
Энтропия файловой системы что это

Как может показаться, анализ сигналов и данных — тема достаточно хорошо изученная и уже сотни раз проговоренная. Но есть в ней и некоторые провалы. В последние годы словом «энтропия» бросаются все кому не лень, толком и не понимая, о чем говорят. Хаос — да, беспорядок — да, в термодинамике используется — вроде тоже да, применительно к сигналам — и тут да. Хочется хотя бы немного прояснить этот момент и дать направление тем, кто захочет узнать чуть больше об энтропии. Поговорим об энтропийном анализе данных.
В русскоязычных источниках очень мало литературы на этот счет. А цельное представление вообще получить практически нереально. Благо, моим научным руководителем оказался как раз знаток энтропийного анализа и автор свеженькой монографии [1], где все расписано «от и до». Счастью предела не было, и я решила попробовать донести мысли на этот счет до более широкой аудитории, так что пару выдержек возьму из монографии и дополню своими исследованиями. Может, кому и пригодится.
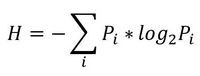
Итак, начнем с начала. Шенноном в 1963 г. было предложено понятие меры усредненной информативности испытания (непредсказуемости его исходов), которая учитывает вероятность отдельных исходов (до него был еще Хартли, но это опустим). Если энтропию измерять в битах, и взять основание 2, то получим формулу для энтропии Шеннона
, где Pi это вероятность наступления i-го исхода.
То есть в этом случае энтропия напрямую связана с «неожиданностью» возникновения события. А отсюда вытекает и его информативность — чем событие более предсказуемо, тем оно менее информативно. Значит и его энтропия будет ниже. Хотя открытым остается вопрос о соотношениях между свойствами информации, свойствами энтропии и свойствами различных ее оценок. Как раз с оценками мы и имеем дело в большинстве случаев. Все, что поддается исследованию — это информативность различных индексов энтропии относительно контролируемых изменений свойств процессов, т.е. по существу, их полезность для решения конкретных прикладных задач.
Энтропия сигнала, описываемого некоторым образом (т.е. детерминированного) стремится к нулю. Для случайных процессов энтропия возрастает тем больше, чем выше уровень «непредсказуемости». Возможно, именно из такой связки трактовок энтропии вероятность->непредсказуемость->информативность и вытекает понятие «хаотичности», хотя оно достаточно неконкретно и расплывчато (что не мешает его популярности). Встречается еще отождествление энтропии и сложности процесса. Но это снова не одно и то же.
- термодинамическая
- алгоритмическая
- информационная
- дифференциальная
- топологическая
Для того, чтобы немного обрисовать области применения энтропии к анализу данных, рассмотрим небольшую прикладную задачку из монографии [1] (которой нет в цифровом виде, и скорей всего не будет).
Пусть есть система, которая каждые 100 тактов переключается между несколькими состояниями и порождает сигнал x (рисунок 1.5), характеристики которого изменяются при переходе. Но какие — нам не известно.
Разбив x на реализации по 100 отсчетов можно построить эмпирическую плотность распределения и по ней вычислить значение энтропии Шеннона. Получим значения, «разнесенные» по уровням (рисунок 1.6).
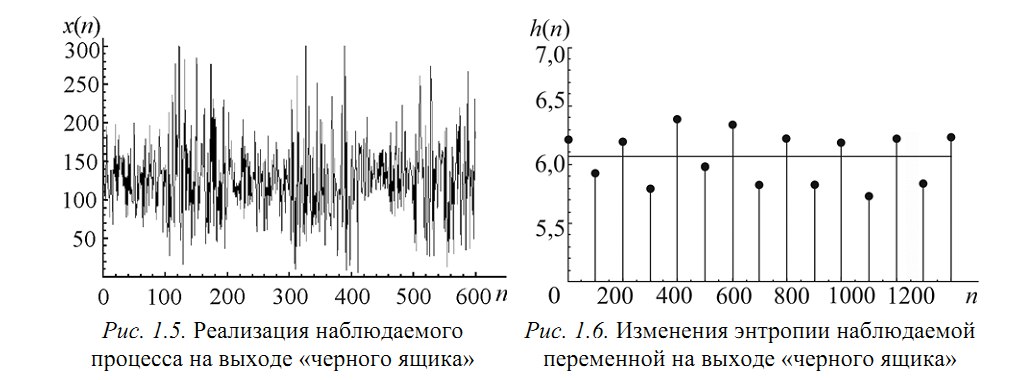
Как можно видеть, переходы между состояниями явно наблюдаются. Но что делать в случае, если время переходов нам не известно? Как оказалось, вычисление скользящим окном может помочь и энтропия так же «разносится» на уровни.В реальном исследовании мы использовали такой эффект для анализа ЭЭГ сигнала (разноцветные картинки про него будут дальше).
Теперь еще про одно занятное свойство энтропии — она позволяет оценить степень связности нескольких процессов. При наличии у них одинаковых источников мы говорим, что процессы связаны (например, если землетрясение фиксируют в разных точках Земли, то основная составляющая сигнала на датчиках общая). В таких случаях обычно применяют корреляционный анализ, однако он хорошо работает только для выявления линейных связей. В случае же нелинейных (порожденных временными задержками, например) предлагаем пользоваться энтропией.
Рассмотрим модель из 5ти скрытых переменных(их энтропия показана на рисунке ниже слева) и 3х наблюдаемых, которые генерируются как линейная сумма скрытых, взятых с временными сдвигами по схеме, показанной ниже справа. Числа-это коэффициенты и временные сдвиги (в отсчетах).
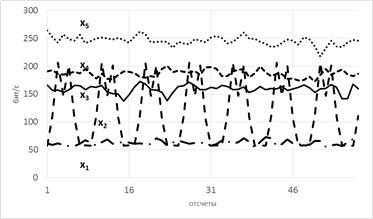
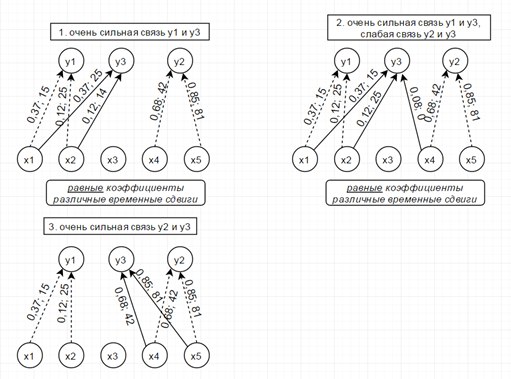
Так вот, фишка в том, что энтропия связных процессов сближается при усилении их связи. Черт побери, как это красиво-то!
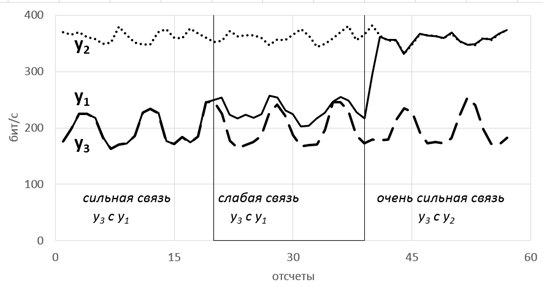
Такие радости позволяют вытащить практически из любых самых странных и хаотичных сигналов (особенно полезно в экономике и аналитике) дополнительные сведения. Мы их вытаскивали из электроэнцефалограммы, считая модную нынче Sample Entropy и вот какие картинки получили.
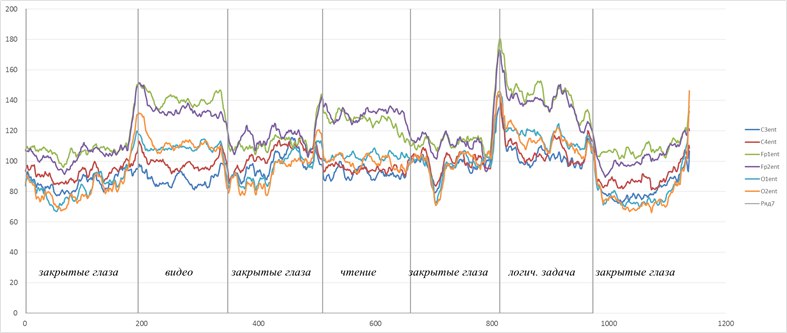
Можно видеть, что скачки энтропии соответствуют смене этапов эксперимента. На эту тему есть пара статей и уже защищена магистерская, так что если кому будут интересны подробности — с радостью поделюсь. А так по миру по энтропии ЭЭГ ищут уже давно разные вещи — стадии наркоза, сна, болезни Альцгеймера и Паркинсона, эффективность лечения от эпилепсии считают и тд. Но повторюсь-зачастую расчеты ведутся без учета поправочных коэффициентов и это грустно, так как воспроизводимость исследований под большим вопросом (что критично для науки, так то).
Резюмируя, остановлюсь на универсальности энтропийного аппарата и его действительной эффективности, если подходить ко всему с учетом подводных камней. Надеюсь, что после прочтения у вас зародится зерно уважения к великой и могучей силе Энтропии.
P.S. При наличии интереса, могу немного подробней поговорить в следующий раз об алгоритмах расчета энтропии и почему энтропию Шеннона сейчас смещают более свежие методы.
P.P.S. Продолжение про локально-ранговое кодирование смотрите тут
Любой компьютерный файл, как известно, состоит из байтов. Байт может принимать значения от 0 до 255. Информационная энтропия – это статистический параметр, который показывает вероятность встречаемости определённых байтов в файле.
Визуально оценить степень энтропии можно с помощью гистограммы – распределения вероятности повторов одинаковых байтов в файле. По энтропии файла можно предположить, какого типа файл перед нами, видя только его гистограмму.
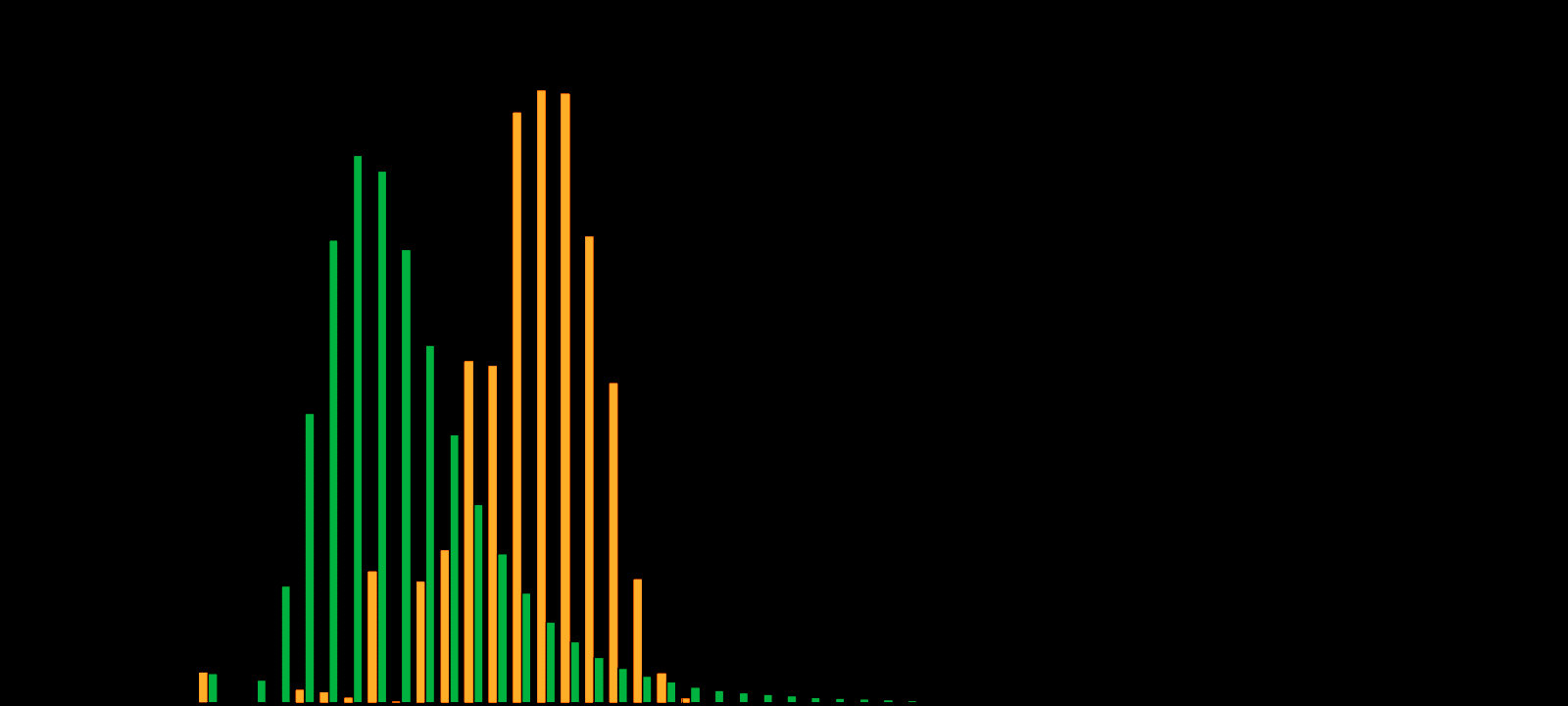
Для демонстрации возьмём три файла разных типов и сравним их гистограммы.
Гистограмма текстового файла
Первый пусть будет текстовый файл (*.TXT). Его гистограмма показана на рисунке:

Гистограмма текстового файла
Текстовый файл содержит только текст. Каждый символ текста кодируется определёнными байтами в соответствии с таблицей кодировки. Хотя видов кодировок достаточно большое количество, представленный файл – в кодировке ASCII, поэтому на первой гистограмме заняты лишь некоторые области, а больше числа 127 значений нет вовсе (127 – предельный код символа в таблице ASCII). Видно, что некоторые из символов (букв или цифр) в файле встречаются чаще, некоторые – реже. Больше всего в текстовом файле пробелов, отсюда и высокий пик на значении байта 3210.
Гистограмма PDF файла
Следующий файл будет формата PDF:

Гистограмма файла PDF
Этот файл имеет все возможные байты, так как формат PDF кодируется не так, как текстовые файлы. Он хранит много служебной информации: форматирование, шрифты, изображения и т.д. Но по его гистограмме видно, что некоторые из байтов встречаются с примерно равной вероятностью, в то время как другие – намного чаще остальных. Отсюда и множественные острые всплески на гистограмме, и в целом она имеет довольно «рваный» вид, хотя и занимает всю доступную ширину.
Гистограмма архива 7Z
И последний файл – заархивированный в формат 7Z:

Гистограмма файла 7Z
Гистограмма архива 7Z имеет две основные особенности: во-первых, все байты встречаются в заархивированном файле с более-менее равной вероятностью (достаточно ровный верхний край), а во-вторых, практически отсутствует свободное пространство над гистограммой, что говорит о почти полном отсутствии избыточности такого файла. Отсюда можно сделать вывод, что алгоритм архиватора каким-то особым образом «перемешивает» байты файла, чтобы добиться их максимально равномерного распределения.
Таким образом, энтропия в информатике, как и в физике – это мера неупорядоченности системы, в данном случае – неупорядоченности распределения байтов в файле. Энтропия позволяет судить о степени сжатия файла и – косвенно – о его типе.
Программа визуализации энтропии файлов
В борьбе со зловредами вирусные аналитики используют множество методов и целый арсенал специального софта. Но самая первая из стоящих перед ними задач — определить, действительно ли им в руки попался вредоносный образец, или это что‑то безобидное. Решить ее помогает изучение показателя под названием «энтропия». Сегодня мы расскажем, как работает эта техника вирусного анализа.
Что такое энтропия? У этого понятия есть определения в разных областях науки, значащие в общих чертах одно и то же. В терминах информатики — это показатель хаотичности, или случайности распределения значений байтов в файле. Условимся, что под этим термином мы имеем в виду энтропию Шеннона. Того самого человека, который в 1948 году предложил использовать слово «бит» для обозначения наименьшей единицы информации.
Окунемся немного в математику. Энтропия любого файла в общем случае считается методом «скользящего окна» по всем байтам файла. Звучит страшно, но на самом деле проще, чем кажется. Чтобы понять принцип скользящего окна, достаточно взглянуть на рисунок.

Скользящее окно
Сначала рассчитываются частоты fi появления для каждого возможного значения байта (i = 0..255). Например, в первом окне значение байта согласно таблице ASCII (десятичное значение = 180) равно символу ´ . В итоге получается вот такая гистограмма по количествам вхождений определенных байтов в файле (ее ты можешь увидеть сам в любом Hex-редакторе).

Частотное распределение байтов в объекте в программе Hex Workshop
Затем найденные частоты (fi) суммируются по формуле ниже, и в результате мы получим значение энтропии.

Суть анализа энтропии заключается в том, что в скомпилированном файле обычной программы участки кода распределены более‑менее равномерно, как масло на бутерброде. При использовании кодировщиков или обфускации, упаковщиков, алгоритмов сжатия или вставок подобного рода кода в исходный файл такая равномерность нарушается. В файле появляются высокоэнтропийные области (как будто концентрированный белый шум) и области, менее подвергнутые обфускации или шифрованию (кодированию), если продолжить метафору бутерброда — комочки в масле или прослойки варенья.
Одно из характерных свойств алгоритмов сжатия — перераспределение частот встречаемости байтов кода (для всех 256 значений), что и станет заметно при анализе! В таких файлах будет высокая степень энтропии, близкая к максимальному значению 8 (2 8 = 256). То есть чем выше энтропия, тем меньше избыточности в файле.
Для закодированных (сжатых, зашифрованных) файлов на практике значение энтропии свыше семи можно считать почти 100%-м признаком применения преобразования кода, в то время как обычные файлы имеют энтропию в районе 2–6. Часто на практике энтропию в файле или выделенном фрагменте файла измеряют в процентах (тут иногда также используют понятие «избыточность»).

Показатель увеличения энтропии в зависимости от содержимого объекта
Представим, что есть какой‑то объект, в который потенциальный злоумышленник может внедрить вредоносный код. Он помещает полезную нагрузку в оригинальный файл, сжимает или зашифровывает определенный фрагмент данных, тем самым увеличивая энтропию. С точки зрения вирусного аналитика, можно быстро проверить образец и его секции на энтропию, понять, запакован он или обфусцирован, и, исходя из этой информации, выбрать методологию для анализа объекта. Итак, какие есть инструменты для подсчета энтропии?
Наиболее популярные инструменты для проведения анализа объектов по энтропии:
Воспользуемся первой программой — Detect It Easy (DIE) — и разберем пару примеров с популярным образцом Agent Tesla.
Agent Tesla — это модульное программное обеспечение для шпионажа, которое распространяется по модели malware-as-a-service под видом кейлоггера. Этот шпион способен извлекать и передавать на сервер злоумышленникам учетные данные пользователя из браузеров, почтовых клиентов и клиентов FTP, регистрировать содержимое буфера обмена, делать снимки экрана. На момент анализа официальный сайт разработчиков был недоступен.
На скриншотах интерфейса утилиты представлена следующая информация:
- тип файла;
- общая оценка энтропии;
- статус (запакован ли файл, если нет — перед нами «чистый» текст);
- подсчет энтропии искомого файла посекционно (Regions) и его статус;
- график энтропии (ось Х — смещение, ось Y — оценка энтропии).
Графики энтропии для образца Agent Tesla и еще одной его разновидности показаны ниже.
Результат анализа образца 1 в программе DIE Результат анализа образца 2 в программе DIE
Типичный пример — когда PE-заголовок читается (энтропия низкая), однако уровень энтропии оставшейся части файла очень высок, а секция кода не может быть статистически проанализирована, поскольку похожа на случайные значения. Это обычно свидетельствует о применении сжатия либо обфускации — типичного приема, чтобы сбить с толку антивирусы. По графику распределения энтропии можно на глаз определять закодированные фрагменты файла.

Примеры работы PortexAnalyzer
Помнишь, недавно мы писали о нечетком хеше SSDeep? Он не всегда отрабатывает корректно, особенно для семплов с низкой энтропией. Опытных пользователей SSDeep частенько смущает сам расчет схожести хешей и множество ложноположительных срабатываний, поэтому Вассил Руссев разработал алгоритм SDHash, который скользящим окном рассчитывает энтропию файла.
Особенность подхода — в тщательной фильтрации высоко- и низкоэнтропийных областей, а также в селекции для каждой области файла самых «редких» по энтропии участков. На основе оценки энтропии и сравнения данных по файлу в целом выбранные для сравнения объекты хешируются и с помощью фильтра Блума объединяются в единый хеш. Что такое фильтр Блума? За математическими формулировками отправляем тебя в Википедию. Если говорить кратко, он проверяет принадлежность хеша нашему множеству кусочных хешей и таким образом позволяет быстро определить принадлежность объекта к определенному множеству. В SDHash хеш (подпись) файла — это последовательность фильтров Блума, можешь использовать его для более продвинутого поиска похожих образцов.
На сегодняшний день анализ энтропии объектов используется множеством приложений и сервисов, относящихся к сфере информационной безопасности. Например, такой анализ применяется в алгоритмах машинного обучения для создания моделей оценки файла в антивирусном ПО. Также оценка энтропии используется при подсчете весов на этапе вынесения оценки вредоносности объекта в анти‑АРТ‑средствах защиты, то есть в процессе динамического анализа объектов.
Пример применения исследования энтропии на практике — модуль поведенческого анализа Polygon в составе комплекса Group-IB Threat Hunting Framework. На рисунке ниже показана часть отчета системы. В нем содержится информация об энтропии в разделе прочих поведенческих маркеров.

Часть отчета Polygon
Таким образом, анализ энтропии можно назвать базовой оценкой тестируемого объекта, которая позволяет понять, на какую секцию или часть файла следует обратить более пристальное внимание при анализе образца и понять, подозрителен ли образец в целом.
Характеризация
и меру информационной энтропии >_(p_,\ldots ,p_)=<\mathcal

Непрерывность Мера должна быть переупорядочены: >_\left(p_,p_,\ldots \right)=<\mathcal
и т.д. Максимум Мера должна быть максимальной, если все исходы одинаково вероятны (неопределённость является самой высокой, когда все возможные события равновероятны). >_(p_,\ldots ,p_)\leq <\mathcal
Для равновероятных событий энтропия должна увеличиваться с увеличением их числа: >_\underbrace <<\frac >,\ldots ,<\frac >> _<<\mathcal
Аддитивность Количество энтропии не должно зависеть от того, как система событий разделена на части (подсистемы). Это последнее функциональное отношение характеризует энтропию системы с подсистемами и требует, чтобы энтропия системы могла быть вычислена через энтропии ее подсистем, если мы знаем, как подсистемы взаимодействуют с друг другом. Дан ансамбль из " width="" height="" />
равномерно распределённых элементов, которые произвольно разделены на " width="" height="" />
коробок (подсистем) с ,\ldots ,b_>" width="" height="" />
элементами соответственно; энтропия всего ансамбля должна быть равна сумме энтропии системы коробок и индивидуальных энтропий коробок, взвешенных с вероятностью обнаружения элемента в соответстувующей коробке. Для положительных целых чисел +\ldots +b_=n>" width="" height="" />
, >_\left(<\frac >,\ldots ,<\frac >\right)=<\mathcal
Выбор =1,\ldots ,b_=1>" width="" height="" />
подразумевает, что энтропия конкретного исхода равна нулю: >_\left(1\right)=0\,>" width="" height="" />
Можно показать, что любое определение энтропии, удовлетворяющее этим предположениям имеет форму
— постоянная, соответствующая выбору единицы измерения.
Содержание
Определение
, которая может принимать значения ,\ldots ,x_>" width="" height="" />
, равна величине
Борис Осепов
Специалист ИБ. Увлекаюсь средствами анализа вредоносного ПО. Люблю проверять маркетинговые заявления на практике :)
Понятие было введено Клодом Элвудом Шенноном (1948) в его работе Математическая теория связи (A Mathematical Theory of Communication) [3] .
Борис Осепов
Специалист ИБ. Увлекаюсь средствами анализа вредоносного ПО. Люблю проверять маркетинговые заявления на практике :)
Понятие было введено Клодом Элвудом Шенноном (1948) в его работе Математическая теория связи (A Mathematical Theory of Communication) [3] .
Пояснения
Дальнейшие свойства
Увеличение энтропии Байеса — закон, согласно которому по мере увеличения выборки сравнения объектов А` для идентификации объекта А, индивидуальные особенности объекта А размываются по отношению к выборке, а идентификация становится бессмысленной. Другими словами с увеличение выборки у объекта А по отношению к ней увеличивается энтропия.
Считается, что закон был открыт эмпирически, до его математического доказательства британским математиком Томасом Байесом. В настоящее время в разных интерпретациях используется в кибернетике, информатике, теории систем, менеджменте и других науках. Некоторые математики и физики считают этот закон еще одним из начал термодинамики.
Пример. Если кто-то захочет установить личность человека, попавшего на видеокамеры, то процесс будет становится тем более бессмысленным, чем с большим количеством людей будет сравнен человек.
Любой компьютерный файл состоит из байтов. Байт может принимать значения от 0 до 255. Информационная энтропия - это статистический параметр, который показывает вероятность встречаемости определённых байтов в файле.

- Что такое энтропия файла
- Принцип возрастания энтропии
- Как определить энтропию
Визуально оценить степень энтропии можно с помощью гистограммы - распределения вероятности повторов одинаковых байтов в файле. По энтропии файла можно предположить, какого типа файл перед нами, видя только его гистограмму.
Для демонстрации возьмём три файла разных типов и сравним их гистограммы. Первый пусть будет текстовый файл (*.TXT). Его гистограмма показана на рисунке:

Текстовый файл содержит только текст. Каждый символ текста кодируется определёнными байтами в соответствии с таблицей кодировки. Хотя видов кодировок достаточно большое количество, очевидно, что буквенно-цифровых символов ограниченное число, которое обычно меньше, чем 255. Поэтому на первой гистограмме заняты лишь некоторые области, а некоторых байтов нет вовсе.
Следующий файл будет формата PDF:

Этот файл содержит все возможные байты, так как формат PDF кодируется не так, как текстовые файлы. Он хранит много служебной информации: форматирование, шрифты, изображения и т.д. Но по его гистограмме видно, что некоторые из байтов встречаются с примерно равной вероятностью, в то время как другие - намного чаще остальных. Отсюда и множественные острые всплески на гистограмме, и в целом она имеет довольно "рваный" вид, хотя и занимает всю доступную ширину.
И последний файл - заархивированный в формат 7Z:

Эта гистограмма имеет две основные особенности: во-первых, все байты встречаются в заархивированном файле с более-менее равной вероятностью (достаточно ровный верхний край), а во-вторых, на практически отсутствует свободное пространство над гистограммой, что говорит о почти полном отсутствии избыточности такого файла. Отсюда можно сделать вывод, что алгоритм архиватора каким-то особым образом "перемешивает" байты файла, чтобы добиться их максимально равномерного распределения.
Таким образом, энтропия в информатике, как и в физике - это мера неупорядоченности системы, в данном случае - неупорядоченности распределения байтов в файле. Энтропия позволяет судить о степени сжатия файла и - косвенно - о его типе.
Пример
Читайте также: