
Что такое расширение компьютерной сети
Современные информационные технологии продолжают возникшую в конце 70-х гг. тенденцию к развитию распределенной обработки данных. Начальным этапом развития таких методов обработки информации явились многомашинные системы, которые представляли собой совокупность вычислительных машин различной производительности, объединенных в систему с помощью каналов связи. Высшей стадией распределенных технологий обработки данных являются компьютерные сети различных уровней - локальные, корпоративные, глобальные.
В общем виде компьютерная сеть представляет собой систему взаимосвязанных и распределенных компьютеров, ориентированных на коллективное использование ресурсов сети, в качестве которых используются аппаратные, программные и информационные ресурсы:
Информационные ресурсы сети представляют собой базы данных общего и индивидуального применения, ориентированные на решаемые в сети задачи.
Аппаратные ресурсы сети составляют компьютеры различных типов, средства территориальных систем связи, аппаратура связи и согласования работы сетей одного и того же уровня или различных уровней.
Программные ресурсы сети представляют собой комплекс программ для планирования, организации и осуществления коллективного доступа пользователей к общесетевым ресурсам, автоматизации процессов обработки информации, динамического распределения и перераспределения общесетевых ресурсов с целью повышения оперативности и надежности удовлетворения запросов пользователей.
Назначение компьютерных сетей:
- обеспечить надежный и быстрый доступ пользователей к ресурсам сети и организовать коллективную эксплуатацию этих ресурсов;
- обеспечить возможность оперативного перемещения информации на любые расстояния с целью своевременного получения данных для принятия управленческих решений.
Компьютерные сети позволяют автоматизировать управление отдельными организациями, предприятиями, регионами. Возможность концентрации в компьютерных сетях больших объемов информации, общедоступность этих данных, а также программных и аппаратных средств обработки и высокая надежность функционирования - все это позволяет улучшить информационное обслуживание пользователей и резко повысить эффективность применения средств вычислительной техники.
Использование компьютерных сетей предоставляет следующие возможности:
- Организовать параллельную обработку данных несколькими ПК.
- Создавать распределенные базы данных, размещаемые в памяти различных компьютеров.
- Специализировать отдельные компьютеры для эффективного решения определенных классов задач.
- Автоматизировать обмен информацией и программами между отдельными компьютерами и пользователями сети.
- Резервировать вычислительные мощности и средства передачи данных на случай выхода из строя отдельных ресурсов сети с целью быстрого восстановления нормальной работы сети.
- Перераспределять вычислительные мощности между пользователями сети в зависимости от изменения потребностей и сложности решаемых задач.
- Сочетать работу в различных режимах: диалоговом, пакетном, режиме "запрос-ответ", режиме сбора, передачи и обмена информацией.
Таким образом, можно отметить, что особенностью использования компьютерных сетей является не только приближение аппаратных средств непосредственно к местам возникновения и использования информации, но и разделение функций обработки и управления на отдельные составляющие с целью их эффективного распределения между несколькими компьютерами, а также обеспечение надежного доступа пользователей к вычислительным и информационным ресурсам и организация коллективной эксплуатации этих ресурсов.
Как показывает практика, за счет расширения возможностей обработки данных, лучшей загрузки ресурсов и повышения надежности функционирования системы в целом стоимость обработки информации в компьютерных сетях не менее, чем в полтора раза ниже по сравнению с обработкой аналогичных данных на автономных (локальных) компьютерах.
Компьютерные сети можно классифицировать по разным признакам, представленным на рис. 6.1.
Характеристика различных видов компьютерных сетей представлена в табл. 6.1.
Расширение сети и использование искусственного интеллекта при эксплуатации сети
Как сохранить сервисы, доступные в кампусных сетях при объединении нескольких сетей посредством глобальных каналов связи или услуг операторов. В общем случае кампусная инфраструктура может состоять из нескольких площадок, из нескольких сайтов.
Использование ИИ при эксплуатации сети
Extreme Networks недавно купил компанию, у которой было хорошо разработано облако. Именно облачное решение по управлению и мониторингом инфраструктурой. Вендор это назвал Extreme Cloud IQ. Сейчас идет работа по интеграции программного и аппаратного портфолио в эту облачную систему. Далее изображен скриншот (из графического интерфейса в облако).
Эта облачная система третьего поколения, т.е. внутри облака работает искусственный интеллект и машинное обучение. Это возможно за счет того, что это облако используют и тысячи других заказчиков. Соответственно, в этом облаке хранится огромное количество статистической информации относительно беспроводного и проводного сегментов. Используя машинное обучение, система может автоматически реагировать на какие-то нестандартные ситуации в сети. Например, в сети появился какой-то Wi-Fi клиент, у которого плохая пропускная способность. Облачная система может посмотреть в своей базе знаний, есть ли примеры того, как с такими клиентами общаться другие пользователи. Как нужно изменить радиоэфир, чтобы у клиента появилось более качественное соединение. К примеру, облачная система находит в своей базе данных, что примерно месяц назад была схожая ситуация у другого заказчика, и она была разрешена за счет Wi-Fi настройки вот таким образом. Облачная система может эти настройки применить автоматически и в этой сети. Таким образом радиоокружение автоматически изменится. И в большинстве случаев вы даже не заметите, как что-то изменилось в вашем радиоокружении, а этот клиент будет подключен на более высоких скоростях, и этим проблемы будут автоматически решены. Это как раз облако третьего поколения со встроенным искусственным интеллектом, машинным обучением и так называемым Big Data, потому что облако хранит информацию о всех заказчиках, которые используют или использовали это облако.
Дополнительные механизмы
Теперь расскажем о дополнительных механизмах, которые позволят начать дизайн сети с Extreme Networks. Первый механизм под названием Extreme IRIS. Это программа-конфигуратор, которая устанавливается на компьютер.
Она имеет доступ в Интернет, и в этой программе можно в графическом виде создать дизайн небольшой сети. Слева изображено дерево компонентов, из которых можно построить сеть. Это дерево автоматически обновляется через Интернет, т.е. при появлении каких-то новых продуктов в портфолио вендора, автоматически этот продукт попадет в это дерево.
Справа дан один из результатов, где изображена небольшая сеть, где автоматически к каждому устройству подтягивается необходимый сервис, причем сервисы можно выбрать разного типа. У компании Extreme Networks есть Extreme Works, Partner Works. Можно использовать графический интерфейс, чтобы в реальности нарисовать небольшую сеть. Здесь можно и большими сетями заниматься. Интерес в том, что система все время проверяет, правильно ли создается дизайн. Скажем, она не даст соединить, скажем, оптический порт с каким-нибудь медным портом, не даст запитать коммутатор неправильным блоком питания. Она обнаруживает многие типичные ошибки при построении сети. В данном примере система предупреждает, что мы «повесили» слишком много точек доступа на один коммутатор и у него не хватает PoE-бюджета, чтобы запитать все эти точки.
Соответственно таких проверок происходит очень много при дизайне сети. Эта программа доступна для всех дистрибьютеров и партнеров Extreme Networks. Соответственно эта программа довольно удобная для перепроверки себя, правильно ли мы сделали дизайн, правильно ли мы сделали квотирование того или иного проекта.
Помочь при дизайне могут и несколько документов. Они называются Extreme Validated Solutions или Extreme Validated Design.
Это технические документы, посвященные той или иной технологии. В этих документах описывается, для чего технология используется, какие проблемы она решает, в них есть непосредственная конфигурация оборудования для того, чтобы та или иная технология «взлетела». Повторяя инструкцию step by step из этих документов можно прямо у себя в правильном виде собрать ту или иную технологию. Внизу дана ссылка, где можно сейчас скачать актуальные документы.
Расширение сети
Тема сегодняшнего мероприятия, посвященного системному дизайну - «Расширение сети», ведет его Павел Денисов, системный инженер московской компании Extreme Networks. Это мероприятие можно считать продолжением того, что коллеги Павла начали с азов по сетевому дизайну и построению сети, они говорили о том, как построить небольшую сеть, каким вопросам нужно при этом уделять внимание, какое оборудование и технологии можно при этом использовать. Сегодня речь пойдет о том, что нужно делать если сеть растет, каким путем ее можно развивать и как это сделать наиболее просто и эффективно.
Сегодня речь пойдет о том, как открывается кампус, какие наиболее оптимальные пути по построению и масштабированию кампусной инфраструктуры предлагает вендор и поддерживает в своих продуктах, как решать в этих сетях задачи по авторизации абонентов, по изоляции трафика пользователей, по построению различных схем маршрутизации.
Поговорим, как сохранить сервисы, доступные в кампусных сетях при объединении нескольких сетей посредством глобальных каналов связи или услуг операторов.
В общем случае кампусная инфраструктура может состоять из нескольких площадок, из нескольких сайтов.
Начнем с сетевой инфраструктуры
На этом слайде изображен классический двухуровневый сетевой дизайн с уровнем доступа (в верхней части слайда).
Коммутаторы доступа и подключенные через проводную инфраструктуру к ним пользователи. Тут же расположены точки беспроводного доступа, которые также обеспечивают подключение клиентов к сети. В нижней части слайда есть серверы, коммутаторы, которые обеспечивают подключение серверов. И в середине слайда пара коммутаторов, которые образуют ядро сетевой инфраструктуры. Классический пример дизайна: коммутаторы уровня доступа подключаются к ядру с использованием резервируемых каналов связи. От каждой группы коммутаторов доступа в ядро ведет два линка. В данном случае они используются для обеспечения резервирования и распределения нагрузки между коммутаторами ядра. В ядре используются технологии MLAG, которые позволяют обеспечивать резервированное подключение коммутаторов доступа в режиме active-active к двум коммутаторам ядра.
MLAG - это наиболее простая и хорошо проработанная технология для решения задачи одновременного использования нескольких путей передачи трафика (напомню, что протокол STP, дабы избежать зацикливания трафика, «замораживает» часть канальных ресурсов, оставляя активным только один путь между двумя узлами).
Что здесь еще как правило используется? Тут еще используются VLAN на коммутаторы доступа, растянутые до нужного количества VLANов.
VLAN (Virtual Local Area Network) — топологическая («виртуальная») локальная компьютерная сеть, представляет собой группу хостов с общим набором требований.
Каждому VLANу соответствует свой subnet.
subnet (подсеть) — это логическое разделение сети IP. IP адрес разделён маской подсети на префикс сети и адрес хоста. Хостом в данном случае является любое сетевое устройство (именно сетевой интерфейс этого устройства).
Все эти subnet сходятся соответственно на коммутаторах уровня распределений ядра Backbone коммутаторов, которые является для пользователей этих VLANов шлюзами по умолчанию. Соответственно для того, чтобы этот шлюз по умолчанию работал отказоустойчиво, используется протокол VRRP.
VRRP (Virtual Router Redundancy Protocol) — сетевой протокол, предназначенный для увеличения доступности маршрутизаторов, выполняющих роль шлюза по умолчанию.
Два коммутатора третьего уровня, стоящих в ядре, выполняют роль основного и резервного шлюза по умолчанию для пользовательских VLANов. Аналогичная инфраструктура построена для серверов. Здесь тоже есть свой набор VLANов. И также маршрутизаторы ядра являются шлюзами по умолчанию для серверов и осуществляют маршрутизацию как пользовательских данных между VLANами, так и пользовательских данных в сторону серверов и в обратную сторону.
По мере роста нашей сети, что может происходить?
Может увеличиваться количество устройств на уровне доступа, может увеличиваться количество серверов и сайтов и, соответственно, растет сетевая инфраструктура и есть возможность использовать технологию MLAG и увеличить сеть, как показано на этой схеме.
Остальные же части сетевого дизайна не меняются, по-прежнему используется VLAN, по-прежнему используется VRRP и маршрутизация данных между различными сетевыми сегментами.
Технология Extreme Fabrica
Есть другая технология, которая позволяет заметно лучше масштабировать сетевые решения, делать это более гибко и не обращать особого внимания на топологию и связанность в ядре.
Эта технология называется Extreme Fabrica, она построена на технологии Extreme Fabric Connect, которая работает в ядре сетевой инфраструктуры. Если возвращаться к схеме, то здесь было бы целесообразно использовать эту архитектуру в зависимости от устройств. Есть несколько подходов по использованию именно Extreme Fabric. Если Fabric хочется начать непосредственно с устройства доступа, мы можем использовать соответствующие модели коммутаторов и начать фабрику непосредственно с коммутаторов доступа, т.к. это показано на слайде. Здесь Fabric работает от коммутаторов доступа и до коммутаторов серверной фермы, т.е. все коммутаторы на этой схеме поддерживают технологию SPBm, что есть основа технологии Extreme Fabric. И все они являются участниками Fabric. Такое решение дает возможность более гибко распределять пользователей, дает возможность по построению и выбору VLANов, по выбору схем адресации для VLANов. Кстати, у нас нет ни одного линка в этой сети, на котором бы работала классическая технология Ethernet.
Фабрика позволяет решить красиво и достаточно эффективно задачу по балансировке нагрузки между разными линками и по отсутствию петель в топологиях. Для чего она, собственно и предназначена.
Можно такую же архитектуру собрать и по другой схеме.
На этой схеме изображено все почти то же самое. Единственно меняется технология на уровне доступа. В ядре сети в серверной ферме по-прежнему используется технология Fabric Connect, а на уровне доступа используется другая технология. Если раньше Fabric начиналась с коммутатора уровня доступа, то сейчас на доступе используются классические технологии. Мы можем их использовать на линках, идущих от коммутаторов доступа к ядру сети, здесь не используются SPBm, а только классический Ethernet и мы вынуждены вернуться к использованию классических схем по агрегации каналов, чтобы избежать ситуации с блокировкой линков. Здесь опять используется LSP группировка линков. В этом случае шире выбор сетевых устройств. Мы можем на уровне доступа не использовать устройства с поддержкой Fabric, а использовать любые коммутаторы доступа, в том числе и коммутаторы серии Extreme EXOS либо ERS, и другие модели, которые не поддерживают Fabric.
Если используются коммутаторы EXOS или ERS, то можно на этих L2-каналах, использующих классический Ethernet и обеспечивающих подключение доступа к ядру, использовать дополнительную технологию, которая называется Fabriс Attach, она позволяет автоматизировать подключение пользователей на уровне доступа и обеспечить им в том числе автоматическое назначение виртуального контента Fabriс.
Одно из основных преимуществ использования технологии Extreme Fabric Connect при построении кампусной инфраструктуры заключается в большом запасе по масштабированию этого решения и по сути независимости, т.е. технология Fabric отлично работает при любых топологиях. Вы можете добавлять уровни, можете использовать классические схемы, которые по традиции используются в кампусной инфраструктуре типа двойная звезда, а можете использовать какие-то другие схемы связанности. И все они одинаково хорошо будут работать с точки зрения фабрики.
На этой схеме добавились два уровня. Появились коммутаторы агрегации в ЦОДах, появились коммутаторы агрегации в системе подключения пользователей, осталось два коммутатора ядра. Но фабрика прекрасно справляется с этой топологией. В данном случае мы вернулись к доступу к фабричным коммутаторам. У нас везде работают SPBm. И на всех линках работает технология Extreme Fabric Connect.
Extreme Fabric Connect простая технология, несмотря на кажущуюся ее сложность. Она позволяет решать много различных задач, но настраивается все достаточно просто, нужно сделать всего лишь несколько действий. Во-первых, создать так называемые Backbone VLAN, которые будут работать на всех каналах, так называемых NNI (Network to Network Interface) links, которые объединяют коммутаторы между собой. На этих интерфейсах работают Backbone VLAN технологии SPBm. Кроме этого нужно включить SPBm, задать имя устройства, задать систему ID-устройства, включить маршрутизацию IS-IS, которая работает вместе с SPBm и обеспечивает передачу данных внутри фабрики. Этого будет достаточно для того, чтобы начать работать Fabric.
Если мы используем другую сетевую архитектуру и идем в сторону использования технологии Fabriс Attach на уровне доступа, у нас соответственно меняется схема взаимодействия коммутаторов доступа с ядром.
Однако логика остается той же самой. Мы по-прежнему в ядре сети (в нижней части слайда, закрашенной серым цветом) используем технологию Extreme Fabric Connect, настраиваем все, как было показано на предыдущем слайде, а на верхних уровнях используем классические сетевые технологии.
Сеть растет
Предположим, что сеть продолжает расти и серверы не вмещаются в одно здание, значит появляется необходимость поместить часть сети в другом здании, расположенном недалеко и мы еще можем использовать оптику для связи между этими зданиями. Самый простой вариант, это сделать так, как показано на следующем слайде.
Здесь можно собирать почти симметричные архитектуры, они, конечно, будут отличаться по количеству и типу используемых коммутаторов, по количеству коммутаторов доступа. Но основное - это связка между коммутаторами ядра осуществлена с использованием технологии Extreme Fabric Connect, которая позволяет таким образом «растянуть» сетевое решение на два здания и использовать одинаковый набор сервисов для этих архитектур. Настраивается все точно так же, как и на прошлом слайде. По-прежнему существуют Backbone VLAN, общая фабрика объединяет два сетевых сегмента и все настраивается ровно также, как настраивалось в случае одного здания.
Построение маршрутизации
Если нам нужно в такой распределенной сети построить маршрутизацию, то в здании, расположенном слева, есть свой ЦОД, в ЦОДе есть серверы, которые размещены в разных виртуальных сетях и VLANах.
У нас справа есть второй ЦОД, предположим, он используется, как резервный, у него есть свои VLANы. Для того, чтобы все правильно работало, надо обеспечить миграцию виртуальных маршей между основным и резервным ЦОДам. Чтобы сервис мог плавно и незаметно для пользователей переехать из одного ЦОДа в другой, нужно обеспечить связность на втором уровне между этими ЦОДами. Это, как говорят, нужно растянуть VLAN между этими ЦОДами.
Такую схему достаточно просто реализовать. Если мы не используем фабрику, то можем взять в этой магистрали один и тот набор VLANов, который приходит на оба сервера, и использовать классическую схему с VLANами и маршрутизацией. Такая схема решит задачу с точки зрения растягивания широковещательного домена между двумя знаниями, но она чревата возникновением других проблем, одна из них показана на слайде.
В чем проблема заключается? Здесь дан пример, когда пользователи имеют доступ к серверу через интерсайт. Даже если сервер будет стоять на этой же площадке, а основные и резервные маршрутизаторы будут в паре работать на другой площадке, трафик пойдет очень сложной петлей между двумя хостами.
Есть специальные термины в архитектурах сетевого дизайна, описывающие такой сценарий, скажем, Data Tromboning. Есть решение, которое позволяет избежать такой несимметричной загрузки межсайтового линка, и заключаются они в использовании фабрики, и дополнительных технологий, которые на эта фабрика позволяет реализовать.
Расширение компьютерной сети
Часто появляется необходимость развивать сеть за границы одного офиса, подключать удаленные объекты. Для решения такой задачи есть несколько путей. Похожую задачу мы решали при объединении вот этих двух сайтов. Самый простой вариант - использование темной оптики (dark fibre).
У некоторых компаний сеть продолжает разрастаться. Что же делать в этом случае? Об этом продолжает рассказ Павел Денисов, системный инженер московской компании Extreme Networks. Чем же сможет помочь Fabric Connect.
Fabric Connect
У нас, как и раньше два здания, но появилась некоторая конкретика. Здесь есть 10-й пользовательский VLAN в левой части, есть 20-й пользовательский VLAN в правой части и 100-й VLAN в ЦОДе.
Если нужно в такой инфраструктуре сделать сервис для клиентов, например, объединить синие VLANы в разных частях между собой, так, чтобы пользователи из синего 10-го VLAN в здании слева имели доступ к серверу в VLANе 100-м, и к тому же серверу имели доступ пользователи в VLAN 20-м из здания, расположенного в правой части слайда, нужно сделать одинаковый набор конфигураций на обоих сайтах.
Здесь создан 10-й VLAN в здании слева, в здании справа - 20-й VLAN. Дальше мы пируем VLAN к I-SID. I-SID - это сервис ID, это идентификатор сервиса, который работает внутри фабрики, в данном случае это L2-сервис. Т.е. это сервис, который обеспечивает связанность между хостами, которые подключены к данному сервису по протоколу Ethernet на уровне MAC-адресов, т.е. на втором уровне. И ровно такую же команду мы должны будем дать в здании слева.
Альтернатива созданию связанности между хостами на втором уровне это маршрутизация, т.е. построение сервисов третьего уровня между различными сетевыми устройствами. Третий уровень позволяет добиться большей масштабируемости в сетевой инфраструктуре. Схемы маршрутизации всегда проще масштабируются, однако в ряде случаев по тем или иным причинам нет возможности использовать маршрутизацию. Обычно это связано со спецификой оконечных устройств, которые используются в сетевой инфраструктуре. До сих пор еще встречаются клиенты, которые не умеют работать через шлюз по умолчанию и стек SPIP на них реализован не очень правильно. Именно для таких клиентов как правило и приходится делать L2-сервисы, объединяющие разные площадки между собой. В классической архитектуре мы вынуждены растягивать ее VLANом, в случае фабрики мы делаем I-SID 2-го уровня и подключаем клиентов.
Итак, маршрутизация. Похожая схема. Мы можем делать несколько виртуальных сервисов, внутри которых будет работать маршрутизация. На этой схеме показано несколько VLANов. Красные VLAN есть и слева, и в правой части слайда. Они подключаются к красному L3VSN, он же I-SID, который создает сервис третьего уровня для клиентов и аналогичный I-SID создан для серверов. Настраивается это чуть сложнее, чем в случае L2 сервиса.
Единственное отличие, пожалуй, заключается в том, что здесь нужно создать еще и IP VRF (Virtual Routing and Forwarding), сделать VRF Instance, в которые будут заниматься маршрутизацией IP пакетов для данного виртуального контекста, и после создания этого Instance мы должны подключить в него наши пользовательские VLAN и создать сервис, а затем привязать его к созданному VRF.
С пользователями все достаточно просто происходит. Теперь нужно оценить, что будет с серверами, с миграцией виртуальных машин и с маршрутизацией в такой сети. Итак, опять те же два сайта. У нас есть серверный сегмент в левом здании и есть серверный сегмент в правом здании.
Для того, чтобы работала миграция виртуальных машин, нужна связанность на втором уровне между обоими серверными сегментами, так, как это показано в нижней части слайда. Здесь есть два subnet, один и тот же VLAN, с одной и той же схемой адресации. Есть синий и зеленый subnet. Есть серверы в том и в другом subnet они в двух ЦОДах расположены. И теперь стоит задача сделать эффективную систему маршрутизации для таких сайтов.
Нужно зарезервировать шлюзы по умолчанию, и первое, что приходит в голову это использовать протокол VRRP, но классическая реализация VRRP не очень удобна, потому что в VRRP-группе есть только один активный маршрутизатор. И где бы он ни располагался в данной схеме, мы всегда рискуем получить не самое эффективное использование межсайтовых линков. Если, например, синий сервер должен «поговорить» с зеленым сервером, расположенном в том же здании, например, в соседней стойке, а, например, VRRP-мастер будет расположен на этом устройстве, трафик будет вынужден пройти межсайтовый канал в одну сторону и потом вернуться, маршрутизироваться и попасть в зеленый VLAN и прийти сюда. Это и есть неэффективное использование link, увеличение задержек и т. д.
Distributed Virtual Routing
Однако, есть способ лучше, который предлагает фабрика. В случае использования фабрики можно всю ту же инфраструктуру реализовать с использованием дополнительной технологии. Внутри технологии Extrim Fabric Connect есть отдельный вид сервиса, называется этот Distributed Virtual Routing (DVR).
У нас опять чуть-чуть изменилась схема, но смысл ее остался тот же. Есть два здания в левой и в правой частях слайда. По-прежнему есть VLANы с серверами, расположенными в левой и в правой части здания. Есть растянутые L2 сегменты между зданиями. И мы хотим теперь оптимизировать пути передачи трафика. Посмотрим, как технология DVR в этом поможет.
Мы создаем DVR Instance и говорим, к какому DVR Instance привязываются Leaf.
А на контроллерах мы создаем похожую конфигурацию. Мы там же создаем VLANы, там же настраиваем шлюзы по умолчанию. Мы используем на контроллерах протокол VRRP для резервирования шлюзов по умолчанию, причем оба маршрутизатора являются участниками VRRP-групп. Это настраивается, как настраивается VRRP. Но на самом деле мы используем не классический VRRP, а за счет использования DVR используем модифицированную логику работы. Использование DVR и фабрики позволяет чуть-чуть по-другому решить задачу. Итак, маршрутизатор выполняет роль маршрутизаторов по умолчанию всех подключений, но они же после настройки, после того, как мы на них настроили VLANы и шлюзы по умолчанию, они эту информацию о VLANах и о шлюзах по умолчанию для этих VLANов передают на все пограничные устройства. Т.е. на каждом пограничном коммутаторе DVR Leaf будет информация о том, что в нашем зеленом VLANе есть шлюз по умолчанию с адресом 101. И он является шлюзом по умолчанию для этого сегмента. И то же самое мы настраиваем на втором маршрутизаторе для резервирования, чтобы роль DVR контроллера была резервирована. Симметричный config настраивается на втором устройстве.
И в здании справа создаем похожую конфигурацию. Единственное отличие в том, что домен DVR здесь другой. А с точки зрения IPV четвертой адресации мы используем одну и ту же схему. Точно также, как мы бы делали в случае настройки по протоколу VRRP, если бы хотели эти четыре маршрутизатора объединить в один виртуальный Instance протокола VRRP, то мы должны бы были указать на них один и тот же виртуальный IP адрес, который бы являлся основным шлюзом по умолчанию для этого VLANа. И мог бы мигрировать между всеми четырьмя маршрутизаторами. Похожая схема с точки зрения настройки IPV четвертого, отличается только логика по тому, как работают маршрутизаторы в данной схеме и как обеспечивается обработка трафика.
Мы сделали симметричные настройки для зеленого и синего VLANов, и теперь создали два DVR домена, настроили контроллеры, настроили DVR Leaf. У нас все пограничные устройства знают про VLANы и шлюзы по умолчанию. Теперь посмотрим, как трафик будет ходить в этом случае.
В данном случае трафик не пойдет до DVR контроллеров, которые формально с точки зрения конфигурации являются у нас шлюзами по умолчанию для сетей, а первый же DVR Leaf на пути нашего пакета сделает маршрутизацию, переложит пакет в VLAN назначения и отправит его в сторону получателя.
А как пойдет трафик между хостами, расположенными в разных доменах? Как говорилось выше, информация о хостах, расположенных в другом DVR домене неизвестна DVR Leaf. Про нее знает только контроллер. В этой схеме нужно обеспечить взаимодействие VM-3 с VM-6, который расположен в другом домене. Поэтому VM-3 пакет доходит до DVR контроллера, который его отправляет через DVR линк на контроллер другой группы, которая в свою очередь имеет полное визибилити внутри себя и отправляет его на конечную станцию.
Для того, чтобы у нас корректно работала VM-технология при миграции виртуальных машин между сайтами, когда машина подключается к хосту, хост активируется, отправляется специальный пакет для того, чтобы сеть «выучила» MAC-адрес и все Leaf-ноды внутри домена. И DVR контроллер узнал про то, что появилась новая станция, о чем он уведомит и другие DVR домены.
И если у нас происходит миграция машин, то анонс об этом по похожей схеме по сети распространяется и сеть может адекватно реагировать, зная о том, что хост переместился, зная о том, что теперь обновит все свои таблицы и все устройства в сети будут знать за каким оконечным коммутатором новый хост расположен.
DVR архитектура позволяет достаточно эффективно решить задачу по оптимизации сложных трафиков в архитектурах, в том числе с распределенными VLANми и L-2 доменами между сайтами. И несмотря на это она обладает достаточно большим запасом по масштабированию, т.е. у нас может быть до восьми контроллеров в каждом домене для обеспечения задачи по резервированию этих контроллеров. До 250-ти пограничных маршрутизаторов может быть в домене. Ну и до 40 тысяч хостов в каждом домене и до 16 доменов. С использованием этой технологии можно собрать достаточно большую систему, которая позволит эффективно решать задачи по маршрутизации трафика в таких архитектурах.
Расширение до удаленного офиса
Часто появляется необходимость развивать сеть за границы одного офиса, подключать удаленные объекты. Для решения такой задачи есть несколько путей. Похожую задачу мы решали при объединении вот этих двух сайтов. Самый простой вариант - использование темной оптики (dark fibre).
Тёмное волокно (англ. dark fiber) — неиспользуемые для передачи данных волокна оптического кабеля, прокладываемые в качестве резерва на случай выхода из строя основных волокон.
Термин применяется, в частности, при описании незадействованного потенциала глобальной системы связи. Компании, занимающиеся строительством/укладкой оптического волокна, часто укладывают дополнительные волокна в расчете на будущий рост трафика, так как затраты ресурсов на расширение существующих ВОЛС слишком велики. Тёмное волокно лежит в бездействии до тех пор, пока владелец сети не использует его для собственных нужд или не сдаст в аренду другой компании. Согласно эмпирическому правилу, в оптическом кабеле на каждые шесть пар задействованных волокон рекомендуется укладка одной резервной пары. Например, по регламентам Ростелекома в магистральном кабеле допускается закладывать до 15% резервных волокон для GPON или до 10% для FTTB, но не менее двух .
Далее применяется система оптического уплотнения с использованием цветной оптики SVDM, через которую можно подключать удаленные сайты, но у вас должны быть доступны такие каналы связи. Часто это бывает не так, особенно когда сайт может быть в другом городе. Оптику для такого сайта организовать можно, но это скорее всего будет очень дорого и не всегда экономически оправдано. Однако есть другие, более экономичные пути. Например, использовать услугу L-2 или L-3 VPN от операторов услуг связи, либо просто построить такое взаимодействие через Интернет с использованием IP VPN сервисов.
Если мы идем любым из этих путей, у нас по-прежнему сохраняется возможность растянуть наши виртуальные контексты, те самые I-SID, которые мы создавали и которые у нас успешно работали в рамках основного и резервного первого и второго сайта в двухсайтовой архитектуре. Мы создавали в них какой-нибудь L-2 или L-3 контексты для решения различных задач. Здесь у нас появилась возможность растянуть сеть, добавить к сетевой инфраструктуре удаленное подразделение, расположенное в другом городе, использовать для этого сеть операторов услуг связи. IPLS или IP VPN решения, мы можем сохранить виртуальные контексты и сохранить принадлежность хостов к виртуальным контекстам при передаче трафика из удаленного сайта в центр и в обратную сторону.
Но для этого следует использовать технологию Fabric Extend, которая также является частью архитектуры для кампусной фабрики. Fabric Extend - это технология, которая использует VXLAN туннели для передачи SPB трафика между разными сайтами, при этом природа межсайтовых каналов не важна. Это может быть L3 VPN. Здесь каждый удаленный сайт имеет IP-адрес в отдельной подсети, это такая как бы «хабенспоктопология» с L3 VPN, это может быть L2 VPN, как в правой части данного слайда. LPLS-технология, которую вам оператор продает. Независимо от того, как выглядит канальная инфраструктура между сайтами, технология Fabric Extend позволит растянуть сервисы между удаленными площадками, сохранив их сегментацию.
Единственное, на что следует обратить особое внимание, то это на тот факт, что за счет дополнительного туннелирования появляются дополнительные заголовки и размер кадров увеличивается. Про это нужно помнить. Если мы хотим растягивать I-SID фабрики через сети операторов, с использованием технологии Fabric Extend, мы должны уточнить у оператора, позволяет ли его сеть передавать пакеты с большим MTU. На слайде показано, что за счет использования VXLAN заголовка, размер пакета становится равным 1594 байта. Обычно операторы поддерживают это. Но это нужно уточнять.
Использование Fabric Extend позволяет, как это показано в нижней части слайда, не просто связывать удаленные здания, но и сохранять принадлежность оконечных устройств и трафик этих оконечных устройств изолировать, устройств, ближайших к I-SID даже при переходе между сайтами. Если бы мы не использовали технологию Fabric Extend, а использовали, например, классический MPLS, нам нужно было бы создавать несколько VRF, по одному VRF для каждого I-SID, что делало бы эту конструкцию более громоздкой и менее удобной в эксплуатации.
Fabric Extend позволяет решить эту задачу, подключать удаленные сайты с сохранением сегментации и сетевой виртуализации.
Для того, чтобы решить эту задачу, у вендора недавно появилось новое устройство - XA1400, которая может быть использована в удаленных сайтах. Это такой пограничный маршрутизатор с поддержкой технологии Fabric Extend для того, чтобы обеспечивать выносы фабрики за пределы одного офиса. При этом это устройство поддерживает не только технологию Fabric Extend, но и маршрутизацию. И можно ее использовать для построения выносов через инфраструктуру операторов услуг связи, через L2, L3 VPN с и без всяких VPN с другой стороны.
Настраивается все достаточно просто. Сейчас не будем на этом заострять внимание.
Операционные модели
А сейчас несколько слов про систему управления. По мере роста нашего сетевого решения становится сложно управлять возросшим парком оборудования через консоль.
Нужны какие-то дополнительные средства, которые бы позволили делать это просто и эффективно. Система Extreme Management Center и предназначена для того, чтобы помочь в решении этой задачи. Система состоит из нескольких модулей. Прежде всего это все, что связано с сетевым управлением, отображением карт, сбором конфигураций, управления конфигурациями, управления файлами ПО, сбором логов и анализом этих логов. Другая компонента обеспечивает автоматизацию подключения пользователей к сети, назначение и регулирование политик доступа пользователей при сетевых подключениях. И еще одна компонента отвечает за сбор аналитики о сетевом трафике пользователей. И при этом все эти три компоненты работают с любыми из коммутаторов вендора.
Одна из компонент этой системы управления называется Fabric Manager. Эта компонента позволяет визуализировать фабрику. Данная компонента доступна в самом простом basic-уровне лицензии системы управления. Лицензия позволяет визуализировать фабрику, смотреть, какие устройства являются ее участниками, отображать состояние этой фабрики, смотреть, какие сервисы в ней активны и какими путями они идут. Если вы хотите заниматься настройкой вашей фабрики через этот графический инструмент, то вам будет необходимо приобрести Edvance уровень лицензии на систему Extreme Managment Center.
Расширяемость (extensibility) означает возможность сравнительно легкого добавления отдельных элементов сети (пользователей, компьютеров, приложений, служб), наращивания длины сегментов сети и замены существующей аппаратуры более мощной. При этом принципиально важно, что легкость расширения системы иногда может обеспечиваться в весьма ограниченных пределах. Например, локальная сеть Ethernet , построенная на основе одного сегмента толстого коаксиального кабеля , обладает хорошей расширяемостью , в том смысле, что позволяет без труда подключать новые станции. Однако такая сеть имеет ограничение на число станций — оно не должно превышать 30–40. Хотя сеть допускает физическое подключение к сегменту и большего числа станций (до 100), но при этом чаще всего резко снижается производительность сети. Наличие такого ограничения и является признаком плохой масштабируемости системы при хорошей расширяемости .
Масштабируемость (scalability) означает, что сеть позволяет наращивать количество узлов и протяженность связей в очень широких пределах, при этом производительность сети не ухудшается. Для обеспечения масштабируемости сети приходится применять дополнительное коммуникационное оборудование и специальным образом структурировать сеть . Например, хорошей масштабируемостью обладает многосегментная сеть , построенная с использованием коммутаторов и маршрутизаторов и имеющая иерархическую структуру связей. Такая сеть может включать несколько тысяч компьютеров и при этом обеспечивать каждому пользователю сети нужное качество обслуживания .
Прозрачность
Прозрачность (transparency) сети достигается в том случае, когда сеть представляется пользователям не как множество отдельных компьютеров, связанных между собой сложной системой кабелей, а как единая традиционная вычислительная машина с системой разделения времени. Известный лозунг компании Sun Microsystems " Сеть — это компьютер " — говорит именно о такой прозрачной сети.
Прозрачность может быть достигнута на двух различных уровнях — на уровне пользователя и на уровне программиста. На уровне пользователя прозрачность означает, что для работы с удаленными ресурсами он использует те же команды и привычные процедуры, что и для работы с локальными ресурсами. На программном уровне прозрачность заключается в том, что приложению для доступа к удаленным ресурсам требуются те же вызовы, что и для доступа к локальным ресурсам. Прозрачности на уровне пользователя достичь проще, так как все особенности процедур, связанные с распределенным характером системы, скрываются от пользователя программистом, который создает приложение . Прозрачность на уровне приложения требует сокрытия всех деталей распределенности средствами сетевой операционной системы .
Прозрачность — свойство сети скрывать от пользователя детали своего внутреннего устройства, что упрощает работу в сети.
Концепция прозрачности применима к различным аспектам сети. Например, прозрачность расположения означает, что от пользователя не требуется знать местонахождение программных и аппаратных ресурсов, таких как процессоры, принтеры, файлы и базы данных . Имя ресурса не должно включать информацию о месте его расположения, поэтому имена типа mashine1:prog.c или \\ftp_serv\pub прозрачными не являются. Аналогично, прозрачность перемещения означает, что ресурсы могут свободно перемещаться из одного компьютера в другой без изменения имен. Еще одним из возможных аспектов прозрачности является прозрачность параллелизма , которая заключается в том, что процесс распараллеливания вычислений происходит автоматически, без участия программиста, при этом система сама распределяет параллельные ветви приложения по процессорам и компьютерам сети. В настоящее время нельзя сказать, что свойство прозрачности в полной мере присуще многим вычислительным сетям, это скорее цель, к которой стремятся разработчики современных сетей.
Поддержка разных видов трафика
Особую сложность представляет совмещение в одной сети традиционного компьютерного и мультимедийного трафика . Передача исключительно мультимедийного трафика компьютерной сетью хотя и связана с определенными сложностями, но доставляет меньше хлопот. А вот сосуществование двух типов трафика с противоположными требованиями к качеству обслуживания является намного более сложной задачей. Обычно протоколы и оборудование компьютерных сетей относят мультимедийный трафик к факультативному, поэтому качество его обслуживания оставляет желать лучшего. Сегодня затрачиваются большие усилия по созданию сетей, которые не ущемляют интересы одного из типов трафика. Наиболее близки к этой цели сети на основе технологии ATM , разработчики которой изначально учитывали случай сосуществования разных типов трафика в одной сети.
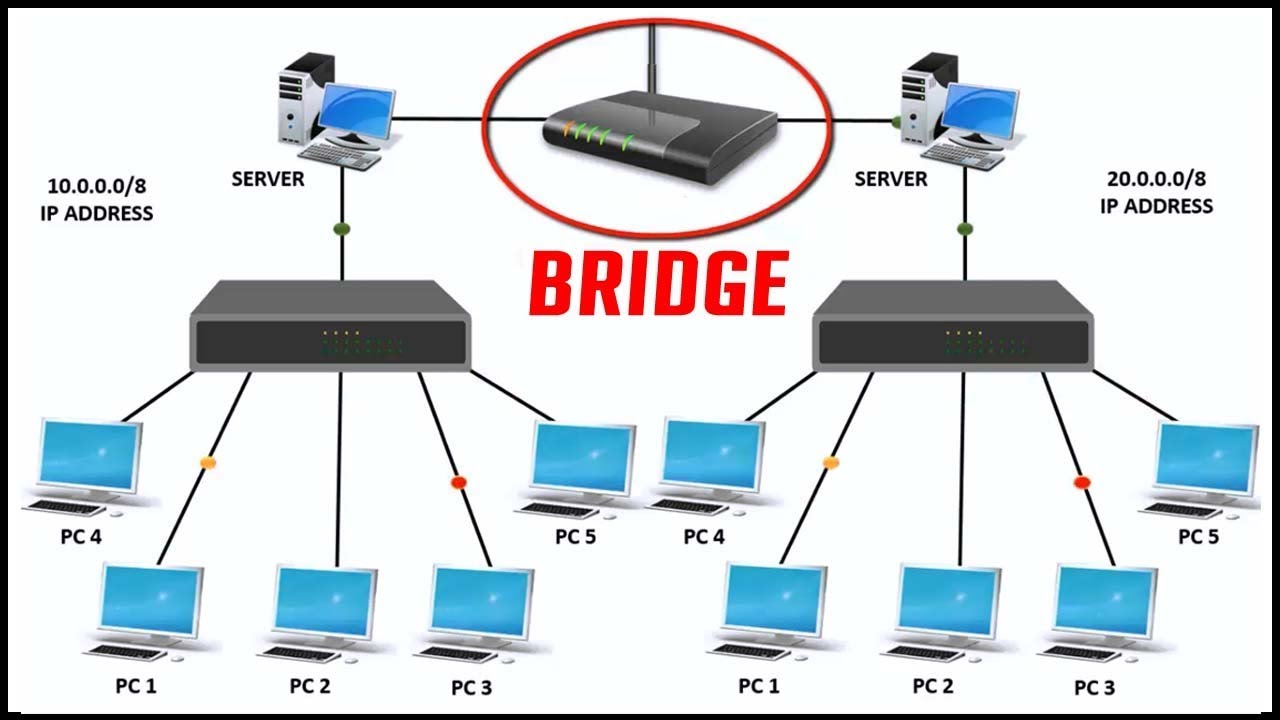
Сетевой мост соединяет две другие отдельные компьютерные сети, чтобы обеспечить связь между ними и позволить им работать как единая сеть. Мосты используются с локальными сетями (ЛВС), чтобы расширить их охват, чтобы охватить более крупные физические области, чем может достичь ЛВС.
Как работают сетевые мосты
Мостовые устройства проверяют входящий сетевой трафик и определяют, следует ли пересылать или отбрасывать его в соответствии с назначенным пунктом назначения. Например, мост Ethernet проверяет каждый входящий кадр Ethernet, включая MAC-адреса источника и назначения, иногда размер кадра, при принятии индивидуальных решений о пересылке. Мостовые устройства работают на уровне линии передачи данных модели OSI
Типы сетевых мостов
Мостовые устройства существуют для Wi-Fi до Wi-Fi, Wi-Fi до Ethernet и Bluetooth для Wi-Fi-соединений. Каждый из них предназначен для определенных типов сетей.
- Беспроводные мосты поддерживают точки беспроводного доступа Wi-Fi.
- Мосты Wi-Fi для Ethernet позволяют подключаться к клиентам Ethernet и связывать их с локальной сетью Wi-Fi, что полезно для более старых сетевых устройств, которым не хватает Wi-Fi.
- Мост Bluetooth для Wi-Fi поддерживает соединения с мобильными устройствами Bluetooth, которые распространяются в домах и офисах в последние годы.
Беспроводное мостовое соединение
Мосты особенно популярны в компьютерных сетях Wi-Fi. В беспроводном соединении Wi-Fi требуется, чтобы точки доступа связывались друг с другом в специальном режиме, который поддерживает трафик, который течет между ними. Две точки доступа, поддерживающие режим беспроводного моста, работают как пара. Каждый из них продолжает поддерживать свою собственную локальную сеть подключенных клиентов, а также обменивается информацией с другой, чтобы обрабатывать мост.
Режим моста можно активировать в точке доступа через административную настройку или иногда физический переключатель на устройстве. Не все точки доступа поддерживают режим беспроводного моста; обратитесь к документации производителя, чтобы определить, поддерживает ли данная модель эту функцию.
Мосты против ретрансляторов
Мосты и сетевые ретрансляторы имеют сходный внешний вид; иногда один блок выполняет обе функции. Однако, в отличие от мостов, ретрансляторы не выполняют никакой фильтрации трафика и не объединяются в две сети. Вместо этого повторители передают весь трафик, который они получают. Ретрансляторы служат главным образом для регенерации сигналов трафика, так что одна сеть может достигать более длительных физических расстояний.
Мосты и коммутаторы и маршрутизаторы
В проводных компьютерных сетях мосты выполняют аналогичную функцию, как сетевые коммутаторы . Традиционно проводные мосты поддерживают одно входящее и одно исходящее сетевое соединение, доступное через аппаратный порт , тогда как коммутаторы обычно предлагают четыре или более аппаратных порта. По этой причине коммутаторы иногда называют многопортовыми мостами.
Читайте также: