
Correctable ecc logging limit reached assert ошибка в vmware
In some cases, the system reports excessive correctable single bit errors. This might cause the system to reach the limited PFA threshold. User will see the following message in the System Event Log (SEL) in Intelligent Platform Management Interface (IPMI): 04/09/2015 02:30:01 Memory device (replaceable memory devices, e.g. DIMM/SIMM) (Memory - DIMM 24): Assertion: Correctable ECC / other correctable memory error logging limit reached. (where PFA = Predictive Failure Analysis)
Solution
Choose one of the following two (2) methods to resolve the errors:
Dell Server Eating Power Supplies
I have a Dell PowerEdge 750 that's been quietly running our old accounting software to network users for at least 15 years. The server began powering off intermittently, so I picked up a refurbished power supply as a replacement. It ran for 3 days and fai.
Additional Information
The new Intel Memory Reference Code (MRC) provides better margin on handling the memory corruption. It helps the additional memory setup margin that reduces the higher frequencies of the memory correctable bit error. The new Intel MRC is incorporated in the UEFI firmware. The system updates with UEFI will improve the storm of the memory correctable error. Before the fix was available, it was strongly recommended to follow the memory problem determination in the installation guide.

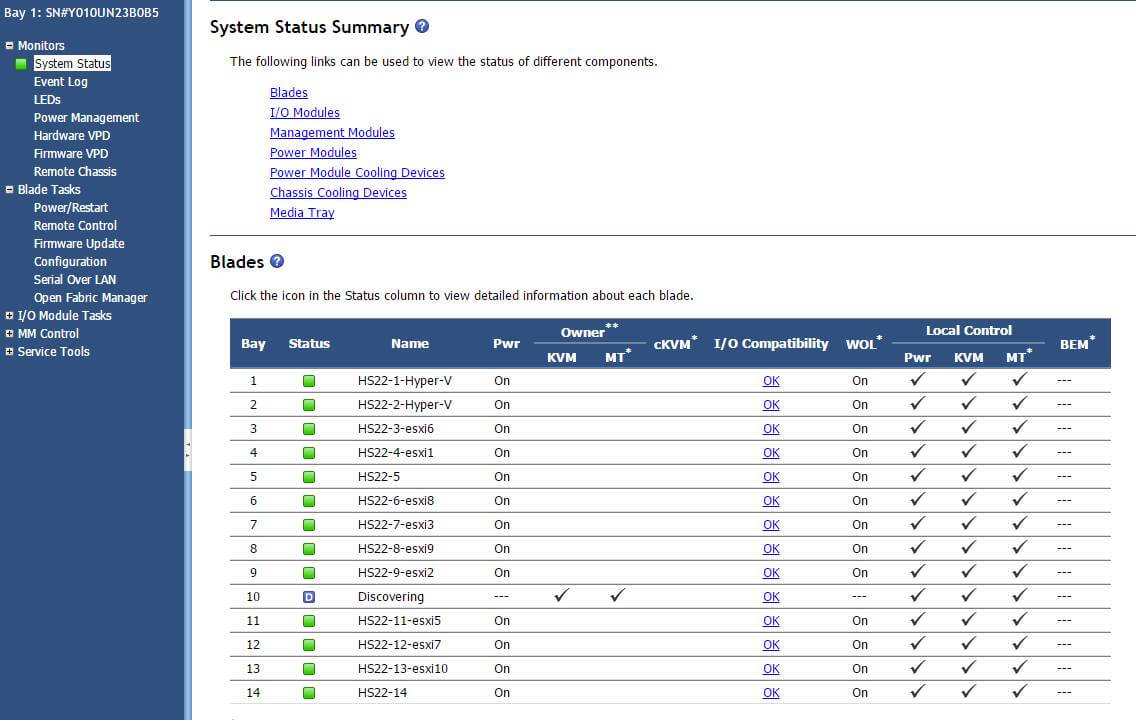
Всем привет сегодня на IBM Blade HS22 вылезла ошибка Correctable ECC memory error logging limit reached. Я расскажу как ее решить. Появляется данная проблема в журналах AMM, кто не в курсе AMM это вебинтерфейс управления корзиной с блейд серверами IBM.
Вот как выглядит данная ошибка в AMM.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-1
Ошибка Correctable ECC memory error logging limit reached, возникает с проблемой в оперативной памяти, сам IBM в первую очередь советует прошить все по максимуму, и если не поможет вытащить блейд и пере ткнуть DDR память.
и в логах эта ошибка тоже присутствует и имеет код 0x806f050c.

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-2
Я пошел первым путем решил все обновить. Ранее я вам рассказывал Как обновить все прошивки на IBM Blade HS22
После обновления видим в логах что ошибка в состоянии recovery

Ошибка Correctable ECC memory error logging limit reached на IBM HS22-11
и когда будет произведена перезагрузка после обновления вы увидите, что ошибка благополучно исчезла и все зеленое.
Как обновить все прошивки на IBM Blade HS22-10
Вот так вот просто решается Ошибка Correctable ECC memory error logging limit reached на IBM HS22.
On one of our computing nodes I am getting ECC CE (correctable errors). What is a little bit peculiar about is is that errors are not massive, just a single occurrence exactly every 5 minutes.
syslog example entry:
Another thing than baffles me is that cat /sys/devices/system/edac/mc/mc*/csrow*/ce_count shows 4x 0 . dmidecode -t memory | grep Size reports there are 8x 2GB dice installed. But cat /sys/devices/system/edac/mc/mc*/csrow*/size_mb shows 4x 4096 . I am guessing that the memory chips are single ranked, and pairs of dice got coupled. Is this thinking right? Still it does not explain why error count is 0 .
This is going on for about 2-3 days already. Every error so far was reported as corrected, but this is pretty annoying and probably not safe.
Is the RAM die dying and I am lucky that it's just some system process happened to be placed in there (as opposed to computation)? I don't think I have anything running every 5 minutes, but maybe some logging tools are.
Or the reason can be something else?
Snap! Cybersecurity & the boardroom, Cooper, Starlink sat internet, & Sgr A*
Your daily dose of tech news, in brief. Not only is it Friday, but it is also Friday the 13th! A day that has inspired a late 19th-century secret society, an early 20th-century novel, a horror film franchise, and triskaidekaphobia, a word I had to.
Spark! Pro Series - May 13th, 2022
To my fellow left-handers, Happy Friday the 13th. While the right-handed majority quakes in fear and wallows in superstition, a malady known as friggatriskaidekaphobia, we celebrate the day that promises health, wea.
The Error Light Emitting Diode (LED) is illuminated on the chassis and the BladeCenter HS22 blade server front information panel. The Advanced Management Module (AMM) system status indicates that there is a "correctable ECC memory error logging limit reached" error. The AMM logs the following errors: 19 E Blade_05 12/08/09, 11:29:06 (octans012) Correctable memory error logging limit reached 20 E Blade_05 12/08/09, 11:29:05 (octans012) Correctable memory error logging limitreached on DIMM 5 The memory errors occur in the following BladeCenter HS22 configuration: - CPU-C states [Enable] - Thermal Mode [Normal] double refresh rate - 4 Gigabyte (GB) Samsung VLP DIMMs installed, Option part number 44T1488, replacement part number (FRU) 44T1498.
Affected Configurations
The system may be any of the following Lenovo x86 servers:
- Lenovo Flex System x240 M5 Compute Node, type 9532, any model, any AC1
- Lenovo NeXtScale nx360 M5, type 5465, any model
- Lenovo NeXtScale nx360 M5, type 5467, any model
- Lenovo System x3500 M5, type 5464, any model
- Lenovo System x3550 M5, type 5463, any model
- Lenovo System x3650 M5, type 5462, any model This tip is not software specific.
This tip is not option specific.
The following system BIOS or UEFI level(s) are affected:Â Â Â
Resolving The Problem
Solution
This behavior was corrected in the following UEFI firmware releases:
- nx360M5 - the108j-1.20
- x3650M5 - tce106k-1.10
- x3550M5 - tbe106k-1.10
- x3500M5 - tae106j-1.11
- x240M5Â - c4e106j-1.10
The file is available by selecting the appropriate Product Group, type of System, Product name, Product machine type, and Operating system on IBM Support's Fix Central web page, at the following URL:Â Â Â Â
Method 2:
Disable CPU C-State
- Boot the blade into the F1 "System Configuration and Boot Management" screen. Highlight System Settings, press Enter, and select Processors. Select CPU C-States, and then change the setting to "Disable."
- Press the Esc key twice to get to "System Configuration and Boot Management" and then select Save Settings and Exit Setup.
- Follow the instructions on the next screen to exit the "Setup Utility.
- Power the blade off for the changes to take effect and restart.
If the LED stays on after the changes have been made, do one of the following to turn it off:
- Using the IPMItool application (which is a third party application available for Windows and Linux):
- impitool sel list (to verify the log contains messages)
- ipmitool sel clear
- ipmitool sel list (to verify the log is now empty)
- Restart the IMM. This can be done via the AMM GUI interface (select Blade Tasks, Power/Restart, and Restart Blade System Mgmt Processor for the appropriate blade) or with the ASU command line tool (asu rebootimm).
Source
RETAIN tip: H196525
7 Replies
![Gary D Williams]()
![This person is a Verified Professional]()
Gary D Williams
On Dell servers this is often related to a firmware bug, not sure about HP but the first thing I'd do is a full firmware upgrade followed by replacing that bad stick of RAM if the errors kept coming.
![tlong_vna]()
![This person is a Verified Professional]()
tlong_vna
![Dan 'Glomgore' Atchley]()
![This person is a Verified Professional]()
Dan 'Glomgore' Atchley
Trying to find the alert for this from HPE, but basically as stated above you need to update your BIOS and iLO firmware.
thanks guys, I just updated ilo firmware sadly the error still occurs, the bad ram was already switched, and the ilo log doesn't show any errors at all.
if the firmware on the ILO and the system are up to date, check the IML logs for which stick is reporting the errors. swap that memory to another slot that is not recording errors. if it follows the memory module then it is the memory (and bad memory comes out of the box that way more often than you would think) also verify that it is true HP memory. if it follows the slot then it is most likely the system board. verify the memory is the correct memory for the server (you can download the quick specs for the server from the HPE website under retired equipment. just search HP dl380 g7 quickspecs. if that does not help you can get the insight online diagnostics tool from the download area. where i have seen this issue on other brands of servers, HP has always done a very good job of qualifying their hardware and have never seen this error without it being a bad memory slot, third-party memory or a failed/ incorrect memory module.
Thanks for the reply david.
As mentioned above there is not a single entry in the iml logs, system health is ok since the RAM switch. If the RAM is still faulty it is not shown.
It just seems to be the problem that some kind of log is full and I can't seem to find it. - ECC logging limit reached
![Gary D Williams]()
![This person is a Verified Professional]()
Gary D Williams
This topic has been locked by an administrator and is no longer open for commenting.
To continue this discussion, please ask a new question.
Method 1:
Change Thermal Mode setting (preferred method)
- Boot the blade into the F1 "System Configuration and Boot Management" screen. Highlight "System Settings." Press Enter and select Memory. Select Thermal Mode and change the setting to "Performance."
- Press the Esc key twice to get to "System Configuration and Boot Management" and then select Save Settings and Exit Setup.
- Follow the instructions on the next screen to exit the "Setup Utility."
- Power the blade off for the changes to take effect and restart.
Changing "Normal" mode to "Performance" mode affects the way that the Dual In-Line Memory Modules (DIMMs) are refreshed. This results in a DIMM temperature warning message occurring at a 10 degree lower temperature. This causes no impact in most industry standard data centers.
Symptom
In some cases, the system reports excessive correctable single bit errors. This might cause the system to reach the limited PFA threshold. User will see the following message in the System Event Log (SEL) in Intelligent Platform Management Interface (IPMI):
04/09/2015 02:30:01 Memory device (replaceable memory devices, e.g. DIMM/SIMM) (Memory - DIMM 24): Assertion: Correctable ECC / other correctable memory error logging limit reached.
(where PFA = Predictive Failure Analysis)
Source
RETAIN Tip: H214565
Symptom
The Error Light Emitting Diode (LED) is illuminated on the chassis and the BladeCenter HS22 blade server front information panel. The Advanced Management Module (AMM) system status indicates that there is a "correctable ECC memory error logging limit reached" error. The AMM logs the following errors:
19 E Blade_05 12/08/09, 11:29:06 (octans012)
Correctable memory error logging limit reached20 E Blade_05 12/08/09, 11:29:05 (octans012)
Correctable memory error logging limit reached on DIMM 5The memory errors occur in the following BladeCenter HS22 configuration:
- CPU-C states [Enable]
- Thermal Mode [Normal] double refresh rate
- 4 Gigabyte (GB) Samsung VLP DIMMs installed, Option part number 44T1488, replacement part number (FRU) 44T1498.
Affected configurations
The system may be any of the following IBM servers:
- BladeCenter HS22, Type 1936, any model
- BladeCenter HS22, Type 7870, any model
This tip is not software specific.
This tip is not option specific.The system has the symptom described above.
The SOC Briefing for May 13th - We are back!
Good morning and welcome to today's briefing. I am starting this back, usually will try to post mostly Fridays on this as much as I can. As usually this post bring various posts regarding Patches & Updates plus Security News and a bonus Security Tip! Hope.
Additional information
This error message usually indicates a failing DIMM, however, a very rare condition has been identified with Samsung DIMMs that can cause a false error. By implementing either of the recommended Workaround s above, the false "correctable ECC memory logging limit reached" error should not occur.
Note: The false "correctable ECC memory error logging limit reached" error does not indicate defective DIMMs.
2 Answers 2
A similar problem happened when I installed new DIMMs in my PowerEdge R815. I thought one of the DIMMs was bad, but didn't know which of the 32 DIMMs it might be. It turned out that the hardware's LCD panel (and the hardware log) reported the failure, and provided the DIMM slot id. When I reseated the DIMM, the error went away -- so it wasn't an error that could be corrected by ECC after all.
Maybe it was just the reboot. In my case after rebooting the error went away, but it is not the 1st time I got corrected errors on this machine. My guess is that after reboot, the faulty chip hasn't been used yet.
It is important to map the csrow and channel to physical slot/DIMM and replace ASAP. In my experience you will start to get more and more errors but it all depends on how fast the chip goes totally bad, I have seen it progress from a few errors a day to dead the next day or it could make it for several months or more (all depending on your workload). Eventually it will be to the point that your console is filled with them and eventually it leads to a UE (Uncorrectable Error) and your server will crash and DIMM will be unusable.
One other important thing is that if your BIOS (and most server BIOS's will do this) detects multiple bit failures it may disable that DIMM slot. Do not wipe/erase or reset the enabled DIMMs in the BIOS otherwise your server will probably not boot at all (as in no POST) and unless you recall which DIMM was marked bad you will have to remove chip after chip until it boots to figure out which one was bad (big pain in a corporate or datacenter setting). Also if replacing a DIMM that has been marked bad you will probably have to re-enable it or wipe the record of the bad DIMM from your BIOS for it to be recognized.
I have the following error in my vphere hardware status:
Memory Correctable ECC logging limit reached
I read a lot of articles about this topic but non of the suggested solutions were helpful for me.
I switched the RAM, rebooted the Server around three times, reset the IML Log, reset the sensors.
The error still occurs, the server itself doesn't show any hardware issues. IT's a ProLiant DL380 G7.
I couldn't find any thread that told me how to reset the ECC Logs. The error started month ago (around april 2017).
I hope anyone has a solution for this.
Thanks in advance.
Contest ends 2022-05-15 Contests Complete a survey about your desktop and or gaming PC(s) Contest Details View all contests
Resolving The Problem
IE11 retires in 1 month on June 15, 2022
Received this reminder email from MS this morning. I won't be sad to finally see this go, even though I know I have a few hold outs who insist on clicking on that E still (mostly out of habit)Is everyone Ready for the big day?-----------------------------.
Читайте также:



