
Для чего нужна opencl dll
Следует отметить, что несмотря на общее негативное мнение пользователей (определённого сегмента) относительно «забагованности» операционной системы Windows 10, разработчики из компании Microsoft всё-таки сделали более стабильную систему, нежели всеми любимая Windows 7. Это мнение основано на уже продолжительном опыте работы с десятой версии на разных компьютерах на разной конфигурации и с различными «стресс-тестами». Но даже с наличием более проработанных инструментов «доставки» и установки файлов обновлений в работе операционной системы Windows 10 всё ещё встречается множество ошибок, большая часть которых связана с некорректной работой драйверного обеспечения и с нарушением целостности файлов динамической библиотеки компоновки. В том числе это распространяется и на тему настоящей статьи, где разбору подлежит ошибка с утверждением об отсутствии файла «OpenCL.dll». В чём причина возникновения данной ошибки? А главное — каким образом её можно решить? Обо всём этом и пойдёт речь далее.
Как устранить ошибку OpenCL.dll.
OpenCL в повседневном использовании
Сейчас вы подумаете «ага, будут говорить про игры и фотошоп». Нет, OpenCL способен ускорить вычисления не только связанные с графикой. Одним из самых популярных приложений, использующих возможности GPGPU является… кроссплатформенный офисный пакет LibreOffice. Поддержка OpenCL появилась в нём в 2014 году и применяется для ускорения расчётов в табличном менеджере Calc.
Вот наглядное видеосравнение производительности системы с AMD A10-7850K с графическим ядром R7 и Intel Core I5 с HD4600 на борту:
В синтетических тестах тот же AMD A10-7850K по гетерогенным вычислениям с применением OpenCL обгоняет почти вдвое более дорогой i5-4670K / 4690:

К слову, в науке и её прикладных направлениях есть масса задач, которые отлично перекладываются на векторные процессоры видеоускорителей и позволяют выполнять расчёты в десятки и сотни раз быстрее, чем на CPU.
Например, различные разделы линейной алгебры. Умножение векторов и матриц — это то, чем GPU занимаются каждый день, работая с графикой. В этих задачах им практически нет равных, т.к. их архитектура затачивалась под решение таких задач годами.
Сюда же относятся и быстрое преобразование Фурье, и всё, что с ним связано: решение сложных дифференциальных уравнений различными методами. Отдельно можно выделить гравитационные задачи N-тел которые применяются для расчёта аэро- и гидродинамики, моделировании жидкостей и плазмы. Сложность расчётов заключается в том, что каждая частица взаимодействует с другими, законы взаимодействия достаточно сложны, а вычисления требуется проводить параллельно. Для таких задач OpenCL и возможности GPU AMD подходят как нельзя лучше, т.к. параллельные вычисления с множеством объектов и так успешно решаются на процессорах такого типа каждый день: в пиксельный шейдерах.
Структурированные решётки часто применяются в растровой графике. Неструктурированные — в вычислениях в области гидродинамики и при различных вычислениях с элементами, чьи графы имеют разный вес. Отличия структурированных решёток от неструктурированных в количестве «соседей» каждого элемента: у структурированных оно равное, у неструктурированных — разное, но и те и те отлично ложатся на возможности OpenCL по ускорению вычислений. Сложности по переносу вычислений, в основном, математические. То есть основная задача у программиста — не только «написать» работу системы, но и разработать математическое описание, которое переложит данные на аппаратные возможности с помощью OpenCL.
Комбинаторная логика (сюда же относится и вычисление хэшей), методы Монте-Карло — то, что отлично переносится на GPU. Множество вычислительных модулей, высокая производительность в параллельных вычислениях — то, что реально ускоряет эти алгоритмы.
Как обстоят дела на настоящий момент
Основной проблемой реализации OpenCL от NVidia является низкая производительность по сравнению с CUDA, но с каждым новым релизом драйверов производительность OpenCL под управлением CUDA все ближе подбирается к производительности CUDA приложений. По заявлениям разработчиков такой же путь проделала и производительность самих CUDA приложений – от сравнительно невысокой на ранний версиях драйверов до впечатляющей в настоящее время.
OpenCL vs CUDA
Сравнивать напрямую производительность OpenCL и CUDA практически не имеет смысла. Во-первых, если мы будем сравнивать их на видеокартах AMD и NVidia, то в грубой гонке вычислительных возможностей победят видеоадаптеры AMD: современные ускорители NVidia имеют ряд ограничений по производительности в формате FP64, внедрённые самой NVidia для того, чтобы продавать «профессиональные» видеокарты для вычислений (серии Tesla и Titan Z). Их цена несоизмеримо выше, чем у аналогов по FLOPS на базе решений AMD и их «родственных» карт в номерной линейке NVidia, что делает сравнение достаточно сложным. Можно учитывать производительность-на-Ватт или производительность-на-доллар, но к чистому сравнению вычислительной мощности это не имеет практически никакого отношения: «FLOPS’ы любой ценой» слабо вяжутся с текущей финансовой обстановкой, а по производительности-на-доллар «старушка» 7970 GHz Edition (она же R9 280X) до сих пор является одной из самых выгодных видеокарт.
Во-вторых, можно попробовать сравнить OpenCL и CUDA на видеокарте от NVidia, но сама NVidia реализует OpenCL через CUDA на уровне драйвера, так что сравнение будет несколько нечестным по вполне понятным причинам.
С другой стороны, если брать во внимание не только производительность, то кое-какой анализ провести всё же можно.

OpenCL работает на куда большем списке железа, чем NVidia CUDA. Практически все CPU, поддерживающие набор инструкций SSE 3, видеоускорители начиная с Radeon HD5xxx и NVidia GT8600 заканчивая новейшими Fury / Fury-X и 980Ti / Titan X, APU от AMD, встроенная графика Intel — в общем, практически любое современное железо с несколькими ядрами может воспользоваться преимуществанми данной технологии.
Особенности реализации CUDA и OpenCL (а также достаточно сложная документация, т.к. параллельное программирование в целом далеко не самая лёгкая область разработки), скорее, отражены в специфических возможностях и инструментах разработки, а не в области производительности.
Например, у OpenCL имеются некоторые проблемы с распределением памяти в силу «The OpenCL documentation is very unclear here».
Вместе с тем, CUDA уступает OpenCL в области синхронизации потоков — данных, инструкций, памяти, чего угодно. К тому же с помощью OpenCL можно использовать внеочередное исполнение потоков (out-of-order queues) и инструкций, а CUDA до сих пор умеет только in-order. На практике это позволяет избежать простоев процессора в ожидании данных, и эффект тем заметнее, чем длиннее ковейер процессора и больше разница между скоростью работы памяти и скоростью работы вычислительных модулей. В двух словах: чем больше мощности вы выделите под OpenCL, тем больше будет отрыв в производительности. CUDA для достижения сравнимых результатов потребует написание куда более сложного кода.
Инструменты для разработки (Дебаггер, профилер, компилятор) CUDA несколько лучше, чем аналогичные у OpenCL, но CUDA реализует API через язык C, а OpenCL — через С++, упрощая работу с объектно-ориентированным программированием, при этом оба фреймворка изобилуют «локальными» хитростями, ограничениями и особенностями.

Подход NVidia в данном случае сильно напоминает то, как работает компания Apple. Закрытое решение, с большим набором ограничений и строгими правилами, но хорошо заточенное для работы на конкретном железе.
OpenCL предлагает более гибкие инструменты и возможности, но требует более высокого уровня подготовки от разработчиков. Общий код на чистом OpenCL должен запуститься на любом поддерживающем его железе, вместе с тем «оптимизированный» под конкретные решения (скажем, видеоускорители AMD или процессоры CELL) будет работать заметно быстрее.

В предыдущей статье про OpenCL был сделан обзор этой технологии, возможностей, которые она может предложить пользователю и ее состояния на настоящий момент.
Теперь рассмотрим технологию более пристально. Постараемся понять, как OpenCL представляет гетерогенную систему, какие предоставляет возможности по взаимодействию с устройством и какой предлагает подход к созданию программ.
OpenCL задумывался как технология для создания приложений, которые могли бы исполняться в гетерогенной среде. Более того, он разработан так, чтобы обеспечивать комфортную работу с такими устройствами, которые сейчас находятся только в планах и даже с теми, которые еще никто не придумал. Для координации работы всех этих устройств гетерогенной системе всегда есть одно «главное» устройство, который взаимодействует со всеми остальным посредствами OpenCL API. Такое устройство называется «хост», он определяется вне OpenCL.
Поэтому OpenCL исходит из наиболее общих предпосылок, дающих представление об устройстве с поддержкой OpenCL: так как это устройство предполагается использовать для вычислений – в нем есть некий «процессор» в общем смысле этого слова. Нечто, что может исполнять команды. Так как OpenCL создан для параллельных вычислений, то такой процессор может, иметь средства параллелизма внутри себя (например, несколько ядер одного CPU, несколько SPE процессоров в Cell). Также элементарным способом наращивания производительности параллельных вычислений является установка нескольких таких процессоров на устройстве (к примеру, многопроцессорные материнские платы PC итд.). И естественно в гетерогенной системе может быть несколько таких OpenCL-устройств (вообще говоря, с различной архитектурой).
Кроме вычислительных ресурсов устройство имеет какой-то объем памяти. Причем никаких требований к этой памяти не предъявляется, она может быть как на устройстве, так и вообще быть размечена на ОЗУ хоста (как например, это сделано у встроенных видеокарт).
Собственно все. Больше об устройстве никаких предположений не делается.
Такое широкое понятие об устройстве позволяет не накладывать каких-либо ограничений на программы, разработанные для OpenCL. Эта технология позволит Вам разрабатывать как приложения, сильно оптимизированные под конкретную архитектуру специфического устройства, поддерживающего OpenCL, так и те, которые будут демонстрировать стабильную производительность на всех типах устройств (при условии эквивалентной производительности этих устройств).
OpenCL предоставляет программисту низкоуровневый API, через который он взаимодействует с ресурсами устройства. OpenCL API может либо напрямую поддерживаться устройством, либо работать через промежуточный API (как в случае NVidia: OpenCL работает поверх CUDA Driver API, поддерживаемый устройствами), это зависит от конкретной реализации не описывается стандартом.
Рассмотрим как же OpenCL обеспечивает такую универсальность, сохраняя при этом низкоуровневую природу.
Далее я приведу вольный перевод части спецификации OpenCL 1.0 с некоторыми комментариями и дополнениями.
- Модель платформы (Platform Model);
- Модель памяти (Memory Model);
- Модель исполнения (Execution Model);
- Программная модель (Programming Model);
Модель исполнения (Execution Model).
Выполение OpenCL-программы состоит из двух частей: хостовая часть программы и kernels (ядра; с Вашего позволения я далее буду употреблять английский термин, как более привычный большинству из нас) исполняющиеся на OpenCL-устройстве. Хостовая часть программы определяет контекст, в котором исполняются kernel'ы, и управляет их исполнением.
Основная часть модели исполнения OpenCL описывает исполнение kernel’ов. Когда kernel ставится в очередь на исполнение, определяется пространство индексов (NDRange, определение будет дано ниже). Копия (instanse) kernel'а выполнятся для каждого индекса из этого пространства. Копия kernel'а выполняющаяся для конкретного индекса называется «Work-Item» (рабочей единицей) и определяется точкой в пространстве индексов, то есть каждой «единице» предоставляется глобальный ID. Каждый Work-Item выполняет один и тот же код, но конкретный путь исполнения (ветвления итп.) и данные, с которыми он работает, могут быть различными.
Work-Item'ы организуются в группы (Work-Groups). Группы предоставляют более крупное разбиение в пространстве индексов. Каждой группе приписывается групповой ID с такой же размерностью, которая использовалась для адресации отдельных элементов. Каждому элементу сопоставляется уникальный, в рамках группы, локальный ID. Таким образом, Work-Item'ы могут быть адресованы как по глобальному ID, так и по комбинации группового и локального ID.
Work-Item'ы в группе исполняются конкурентно (параллельно) на PE одного вычислительного блока.
Здесь хорошо видна унифицированная модель устройства: несколько PE -> CU, несколько CU -> устройство, несколько устройств -> гетерогенная система.
Пространство индексов в OpenCL 1.0 называется NDRange и может быть 1-, 2- и 3-мерным. NDRange – массив целых чисел (integer) длины N, указывающий размерность в каждом из направлений.
Выбор размерности NDRange определяется удобством для конкретного алгоритма: в случае работы с трехмерными моделями удобно индексировать по трехмерным координатам, в случае работы с изображениями или двумерными сетками – удобнее, когда размерность индексов – 2. 4х-мерные объекты в нашем мире большая редкость, поэтому размерность ограничена 3. Кроме того, как бы там ни было, но в данный момент основная цель OpenCL – это GPU. GPU Nvidia сейчас нативно поддерживают размерность индексов до 3, соответственно, чтобы реализовать большую размерность, пришлось бы прибегать к хитростям и усложнению либо CUDA Driver API, либо реализации OpenCL.
Контекст исполнения и очереди команд в модели исполнения OpenCL.
- Устройства: набор OpenCL-устройств, которые использует хост.
- Kernel'ы: OpenCL функции, которые исполняются на устройствах.
- Объекты программ (Program Objects): исходные коды и исполняемые файлы kernel’ов.
- Объекты памяти (Memory Objects): набор объектов в памяти, видимых как хосту, так и OpenCL устройству. Объекты памяти содержат значения, с которыми могут работать kernel'ы.
- Команда исполнения ядра: исполнить ядро на PEs устройства.
- Команды памяти: переместить данные в объекты памяти, из них или между ними.
- Команды синхронизации: управление порядком исполнения команд.
- Исполнение по порядку: команды запускаются на исполнение в том порядке, в котором они расположены в очереди и завершаются так же по порядку. То есть команды выполняются последовательно.
- Непоследовательное исполнение: команды отправляются на исполнение по порядку, но не ждут завершения предыдущей команды перед началом исполнения. В этом случае программист должен явно использовать команды синхронизации.
Использование очереди команд, позволяет добиться большой универсальности и гибкости при использовании OpenCL. Современные GPU имеют собственный планировщик, который решает, что и когда и на каких вычислительных блоках исполнять. Использование очереди не стесняет работу планировщика, который имеет собственную очередь команд.
Модель исполнения: категории kernel.
- OpenCL kernel: написаны на OpenCL C и компилируется компилятором OpenCL. Все реализации OpenCL должны поддерживать OpenCl-kernel. Реализации могут предоставлять другие механизмы создания OpenCL-kernel.
- Naitive kernel: доступ к ним осуществляется через хостовые указатели на функцию. Нативные kernel ставится в очередь на исполнение, так же как и OpenCL-kernel и использует те же объекты памяти, что и OpenCL-kernel. К примеру, такие kernel'ы могут быть функциями, определенными в коде приложения или экспортированными из библиотеки. Отметим, что возможность исполнять нативные kernel'ы является опциональной и их семантика не определяется стандартом. API OpenCL включает функции для опроса возможностей устройства на предмет поддержки таких kernel'ов.
Из чего состоит платформа OpenCL
- OpenCL Platform Layer: позволяет хосту обнаруживать OpenCL-устройства, опрашивать их свойства и создавать контекст.
- OpenCL Runtime: среда исполнения позволяет программе на хосте управлять контекстами после того как они были созданы.
- Компилятор OpenCL: компилятор OpenCL создает исполняемые файлы, содержащие OpenCL–kernel. Язык программирования OpenCL-C реализуется компилятором, который поддерживает подмножество стандарта языка ISO C99 с расширениями для параллелизма.
GPGPU, OpenCL и немного истории
Само собой, OpenCL — не единственный способ реализовывать общие вычисления на GPU. Помимо OpenCL на рынке присутствуют CUDA, OpenACC и C++AMP, но по-настоящему популярными и находящимися на слуху являются первые две технологии.
Разработкой стандарта OpenCL занимались те же люди, которые подарили миру технологии OpenGL и OpenAM: Khronos Group. Сама торговая марка OpenCL принадлежит компании Apple, но, к счастью для программистов и пользователей по всему миру, данная технология не является закрытой или привязанной к продукции «яблочной» компании. Помимо Apple в Khronos Goup входят такие гиганты рынка, как Activision Blizzard, AMD, IBM, Intel, NVidia и ещё с десяток компаний (в основном, производителей ARM-решений), которые присоединились к консорциуму позже.
В определённой мере OpenCL и CUDA идеологически и синтаксически схожи, от чего сообщество только выиграло. Программистам (в силу схожести определённых методов и подходов) проще использовать обе технологии, переходить от «закрытой» и привязанной к железу NVidia CUDA к универсальному и работающему везде (в том числе и на обычных многоядерных CPU, и на суперкомпьютерах на базе архитектуры CELL) OpenCL.
Заключение
Технология OpenCL представляет интерес для различных компания IT сферы – от разработчиков игр до производителей чипов, а это означает что у нее большие шансы стать фактическим стандартом для разработки высокопроизводительных вычислений, отобрав этот титул у главенствующей в этом секторе CUDA.
В будущем я планирую более подробную статью о самом OpenCL, описывающую что из себя представляет эта технология, ее особенности, достоинства и недостатки.
Спасибо за внимание.
Недавно мы рассказывали про HSA и в ходе обсуждения преимуществ нового подхода к построению ПК затронули такую интересную тему, как GPGPU — вычисления общего назначения на графическом ускорителе. Сегодня видеоускорители AMD предоставляют доступ к своим ресурсам с помощью OpenCL — фреймворка, обеспечивающего сравнительно простое и понятное программированое высокопараллельной системы.

Сегодня технологии OpenCL поддерживаются всеми основными игроками на рынке: возможность предоставить программам доступ к «продвинутому» ускорению (к тому же бесплатная, т.к. OpenCL не подразумевает каких-либо отчислений и роялти) явно того стоит, а от универсальности таких API выигрывают все, кто реализует поддержку OpenCL в своих продуктах.
Подробнее о том, где сегодня можно встретить OpenCL в повседневной жизни, как он ускоряет обычный офисный софт и какие возможности открывает разработчикам сегодня и поговорим.
Заключение.
В итоге модель OpenCL получилась весьма универсальной, при этом она остается низкоуровневой, позволяя оптимизировать приложения под конкретную архитектуру. Так же она обеспечивает кроссплатформенность при переходе от одного типа OpenCL-устройств к другому. Поставщик реализации OpenCL имеет возможность всячески оптимизировать взаимодействие своего устройства с OpenCL API, добиваясь повышения эффективности распределения ресурсов устройства. Кроме того, правильно написанное OpenCL приложение будет оставаться эффективным при смене поколений устройств.

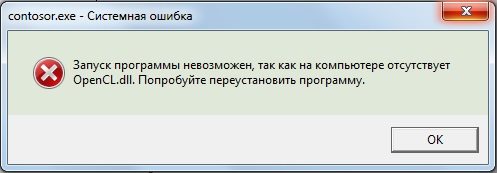
Opencl.dll — одна из библиотек DLL, используемых в программах, использующих технологии OpenCL (Open Computing Language) для просчета графики или других операций с использованием GPU (видеокарты). Технология поддерживается NVIDIA, Intel и AMD.

Скачивать этот файл отдельно со стороннего сайта и пробовать его зарегистрировать в Windows вручную можно, но не является лучшим методом. В случае видеокарт AMD ранее был доступен отдельный OpenCL Driver, но сегодня для систем Windows 10, 8.1 или Windows 7 он не актуален.
Файл opencl.dll присутствует в комплекте драйверов для всех современных дискретных и интегрированных видеокарт: NVIDIA GeForce, AMD Radeon и Intel HD Graphics. Поэтому лучшее и наиболее часто работающее решение — установка этих драйверов:
- Внимание: «обновление» драйвера кнопкой «Обновить» в диспетчере устройств — это не то, что требуется: так мы получим не все файлы и более того, этот метод иногда и вовсе не производит обновления.
- Если вы, еще до того, как нашли это руководство откуда-то скачали и поместили вручную файлы opencl.dll в папки C:\Windows\System32 и C:\Windows\SysWOW64, лучше их оттуда убрать, они могут помешать следующим шагам.
- Скачайте последний драйвер для вашей видеокарты с официального сайта NVIDIA, AMD или Intel. Внимание: если у вас есть и интегрированная и дискретная видеокарта, например, AMD и Intel, загрузите оба драйвера. Особенно это важно для драйверов AMD, без сопутствующей установки драйвера от Intel (при наличии и этого GPU), ошибки amdrsserv.exe могут продолжать появляться.
- Будет полезным (но обычно не обязательно), если перед запуском установщиков вы удалите текущие драйверы: для некоторых это возможно сделать в Панель управления — Программы и компоненты, для некоторых — с помощью бесплатной утилиты Display Driver Uninstaller (DDU).
- Установите загруженный драйвер или драйверы (при наличии нескольких GPU). В случае если установщик в параметрах предлагает выполнить «чистую установку» (например, NVIDIA), выполните именно её.
- На всякий случай перезагрузите компьютер.
После выполнения указанных действий файлы opencl.dll должны автоматически оказаться в папке C:\Windows\System32, а в Windows x64 — еще и в C:\Windows\SysWOW64, а ошибки «Не удается продолжить выполнение кода, поскольку система не обнаружила opencl.dll», «Системная ошибка amdrsserv.exe» (напрямую связанная с драйверами AMD, которые при появлении этой ошибки следует переустановить вручную) и подобные не должны вас больше побеспокоить.
Диагноз и лечение
Начать стоит с того, что, как уже было неоднократно подтверждено, представители данной библиотеки крайне предрасположены к негативному воздействию, даже в большей степени нежели «sys»-объекты (драйверы). Например, на корректность работы данных системных компонентов могут оказывать:
- Пользователем проводились какие-либо манипуляции с системными файлами (например, с реестром).
- Деятельность вирусного программного обеспечения.
- Незавершённость скачивания и установки обновлений для Windows и многое другое.
Наименование файла прямо говорит о его функционале. «OpenCL» — это фреймворк (то есть заготовка или шаблон) для написания программного обеспечения с определённой структурой. В рамках статьи нюансы структуры данного ПО не носят ключевого значения, поэтому и останавливаться на этом более подробно не стоит. Следует лишь выделить немного другую интерпретацию выполняемого им функционала. Заключается она в том, что данная технология необходима для реализации процессов с одновременным применением центрального и графического процессора.
Если вы в поисках решений посещали иные ресурсы в интернете, то с большой долей вероятности встречали такой совет как: «Ручное скачивание «OpenCL.dll» и его ручное помещение в системный каталог или самостоятельная регистрация». При этом приводится множество ссылок на якобы «безопасные» сайты/каталоги/библиотеки, где «dll» можно скачать абсолютно бесплатно и без вирусного ПО внутри. Не стоит утверждать, что они однозначно не правы, но только необходимо учитывать, что представители библиотеки динамической компоновки часто используются для сокрытия в их структуре вирусного программного обеспечения. А если вы скачали подобный объект с сюрпризом внутри, и тем более поместили его в раздел диска, где установлена «Windows», то сами постелили красную дорожку для заражения вирусом собственного компьютера. Необходимо понимать, что на пустом месте ничего не происходит. Возникновению любой ошибки предшествует определённая последовательность каких-либо действий. И именно из этого аспекта следует отталкиваться в поисках решения проблем.

- Первое, что необходимо сделать (особенно для владельцев видеокарт от Nvidia и AMD), – это провести проверку на актуальность драйверов видеокарты. Для проверки лучше использовать официальные ресурсы разработчиков и скачивать драйверы только с проверенных источников.
- Если обновление/переустановка драйверов результатов не дали, то попробуйте предварительно полностью удалить старую версию (можно воспользоваться утилитой «Display Driver Uninstaller») и повторно установите новую.
- Если проблема возникла в игре или в приложении, то особое внимание стоит уделить источнику, который использовался для их установки. Например, смените автора репака, попробуйте воспользоваться другим установочным файлов, в том числе скачайте его/их с официального сайта разработчиков. В том числе на время установки ПО (игры) отключите антивирус.
- Проверьте целостность системных компонентов, для этого:
- Нажмите «WIN+S» и введите «cmd.exe».
- Кликните правой кнопкой мышки и выберите «Запуск от имени администратора».
- Введите и выполните команду «sfc/scannow».
- Дождитесь завершения и вывода результатов сканирования.
- Откройте раздел «Параметры» — «Обновление и безопасность» и нажмите на кнопку «Проверить наличие обновлений» (Check for updates).
Установите все критические обновления, так как уже неоднократно было сказано, что с появлением «Windows 10» большая часть обязанностей по поддержанию актуальности драйверов была делегирована «Центру обновления».
Дополнительная информация
Модель платформы (Platform Model).
Платформа OpenCL состоит из хоста соединенного с устройствами, поддерживающими OpenCL. Каждое OpenCL-устройство состоит из вычислительных блоков (Compute Unit), которые далее разделяются на один или более элементы-обработчики (Processing Elements, далее PE).
OpenCL-приложение исполняется на хосте в соответствии с нативными моделями его платформы. OpenCL-приложение отправляет с хоста команды устройствам на выполнение вычислений на PE. PE в рамках вычислительного блока выполняют один поток команд как SIMD блоки (одна инструкция выполняется всеми одновременно, обработка следующей инструкции не начнется, пока все PE не завершат исполнение текущей инструкции), либо как SPMD блоки (у каждого PE собственный счетчик инструкций (program counter)).
То есть OpenCL обрабатывает некие команды, поступающие от хоста. Таким образом приложение не связано жестко с OpenCL, а значит всегда можно подменить реализацию OpenCL, не нарушив работоспособность программы. Даже если будет создано такое устройство, которое не укладывается в модель «OpenCL-устройства», для него можно будет создать реализацию OpenCL, транслирующую команды хоста в более удобный для устройства вид.
Как это все работает?
В следующей статье я подробно разберу процесс создания приложения OpenCL на примере одного из приложений, распространяемых вместе с Nvidia Computing SDK. Приведу примеры оптимизаций работы приложений для OpenCL, предлагаемые Nvidia в качестве рекомендаций.
- Создаем контекст для исполнения нашей программы на устройстве.
- Выбираем необходимое устройство (можно сразу выбрать устройство с наибольшим количеством Flops).
- Инициализируем выбранное устройство созданным нами контекстом.
- Создаем очередь команд на основе ID устройства и контекста.
- Создаем программу на основе исходных кодов и контекста,
либо на основе бинарных файлов и контекста. - Собираем программу (build).
- Создаем kernel.
- Создаем объекты памяти для входных и выходных данных.
- Ставим в очередь команду записи данных из области памяти с данными на хосте в память устройства.
- Ставим в очередь команду исполнения созданного нами kernel.
- Ставим в очередь команду считывания данных из устройства.
- Ждем завершения операций.
Стоит отметить что сборка программы осуществляется во время исполнения, практически JIT-комиляция. В стандарте описано, что это сделано для того, чтобы можно было собрать программу с учетом выбранного контекста. Так же это позволяет каждому поставщику реализации OpenCL оптимизировать компилятор под свое устройство. Впрочем, программу можно также создавать из бинарных кодов. Либо создавать ее один раз при первом запуске, а в дальнейшем переиспользовать, такая возможность тоже описана в стандарте. Тем не менее компилятор интегрирован в платформу OpenCL, хорошо это или плохо, но это так.
Загрузка и установка opencl.dll — видео инструкция
Надеюсь, инструкция сработала для вашего случая. На всякий случай учитывайте: если проблема появилась после каких-то недавних действий с компьютером, вполне возможно, что вам помогут точки восстановления системы.
Предпосылки появления OpenCL
Основным местом, где можно встретить гетерогенные системы, являются высокопроизводительные вычисления: от моделирования физических процессов в пограничном слое до кодирования видео и рендеринга трехмерных сцен. Раньше подобные задачи решали применяя суперкомпьютеры либо очень мощные настольные системы. С появлением технологий NVidia CUDA/AMD Stream стало возможным относительно просто писать программы, использующие вычислительные возможности GPU.
Стоит отметить, что подобные программы создавались и раньше, но именно NVidiaа CUDA обеспечила рост популярности GPGPU за счет облегчения процесса создания GPGPU приложений. Первые GPGPU приложения в качестве ядер (kernel в CUDA и OpenCL) использовали шейдеры, а данные запаковывались в текстуры. Таким образом необходимо было быть хорошо знакомым OpenGL или DirectX. Чуть позже появился язык Brook, который немного упрощал жизнь программиста (на основе этого языка создавалась AMD Stream (в ней используется Brook+) ).
CUDA стала набирать обороты, а между тем (а точнее несколько ранее) в кузнице, расположенной глубоко под землей, у подножия горы Фуджи (Fuji), японскими инженерами был выкован процессор всевластия Cell (родился он в сотрудничестве IBM, Sony и Toshiba). В настоящее время Cell используется во всех суперкомпьютерах, поставляемых IBM, на его основе постоены самые производительные в мире суперкомпьютеры (по данным top500). Чуть менее года назад компания Toshiba объявила о выпуске платы расширения SpursEngine для PC для ускорения декодирования видео и прочих ресурсоемких операций, используя вычислительные блоки (SPE), разработанные для Cell. В википедии есть статья, в кратце описывающая SpursEngine и его отличия от Cell.
Примерно в то же время (около года назад) оживилась и S3 Graphics (на самом деле VIA), представив на суд общественности свой новый графический адаптер S3 Graphics Chrome 500. По заявлениям самой компании этот адаптер так же умеет ускорять всяческие вычисления. В комплекте с ним поставляется программный продукт (графический редактор), который использует все прелести такого ускорения. Описание технологии на сайте производителя.
Итак, что мы имеем: машина, на которой проводятся вычисления может содержать процессоры x86, x86-64, Itanium, SpursEngine (Cell), NVidia GPU, AMD GPU, VIA (S3 Graphics) GPU. Для каждого из этих типов процессов существует свой SDK (ну кроме разве что VIA), свой язык программирования и программная модель. То есть если Вы захотите чтобы ваш движок рендеринга или программа расчета нагрузок на крыло боинга 787 работала на простой рабочей станции, суперкомпьютере BlueGene, или компьютере оборудованном двумя ускорителями NVidia Tesla – Вам будет необходимо переписывать достаточно большую часть программы, так как каждая из платформ в силу своей архитектуры имеет набор жестких ограничений.
Так как программисты – народ ленивый, и не хотят писать одно и то же для 5 различных платформ с учетом всех особенностей и учиться использовать разные программные средства и модели, а заказчики – народ жадный и не хотят платить за программу для каждой платформы как за отдельный продукт и оплачивать курсы обучения для программистов, было решено создать некий единый стандарт для программ, исполняющихся в гетерогенной среде. Это означает, что программа, вообще говоря, должна быть способна исполняться на компьютере, в котором установлены одновременно GPU NVidia и AMD, Toshiba SpursEngine итд.
Модель памяти (Memory Model).
- Глобальная память. Эта память предоставляет доступ на чтение и запись элементам всех групп. Каждый Work-Item может писать и читать из любой части объекта памяти. Запись и чтение глобальной памяти может кэшироваться в зависимости от возможностей устройства.
- Константная память. Область глобальной памяти, которая остается постоянной во время исполнения kernel'а. Хост аллоцирует и инициализирует объекты памяти, расположенные в константной памяти.
- Локальная память. Область памяти, локальная для группы. Эта область памяти может использоваться, чтобы создавать переменные, разделяемые всей группой. Она может быть реализована как отдельная память на OpenCL-устройстве. Альтернативно эта память может быть размечена как область в глобальной памяти.
- Частная (private) память. Область памяти, принадлежащая Work-Item. Переменные, определенные в частной памяти одного Work-Item’а, не видны другим.
Спецификация определяет 4 типа памяти, но снова не накладывает никаких требований на реализацию памяти в железе. Все 4 типа памяти могут находиться в глобальной памяти, и разделение типов может осуществляться на уровне драйвера и напротив, может существовать жесткое разделение типов памяти, продиктованное архитектурой устройства.
Существование именно этих типов памяти достаточно логично: у процессорного ядра есть свой кэш, у процессора есть общий кэш и у всего устройства есть некоторый объем памяти.
Заключение
Только после применения вышеизложенных рекомендаций (соответственно, если ошибка так и осталась нерешённой) можно (на свой страх и риск) попробовать скачать «OpenCL.dll» и поместить его в директорию вручную. Но все возможные негативные последствия придётся решать вам! Поэтому лучшим вариантом будет всё своё внимание уделить комплексной проверке Windows.
Многие, наверное, слышали или читали на хабре об OpenCL – новом стандарте для разработки приложений для гетерогенных систем. Именно так, это не стандарт для разработки приложений для GPU, как многие считают, OpenCL изначально задумывался как нечто большее: единый стандарт для написания приложений, которые должны исполняться в системе, где установлены различные по архитектуре процессоры, ускорители и платы расширения.
Решение проблемы
Первая версия стандарта была опубликована в конце 2008 года и с тех пор уже успела претерпеть несколько ревизий.
Что ещё можно ускорить с помощью OpenCL и мощных GPU?
Поиск обратного пути. Вычисления графов и динамическое программирование: сортировки, обнаружение коллизий (соприкосновений, пересечений), генерацию регулярных структур, различные алгоритмы выборки и поиска. С некоторыми ограничениями, но поддаются оптимизации и ускорению работы нейронных сетей и связанных с ними структур, но здесь, скорее, проблемы в том, что нейронные структуры просто «дорого» виртуализировать, выгоднее использовать FPGA-решения. Отлично показывают себя работы конечных автоматов (которые и так применяются в работе с GPU, например, когда речь идёт о компрессии / декомпресии видеосигнала или работе по поиску повторяющихся элементов).
Программная модель. (Programming Model)
Модель исполнения OpenCL поддерживает две программные модели: параллелизм данных (Data Parallel) и параллелизм заданий (Task Parallel), так же поддерживаются гибридные модели. Основная модель, определяющая дизайн OpenCL, – параллелизм данных.
Программная модель с параллелизмом данных.
Эта модель определяет вычисления как последовательность инструкций, применяемых к множеству элементов объекта памяти. Пространство индексов, ассоциированное с моделью исполнения OpenCL, определяет Work-Item'ы и как данные распределяются между ними. В строгой модели параллелизма данных существует строгое соответствие один к одному между Work-Item и элементом в объекте памяти, с которым kernel может работать параллельно. OpenCL реализует более мягкую модель параллелизма данных, где строгое соответствие один к одному не требуется.
OpenCL предоставляет иерархическую модель параллелизма данных. Существует два способа определить иерархическое деление. В явной модели программист определяет общее число элементов, которые должны исполняться параллельно и так же каким образом эти элементы будут распределены по группам. В неявной модели программист только определяет общее число элементов, которые должны исполняться параллельно, а разделение по рабочим группам выполняется автоматически.
Программная модель с параллелизмом заданий.
- используют векторные типы данных, реализованные в устройстве;
- устанавливают в очередь множество заданий;
- устанавливают в очередь нативные kernel'ы, использующие программную модель, ортогональную к OpenCL;
Существование двух моделей программирования – также дань универсальности. Для современных GPU и Cell хорошо подходит первая модель. Но не все алгоритмы можно эффективно реализовать в рамках такой модели, а так же есть вероятность появления устройства, архитектура которого будет неудобна для использования первой модели. В таком случае вторая модель позволяет писать специфичные для другой архитектуры приложения.
Читайте также: