
Что такое схема в oracle
Use the CREATE SCHEMA statement to create multiple tables and views and perform multiple grants in your own schema in a single transaction.
To execute a CREATE SCHEMA statement, Oracle Database executes each included statement. If all statements execute successfully, then the database commits the transaction. If any statement results in an error, then the database rolls back all the statements.
This statement does not actually create a schema. Oracle Database automatically creates a schema when you create a user (see CREATE USER). This statement lets you populate your schema with tables and views and grant privileges on those objects without having to issue multiple SQL statements in multiple transactions.
The CREATE SCHEMA statement can include CREATE TABLE , CREATE VIEW , and GRANT statements. To issue a CREATE SCHEMA statement, you must have the privileges necessary to issue the included statements.
Specify the name of the schema. The schema name must be the same as your Oracle Database username.
Specify a CREATE TABLE statement to be issued as part of this CREATE SCHEMA statement. Do not end this statement with a semicolon (or other terminator character).
Specify a CREATE VIEW statement to be issued as part of this CREATE SCHEMA statement. Do not end this statement with a semicolon (or other terminator character).
Specify a GRANT statement to be issued as part of this CREATE SCHEMA statement. Do not end this statement with a semicolon (or other terminator character). You can use this clause to grant object privileges on objects you own to other users. You can also grant system privileges to other users if you were granted those privileges WITH ADMIN OPTION .
The CREATE SCHEMA statement supports the syntax of these statements only as defined by standard SQL, rather than the complete syntax supported by Oracle Database.
The order in which you list the CREATE TABLE , CREATE VIEW , and GRANT statements is unimportant. The statements within a CREATE SCHEMA statement can reference existing objects or objects you create in other statements within the same CREATE SCHEMA statement.
Restriction on Granting Privileges to a Schema
The syntax of the parallel_clause is allowed for a CREATE TABLE statement in CREATE SCHEMA , but parallelism is not used when creating the objects.
The parallel_clause in the CREATE TABLE documentation
Creating a Schema: Example
The following statement creates a schema named oe for the sample order entry user oe , creates the table new_product , creates the view new_product_view , and grants the SELECT object privilege on new_product_view to the sample human resources user hr .

В базе данных Oracle схема (schema) определяется как коллекция логических структур данных, или объектов схемы, хотя в основном используется в качестве синонима пользователя базы данных (в частности, владельца приложения), который владеет схемой, относящейся к определенному приложению. Таким образом, схема accounting (бухгалтерия) внутри базы данных компании должна владеть всеми таблицами и кодом, относящимся к бухгалтерскому отделу. В дополнение к таблицам, схема включает в себя и другие объекты базы, такие как процедуры и функции PL/SQL, представления, последовательности, синонимы и кластеры. Подобное логическое отделение объектов внутри базы данных позволяет существенно облегчить задачу управления и защиты базы данных Oracle Database.
Хотя администратор баз данных может использовать оператор CREATE SCHEMA для заполнения схемы объектами базы данных, наподобие таблиц и представлений, гораздо чаще владелец приложения создает объекты базы, и его называют владельцем схемы . Пользователь, который создает объекты, владеет такими объектами, как таблицы, представления, процедуры, функции и триггеры. Владелец объекта должен явно выдать права доступа другим пользователям, наподобие прав на SELECT или UPDATE, чтобы пользователи могли работать с этими объектами.
Базы данных и экземпляры Oracle
Многие пользователи Oracle Database употребляют термины экземпляр и база данных как синонимы. На самом деле это разные (хотя и взаимосвязанные) вещи. Различие существенно, так как проливает свет на архитектуру Oracle.
В Oracle термином база данных описывается физическое хранилище информации, а термином экземпляр – программное обеспечение, работающее на сервере и предоставляющее доступ к информации в базе данных Oracle Database. Экземпляр исполняется на конкретном компьютере или сервере; база данных хранится на дисках, подключенных к этому серверу. Эта взаимосвязь изображена на рисунке 1 ниже:
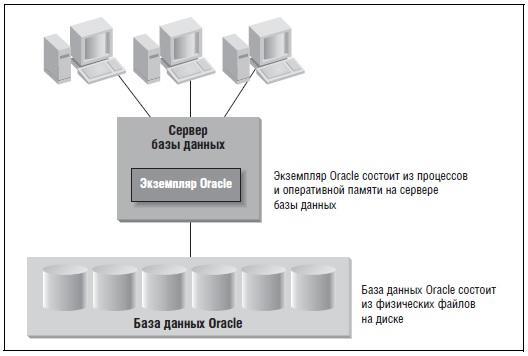
Рис. 1. Экземпляр и база данных
База данных Oracle Database – физическая сущность: она состоит из файлов, хранящихся на дисках. Экземпляр – сущность логическая: он состоит из структур в оперативной памяти и процессов, работающих на сервере.
Например, Oracle использует область разделяемой памяти System Global Area (SGA, системная глобальная область) и области памяти в каждом процессе – Program Global Area (PGA, программная глобальная область). Экземпляр может быть частью одной и только одной базы данных. Напротив, с одной базой данных может быть ассоциировано несколько экземпляров. Время жизни экземпляров ограничено, тогда как база данных при должном обслуживании может существовать вечно.
Пользователи не имеют прямого доступа к информации, хранящейся в базе данных Oracle; они должны запрашивать информацию у экземпляра Oracle.
В реальном мире есть хорошая аналогия экземплярам и базам данных. Можно считать экземпляр мостом к базе данных, а саму ее – островом. Транспорт попадает на остров и уходит с него по мосту. Если мост перекрыт, то остров на месте, но транспорту туда не попасть. В терминологии Oracle, если экземпляр запущен, то данные могут попадать в базу и уходить из нее. Физическое состояние базы данных при этом изменяется. Если же экземпляр остановлен, то пользователи не могут обращаться к базе данных, пусть даже физически она никуда не делась. База данных в этом случае статична, никаких изменений в ней не происходит. Экземпляр снова запущен – и данные тут как тут.
Определяемые пользователем типы объектов
Oracle Database 11g и 12c — объектно-реляционная база данных, и как таковая, позволяет пользователям определять несколько типов объектов данных, которых нет среди стандартных реляционных типов данных. Эти определяемые пользователем объекты включают перечисленные ниже.
- Объектные типы. Эти сложные типы являются абстракциями сущностей реального мира.
- Типы массивов. Эти типы используются для создания упорядоченных множеств элементов данных одного и того же типа.
- Табличные типы. Эти типы используются для создания неупорядоченных наборов элементов данных одного и того же типа.
- Схемы XML. Это новый объектный тип, используемый для создания типов и элементов хранения документов XML на основе схемы XML.
В приложении приведены примеры создания различного рода пользовательских объектных типов.
Вдобавок, владелец схемы может также создавать синонимы, которые служат псевдонимами различных объектов для других пользователей базы. Синонимы, которые будут описаны далее в моих статьях, служат множеству целей, включая маскировку принадлежности объектов данных и упрощение операторов SQL для пользователей, за счет исключения необходимости для них специфицировать имя владельца схемы при каждом обращении к объекту данных, не принадлежащему им.
Существуют два основных способа создания схемы в базе данных Oracle. Более распространенный способ состоит в подключении от имени владельца схемы и создании всех таблиц, индексов и прочих объектов, которые планируется включить в схему. Поскольку все объекты создаются владельцем схемы, они автоматически становятся частью этой схемы.
Второй способ создания схемы предусматривает ее явное создание с помощью оператора CREATE SCHEMA. Этот оператор позволяет создать множество таблиц и представлений, а также выдать пользователям привилегии доступа к ним, и все это в единственном операторе SQL.

Данная статья - это обзор концепций и структур, относящихся к ядру СУБД Oracle Database. Разобравшись в архитектуре сервера Oracle, вы заложите фундамент для понимания остальных обширных средств, предоставляемых базой данных Oracle. СУБД Oracle Database состоит из физических и логических компонентов.
Секционированные индексы
Секционированные индексы используются для индексации секционированных таблиц. Oracle предлагает два типа индексов для таких таблиц: локальные и глобальные.
Существенное различие между ними заключается в том, что локальные индексы основаны на разделах таблицы, по которой они созданы. Если таблица секционирована на 12 разделов по диапазонам дат, то индексы также будут распределены по тем же 12 разделам. Другими словами, между разделами индексов и разделами таблиц существует соответствие «один к одному». Такого соответствия нет между глобальными индексами и разделами таблицы, потому что глобальные индексы секционируются независимо от базовых таблиц.
В следующих разделах будут раскрыт важные различия между управлением глобального секционированными индексами и локально секционированными индексами.
Локальные индексы
Локально секционированные индексы, в отличие от глобально секционированных индексов, имею отношение «один к одному» с разделами таблицы. Локально секционированные индексы можно создавать в соответствии с разделами и даже подразделами. База данных конструирует индекс таким образом, чтобы он был секционирован так же, как и его таблица. При каждой модификации раздела таблицы база автоматически сопровождает это соответствующей модификацией раздела индекса. Это, наверное, самое большое преимущество использования локально секционированных индексов – Oracle автоматически перестраивает их всегда, когда уничтожается раздел или над ним выполняется какая-то другая операция DDL.
Ниже приведен простой пример создания локально секционированного индекса на секционированной таблице:
Табличные пространства
Любые данные, хранящиеся в базе Oracle, должны находиться в каком-то табличном пространстве. Табличное пространство (tablespace) – это логическая структура; нельзя попросить операционную систему показать вам табличное пространство. Каждое табличное пространство состоит из физических структур, называемых файлами данных (data files). В одном табличном пространстве может быть один или несколько файлов данных, тогда как каждый файл данных принадлежит ровно одному табличному пространству. При создании таблицы можно указать, в какое табличное пространство ее поместить. Тогда Oracle найдет для нее место в одном из файлов данных, составляющих указанное табличное пространство.
На рисунке 2 показано соотношение между табличными пространствами и файлами данных. Здесь мы видим два табличных пространства в базе данных Oracle.
При создании новой таблицы ее можно поместить в табличное пространство DATA1 или DATA2. Физически таблица окажется в одном из файлов данных, составляющих указанное табличное пространство.
Начиная с версии Oracle Database 10g Release 2 для всех типов таблиц по умолчанию подразумеваются локально управляемые табличные пространства. В таком табличном пространстве можно создавать большие файлы, то есть при работе в 64-разрядных системах задействуется возможность создавать сверхбольшие файлы.
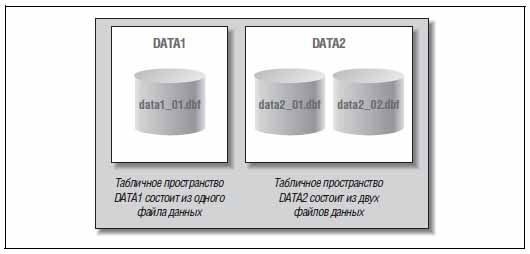
Рис. 2. Табличные пространства и файлы данных Oracle
В Oracle9i появился механизм файлов, управляемых Oracle (Oracle Managed Files, OMF), позволяющий автоматически создавать, именовать и, если понадобится, удалять все файлы, составляющие базу данных. OMF упрощает обслуживание базы данных, поскольку не нужно помнить имена всех составляющих ее файлов. К тому же не возникают проблемы из-за ошибок человека, ответственного за именование файлов. Начиная с версии Oracle Database 10g сочетание OMF и табличных пространств с большими файлами делает работу с файлами данных совершенно прозрачной.
Максимальное количество файлов данных в базе Oracle - 64 000. Поскольку табличное пространство с большими файлами может содержать файл, который в 1024 раза больше файла в табличном пространстве с малыми файлами, а размер блока в табличном пространстве с большими файлами для 64-разрядных операционных систем составляет 32 Кбайт, общий размер базы данных Oracle может достигать 8 экзабайт (1 экзабайт = 1 000 000 терабайт) . Табличные пространства с большими файлами предназначены для использования совместно с подсистемой автоматического управления хранением Automatic Storage Management (ASM), иными менеджерами логических томов, поддерживающими расслоение, и RAID-массивами .
Индексы с реверсированным ключом
Индексы с реверсированным ключом – это, по сути, то же самое, что и индексы B-деревьев, за исключением того, что байты данных ключевого столбца при индексации меняют порядок на противоположный. Порядок столбцов остается нетронутым, меняется только порядок байтов. Самое большое преимущество применения индексов с реверсивным ключом состоит в том, что они исключают неприятные последствия упорядоченной вставки значений в индекс. Вот как создается индекс с реверсированным ключом:
При использовании индекса с реверсированным ключом базы данных не сохраняет ключи индекса друг за другом в лексикографическом порядке. Таким образом, когда в запросе присутствует предикат неравенства, ответ получается медленнее, поскольку база данных вынуждена выполнять полное сканирование таблицы. При индексе с реверсированным ключом база данных не может запустить запрос по диапазону ключа индекса.
Битовые индексы (bitmap indexes)
Битовые индексы используют битовые карты для указания значения индексированного столбца. Это идеальный индекс для столбца с низкой кардинальностью (число уникальных записей в таблице мало) при при большом размере таблицы. Эти индексы обычно не годятся для таблиц с интенсивным обновлением, но хорошо подходят для приложений хранилищ данных.
Битовые индексы состоят из битового потока (единиц и нулей) для каждого столбца индекса. Битовые индексы очень компактны по сравнению с нормальными индексами на основе B-деревьев.
| Индексы B-деревьев | Битовые индексы |
| Хороши для данных с высокой кардинальностью | Хороши для данных с низкой кардинальностью |
| Хороши для баз данных OLTP | Хороши для приложений хранилищ данных OLAP |
| Занимают много места | Используют, относительно мало места |
| Легко обновляются | Трудно обновляются |
Для создания битового индекса используется оператор
Иногда можно наблюдать значительное повышение производительности при замене обычных индексов B-дерева на битовые в некоторых очень крупных таблицах. Однако каждый элемент битового индекса открывает огромное количество строк в таблице, так что когда данные обновляются,вставляются или удаляются из таблицы, то необходимые обновления битового индекса очень велики., и сам индекс может существенно увеличиться в размере. Единственный способ обойти это увеличение размера индекса с последующим падением производительности заключается в регулярной его перестройке. Битовый индекс – не слишком разумная альтернатива для таблиц, подвергающихся большому количеству вставок, удалений и обновлений.
Создание индекса
Индекс создается с помощью оператора CREATE INDEX
По умолчанию Oracle допускает дублирование значения в столбцах индекса, которые также называются ключевыми столбцами. Однако можно специфицировать уникальный индекс, что исключит дублирование значений столбца в нескольких строках.
Для создания уникального индекса служит оператор CREATE UNIQUE INDEX.
Схемы индексации Oracle
Oracle предлагает несколько схем индексации, соответствующих требованиям различных типов приложений. На фазе проектирования после тщательного анализа конкретных требований приложения, необходимо выбрать правильный тип индекса.
Специальные типы индексов
Нормальный или типовой индекс, который создается в базе данных, называется индексом кучи (heap index), или неупорядоченным индексом. Oracle также предоставляет несколько специальных типов индексов для специфических нужд.
Индексы со сжатым ключом
Сэкономить пространство хранения индекса вместе с повышением производительности можно за счет создания индекса со сжатым ключом. Всякий раз, когда индексируемый ключ имеет повторяющийся компонент, или же создается уникальный многостолбцовый индекс, получается выигрыш от использования сжатия ключа. Вот пример:
Приведенный выше оператор сжимает все дублированные вхождения индексированного ключа в листовом блоке индекса (на уровне 1).
Руководство по созданию индексов
Хотя хорошо известно, что индексы повышают производительность базы данных, следует знать, как их заставить работать должным образом. Добавление ненужных или неподходящих индексов к таблице может даже привести к снижению производительности. Ниже предоставлены некоторые рекомендации по созданию эффективных индексов в базе данных Oracle.
- Индекс имеет смысл, если нужно обеспечить доступ одновременно не более чем к 4-5% данных таблицы. Альтернативной использования индекса для доступа к данным строки является полное последовательное чтение таблицы от начала до конца, что называется полным сканированием таблицы. Полное сканирование таблицы больше подходит для запросов, которые требуют извлечения большего процента данных таблицы. Помните, что применение индексов для извлечения строк требует двух операций чтения: индекса и затем таблицы.
- Избегайте создания индексов для сравнительно небольших таблиц. Для таких таблиц больше подходит полное сканирование. В случае маленьких таблиц нет необходимости в хранении данных и таблиц, и индексов.
- Создавайте первичные ключи для всех таблиц. При назначении столбца в качестве первичного колюча Oracle автоматически создаст индекс по этому столбцу.
- Индексируйте столбцы, участвующие в многотабличных операциях соединения.
- Индексируйте столбцы, которые часто используются в конструкциях WHERE.
- Индексируйте столбцы, участвующие в операциях ORDER BY и GROUP BY или других операциях, таких как UNION и DISTINCT, включающих сортировку. Поскольку индексы уже отсортированы, объем работы по выполнению необходимой сортировки данных для упомянутых операций будет существенно сокращен.
- Столбцы, стоящие из длинно-символьных строк, обычно плохие кандидаты на индексацию.
- Столбцы, которые часто обновляются, в идеале не должны быть индексированы из-за связанных с этим накладных расходов.
- Индексируйте таблицы в которых мало строк имеют одинаковые значения.
- Сохраняйте количество индексов небольшим.
- Составные индексы могут понадобиться там, где одностолбцовые значения сами по себе не уникальны. В составных индексах первым столбцом ключа должен быть столбец в котором количество строк с одинаковым значением минимально.
Всегда помните золотое правило индексации таблиц: индекс таблицы должен быть основан на типах запросов, которые будут выполняться над столбцами этой таблицы. На таблице можно создавать более одного индекса: например, можно создать индекс на столбце X, или столбце Y, или обоих сразу, а также один составной индекс на обоих столбцах. Принимая правильное решение относительно того, какие индексы следует создавать, подумайте о наиболее часто используемых типах запросов данных таблицы.
Глобальные индексы
Глобальные индексы на секционированных таблицах могут быть как секционированными, так и несекционированными. Глобальные несекционированные индексы подобны обычным индексам Oracle для несекционированных таблиц. Для создания таких индексов применяется обычный синтаксис CREATE INDEX.
Ниже приведен пример глобального индекса на таблице ticket_sales:
Обратите внимание, что управление глобально секционированными индексами требует серьезных усилий. Всякий раз, когда происходит какое-т о действие DDL над секционированной таблицей, ее глобальные индексы требуют перестройки. Действия DDL над лежащей в основе таблице помечают глобальные индексы как недействительные. По умолчанию любая операция обслуживания секционированной таблицы делает недействительными глобальные индексы.
Давайте в качестве примера воспользуемся таблицей ticket_sales, чтобы разобраться, почему это так. Предположим, что вы ежеквартально уничтожаете самый старый раздел, чтобы освободить место для нового раздела, в который поступят данные за новый квартал. Когда уничтожается раздел, относящийся к таблице ticket_sales, глобальные индексы могут стать недействительными, потому что часть данных, на которые они указывают, перестают существовать. Чтобы предотвратить такое объявление недействительным индекса из-за уничтожения раздела, необходимо использовать опцию UPDATE GLOBAL INDEXES вместе с оператором DROP PARTITION:
Если не включить оператор UPDATE GLOBAL INDEXES, то все глобальные индексы станут недействительными. Опцию UPDATE GLOBAL INDEXES можно также использовать при добавлении, объединении, обмене, слиянии, перемещении, разделении или усечении секционированных таблиц. Разумеется, с помощью ALTER INDEX..REBUILD можно перестраивать любой индекс, который становится недействительным, но эта опция также требует дополнительных затрат времени и обслуживания.
При небольшом количестве листовых блоков индекса, что приводит к высокой конкуренции Oracle рекомендует использовать глобальные индексы с хэш-секционированием. Синтаксис для создания хэш-секционированного глобального индекса подобен тому, что применяется для хэш-секционированной таблицы. Например, следующий оператор создает хэш-секционированный глобальный индекс:
Структура базы данных Oracle Database
База данных состоит из табличных пространств, управляющих файлов, журналов, архивных журналов, файлов трассировки изменения блоков, ретроспективных журналов и файлов резервных копий (RMAN). В этом разделе мы познакомимся со многими из этих структур, а также с другими компонентами, составляющими в совокупности базу данных.
Файлы базы данных Oracle
База данных Oracle состоит из физических файлов трех основных типов:
- управляющие файлы (control files);
- файлы данных (datafiles);
- журнальные файлы, или журналы (redo log files).
На рис. 3 показаны эти три типа файлов и отношения между ними.
В управляющем файле хранится информация о местонахождении других физических файлов, составляющих базу данных, - файлов данных и журналов. Там же хранится важнейшая информация о содержимом и состоянии базы данных:
- имя базы данных;
- время создания базы данных;
- имена и местонахождение файлов данных и журнальных файлов;
- информация о табличных пространствах;
- информация о файлах данных в автономном режиме;
- история журналов и информация о порядковом номере текущего журнала;
- информация об архивных журналах;
- информация о наборах и фрагментах резервных копий, файлах данных и журналах;
- информация о копиях файлов данных;
- информация о контрольных точках.
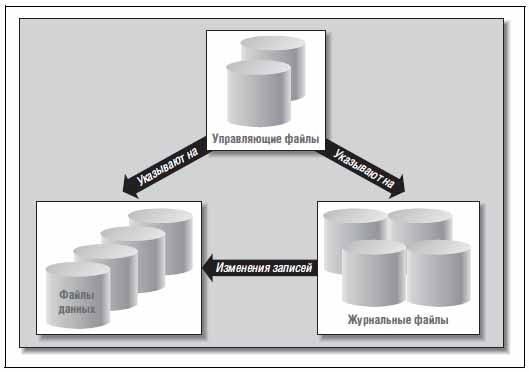
Рис. 3. Файлы, составляющие базу данных
Управляющие файлы не только содержат важную информацию, необходимую при запуске экземпляра, они полезны и при удалении базы данных. Начиная с версии Oracle Database 10g с помощью команды DROP DATABASE можно удалить все файлы, перечисленные в управляющем файле базы данных, а также сам управляющий файл.
Невидимые индексы
По умолчанию оптимизатор «видит» все индексы. Тем не менее, можно создать невидимый индекс, который оптимизатор не обнаруживает и не принимает во внимание при создании плана выполнения оператора. Невидимый индекс можно применять в качестве временного индекса для определенных операций или его тестирования перед тем, как сделать его «официальным». Вдобавок, иногда объявления индекса невидимым можно использовать в качестве альтернативы уничтожению индекса или объявлению его недоступным. Сделать индекс невидимым можно временно, чтобы протестировать эффект от его уничтожения.
База данных поддерживает невидимый индекс точно так же, как и нормальный (видимый) индекс. После объявления индекса невидимым, его и все прочие невидимые индексы можно сделать вновь видимым для оптимизатора, установив значение параметра optimizer_use_invisible_index равным TRUE на уровне сеанса или всей системы. Значением этого параметра по умолчанию является FALSE, а это означает, что оптимизатор по умолчанию не может использовать невидимые индексы.
Создание невидимого индекса.
Чтобы сделать индекс невидимым, к оператору CRETE INDEX нужно добавить конструкцию INVISIBLE.
С помощью команды ALTER INDEX можно превратить существующий индекс в невидимый.


Для изучения возможностей базы данных и программирования важно иметь примеры и демонстрационные схемы, и Oracle поставляет их в виде части серверного программного обеспечения Oracle Database 11g и 12c. Эти демонстрационные схемы предназначены для отделов вымышленной компании и выглядят следующим образом.
- HR. Эта схема предназначена для отдела кадров (Human Resources — HR) и потому содержит информацию о сотрудниках. Такая схема применяется чаще всех и включает хорошо знакомые таблицы сотрудников и отделов. В ней используются скалярные типы данных и простые таблицы с базовыми ограничениями.
- OE. Эта схема предназначена для отдела принятия заказов (Order Entry — OE) и потому содержит данные по инвентаризации и продажам. Она охватывает простую систему принятия заказов и включает в себя как обычные реляционные объекты, так и объектно-реляционные объекты. Благодаря тому, что она содержит синонимы таблиц из схемы HR, из нее можно выполнять запросы к объектам схемы HR.
- PM. Эта схема предназначена для отдела мультимедийного сопровождения продуктов (Product Media — PM) и содержит данные, касающиеся управления контентом. Ее можно использовать при изучении предлагаемой Oracle опции Multimedia (Мультимедиа). В частности, в таблицах внутри этой схемы содержатся аудио- и видео-треки, изображения и документы.
- IX. Эта схема предназначена для отдела обмена информацией (Information Exchange — IX) и отвечает за доставку данных с помощью различных приложений, работающих по схеме B2B (“бизнес для бизнеса”).
- SH. Эта схема предназначена для отдела истории сбыта (Sales History) и отвечает за накапливание данных по продажам. Она является самой большой среди демонстрационных схем и может применяться для тестирования примеров с большими объемами данных. В ее состав входят секционированные таблицы, внешняя таблица и функции для оперативной аналитической обработки (Online Analytical Processing — OLAP). В таблицах SALES/ и COSTS/ внутри этой схемы содержится, соответственно, 750 000 и 250 000 строк, а не 107, как в таблице сотрудников внутри схемы HR .
Для установки схемы SH необходимо, чтобы в базе данных был инсталлирован компонент, позволяющий использовать секционированные таблицы и индексы. В идеале демонстрационные схемы Oracle следует устанавливать в тестовой базе данных, в которой можно безопасно практиковаться в использовании незнакомых частей SQL. Более подробная информация о демонстрационных схемах доступна в поставляемом Oracle руководстве, в разделе Sample Schemas.
В случае создания стартовой базы данных с применением утилиты DBCA (Database Configuration Assistant — помощник по конфигурированию сервера базы данных) во время инсталляции программного обеспечения Oracle (за счет выбора варианта Basic Installation (Базовая установка)), демонстрационные схемы создаются автоматически внутри этой новой стартовой базы данных.
В случае пропуска этапа создания стартовой базы данных (за счет выбора во время установки программного обеспечения Oracle варианта Software Only (Только программное обеспечение)), демонстрационные схемы можно установить вручную внутри существующей базы данных, запустив утилиту DBCA и выбрав опцию Sample Schemas (Демонстрационные схемы). По умолчанию учетные записи всех демонстрационных схем блокируются, поэтому нужно обязательно воспользоваться оператором ALTER USER. ACCOUNT UNLOCK/ для их разблокировки.
Демонстрационные схемы можно также устанавливать в базе данных и без помощи DBCA, запуская соответствующие сценарии, поставляемые Oracle.
(B*tree)
В реализации индексов на основе B-деревьев используется концепция сбалансированного (на что указывает буква ‘B’ (balanced)) дерева поиска в качестве основы структуры индекса. В Oracle имеется собственный вариант B-дерева. Это обычные индексы, создаваемые по умолчанию, когда вы применяете оператора CREATE INDEX.
Индексы на основе B-деревьев структурированы в форме обратного дерева, где блоки верхнего уровня называются блоками ветвей (branch blocks), а блоки нижнего уровня – листовыми блоками (leaf blocks). В иерархии узлов все узлы кроме вершины, или корневого узла, имеют родительский узел и могут иметь ноль или более дочерних узлов. Если глубина древовидной структуры , т.е. количество уровней, одинакова от каждого листового блока до корневого узла, то такое дерево называется сбалансированным, или B-деревом.
B-деревья автоматически поддерживают необходимый уровень индекса по размеру таблицы. B-деревья также гарантируют, что индексные блоки всегда будут заполнены не меньше, чем наполовину, и менее, чем на 100%. B-деревья допускают операции выборки, вставки и удаления с очень небольшим количеством операций ввода-вывода на один оператор. Большинство B-деревьев имеет всего три и менее уровней. При использовании B-дерева нужно читать только блоки B-дерева, так что количество операций ввода-вывода будет ограничено числом уровней B-дерева (скажем, тремя) плюс две операции ввода-вывода на выполнение обновления или удаления (одна для чтения и одна для записи). Для выполнения поиска по B-дереву понадоисят всего три или менее обращений к диску.
Реализация B-дерева от Oracle – всегда сохраняет дерево сбалансированным. Листовые блоки содержат по два элемента: индексированные значения столбца и соответствующий идентификатор ROWID для строки, которая содержит это значение столбца. ROWID – уникальный указатель Oracle, идентифицирующий физическое местоположение строки и обеспечивающий самый быстрый способ доступа к строке в базе данных Oracle. Сканирование индекса быстро дает ROWID строки, и отсюда можно быстро получить к ней доступ непосредственно. Если запрос нуждается лишь в значении индексированного столбца, то конечно, последний шаг исключается, поскольку извлекать дополнительные данные, кроме прочитанных из индекса, не потребуется.
Оценка размера индекса
Для оценки размера нового индекса можно использовать пакет DBMS_SPACE. Процедуре CREATE_INDEX_COST этого пакета потребуется передать оператор DDL, создающий индекс, в качестве атрибута.
Обратите внимание на отличие между атрибутами, касающимися размера, в процедуре CREATE_INDEX_COST:
- Used_bytes показывает количество байт, которыми представлены данные индекса;
- Alloc_bytes показывает количество байт, которое займет индекс в табличном пространстве после его создания.
Инициализация базы данных
При запуске экземпляра Oracle считываются параметры инициализации. Они определяют, как база данных должна использовать физическую инфраструктуру и иную конфигурационную информацию об экземпляре. Параметры инициализации хранятся в файле параметров инициализации экземпляра, который обычно называют просто INIT.ORA, или, начиная с версии Oracle9i, в репозитории, который называется файлом параметров сервера (или SPFILE). Количество обязательных параметров инициализации уменьшается с выходом каждой новой версии Oracle. В дистрибутиве Oracle есть пример файла инициализации, пригодный для запуска базы данных. Либо можно воспользоваться программой Database Configuration Assistant (DCA), которая подскажет обязательные значения (например, имя базы данных).
Вот обязательные параметры инициализации для версии Oracle Database 11g:
Местонахождение управляющих файлов.
Локальное имя базы данных.
Местонахождение архивного журнала.
Параметр, включающий архивирование журналов.
Местонахождение области быстрого восстановления (flash recovery area) (каталог, файловая система или группа дисков ASM).
Максимальный размер области быстрого восстановления базы данных в байтах.
Размер блока базы данных в байтах (например, для 4 Кбайт указывается значение 4096).
Максимальное число процессов операционной системы, обслуживающих одновременный доступ к базе данных.
Максимальное число сеансов работы с базой данных.
Максимальное число открытых в базе данных курсоров.
Минимальное число разделяемых серверов базы данных.
REM O TE_LI S TENER
Имя удаленного прослушивателя.
Версия базы данных, с которой должна поддерживаться совместимость, в тех случаях, когда то или иное средство затрагивает формат файла (например, 11.1.0, 10.0.0).
Размер области памяти, автоматически выделяемой для SGA и PGA экземпляра.
Для команд языка определения данных (DDL) - время (в секундах) ожидания возможности установить монопольную блокировку, прежде чем сообщить об ошибке.
Язык, определенный в подсистеме поддержки национальных языков (National Language Support, NLS) для базы данных.
Территория, определенная в подсистеме поддержки национальных языков для базы данных.
В качестве признака взятого курса на автоматизацию отметим, что в версии Oracle Database 11g параметр UNDO_MANAGEMENT по умолчанию устанавливается в режим автоматического управления откатом (undo). Механизм отката применяется при откате транзакций, а также для восстановления базы данных, обеспечения согласованности по чтению и реализации ретроспекции. (Однако записи о повторном выполнении располагаются в физических журналах повтора, или наката, redo log; в них хранятся изменения, произведенные в сегментах данных и блоках сегментов отката, там же хранится таблица транзакций для сегментов отката.) Время хранения информации для отката Oracle теперь подбирает автоматически, исходя из того, как сконфигурировано табличное пространство отката.
Изучите поставляемую с вашей версией СУБД документацию в части дополнительных параметров инициализации, поскольку эта информация изменяется от версии к версии.
Индексы Oracle обеспечивают быстрый доступ к строкам таблиц, сохраняя отсортированные значения указанных столбцов и используя эти отсортированные значения для быстрого нахождения ассоциированных строк таблицы . Индексы позволяют находить строку с определенным значением столбца, просматривая при этом лишь небольшую часть общего объема строк таблицы. Таким образом правильное использование индексов сокращает до минимума количество дорогостоящих операций ввода-вывода.
Применение индексов представляет собой компромисс между ускорением получения результатов запросов и замедлением обновлений и вставок данных. Первая часть этого компромисса – ускорение запросов – довольно очевидна: если поиск выполняется по отсортированному индексу вместо полного сканирования всей таблиц, то запрос проходит намного быстрее. Но всякий раз, когда вы обновляете, вставляете или удаляете строку таблицы с индексами, индексы также должны быть обновлены соответствующим образом. То есть такие операции на таблицах с индексами обходятся дороже.
Вообще говоря, если таблицы в основном используются для чтения (выборки) информации, как в хранилищах данных, то лучше иметь много индексов. Если база данных относится к типу OLTP, с большим количеством вставок, обновлений и удалений, то лучше обойтись меньшим числом индексов.
Если только вам не нужно обращаться к большинству сток таблицы, индексированные запросы обеспечивают более быстрое получение результатов, чем запросы, не использующие индексы. Не существует ограничений на количество индексов, которые могут относиться к одной таблице Oracle, но, как упоминалось ранее, от их количества зависит производительность. Индекс полностью прозрачен для пользователя – т.е. оператор SQL пользователя не должен изменяться в результате создания индексов. Однако разработчикам приложений для построения эффективных запросов следует хорошо представлять себе , что такое индексы и как они работают.
Индексы могут относиться к нескольким типам, наиболее важные из которых перечислены ниже:
- Уникальные и неуникальные индексы. Уникальные индексы основаны на уникальном столбце – обычно вроде номера карточки социального страхования сотрудника. Хотя уникальные индексы можно создавать явно, Oracle не рекомендует это делать. Вместо этого следует использовать уникальные ограничения. Когда накладывается ограничение уникальности на столбец таблицы, Oracle автоматически создает уникальные индексы по этим столбцам.
- Первичные и вторичные индексы. Первичные индексы – это уникальные индексы в таблице, которые всегда должны иметь какое-то значение и не могут быть равны null. Вторичные индексы – это прочие индексы таблицы, которые могут и не быть уникальными.
- Составные индексы – индексы, содержащие два или более столбца из одной и той же таблицы. Они также известны как сцепленные индексы (concatenated index). Составные индексы особенно полезны для обеспечения уникальности сочетания столбцов таблицы в тех случаях, когда нет уникального столбца, однозначно идентифицирующего строку.
Индексы на основе функций
Индексы на основе функций предварительно вычисляют значения функций по заданному столбцы и сохраняют результат в индексе. Когда конструкция WHERE содержит вызовы функций, то основанные на функциях индексы являются идеальным способом индексирования столбца.
Ниже показано, как создать индекс на основе функции LOWER
Этот оператор CREATE INDEX создаст индекс по столбцу l_name, хранящему фамилии сотрудников в верхнем регистре. Однако этот индекс будет основан на функции, поскольку база данных создаст его по столбцу l_name, применив к нему предварительно функцию LOWER для преобразования его значения в нижний регистр.
Читайте также: