
Что такое процессорный конвейер
Конвейер команд. Конвейеризация — способ обеспечения параллельности выполнения команд
Первым шагом на пути обеспечения параллельности уровня команд явилось создание конвейера команд. Идея конвейера команд была предложена в 1956 году С.А. Лебедевым. Команда подразделяется на несколько этапов, каждый из которых выполняется своей частью аппаратуры, причем, эти части могут работать параллельно. Если на выполнение каждого этапа расходуется одинаковое время (один такт), то на выходе процессора в каждый такт появляется результат очередной команды. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняется несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах. Количество этапов, на которые конструкторы разбивают выполнение процессорной команды, может быть различным (в разных моделях процессоров х86 колеблется от 2 i8088 до 20 Pentium IV).
Трудности
Множество схем включают в себя конвейеры в 7, 10 или даже 20 уровней (как, например, в Intel Pentium 4). Поздние ядра Pentium 4 с кодовыми именами «Prescott» и «Cedar Mill» (и их Pentium D-производные) имеют 31-уровневый конвейер, самый длинный среди популярных процессоров. Xelerator X10q имеет конвейер длиной более, чем в тысячу шагов [1] . Обратной стороной медали в данном случае является необходимость сбрасывать полностью весь конвейер в случае, если ход программы изменился (например, по условному оператору). Эту проблему пытаются решать предсказатели переходов (англ. en:Branch predictor ). Предсказание переходов само по себе может только усугубить ситуацию, если предсказание производится плохо. В некоторых областях применения, таких как вычисления на суперкомпьютерах, программы специально пишутся так, чтобы как можно реже использовать условные операторы, поэтому очень длинные конвейеры весьма позитивно скажутся на общей скорости вычислений, так как длинные конвейеры проектируются так, чтобы уменьшить CPI (количество тактов на инструкцию). Если ветвление происходит постоянно, переорганизация таким образом, чтобы те инструкции, которые, скорее всего, понадобятся, были размещены в конвейере, может значительно уменьшить потери скорости по сравнению с необходимостью каждый раз полностью сбрасывать конвейер. Программы типа gcov могут использоваться для того, чтобы определять, как часто отдельные ветки исполняются на самом деле, используя технологию, известную как анализ покрытия кода (англ. Code coverage analysis , хотя на практике подобный анализ является последней мерой при оптимизации.
Высокая пропускная способность конвейеров оборачивается тормозами в случае, если в исполняемом коде содержится много условных переходов: процессор не знает, откуда читать следующую инструкцию, и поэтому вынужден ждать, когда закончится инструкция условного перехода, оставляя за ней пустой конвейер. После того, как ветка будет пройдена и станет известно, куда процессору необходимо переходить в дальнейшем, следующая инструкция должна будет пройти весь путь через конвейер перед тем, как результат становится доступным и процессор снова «работает». В крайнем случае, производительность конвейерного процессора может теоретически упасть до производительности безконвейерного, или даже быть хуже за счет того, что будет занят только один уровень конвейера и между уровнями присутствует небольшая задержка.
Из-за конвейера процессора, код, который загружает процессор, не будет исполнен мгновенно. Из-за этого, обновления в коде, которые находятся очень близко к текущему месту исполнения программы, могут пройти незамеченными из-за того, что код уже предзагружен в en:Prefetch Input Queue. Кэши инструкций (англ. en:Instruction cache ) еще больше усугубляют эту проблему. Стоит учитывать, что данная проблема присутствует только в самомодифицирующихся программах.
Конве́йер — это способ организации вычислений, используемый в современных процессорах и контроллерах с целью ускорения выполнения инструкций (увеличения числа инструкций, выполняемых в единицу времени).
Идея состоит в разделении обработки машинной инструкции на последовательность независимых стадий с памятью в конце каждой стадии. Это позволяет управляющим схемам инициировать обработку инструкций с темпом обработки на самой медленной стадии, что гораздо быстрее, чем время, необходимое для выполнения всех стадий сразу. Таким образом, в каждый момент времени в разных стадиях обработки находятся несколько инструкций. Это схемотехническое решение носит название конвейер инструкций.
Wikimedia Foundation . 2010 .
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Примеры
Содержание
Смотреть что такое "Конвейер (процессоры)" в других словарях:
Конвейер (процессоры)/Перевод — Пожалуйста, не удаляйте эту статью! В данный момент в ней идет работа по переводу основной английской версии для замены кошмарной русской. После завершения работы я объединю получившуюся статью с имеющейся русской версией. Простой пятиуровневый… … Википедия
Конвейер (процессор) — У этого термина существуют и другие значения, см. Конвейер (значения). Простой пятиуровневый конвейер в RISC процессорах (IF (англ. Instruction Fetch) получение … Википедия
Процессоры — Intel 80486DX2 в керамическом корпусе PGA. Intel Celeron 400 socket 370 в пластиковом корпусе PPGA, вид снизу. Intel Celeron 400 socket 370 в пластиковом корпусе PPGA, вид сверху … Википедия
Графический конвейер — Графический конвейер аппаратно программный комплекс визуализации трёхмерной графики. Содержание 1 Элементы трехмерной сцены 1.1 Аппаратные средства 1.2 Программные интерфейсы … Википедия
Вычислительный конвейер — У этого термина существуют и другие значения, см. Конвейер (значения). Конвейер способ организации вычислений, используемый в современных процессорах и контроллерах с целью повышения их производительности (увеличения числа инструкций,… … Википедия
RISC (процессоры) — RISC (англ. Reduced Instruction Set Computing) вычисления с сокращённым набором команд. Это концепция проектирования процессоров, которая во главу ставит следующий принцип: более компактные и простые инструкции выполняются быстрее. Простая… … Википедия
Графические процессоры — Графический процессор (англ. Graphics Proccesing Unit, GPU) отдельное устройство персонального компьютера или игровой приставки, выполняющее графический рендеринг. Современные графические процессоры очень эффективно обрабатывают и изображают… … Википедия
ARM (архитектура) — Эту статью следует викифицировать. Пожалуйста, оформите её согласно правилам оформления статей. У этого термина существуют и другие значения, см. ARM … Википедия
Pentium 4 — > Центральный процессор Производство … Википедия
Willamette — > Центральный процессор Производство: с 2000 по 2008 год Производитель: ЦП: 1300 3800 МГц Частота FSB … Википедия
Конве́йер — способ организации вычислений, используемый в современных процессорах и контроллерах с целью повышения их производительности (увеличения числа инструкций, выполняемых в единицу времени), технология, используемая при разработке компьютеров и других цифровых электронных устройств.
Идея заключается в разделении обработки компьютерной инструкции на последовательность независимых стадий с сохранением результатов в конце каждой стадии. Это позволяет управляющим цепям процессора получать инструкции со скоростью самой медленной стадии обработки, однако при этом намного быстрее, чем при выполнении эксклюзивной полной обработки каждой инструкции от начала до конца.


На иллюстрации справа показан простой пятиуровневый конвейер в RISC-процессорах. Здесь:
- IF (англ.Instruction Fetch ) — получение инструкции,
- ID (англ.Instruction Decode ) — раскодирование инструкции,
- EX (англ.Execute ) — выполнение,
- MEM (англ.Memory access ) — доступ к памяти,
- WB (англ.Register write back ) — запись в регистр.
Вертикальная ось — последовательные независимые инструкции, горизонтальная — время. Зелёная колонка описывает состояние процессора в один момент времени, в ней самая ранняя, верхняя инструкция уже находится в состоянии записи в регистр, а самая последняя, нижняя инструкция только в процессе чтения.
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Преимущества и недостатки
Конвейер помогает не во всех случаях. Существует несколько возможных минусов. Конвейер инструкций можно назвать «полностью конвейерным», если он может принимать новую инструкцию каждый машинный цикл. Иначе в конвейер должны быть вынужденно вставлены задержки, которые выравнивают конвейер, при этом ухудшат его производительность.
- Время цикла процессора уменьшается, таким образом увеличивая скорость обработки инструкций в большинстве случаев.
- Некоторые комбинационные логические элементы, такие как сумматоры или умножители могут быть ускорены путем увеличения количества логических элементов. Использование конвейера может предотвратить ненужное наращивание количества элементов.
- Беcконвейерный процессор исполняет только одну инструкцию за раз. Это предотвращает задержки веток инструкций (фактически, каждая ветка задерживается), и проблемы, связанные с последовательными инструкциями, которые исполняются параллельно. Следовательно, схема такого процессора проще и он дешевле для изготовления.
- Задержка инструкций в беcконвейерном процессоре слегка ниже, чем в конвейерном эквиваленте. Это происходит из-за того, что в конвейерный процессор должны быть добавлены дополнительные триггеры.
- У беcконвейерного процессора скорость обработки инструкций стабильна. Производительность конвейерного процессора предсказать намного сложнее, и она может значительно различаться в разных программах.
Пример 1
Допустим, типичная инструкция для сложения двух чисел это СЛОЖИТЬ A, B, C , которая суммирует значения, которые находятся в ячейках памяти A и B, а затем кладет результат в ячейку памяти C. В конвейерном процессоре контроллер может разбить эту операцию на последовательные задачи вида
Ячейки R1 и R2 являются регистрами процессора. Значения, которые хранятся в ячейках памяти, которые мы называем A и B, загружаются (т.е. копируются) в эти регистры, затем суммируются, и результат записывается в ячейку памяти C.
В данном примере конвейер состоит из трех уровней - загрузки, исполнения и записи. Эти шаги называются, очевидно, уровнями или шагами конвейера.
В бесконвейерном процессоре, только один шаг может работать в один момент времени, поэтому инструкция должна полностью закончиться прежде, чем следующая инструкция в принципе начнется. В конвейерном процессоре, все эти шаги могут выполняться одновременно на разных инструкциях. Поэтому когда эта инструкция находится на шаге исполнения, вторая инструкция будет на стадии раскодирования, и третья инструкция будет на стадии прочтения.
Конвейер не уменьшает время, которое необходимо для того, чтобы выполнить инструкцию, но зато он увеличивает объем (число) инструкций, которые могут быть выполнены одновременно и таким образом уменьшает задержку между выполненными инструкциями — увеличивая т.н. пропускную способность. Чем больше уровней имеет конвейер, тем больше инструкций могут выполняться одновременно и тем меньше задержка между завершенными инструкциями. Каждый микропроцессор, произведенный в наши дни, использует как минимум двухуровневый конвейер. Процессоры Intel Pentium 4 имеют 20-тиуровневый конвейер.
Трудности
Множество схем включают в себя конвейеры в 7, 10 или даже 20 уровней (как, например, в Pentium 4). Поздние ядра Pentium 4 с кодовыми именами Prescott и Cedar Mill (и их Pentium D-производные) имеют 31-уровневый конвейер, самый длинный среди популярных процессоров (Xelerator X10q имеет конвейер длиной более, чем в тысячу шагов. [4] ). Обратной стороной медали в данном случае является необходимость сбрасывать весь конвейер в случае, если ход программы изменился (например, по условному оператору). Эту проблему пытаются решать предсказатели переходов. Предсказание переходов само по себе может только усугубить ситуацию, если предсказание производится плохо. В некоторых областях применения, таких как вычисления на суперкомпьютерах, программы специально пишутся так, чтобы как можно реже использовать условные операторы, поэтому очень длинные конвейеры весьма позитивно скажутся на общей скорости вычислений, так как длинные конвейеры проектируются так, чтобы уменьшить CPI (англ. Clocks Per Instruction , количество тактов на инструкцию). Если ветвление происходит постоянно, переорганизация таким образом, чтобы те инструкции, которые, скорее всего, понадобятся, были размещены в конвейере, может значительно уменьшить потери скорости по сравнению с необходимостью каждый раз полностью сбрасывать конвейер. Программы типа gcov могут использоваться для того, чтобы определять, как часто отдельные ветки исполняются на самом деле, используя технологию, известную как анализ покрытия кода (англ. Code coverage analysis ), хотя на практике подобный анализ является последней мерой при оптимизации. [источник не указан 755 дней]
Высокая пропускная способность конвейеров оборачивается тормозами в случае, если в исполняемом коде содержится много условных переходов: процессор не знает, откуда читать следующую инструкцию, и поэтому вынужден ждать, когда закончится инструкция условного перехода, оставляя за ней пустой конвейер. После того, как ветка будет пройдена и станет известно, куда процессору необходимо переходить в дальнейшем, следующая инструкция должна будет пройти весь путь через конвейер перед тем, как результат становится доступным и процессор снова «работает». В крайнем случае, производительность конвейерного процессора может теоретически упасть до производительности бесконвейерного, или даже быть хуже за счет того, что будет занят только один уровень конвейера и между уровнями присутствует небольшая задержка.
Из-за конвейера процессора, код, который загружает процессор, не будет исполнен мгновенно. Из-за этого, обновления в коде, которые находятся очень близко к текущему месту исполнения программы, могут пройти незамеченными из-за того, что код уже предзагружен во входную очередь предвыборки (en:Prefetch input queue). Кэш инструкций ещё больше усугубляют эту проблему. Стоит учитывать, что данная проблема присутствует только в самомодифицирующихся программах, а также в упаковщиках исполняемых файлов.
Пример 1
Допустим, типичная инструкция для сложения двух чисел это СЛОЖИТЬ A, B, C . Эта инструкция суммирует значения, находящиеся в ячейках памяти A и B, а затем кладет результат в ячейку памяти C. В конвейерном процессоре контроллер может разбить эту операцию на последовательные задачи вида
Ячейки R1, R2 и R3 являются регистрами процессора. Значения, которые хранятся в ячейках памяти, которые мы называем A и B, загружаются (то есть копируются) в эти регистры, затем суммируются, и результат записывается в ячейку памяти C.
В данном примере конвейер состоит из трех уровней — загрузки, исполнения и записи. Эти шаги называются, очевидно, уровнями или шагами конвейера.
В бесконвейерном процессоре, только один шаг может работать в один момент времени, поэтому инструкция должна полностью закончиться прежде, чем следующая инструкция в принципе начнется. В конвейерном процессоре, все эти шаги могут выполняться одновременно на разных инструкциях. Поэтому когда первая инструкция находится на шаге исполнения, вторая инструкция будет на стадии раскодирования, а третья инструкция будет на стадии прочтения.
Конвейер не уменьшает время, которое необходимо для того, чтобы выполнить инструкцию, но зато он увеличивает объём (число) инструкций, которые могут быть выполнены одновременно и таким образом уменьшает задержку между выполненными инструкциями — увеличивая т. н. пропускную способность. Чем больше уровней имеет конвейер, тем больше инструкций могут выполняться одновременно и тем меньше задержка между завершенными инструкциями. Каждый микропроцессор, произведенный в наши дни, использует как минимум двухуровневый конвейер.
Бесконвейерная архитектура
Бесконвейерная архитектура значительно менее эффективна из-за меньшей загрузки функциональных модулей процессора в то время, пока один или небольшое число модулей выполняет свою роль во время обработки инструкций. Конвейер не убирает полностью время простоя модулей в процессорах как таковое и не уменьшает время выполнения каждой конкретной инструкции, но заставляет модули процессора работать параллельно над разными инструкциями, увеличивая тем самым количество инструкций, выполняемых за единицу времени, а значит и общую производительность программ.
Процессоры с конвейером внутри устроены так, что обработка инструкций разделена на последовательность стадий, предполагая одновременную обработку нескольких инструкций на разных стадиях. Результаты работы каждой из стадий передаются через ячейки памяти на следующую стадию, и так — до тех пор, пока инструкция не будет выполнена. Подобная организация процессора, при некотором увеличении среднего времени выполнения каждой инструкции, тем не менее обеспечивает значительный рост производительности за счёт высокой частоты завершения выполнения инструкций.
Не все инструкции являются независимыми. В простейшем конвейере, где обработка инструкции представлена пятью стадиями, для обеспечения полной загрузки, в то время пока заканчивается обработка первой инструкции, должно обрабатываться параллельно ещё четыре последовательных независимых инструкции. Если последовательность содержит инструкции, зависимые от выполняемых в данный момент, то управляющая логика простейшего конвейера приостанавливает несколько начальных стадий конвейера, помещая этим самым в конвейер пустую инструкцию («пузырёк»), иногда неоднократно, — до тех пор, пока зависимость не будет разрешена. Существует ряд приёмов, таких как форвардинг, значительно снижающих необходимость приостанавливать в таких случаях часть конвейера. Однако зависимость между инструкциями, одновременно обрабатываемыми процессором, не позволяет добиться увеличения производительности кратно количеству стадий конвейера в сравнении с бесконвейерным процессором.
Содержание
Конвейеризация — способ обеспечения параллельности выполнения команд
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды — IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
- декодирование команды / выборка операндов из регистров — ID;
- выполнение операции / вычисление эффективного адреса памяти — EX;
- обращение к памяти — MEM;
- запоминание результата — WB.
В зависимости от типа команды и способа адресации, время выполнения команды сильно варьируется. Дольше всего выполняются этапы, связанные с обращением к памяти. На рисунках показаны блоки и конвейер команд гипотетического процессора, имеющего пять блоков исполнения команд и соответственно пять этапов (ступеней). Изображены выполняемые команды, номера тактов и этапы выполнения команд. На первом такте считывается первая команда. На втором, пока декодируется первая команда, считывается вторая. На пятом такте в процессоре одновременно находятся пять команд, каждая в своем узле.

Блоки прохождения команды в процессоре
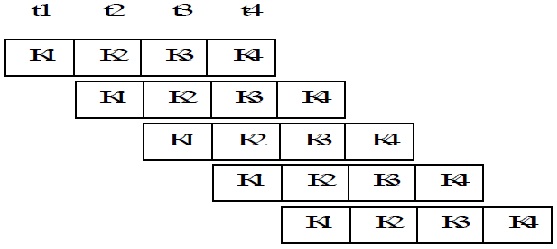
Пятиступенчатая схема конвейера
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. Имеются некоторые накладные расходы на конвейеризацию, возникающие в результате несбалансированности задержки на каждой его ступени. Частота синхронизации (такт синхронизации) не может быть выше, чем время, необходимое для работы наиболее медленной ступени конвейера. Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соответствии с логикой обработки. Отдельные блоки в цепочке могут пропускаться, а другие — образовывать циклические процедуры. Это позволяет с помощью одного конвейера вычислять более одной функции.
Поток команд — естественная последовательность команд, проходящая по конвейеру процессора. Процессор может поддерживать несколько потоков команд (суперпроцессоры 5 и 6 поколения), если для каждого потока и каждого этапа есть исполнительные элементы.
Суперконвейер команд — разбиение каждой ступени на подступени при одновременном увеличении тактовой частоты внутри конвейера; включение в состав процессора многих конвейеров, работающих с перекрытием. Дробление ступеней позволяет поднять тактовые частоты процессора. К суперконвейерным относятся процессоры, в которых число ступеней больше шести (см. таблицу).
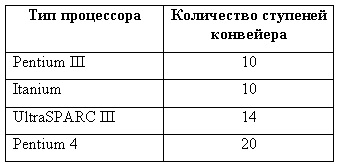
Суперконвейер
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
Примеры
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Общий конвейер
Справа изображён общий конвейер с четырьмя стадиями работы:
- Получение (англ.Fetch )
- Раскодирование (англ.Decode )
- Выполнение (англ.Execute )
- Запись результата (англ.Write-back )
Верхняя серая область — список инструкций, которые предстоит выполнить. Нижняя серая область — список инструкций, которые уже были выполнены. И средняя белая область является самим конвейером.
Выполнение происходит следующим образом:
- Зелёная инструкция забирается из памяти
- Зелёная инструкция раскодируется
- Фиолетовая инструкция забирается из памяти
- Зелёная инструкция выполняется (то есть исполняется то действие, которое она кодировала)
- Фиолетовая инструкция раскодируется
- Синяя инструкция забирается из памяти
- Итоги исполнения зелёной инструкции записываются в регистры или в память
- Фиолетовая инструкция выполняется
- Синяя инструкция раскодируется
- Красная инструкция забирается из памяти
- Зелёная инструкция завершилась
- Итоги исполнения фиолетовой инструкции записываются в регистры или в память
- Синяя инструкция выполняется
- Красная инструкция раскодируется
- Фиолетовая инструкция завершилась
- Результаты исполнения синей инструкция записываются в регистры или в память
- Красная инструкция выполняется
- Синяя инструкция завершилась
- Итоги исполнения красной инструкции записываются в регистры или в память
- Красная инструкция завершилась
Пузырёк
Когда в выполнении по каким-либо причинам случается небольшой сбой или задержка, в конвейере получается «пузырёк», в котором не происходит ничего полезного. Во втором такте обработка фиолетовой инструкции задерживается и вместо стадии расшифровки в третьем такте теперь находится пузырёк. Всё, что находится «за» фиолетовой инструкцией, испытывает задержку в один такт, тогда как всё, что находится «перед» фиолетовой инструкцией продолжает исполняться.
Очевидно, что наличие пузырька в конвейере даёт суммарное время исполнения в 8 тактов вместо 7 на схеме исполнения, показанной выше.
Пузырьки — это как заглушки, в которых не происходит ничего полезного при их прочтении, раскодировании, исполнении и записи результата. Они могут быть выражены при помощи инструкции NOP [1] [2] [3] ассемблера.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )

Простой пятиуровневый конвейер в RISC-процессорах (IF (англ. Instruction Fetch ) — получение инструкции, ID (англ. Instruction Decode ) — раскодирование инструкции, EX (англ. Execute ) — выполнение, MEM (англ. Memory access ) — доступ к памяти, WB (англ. Register write back ) — запись в регистр. Вертикальная ось — это последовательные независимые инструкции, горизонтальная — время. Соответственно, в зеленой колонке, которая описывает состояние процессора в один момент времени, самая ранняя, верхняя инструкция уже находится в состоянии записи в регистр, а самая последняя, нижняя инструкция только в процессе чтения.
Конве́йер — это способ организации вычислений, используемый в современных процессорах и контроллерах с целью ускорения выполнения инструкций (увеличения числа инструкций, выполняемых в единицу времени). Применительно к процессорам, является приемом, используемым при разработке компьютеров и других цифровых электронных устройств для увеличения их инструкционной пропускной способности (количеству инструкций, которые могут быть выполнены за определенный временной промежуток).
Идея заключается в том, чтобы разделить обработку компьютерной инструкции на последовательности независимых шагов, с сохранением результатов в конце каждого шага. Это позволяет управляющим цепям компьютера получать инструкции со скоростью самого медленного шага обработки, но такое решение намного быстрее, чем выполнение всех этих шагов эксклюзивно для каждой инструкции.
Сам термин «конвейер» пришел из промышленности, где используется аналогичный принцип работы — материал автоматически подтягивается по ленте конвейера к рабочему, который осуществляет с ним необходимые действия, следующий за ним рабочий выполняет свои функции над получившейся заготовкой, следующий делает еще что-то, таким образом, к концу конвейера цепочка рабочих полностью выполняет все поставленные задачи, не срывая, однако, темпов производства.
Считается, что впервые конвейерные вычисления были использованы либо в проекте ILLIAC II (англ. en:ILLIAC II ), либо в проекте IBM Stretch (англ. en:IBM Stretch ). Проект IBM Stretch предложил термины «получение» (англ. «Fetch» ), «расшифровка» (англ. «Decode» ) и «выполнение» (англ. «Execute» ), которые затем стали общеупотребляемыми.
Многие современные процессоры управляются таймером. Процессор внутри состоит из логики и памяти (триггеров). Когда приходит сигнал от таймера, триггеры приобретают своё новое значение и логике требуется отрезок времени для декодирования новых значений. Затем приходит следующий сигнал от таймера, триггеры снова принимают новые значения, и так далее. Разбивая логику на более мелкие части и вставляя триггеры между частями логики, время, необходимое логике для правильного вывода, уменьшается. В этом случае, интервал сработки таймера процессора может быть соответственно уменьшен. Например, конвейер RISC-процессоров разбит на 5 шагов, с набором триггеров между шагами:
- получение инструкции (англ.Instruction Fetch );
- раскодирование инструкции (англ.Instruction Decode ) и чтение регистров (англ.Register fetch );
- выполнение(англ.Execute );
- доступ к памяти (англ.Memory access );
- запись в регистр (англ.Register write back );
Когда программист (либо компилятор) пишут ассемблерный код, они делают предположение, что каждая инструкция заканчивает выполняться до того, как начнет выполняться следующая за ней. Использование конвейера делает это предположение неверным. Ситуация, когда использование конвейера заставляет программу работать некорректно, известна как «конфликт конвейера» (англ. en:Hazard (computer architecture) ). Существуют различные техники устранения конфликтов, например, форвардинг (англ. «Forwarding» ) или пробуксовка (англ. «Stalling» ).
Неконвейерная архитектура неэффективна потому, что некоторые компоненты (модули) процессора простаивают, пока какой-то из модулей выполняет свою роль в цикле обработки инструкций. Конвейер не убирает полностью время простоя в процессорах как таковое, но заставляет модули процессора работать параллельно, за счет этого увеличивая общую производительность программ.
Процессоры с конвейером внутри устроены так, что они разделены на «этапы», которые могут полу-независимо работать над разными задачами. Каждый этап связан в «цепочку» с другими таким образом, что результаты работы каждого из этапов «скармливаются» следующему этапу в цепочке до тех пор, пока работа не будет выполнена. Подобная организация процессора позволяет значительно уменьшить время работы.
К сожалению, не все инструкции являются независимыми. В простом конвейере обработка инструкции может потребовать 5-ти этапов обработки. Для работы в полную мощность, этот конвейер должен выполнять 4 последовательные независимые инструкции, пока заканчивается обработка первой. Если же 4-х инструкций, которые не зависят от результата выполнения первой инструкции, нет, управляющая логика должна вставлять в конвейер ничего не делающую заглушку (англ. stall ) до тех пор, пока зависимость не будет разрешена. К счастью, такие техники, как форвардинг, значительно уменьшают количество случаев, где всё же необходимо вставлять заглушки (то есть заставлять процессор пробуксовывать). Хотя конвейеры в теории позволяют увеличить производительность по сравнению с бесконвейерным процессором в количество раз, равное количеству этапов (подразумевая, что частота таймера также масштабируется с количеством этапов), в реальности, большинство кода не позволяет идеального выполнения.
Пример 2
Теоретический трёхуровневый конвейер:
| Шаг | Англ. название | Описание |
|---|---|---|
| Выборка | Fetch | Прочитать инструкцию из памяти |
| Исполнение | Execute | Исполнить инструкцию |
| Запись | Write-back | Записать результат в память и/или регистры |
Псевдоассемблерный листинг, который нужно выполнить:
Как это будет исполняться:
| Такт | Выборка | Исполнение | Запись | Пояснение |
|---|---|---|---|---|
| Такт 1 | ЗАГРУЗИТЬ | Инструкция ЗАГРУЗИТЬ читается из памяти. | ||
| Такт 2 | КОПИРОВАТЬ | ЗАГРУЗИТЬ | Инструкция ЗАГРУЗИТЬ выполняется, инструкция КОПИРОВАТЬ читается из памяти. | |
| Такт 3 | СЛОЖИТЬ | КОПИРОВАТЬ | ЗАГРУЗИТЬ | Инструкция ЗАГРУЗИТЬ находится на шаге записи результата, где её результат (то есть число 40) записывается в регистр А. В это же время, инструкция КОПИРОВАТЬ исполняется. Так как она должна скопировать содержимое регистра A в регистр B, она должна дождаться окончания инструкции ЗАГРУЗИТЬ. |
| Такт 4 | ЗАПИСАТЬ | СЛОЖИТЬ | СКОПИРОВАТЬ | Загружена инструкция ЗАПИСАТЬ, тогда как инструкция СКОПИРОВАТЬ прощается с нами, а по инструкции СЛОЖИТЬ в данный момент производятся вычисления. |
И так далее. Следует учитывать, что иногда инструкции будут зависеть от итогов других инструкций (например, как наша инструкция СКОПИРОВАТЬ). Когда более, чем одна инструкция ссылается на определённое место, читая его (то есть используя в качестве входного операнда) либо записывая в него (то есть используя его в качестве выходного операнда), исполнение инструкций не в порядке, который был изначально запланирован в оригинальной программе может повлечь за собой «конфликт конвейера (англ. Hazard )» (о чём упоминалось выше). Существует несколько зарекомендовавших себя приёмов либо для предотвращения конфликтов, либо для их исправления, если они случились.
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
Прерывания
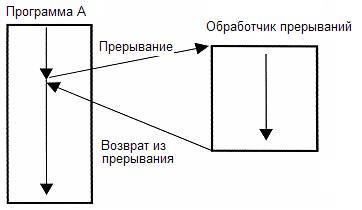
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Преимущества и недостатки
Конвейер помогает не во всех случаях. Существует несколько возможных минусов. Конвейер инструкций можно назвать "полностью конвейерным", если он может принимать новую инструкцию каждый машинный цикл (англ. en:clock cycle ). Иначе в конвейер должны быть вынужденно вставлены задержки, которые выравняют конвейер, при этом ухудшат его производительность.
Преимущества конвейера:
- Время цикла процессора уменьшается, таким образом увеличивая скорость обработки инструкций в большинстве случаев.
- Некоторые комбинационные логические элементы, такие как сумматоры (англ.adders ) или умножители (англ.multipliers ) могут быть ускорены путем увеличения количества логических элементов. Использование конвейера может предотвратить ненужное наращивание количества элементов.
Недостатки конвейера:
- Беcконвейерный процессор исполняет только одну инструкцию за раз. Это предотвращает задержки веток инструкций (фактически, каждая ветка задерживается), и проблемы, связанные с последовательными инструкциями, которые исполняются параллельно. Следовательно, схема такого процессора проще и он дешевле для изготовления.
- Задержка инструкций в беcконвейерном процессоре слегка ниже, чем в конвейерном эквиваленте. Это происходит из-за того, что в конвейерный процессор должны быть добавлены дополнительные триггеры.
- У беcконвейерного процессора скорость обработки инструкций стабильна. Производительность конвейерного процессора предсказать намного сложнее, и она может значительно различаться в разных программах.
Тактовый генератор
Многие современные процессоры управляются тактовым генератором. Процессор внутри состоит из логических элементов и ячеек памяти — триггеров. Когда приходит сигнал от тактового генератора, триггеры приобретают своё новое значение и «логике» требуется некоторое время для декодирования новых значений. Затем приходит следующий сигнал от тактового генератора, триггеры принимают новые значения, и так далее. Разбивая последовательности логических элементов на более короткие и помещая триггеры между этими короткими последовательностями, уменьшают время, необходимое логике для обработки сигналов. В этом случае длительность одного такта процессора может быть соответственно уменьшена.
Например, простейший конвейер RISC-процессоров можно представить пятью стадиями с наборами триггеров между стадиями:
- получение инструкции (англ.Instruction Fetch );
- декодирование инструкции (англ.Instruction Decode ) и чтение регистров (англ.Register fetch );
- выполнение (англ.Execute );
- доступ к памяти (англ.Memory access );
- запись в регистр (англ.Register write back );
Полезное
Общий конвейер

Справа изображен общий конвейер с четырьмя стадиями работы:
- Получение (англ.Fetch )
- Раскодирование (англ.Decode )
- Выполнение (англ.Execute )
- Запись результата (англ.Write-back )
Верхняя серая область — список инструкций, которые предстоит выполнить. Нижняя серая область — список инструкций, которые уже были выполнены. И средняя белая область является самим конвейером.
Выполнение происходит следующим образом:
Пузырек
Когда в выполнении по каким-либо причинам случается небольшой сбой или задержка, в конвейере получается "пузырек", в котором не происходит ничего полезного. Во втором такте обработка фиолетовой инструкции задерживается и вместо стадии расшифровки в третьем такте теперь находится пузырек. Всё, что находится «за» фиолетовой инструкцией, испытывает задержку в один такт, тогда как все, что находится «перед» фиолетовой инструкцией продолжает исполняться.
Очевидно, что наличие пузырька в конвейере дает суммарное время исполнения в 8 тактов вместо 7 на схеме исполнения, продемонстрированной выше.
Пузырьки - это как заглушки, в которых не случается ничего полезного при их прочтении, раскодировании, исполнении и записи результата. Они могут быть выражены при помощи NOP.
Конфликт конвейера
При написании ассемблерного кода (либо разработке компилятора, генерирующего последовательность инструкций) делается предположение, что результат выполнения инструкций будет точно таким, как если бы каждая инструкция заканчивала выполняться до начала выполнения следующей за ней. Использование конвейера сохраняет справедливость этого предположения, однако не обязательно сохраняет порядок выполнения инструкций. Ситуация, когда одновременное выполнение нескольких инструкций может привести к логически некорректной работе конвейера, известна как «конфликт конвейера (англ. Pipeline hazard )». Существуют различные методы устранения конфликтов (форвардинг (англ. Register forwarding ) и другие).
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
История
Сам термин «конвейер» пришёл из промышленности, где используется подобный принцип работы — материал автоматически подтягивается по ленте конвейера к рабочему, который осуществляет с ним необходимые действия, следующий за ним рабочий выполняет свои функции над получившейся заготовкой, следующий делает ещё что-то. Таким образом, к концу конвейера цепочка рабочих полностью выполняет все поставленные задачи, сохраняя высокий темп производства. Например, если на самую медленную операцию затрачивается одна минута, то каждая деталь будет сходить с конвейера через одну минуту.
Считается, что впервые конвейерные вычисления были использованы либо в проекте ILLIAC II (англ.), либо в проекте IBM Stretch (англ.). Проект IBM Stretch предложил термины «получение» (англ. Fetch ), «расшифровка» (англ. Decode ) и «выполнение» (англ. Execute ), которые затем стали общеупотребительными.
Пример 2
Чтобы лучше продемонстрировать идею, давайте посмотрим на теоретический трехуровневый конвейер:
| Шаг | Описание |
|---|---|
| Загрузка | Прочитать инструкцию из памяти |
| Исполнение | Исполнить инструкцию |
| Запись | Записать результат в память и/или регистры |
и на псевдоассемблерный листинг, который нужно выполнить:
Теперь как это всё будет исполняться:
| Загрузка | Исполнение | Запись |
|---|---|---|
| ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ читается из памяти.
| Загрузка | Исполнение | Запись |
|---|---|---|
| КОПИРОВАТЬ | ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ выполняется, тогда как инструкция КОПИРОВАТЬ читается из памяти.
| Загрузка | Исполнение | Запись |
|---|---|---|
| СЛОЖИТЬ | КОПИРОВАТЬ | ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ находится на шаге записи результата, где её результат (т.е. число 40) записывается в регистр А. В это же время, инструкция КОПИРОВАТЬ исполняется. Так как она должна скопировать содержимое регистра A в регистр B, она должна дождаться окончания инструкции ЗАГРУЗИТЬ.
| Загрузка | Исполнение | Запись |
|---|---|---|
| ЗАПИСАТЬ | СЛОЖИТЬ | СКОПИРОВАТЬ |
Загружена инструкция ЗАПИСАТЬ, тогда как инструкция СКОПИРОВАТЬ прощается с нами, а по инструкции СЛОЖИТЬ в данный момент производятся вычисления.
И так далее. Следует учитывать, что иногда инструкции будут зависеть от результатов других инструкций (например, как наша инструкция СКОПИРОВАТЬ). Когда более, чем одна инструкция ссылается на определенное место, читая его (т.е. используя в качестве входного операнда) либо записывая в него (т.е. используя его в качестве выходного операнда), исполнение инструкций не в порядке, который был изначально запланирован в оригинальной программе может повлечь за собой «конфликт конвейера» (англ. en:Hazard (computer architecture) ) (о чем упоминалось выше). Существует несколько зарекомендовавших себя приемов для либо предотвращения конфликтов, либо их исправления, если они случились.
Читайте также: