
Что такое vss monitoring ethernet trailer
Добрый день.
Подскажите получатель igmp джоинта (cisco), не понимать\дропать пакет, из за лишних байтов?
Frame 542: 66 bytes on wire (528 bits), 66 bytes captured (528 bits) on interface 0
Interface id: 0 (\Device\NPF_)
Encapsulation type: Ethernet (1)
Arrival Time: Aug 18, 2017 10:45:19.461401000 RTZ 2 (����)
[Time shift for this packet: 0.000000000 seconds]
Epoch Time: 1503042319.461401000 seconds
[Time delta from previous captured frame: 0.180545000 seconds]
[Time delta from previous displayed frame: 28.995750000 seconds]
[Time since reference or first frame: 165.518188000 seconds]
Frame Number: 542
Frame Length: 66 bytes (528 bits)
Capture Length: 66 bytes (528 bits)
[Frame is marked: False]
[Frame is ignored: False]
[Protocols in frame: eth:ethertype:ip:igmp:igmp:vssmonitoring]
[Coloring Rule Name: Routing]
[Coloring Rule String: hsrp || eigrp || ospf || bgp || cdp || vrrp || carp || gvrp || igmp || ismp]
Ethernet II, Src: Zhongxin_9c:7f:9a (00:d0:d0:9c:7f:9a), Dst: IPv4mcast_00 (01:00:5e:00:00:00)
Destination: IPv4mcast_00 (01:00:5e:00:00:00)
Address: IPv4mcast_00 (01:00:5e:00:00:00)
. ..0. . . . . = LG bit: Globally unique address (factory default)
. . 1 . . . . = IG bit: Group address (multicast/broadcast)
Source: Zhongxin_9c:7f:9a (00:d0:d0:9c:7f:9a)
Address: Zhongxin_9c:7f:9a (00:d0:d0:9c:7f:9a)
. ..0. . . . . = LG bit: Globally unique address (factory default)
. . 0 . . . . = IG bit: Individual address (unicast)
Type: IPv4 (0x0800)
Padding: 0000000000000000000000000000
Internet Protocol Version 4, Src: 192.168.2.14, Dst: 225.0.0.0
Internet Group Management Protocol
[IGMP Version: 2]
Type: Membership Report (0x16)
Max Resp Time: 0.0 sec (0x00)
Header checksum: 0x08ff [correct]
Multicast Address: 225.0.0.0
VSS-Monitoring ethernet trailer, Source Port: 0
Src Port: 0
First time here? Check out the FAQ!
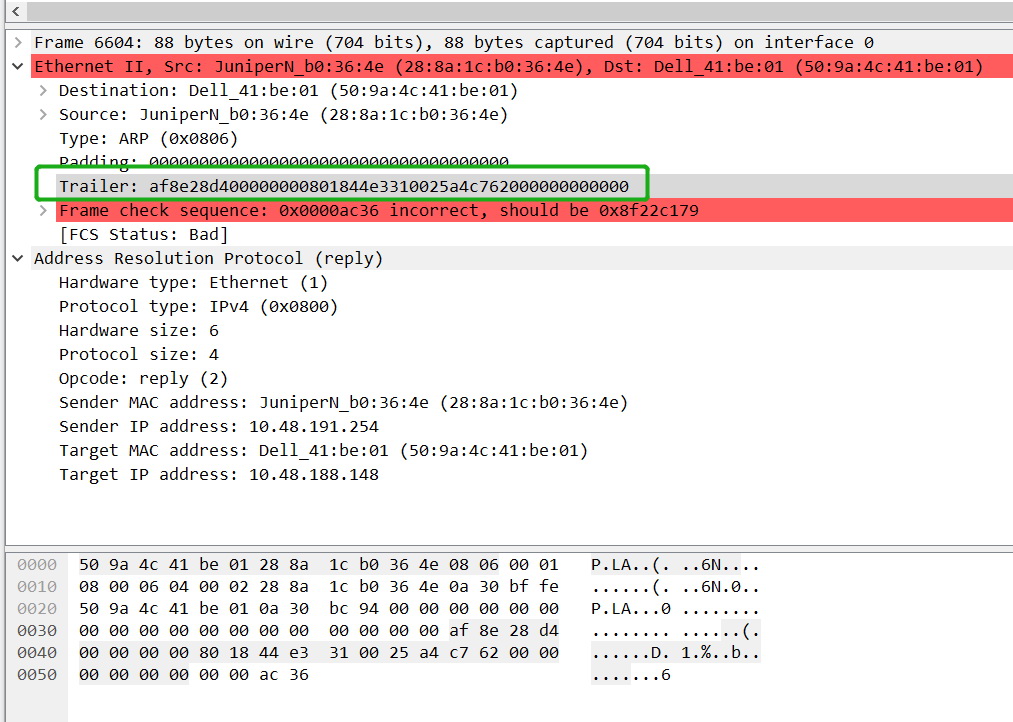
I captured an ARP Reply, there are both padding and trailer in the Ethernet frame.
As far as I know, padding is to make the frame length reach at least 64B.
But, what is the trailer used for?
And Wireshark does not display FCS in other frames,why is the FCS incorrect in this frame?
The preliminaries
I set up my OpenStack cluster on 6 Dell OptiPlex 7040 machines, 1 router, 1 managed switch, and 1 unmanaged switch. True, this is not the usual enterprise hardware you would want for a production cluster, but I tend to take things literally, so I set up OpenStack on commodity hardware. In any event, my goal was to set up a portable OpenStack cluster for demo purposes, not for production use cases.

OpenStack Cluster
Since my cluster nodes only have one NIC and I wanted to have a multi-NIC setup, I considered my options and settled on a USB 3.0 to Gigabit Ethernet adapter as a second NIC. The adapter supports 802.1Q, checksum offloading, has drivers for Linux kernel 4.x/3.x/2.6.x, and it’s received positive reviews for running on Linux. Once everything was set up and the wiring was complete, I started the installation of Mirantis OpenStack 9.1 from a USB stick on my designated Fuel master node.
Много фильтраций, хороших и разных
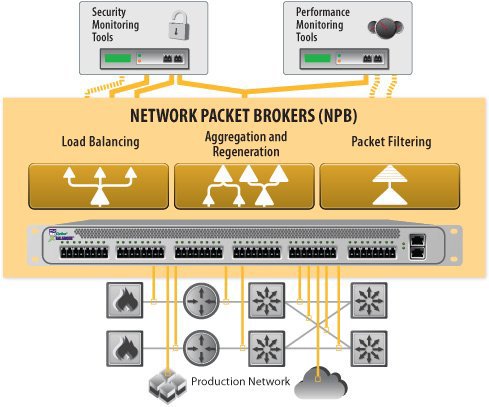
Для того, чтобы дать более ясное представление о том, что происходит с пакетами внутри NPB и что же в итоге отправляется на балансировку, рассмотрим некоторые из основных функций фильтрации, реализованных в большинстве приборов данного типа.

Packet Filtering
Позволяет фильтровать приходящие пакеты с помощью заданных правил. Это может быть протокол, MAC, IP, VLAN теги, метки MPLS и другие. Поиск при этом ведется по всему содержимому пакета (включая payload). Шаблоны, которые при этом используются, могут быть как простыми строками со статическим, заданным пользователем отступом, так и сложными регулярными выражениями с меняющимся отступом. Основная задача — пропустить пакеты, попадающие под заданные критерии, для их последующей балансировки.

Port Stamping
Функция вставки в пакет метки номера порта, с которого он пришел. Генерация номера, записываемого в поле самой метки, происходит по определенной формуле. В некоторых приборах есть возможность назначения номера порта самостоятельно через CLI. Длина поля не больше 2-х байт. При этом CRC пакета после вставки метки пересчитывается.

Packet De-duplication
Помечает или вовсе удаляет дублированные пакеты, которые обнаруживаются при помощи сконфигурированного интервала оригинального пакета (от 1 до 50,000 микросекунд). Встречаются при использовании технологий SPAN и mirror в switch'ах, либо при сборе пакетов с нескольких мест.

Tagging (VLAN и MPLS)
Служит для вставки в пакеты меток VLAN или MPLS, что позволяет отслеживать их и управлять их перемещением по сети.

Protocol/Header Stripping, De-incapsulation
Функции, обратные tagging’у и не отличающиеся друг от друга по принципу действия — удаление определенной части пакета (например, заголовков или меток).
How Dynatrace could have saved me time
If I’d used Dynatrace OpenStack Monitoring to troubleshoot this issue to troubleshoot this issue I’d have seen the impact on network quality on all of my monitored VMs. Additionally, I could have enabled Dynatrace log analytics to assist with troubleshooting from a log-analysis perspective. When your gut tells you that there may be troubles with MTU coming your way, you can proactively add the /var/log/kern.log file to Dynatrace log analytics and create a pattern-recognition rule (for example, over-mtu packet ). With this approach, I could have received a notification each time this pattern appeared in the log files and I would have instantly known where to look for errors in the configuration… or in the network drivers.
Go-Go Gadget troubleshooting
Suspecting that a series of unfortunate events had simply occurred, I tried again. Unfortunately, I got the same result: SSH, ps faux , freeze… Damn! I was able to ping the instance, connect to it, interact with it, but it seemed that the large amount of data I was attempting to transfer was breaking the connection. I started to investigate by pinging the instance again using different packet sizes. I received the following result:
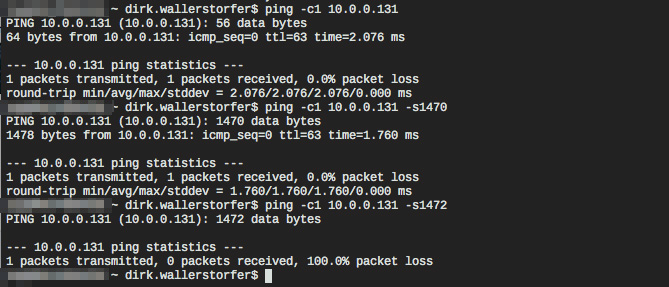
Ping with different payload sizes
Interestingly, pings with large payloads weren’t answered. It was time to get to the bottom of this issue using some Network 101 analysis:
- Your average Ethernet frame is 1514 bytes long
- The Ethernet header takes up 14 bytes, which leaves 1500 bytes for payload
- The IP header is 20 bytes long
- The ICMP header is 8 bytes
- That should leave exactly 1472 bytes (1500 – 20 – 8 = 1472) for ICMP payload
The odd thing is, a payload of 1470 bytes works while a payload of 1472 bytes doesn’t work. This is only a 2-byte difference, which makes no sense. There is clearly a problem with large packets, but how on earth can it be off by 2 bytes? 2 bytes is essentially nothing; a VLAN header has 4 bytes and the link layer takes care of VLANs, so this doesn’t affect the payload size. Maybe IP options are the culprit? Nope, the IP header must be a multiple of 4 bytes. 2 bytes is simply inexplicable from a network protocol point of view. It’s time to send in tcpdump and Wireshark to the rescue.
2 Answers
Since the Ethernet header does not include a length field, Wireshark needs to figure out the purpose of the data on its own. For "normal" frames it would be one of the following formats:
By dissecting the "payload", Wireshark knows how much data was actually upper protocol data, so the rest should be part of the ethernet layer. It will then use some heuristics to decide what part of that data was padding and whether there was a FCS (which will be stripped by most NIC's before Wireshark gets to see the packets), meaning Wireshark sees:
Now when there is extra data that can't be padding, Wireshark will show it as "trailer" data. There are systems that add stuff to the ethernet packet as trailer. For instance, packet brokers often add timestamps and port information into an ethernet trailer. F5 loadbalancers also add trailers to provide information on the Virtual being used for the traffic for instance.
In your case, there is no dissector dissecting the trailer bytes into some protocol headers, so all Wireshark can do is display it as a (general) trailer. It then also (incorrectly) assumes that the last 4 bytes are the FCS and so it tries to verify it's correctness. However, mot likely, the real FCS has already been stripped by the NIC.
You can fiddle with the "Ethernet" protocol preferences to make Wireshark not assume there was a FCS and just display the trailer data as "trailer".
The interesting question is "Where and how was this capture taken?". As some system must have included the extra trailer for some reason. Do you know if there was a loadbalancer or packet broker involved?
Недавно, в ходе работы над 100GE анализатором трафика передо мной была поставлена задача по изучению такого типа приборов, как Network Packet Broker (также встречается название Network Monitoring Switch), или, если просто и по-русски, «балансировщик».
Используется этот прибор преимущественно в системах сетевого мониторинга. Постепенно, углубляясь в тему, накопилось достаточное количество информации, разрозненной по различным уголкам интернета и документациям. Так и родилась идея статьи, в которой я решил собрать всю найденную информацию воедино и поделиться с хабросообществом.
Для тех, кому стало интересно, что же такого особенного в этом типе приборов, как они используются и почему именно «балансировщик» — прошу под кат.
Что в имени тебе моем?

NPB — встраиваемое в стойку сетевое устройство, получающее и агрегирующее сетевой трафик с SPAN -портов или TAP -ов. Этим-то трафиком (или его копиями) и манипулирует в дальнейшем сам NPB.
NPB могут быть как цельным устройством, так и модульным (т.е. состоять из нескольких blade-ов в одном корпусе с возможностью замены). Типичным набором характеристик NPB являются:
Преимущества приобретения ПО у нас
Компания Nettix работает с программным обеспечением для компьютерных сетей. Всё, что мы реализуем, заточено под их нужды. Компания следит за качеством предоставляемого оборудования, а также ведёт выгодную для обеих сторон ценовую политику.
Чтобы работать с нами, просто позвоните или приезжайте по указанному адресу.
Для быстрого заказа используйте электронную форму, которая размещена на сайте.
Расширенные Network packet brokers для сервис-провайдеров, крупных и средний предприятий и федеральных государственных учреждений:
Оборудование обеспечивает полную прозрачность сети путем захвата и раздачи (brokering) трафика из одной или нескольких полнодуплексных сетей в несколько пассивных систем мониторинга, доступ к данным и оптимизацию работы средств мониторинга сети и средств обеспечения безопасности.
Сетевая интеллектуальная система сбора трафика с уникальными возможностями для оптимизации встроенных средств безопасности и возможностью построения многоуровневых архитектур безопасности.
Серия Protector позволяет вам использовать активные (линейные) интеллектуальные сетевые устройства (такие, как IPS (системы предотвращения вторжений), прокси-серверы, контроллеры WAN-акселлерации) в ваших системах оптимизации сети.

vMC
Традиционные ответвители (Test Access Points, TAPs) компании VSS включают в себя базовые сетевые ответвители, коммутаторы TAP и SPAN, репплицирующие и агрегирующие ответвители (агрегаторы SPAN-портов).
Открывает доступ к трафику от полнодуплексных сетей, делая их доступными для интеллектуальных сетевых инструментов и систем оптимизации при построении сетей.
Консоль управления VSS Monitoring на уровне системы, для управления Network packet brokers и TAPs, обеспечивающая просмотр профиля топологии всей сети, управление политиками, отчетностями и обновлениями.
Серия устройств vInspector обеспечивает в реальном времени двунаправленную расшифровку и повторную шифровку SSL трафика, проходящего через корпоративные сети.
Серия интеллектуальных устройств распределенного сбора трафика (Distributed Traffic Capture System, DTCS) для пассивных инструментов анализа.
Оборудование позволяет захватывать трафик непосредственно в сети или в SPAN-портах и передавать его в пассивные инструменты сетевого мониторинга и сетевой безопасности.
Доступ, захват, объединение, фильтрация и способ передачи трафика из одного или нескольких физических или виртуальных точек сетевого доступа, непосредственно к нескольким хранилищам или платформам содержащим большое количество данных.
Lessons learned
I learned a lot while troubleshooting this issue. Here are my insights:
- First and foremost, use recommended/certified hardware for OpenStack and follow the recommendations of your distribution of choice. I spent a lot of time chasing down a bug that would have been avoided if I’d used appropriate hardware.
- Knowing computer networks and understanding OpenStack Neutron is mandatory for troubleshooting. Get familiar with the technologies you’re using.
- OpenStack works. There are huge setups out there working in production. When something doesn’t work as expected, the issue is likely not with OpenStack or its services.
- When troubleshooting, trust your experience and gut feelings!
- Have a monitoring solution in place that allows you to verify your assumptions!
Ссылки:
Сайт Gigamon.
Сайт VSS Monitoring.
Сайт Ixia.
Сайт Apcon.
P.S. Выражаю огромную благодарность Des333 и paulig за помощь в подготовке статьи.
Once upon a time, I set up an OpenStack cluster and experienced some strange connectivity problems with all my OpenStack instances. It was the perfect opportunity to learn more about OpenStack, perform a head-long deep dive into Neutron, and update my network troubleshooting skills.
Bring in the big guns
I start up Wireshark on my laptop and again ping the floating IP address of the OpenStack instance. No additional information; the last ping with a payload of 1472 bytes doesn’t receive a response.
Ping analysis with Wireshark
The next step is to run tcpdump on the OpenStack controller node that also runs Neutron, the OpenStack networking component in my setup. Neutron takes care of capturing, NATing, and forwarding the ICMP message to the instance. To understand all the details of OpenStack networking in detail, please check out the official OpenStack Networking Guide. In short, OpenStack networking is a lot like Venice—there are masquerades and bridges all over the place!

OpenStack networking is like Venice
Joking aside, the tcpdump on the controller reveals no further information.
Tcpdump of ping on Neutron node
However, it does show how many hops it takes to ping an OpenStack instance. The ICMP packet traverses the physical network from my laptop (10.0.0.100) to the floating IP address of the instance (10.0.0.131), several virtual interfaces and bridges, until it reaches the OpenStack instance on its private IP address (192.168.10.101), which in turn sends the response back to my laptop along the same route.

Tcpdump of ping with payload sizes 1470 and 1472 (+8 bytes ICMP header, yields lengths of 1478 and 1480)
Once again, the ping with 1470 bytes of payload receives a response while the 1472-byte payload remains unanswered. However, we get some additional information. The packet vanishes before the destination address is changed to the private IP address of the instance and the packet is forwarded to the compute node that runs the instance. I checked the Neutron log files, Nova log files, and syslog, but couldn’t find anything. Eventually, I found something interesting in the kern.log file.
Kernel log file showing dropped packets
Remember the 2-byte difference we identified earlier? Here they are, causing the kernel to drop the packets silently because they’re too long. Now we have evidence that something is messing up the network packets. However, the questions remain; why and how? Analyzing the tcpdump with Wireshark sheds more light on the problem. Can you spot it in the image below?

Wireshark view of previous tcpdump
First, the destination MAC address is empty because we used tcpdump on “any” device. In that mode, tcpdump doesn’t capture the link-layer header correctly. Instead, it supplies a fake header. Secondly, the Ethernet frame No. 1 has a length of 1518 bytes, which is odd given the 1470 bytes of ICMP payload, 8 bytes of ICMP header, 20 bytes of IP header, and 18 bytes of Ethernet + VLAN header (1470 + 8 + 20 + 18 = 1516 bytes).
Have a look at the line VSS-Monitoring ethernet trailer, Source Port: 9599 in the Wireshark screenshot above, just below the yellow highlighted ICMP line.

Trailing bytes
Finally, we’ve found the 2 additional bytes! But, where do they come from? Google tells us that this can be caused by the padding of packets at the network-driver level. I reconsidered my setup and identified the USB network adapter as the weakest link. To be honest, I suspected this might be the issue from the beginning, but I never imagined it would catch up with me in this way.
I downloaded and built the latest version of the driver and replaced the kernel module. Lo and behold, all my networking problems were gone! Pings of arbitrary payload sizes, SSH sessions, and file transfers all suddenly worked. In the end, my networking issues were caused by an issue with the driver that ships by default with the Linux kernel.
Как работает?
Анализатор трафика работает на основе перехвата данных протокола. После захвата можно вывести анализ пакетов на экран, чтобы затем сделать определённые выводы. Для использования оборудования нужны минимальные знания в сфере информационных технологий.
Самые известные программы для анализа трафика:
- VSS Monitoring – системы, которые копируют и передают трафик в пассивном режиме. Благодаря этому возможен дальнейший его анализ;
- Network Security Systems.
Оборудование зарекомендовало себя как надёжное и простое в обращении.
Вместо заключения
Подытоживая все вышесказанное, можно сказать, что в лице Netwok Packet Broker’ов мы имеем мощный и гибко-настраиваемый инструмент позволяющий фильтровать, агрегировать и перераспределять трафик на различные устройства, без замены уже используемого оборудования.
Платой за пользу такого рода приборов является сложность внедрения их в уже существующие сети — это требует многие часы перепланирования (в зависимости от сложности структуры самой сети и желаемых критериев фильтрации и балансировки).
Среди производителей NPB стоит выделить несколько компаний, таких как VSS Monitoring, Gigamon, Apcon и Ixia (в состав которой, с недавних пор, входит еще и NetOptics, которая также выпускала NPB). Кому интересно, что предлагают те или производители — милости прошу в ссылки.
Спасибо за внимание!
В каких случаях поможет?
Анализ сетевого трафика необходимо совершать постоянно, чтобы исключить длительные проблемы с работой компьютерного оборудования.
Он используется при:
- медленной работе интернет-сети;
- непредвиденных ошибках ПО, которые затрудняют работу;
- появлении специфических проблем в узких участках сети;
- системной ошибке соединения ПК и сети, если GET-запрос не принимается прокси-сервером.
Кроме того, анализатор пригодится для:
- обнаружения подозрительного программного обеспечения, которое плохо документировано;
- анализа сетевого трафика, который используется с определённого компьютера;
- обеспечения безопасности внутренней локальной сети от DoS-атак;
- контроля за безопасностью логинов и паролей;
- установки фильтров на устройство.
Как вы уже поняли, анализатор протоколов необходим для защиты и контроля. На практике он используется для своевременного выявления сетевых ошибок и проблем, что позволяет сохранить работоспособность оборудования и обеспечить бесперебойный рабочий процесс. Это важно на крупных фирмах, где простой стоит солидных денег.
Защита от вредоносного вторжения позволит обеспечить сохранность паролей и другой секретной информации, которая имеется у предприятия. Это залог безопасности коммерческой деятельности.
Анализируя трафик, который используется в локальной сети компьютеров, работодатель может следить за тем, какими ресурсами пользуются его сотрудники. Это его право, ведь зарплата выплачивается за работу, а не просмотр интересующей информации.
Это же программное обеспечение могут использовать родители, переживающие за то, какой контент изучают их дети.
Установка фильтров помогает контролировать трафик, который является доступным для ПК. Вы просто отсекаете материалы, являющиеся противозаконными или экстремистскими.
Также устройство помогает делать анализ активности пользователя с целью выяснить, какое время затрачивается на определённые операции. Система учёта трафика используется в офисах для определения реального рабочего времени сотрудников.
Все эти возможности будут кстати администратору, который хочет вести глобальный мониторинг всего, что происходит в сети.
Что же умеет NPB и в чем его особенности?
Основной и самой главной функцией NPB является балансировка нагрузки (поэтому его и можно назвать «балансировщиком»). Сама по себе балансировка нагрузки — процесс разделения входного потока c одного или нескольких интерфейсов на несколько выходных интерфейсов по определенным правилам или критериям. Почти всегда вместе с балансировкой используются следующие функции:
- Фильтрация — правила, позволяющие выделить потоки с целью их последующей балансировки и уменьшения количества данных в этих потоках.
- Агрегация — объединение потоков с нескольких входных интерфейсов в один перед выполнением операции балансировки.
- Коммутация — большинство NPB может выполнять роль коммутатора.
Во многих компаниях сейчас установлено множество инструментов мониторинга для обеспечения безопасности, наблюдения, аналитики и управления производительностью. Здесь встает проблема перехода на другие уровни скоростей ( с 1G на 10G, с 10G на 100G), ведь остается много оборудования, которое попросту не умеет работать с такими скоростями. Варианта здесь два — либо закупка нового дорогого оборудования, либо внедрение в существующую структуру прослойки в виде NPB, которые будут заниматься адаптацией потоков данных под старое оборудование.

Возьмем для примера обычный call-центр. Практически все они сейчас цифровые и все звонки там проходят в виде VoIP-трафика по LAN, а для записи звонков используются специальные записывающие устройства (network traffic recorders). При увеличении количества звонков в call-центр, какое-то из записывающих устройств может достичь порога своей пропускной способности. Здесь и применяется балансировка нагрузки, позволяющая работать параллельно нескольким записывающим устройствам, c выполнением следующих условий:
- Для каждого звонка, весь разговор (в обоих направлениях потока трафика) должен заканчиваться на одном записывающем устройстве, чтобы не нужно было искать части записанного разговора на нескольких устройствах.
- Вызов установки трафика (трафик SIP) должен быть доступен для всех звонков, поступающих на данное записывающее устройство.
- Равномерная (per-packet или round-robin).
На все выходные порты идет примерно одинаковое количество трафика, пакеты назначаются на выходные интерфейсы по кругу. Данный тип балансировки не обеспечивает Flow Coherency, т.к. направление пакета никак не связано с направлениями других пакетов. - Статическая
Балансировка происходит по фиксированному набору заданных правил, например, по IP-source или типу протокола. При этом количество данных, пришедших на конкретный выходной интерфейс, никак не учитывается, т.е. нет никакой обратной информации о том, какой из выходных интерфейсов получил больше или меньше трафика. В зависимости от того, по каким именно полям происходит фильтрация, данный тип балансировки нагрузки может либо обеспечивать, либо не обеспечивать Flow Coherency. - Динамическая
Идет учет трафика, отправляемого на каждый выходной порт. Наиболее оптимальна, если есть жесткие требования к равномерной нагрузке на выходных интерфейсах. По каким полям будет производиться данный вид балансировки зависит от алгоритма. Поддерживает Flow Coherency. - На основе хэшей
Для выбора порта используются значения хэш-функций, рассчитанных по полям пакета (которые задаются пользователем). Так как для одних и тех же полей всегда будет рассчитан один и тот же хеш, то, при выборе нужных полей, балансировка будет обеспечивать Flow Coherency. Если так выйдет, что в распределении хешей будет перекос, то балансировка может стать очень неравномерной, так как статистика по реальной выходной нагрузке не используется в алгоритме балансировки, но вероятность этого не велика.
- Link state awaraness — функция, которая позволяет отслеживать состояние выходных каналов. Если один из них (или клиентское оборудование) выходит из строя, то трафик автоматически перераспределяется между остальными выходными портами данной группы. Когда канал возвращается в рабочее состояние, то вновь происходит перераспределение трафика. В моменты перераспределения возможны кратковременные нарушения когерентности потока. Работоспособность канала отслеживается по наличию линка и/или при помощи keep-alive пакетов.
- N+M redundancy — функция резервирования каналов, которая работает следующим образом: в балансировочной группе выбираются N используемых (активных) и M резервных каналов и если один из активных каналов группы выходит из строя, то его трафик переводится на один из резервных каналов. При восстановлении канала перераспределения не происходит и восстановленный канал становится резервным. Эта функция используется в том случае, когда недопустимы даже кратковременные нарушения когерентности потока (вместо link state awaraness).
- Overflow mode — эта функция позволяет задействовать каналы по мере увеличения количества трафика. Пользователь выбирает группу каналов и указывает те, которые будут активны сразу. Остальные каналы автоматические будут задействованы после того, как нагрузка на основные превысит заданный пользователем порог.
Hey, ho, let’s go!
My OpenStack cluster has an administration network that is also used for PXE on the onboard NIC. The second NIC is used for private, storage, and public networking via VLANs. Following the successful OpenStack deployment with Fuel, I started an instance on the private network using the cirrOS image to confirm that everything was working. I assigned a floating IP and was able to connect via SSH. I checked the network configuration and then decided to view the running processes using ps faux . After executing the command, the terminal showed some processes, but then the connection froze and became unresponsive. I killed the SSH session on my machine rather than wait for a timeout.
Start a free trial!
Dynatrace is free to use for 15 days! The trial stops automatically, no credit card is required. Just enter your email address, choose your cloud location and install our agent.

Распределенный фильтрующий ответвитель Optimizer 2016 LTE - гибко конфигурируемое «умное» устройство захвата трафика, предназначенное специально для сетей 4G/LTE .

Устройство имеет четыре фиксированных медиа-порта в 10G и двадцать индивидуально активируемых SFP+ -порта в 10G/1G, которые позволяют осуществлять различные .

Предназначены для захвата трафика и передачи его в системы анализа в оптоволоконных сетях, эти ответвители позволяют полностью дублировать весь трафик в сетях .

Предназначены для захвата трафика в стандартных медных сетях и оптоволоконных 1Gb-сетях. Эти ответвители позволяют полностью дублировать весь трафик в таких .

Предназначены для захвата трафика в медных сетях, эти ответвители позволяют полностью дублировать весь трафик в 10 Мб/с или 100 Мб/с-сетях Ethernet .

Современные информационные сети функционируют ещё недостаточно слаженно. То и дело можно столкнуться с небольшими ошибками при запуске сетевых приложений и протоколов.
Это программное обеспечение позволяет захватить информацию при передаче данных и разобрать её по полочкам, определив ошибки.
Читайте также: