
Что такое заголовочные файлы ядра
Я знаю, что если я хочу скомпилировать свое собственное ядро Linux, мне нужны заголовки ядра Linux, но для чего они хороши?
Я узнал, что в /usr/src/ , похоже, есть десятки файлов заголовков C. Но какова их цель, они напрямую не включены в источники ядра?
Установка заголовочных файлов ядра в Debian, Ubuntu или Linux Mint
Если вы не компилировали ядро вручную, то можете установить соответствующие заголовочные файлы ядра с помощью команды apt-get.
Сначала проверьте, не установлены ли уже требуемые заголовочные файлы с помощью команды:
Теперь установите заголовочные файлы, как показано ниже.
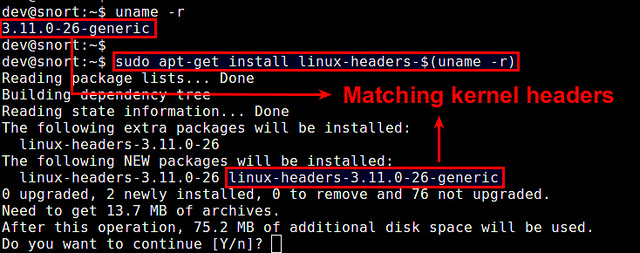
Проверьте, что установка прошла успешно.
По умолчанию в Debian, Ubuntu или Linux Mint заголовочные файлы находятся в /usr/src.
3 ответа
Файлы заголовков определяют интерфейс: они определяют способ определения функций в исходном файле.
Они используются таким образом, чтобы компилятор мог проверить правильность использования функции в качестве сигнатуры функции (возвращаемое значение и параметры) в файле заголовка. Для этой задачи фактическая реализация функции не требуется.
Вы можете сделать то же самое со всеми исходными файлами ядра, но вы установите много ненужных файлов.
Пример: если я хочу использовать функцию
в программе мне не нужно знать, как реализована реализация foo , мне просто нужно знать, что она принимает один param ( double ) и возвращает целое число.
Как указано, файлы заголовков определяют интерфейсы для функций, а также структуры, используемые программами.
В случае файлов заголовков ядра эти функции и структуры находятся внутри самого ядра.
Если вы создаете полное ядро, то, очевидно, вам нужны полные исходные файлы, а не только заголовки. Однако, если вы компилируете драйвер устройства или другой загружаемый модуль, который подключается к ядру, вам нужны только файлы заголовков, поэтому вы можете сэкономить место, не устанавливая полные источники.
Разделение пакетов так, что вы можете установить только файлы заголовков, частично исторически, поскольку разница в использовании диска была существенной, когда диски были меньше. В наши дни весь источник на диске (без необходимости) не будет основным соображением на диске.
Термированные заголовочные файлы происходят из языка программирования C , используемого при написании ядра Linux.
Чтобы объяснить это с очень высокого уровня .
В C перед использованием необходимо иметь декларацию вперед функции. Другими словами, описание функции, ее параметров и возвращаемых данных. Общепринятой практикой является включение всех форвардных деклараций в один файл с заголовком . Файлы исходного кода для других программ могут затем include этот заголовок и иметь доступ ко всем функциям исполняемого исполняемого файла программы после его компиляции .
Файлы заголовков Linux являются файлами .h , которые содержат функции, которые предоставляет ядро Linux, которые могут быть вызваны из других программ .
Заключение
Надеюсь, вам понравились наши шалости в пространстве ядра. Хотя показанные примеры примитивны, эти структуры можно использовать для создания собственных модулей, выполняющих очень сложные задачи.
Просто помните, что в пространстве ядра всё под вашу ответственность. Там для вашего кода нет поддержки или второго шанса. Если делаете проект для клиента, заранее запланируйте двойное, если не тройное время на отладку. Код ядра должен быть идеален, насколько это возможно, чтобы гарантировать цельность и надёжность систем, на которых он запускается.

Ядро — это та часть операционной системы, работа которой полностью скрыта от пользователя, т. к. пользователь с ним не работает напрямую: пользователь работает с программами. Но, тем не менее, без ядра невозможна работа ни одной программы, т.е. они без ядра бесполезны. Этот механизм чем-то напоминает отношения официанта и клиента: работа хорошего официанта должна быть практически незаметна для клиента, но без официанта клиент не сможет передать заказ повару, и этот заказ не будет доставлен.
В Linux ядро монолитное, т.е. все его драйвера и подсистемы работают в своем адресном пространстве, отделенном от пользовательского. Сам термин «монолит» говорит о том, что в ядре сконцентрировано всё, и, по логике, ничего не может в него добавляться или удаляться. В случае с ядром Linux — это правда лишь отчасти: ядро Linux может работать в таком режиме, однако, в подавляющем большинстве сборок возможна модификация части кода ядра без его перекомпиляции, и даже без его выгрузки. Это достигается путем загрузки и выгрузки некоторых частей ядра, которые называются модулями. Чаще всего в процессе работы необходимо подключать модули драйверов устройств, поддержки криптографических алгоритмов, сетевых средств, и, чтобы уметь это правильно делать, нужно разбираться в строении ядра и уметь правильно работать с его модулями. Об этом и пойдет речь в этой статье.
В современных ядрах при подключении оборудования модули подключаются автоматически, а это событие обрабатывается демоном udev, который создает соответствующий файл устройства в каталоге "/dev". Все это выполняется в том случае, если соответствующий модуль корректно установлен в дерево модулей. В случае с файловыми системами ситуация та же: при попытке монтирования файловой системы ядро подгружает необходимый модуль автоматически, и выполняет монтирование.
Если необходимость в модуле не на столько очевидна, ядро его не загружает самостоятельно. Например, для поддержки функции шифрования на loop устройстве нужно вручную подгрузить модуль «cryptoloop», а для непосредственного шифрования — модуль алгоритма шифрования, например «blowfish».
Поиск необходимого модуля
Модули хранятся в каталоге "/lib/modules/" в виде файлов с расширением «ko». Для получения списка всех модулей из дерева можно выполнить команду поиска всех файлов с расширением «ko» в каталоге с модулями текущего ядра:
find /lib/modules/`uname -r` -name ‘*.ko’
Полученный список даст некоторое представление о доступных модулях, их назначении и именах. Например, путь «kernel/drivers/net/wireless/rt2x00/rt73usb.ko» явно указывает на то, что этот модуль — драйвер устройства беспроводной связи на базе чипа rt73. Более детальную информацию о модуле можно получить при помощи команды modinfo:
Загрузка и выгрузка модулей
Загрузить модуль в ядро можно при помощи двух команд: «insmod» и «modprobe», отличающихся друг от друга возможностью просчета и удовлетворения зависимостей. Команда «insmod» загружает конкретный файл с расширением «ko», при этом, если модуль зависит от других модулей, еще не загруженных в ядро, команда выдаст ошибку, и не загрузит модуль. Команда «modprobe» работает только с деревом модулей, и возможна загрузка только оттуда по имени модуля, а не по имени файла. Отсюда следует область применения этих команд: при помощи «insmod» подгружается файл модуля из произвольного места файловой системы (например, пользователь скомпилировал модули и перед переносом в дерево ядра решил проверить его работоспособность), а «modprobe» — для подгрузки уже готовых модулей, включенных в дерево модулей текущей версии ядра. Например, для загрузки модуля ядра «rt73usb» из дерева ядра, включая все зависимости, и отключив аппаратное шифрование, нужно выполнить команду:
После загрузки модуля можно проверить его наличие в списке загруженных в ядро модулей при помощи команды «lsmod»:
| Module | Size | Used by | |
| rt73usb | 17305 | 0 | |
| crc_itu_t | 999 | 1 | rt73usb |
| rt2x00usb | 5749 | 1 | rt73usb |
| rt2x00lib | 19484 | 2 | rt73usb,rt2x00usb |
Из вывода команды ясно, что модуль подгружен, а так же в своей работе использует другие модули.
Чтобы его выгрузить, можно воспользоваться командой «rmmod» или той же командой «modprobe» с ключем "-r". В качестве параметра обоим командам нужно передать только имя модуля. Если модуль не используется, то он будет выгружен, а если используется — будет выдана ошибка, и придется выгружать все модули, которые от него зависят:
Для автоматической загрузки модулей в разных дистрибутивах предусмотрены разные механизмы. Я не буду вдаваться здесь в подробности, они для каждого дистрибутива свои, но один метод загрузки всегда действенен и удобен: при помощи стартовых скриптов. В тех же RedHat системах можно записать команды загрузки модуля прямо в "/etc/rc.d/rc.local" со всеми опциями.
Файлы конфигурация модулей находится в каталоге "/etc/modprobe.d/" и имеют расширение «conf». В этих файлах преимущественно перечисляются альтернативные имена модулей, их параметры, применяемые при их загрузке, а так же черные списки, запрещенные для загрузки. Например, чтобы вышеупомянутый модуль сразу загружался с опцией «nohwcrypt=1» нужно создать файл, в котором записать строку:
options rt73usb nohwcrypt=1
Черный список модулей хранится преимущественно в файле "/etc/modules.d/blacklist.conf" в формате «blacklist ». Используется эта функция для запрета загрузки глючных или конфликтных модулей.
Сборка модуля и добавление его в дерево
Иногда нужного драйвера в ядре нет, поэтому приходится его компилировать вручную. Это так же тот случай, если дополнительное ПО требует добавление своего модуля в ядро, типа vmware, virtualbox или пакет поддержки карт Nvidia. Сам процесс компиляции не отличается от процесса сборки программы, но определенные требования все же есть.
Во первых, нужен компилятор. Обычно установка «gcc» устанавливает все, что нужно для сборки модуля. Если чего-то не хватает — программа сборки об этом скажет, и нужно будет доустановить недостающие пакеты.
Во вторых, нужны заголовочные файлы ядра. Дело в том, что модули ядра всегда собираются вместе с ядром, используя его заголовочные файлы, т.к. любое отклонение и несоответствие версий модуля и загруженного ядра ведет к невозможности загрузить этот модуль в ядро.
Если система работает на базе ядра дистрибутива, то нужно установить пакеты с заголовочными файлами ядра. В большинстве дистрибутивов это пакеты «kernel-headers» и/или «kernel-devel». Для сборки модулей этого будет достаточно. Если ядро собиралось вручную, то эти пакеты не нужны: достаточно сделать символическую ссылку "/usr/src/linux", ссылающуюся на дерево сконфигурированных исходных кодов текущего ядра.
После компиляции модуля на выходе будет получен один или несколько файлов с расширением «ko». Можно попробовать их загрузить при помощи команды «insmod» и протестировать их работу.
Если модули загрузились и работают (или лень вручную подгружать зависимости), нужно их скопировать в дерево модулей текущего ядра, после чего обязательно обновить зависимости модулей командой «depmod». Она пройдется рекурсивно по дереву модулей и запишет все зависимости в файл «modules.dep», который, в последствие, будет анализироваться командой «modprobe». Теперь модули готовы к загрузке командой modprobe и могут загружаться по имени со всеми зависимостями.
Стоит отметить, что при обновлении ядра этот модуль работать не будет. Нужны будут новые заголовочные файлы и потребуется заново пересобрать модуль.
Ошибка «Invalid argument» может говорить о чем угодно, саму ошибку ядро на консоль написать не может, только при помощи функции «printk» записать в системный лог. Посмотрев логи можно уже узнать в чем ошибка:
В этом примере выведена только последняя строка с ошибкой, чтобы не загромаждать статью. Модуль может написать и несколько строк, поэтому лучше выводить полный лог, или хотя бы последние строк десять.
Ошибку уже легко найти: значение «2» неприемлемо для параметра «nohwcrypt». После исправления, модуль корректно загрузится в ядро.
Из всего сказанного можно сделать один вывод: ядро Linux играет по своим правилам и занимается серьезными вещами. Тем не менее — это всего лишь программа, оно, по сути, не сильно отличается от других обычных программ. Понимание того, что ядро не так уж страшно, как кажется, может стать первым шагом к пониманию внутреннего устройства системы и, как результат, поможет быстро и эффективно решать задачи, с которыми сталкивается любой администратор Linux в повседневной работе.
Популярные теги
Оригинал: How to install kernel headers on Linux
Автор: Dan Nanni
Дата публикации: 11 декабря 2014 года
Перевод: А. Кривошей
Дата перевода: апрель 2015 г.
Когда вы компилируете драйвер устройства как модуль ядра, вам необходимы установленные заголовочные файлы ядра. Также они требуются, если вы собираете пользовательское приложение, которое взаимодействует напрямую с ядром. При установке заголовочных файлов ядра, необходимо убедиться, что их версия совпадает с версией ядра установленного в системе.
Если версия вашего ядра не менялась после установки дистрибутива, или вы обновляли его с использованием системного менеджера пакетов (то есть apt-get, aptitude или yum) из системных репозиториев, то заголовочные файлы вы также можете установить с помощью пакетного менеджера. Однако если вы скачивали исходный код ядра и компилировали его самостоятельно, то заголовочные файлы необходимо устанавливать с помощью команды make.
Здесь мы предполагаем, что ваше ядро установлено из основного системного репозитория вашего дистрибутива, и вы хотите установить соответствующие заголовочные файлы ядра.
Похожие вопросы
Установка среды разработки
На Ubuntu нужно запустить:
Устанавливаем самые важные инструменты разработки и заголовки ядра, необходимые для данного примера.
Примеры ниже предполагают, что вы работаете из-под обычного пользователя, а не рута, но что у вас есть привилегии sudo. Sudo необходима для загрузки модулей ядра, но мы хотим работать по возможности за пределами рута.
Не для простых смертных
Написание модуля ядра Linux — занятие не для слабонервных. Изменяя ядро, вы рискуете потерять данные. В коде ядра нет стандартной защиты, как в обычных приложениях Linux. Если сделать ошибку, то повесите всю систему.
Ситуация ухудшается тем, что проблема необязательно проявляется сразу. Если модуль вешает систему сразу после загрузки, то это наилучший сценарий сбоя. Чем больше там кода, тем выше риск бесконечных циклов и утечек памяти. Если вы неосторожны, то проблемы станут постепенно нарастать по мере работы машины. В конце концов важные структуры данных и даже буфера могут быть перезаписаны.
Можно в основном забыть традиционные парадигмы разработки приложений. Кроме загрузки и выгрузки модуля, вы будете писать код, который реагирует на системные события, а не работает по последовательному шаблону. При работе с ядром вы пишете API, а не сами приложения.
У вас также нет доступа к стандартной библиотеке. Хотя ядро предоставляет некоторые функции вроде printk (которая служит заменой printf ) и kmalloc (работает похоже на malloc ), в основном вы остаётесь наедине с железом. Вдобавок, после выгрузки модуля следует полностью почистить за собой. Здесь нет сборки мусора.
Необходимые компоненты
Прежде чем начать, следует убедиться в наличии всех необходимых инструментов для работы. Самое главное, нужна машина под Linux. Знаю, это неожиданно! Хотя подойдёт любой дистрибутив Linux, в этом примере я использую Ubuntu 16.04 LTS, так что в случае использования других дистрибутивов может понадобиться слегка изменить команды установки.
Во-вторых, нужна или отдельная физическая машина, или виртуальная машина. Лично я предпочитаю работать на виртуальной машине, но выбирайте сами. Не советую использовать свою основную машину из-за потери данных, когда сделаете ошибку. Я говорю «когда», а не «если», потому что вы обязательно подвесите машину хотя бы несколько раз в процессе. Ваши последние изменения в коде могут ещё находиться в буфере записи в момент паники ядра, так что могут повредиться и ваши исходники. Тестирование в виртуальной машине устраняет эти риски.
И наконец, нужно хотя бы немного знать C. Рабочая среда C++ слишком велика для ядра, так что необходимо писать на чистом голом C. Для взаимодействия с оборудованием не помешает и некоторое знание ассемблера.
Установка заголовочных файлов ядра в Fedora, CentOS или RHEL
Если вы не обновляли ядро вручную, то можете установить соответствующие заголовочные файлы ядра с помощью команды yum.
Сначала проверьте, не установлены ли уже требуемые заголовочные файлы. По умолчанию заголовочные файлы ядра расположены в /usr/src/kernels/.
Если подходящих заголовочных файлов не установлено, вы можете установить их с помощью команды yum. Она автоматически найдет подходящий пакет.
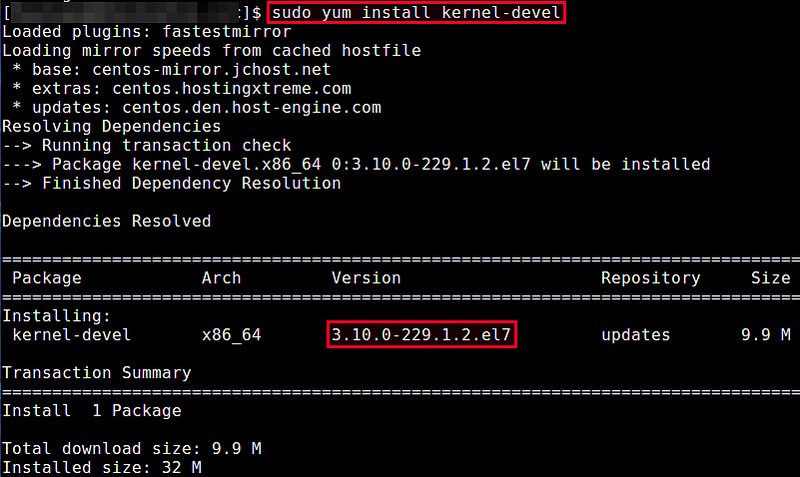
Если заголовочные файлы ядра, установленные с помощью вышеприведенной команды, не соответствуют установленному в системе ядре, значит оно устарело. В этом случае обновите ядро системы до последней версии с помощью приведенной ниже команды. После обновления необходимо перезагрузить систему.
Теперь проверьте, что установлены заголовочные файлы соответствующей версии с помощью команды:
В этом посте я расскажу о своих поисках признаков того, как можно определить, что из некоторых файлов исходных текстов собирается загружаемый модуль ядра Linux (LKM), а не обычный исполняемый файл.
Допустим, что информации о назначении исходников нет или её пытаются преднамеренно скрыть.
Upd: Объём кода > 4 Гб и надо оперативно выделить только те исходники, которые реализуют модули ядра.

При сборке исходных текстов определён символ препроцессора __KERNEL__.
Как пишут Alessandro Rubini и Jonathan Corbet в книге «Драйверы устройств в Linux»:
Например, в makefile может присутствовать строчка «CFLAGS = -D__KERNEL__».
Или "-D__KERNEL__" можно обнаружить в логах сборки .
Если модуль не линкуется к ядру статически, то в составе переменной CFLAGS обязательно будет присутствовать строка "-DMODULE". Этот символ препроцессора должен быть определён до подключения файла linux/module.h.
Таким образом разработчик избегает «загрязнения» пространства имён ядра — иначе при отладке ему пришлось бы отлавливать имена своего модуля среди всех имён ядра. Использование префикса освобождает от обязанности придумывать уникальные имена, которые не будут совпадать с именами, уже присутствующими в пространстве имён ядра.
В исходных текстах вместо функции printf() используется функция printk(). «Драйверы устройств в Linux» говорит:
«Функция printk определена в ядре и по своему поведению напоминает функцию printf из стандартной библиотеки языка C. Зачем же тогда ядру своя собственная функция? Все просто — ядро, это самостоятельный код, который собирается без вспомогательных библиотек языка C.»
«Приложение выполняется как цельная задача, от начала и до конца. Модуль же просто регистрирует себя самого в ядре, подготавливая его для обслуживания возможных запросов и его функция „main“ завершает свою работу сразу же после вызова. Другими словами, задача функции init_module (точка входа) состоит в подготовке функций модуля для последующих вызовов. Она как бы говорит ядру: „Эй! Я здесь! Вот то, что я могу делать!“. Вторая точка входа в модуль — cleanup_module — вызывается непосредственно перед выгрузкой модуля. Она сообщает ядру: „Я ухожу! Больше не проси меня ни о чем!“. „
Upd: Более надёжным признаком является наличие в тексте функции cleanup_module, т.к. функции с таким именем встречаются в примерно в 20 раз реже, чем с именем “init_module». Судя по всему, название "init_module" пользуется популярностью не только среди писателей модулей ядра.
" <. >Код ядра может определить текущий процесс, обратившийся к модулю, через глобальный элемент current — указатель на struct task_struct, который в ядре 2.4 объявляется в файле . Указатель current ссылается на текущий пользовательский процесс. В процессе выполнения системных вызовов, таких как read или write, текущим считается процесс, сделавший этот вызов. Ядро может воспользоваться информацией о текущем процессе, используя указатель current, если возникнет такая необходимость. <. >
Фактически current более не является глобальной переменной ядра, как это было ранее. Разработчики оптимизировали доступ к структуре, описывающей текущий процесс, перенеся ее на стек. Реализацию current вы найдете в файле . Но прежде, чем вы отправитесь исследовать этот файл, вы должны запомнить, что Linux — это SMP-совместимая система (от англ. SMP — Symmetric Multi-Processing) и потому простая глобальная переменная здесь просто неприменима. Детали реализации находятся в других подсистемах ядра и все же, драйвер устройства может подключить заголовочный файл и обращаться к указателю current.
С точки зрения модуля, current — обычная внешняя ссылка, как например printk. Модуль может обращаться к current всякий раз, когда сочтет это необходимым. Например, следующий код выведет идентификатор (ID) процесса и имя команды, запустившей процесс:
printk(«The process is \»%s\" (pid %i)\n", current->comm, current->pid);
Имя команды хранится в поле current->comm и представляет собой имя файла программы.
А какие вы ещё знаете отличия модуля ядра от исполняемого файла на уровне исходников?

Linux предоставляет мощный и обширный API для приложений, но иногда его недостаточно. Для взаимодействия с оборудованием или осуществления операций с доступом к привилегированной информации в системе нужен драйвер ядра.
Модуль ядра Linux — это скомпилированный двоичный код, который вставляется непосредственно в ядро Linux, работая в кольце 0, внутреннем и наименее защищённом кольце выполнения команд в процессоре x86–64. Здесь код исполняется совершенно без всяких проверок, но зато на невероятной скорости и с доступом к любым ресурсам системы.
Немного интереснее
Копнём чуть глубже. Хотя модули ядра способны выполнять все виды задач, взаимодействие с приложениями — один из самых распространённых вариантов использования.
Поскольку приложениям запрещено просматривать память в пространстве ядра, для взаимодействия с ними приходится использовать API. Хотя технически есть несколько способов такого взаимодействия, наиболее привычный — создание файла устройства.
Вероятно, раньше вы уже имели дело с файлами устройств. Команды с упоминанием /dev/zero , /dev/null и тому подобного взаимодействуют с устройствами “zero” и “null”, которые возвращают ожидаемые значения.
В нашем примере мы возвращаем “Hello, World”. Хотя это не особенно полезная функция для приложений, она всё равно демонстрирует процесс взаимодействия с приложением через файл устройства.
Вот полный листинг:
Начинаем
Приступим к написанию кода. Подготовим нашу среду:
Запустите любимый редактор (в моём случае это vim) и создайте файл lkm_example.c следующего содержания:
Мы сконструировали самый простой возможный модуль, рассмотрим подробнее самые важные его части:
- В include перечислены файлы заголовков, необходимые для разработки ядра Linux.
- В MODULE_LICENSE можно установить разные значения, в зависимости от лицензии модуля. Для просмотра полного списка запустите:
Если мы запускаем make , он должен успешно скомпилировать наш модуль. Результатом станет файл lkm_example.ko . Если выскакивают какие-то ошибки, проверьте, что кавычки в исходном коде установлены корректно, а не случайно в кодировке UTF-8.
Теперь можно внедрить модуль и проверить его. Для этого запускаем:
Если всё нормально, то вы ничего не увидите. Функция printk обеспечивает выдачу не в консоль, а в журнал ядра. Для просмотра нужно запустить:
Вы должны увидеть строку “Hello, World!” с меткой времени в начале. Это значит, что наш модуль ядра загрузился и успешно сделал запись в журнал ядра. Мы можем также проверить, что модуль ещё в памяти:
Для удаления модуля запускаем:
Если вы снова запустите dmesg, то увидите в журнале запись “Goodbye, World!”. Можно снова запустить lsmod и убедиться, что модуль выгрузился.
Как видите, эта процедура тестирования слегка утомительна, но её можно автоматизировать, добавив:
в конце Makefile, а потом запустив:
для тестирования модуля и проверки выдачи в журнал ядра без необходимости запускать отдельные команды.
Теперь у нас есть полностью функциональный, хотя и абсолютно тривиальный модуль ядра!
Тестирование улучшенного примера
Теперь после запуска make test вы увидите выдачу старшего номера устройства. В нашем примере его автоматически присваивает ядро. Однако этот номер нужен для создания нового устройства.
Возьмите номер, полученный в результате выполнения make test , и используйте его для создания файла устройства, чтобы можно было установить коммуникацию с нашим модулем ядра из пространства пользователя.
(в этом примере замените MAJOR значением, полученным в результате выполнения make test или dmesg )
Параметр c в команде mknod говорит mknod, что нам нужно создать файл символьного устройства.
Теперь мы можем получить содержимое с устройства:
или даже через команду dd :
Вы также можете получить доступ к этому файлу из приложений. Это необязательно должны быть скомпилированные приложения — даже у скриптов Python, Ruby и PHP есть доступ к этим данным.
Когда мы закончили с устройством, удаляем его и выгружаем модуль:
Читайте также: