последнего байта.
Задача препроцессинга заканчивается генерацией чистых форматов. Сохранять данные можно разными способами. Если данных чуть больше чем много, то сохранять надо исключительно в бинаризированном виде (БД или файлы) и никаких CSV. При сохранении в БД надо учитывать еще большие накладные расходы на передачу по сети. Так что, если это локальный промежуточный шаг, то оптимально сбрасывать все в локальные файлы, используя, в зависимости от задач только быстрые библиотеки и алгоритмы:
-
— кроссплатформенное хранение, есть возможность частичной выборки и фильтрации данных еще на этапе загрузки; — табличное хранение для ограниченного количества типов с возможностью частичной загрузки требуемых колонок; — сериализованная выгрузка любых объектов R.
Ниже посмотрим, что можно сделать в отдельных случаях. Смотрим по умолчанию в контексте эпизодической ad-hoc аналитики, хотя большинство решений может быть применено и в потоковом продуктивном контуре.
Советы от опытных дата-аналитиков
Опытные аналитики рекомендуют при создании процесса загрузки оглядываться на потребности бизнеса. Если получается так, что загружаться данные будут неделю, а бизнесу требуется готовая аналитика через пять дней, то необходимо все снести и поставить на загрузку информацию заново, так как чуда не случится и, возможно, вы не впишетесь в указанные сроки.
Так как информация может загружаться волнами, рекомендуется сделать технический справочник под названием «Период загрузки», где будут изолированы процессы загрузки от разных периодов. Это нужно, чтобы не потерять историю изменения данных.
Необходимо всегда сохранять несколько версий работы. Например, начальную, рабочую и финальную. Таким образом дата-аналитик избежит путаницы в получаемых данных.
Получаемая информация всегда будет содержать какие-то ошибки. Поэтому постоянно перезагружать пакет из 100 гигабайт будет очень неэкономично. Рекомендуется делить этот пакет на небольшие части и проводить постепенную загрузку с постоянным обновлением. Опытные дата-аналитики советуют завести систему «файл-источник» и установить к нему интерфейс, который позволит снести документ, содержащий ошибки.
2 парадигмы: SQL против JVM
Как мы выяснили, у компаний есть огромный выбор того, какие инструменты использовать для ETL, и для начинающего data scientist-а не всегда понятно, какому именно фреймворку посвятить время. Это как раз про меня: в Washington Post Labs очередность джобов осуществлялась примитивно, с помощью Cron, в Twitter ETL джобы строились в Pig, а сейчас в Airbnb мы пишем пайплайны в Hive через Airflow. Поэтому перед тем, как пойти в ту или иную компанию, постарайтесь узнать, как именно организованы ETL в них. Упрощенно, можно выделить две основные парадигмы: SQL и JVM-ориентированные ETL.
JVM-ориентированные ETL обычно написаны на JVM-ориентированном языке (Java или Scala). Построение пайплайнов данных на таких языках означает задавать преобразования данных через пары «ключ-значение», однако писать пользовательские функции и тестировать джобы становится легче, поскольку не требуется использовать для этого другой язык программирования. Эта парадигма весьма популярна среди инженеров.
SQL-ориентированные ETL чаще всего пишутся на SQL, Presto или Hive. В них почти все крутится вокруг SQL и таблиц, что весьма удобно. В то же время написание пользовательских функций может быть проблематично, поскольку требует использования другого языка (к примеру, Java или Python). Такой подход популярен среди data scientist-ов.
Поработав с обеими парадигмами, я все-таки предпочитаю SQL-ориентированные ETL, поскольку, будучи начинающим data scientist-ом, намного легче выучить SQL, чем Java или Scala (если, конечно, вы еще с ними не знакомы) и сконцентрироваться на изучении новых практик, чем накладывать это поверх изучения нового языка.
Spark
Apache Spark — это единый аналитический движок для крупномасштабной обработки данных. В отличие от pandas, Spark предназначен для работы с огромными наборами данных на огромных кластерах компьютеров. Технически Spark не является инструментом Python, но PySpark API упрощает обработку заданий Spark в рабочем процессе Python. Это позволяет писать кратко, читабельно,и совместно используемый код для заданий ETL произвольного размера.
Вот пример кода, показывающий, как инициализировать сеанс Spark, читать в CSV, применять некоторые преобразования и записывать в другой CSV:
Очевидно, Spark может делать гораздо больше, чем просто читать и писать в файлы CSV, но это дает вам представление о его интуитивно понятном API. Подумайте о Spark, если вам нужна скорость и объем операций с данными.
Python ETL (petl) — это инструмент, в основе которого лежит простота использования и удобство. Если вы работаете со смешанными качественными, незнакомыми и разнородными данными, petl создан для вас! С помощью petl вы можете создавать таблицы на Python из различных источников данных (CSV, XLS, HTML, TXT, JSON и т.д.) И выводить их в желаемый формат хранения.
Petl ориентирован только на ETL. Таким образом, он более эффективен, чем pandas, поскольку он не загружает базу данных в память каждый раз, когда выполняет строку кода. С другой стороны, он не включает дополнительных функций, таких как встроенный анализ данных или визуализация.
Вот пример того, как читать в нескольких файлах CSV,объедините их вместе и запишите в новый файл CSV:
Petl все еще находится в активной разработке, но существует расширенная библиотека petlx , которая предоставляет расширения для работы с массивом различных типов данных. Одно предостережение: документация немного устарели и содержит некоторые опечатки. Зато у него солидная пользовательская база и хороший функционал. Если вы хотите сосредоточиться исключительно на ETL, petl может стать для вас инструментом Python.
Data Engineering
Maxime Beauchemin, один из разработчиков Airflow, так охарактеризовал data engineering: «Это область, которую можно рассматривать как смесь бизнес-аналитики и баз данных, которая привносит больше элементов программирования. Эта сфера включает в себя специализацию по работе с распределенными системами больших данных, расширенной экосистемой Hadoop и масштабируемыми вычислениями».
Среди множества навыков инженера данных можно выделить один, который является наиболее важным — способность разрабатывать, строить и поддерживать хранилища данных. Отсутствие качественной инфраструктуры хранения данных приводит к тому, что любая активность, связанная с анализом данных, либо слишком дорога, либо немасштабируема.
Зачем еще нужны ETL-фреймворки — примеры
Однако вышеописанными задачами и советами от дата-аналитиков целевые назначения ETL не заканчиваются. Этот фреймворк рассматривают как инструмент для переноса из разных источников в централизованный КХД.
Теперь давайте посмотрим один из примеров, когда используется ETL.
Принимают человека на работу. Разумеется, необходимо завести на него карточку во многих корпоративных системах. В крупных компаниях данным заданием занимаются специалисты, но работа их не скоординирована. В результате сотрудник долго не может получить собственную банковскую карту. А при увольнении сотрудников последние еще долго имеют доступ к своей рабочей электронной почте и другим благам организации. Естественно, это приводит к путанице, а в некоторых случаях конкуренты компании получают доступ к довольно долго остающейся открытой информации организации. ETL помогает быстро и эффективно решить эту проблему и закрыть дыры в структуре организации — вопрос добавления и удаления уволенных людей из БД в конкретном случае.
ETL-технологии дают возможность сделать автоматическим удаление аккаунтов человека из всех систем организации в случае увольнения без участия в этом отдела кадров. Вот как это происходит:
- В систему найма поступает информация о дате прекращения работы сотрудника в данной компании.
- Данные о начале процедуры блокировки его записи поступают контроллеру домена. Рабочая почта, все аккаунты сотрудника автоматически сохраняются и закрываются для доступа уволенного пользователя, а его электронная почта блокируется.
- Компания, которая увольняет сотрудника, может позволить себе полуавтоматический режим с отправкой заявления на блокировку в сервис технической поддержки штатного системного администратора.
Так на реальном примере работает ETL-система. Она позволяет, игнорируя человеческий фактор (ошибку или забывчивость), сделать за несколько дней или часов то, что обычные сотрудники будут делать в течение месяца.
Читайте также: