
Если в файле robots txt присутствуют директивы user agent и user agent googlebot то
1 сентября 2019 года Google прекратит поддержку нескольких директив в robots.txt. В список попали: noindex, crawl-delay и nofollow. Вместо них рекомендуется использовать:
Мета-тег noindex, как наиболее эффективный способ удалить страницу из индекса .
404 и 410 коды ответа сервера. В ряде случаев, 410 отрабатывает значительно быстрей для удаления URL из индекса.
Временное удаление страницы из индекса с помощью инструмента в Search Console.
Disallow в robots.txt.
Тем не менее, robots.txt по-прежнему остаётся одним из главных файлов для SEO-специалиста. Давайте вспомним самые полезные директивы от простых, до менее очевидных.
Расположение и области действия файла
Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, где расположен файл, а также протокола и номера порта, по которым доступен этот файл.
User-Agent
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определённые указания конкретному ему.
Если брать шире, то User-Agent — клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
User-agent: * — символ астериск используются для обозначения сразу же всех краулеров.
User-agent: Yandex — основной краулер Яндекс-поиска.
User-agent: Google-Image — робот поиска Google по картинкам.
User-agent: AhrefsBot — краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила.
В примере ниже краулер DuckDukcGo сможет сканировать папки сайта /api/ и /tmp/ , несмотря на астериск («звёздочку»), отвечающий за инструкции всем роботам.
Соответствие значения пути конкретным URL
Google использует значение пути в директивах allow и disallow , чтобы определить, должно ли правило применяться к определенному URL на сайте. Для этого правило сравнивается с компонентом пути в URL, данные по которому пытается получить поисковый робот. Символы, не входящие в набор 7-битных символов ASCII, можно указать в виде экранированных значений в кодировке UTF-8 (см. RFC 3986).
Google, Bing и другие крупные поисковые системы поддерживают определенные подстановочные знаки для путей:
- * обозначает 0 или более вхождений любого действительного символа.
- $ обозначает конец URL.
Соответствует всем путям, которые начинаются с /fish .
- /fish
- /fish.html
- /fish/salmon.html
- /fishheads
- /fishheads/yummy.html
- /fish.php?id=anything
- /Fish.asp
- /catfish
- /?id=fish
- /desert/fish
Аналогичен элементу /fish . Подстановочный знак игнорируется.
- /fish
- /fish.html
- /fish/salmon.html
- /fishheads
- /fishheads/yummy.html
- /fish.php?id=anything
Соответствует любым элементам в папке /fish/ .
- /fish/
- /animals/fish/
- /fish/?id=anything
- /fish/salmon.htm
Соответствует всем путям, которые содержат .php .
- /index.php
- /filename.php
- /folder/filename.php
- /folder/filename.php?parameters
- /folder/any.php.file.html
- /filename.php/
- / (хотя и соответствует /index.php)
- /windows.PHP
Соответствует всем путям, которые заканчиваются на .php .
- /filename.php?parameters
- /filename.php/
- /filename.php5
- /windows.PHP
Соответствует всем путям, которые содержат /fish и .php (именно в таком порядке).
- /fish.php
- /fishheads/catfish.php?parameters
Не соответствует: /Fish.PHP
Имеет ли значение регистр?
Определённо да. При указании правил Disallow / Allow, URL адреса могут быть относительными, но обязаны сохранять регистр.
Но сами директивы могут объявляться как с заглавной, так и с прописной: Disallow: или disallow: — без разницы. Исключение — Sitemap: всегда указывается с заглавной.
Синтаксис
Google поддерживает следующие поля:
- user-agent : агент пользователя робота, для которого применяется правило.
- allow : путь URL, который можно сканировать.
- disallow : путь URL, который запрещено сканировать.
- sitemap : полный URL файла Sitemap.
Поля allow и disallow также называются директивами. Они всегда задаются в формате directive: [path] , где значение [path] указывать необязательно. По умолчанию роботы могут сканировать весь контент. Они игнорируют директивы без [path] .
Значения [path] указываются относительно корневого каталога сайта, на котором находится файл robots.txt (используется тот же протокол, порт, хост и домен). Значение пути должно начинаться с символа / , обозначающего корневой каталог. Регистр учитывается. Подробнее о соответствии значения пути конкретным URL…
Duplex в интернете
Disallow
Директива, которая позволяет блокировать от индексации полностью весь сайт или определённые разделы.
Упростить инструкции помогают операторы:
* — любая последовательность символов в URL. По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *.
$ — символ в конце URL-адреса, он используется чтобы отменить использование * на конце правила.
Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента.
Действующие правила robots.txt
Роботы Яндекс и Google
У популярнейших поисковых систем присутствует большое количество роботов, и все они выполняют определенные функции. Благодаря robots.txt вы можете контролировать действия каждого из них. Но некоторые роботы держатся в секрете поисковыми системами. Ниже перечислены все публичные роботы Яндекса и Гугла с кратким описанием.
Роботы Яндекс:
Роботы Google:
- Googlebot. Это основной робот поискового гиганта, индексирующий главный текстовый контент страниц и обеспечивающий формирование органической выдачи.
- GoogleBot (Google Smartphone). Главный индексирующий бот Гугла для смартфонов и планшетов.
- Googlebot-News. Робот, индексирующий новостные публикации сайта.
- Googlebot-Video. Включает в поисковую выдачу видеофайлы.
- Googlebot-Image. Робот, занимающийся графическим контентом веб-ресурсов.
- AdsBot-Google. Проверяет качество целевых страниц – скорость загрузки, релевантность контента, удобство навигации и так далее.
- AdsBot-Google-Mobile-Apps. Оценивает качество мобильных приложений по тому же принципу, что и предыдущий бот.
- Mediapartners-Google. Робот контекстной рекламы, включающий сайт в индекс и оценивающий его для дальнейшего размещения рекламных блоков.
- Mediapartners-Google (Google Mobile AdSense). Аналогичный предыдущему бот, только отвечает за размещение релевантной рекламы для мобильных устройств.
Зачастую в файле Robots прописывают директории сразу для всех роботов поисковиков Google и Яндекс. Но для специфических задач оптимизаторы дают указания роботам разных поисковых систем отдельно.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Файл robots.txt необходим роботам поисковых систем, чтобы они могли понять, какие страницы и разделы сайта следует посещать и включать в индекс, а какие – не нужно. Запрещенные для посещения поисковыми ботами страницы не будут индексироваться и появляться в выдаче Яндекса, Google и прочих поисковиков.
Вот наглядный пример того, в чем разница между веб-ресурсом, у которого настроен файл robots, и сайтом без него:
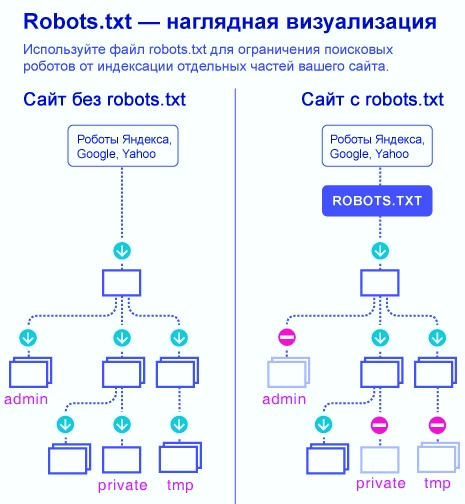
В данной статье я расскажу о нескольких способах правильной настройки robots.txt для популярного движка WordPress.
user-agent
Строка user-agent определяет, для какого робота применяется правило. Полный список поисковых роботов Google и строк для различных агентов пользователя, которые можно добавить в файл robots.txt, вы можете найти здесь.
Значение строки user-agent обрабатывается без учета регистра.
Распространенная ошибка
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже — слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот Crawl-delay, напротив, установлена только для него.
Mobile Apps Android
Проверяет качество рекламы в приложениях для устройств Android. Этот робот действует в соответствии с теми же правилами, что и AdsBot-Google .
Управление скоростью сканирования
Поисковые роботы Google посещают сайты с разными целями. Периодичность их появлений тоже отличается. Чтобы определить оптимальную частоту обработки каждого сайта, Google использует ряд алгоритмов. Если наш поисковый робот посещает ваш ресурс слишком часто, вы можете уменьшить частоту сканирования.
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Роботы Google бывают двух типов. Одни (поисковые) действуют автоматически и поддерживают стандарт исключений для роботов (REP). Это означает, что перед сканированием сайта они скачивают и анализируют файл robots.txt, чтобы узнать, какие разделы сайта для них открыты. Другие контролируются пользователями (например, собирают контент для фидов) или обеспечивают их безопасность (например, выявляют вредоносное ПО). Они не следуют этому стандарту.
Запрет сканирования определенного файла
Полная блокировка доступа к хосту
Googlebot Image
Группировка строк и правил
Вы можете группировать правила, которые применяются для разных агентов пользователя. Просто повторите строки user-agent для каждого поискового робота.
В этом примере есть четыре группы правил:
- первая – для агента пользователя "a";
- вторая – для агента пользователя "b";
- третья – одновременно для агентов пользователей "e" и "f";
- четвертая – для агента пользователя "h".
Техническое описание группы вы можете найти в разделе 2.1 этого документа.
Feedfetcher
Советы по использованию операторов
Как упоминалось выше, широко применяются два оператора: * и $ . С их помощью можно:
1. Заблокировать определённые типы файлов.
В примере выше астериск * указывает на любые символы в названии файла, а оператор $ гарантирует, что расширение .json находится точно в конце адреса, и правило не затрагивает страницы вроде /locations.json.html (вдруг есть и такие).
2. Заблокировать URL с параметром ? , после которого следуют GET-запросы (метод передачи данных от клиента серверу).
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET-параметрами точно являются дублями.
Заблокировать результаты поиска, но не саму страницу поиска.
Примеры
Сопоставление полей user-agent
Поисковые роботы выберут нужные группы следующим образом:
Группировка правил
Если в файле robots.txt есть несколько групп для определенного агента пользователя, выполняется внутреннее объединение этих групп. Пример:
Поисковые роботы объединяют правила с учетом агента пользователя, как указано в примере кода ниже.
Парсер для файлов robots.txt игнорирует все правила, кроме следующих: allow , disallow , user-agent . В результате указанный фрагмент файла robots.txt обрабатывается как единая группа и правило disallow: / : влияет как на user-agent a , так и на b :
При обработке правил в файле robots.txt поисковые роботы игнорируют строку sitemap . Например, вот как роботы обработали бы приведенный выше фрагмент файла robots.txt:
Динамический robots.txt
В CMS Вордпресс обработка запроса на файл robots производится отдельно. Вебмастеру нет нужды самостоятельно создавать в корневом каталоге сайта файл robots. Это не то что можно не делать, но и нужно, иначе плагины не смогут изменять созданный вебмастером файл, когда в этом появится необходимость.
Для изменения содержания динамического robots налету, через хук do_robotstxt, добавьте данный код в файл funtcions.php:
Mobile AdSense
Примеры использования директивы User-agent в robots.txt
Если в файле задавать конкретного робота, то он будет следовать инструкциям, которые относятся только к нему.
disallow
Директива disallow определяет, какие пути не должны сканироваться поисковыми роботами, определенными строкой агента пользователя, с которой сгруппирована директива disallow . Роботы игнорируют директиву без указания пути.
Значение директивы disallow обрабатывается с учетом регистра.
Сортировка правил перед обработкой
Google и Яндекс обрабатывают правила Disallow и Allow без соблюдения порядка, в котором они прописаны в robots.txt. Поисковики сортируют директивы от коротких к длинным, после чего обрабатывают последнюю подходящую директиву.
Например, данная инструкция:
Поисковые системы обработают следующим образом:
В случае проверки ссылки типа /wp-content/uploads/file.jpg, директива Disallow сначала запретит ссылку с /wp-, а затем Allow разрешит ее индексировать, поэтому ссылка будет доступна для роботов.
На заметку. Запомните главное при сортировке правил: чем директива в файле robots.txt длиннее, тем она приоритетнее. Когда директивы одинаковой длины, приоритетной становится Allow.
robots.txt
Это простой текстовый файл, который содержит инструкции для поисковых краулеров — какие страницы сайта не следует посещать, где лежит наш Sitemap.xml и для каких поисковых роботов распространяются правила.
Файл размещается в корневой директории сайта. Например:
Прежде чем начать сканирование сайта, краулеры проверяют наличие robots.txt и находят правила специфичные для их User-Agent, например Googlebot. Если таких нет — следуют общим инструкциям.
Стандартный файл robots для WordPress
Хотя первый метод является более современным и логичным, но я все же пользуюсь вторым файлом robots.txt. Потому что мне так спокойнее, что с помощью директивы Dissalow: /wp- я не запрещу что то нужное, поэтому я прописываю каждую папку отдельно.
Исходя из вышеперечисленных правок, у меня получается вот такой robots.txt:
allow
Директива allow определяет пути, которые могут сканироваться поисковыми роботами. Если путь не указан, она игнорируется.
Значение директивы allow обрабатывается с учетом регистра.
AdsBot
Проверяет качество рекламы на веб-страницах, предназначенных для компьютеров.
Заключение
Обязательно следите за актуальностью своего robots.txt. Проверяйте страницы на индексацию, чтобы там не было мусорных, не нужных страниц. Если такие заметили, то блокируйте их. При внесении изменений в файл robots.txt для уже рабочего веб-сайта результат будет видно не раньше, чем через 2-3 месяца.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Поисковые роботы, перечисленные в таблице ниже, обеспечивают работу различных продуктов и сервисов Google.
- Токен агента пользователя указывается в строке User-agent: файла robots.txt и позволяет выбирать, на каких поисковых роботов будет распространяться то или иное правило сканирования. Как видно из таблицы, некоторым роботам соответствует несколько токенов, но для того, чтобы правило действовало, достаточно одного. Приведенный ниже перечень не является исчерпывающим. Он содержит информацию о тех роботах, которые с наибольшей вероятностью будут посещать ваш сайт.
- Полная строка агента пользователя – это подробное описание поискового робота. Оно указывается в запросах и журналах. Внимание! Строка агента пользователя может быть подделана. Узнайте, как проверить, является ли посетитель поисковым роботом Google.
Googlebot News
Googlebot Desktop
Как проверить robots.txt?
Есть множество сервисов проверки корректности файлов robots.txt, но, пожалуй, самые надёжные: Google Search Console и Яндекс.Вебмастер.
Для мониторинга изменений, как всегда, незаменим «Модуль ведения проектов»:
Контроль индексации на вкладке «Аудит» — динамика сканирования страниц сайта в Яндексе и Google.
Контроль изменений в файле robots.txt. Теперь точно не упустите, если кто-то из коллег закрыл сайт от индексации (или наоборот).
Держите свои robots.txt в порядке, и пусть в индекс попадает только необходимое!
Формат файла
В файле robots.txt должен быть обычный текст в кодировке UTF-8. В качестве разделителей строк следует использовать символы CR , CR/LF и LF .
Добавляемая в начало файла robots.txt метка порядка байтов Unicode BOM игнорируется, как и недопустимые строки. Например, если вместо правил robots.txt Google получит HTML-контент, система попытается проанализировать контент и извлечь правила. Все остальное будет проигнорировано.
Если для файла robots.txt используется не UTF-8, а другая кодировка, Google может проигнорировать символы, не относящиеся к UTF-8. В таком случае правила из файла robots.txt не будут работать.
В настоящее время максимальный размер файла, установленный Google, составляет 500 кибибайт (КиБ). Контент сверх этого лимита игнорируется. Чтобы не превысить его, применяйте более общие директивы. Например, поместите все материалы, которые не нужно сканировать, в один каталог.
Google StoreBot
Mozilla/5.0 (X11; Linux x86_64; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36
Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012; Storebot-Google/1.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Mobile Safari/537.36
В строках, которые содержат элемент Chrome/W.X.Y.Z, сочетание символов W.X.Y.Z – это плейсхолдер для версии браузера Chrome, используемой агентом пользователя. Пример: 41.0.2272.96 . Это значение соответствует последней версии Chromium, используемой роботом Googlebot, и поэтому со временем оно будет возрастать.
При поиске агента пользователя в журнале или на сервере не указывайте точное значение версии, а используйте подстановочные знаки.
sitemap
Значение поля sitemap обрабатывается с учетом регистра.
Строка [absoluteURL] указывает на расположение файла Sitemap или файла индекса Sitemap. URL должен быть полным, с указанием протокола и хоста. Нет необходимости кодировать URL. Хост URL не обязательно должен быть таким же, как и у файла robots.txt. Вы можете добавить несколько полей sitemap . Эти поля не связаны с каким-либо конкретным агентом пользователя. Если их сканирование не запрещено, они доступны для всех поисковых роботов.
Приоритет агентов пользователей
Для отдельного поискового робота действительна только одна группа. Он должен найти ту, в которой наиболее конкретно указан агент пользователя из числа подходящих. Другие группы игнорируются. Весь неподходящий текст игнорируется. Например, значения googlebot/1.2 и googlebot* эквивалентны значению googlebot . Порядок групп в файле robots.txt не важен.
Если агенту пользователя соответствует несколько групп, то все относящиеся к нему правила из всех групп объединяются в одну. Группы, относящиеся к определенным агентам пользователя, не объединяются с общими группами, которые помечены значком * .
Противоречия директив
Общее правило — если две директивы противоречат друг другу, приоритетом пользуется та, в которой большее количество символов .
Может показаться, что файл /admin/js/global.js попадает под правило блокировки содержащего его раздела Disallow: /admin/ . Тем не менее, он будет доступен для сканирования, в отличие от всех остальных файлов в каталоге.
Crawl-delay
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз.
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано не более 2880 страниц в день, что мало для крупных сайтов.
Доработка файла под свои цели
Если потребуется заблокировать еще какие-то страницы или разделы веб-ресурса, добавьте директиву Disallow. К примеру, желая скрыть от роботов все публикации в рубрике News, пропишите правило:
И если заметили мусорные, ненужные страницы, то блокируйте их в robots.txt.
AdsBot Mobile Web Android
Проверяет качество рекламы на веб-страницах, предназначенных для устройств Android.
Узнайте, как увеличить SEO‑трафик сайта в 3+ раза?
Укажите домен вашего сайта, приоритетные регионы продвижения и получите самый
полный список точек взрывного роста трафика и заявок с вашего сайта
User-agent – это директива, указывающая, для какой поисковой системы и какого конкретно робота прописываются инструкции в файле robots.txt.
С данного правила начинается любой корректный Robots. Все боты при обращении к файлу проверяют записи, начинающиеся с User-Agent, где учитываются подстроки с названиями ботов поисковиков (Yandex, Google и пр.) либо «*».
На заметку.Если строки User-agent: *, User-agent: Yandex или User-agent: Google не указаны в файле, то по умолчанию робот считает, что никаких ограничений на индексацию у него нет.
Sitemap
Одно из ключевых применений robots.txt в SEO — указание на расположение карты сайты. Обратите внимание, используется полный URL-адрес (их может быть несколько).
Нужно иметь в виду:
Директива Sitemap указывается с заглавной S.
Sitemap не зависит от инструкций User-Agent.
Нельзя использовать относительный адрес карты сайта, только полный URL.
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус 200 OK без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
APIs-Google
Примеры действительных URL файла robots.txt
Примеры URL файла robots.txt и путей URL, для которых они действительны, приведены в таблице ниже.
Google выполняет пять переходов в цепочке переадресаций согласно RFC 1945. Затем поисковый робот прерывает операцию и интерпретирует ситуацию как ошибку 404 , относящуюся к файлу robots.txt. Это также относится к любым заблокированным URL в цепочке переадресаций, поскольку из-за них поисковый робот не может получить правила.
Google не обрабатывает логические перенаправления в файлах robots.txt (фреймы, JavaScript или метатеги refresh).
Поисковые роботы Google воспринимают все ошибки 4xx (кроме ошибки 429 ) так, как если бы действительный файл robots.txt отсутствовал. При этом сканирование выполняется без ограничений.
Порядок применения правил
Когда роботы соотносят правила из файла robots.txt с URL, они используют самое строгое правило (с более длинным значением пути). При наличии конфликтующих правил (в том числе с подстановочными знаками) выбирается то, которое предполагает наименьшие ограничения.
Ознакомьтесь с примерами ниже.
Применяемое правило: allow: /p , поскольку оно наиболее строгое.
Применяемое правило: allow: /folder , поскольку при наличии конфликтующих правил используется наименее строгое.
Применяемое правило: disallow: /*.htm поскольку оно имеет более длинное значение пути и точнее совпадает с символами в URL, поэтому является более строгим.
Применяемое правило: allow: /page , поскольку при наличии конфликтующих правил используется наименее строгое.
Применяемое правило: allow: /$ , поскольку оно наиболее строгое.
Применяемое правило: disallow: / , поскольку правило allow действует только для корневого URL.
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Агенты пользователей в метатегах robots
Некоторые страницы содержат несколько метатегов, в которых указаны инструкции для различных поисковых роботов. Примеры:
В этом случае Google будет следовать всем запрещающим инструкциям, а Googlebot выполнит обе директивы: noindex и nofollow . Подробнее об управлении сканированием и индексированием сайта роботами Google…
AdSense
Проверка файла и документация
Проверить корректность директив, прописанных в robots.txt, вы можете по ссылкам:
Поисковые роботы
Googlebot Smartphone
Агенты пользователей в файлах robots.txt
Если в файле robots.txt обнаружится несколько токенов агентов пользователей, робот Google последует правилу с наиболее точно соответствующим ему токеном. Если вы хотите оставить сайт доступным для всех наших роботов, такой файл вообще не нужен. Чтобы запретить или разрешить всем поисковым роботам Google доступ к определенному контенту, укажите в правиле агент пользователя Googlebot. К примеру, чтобы все страницы сайта появлялись в Google Поиске, а на самих страницах показывались объявления AdSense, не используйте файл robots.txt. Если же вы решите полностью запретить Google сканировать некоторые страницы, правило для агента пользователя Googlebot заблокирует доступ к контенту и всем остальным нашим роботам.
В случае необходимости вы можете указать агент пользователя более точно. Предположим, вы хотите, чтобы все страницы сайта показывались в Google Поиске, но чтобы при этом не сканировались изображения из вашего личного каталога. В таком случае в файле robots.txt запретите агенту пользователя Googlebot-Image сканировать файлы в каталоге /personal. При этом робот Googlebot по-прежнему будет иметь доступ к файлам во всех каталогах. Запись должна выглядеть следующим образом:
Рассмотрим другой пример. Вы хотите разместить на всех страницах рекламу, но сами страницы не должны появляться в Google Поиске. В таком случае следует полностью заблокировать доступ агенту пользователя Googlebot, но разрешить сканирование агенту пользователя Mediapartners-Google . Запись должна выглядеть так:
Google Read Aloud
Текущие агенты пользователя:
Прежняя версия (больше не поддерживается):
Список распространенных User-Agent
Что такое файл robots.txt
Типичный robots.txt
Ниже представлены простые и распространенные шаблоны команд для поисковых роботов.
Запрет конкретного раздела сайта
Кеширование
Google Favicon
Разрешить полный доступ
Обратите внимание, правило для Disallow в этом случае не заполняется.
Allow
С помощью этой директивы можно, напротив, разрешить каталог или конкретный адрес к индексации. В некоторых случаях проще запретить к сканированию весь сайт и с помощью Allow открыть нужные разделы.
Также Allow можно использовать для отдельных User-Agent.
Пример использования нескольких User-agent в robots.txt
Данная инструкция лишь обращается к определенному поисковому роботу или всем роботам, а уже под директивой прописываются непосредственно команды для него/них.
Для корректной настройки файла Robots не стоит допускать пустые строки между директивами User-agent и Disallow, Allow, идущими в пределах одной директивы User-agent, к которой они относятся.
Пример некорректного отображения строк в файле Robots:
Пример корректного отображения строк в файле Robots:
Как видите, директории в роботсе делятся на блоки, и в каждом из них прописываются указания для всех ботов или для определенного.
AdsBot Mobile Web
Проверяет качество рекламы на веб-страницах, предназначенных для устройств iOS.
Googlebot Video
Оптимальный код файла для WordPress
Теперь разберем, какие директивы в коде что означают:
1. Директива User-agent: * означает, что все правила, описанные ниже нее, касаются всех роботов поисковых систем. Если вы хотите прописать правила для одного определенного бота, вместо * нужно ввести его имя. Например:
- User-agent: Googlebot – для главного робота Гугла.
- User-agent: Yandex – для главного бота Яндекса.
2. Строка Allow: /uploads указывается, чтобы разрешить ботам вносить в индекс страницы, где присутствует /uploads. Нужно обязательно указать данное правило, потому что выше запрещены к индексированию страницы, которые начинаются с /wp-, а проблема в том, что /uploads присутствует в /wp-content/uploads.
Команда Allow: /uploads нужна для перебивания правила Disallow: /wp-, так как по ссылкам типа /wp-content/uploads/ могут располагаться изображения, важные для индексации. Помимо картинок есть вероятность присутствия прочих файлов, которые нет нужды запрещать включать в поиск. Строчку Allow допускается прописывать и до, и после Disallow.
3. Директивы Disallow: запрещают ботам переходить по ссылкам, начинающимся с:
- Disallow: /trackback — закрывает уведомления
- Disallow: /s или Disallow: /*? — закрывает страницы поиска
- Disallow: /page/ — закрывает все виды пагинации
Рекомендуется не закрывать от индексации фиды: Disallow: /feed.
Это связано с тем, что доступ к фидам нужен, к примеру, для подключения сайта к каналу Яндекс Дзен, Турбо страниц. Могут быть еще некоторые случаи, где нужны открытые фиды. Через feed передается контент в формате .rss. Если вы не знаете что это такое, то читайте более подробную статью — что такое RSS.
У фидов собственный формат в заголовках ответа, что позволяет поисковым системам понять, что это фид, а не HTML документ, и обрабатывать его по-другому.
А если вы не хотите передавать RSS, чтобы например у вас не воровали через него контент, то тогда надежнее отключить его с помощью специальных плагинов, например Disable Feeds.
Web Light
Читайте также: