
Добавить партицию в таблицу oracle
Как лучше всего партиционировать существующую таблицу, которая уже содержит большой объем данных ?
1) Создать новую партиционированную таблицу и залить данные из старой
CREATE TABLE . PARTITION BY (RANGE).
INSERT INTO . SELECT * FROM not_partitioned_table;
или
INSERT /*+ append */INTO . SELECT * FROM not_partitioned_table;
2) Создать новую партиционированную таблицу из старой таблицы
CREATE TABLE partitioned_table
PARTITION BY (RANGE) .
AS SELECT * FROM not_partitioned_table;
3) С помощью EXCHANGE PARTITION
ALTER TABLE partitioned_table
EXCHANGE PARTITION calls_01012008
WITH TABLE not_partitioned_table;
4) С помощью пакета DBMS_REDEFITION
Во всех вышеперечисленных вариантах партиционирования существующей таблицы для активной системы по любому понадобится даунтайм таблицы, кроме 4 пункта(использование DBMS_REDEFINITION).
Теперь, попробую более подробно описать каждый из вариантов.
Скажем, у нас есть партиционированная таблица NOT_PARTITIONED_TABLE, в которой хранятся данные о звонках.В итоге, у нас есть непартиционированная таблица NOT_PARTITIONED_TABLE с 1 миллионом записей о звонках с 1 по 7 января 2008 года:Наша цель: партиционировать эту таблицу с наименьшим даунтаймом таблицы.
Вариант 1: Создать новую партиционированную таблицу и залить данные из старой
План действий такой:
- Создаем новую партиционированную таблицу
- Можно заблокировать непартиционированной таблицу, чтоб никто не смог изменить данные во время заливки
- Заливаем данные из непартиционированной таблицу
- Удаляем непартиционированную таблицу
- Переименовываем новую партиционированную таблицуПеред заливкой заблокируем таблицу в режиме EXCLUSIVE командой LOCK TABLE, чтоб пока мы заливаем данные, никто не смог изменить данные в них или добавить новые.Теперь зальем данные командой INSERT. Сперва посмотрим заливку обычным INSERTом:Заливка 1 миллиона записей длилась почти 8 минут. Инсерт сгенерил 35 909 076 байт redo - это почти равно размеру непартиционированной таблицы, таблица весит 33 554 432 байт.Теперь попробуем залить те же данные прямым инсертом (direct path insert), командой INSERT /*+ APPEND */.
Direct Path Insert отличается от обычного инсерта тем, что вставка происходит:
1) в обход буферного кеша
2) новые блоки добавляются за отметкой HWM
То есть новые блоки данных подготавливаются в pga сессии и в обход буферного кеша добавляются ЗА отметкой HWM , если даже до отметки HWM есть свободное место для данных. Как объясняет Том Кайт, неправильно считать, что при таком инсерте (direct path insert) вообще не генерится redo. Redo по-любому генерится, но совсем малюсенький по сравнению с обычным инсертом, что существенно увеличивает скорость заливки.
После таких заливок следует сделать полный бэкап базы на всякий случай.Заливка "инсерт аппендом" закончилась за 3 минуты (почти в 3 раза быстрей обычного инсерта), и сгенерил 343352 байтов redo (почти в 100 раз меньше чем при обычном инсерте).
В три раза быстрей чем обычный инсерт, но как можно еще как-то ускорить заливку? Есть один способ: можно заранее выделить необходимый объем экстентов партициям , чтоб во время заливки на это не тратилось время.После предварительного выделения эктентов партициям, инсерт аппенд отработал всего за 5 секунд. А обычный инсерт отработал за 11 секунд:Для ускорения заливки и уменьшения даунтайма таблицы, можно заранее выделить необходимые эктенты партициям, чтоб во времы заливки на эту рекурсивную операцию не тратилось время.
Теперь осталось удалить старую таблицу и переименовать партиционированную таблицу.Можно и партиции переименовать (но их можно было бы создать с нужным именем изначально):
В следующие варианты - в следующем выпуске новостей.

В этой части статьи рассматриваются особенности создания секционированных таблиц, в следующей речь пойдет об особенностях перевода существующих больших несекционированчых таблиц в секционированные таблицы, а также особенности секционирования индексов и работа с секциями.
Задачи, решаемые секционированием
Прежде чем приступить к секционированию, надо четко определить задачи, которые предполагается решить
- Первой и наиболее часто решаемой задачей при секционировании является повышение производительности работы SQL-запросов и DML-операций по модификации строк таблицы. Это достигается за счет того, что поиск и модификация строк в таблице идут не по всей таблице, а только в ее части (в одной или нескольких секциях). Кроме того, разбиение таблицы на секции позволяет увеличит скорость обработки таблицы за счет использования параллелизма.
- Вторая задача, которая нашла широкое применение в нашей организации, - это быстрое удаление значительного числа строк в больших таблицах за счет выполнения операции truncate секций. Другим широким применением секционирования является освобождение табличного пространства, занимаемого таблицей, после удаления строк из таблицы командой delete. Использование команд Shrink (сжатие таблицы) или Move (перемещение в табличное пространство) для освобождения табличного пространства в большой несекционированной таблице может занимать значительное время. В секционированных таблицах выполнение таких команд в пределах секции будет выполниться существенно быстрее.
- Третьей задачей секционирования является разбиение большой таблицы на оперативную и архивную части. Особенно это эффективно, если оперативная часть в виде секции интенсивно пополняется и модифицируется, а архивная часть (секции) менее подвержена изменениям, и существенно реже из нее извлекается информация. Строки таблицы из оперативной секции со временем могут быть переведены в архивные секции, при этом архивные секции могут периодически очищаться.
- Четвертой задачей является существенное снижение конкуренции за строки и индексы таблицы, в том числе уменьшения вероятности блокировок. Так в результате секционирования одной из таблиц по HASH-методу полностью была решена задача множественных блокировок, возникающих в таблице.
- Пятой задачей является обеспечение устойчивости функционирования таблиц. Поскольку секция - это поименованный самостоятельный фрагмент памяти на дисках, то при возникновении проблем в одних секциях другие продолжают успешно функционировать. Устойчивости функционирования способствует также хранение секций в различных табличных пространствах и на различных физических носителях. Это особенно важно для таблиц, которые обеспечивают работу множества других таблиц (например. справочники, к которым идет интенсивное обращение). Кроме того, секционирование позволяет осуществлять независимое копирование и резервирование секций, оперативное восстановление секций, а также возможности более быстрой и более частой перестройки индексов наиболее активной секции, не затрагивая индексы пассивных секций.
Ключ секционирования
Следующим важным шагом в создании секционированной таблицы является определение ключа секционирования. В качестве ключа секционирования может выступить столбец или несколько столбцов, относительно значений которых будет делаться разнесение таблицы на секции. К потенциальным столбцам для создания ключа секционирования относятся столбцы типа date (например, столбец created - дата создания строки или updated - дата изменения строки) для секционирования по методам Range и List . Столбцы типа number с высокой степенью уникальности значений хорошо подходят для секционирования по методам Range и Hash . Столбцы, имеющие список фиксированных значений, подходят для секционирования по списку List .
В Oracle 11g появилась возможность в качестве ключа секционирования использовать виртуальный столбец (virtual column), построенный на функции к реальному столбцу таблицы. Виртуальный столбец в действительности не хранится в таблице, а каждый раз вычисляется при обращении к нему во время ввода данных в таблицу. Для создания виртуального столбца используется фраза generated always as. после которой идет функция, выполняемая над реальным столбцом таблицы, а далее идет обязательная фраза virtual. Например, PARTID generated always AS (to_char(UPDATED,'MM')) virtual . Возможен вариант создания виртуального столбца более короткой фразой PARTID AS (to_char(UPDATED,'MM')) .
Увидеть, какой столбец в таблице виртуальный позволяет запрос:
Замечание. При вводе данных в таблицу с виртуальным столбцом следует указать в insert и values перечень столбцов, иначе будет ошибка ORA-00947: not enough value .
Секционирование методом Range по диапазону ключа
В практике секционирования по методу Range используем два вида секционирования: по диапазону дат и по диапазону значений.
Что не так со встроенными механизмами Oracle DB
Убирать данные на ленту и возвращать их из долговременного архива помогает опция Partitioning, с ее помощью можно разделить таблицу на части по какому-то принципу, например, по диапазону дат. Кроме управляемости и доступности, такое разделение еще позволяет повысить производительность. Каждый период хранится в отдельном табличном пространстве, что позволяет с помощью технологии transportable tablespace, достаточно быстро перемещать табличные пространства между различными отчетными и архивными БД с различными версиями и платформами. Но проблема в том, что стандартных механизмов не всегда достаточно: они позволяют только создавать базовые структуры без учета специфики приложения. А дальше администратор вынужден создавать вокруг них кучу инструментов управления. Да и сам процесс отключения-подключения-переноса требует навыков администрирования БД. Поэтому задача минимум – автоматизировать этот процесс, сделать его доступным для администраторов приложений.
Мы разработали набор скриптов, с помощью которых можно управлять секционированными таблицами, получать любую информацию о них и т.д. Не нужно знание команд, опыта работы с СУБД. Администратор приложения просто запускает скрипт или выбирает в интерфейсе нужное действие, указывает нужную партицию, и все происходит само собой.
Хеш-секционирование HASH
Как правило, если не получается секционировать по диапазону RANGE или LIST , то применяется хешсекционирование, основанное на хеш-функции. В этом случае строки таблицы равномерно распределяются между секциями на основании внутренних алгоритмов хеширования Oracle. При этом чем уникальнее значения столбца в таблице, по которому идет секционирование, тем лучше будет распределение данных по разделам. Первичный ключ или уникальный столбец (столбцы) является самым хорошим хеш- ключом. Oracle рекомендует число секций N как степень 2, т.е. N=2,4,8,16,32 и т.д. При этом добавление или удаление какой-то хеш-секции вызывает перезапись всех данных в другие секции. Рассмотрим HASH секционирование на примере индексноорганизованной таблицы LISTIN. Целью HASH секционирования таблицы было добиться существенного снижение числа блокировок, возникающих в этой таблице. Эта цель была успешно реализована за счет секционирования таблицы по 16 секциям (фраза PARTITIONS 16 ), где ключом секционирования выступал столбец TASKISN. Команда создания таблицы имеет вид:
Следует заметить, что если в качестве ключа секционирования используется столбец, в котором имеем очень неравномерное распределение значения столбца (малая уникальность), то применение хеш-секционирования не целесообразно. При этом число секций не имеет особого значения, поскольку все значения ключевого столбца «свалятся» в одну-две секции.
Замечание. Увидеть размер секций в mb по всем указанным выше методам можно по запросу:
Секционирование методом RANG по диапазону значений
Секционирование по диапазону значений похоже на секционирование по диапазону дат, только вместо ключа по дате используется ключ по столбцу, принимающему числовое значение (желательно имеющее равномерное распределение по всему диапазону значений). Для этого хорошо подходит столбец с уникальным значением. Рассмотрим на примере той же таблицы AIF.HISTLG, секционированной выше по диапазону дат. В качестве ключа секционирования используется столбец ISN с уникальными значениями. Команда создания таблицы имеет вид:
где PARTITION BY RANGE (ISN) говорит о секционировании no RANGE при ключе секционирования ISN, интервал создания секции через 1000 значений.
Секционирование по списку ключей LIST
Секционирование по списку применяется, если есть возможность указать конкретный перечень дискретных значений столбца, по которому происходит разбиение на секции. При секционировании по LIST в команде create указываются метод секционирования LIST (PARTITION BY LIST) , ключ секционирования и имена секций, в которых указывается одно или несколько дискретных значений.
В качестве примера проведем секционирование таблицы AIF.AGREEM. используя в качестве ключа виртуальный столбец partid. При каждом вводе строки в таблицу в виртуальном столбце формируется числовой номер месяца по функции to_number(to_char(updated,'MM')) . Таблицу разбиваем на 12 секций, кроме того, используем подход секционирования по циклу, когда в следующем году строки января вводятся в ту же секцию января, а перед этим секция за январь чистится от старых данных по delete или по truncate. Команда создания секции примет вид:
Вместо виртуального столбца может быть введен реальный столбец partid (тип number) , заполняемый при вводе строки в таблицу. Указанный выше вариант эффективно использовался в таблицах как с 366 секциями, так и с 12 с очисткой последних по truncate, поскольку информация в таблицах хранится меньше года. Достоинство этого подхода в том, что создавать новые секции не приходится, а табличное пространство старых секций ежемесячно быстро освобождается по truncate .
Замечание. Если необходимо очистить табличное пространство секции, то используются либо команды сжатия SHRINK , либо MOVE (перемещения в табличное пространство):
Другие стандартные варианты секционирования по методу LIST изложены в различных источниках.
«Хьюстон, у нас проблема»
В ходе реализации этих механизмов мы столкнулись с еще одной проблемой, неожиданно часто возникающей у заказчиков. В процессе отключения что-то может пойти не так, вплоть до банального отключения электричества, так что подключение секции может в любой момент прерваться. В результате получаем базу, которая находится в «промежуточном» состоянии.
В СУБД Oracle есть DDL и DML. В DML реализован механизм для обеспечения транзакционной целостности, который откатывает назад результаты, если транзакция не прошла. В DDL такого механизма нет, и любые действия с секцией – это путь в один конец.
Мы разработали механизм, который проверяет выполнение всех шагов по отключению-подключению партиции и корректирует возникающие проблемы. В случае возникновения проблем механизм перезапускает операции с партицией с того момента, когда что-то пошло не так. Ошибки при отключении-подключении логируются, и это позволяет в любой момент узнать, какие проблемы и когда возникали.

Партицирование таблиц Oracle по диапазон у значений основывается на каком-либо столбце табличных данных, который содержит уникальные сведения. Создание отдельных табличных секций происходит по такому принципу:
CREATE TABLE MY.NEWTABLE ( ISN NEWNUMBERS. UPDATED NEWDATES) TABLESPACES HSTNEWDATA
PARTITION BY RANGE (ISN)
(PARTITION PARTISAN_01 VALUE LESS THAN (1500),
PARTITION PARTISAN_02 VALUE LESS THAN (2500),
PARTITION PARTISAN_03 VALUE LESS THAN (3500),
PARTITION PARTISAN_MAXIMUM VALUE LESS THAN (MAXVALUES)
) ENABLE ROW MOVEMENT;
Партицирование таблиц Oracle по спискам значений
Такой метод партицирования удобен, когда присутствует возможность определить список элементов конкретного столбца, чтобы по ним разбить табличное представление на отдельные области. Вот как это происходит на практике:
CREATE TABLE MY.NEWTABLE (ISN NEWNUMBER,UPDATED NEWDATES, L
PARTID AS (TO_NEWNUMBERS(TO_CHAR(UPDATEDS, ’ ’)))
) PARTITION BY LIST(PARTID)
( PARTITION TABLEPART_3 VALUES (3),
PARTITION TABLEPART_4 VALUES (4),
PARTITION TABLEPART_14 VALUES (14));
Партицирование по хеш-значению
Первые два способа партицирования наиболее популярны и часто используются. Все способы, которы е будут описаны ниже , применяются в специфич еских случаях, в том числе и разбивка на табличные секции по хеш-значению. Данный способ основывается на хеш-функциях, поэтому считается наиболее точным.
Вот как этот способ выглядит на практике:
CREATE TABLE MY.NEWTABLE (TASKSISN NEWNUMBERS, OBJECTISN NEWNUMBERS, K PARAMETRS NEWNUMBERS,
CONSTRAINT NEWPK_LISTIN PRIMARY NEWKEY(TASKSISN,OBJECTISN,OBJECTROWID,K PARAMETRS)
) MYORGANIZATION INDEX INCLUDING PARAMETRS OVERFLOW PARTITION BY HASH (TASKSISN) PARTITIONS 24
Составное партицирование
При таком методе внутри одной секции образу е тся несколько связанных подсекций. А вообще, такой метод понимает смешанное применение нескольк их других методов, описанных чуть выше , н апример , по списку значений и хеш-значениям и др. Причем сочетания способов мо гут быть различным и .
Вот как выглядит составное партицирование таблиц Oracle, где одновременно используются первые два способа, описанные сегодня в статье:
CREATE TABLE MYTABLE.NEWPAY_ORD_RECORDING ( ISN NEWNUMBERS, K
NEWPAY_NEWDATA NEWDATES, NEWPAYER_NEWNAMES VARCHAR3(255). K NEWSTATUS NEWNUMBERS ) TABLESPACE HSTNEWDATA
PARTITION BY RANGE (NEWPAY_NEWDATA)
INTERVAL (NEWINTERVAL '7' DAYS)
SUBPARTITION BY LIST (NEWSTATUS)
SUBPARTITION NEWTEMPLATE (
SUBPARTITION NEWSTATUSK) VALUE0 (0) K TABLESPACE TRNEWDATA1,
SUBPARTITION NEWSTATUS_1 VALUE1 (1) K TABLESPACE TRNEWDATA2,
SUBPARTITION NEWSTATUSK VALUE2 (2) K TABLESPACE TRNEWDATA3 )
(PARTITION PK015KK1 VALUE LESS K
THAN(TO_NEWDATE('02.02.2022','DD.MM.YYYY')))
ENABLE ROW MOVEMENT;
Решение для прочих случаев
В случаях случаях, когда мы указываем секцию по умолчанию, мы можем разделять ее тогда, когда туда уже попали записи, вопрос в том как это автоматически отслеживать.
В Data dictionary мы можем получить информацию о всех секциях секционированных таблиц, сделав выборку из dba_tab_partitions, в которой partition_position указывает порядок секции в таблице, а high_value — параметры секции. Следовательно, мы можем получить имя последней секции в таблице и сделать выборку из нее для получения количества записей в ней.
- если у вас настроена автоматическая отправка алертов на почту, то просто записать событие в alert.log;
- просто написать процедуру для отправки писем с уведомлением.
- первый(BINARY_INTEGER) — куда записывать, с возможными значениями:1 — в стандартный трейс-файл, 2 — в alert.log, 3 — в оба;
- и второй(varchar2) — собственно сама строка, которую пишем.
Второй вариант — использовать пакет utl_mail или более низкоуровневые — utl_smtp или utl_tcp.
utl_mail — это более удобная обертка для utl_smtp, но для ее использования обязательно необходимо установить параметр smtp_out_server. Вы можете сделать это как только для сессии — «ALTER SESSION SET smtp_out_server = . » так и для системы «ALTER SYSTEM SET smtp_out_server = . ».
Не удивляйтесь, если вы не можете найти этот пакет у себя — изначально он не включен и для его создания вы должны выполнить два скрипта:
- function get_penultimate_maxvalue(p_table_owner varchar2, p_table_name varchar2) return varchar2;
Функция принимает в качестве параметров владельца и имя таблицы и возвращает значение условия(high_value) предпоследней секции. Данная информация может быть нужна, например, в случаях, где последняя секция — секция c maxvalue параметром, и, соответственно, параметр предпоследней секции может быть нужен для определения параметра для новой секции. - function get_maxvalued_partitions return tables_props_array pipelined;
Функция возвращающая названия таблиц и их владельцев, у которых начала заполняться последняя секция.
Пример использования:
- select
- p.*,
- sys.pkg_partitions.get_penultimate_maxvalue(p.table_owner,p.table_name) pre_maxvalue
- from
- table (sys.pkg_partitions.get_maxvalued_partitions) p
UPD
Как правильно подсказал zhekappp можно использовать num_rows при включении автоматического сбора статистики. Сбор статистики можно будет включить добавлением задания с помощью dbms_job с dbms_stats.gather_table_stats.
Тогда нужно будет убрать запрос количества записей в секции и изменить запрос на:
- select
- pl.table_owner,
- pl.table_name,
- count (1) cnt,
- max (pl.num_rows) keep(dense_rank last order by (pl.partition_position)) partition_rows,
- max (pl.partition_name) keep(dense_rank last order by (pl.partition_position)) partition_name
- from dba_tab_partitions pl
- where pl.table_name not like 'BIN$%'
- group by pl.table_owner,pl.table_name
Методы секционирования таблиц
Секционирование повышает эффективность работы с таблицами и индексами
Выбранный ключ секционирования, как правило, определяет методы секционирования. В настоящее время имеются следующие методы секционирования таблиц:
- Range -секционирование по диапазону ключа,
- List - секционирование по списку ключа.
- Hash - хеш-секционирование,
- составное секционирование.
- интервальное секционирование.
- ссылочное секционирование,
- системное секционирование
Последние три появились в Oracle 11g. вместе с тем последние два у нас пока не нашли большого применения.
(Не)совместимость версий
Итак, мы автоматизировали отключение секций и отправку их в долгосрочный архив. Но с долгосрочным архивом есть проблема: иногда его нужно вернуть.
Допустим, администратор перенес в него несколько секций в старой версии. Через год вышла новая версия, в которой добавились новые поля в таблицы, новые индексы, и в долгосрочный архив ушло еще некоторое количество секций. А потом безопасник расследует некий инцидент, и ему необходимо поднять данные двухлетней давности, т.е. поднять секцию несколько версий назад и каким-то образом подключить ее к БД.
Структура таблиц новой версии иногда отличается от исторической. Необходим ряд проверок и изменений для архивной секции. Проверка всегда начинается со сравнения текущей версии Solar Dozor и версии СУБД, и подключаемой партиции. Если есть различия, запускаются процедуры, корректирующие метаданные, добавляются необходимые поля, индексы, ключи, проверяется консистентность подключаемых данных, и пр., удаляется лишнее.
Дополнительные сложности приносит и использование для поиска в Solar Dozor текстовых индексов. Есть некоторые баги, связанные с EXCHANGE PARTITION для текстовых индексов, созданных в разных версиях СУБД или при использовании transportable tablespace (до 12 версии index metadata corruption). Патчи не всегда есть для нужной версии или платформы. Пересоздавать индексы при подключении – не быстрая и достаточно ресурсоемкая процедура. Пришлось «впилить» workaround-ы в процедуры подключения партиции. Структура DR$ таблиц текстовых индексов подключаемой партиции «выравнивается» с текущей, апдейтится поле таблицы ctxsys.dr$index.
Есть и защита от разных ошибок администраторов. Например, на уровне приложения запрещены любые действия с партицией, в которую в данный момент заливаются данные и имеющую статус «current».
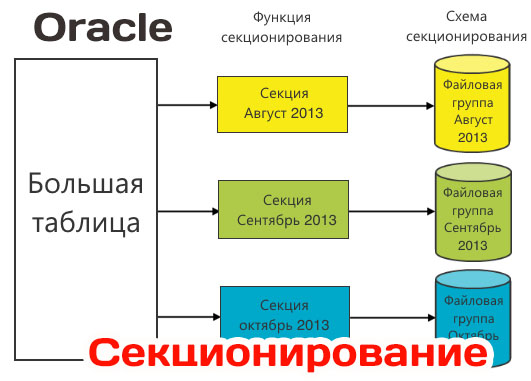
Секционирование методом Range по диапазону дат
При секционировании этим методом нами используются секционирование по дням, месяцам и по годам. Секционирование этим методом покажем на примере таблицы HISTLG в схеме AIF. Ключом секционирования выступает столбец updated (дата корректировки строки), при этом секции создаются с шагом секций в один месяц. Команда создания секционированной таблицы create имеет вид:
В команде CREATE указаны табличное пространство TABLESPACE HSTDATA, в котором будет находиться таблица, метод секционирования и ключ секционирования PARTITION BY RANGE (UPDATED) , имена секций и максимальное значение диапазона ключевого столбца этой секции. Например, первая секция PARTITION PARTMM_2015_01 VALUES LESS THAN TO_DATE('01.01.20157DD.MM.YYYY') говорит о том, что все значения столбца update меньше 01.01.2015 попадут в первую секцию, а значения update меньше 01.02.2015 попадут во вторую секцию и т.д. В таблице создана последняя секция PARTITION PARTMM_MAX VALUES LESS THAN (MAXVALUE) , позволяющая при превышении значения ключа значения диапазона предпоследней секции размещать строки таблицы в эту последнюю секцию (это подстраховка на случай, если забыли создать новую секцию). Фраза COMPRESS определяет, что первая секция будет сжата.
Следует обратить особое внимание на последнюю фразу ENABLE ROW MOVEMENT , которая позволяет переходить строкам таблицы из секции в секцию. В отсутствии этой фразы Oracle выдаст ошибку. Переход строк по секциям может происходить автоматически при изменении значения ключа (например, столбец updated в результате операции update изменит значение на то. при котором он должен уже принадлежать другой секции) или может происходить специально, например, для перевода строк из оперативной секции в архивную секцию путем изменения значения ключевого столбца. Если не указали эту фразу при создании таблицы, то, чтобы избежать ошибки, следует выполнить команду ALTER TABLE ИМЯ ТАБЛИЦЫ ENABLE ROW MOVEMENT .
Увидеть секции таблицы можно по запросу:
А содержимое секции по запросу:
Системное секционирование (system partitioning)
Появилось в Oracle 11 g и применяется, как правило, для таблиц, которые не могут быть секционированы никакими другими методами. В этом методе Oracle сам управляет, какую строку таблицы в какую секцию помещать. Для этого метода необходимо просто написать название секций, например, секции Р1, Р2, РЗ:
Увидеть разбиение таблицы на секции можно по запросу:
Увидеть метод секционирования, что он именно SYSTEM , можно по запросу:
Следует заметить, что для правильного ввода данных в таблицу надо, помимо имени таблицы, указать еще имя сегмента, иначе будет ошибка ORA-14701 . Тоже для ускоренной выборки данных по запросу следует указать имя сегмента.
Замечание. В таблице подвергнуться секционированию может не только сама таблица, но и индексы таблицы. В силу объемности и важности материала о секционировании индексов пойдет речь во второй части. Там же будет рассказано об особенностях перехода от несекционированных больших по объему таблиц к секционированным таблицам, в том числе о возникающих в этих случаях особенностях поведения индексов, триггеров, синонимов и т.д. этих таблиц.
В версии 11g в Oracle появилась несколько новых замечательных схем секционирования — например, удобная функциональность интервального секционирования — автоматического создания секций по мере выхода range из заданных границ.
В версиях до 11g необходимо периодически вручную либо заранее добавлять секции, либо разбивать секцию по умолчанию. То есть постоянно необходимо отслеживать состояние таких таблиц. В данной статье я поделюсь своими решениями для автоматизации таких задач секционирования.
Сначала приведу пример для 11g:
- create table res (
- res_id number not null ,
- res_date date ,
- hotel_id number(3),
- guest_id number
- )
- partition by range (res_id)
- interval (100) store in (users)
- (
- partition p1 values less than (101)
- );
Этот скрипт создает секцию p1 для записей, значение столбца res_id которых находится в диапазоне 1-100. Когда вставляются записи со значением столбца res_id меньшим 101, они помещаются в секцию p1, а когда в новой записи значение этого столбца равно или больше 101, сервер Oracle Database 11g создает новую секцию, имя которой генерируется системой. Подробнее с этим примером и прочими новыми схемами секционирования вы можете познакомиться в переводе статьи Арупа Нанды в русском издании Oracle Magazine.
Рассмотренные ниже решения можно применить и в других СУБД, не поддерживающих автоматическое добавление секций
Автоматическое выполнение
Осталось только настроить автоматическое выполнение. Сделаем это с помощью dbms_job.
Например, ежедневное автоматическое выполнение скрипта получения данных:
Мы уже рассказывали о том, почему секционирование баз данных очень важно для производительности DLP-системы и как мы реализовывали его в PostgreSQL. В этой статье речь пойдет об Oracle.
Специфика использования СУБД в DLP-решениях состоит в том, что объем данных прирастает очень быстро. Их невозможно держать в оперативном архиве, и долговременное хранение – это необходимость в компании численностью свыше хотя бы 50 человек. При этом оперативный архив наполняется так быстро, что отдавать информацию в долгосрочный архив приходится раз в 2 недели или чаще. Использование только встроенных средств СУБД требует знаний и опыта. Это главная сложность, и она, в общем-то, очевидна «на берегу».
Кроме того, возникают проблемы, не очевидные сразу. Как вернуть из долгосрочного архива партицию с данными более старой версии приложения и прицепить к более свежей? Что делать, если у них разных формат хранения данных? Что делать, если подключение секции было прервано, и она «зависла» между долговременным и оперативным архивом?

В целом, решение этих вопросов сводится к двум основным техническим задачам: автоматизация управления секциями в СУБД Oracle (отключение и подключение) и система «отката» секций в случае, если при подключении что-то пошло не так.
Заключение
Сегодня мы лишь поверхностно коснулись темы «Партиционирование таблиц Oracle» и привели простейшие практические примеры, чтобы вы могли ознакомит ь ся с тем , как оно выглядит. В следующих статьях мы подробнее остановимся на каждом отдельном методе, потому что по каждому из ни есть что рассказать.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Решение для равномерно увеличивающегося ключа секционирования без пропусков
- create table test_part(
- id number not null ,
- name varchar2(100) not null ,
- owner varchar2(100) not null ,
- type varchar2(100) not null ,
- created date not null ,
- constraint test_part_pk
- primary key (id)
- )
- partition by range (id) (partition p1 values less than (10000));
Логично, что если в такой таблице не будет пропусков, то новые секции было бы желательно создавать до того как ключ секционирования приблизится к границе максимальной секции. Сколько у нас осталось значений ключа до границы, мы легко можем определить согласно простой формуле: partition_size — (key-start_key_in_partition), где key — текущий ключ секционирования, start_key_in_partition — первый ключ, который попадает в эту секцию, partition_size — количество ключей в секции, а % — операция целочисленного деления(div). Обычно такое секционирование производится на равные секции, и с учетом этого мы можем упростить эту формулу до такой: partition_size — key%partition_size.
Что нам это дает: зная момент мы можем создать триггер, который будет добавлять секции при наступлении данного события.
Создадим данный триггер:
- create or replace trigger tr_test_part
- before insert on test_part
- for each row
- when (mod( NEW .id,10000) = 6000)
- declare
- l_part_name number;
- l_maxvalue number;
- l_exist number;
- l_partition_exists exception ;
- PRAGMA EXCEPTION_INIT(l_partition_exists, -14074);
- PRAGMA AUTONOMOUS_TRANSACTION;
- begin
- l_part_name:=ceil(: NEW .ID/10000)+1;
- BEGIN
- execute immediate 'alter table xtender.test_part add partition p' ||l_part_name|| ' values less than(' ||l_maxvalue|| ')' ;
- EXCEPTION
- when l_partition_exists then null ;
- END ;
- end tr_test_part;
Данный триггер с использованием автономных транзакций автоматически создает новую секцию с именем 'P'+номер секции размером в 10000, когда ID — наш ключ секционирования — остается 4000 значений до границы секции(10000-4000 = 6000, т.е. и тд.), но сначала проверяется не существует ли уже данная секция(такое может произойти, например, при повторном добавлении 6000-й записи, или ручном добавлении секции). Параметры секционирования — 10000 и 4000, вы должны подбирать исходя из вашей конкретной ситуации, но следует учесть, что граница(4000 в примере) должна быть больше максимального количества одномоментно добавляемых записей, т.к. иначе на момент транзакции вставки данных, транзакция не будет «знать» о новой секции, т.к. на начало транзакции ее не существовало, поэтому данные вставлены не будут с жалобой об отсутствии сопоставления секции данному ключу. Этого бы можно было избежать с использованием alter table split default_partition, который я рассмотрю далее, но это скажется на времени выполнения.
Проверим наш триггер, заполнив секцию:
insert into xtender.test_part
select rownum, o.OBJECT_NAME, o.OWNER, o.OBJECT_TYPE, o.CREATED
from all_objects o
where rownum
Кроме того, в случае использования сиквенсов, которые из-за кэширования «шагают» не последовательно можно изменить триггер, чтобы он выполнялся для набора значений с 4000 до 3900 записи с конца секции:
заменим условие
на
Составное секционирование
При составном секционировании внутри секции создаются подсекции Однако в версиях до Oracle 11g смешанное секционирование разрешалось только по RANGE методу для секции и методам HASH или LIST для подсекции. В Oracle 11g варианты методов секций-подсекций были существенно расширены, и в настоящее время можно осуществлять составное секционирование в следующих комбинациях: Range-Range, Range-Hash , Range-List, List-Range, List-Hash или Ust-List. Надо отметить, что при составном секционировании данные физически хранятся в подсекциях, а секции высту-пают только в роли логических контейнеров.
Рассмотрим смешанное секционирование на примере таблицы платежей AIF.PAY_ORD_RECORD с делением таблицы на секции по методу RANGE , а на подсекции по методу LIST . Ключом секционирования по секциям выступает столбец PAY_DATA (тип date), а ключом секционирования подсекции выступает столбец STATUS (тип number), принимающий три значения: 0. 1,2. Команда создания секционированной таблицы в Oracle 11g с секционированием по месяцам примет вид:
где разбиение по секциям задает фраза PARTITION BY RANGE (PAY_DATA) , а по подсекциям фраза SUBPARTITION BY LIST (STATUS) . Далее идет список подсекций со своими значениями: STATUS_0 VALUES (0) . STATUSJ VALUES (1) . STATUSJ? VALUES (2) . Для каждой подсекции может быть задано свое табличное пространства, которое может отличаться от табличного пространства таблицы HSTDATA. С гомощью предложения SUBPARTITION TEMPLATE один и тот же набор подсекций будет автоматически использоваться во всех секциях. Однако создание подсекций можно сделать вручную, указав все подсекции для каждого секции. Просмотреть созданные подсекции по имени таблицы можно по запросу:
Создание новой секции в секционированной таблице по методу Range
Каждый раз при создании секционированной таблицы возникает непростой вопрос: как создавать новые секции. До Oracle 11g было три варианта создания новой секции.
Первый вариант - это в команде create таблицы вручную создается множество секций (например, на несколько лет вперед). Однако, как показала практика, этот метод приводит к тому, что через несколько лет о том, что таблица была секционирована, могут забыть. Когда об этом вспоминают, то оказывается, что информация длительное время пишется в одну и ту же последнюю секцию THAN (MAXVALUE) . В результате секционированная таблица практически превратилась в обычную таблицу. В этой ситуации надо либо снова создавать новую секционированную таблицу, либо по команде Split разбивают последнюю секцию на несколько секций. Например, для таблицы AIF.HISTLG (секционированной по дате) команда Split по созданию новой секции PARTMM_2016_01 на основе расщепления последней PARTMM.MAX секции имеет вид:
Фраза UPDATE GLOBAL INDEXES обеспечивает исправность индексов после команды Split.
Второй вариант - создать процедуру, которая автоматически образует новую секцию. Такая универсальная процедура для секционирования по дням и месяцам была нами разработана. Данная процедура запускается Job Sheduler ежедневно для секционирования по дням или ежемесячно для секционирования по месяцам.
Данные процедуры успешно работают уже несколько лет, своевременно создавая новые секции. Основой процедуры являются представление ALL_TAB_PARTITIONS ДЛЯ поиска последней секции таблицы и команда Split для расщепления этой секции по команде ALTER , указанной выше.
Третий вариант (разработан нашими специалистами и успешно применяется в течение несколько лет) - это создание секционированной таблицы с секциями, используемыми по циклу. Под секционированием таблиц по циклу понимаются секционирование, выполненное в соответствии с двумя правилами. Первое правило - таблица должна содержать фиксированное количество секций, равное либо максимальному числу дней в месяце (31 секция), либо максимальному число дней в году (366 секций), либо числу месяцев в году (12 секций). Второе правило: данные в одну и ту же секцию попадают с определенной периодичностью (цикличностью).
Например, в следующем году информация за январь пишется снова в ту же секцию января, что и в прошедшем году. При этом секции чистятся от прошлогодней информации. Преимущество этого метода в том, что не надо создавать новые секции.
В Oracle 11g появилась новая замечательная возможность автоматического создания секций с использованием при создании таблицы фразы INTERVAL (такой подход называется интервальное секционирование Interval Partitioning). Тогда при создании секций методом Range по интервалу дат с использованием фразы Interval команда создания секционированной таблицы примет вид:
где фраза INTERVAL (INTERVAL '1' MONTH) указывает, что секции будут автоматически создаваться каждый месяц (та же фраза может иметь вид INTERVAL (NUMTOYMINTERVAL (1. 'MONTH') . Для секционирования по дням используется фраза INTERVAL (INTERVAL '1' DAY) , а по годам - INTERVAL (INTERVAL '1' YEAR) . При автоматическом создании секций методом Range по интервалу значений с использованием фразы Interval команда создания таблицы примет вид:
где фраза INTERVAL(1000) задает режим автоматического создания секции через 1000 значений ISN.
Следует учесть, что новые секции создаются в процессе ввода данных. Следует также иметь в виду, что имя новой автоматически создаваемой секции будет иметь вид SYS_PNNNNN, например, SYS_P28981. При этом при интервальном секционировании не нужно создавать последнюю секцию VALUES LESS THAN (MAXVALUE) . иначе появится ошибка ORA-14761.
Таким образом, в Oracle 11g у команды create создания секционированной таблицы существенно меньшее число строк, а о создании новой секции своевременно позаботится Oracle.
Задачи, решаемые секционированием
Прежде чем приступить к секционированию, надо четко определить задачи, которые предполагается решить
- Первой и наиболее часто решаемой задачей при секционировании является повышение производительности работы SQL-запросов и DML-операций по модификации строк таблицы. Это достигается за счет того, что поиск и модификация строк в таблице идут не по всей таблице, а только в ее части (в одной или нескольких секциях). Кроме того, разбиение таблицы на секции позволяет увеличит скорость обработки таблицы за счет использования параллелизма.
- Вторая задача, которая нашла широкое применение в нашей организации, - это быстрое удаление значительного числа строк в больших таблицах за счет выполнения операции truncate секций. Другим широким применением секционирования является освобождение табличного пространства, занимаемого таблицей, после удаления строк из таблицы командой delete. Использование команд Shrink (сжатие таблицы) или Move (перемещение в табличное пространство) для освобождения табличного пространства в большой несекционированной таблице может занимать значительное время. В секционированных таблицах выполнение таких команд в пределах секции будет выполниться существенно быстрее.
- Третьей задачей секционирования является разбиение большой таблицы на оперативную и архивную части. Особенно это эффективно, если оперативная часть в виде секции интенсивно пополняется и модифицируется, а архивная часть (секции) менее подвержена изменениям, и существенно реже из нее извлекается информация. Строки таблицы из оперативной секции со временем могут быть переведены в архивные секции, при этом архивные секции могут периодически очищаться.
- Четвертой задачей является существенное снижение конкуренции за строки и индексы таблицы, в том числе уменьшения вероятности блокировок. Так в результате секционирования одной из таблиц по HASH-методу полностью была решена задача множественных блокировок, возникающих в таблице.
- Пятой задачей является обеспечение устойчивости функционирования таблиц. Поскольку секция - это поименованный самостоятельный фрагмент памяти на дисках, то при возникновении проблем в одних секциях другие продолжают успешно функционировать. Устойчивости функционирования способствует также хранение секций в различных табличных пространствах и на различных физических носителях. Это особенно важно для таблиц, которые обеспечивают работу множества других таблиц (например. справочники, к которым идет интенсивное обращение). Кроме того, секционирование позволяет осуществлять независимое копирование и резервирование секций, оперативное восстановление секций, а также возможности более быстрой и более частой перестройки индексов наиболее активной секции, не затрагивая индексы пассивных секций.
Читайте также: