
Data default oracle что это
This article describes the changes to table column defaults in Oracle Database 12c.
INDEX_STATS
Представление INDEX_STATS полезно для того, чтобы узнать, насколько эффективно индекс использует свое пространство. Крупные индексы имеют тенденцию со временем становиться несбалансированными, если происходит много удалений данных таблицы (а, следовательно, и индекса). Ваша цель — не упускать из виду эти крупные индексы,чтобы сохранять их сбалансированными.
Обратите внимание, что представление INDEX_STATS наполняется, только когда таблица подвергается анализу с помощью команды ANALYZE, как показано ниже:
Запрос из листинга ниже, использующий представление INDEX_STATS, помогает определить необходимость в перестройке индекса. Чтобы определить, следует ли перестраивать индекс, в запросе необходимо сосредоточиться на перечисленных ниже столбцах представления INDEX_STATS.

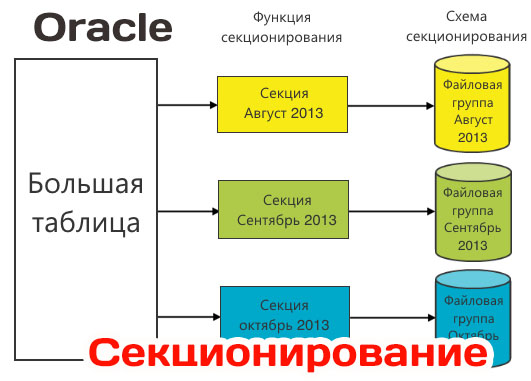
В этой части статьи рассматриваются особенности создания секционированных таблиц, в следующей речь пойдет об особенностях перевода существующих больших несекционированчых таблиц в секционированные таблицы, а также особенности секционирования индексов и работа с секциями.
FOREIGN KEY (FK)
In Oracle, the Foreign Key constraint designates a column (or a set of columns) as a Foreign Key and establishes a relationship between a Primary Key (or Unique) in different table (or in the same table) The syntax used for defining a Check Constraint is as follows:
DBA_TAB_PARTITIONS
Представление DBA_TAB_PARTITIONS подобно представлению DBA_TABLES, но содержит детальную информацию о разделах таблиц. Благодаря DBA_TAB_PARTITIONS, можно узнать имя раздела, его максимальные значения, информацию о хранении раздела,статистику по разделу, а также прочую информацию, которая доступна в представлении DBA_TABLES. В листинге ниже показан простой запрос, использующий представление DBA_TAB_PARTITIONS.
Создание новой секции в секционированной таблице по методу Range
Каждый раз при создании секционированной таблицы возникает непростой вопрос: как создавать новые секции. До Oracle 11g было три варианта создания новой секции.
Первый вариант - это в команде create таблицы вручную создается множество секций (например, на несколько лет вперед). Однако, как показала практика, этот метод приводит к тому, что через несколько лет о том, что таблица была секционирована, могут забыть. Когда об этом вспоминают, то оказывается, что информация длительное время пишется в одну и ту же последнюю секцию THAN (MAXVALUE) . В результате секционированная таблица практически превратилась в обычную таблицу. В этой ситуации надо либо снова создавать новую секционированную таблицу, либо по команде Split разбивают последнюю секцию на несколько секций. Например, для таблицы AIF.HISTLG (секционированной по дате) команда Split по созданию новой секции PARTMM_2016_01 на основе расщепления последней PARTMM.MAX секции имеет вид:
Фраза UPDATE GLOBAL INDEXES обеспечивает исправность индексов после команды Split.
Второй вариант - создать процедуру, которая автоматически образует новую секцию. Такая универсальная процедура для секционирования по дням и месяцам была нами разработана. Данная процедура запускается Job Sheduler ежедневно для секционирования по дням или ежемесячно для секционирования по месяцам.
Данные процедуры успешно работают уже несколько лет, своевременно создавая новые секции. Основой процедуры являются представление ALL_TAB_PARTITIONS ДЛЯ поиска последней секции таблицы и команда Split для расщепления этой секции по команде ALTER , указанной выше.
Третий вариант (разработан нашими специалистами и успешно применяется в течение несколько лет) - это создание секционированной таблицы с секциями, используемыми по циклу. Под секционированием таблиц по циклу понимаются секционирование, выполненное в соответствии с двумя правилами. Первое правило - таблица должна содержать фиксированное количество секций, равное либо максимальному числу дней в месяце (31 секция), либо максимальному число дней в году (366 секций), либо числу месяцев в году (12 секций). Второе правило: данные в одну и ту же секцию попадают с определенной периодичностью (цикличностью).
Например, в следующем году информация за январь пишется снова в ту же секцию января, что и в прошедшем году. При этом секции чистятся от прошлогодней информации. Преимущество этого метода в том, что не надо создавать новые секции.
В Oracle 11g появилась новая замечательная возможность автоматического создания секций с использованием при создании таблицы фразы INTERVAL (такой подход называется интервальное секционирование Interval Partitioning). Тогда при создании секций методом Range по интервалу дат с использованием фразы Interval команда создания секционированной таблицы примет вид:
где фраза INTERVAL (INTERVAL '1' MONTH) указывает, что секции будут автоматически создаваться каждый месяц (та же фраза может иметь вид INTERVAL (NUMTOYMINTERVAL (1. 'MONTH') . Для секционирования по дням используется фраза INTERVAL (INTERVAL '1' DAY) , а по годам - INTERVAL (INTERVAL '1' YEAR) . При автоматическом создании секций методом Range по интервалу значений с использованием фразы Interval команда создания таблицы примет вид:
где фраза INTERVAL(1000) задает режим автоматического создания секции через 1000 значений ISN.
Следует учесть, что новые секции создаются в процессе ввода данных. Следует также иметь в виду, что имя новой автоматически создаваемой секции будет иметь вид SYS_PNNNNN, например, SYS_P28981. При этом при интервальном секционировании не нужно создавать последнюю секцию VALUES LESS THAN (MAXVALUE) . иначе появится ошибка ORA-14761.
Таким образом, в Oracle 11g у команды create создания секционированной таблицы существенно меньшее число строк, а о создании новой секции своевременно позаботится Oracle.
Задачи, решаемые секционированием
Прежде чем приступить к секционированию, надо четко определить задачи, которые предполагается решить
- Первой и наиболее часто решаемой задачей при секционировании является повышение производительности работы SQL-запросов и DML-операций по модификации строк таблицы. Это достигается за счет того, что поиск и модификация строк в таблице идут не по всей таблице, а только в ее части (в одной или нескольких секциях). Кроме того, разбиение таблицы на секции позволяет увеличит скорость обработки таблицы за счет использования параллелизма.
- Вторая задача, которая нашла широкое применение в нашей организации, - это быстрое удаление значительного числа строк в больших таблицах за счет выполнения операции truncate секций. Другим широким применением секционирования является освобождение табличного пространства, занимаемого таблицей, после удаления строк из таблицы командой delete. Использование команд Shrink (сжатие таблицы) или Move (перемещение в табличное пространство) для освобождения табличного пространства в большой несекционированной таблице может занимать значительное время. В секционированных таблицах выполнение таких команд в пределах секции будет выполниться существенно быстрее.
- Третьей задачей секционирования является разбиение большой таблицы на оперативную и архивную части. Особенно это эффективно, если оперативная часть в виде секции интенсивно пополняется и модифицируется, а архивная часть (секции) менее подвержена изменениям, и существенно реже из нее извлекается информация. Строки таблицы из оперативной секции со временем могут быть переведены в архивные секции, при этом архивные секции могут периодически очищаться.
- Четвертой задачей является существенное снижение конкуренции за строки и индексы таблицы, в том числе уменьшения вероятности блокировок. Так в результате секционирования одной из таблиц по HASH-методу полностью была решена задача множественных блокировок, возникающих в таблице.
- Пятой задачей является обеспечение устойчивости функционирования таблиц. Поскольку секция - это поименованный самостоятельный фрагмент памяти на дисках, то при возникновении проблем в одних секциях другие продолжают успешно функционировать. Устойчивости функционирования способствует также хранение секций в различных табличных пространствах и на различных физических носителях. Это особенно важно для таблиц, которые обеспечивают работу множества других таблиц (например. справочники, к которым идет интенсивное обращение). Кроме того, секционирование позволяет осуществлять независимое копирование и резервирование секций, оперативное восстановление секций, а также возможности более быстрой и более частой перестройки индексов наиболее активной секции, не затрагивая индексы пассивных секций.
Секционирование методом Range по диапазону дат
При секционировании этим методом нами используются секционирование по дням, месяцам и по годам. Секционирование этим методом покажем на примере таблицы HISTLG в схеме AIF. Ключом секционирования выступает столбец updated (дата корректировки строки), при этом секции создаются с шагом секций в один месяц. Команда создания секционированной таблицы create имеет вид:
В команде CREATE указаны табличное пространство TABLESPACE HSTDATA, в котором будет находиться таблица, метод секционирования и ключ секционирования PARTITION BY RANGE (UPDATED) , имена секций и максимальное значение диапазона ключевого столбца этой секции. Например, первая секция PARTITION PARTMM_2015_01 VALUES LESS THAN TO_DATE('01.01.20157DD.MM.YYYY') говорит о том, что все значения столбца update меньше 01.01.2015 попадут в первую секцию, а значения update меньше 01.02.2015 попадут во вторую секцию и т.д. В таблице создана последняя секция PARTITION PARTMM_MAX VALUES LESS THAN (MAXVALUE) , позволяющая при превышении значения ключа значения диапазона предпоследней секции размещать строки таблицы в эту последнюю секцию (это подстраховка на случай, если забыли создать новую секцию). Фраза COMPRESS определяет, что первая секция будет сжата.
Следует обратить особое внимание на последнюю фразу ENABLE ROW MOVEMENT , которая позволяет переходить строкам таблицы из секции в секцию. В отсутствии этой фразы Oracle выдаст ошибку. Переход строк по секциям может происходить автоматически при изменении значения ключа (например, столбец updated в результате операции update изменит значение на то. при котором он должен уже принадлежать другой секции) или может происходить специально, например, для перевода строк из оперативной секции в архивную секцию путем изменения значения ключевого столбца. Если не указали эту фразу при создании таблицы, то, чтобы избежать ошибки, следует выполнить команду ALTER TABLE ИМЯ ТАБЛИЦЫ ENABLE ROW MOVEMENT .
Увидеть секции таблицы можно по запросу:
А содержимое секции по запросу:
DBA_OBJECTS
Представление DBA_OBJECTS содержит информацию обо всех объектах базы данных, включая таблицы, индексы, пакеты, процедуры, функции, измерения, материализованные представления, планы ресурсов, типы, последовательности, синонимы, триггеры, представления и разделы таблиц (оно же секционирование). Как несложно догадаться, это представления удобно, когда нужно знать общую информацию относительно любого объекта базы данных. В листинге ниже показан запрос, предназначенный для нахождения времени создания и времени последней модификации объекта (LAST_DDL_TIME). Этот тип запроса поможет идентифицировать время модификации определенного объекта, что часто используется в процессе аудита.
4.4.6 Mapping Boolean and Guid Parameters in Custom INSERT, UPDATE, and DELETE Stored Procedures
When using your custom INSERT, UPDATE, or DELETE stored procedure in Stored Procedure Mapping, the following error might occur:
Error 2042: Parameter Mapping specified is not valid.
This can happen if a Number parameter has been mapped to a Boolean attribute, or if a RAW parameter has been mapped to a Guid attribute.
The solution is to manually add Precision="1" for the Number parameter, and MaxLength="16" for the RAW parameter of your stored procedure in the SSDL.
Существует несколько важных представлений словаря базы данных, которые можно использовать для нахождения детальной информации о любом из объектов базы данных, о которых говорилось в этой главе. Администраторы баз данных также интенсивно используют представления словаря данных, чтобы управлять различными объектами схемы. Здесь приводится краткий список важнейших представлений, часть из которых упоминалась выше. Полные данные о типах информации, которую можно получить от каждого из этих представлений, доступны по команде DESCRIBE (например, DESCRIBE DBA_CATALOG).
В этой статье блога будут описаны некоторые важные представления словаря данных, которые помогут управлять объектами, не хранящими данные (т.е. объектами, которые не относятся к таблицам и индексам). Ниже приведен список важнейших представлений словаря данных для просмотра объектов базы данных.
- DBA_SYNONYMS. Информация о синонимах базы данных.
- DBA_TRIGGERS. Информация о триггерах.
- DBA_SEQUENCES. Информация о созданных пользователем последовательностях.
- DBA_DB_LINKS. Информация о связях базы данных.
Как упоминалось ранее, представление DBA_OBJECTS предоставляет важную информацию обо всех перечисленных объектах, наряду с некоторыми другими типами объектов базы данных. Однако перечисленные представления содержат детальную информацию о каждом объекте, такую как исходный текст триггера, которую вы не получите из представления DBA_OBJECTS.
Управление такими объектами, как таблицы и представления, осуществляется ссылкой на представления словаря данных, наподобие DBA_TABLES и DBA_VIEWS. Существуют также отдельные представления для секционированных таблиц. Давайте рассмотрим ключевые представления словаря данных, относящиеся к таблицам и индексам.
Секционирование методом Range по диапазону ключа
В практике секционирования по методу Range используем два вида секционирования: по диапазону дат и по диапазону значений.
Defining Constraints at the Column Level
Constraint enforced at the column level:
The following naming convention is commonly used by many database developers :

Хеш-секционирование HASH
Как правило, если не получается секционировать по диапазону RANGE или LIST , то применяется хешсекционирование, основанное на хеш-функции. В этом случае строки таблицы равномерно распределяются между секциями на основании внутренних алгоритмов хеширования Oracle. При этом чем уникальнее значения столбца в таблице, по которому идет секционирование, тем лучше будет распределение данных по разделам. Первичный ключ или уникальный столбец (столбцы) является самым хорошим хеш- ключом. Oracle рекомендует число секций N как степень 2, т.е. N=2,4,8,16,32 и т.д. При этом добавление или удаление какой-то хеш-секции вызывает перезапись всех данных в другие секции. Рассмотрим HASH секционирование на примере индексноорганизованной таблицы LISTIN. Целью HASH секционирования таблицы было добиться существенного снижение числа блокировок, возникающих в этой таблице. Эта цель была успешно реализована за счет секционирования таблицы по 16 секциям (фраза PARTITIONS 16 ), где ключом секционирования выступал столбец TASKISN. Команда создания таблицы имеет вид:
Следует заметить, что если в качестве ключа секционирования используется столбец, в котором имеем очень неравномерное распределение значения столбца (малая уникальность), то применение хеш-секционирования не целесообразно. При этом число секций не имеет особого значения, поскольку все значения ключевого столбца «свалятся» в одну-две секции.
Замечание. Увидеть размер секций в mb по всем указанным выше методам можно по запросу:
DBA_IND_COLUMNS
Представления DBA_IND_COLUMNS по структуре подобно представлению DBA_CONS_COLUMNS и содержит информацию обо всех проиндексированных столбцах каждой таблицы. Эта информация важна при настройке производительности, когда вы замечаете,что запрос использует индекс, но вы не знаете точно, на каких столбцах этот индекс определен. Запрос, приведенный в листинге ниже, показывает, что таблица имеет индексы, определенные на неверных столбцах.
Совет. Взглянув на столбец INDEX_NAME, можно легко идентифицировать составные ключи. Если одно и то же вхождение INDEX_NAME появляется больше одного раза, значит, это составной ключ; и столбцы, являющиеся его частью, показаны в столбце COLUMN_NAME. Например,INVENTORY_PK — первичный ключ таблицы INVENTORIES, определенный на двух столбцах:PRODUCT_ID и WAREHOUSE_ID. Порядок столбцов в определении составного ключа можно узнать с помощью столбца COLUMN_POSITION.
Ключ секционирования
Следующим важным шагом в создании секционированной таблицы является определение ключа секционирования. В качестве ключа секционирования может выступить столбец или несколько столбцов, относительно значений которых будет делаться разнесение таблицы на секции. К потенциальным столбцам для создания ключа секционирования относятся столбцы типа date (например, столбец created - дата создания строки или updated - дата изменения строки) для секционирования по методам Range и List . Столбцы типа number с высокой степенью уникальности значений хорошо подходят для секционирования по методам Range и Hash . Столбцы, имеющие список фиксированных значений, подходят для секционирования по списку List .
В Oracle 11g появилась возможность в качестве ключа секционирования использовать виртуальный столбец (virtual column), построенный на функции к реальному столбцу таблицы. Виртуальный столбец в действительности не хранится в таблице, а каждый раз вычисляется при обращении к нему во время ввода данных в таблицу. Для создания виртуального столбца используется фраза generated always as. после которой идет функция, выполняемая над реальным столбцом таблицы, а далее идет обязательная фраза virtual. Например, PARTID generated always AS (to_char(UPDATED,'MM')) virtual . Возможен вариант создания виртуального столбца более короткой фразой PARTID AS (to_char(UPDATED,'MM')) .
Увидеть, какой столбец в таблице виртуальный позволяет запрос:
Замечание. При вводе данных в таблицу с виртуальным столбцом следует указать в insert и values перечень столбцов, иначе будет ошибка ORA-00947: not enough value .
DBA_PART_TABLES
Представление DBA_PART_TABLES содержит информацию о типе схемы раздела и прочих параметрах хранения разделов и подразделов. Узнать тип каждого раздела каждой секционированной таблицы можно с помощью следующего запроса:
Metadata-Only DEFAULT Values
Prior to Oracle 11g, adding a new column to an existing table required all rows in that table to be modified to add the new column.
Oracle 11g introduced the concept of metadata-only default values. Adding a NOT NULL column with a DEFAULT clause to an existing table involved just a metadata change, rather than a change to all the rows in the table. Queries of the new column were rewritten by the optimizer to make sure the result was consistent with the default definition.
Oracle 12c takes this a step further, allowing metadata-only default values of both mandatory and optional columns. As a result, adding a new column with a DEFAULT clause to an existing table will be handled as a metadata-only change, regardless of whether that column is defined as NOT NULL or not. This represents both a space saving and performance improvement.
There are some fairly obvious restrictions on this functionality, but it's worth checking the ALTER TABLE : DEFAULT section of the manual to make sure you are not hitting one.
DBA_MVIEWS
Представление словаря DBA_MVIEWS сообщает все о материализованных представлениях в базе данных, в том числе информацию, включено ли для них средство переписывания запросов. В листинге ниже демонстрируется использования этого представления.
Primary Key (PK)
In Oracle, the Primary Key constraint is a column (or a set of columns) that uniquely identifies each row in the table, this constraint enforces uniqueness and ensures that no column that is part of the Primary Key can hold a NULL value. Only one Primary Key can be created for each table.
The syntax used for defining a Primary Key Constraint is as follows:
Please note – the square brackets in this demonstration (and in those that follow) indicate that what enclosed within them is optional, the square brackets are not part of the CREATE TABLE statement.
4.4.1 Entity Framework 5 and Earlier Mapping and Customization
Example 4-1, Example 4-2, and Example 4-3 customizes the mappings as follows:
Number(2,0) to Number(3,0)
Number(6,0) to Number(9,0)
Number(11,0) to Number(18,0)
When using Model First, a Byte attribute is mapped to Number(3,0) by default. However, when a model is generated for a Number(3,0) column, it gets mapped to Int16 by default unless custom mapping for Byte is specified.
DBA_INDEXES
Представление словаря DBA_INDEXES служит для того, чтобы узнать все необходимое об индексах в базе данных, включая имя индекса, его тип, таблицу и табличное пространство, к которому он относится. Определенные столбцы, наподобие BLEVEL (сообщает уровень B-дерева индекса) и DISTINCT_KEYS (количество разных значений ключа индекс), наполняются, только если собрана статистика по индексу с использованием пакета DBMS_STATS.
Creating Oracle Constraints
Constraints enforce rules on the data in a table whenever a row is inserted, deleted, or updated. Constraints can be defined at the column or table level.
Секционирование по списку ключей LIST
Секционирование по списку применяется, если есть возможность указать конкретный перечень дискретных значений столбца, по которому происходит разбиение на секции. При секционировании по LIST в команде create указываются метод секционирования LIST (PARTITION BY LIST) , ключ секционирования и имена секций, в которых указывается одно или несколько дискретных значений.
В качестве примера проведем секционирование таблицы AIF.AGREEM. используя в качестве ключа виртуальный столбец partid. При каждом вводе строки в таблицу в виртуальном столбце формируется числовой номер месяца по функции to_number(to_char(updated,'MM')) . Таблицу разбиваем на 12 секций, кроме того, используем подход секционирования по циклу, когда в следующем году строки января вводятся в ту же секцию января, а перед этим секция за январь чистится от старых данных по delete или по truncate. Команда создания секции примет вид:
Вместо виртуального столбца может быть введен реальный столбец partid (тип number) , заполняемый при вводе строки в таблицу. Указанный выше вариант эффективно использовался в таблицах как с 366 секциями, так и с 12 с очисткой последних по truncate, поскольку информация в таблицах хранится меньше года. Достоинство этого подхода в том, что создавать новые секции не приходится, а табличное пространство старых секций ежемесячно быстро освобождается по truncate .
Замечание. Если необходимо очистить табличное пространство секции, то используются либо команды сжатия SHRINK , либо MOVE (перемещения в табличное пространство):
Другие стандартные варианты секционирования по методу LIST изложены в различных источниках.
Not Null (NN)
In Oracle, the Not Null constraint ensures that the column contains no NULL values. The syntax used for defining a Not Null constraint is as follows:
This constraint can only be defined at the column level
DBA_EXTERNAL_TABLES
Представление DBA_EXTERNAL_TABLES показывает подробности о любой внешней таблице в базе данных, включая их тип доступа, параметры доступа и информацию о каталоге.
DBA_TABLES
Представление DBA_TABLES содержит информацию обо всех реляционных таблицах базы данных. Представление DBA_TABLES — основной справочник для нахождения информации о хранении, количестве строк в таблице, состоянии протоколирования, информации буферного пула и многих других деталях. Ниже приведен простой пример запроса представления DBA_TABLES:
На заметку! Представление DBA_ALL_TABLES содержит информацию обо всех объектных и реляционных таблицах в базе данных, в то время как представление DBA_TABLES ограничено только реляционными таблицами.
Представление DBA_TABLES служит для нахождения таких вещей, как включено ли сжатие и отслеживание зависимостей на уровне строки, и была ли таблица уничтожена и помещена в корзину (Recycle Bin).
Секционирование методом RANG по диапазону значений
Секционирование по диапазону значений похоже на секционирование по диапазону дат, только вместо ключа по дате используется ключ по столбцу, принимающему числовое значение (желательно имеющее равномерное распределение по всему диапазону значений). Для этого хорошо подходит столбец с уникальным значением. Рассмотрим на примере той же таблицы AIF.HISTLG, секционированной выше по диапазону дат. В качестве ключа секционирования используется столбец ISN с уникальными значениями. Команда создания таблицы имеет вид:
где PARTITION BY RANGE (ISN) говорит о секционировании no RANGE при ключе секционирования ISN, интервал создания секции через 1000 значений.
DEFAULT Values On Explicit NULLs
In the previous section we saw default values are only used when a column is not referenced in an insert statement. If the column is referenced, even when supplying the value NULL, the default value is not used. Oracle 12c allows you to modify this behaviour using the ON NULL clause in the default definition.
The following example compares the default action of the DEFAULT clause, with that of DEFAULT ON NULL . The example uses sequences to populate two columns, one using the standard DEFAULT clause, the other using the DEFAULT ON NULL clause.
Notice the difference in the way the explicit NULL is handled.
Методы секционирования таблиц
Секционирование повышает эффективность работы с таблицами и индексами
Выбранный ключ секционирования, как правило, определяет методы секционирования. В настоящее время имеются следующие методы секционирования таблиц:
- Range -секционирование по диапазону ключа,
- List - секционирование по списку ключа.
- Hash - хеш-секционирование,
- составное секционирование.
- интервальное секционирование.
- ссылочное секционирование,
- системное секционирование
Последние три появились в Oracle 11g. вместе с тем последние два у нас пока не нашли большого применения.
Составное секционирование
При составном секционировании внутри секции создаются подсекции Однако в версиях до Oracle 11g смешанное секционирование разрешалось только по RANGE методу для секции и методам HASH или LIST для подсекции. В Oracle 11g варианты методов секций-подсекций были существенно расширены, и в настоящее время можно осуществлять составное секционирование в следующих комбинациях: Range-Range, Range-Hash , Range-List, List-Range, List-Hash или Ust-List. Надо отметить, что при составном секционировании данные физически хранятся в подсекциях, а секции высту-пают только в роли логических контейнеров.
Рассмотрим смешанное секционирование на примере таблицы платежей AIF.PAY_ORD_RECORD с делением таблицы на секции по методу RANGE , а на подсекции по методу LIST . Ключом секционирования по секциям выступает столбец PAY_DATA (тип date), а ключом секционирования подсекции выступает столбец STATUS (тип number), принимающий три значения: 0. 1,2. Команда создания секционированной таблицы в Oracle 11g с секционированием по месяцам примет вид:
где разбиение по секциям задает фраза PARTITION BY RANGE (PAY_DATA) , а по подсекциям фраза SUBPARTITION BY LIST (STATUS) . Далее идет список подсекций со своими значениями: STATUS_0 VALUES (0) . STATUSJ VALUES (1) . STATUSJ? VALUES (2) . Для каждой подсекции может быть задано свое табличное пространства, которое может отличаться от табличного пространства таблицы HSTDATA. С гомощью предложения SUBPARTITION TEMPLATE один и тот же набор подсекций будет автоматически использоваться во всех секциях. Однако создание подсекций можно сделать вручную, указав все подсекции для каждого секции. Просмотреть созданные подсекции по имени таблицы можно по запросу:
UNIQUE (UQ)
In Oracle, the Unique constraint requires that every value in a column (or set of columns) be unique. The syntax used for defining a UNIQUE Constraint is as follows:
4.4.3 Data Type Mapping and Customization Process
If the EDM was created already before providing the mapping information, then you can modify the mappings either through the Visual Studio tools or manually. Using Visual Studio, go to the EDM Model Browser page. Right-click on the table(s) requiring new data type mapping and select Table Mapping from the pop-up menu. The Mapping Details window will appear usually at the bottom of your screen. Update Column Mappings as desired.
Example Mapping Before CSDL Customization:
Example Mapping After CSDL Customization:
You can employ combinations of these customization possibilities depending on your planned mapping changes. If many tables and many columns require mapping changes, it is most efficient to delete the EDMX file and regenerate the data model. If a few tables and many columns require changes, then delete the affected tables, save the EDMX file, and select Update Model from Database. to include those tables again. If only a single table and one or two columns require changes, then modify the EDMX either manually or by using the Mapping Details window.
When using the EDM wizard to create a complex type from a function import, any custom EDM type mappings specified will not be applied automatically. The EDM wizard uses the default type mappings. Developers must then manually edit the resulting complex type. Developers begin this process after the complex type is generated. Any type declaration (field, property, constructor parameter, etc.) in the complex object which has an undesired type mapping, such as Decimal rather than Boolean, should be manually edited to the desired type.
4.4.5 Resolving Compilation Errors When Using Custom Mapping
Under certain scenarios, custom mapping may cause compilation errors when a project that uses custom mapping is loaded by Visual Studio. One specific scenario is when Visual Studio opens a project with an existing custom mapping that now generates errors when those errors did not exist before. You may use the following workaround for such scenarios:
Open Visual Studio Help, About Microsoft Visual Studio. Click OK to exit the dialog box.
Alternatively, open the to-be-used connection in Server Explorer.
Compile the project again to eliminate the compilation errors.
Data Types
| Column Type | Description | Example |
| varchar2 (size) | String column. The value within the brackets indicates the maximum size of each field in the column (in characters) | varchar2(3) → ‘ABC’ |
DEFAULT Values Using Sequences
In Oracle 12c, it is now possible to specify the CURRVAL and NEXTVAL sequence pseudocolumns as the default values for a column. You should also consider using Identity columns for this purpose.
In the following example you can see the effect of specifying a sequence as the default value for a column. The default value is only used when the column is not referenced by the insert. This behaviour can be modified using the ON NULL clause described in the next section.
The fact we can use both the NEXTVAL and CURRVAL pseudocolumns gives us the ability to auto-populate master-detail relationships, as shown below.
Of course, this would only make sense if you could guarantee the inserts into the detail table would always immediately follow the insert into the master table, which would prevent you from using bulk-bind operations.
A few things to remember about using sequence pseudocolumns as defaults include:
- During table creation, the sequence must exist and you must have select privilege on it for it to be used as a column default.
- The users performing inserts against the table must have select privilege on the sequence, as well as insert privilege on the table.
- If the sequence is dropped after table creation, subsequent inserts will error.
- Sequences used as default values are always stored in the data dictionary with fully qualified names. Normal name resolution rules are used to determine the sequence owner, including expansion of private and public synonyms.
- As with any use of a sequence, gaps in the sequence of numbers can occur for a number of reasons. For example, if a sequence number is requested and not used, a statement including a sequence is rolled back, or the databases is turned off and cached sequence values are lost.
4.4.2 Entity Framework 6 Mapping and Customization
DBType is the Oracle Database data type
4.4.2.1 New Default Mappings
Системное секционирование (system partitioning)
Появилось в Oracle 11 g и применяется, как правило, для таблиц, которые не могут быть секционированы никакими другими методами. В этом методе Oracle сам управляет, какую строку таблицы в какую секцию помещать. Для этого метода необходимо просто написать название секций, например, секции Р1, Р2, РЗ:
Увидеть разбиение таблицы на секции можно по запросу:
Увидеть метод секционирования, что он именно SYSTEM , можно по запросу:
Следует заметить, что для правильного ввода данных в таблицу надо, помимо имени таблицы, указать еще имя сегмента, иначе будет ошибка ORA-14701 . Тоже для ускоренной выборки данных по запросу следует указать имя сегмента.
Замечание. В таблице подвергнуться секционированию может не только сама таблица, но и индексы таблицы. В силу объемности и важности материала о секционировании индексов пойдет речь во второй части. Там же будет рассказано об особенностях перехода от несекционированных больших по объему таблиц к секционированным таблицам, в том числе о возникающих в этих случаях особенностях поведения индексов, триггеров, синонимов и т.д. этих таблиц.
This SQL tutorial explains how to use the CREATE TABLE statement in Oracle. This tutorial is the first part of two posts describing DDL (Data Definition Language) statements in Oracle.
The DDL statements are a subset of SQL statements used to create, modify, or remove database structures. In this post you will learn how to create and delete tables.
This tutorial allows you to become familiar with the following topics:
The next post will describe how to use the Oracle ALTER TABLE statement.
DBA_TAB_COLUMNS
Предположим, вы нужно узнать среднюю длину каждой строки таблицы или значение по умолчанию каждого столбца (если таковое есть). Представление DBA_TAB_COLUMNS — отличный способ быстро получить всю детальную информацию о столбцах таблиц схемы, как показано в листинге ниже.
CHECK (CK)
In Oracle, the Check constraint defines a condition that each row must satisfy. The syntax used for defining a Check Constraint is as follows:
- The condition written in the CHECK is quite similar in its structure to each of the conditions written in a WHERE sentence.
- The condition in the CHECK part must not include:
- Values that are returned as a result of using SEQUENCES
- Functions such as SYSDATE, ROWNUM
- Subqueries
4.4.4 StoreGeneratedPattern Enumeration
The following sections describe the Identity attribute and the Virtual column.
4.4.4.1 Identity Attribute
For Oracle Database 11 g Release 2 (11.2) and earlier versions that do not support Identity columns, application developers can manually set StoreGeneratedPattern to Identity in columns through the entity model designer Properties after model generation, then create an INSERT trigger. Depending on the data type, a sequence may not be necessary if a server function, such as sys_guid() , can generate the value for the column.
4.4.4.2 Virtual Column
DBA_VIEWS
Как известно, представления — это результаты запросов к некоторым таблицам базы данных. Представление словаря данных DBA_VIEWS позволяет увидеть SQL-запросы, лежащие в основе представлений. В листинге ниже показано, как получить текст представления OS_CUSTOMERS, принадлежащего пользователю oe.
Совет. Чтобы обеспечить полное отображение текста при использовании представления DBA_VIEWS, установите большое значение переменной long (например, SET LONG 2000). В противном случае вы увидите лишь несколько первых строк определения представления.
Oracle CREATE TABLE Statement
Oracle CREATE TABLE statement is used to create new tables in the database.
![sql_create_table]()
Oracle Default Value
A column can be given a default value using the DEFAULT keyword. The DEFAULT keyword provides a default value to a column when the Oracle INSERT INTO statement does not provide a specific value. The default value can be literal value, an expression, or a SQL Function, such as SYSDATE.
To define a Default value, use this syntax:
DBA_TAB_MODIFICATIONS
Представление DBA_TAB_MODIFICATIONS показывает все изменения DML в таблице,произошедшие с момента последнего сбора статистики по этой таблице. Вот запрос к этому представлению:
База данных не обновляет представление DBA_TAB_MODIFICATIONS в реальном времени. Следовательно, вы можете и не увидеть изменений в различных таблицах, немедленно отраженных в этом представлении.
Читайте также:
