
Что такое сжатие файлов
Для чего используется сжатие файлов?
Для чего используется сжатие файлов? К архивации прибегают в нескольких случаях. Например, для сохранения свободного места в хранилище устройства.
Меньший объем файлов позволяет не только их проще хранить, но и без труда переносить с устройства на устройство. При ведении контекстной рекламы Яндекс тоже можно использовать сжатые файлы, например, изображения.
Время копирования заархивированных файлов кратно меньше. К тому же, такие файлы больше защищены, как от взлома, так и от компьютерных вирусов. Коэффициент сжатия можно вычислить по формуле.
Где объем сжатого файла делится на объем исходника, затем умножается на 100%. В итоге получается степень сжатия. Заархивированные файлы можно как упаковать, так и распаковать. Если файлы даже в архиве очень большие, то хранить их можно на нескольких дисках, которые называют томами.
Способ 3: PeaZip
PeaZip — последний подходящий архиватор для максимального сжатия архивов, о котором пойдет речь в этой статье. По своей функциональности он ничем не уступает рассмотренным выше решениям, однако иногда может оказаться полезнее из-за алгоритмов сжатия.
-
Для начала добавления файлов в архив в PeaZip можно использовать и контекстное меню «Проводника», поскольку элементы управления программой добавляются туда автоматически. Выделите требуемые документы и сделайте правый клик мышкой по одному из них.








Существуют и онлайн-сервисы, выполняющие функции архиваторов. Конечно, их эффективность значительно падает, поскольку онлайн не удается реализовать те же алгоритмы, что доступны в десктопных приложениях, однако если вам интересно, попробуйте создать архив через специальные веб-сервисы, ознакомившись с принципом взаимодействия с ними в другой статье на нашем сайте.

Мы рады, что смогли помочь Вам в решении проблемы.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Кодирование длин серий
Кодирование длин серий (RLE — Run-Length Encoding) — это один из самых простых и распространённых алгоритмов сжатия данных. В этом алгоритме последовательность повторяющихся символов заменяется символом и количеством его повторов.
Например, строку «ААААА», требующую для хранения 5 байт (при условии, что на хранение одного символа отводится байт), можно заменить на «5А», состоящую из двух байт. Очевидно, что этот алгоритм тем эффективнее, чем длиннее серия повторов.
Основным недостатком этого алгоритма является его крайне низкая эффективность на последовательностях неповторяющихся символов. Например, если рассмотреть последовательность «АБАБАБ» (6 байт), то после применения алгоритма RLE она превратится в «1А1Б1А1Б1А1Б» (12 байт). Для решения проблемы неповторяющихся символов существуют различные методы.
Самым простым методом является следующая модификация: байт, кодирующий количество повторов, должен хранить информацию не только о количестве повторов, но и об их наличии. Если первый бит равен 1, то следующие 7 бит указывают количество повторов соответствующего символа, а если первый бит равен 0, то следующие 7 бит показывают количество символов, которые надо взять без повтора. Если закодировать «АБАБАБ» с использованием данной модификации, то получим «-6АБАБАБ» (7 байт). Очевидно, что предложенная методика позволяет значительно повысить эффективность RLE алгоритма на неповторяющихся последовательностях символов. Реализация предложенного подхода приведена в Листинг 1:
- type
- TRLEEncodedString = array of byte ;
- function RLEEncode ( InMsg : ShortString ) : TRLEEncodedString ;
- var
- MatchFl : boolean ;
- MatchCount : shortint ;
- EncodedString : TRLEEncodedString ;
- N , i : byte ;
- begin
- N : = 0 ;
- SetLength ( EncodedString , 2 * length ( InMsg ) ) ;
- while length ( InMsg ) > = 1 do
- begin
- MatchFl : = ( length ( InMsg ) > 1 ) and ( InMsg [ 1 ] = InMsg [ 2 ] ) ;
- MatchCount : = 1 ;
- while ( MatchCount < = 126 ) and ( MatchCount < length ( InMsg ) ) and ( ( InMsg [ MatchCount ] = InMsg [ MatchCount + 1 ] ) = MatchFl ) do
- MatchCount : = MatchCount + 1 ;
- if MatchFl then
- begin
- N : = N + 2 ;
- EncodedString [ N - 2 ] : = MatchCount + 128 ;
- EncodedString [ N - 1 ] : = ord ( InMsg [ 1 ] ) ;
- end
- else
- begin
- if MatchCount <> length ( InMsg ) then
- MatchCount : = MatchCount - 1 ;
- N : = N + 1 + MatchCount ;
- EncodedString [ N - 1 - MatchCount ] : = - MatchCount + 128 ;
- for i : = 1 to MatchCount do
- EncodedString [ N - 1 - MatchCount + i ] : = ord ( InMsg [ i ] ) ;
- end ;
- delete ( InMsg , 1 , MatchCount ) ;
- end ;
- SetLength ( EncodedString , N ) ;
- RLEEncode : = EncodedString ;
- end ;
- type
- TRLEEncodedString = array of byte ;
- function RLEDecode ( InMsg : TRLEEncodedString ) : ShortString ;
- var
- RepeatCount : shortint ;
- i , j : word ;
- OutMsg : ShortString ;
- begin
- OutMsg : = '' ;
- i : = 0 ;
- while i < length ( InMsg ) do
- begin
- RepeatCount : = InMsg [ i ] - 128 ;
- i : = i + 1 ;
- if RepeatCount < 0 then
- begin
- RepeatCount : = abs ( RepeatCount ) ;
- for j : = i to i + RepeatCount - 1 do
- OutMsg : = OutMsg + chr ( InMsg [ j ] ) ;
- i : = i + RepeatCount ;
- end
- else
- begin
- for j : = 1 to RepeatCount do
- OutMsg : = OutMsg + chr ( InMsg [ i ] ) ;
- i : = i + 1 ;
- end ;
- end ;
- RLEDecode : = OutMsg ;
- end ;
Вторым методом повышения эффективности алгоритма RLE является использование алгоритмов преобразования информации, которые непосредственно не сжимают данные, но приводят их к виду, более удобному для сжатия. В качестве примера такого алгоритма мы рассмотрим BWT-перестановку, названную по фамилиям изобретателей Burrows-Wheeler transform. Эта перестановка не изменяет сами символы, а изменяет только их порядок в строке, при этом повторяющиеся подстроки после применения перестановки собираются в плотные группы, которые гораздо лучше сжимаются с помощью алгоритма RLE. Прямое BWT преобразование сводится к последовательности следующих шагов:
1. Добавление к исходной строке специального символа конца строки, который нигде более не встречается;
2. Получение всех циклических перестановок исходной строки;
3. Сортировка полученных строк в лексикографическом порядке;
4. Возвращение последнего столбца полученной матрицы.
Реализация данного алгоритма приведена в Листинг 3.
- const
- EOMsg = '|' ;
- function BWTEncode ( InMsg : ShortString ) : ShortString ;
- var
- OutMsg : ShortString ;
- ShiftTable : array of ShortString ;
- LastChar : ANSIChar ;
- N , i : word ;
- begin
- InMsg : = InMsg + EOMsg ;
- N : = length ( InMsg ) ;
- SetLength ( ShiftTable , N + 1 ) ;
- ShiftTable [ 1 ] : = InMsg ;
- for i : = 2 to N do
- begin
- LastChar : = InMsg [ N ] ;
- InMsg : = LastChar + copy ( InMsg , 1 , N - 1 ) ;
- ShiftTable [ i ] : = InMsg ;
- end ;
- Sort ( ShiftTable ) ;
- OutMsg : = '' ;
- for i : = 1 to N do
- OutMsg : = OutMsg + ShiftTable [ i ] [ N ] ;
- BWTEncode : = OutMsg ;
- end ;
Проще всего пояснить это преобразование на конкретном примере. Возьмём строку «АНАНАС» и договоримся, что символом конца строки будет символ «|». Все циклические перестановки этой строки и результат их лексикографической сортировки приведены в Табл. 1.

Реализация обратного преобразования на первый взгляд не представляет сложности, и один из вариантов реализации приведён в Листинг 4.
- const
- EOMsg = '|' ;
- function BWTDecode ( InMsg : ShortString ) : ShortString ;
- var
- OutMsg : ShortString ;
- ShiftTable : array of ShortString ;
- N , i , j : word ;
- begin
- OutMsg : = '' ;
- N : = length ( InMsg ) ;
- SetLength ( ShiftTable , N + 1 ) ;
- for i : = 0 to N do
- ShiftTable [ i ] : = '' ;
- for i : = 1 to N do
- begin
- for j : = 1 to N do
- ShiftTable [ j ] : = InMsg [ j ] + ShiftTable [ j ] ;
- Sort ( ShiftTable ) ;
- end ;
- for i : = 1 to N do
- if ShiftTable [ i ] [ N ] = EOMsg then
- OutMsg : = ShiftTable [ i ] ;
- delete ( OutMsg , N , 1 ) ;
- BWTDecode : = OutMsg ;
- end ;
Но на практике эффективность зависит от выбранного алгоритма сортировки. Тривиальные алгоритмы с квадратичной сложностью, очевидно, крайне негативно скажутся на быстродействии, поэтому рекомендуется использовать эффективные алгоритмы.

После сортировки таблицы, полученной на седьмом шаге, необходимо выбрать из таблицы строку, заканчивающуюся символом «|». Легко заметить, что это строка единственная. Т.о. мы на конкретном примере рассмотрели преобразование BWT.
Подводя итог, можно сказать, что основным плюсом группы алгоритмов RLE является простота и скорость работы (в том числе и скорость декодирования), а главным минусом является неэффективность на неповторяющихся наборах символов. Использование специальных перестановок повышает эффективность алгоритма, но также сильно увеличивает время работы (особенно декодирования).
За счет чего происходит сжатие файлов?
За счет чего происходит сжатие файлов? Посмотрим, какие программы помогают уменьшать объем исходников. Есть не менее десятка специализированных программ. У каждой есть свой набор специальных функций. Производители подобных программ есть как за рубежом, так и в России.
Чаще всего упаковка и распаковка фалов проводится одной программой, но бывает и так, что для каждой операции своя. Есть файлы, которые обладают свойством самораспаковывания. Суть в том, что исполняемый модуль способен к саморазархивации.
Чаще всего при распаковке файлов программы сохраняют его на жесткий диск. Но есть и программы, которые создают упакованный исполняемый модуль. При этом в программном файле сохраняется имя и расширение, он загружается на жесткий диск, распаковывается и после этого начинает работать. После работы можно вернуть его обратно в архив.
Программы архиваторы помогают архивировать файлы, просматривать их, создавать архивы из большого количества томов. Архивные файлы можно протестировать, они позволяют вводить комментарии. В архиве можно хранить несколько версий исходника.
Что даёт сжатие файлов?
Что дает сжатие файлов? Сейчас люди обмениваются большим количеством информации. Информация обновляется постоянно. Старая информация заменяет новую, большинство данных приходится сохранять. Для того чтобы она не занимала много места на устройствах хранения лучше запаковывать файлы в архив. Есть специальные облачные хостинги что это такое, мы уже знаем.
При сжатии нужно руководствоваться тем, что файл сохранит свои исходные показатели по качеству, информативности, цветопередаче и т.д. Сжатие используется, например, при загрузке файлов в социальных сетях, где есть лимит по тяжести загруженных файлов.
Сжатые файлы используются в деловых переписках, особенно если у получателя на корпоративном сервере есть лимит по объему полученной информации в одном письме. Архивирование используется для сохранения памяти на устройствах.
Доброго времени суток.
Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
- Пересылка документов по электронной почте (особенно больших объемов документов с использованием мобильных устройств)
- При публикации документов на сайтах, потребность в экономии трафика
- Экономия дискового пространства в тех случаях, когда замена или добавление средств хранения затруднительно. Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
| Сжатие с потерями |
| Лучшие степени сжатия, при сохранении «достаточно хорошего» качества данных. Применяются в основном для сжатия аналоговых данных — звука, изображений. В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человеческого уха или глаза в большинстве практических применений. |
| Сжатие без потерь |
| Данные восстанавливаются с точностью до бита, что не приводит к каким-либо потерям информации. Однако, сжатие без потерь показывает обычно худшие степени сжатия. |
Итак, перейдем к рассмотрению алгоритмов сжатия без потерь.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon's source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики

Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F =
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.

Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.

Пусть задан некоторый алфавит , состоящий из некоторого (конечного) числа букв. Назовем каждую конечную последовательность символов из этого алфавита (A=a1, a2,… ,an) словом, а число n — длиной этого слова.

Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 B1
a2 B2
…
an Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Пусть слово B имеет вид B=B'B''. Тогда B' называют началом, или префиксом слова B, а B'' — его концом. Это довольно простое определение, но нужно отметить, что для любого слова B, и некое пустое слово ʌ («пробел»), и само слово B, могут считаться и началами и концами.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — < a1, a2, a3, a4>. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
- Объединяем два символа с наименьшими вероятностями (0.11 и 0.15) в псевдосимвол p'.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Объединяем два символа с наименьшей вероятностью (0.24 и 0.26) в псевдосимвол p''.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Наконец, объединяем оставшиеся два символа, и получаем вершину дерева.
Если сделать иллюстрацию этого процесса, получится примерно следующее:

Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).

WinRAR — самый популярный архиватор для Windows, обладающий всеми необходимыми функциями для того, чтобы максимально сжать файл или несколько файлов в один архив. Предлагаем начать именно с него, детально разобрав процесс создания архива для дальнейшего сохранения на съемных носителях или локальном компьютере.
-
Если вы еще не установили WinRAR на свой ПК, сделайте это, перейдя по ссылке выше. После инсталляции элементы управления софтом сразу же будут добавлены в контекстное меню «Проводника», а значит, их можно использовать для выполнения сжатия. Сначала выделите все необходимые файлы, а затем кликните по одному из них правой кнопкой мыши.










Если после сжатия оказалось, что объем архива вас не устраивает, попробуйте использовать для этой же процедуры одну из альтернативных программ, о которых мы поговорим в следующих способах. Там задействованы другие алгоритмы сжатия, настроенные на более интенсивную экономию места.
Кодирование с помощью деревьев Шеннона-Фано
Алгоритм Шеннона-Фано — один из первых разработанных алгоритмов сжатия. В основе алгоритма лежит идея представления более частых символов с помощью более коротких кодов. При этом коды, полученные с помощью алгоритма Шеннона-Фано, обладают свойством префиксности: т.е. ни один код не является началом никакого другого кода. Свойство префиксности гарантирует, что кодирование будет взаимно-однозначным. Алгоритм построения кодов Шеннона-Фано представлен ниже:
1. Разбить алфавит на две части, суммарные вероятности символов в которых максимально близки друг к другу.
2. В префиксный код первой части символов добавить 0, в префиксный код второй части символов добавить 1.
3. Для каждой части (в которой не менее двух символов) рекурсивно выполнить шаги 1-3.
Несмотря на сравнительную простоту, алгоритм Шеннона-Фано не лишён недостатков, самым существенным из которых является неоптимальность кодирования. Хоть разбиение на каждом шаге и является оптимальным, алгоритм не гарантирует оптимального результата в целом. Рассмотрим, например, следующую строку: «ААААБВГДЕЖ». Соответствующее дерево Шеннона-Фано и коды, полученные на его основе, представлены на Рис. 1:

От чего зависит степень сжатия файлов?
От чего зависит степень сжатия файлов? Зависит данный показатель от множества факторов. Например, программы, которая используется для уменьшения, метод, тип исходника. Самая большая степень сжатия у фотографий, текстовых файлов. Самая меньшая степень сжатия – у загрузочных модулей и программ. Архивы практически не поддаются сжатию.
Степень сжатия – это основной параметр архивации. Есть специальная формула, которая характеризует степень сжатия. Есть специальные программы, которые помогают создавать архивы. Такие программы позволяют избавиться от лишней информации исходника:
- упрощение кодов;
- исключение постоянных битов;
- исключение повторяющихся символов.
Сжать можно сразу несколько файлов одновременно. Архив – это файл, который может содержать большое количество файлов. Вся информация, которая касается файлов тоже храниться в архиве. Для формирования архивов можно обратиться за помощью к специалистам IT и продвижения SEO, они всегда смогут помочь.
Сжатие с потерями vs сжатие без потерь
Теперь, когда мы рассмотрели обе формы сжатия файлов, может возникнуть вопрос, когда и какую следует использовать. Здесь всё зависит от того, для чего вы используете файлы.
Скажем, вы только что откопали свою старую коллекцию компакт-дисков и хотите оцифровать её. Когда вы копируете свои компакт-диски, имеет смысл использовать формат FLAC, формат без потерь. Это позволяет получить мастер-копию на компьютере, которая обладает тем же качеством звука, что и оригинальный компакт-диск.
Позже вы, возможно, захотите загрузить музыку на телефон или старый MP3-плеер. Здесь не так важно, чтобы музыка была в идеальном качестве, поэтому вы можете конвертировать файлы FLAC в MP3. Это даст вам аудиофайл, который по-прежнему достаточно хорош для прослушивания, но не занимает много места на мобильном устройстве. Качество MP3, преобразованного из FLAC, будет таким же, как если бы вы создали сжатый MP3 с оригинального CD.
Тип данных, представленных в файле, также может определять, какой вид сжатия подходит больше. В PNG используется сжатие без потерь, поэтому его хорошо использовать для изображений, в которых много однотонного пространства. Например, для скриншотов. Но PNG занимает гораздо больше места, когда картинка состоит из смеси множества цветов, как в случае с фотографиями. В этом случае с точки зрения размера файлов лучше использовать JPEG.
Словарное сжатие (алгоритмы LZ)
Группа словарных алгоритмов, в отличие от алгоритмов группы RLE, кодирует не количество повторов символов, а встречавшиеся ранее последовательности символов. Во время работы рассматриваемых алгоритмов динамически создаётся таблица со списком уже встречавшихся последовательностей и соответствующих им кодов. Эту таблицу часто называют словарём, а соответствующую группу алгоритмов называют словарными.
Например, только что инициализированный словарь для фразы «КУКУШКАКУКУШОНКУКУПИЛАКАПЮШОН» приведён в Табл. 3:


При описании алгоритма намеренно было опущено описание ситуации, когда словарь заполняется полностью. В зависимости от варианта алгоритма возможно различное поведение: полная или частичная очистка словаря, прекращение заполнение словаря или расширение словаря с соответствующим увеличением разрядности кода. Каждый из этих подходов имеет определённые недостатки. Например, прекращение пополнения словаря может привести к ситуации, когда в словаре хранятся последовательности, встречающиеся в начале сжимаемой строки, но не встречающиеся в дальнейшем. В то же время очистка словаря может привести к удалению частых последовательностей. Большинство используемых реализаций при заполнении словаря начинают отслеживать степень сжатия, и при её снижении ниже определённого уровня происходит перестройка словаря. Далее будет рассмотрена простейшая реализация, прекращающая пополнение словаря при его заполнении.
Для начала определим словарь как запись, хранящую не только встречавшиеся подстроки, но и количество хранящихся в словаре подстрок:
- type
- TDictionary = record
- WordCount : byte ;
- Words : array of string ;
- end ;
Встречавшиеся ранее подпоследовательности хранятся в массиве Words, а их кодом являются номера подпоследовательностей в этом массиве.
Также определим функции поиска в словаре и добавления в словарь:
- const
- MAX_DICT_LENGTH = 256 ;
- function FindInDict ( D : TDictionary ; str : ShortString ) : integer ;
- var
- r : integer ;
- i : integer ;
- fl : boolean ;
- begin
- r : = - 1 ;
- if D . WordCount > 0 then
- begin
- i : = D . WordCount ;
- fl : = false ;
- while ( not fl ) and ( i > = 0 ) do
- begin
- i : = i - 1 ;
- fl : = D . Words [ i ] = str ;
- end ;
- end ;
- if fl then
- r : = i ;
- FindInDict : = r ;
- end ;
- procedure AddToDict ( var D : TDictionary ; str : ShortString ) ;
- begin
- if D . WordCount < MAX_DICT_LENGTH then
- begin
- D . WordCount : = D . WordCount + 1 ;
- SetLength ( D . Words , D . WordCount ) ;
- D . Words [ D . WordCount - 1 ] : = str ;
- end ;
- end ;
Используя эти функции, процесс кодирования по описанному алгоритму можно реализовать следующим образом:
- function LZWEncode ( InMsg : ShortString ) : TEncodedString ;
- var
- OutMsg : TEncodedString ;
- tmpstr : ShortString ;
- D : TDictionary ;
- i , N : byte ;
- begin
- SetLength ( OutMsg , length ( InMsg ) ) ;
- N : = 0 ;
- InitDict ( D ) ;
- while length ( InMsg ) > 0 do
- begin
- tmpstr : = InMsg [ 1 ] ;
- while ( FindInDict ( D , tmpstr ) > = 0 ) and ( length ( InMsg ) > length ( tmpstr ) ) do
- tmpstr : = tmpstr + InMsg [ length ( tmpstr ) + 1 ] ;
- if FindInDict ( D , tmpstr ) < 0 then
- delete ( tmpstr , length ( tmpstr ) , 1 ) ;
- OutMsg [ N ] : = FindInDict ( D , tmpstr ) ;
- N : = N + 1 ;
- delete ( InMsg , 1 , length ( tmpstr ) ) ;
- if length ( InMsg ) > 0 then
- AddToDict ( D , tmpstr + InMsg [ 1 ] ) ;
- end ;
- SetLength ( OutMsg , N ) ;
- LZWEncode : = OutMsg ;
- end ;
Результатом кодирования будут номера слов в словаре.
Процесс декодирования сводится к прямой расшифровке кодов, при этом нет необходимости передавать созданный словарь, достаточно, чтобы при декодировании словарь был инициализирован так же, как и при кодировании. Тогда словарь будет полностью восстановлен непосредственно в процессе декодирования путём конкатенации предыдущей подпоследовательности и текущего символа.
Единственная проблема возможна в следующей ситуации: когда необходимо декодировать подпоследовательность, которой ещё нет в словаре. Легко убедиться, что это возможно только в случае, когда необходимо извлечь подстроку, которая должна быть добавлена на текущем шаге. А это значит, что подстрока удовлетворяет шаблону cSc, т.е. начинается и заканчивается одним и тем же символом. При этом cS – это подстрока, добавленная на предыдущем шаге. Рассмотренная ситуация – единственная, когда необходимо декодировать ещё не добавленную строку. Учитывая вышесказанное, можно предложить следующий вариант декодирования сжатой строки:
- function LZWDecode ( InMsg : TEncodedString ) : ShortString ;
- var
- D : TDictionary ;
- OutMsg , tmpstr : ShortString ;
- i : byte ;
- begin
- OutMsg : = '' ;
- tmpstr : = '' ;
- InitDict ( D ) ;
- for i : = 0 to length ( InMsg ) - 1 do
- begin
- if InMsg [ i ] > = D . WordCount then
- tmpstr : = D . Words [ InMsg [ i - 1 ] ] + D . Words [ InMsg [ i - 1 ] ] [ 1 ]
- else
- tmpstr : = D . Words [ InMsg [ i ] ] ;
- OutMsg : = OutMsg + tmpstr ;
- if i > 0 then
- AddToDict ( D , D . Words [ InMsg [ i - 1 ] ] + tmpstr [ 1 ] ) ;
- end ;
- LZWDecode : = OutMsg ;
- end ;
К плюсам словарных алгоритмов относится их большая по сравнению с RLE эффективность сжатия. Тем не менее надо понимать, что реальное использование этих алгоритмов сопряжено с некоторыми трудностями реализации.
Что такое сжатие?
Сжатие файла — это уменьшение его размера при сохранении исходных данных. В этом случае файл занимает меньше места на устройстве, что также облегчает его хранение и передачу через интернет или другим способом. Важно отметить, что сжатие не безгранично и обычно делится на два основных типа: с потерями и без потерь. Рассмотрим каждый из них по отдельности.
Проблемы во время сжатия файлов
Бесполезно конвертировать формат с потерями в формат без потерь. Это пустая трата пространства. Скажем, у вас есть MP3-файл весом в 3 МБ. Преобразование его в FLAC может привести к увеличению размера до 30 МБ. Но эти 30 МБ содержат только те звуки, которые имел уже сжатый MP3. Качество звука от этого не улучшится, но объём станет больше.
Также стоит иметь в виду, что преобразовывая один формат с потерями в аналогичный, вы получаете дальнейшее снижение качества. Каждый раз, когда вы применяете сжатие с потерями, вы теряете больше деталей. Это становится всё более и более заметно, пока файл по существу не будет разрушен. Помните также, что форматы с потерями удаляют некоторые данные и их невозможно восстановить.
Кодирование с помощью деревьев Хаффмана

Заключение
Мы рассмотрели как сжатие файлов с потерями, так и без потерь, чтобы увидеть, как они работают. Теперь вы знаете, как можно уменьшить размер файла и как выбрать лучший способ для этого.
Алгоритмы, которые определяют, какие данные выбрасываются в методах с потерями и как лучше хранить избыточные данные при сжатии без потерь, намного сложнее, чем описано здесь. На эту тему можно почитать больше информации здесь, если вам интересно.
В данной статье мы узнаем, что такое сжатие файлов, для чего оно используется и как позволяет оптимизировать деятельность. Посмотрим, какие факторы влияют на сжатие файлов и какую формулу можно использовать для определения его степени. Рассмотрим, какие можно применять программы для создания архивов.
Где используется сжатие с потерями
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства медиафайлов. Это крайне важно для таких компаний как Spotify и Netflix, которые постоянно транслируют большие объёмы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной.
Сжатие без потерь
Сжатие без потерь позволяет уменьшить размер файла так, чтобы в дальнейшем можно было восстановить первоначальное качество. В отличие от сжатия с потерями, этот способ не удаляет никакую информацию. Рассмотрим простой пример. На картинке ниже стопка из 10 кирпичей: два синих, пять жёлтых и три красных.

Вместо того чтобы показывать все 10 блоков, мы можем удалить все кирпичи одного цвета, кроме одного. Используя цифры, чтобы показать, сколько кирпичей каждого цвета было, мы представляем те же данные используя гораздо меньше кирпичей — три вместо десяти.
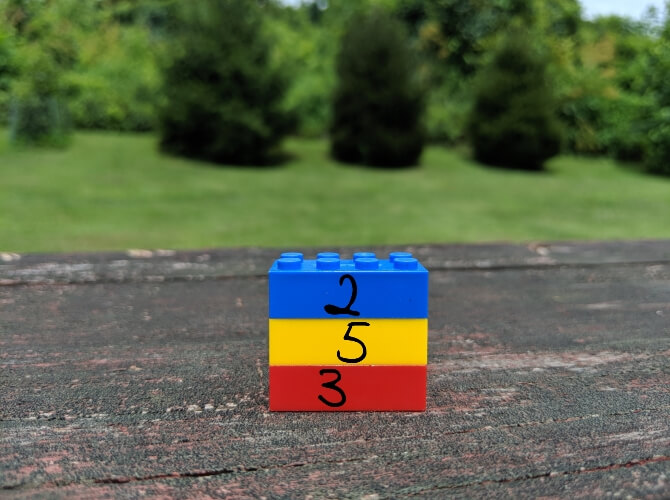
Это простая иллюстрация того, как осуществить сжатие без потерь. Та же информация сохраняется более эффективным способом. Рассмотрим реальный файл: mmmmmuuuuuuuoooooooooooo. Его можно сжать до гораздо более короткой формы: m5u7o12. Это позволяет использовать 7 символов вместо 24 для представления одних и тех же данных.
Сжатие с потерями
Такой способ уменьшает размер файла, удаляя ненужные биты информации. Чаще всего встречается в форматах изображений, видео и аудио, где нет необходимости в идеальном представлении исходного медиа. MP3 и JPEG — два популярных примера. Но сжатие с потерями не совсем подходит для файлов, где важна вся информация. Например, в текстовом файле или электронной таблице оно приведёт к искажённому выводу.
MP3 содержит не всю аудиоинформацию из оригинальной записи. Этот формат исключает некоторые звуки, которые люди не слышат. Вы заметите, что они пропали, только на профессиональном оборудовании с очень высоким качеством звука, поэтому для обычного использования удаление этой информации позволит уменьшить размер файла практически без недостатков.

Аналогично файлы JPEG удаляют некритичные части изображений. Например, в изображении с голубым небом сжатие JPEG может изменить все пиксели на один или два оттенка синего вместо десятков.
Чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, замечали такое, слушая некачественную музыку в формате MP3, загруженную на YouTube. Например, сравните музыкальный трек высокого качества с сильно сжатой версией той же песни.
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, у вас есть огромный файл с исходным (RAW) изображением. Целесообразно сохранить это качество для печати изображения на большом баннере, но загружать исходный файл в Facebook будет бессмысленно. Картинка содержит множество данных, не заметных при просмотре в социальных сетях. Сжатие картинки в высококачественный JPEG исключает некоторую информацию, но изображение выглядит почти как оригинал.
При сохранении в формате с потерями, вы зачастую можете установить уровень качества. Например, у многих графических редакторов есть ползунок для выбора качества JPEG от 0 до 100. Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла с незначительной визуальной разницей. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Посмотрите на этот пример.
Оригинальное изображение, загруженное с Pixabay в формате JPEG. 874 КБ:

Результат сохранения в формате JPEG с 50-процентным качеством. Выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. 310 КБ:

Исходное изображение, сохранённое в формате JPEG с 10-процентным качеством. Выглядит ужасно. 100 КБ:

Арифметическое кодирование

При декодировании необходимо выполнить аналогичную последовательность действий, только на каждом шаге необходимо дополнительно определять, какой именно символ был закодирован.
Очевидным плюсом арифметического кодирования является его эффективность, а основным (за исключением патентных ограничений) минусом – чрезвычайно высокая сложность процессов кодирования и декодирования.
Сжатие файлов позволяет быстрее передавать, получать и хранить большие файлы. Оно используется повсеместно и наверняка хорошая вам знакомо: самые популярные расширения сжатых файлов — ZIP, JPEG и MP3. В этой статье кратко рассмотрим основные виды сжатия файлов и принципы их работы.
Способ 2: 7-Zip
В архиваторе под названием 7-Zip присутствуют практически те же инструменты сжатия, о которых мы говорили при разборе предыдущей программы, однако здесь разработчиками добавлен еще один вариант, называющийся «Ультра» — его мы и предлагаем использовать при дальнейшей настройке.
-
Управлять 7-Zip для добавления архива проще всего через файловый менеджер, поэтому сначала советуем запустить его, выполнив поиск приложения через «Пуск».










Где используется сжатие без потерь
ZIP-файлы — популярный пример сжатия без потерь. Хранить информацию в виде ZIP-файлов более эффективно, при этом когда вы распаковываете архив, там присутствует вся оригинальная информация. Это актуально для исполняемых файлов, так как после сжатия с потерями распакованная версия будет повреждена и непригодна для использования.
Другие распространённые форматы без потерь — PNG для изображений и FLAC для аудио. Форматы видео без потерь встречаются редко, потому что они занимают много места.
Кодирование с помощью деревьев секущих функций
Кодирование с помощью секущих функций – разработанный авторами алгоритм, позволяющий получать префиксные коды. В основе алгоритма лежит идея построения дерева, каждый узел которого содержит секущую функцию. Чтобы подробнее описать алгоритм, необходимо ввести несколько определений.
Слово – упорядоченная последовательность из m бит (число m называют разрядностью слова).
Литерал секущей – пара вида разряд-значение разряда. Например, литерал (4,1) означает, что 4 бит слова должен быть равен 1. Если условие литерала выполняется, то литерал считается истинным, в противном случае — ложным.
k-разрядной секущей называют множество из k литералов. Если все литералы истинны, то и сама секущая функция истинная, в противном случае она ложная.
Дерево строится так, чтобы каждый узел делил алфавит на максимально близкие части. На Рис. 3 показан пример дерева секущих:

Дерево секущих функций в общем случае не гарантирует оптимального кодирования, но зато обеспечивает крайне высокую скорость работы за счёт простоты операции в узлах.
От чего зависит сжатие файла?
От чего зависит сжатие файла? Это одно из самых простых действий, которое может сделать пользователь, для того чтобы уменьшить размер файла, что такое сжатие изображения и как настроить, мы уже знаем. Сжатие используется для:
- экономии пространства на носителях;
- при отправке почты;
- при использовании файлов, где есть лимитирование объемов информации.
В целом, сжатие данных это алгоритм, который позволяет избавиться от избытка исходных данных, которые содержаться в исходном файле. Есть такое понятие, как сжатый атрибут. Это один из методов сжатия файла. Такое сжатие помогает сохранить место в хранилище.
Для осуществления данного способа есть несколько способов. В персональных компьютерах есть автоматическая опция для показа сжатых файлов. При его использовании данные исходного файла не утрачиваются, и он воспроизводится как обычный файл.
Распаковка файла осуществляется за счет возможностей Windows. Но при закрытии файл сжимается снова. Это значительная экономия памяти. Лучше сжимать файлы, которые практически не используются.
Размер памяти современных ПК позволяет хранить большой объем информации, поэтому нет необходимости в компрессии, об этом подробнее можно на курсах SEO с нуля можно узнать.
Файлы, которыми нужно пользоваться часто лучше не сжимать, т.к. распаковка потребует дополнительной вычислительной мощности. Использовать сжатие можно с помощью проводника и командной строки.
Читайте также: